Linux 磁盘管理+实例
目录
一、文件系统
二、添加磁盘
三、查看磁盘信息(块设备)
四、分区
1、格式
1)MBR分区
2)GPT分区
2、管理分区
1)使用fdisk
2)使用gdisk
3)使用parted
a.交互式
b.非交互式
3、格式化分区
五、挂载
1、格式:
2、取消挂载
3、自动挂载
六、查看磁盘空间使用量
1、df
2、du
七、实操(分区+格式化+挂载)
一、文件系统
Windows常见的文件系统:nfs、fat32
Linux常见的文件系统:ext4,xfs,vfat
nfs(Windows Network File System) :电脑使用的新式的文件系统,只能在Windows上用
fat32:跨平台,兼容性强,稳定性好,一般用于U盘,但大小有限制
ext4:配置了日志系统,软件数据容易恢复,注重稳定性
xfs:更注重性能,性能更强
vfat:类似fat32,为跨平台而设计的
二、添加磁盘
如何再添加一块磁盘?
选择要配置的虚拟机(关机状态),打开虚拟机设置,硬件下 “添加” ,点击后,硬件类型选择硬盘,然后一直下一步就🆗,最后记得“完成”+"确定"
磁盘类型推荐选择NVMe(V)[专门兼容固态盘],磁盘大小不要给太大,20G左右就足够了
三、查看磁盘信息(块设备)
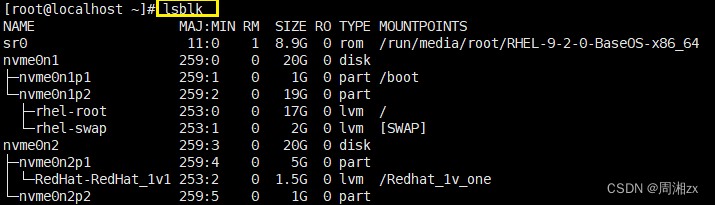
[root@localhost ~]# lsblk
[root@localhost ~]# lsscsi
四、分区
1、格式
1)MBR分区
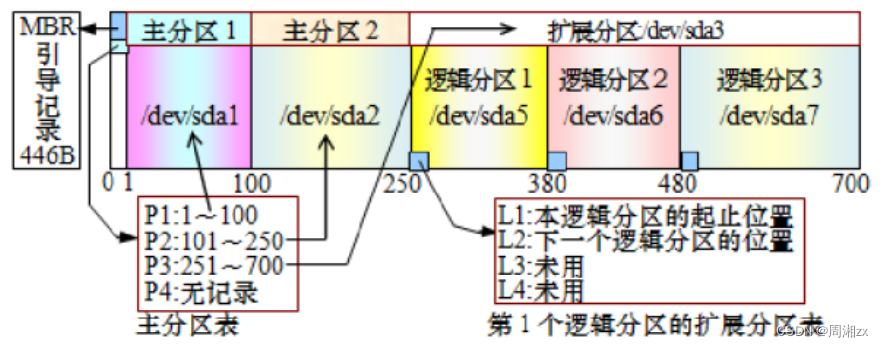
分区空间最大支持2.2TB;支持的分区数量:4个主分区或者3个主分区1个扩展分区
主分区(primary partition):一块硬盘最多4个主分区,主分区不可以再进行二次分区。 主分区可以直接建立文件系统,存放数据 可以用来引导、启动操作系统
扩展分区(extended partition):一块硬盘最多一个扩展分区,加主分区最多4个,不能创建文件系统;扩展分区可以划分逻辑分区(logical partition),逻辑分区可以创建文件系统,存放数据逻辑分区的数量没有限制。
2)GPT分区
——比MBR分区更先进、更灵活的磁盘分区模式
在默认情况下,GPT最多可支持128个分区
支持大于2.2TB的总容量及大于2.2TB的分区,最大支持18EB(1EB=1024PB,1PB=1024TB)
GPT分区表自带备份;向后兼容,GPT分区表上包含保护性的MBR区域
2、管理分区
1)使用fdisk
——默认将磁盘划分为mbr格式的分区;以交互方式进行操作,在菜单中选择相应功能键即可
命令:fdisk 设备名

[root@localhost ~]# fdisk /dev/sda #对sda进行分区
Command (m for help): # 进入fdisk交互界面进行分区
Command (m for help): m #输入m可查看帮助信息
Command (m for help): n #输入n创建新分区
Select (default p): p #输入p创建主分区
Command (m for help): p #输入p查看分区信息
Command (m for help): w #所有分区设置完成后,输入w保存,即可退出fdisk交互界面
2)使用gdisk
——默认将磁盘划分为GPT格式的分区
[root@localhost ~]# gdisk /dev/sda #进入gdisk交互界面
Command (? for help): ? #输入?可查看帮助信息
Command (? for help): n #输入n创建新分区
Command (? for help): p #输入p查看分区情况
Command (? for help): w #输入w保存分区并退出gdisk交互界面
Do you want to proceed? (Y/N): y
3)使用parted
a.交互式
[root@localhost ~]# parted /dev/sda #进入parted交互界面
(parted) help #输入help查看帮助信息
(parted) mklabel #创建一个分区表
New disk label type? yes
New disk label type? gpt
#默认为msdos形式的分区,我们要正确分区大于2TB的磁盘,应该使用gpt方式的分区表,输入gpt后回车(parted) mkpart #进行分区操作
Partition name? []? dp2 #输入分区名称
File system type? [ext2]? #文件系统 (类型:ext4,ext3,ext2,xfs,其他...... )
Start? 0
#开始位置 (0:设定当前分区的起始点为磁盘的第一个扇区;1G:设定当前分区的起始点为磁盘的1G处开始)End? 10G
#结束位置(-1:设定当前分区的结束点为磁盘的最后一个扇区;10G:设定当前分区的结束点为磁盘的10G处)(parted) p #查看分区信息(parted) quit #退出parted交互界面
b.非交互式
——可将命令行写在脚本中,运行脚本实现一键创建;适用于远程批量管理多台主机的场景。 设置分区格式为gpt/mbr
格式: parted 设备 mkpart PART-TYPE [FS-TYPE] START END
PART-TYPE:分区类型,primary(主分区)logical(逻辑分区)extended(扩展分 区)
FS-TYPE:可选项,文件系统类型,ext4、ext3、xfs等等
START:设定磁盘分区起始点;可以为0或者numberMiB/GiB/TiB
END:设定磁盘分区结束点;可以为-1或者numberMiB/GiB/Ti
[root@localhost ~]# parted /dev/sda mklabel gpt
[root@kongd ~]# parted /dev/sda mklabel msdos
#创建1G大小的分区
[root@localhost ~]# parted /dev/sda mkpart primary 0 1G
#删除分区
[root@kongd ~]# parted /dev/sda rm 1
3、格式化分区
格式化的目的: 是为了形成文件系统,文件系统是操作系统用于明确存储设备或分区上的文件的方法和 数据结构;即在存储设备上组织文件的方法。
格式: mkfs|mkfs.xfs|mkfs.ext4 [选项] 分区的设备名
选项:
-t 文件系统类型——当命令名为mkfs时,指定要创建的文件系统的类型(如:xfs、ext4、vfat等)。 当命令名为mkfs.xfs、mkfs.ext4等时,不需要该选项。
-c——建立文件系统前先检查坏块。
-V——输出建立文件系统的详细信息。
如果已有其他文件系统创建在此分区,必须在 mkfs.xfs 命令中加上选项 -f 强行进行格式化
[root@localhost ~]# mkfs.xfs /dev/sda1
[root@localhost ~]# mkfs.ext4 /dev/sda2
[root@localhost ~]# blkid # 查看格式化后的磁盘分区信息

五、挂载
——将一个分区或者设备挂载至挂载点目录。
1、格式:
mount [-t 文件系统类型] 设备名 挂载点目录
[root@localhost ~]# mkdir /Redhat_1v_one # 创建挂载点目录
[root@localhost ~]# mount /dev/RedHat/RedHat_1v1 /Redhat_1v_one # 挂载# 查看挂载信息
[root@localhost ~]# mount | grep /dev/mapper/RedHat-RedHat_1v1
/dev/mapper/RedHat-RedHat_1v1 on /Redhat_1v_one type xfs (rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,noquota)2、取消挂载
umount 挂载点目录或存储设备名
[root@localhost ~]# umount /dev/sda13、自动挂载
手动挂载的分区会在系统重启后失效,若用户需要永久挂载分区,则需要通过编辑 /etc/fstab 文件来实现。当系统启动的时候,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的 文件系统挂载到指定的目录
[root@localhost ~]# vim /etc/fstab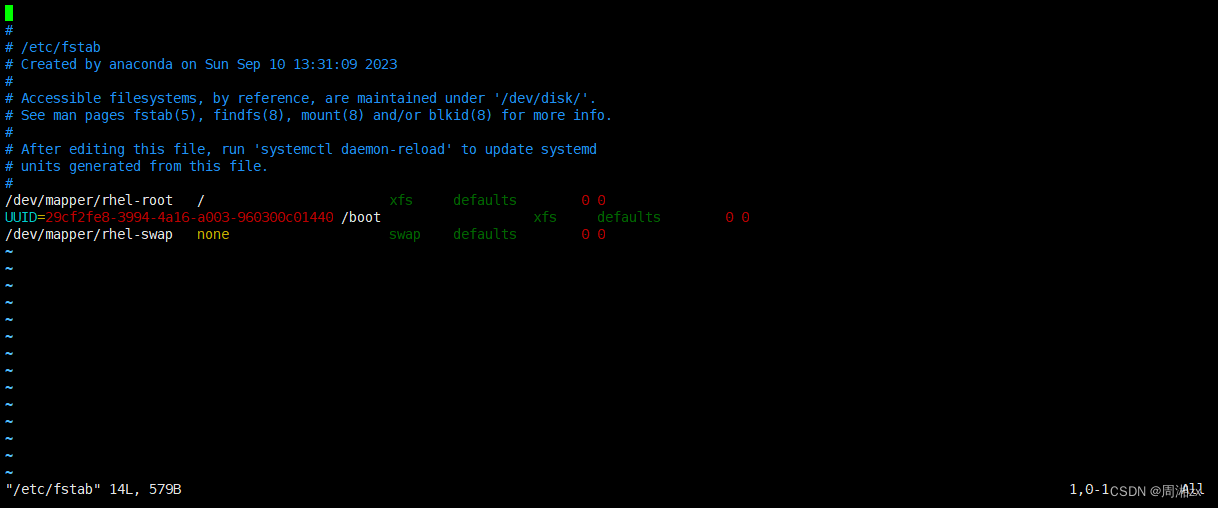
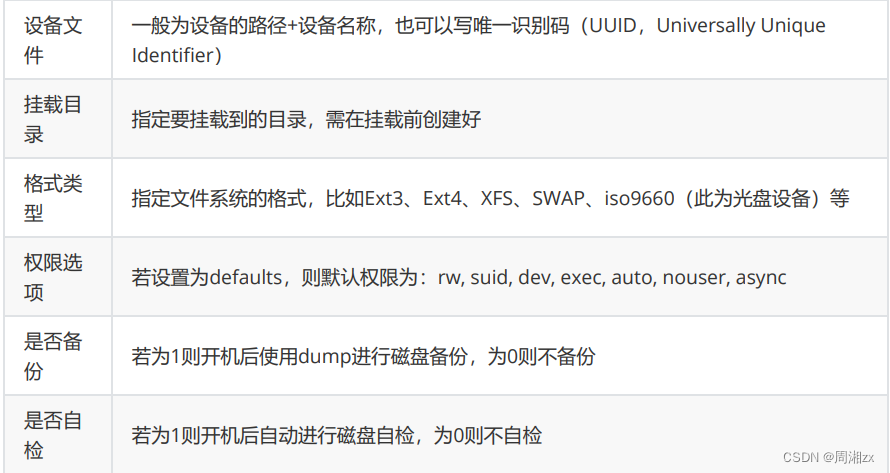
字段解释:
六、查看磁盘空间使用量
1、df
——列出文件系统的磁盘空间占用情况
格式:df [-ahikHTm] [目录或文件名]
选项:
-a:列出所有的文件系统,包括系统特有的/proc等文件系统
-k:以KB的容量显示各文件系统
-m:以MB的容量显示各文件系统
-h:以人们较易阅读的GB,MB,KB等格式自行显示
-H:以M=1000K替代M=1024K的进位方式
-T:连同该分区的文件系统名称(例如ext3)也列出
-i:不用硬盘容量,而以inode的数量来显示
df . 查看当前文件夹的占用

2、du
——显示磁盘空间使用量(统计目录或文件所占磁盘空间大小),在默认情况下,文件大小的单位是KB。
格式:du [-ahskm] 文件或目录名称
选项:
-a : 列出所有的文件与目录容量,因为默认仅统计目录下面的文件量而已;
-h : 以人们较易读的容量格式(G/M)显示;
-s : 列出总量,而不列出每个个别的目录占用了容量;
-S : 不包括子目录下的总计,与-s有点差别;
-k : 以KB列出容量显示;
-m : 以MB列出容量显示。

七、实操(分区+格式化+挂载)
1、思路:
- 创建分区 nvme1,nvme2(两个分区)
- 通过该分区创建物理卷pv(pvcreate)
- 通过pv 创建卷组vg(vgcreate 卷组名 pv1,pv2...)
- 通过vg 产生逻辑卷lv(lvcreate -n 逻辑卷名 -L + 容量(K,M,G))
- mkfs.xfx ext4 vfat 将lv格式化
- 然后将lv 挂载到某个文件夹下
逻辑卷的相关知识:Linux 逻辑卷-CSDN博客
2、实践:
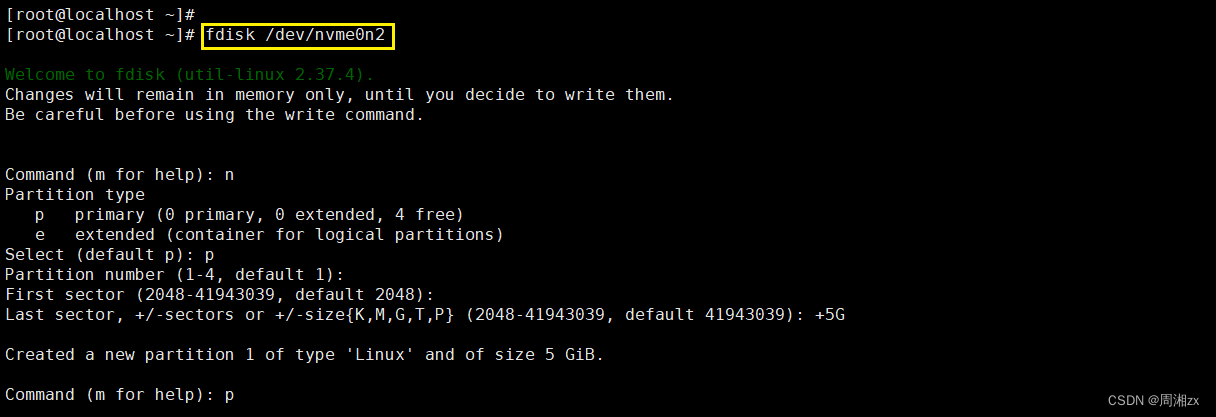
# 使用fdisk进行分区
Command (m for help): n
Partition typep primary (0 primary, 0 extended, 4 free)e extended (container for logical partitions)
Select (default p): p # 主分区
Partition number (1-4, default 1): # 默认
First sector (2048-41943039, default 2048): # 默认
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-41943039, default 41943039): +5G
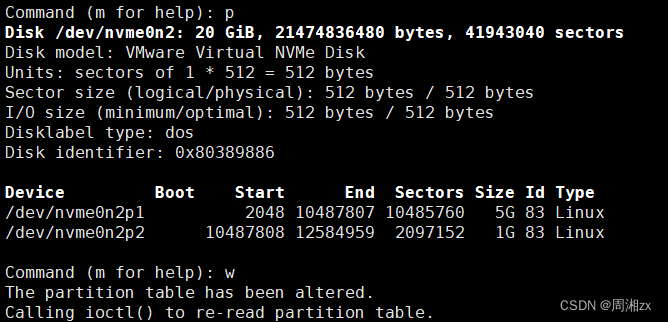
# 分配5G的内存Created a new partition 1 of type 'Linux' and of size 5 GiB.Command (m for help): p # 显示磁盘分区信息
Disk /dev/nvme0n2: 20 GiB, 21474836480 bytes, 41943040 sectors
Disk model: VMware Virtual NVMe Disk
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x80389886Device Boot Start End Sectors Size Id Type
/dev/nvme0n2p1 2048 10487807 10485760 5G 83 LinuxCommand (m for help): n # 再进行一次分区
Partition typep primary (1 primary, 0 extended, 3 free)e extended (container for logical partitions)
Select (default p): p
Partition number (2-4, default 2):
First sector (10487808-41943039, default 10487808):
Last sector, +/-sectors or +/-size{K,M,G,T,P} (10487808-41943039, default 41943039): +1GCreated a new partition 2 of type 'Linux' and of size 1 GiB.
查看磁盘信息
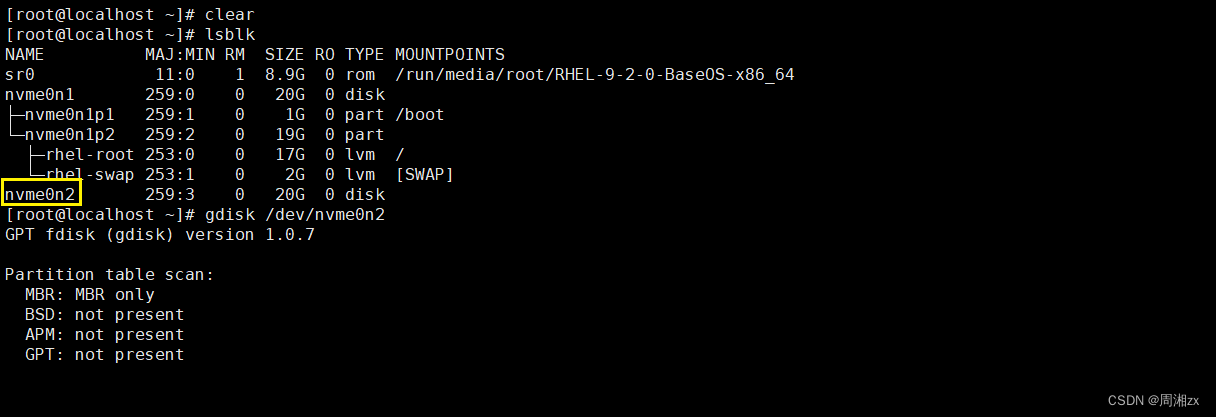
对nvme0n2进行分区
[root@localhost ~]# pvcreate /dev/nvme0n2p1 # 创建物理卷
[root@localhost ~]# pvscan # 查看系统中的物理卷信息
[root@localhost ~]# pvcreate /dev/nvme0n2p2# 卷组创建,RedHat是自定义的卷组名称,由/dev/nvme0n2p1 和 /dev/nvme0n2p{1,2} 构成
[root@localhost ~]# vgcreate RedHat /dev/nvme0n2p{1,2}
[root@localhost ~]# vgscan # 查看系统中的卷组信息
[root@localhost ~]# vgdisplay RedHat # 指定卷组详情# 从卷组RedHat中创建逻辑卷,-n 后接名称, -L 后接指定大小
[root@localhost ~]# lvcreate -n RedHat_1v1 -L +1.5G RedHat
[root@localhost ~]# lvscan# 格式化
[root@localhost ~]# mkfs.xfs /dev/RedHat/RedHat_1v1
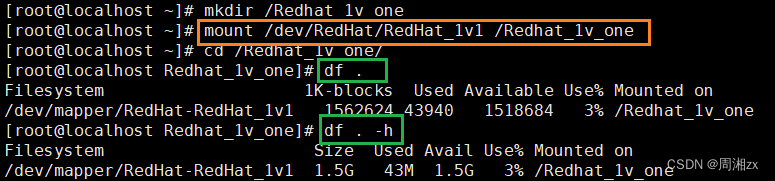
[root@localhost ~]# mkdir /Redhat_1v_one# 挂载
[root@localhost ~]# mount /dev/RedHat/RedHat_1v1 /Redhat_1v_one
[root@localhost ~]# cd /Redhat_1v_one/
[root@localhost Redhat_1v_one]# df .
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/RedHat-RedHat_1v1 1562624 43940 1518684 3% /Redhat_1v_one
[root@localhost Redhat_1v_one]# df . -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/RedHat-RedHat_1v1 1.5G 43M 1.5G 3% /Redhat_1v_one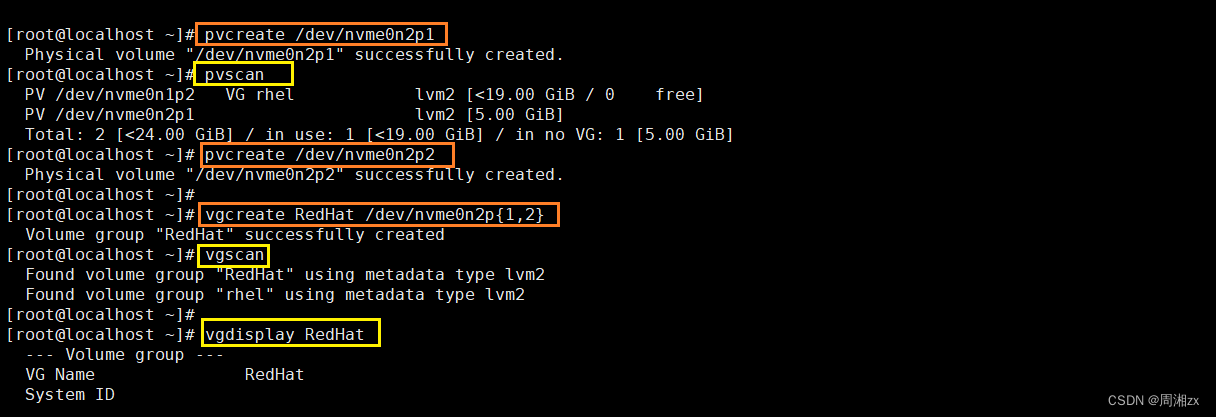

相关文章:
Linux 磁盘管理+实例
目录 一、文件系统 二、添加磁盘 三、查看磁盘信息(块设备) 四、分区 1、格式 1)MBR分区 2)GPT分区 2、管理分区 1)使用fdisk 2)使用gdisk 3)使用parted a.交互式 b.非交互式 3、…...
MongoDB——centOS7安装mongodb5.0.21版本服务端(图解版)
目录 一、mongodb官网下载地址二、安装步骤2.1、上传安装包并解压2.2、配置环境变量2.3、创建目录并授权2.4、创建配置文件2.5、启动MongoDB 三、开放端口四、客户端连接 一、mongodb官网下载地址 mongodb官网下载地址:https://www.mongodb.com/try/download/commu…...
C#实现OPC DA转OPC UA服务器
运行软件前提前安装好OPC运行组件: 为方便演示,提前准备好了一个DAServer服务器: 接下来开始配置: 该软件主要实现的功能如下: 配置过程也相对简单: 第一步: 编辑如下文件: 第二步…...
TCP/IP网络协议通信函数接口
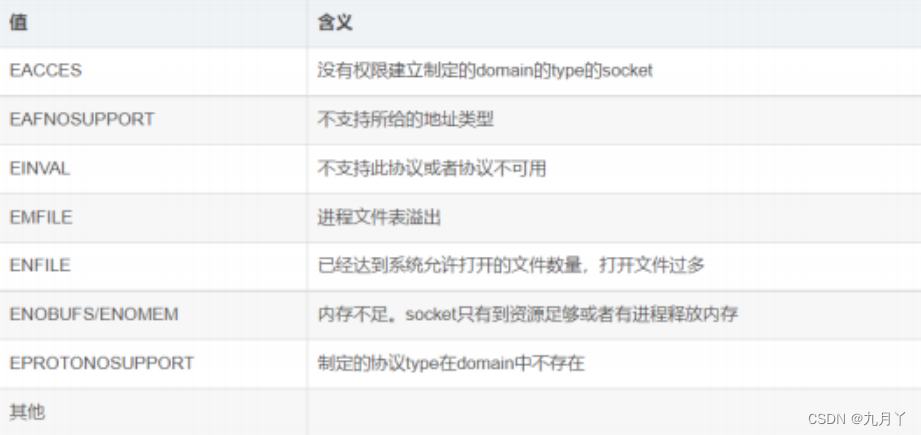
创建套接字函数 socket 【头文件】 #include <sys/types.h> #include <sys/socket.h> 【函数原型】 int socket(int domain, int type, int protocol); 【函数功能】 socket 函数创建一个通信端点,并返回一个引用该端点的文件描述符,…...
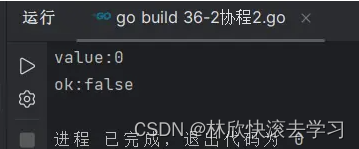
go语言判断管道是否关闭的误区
前言 本文是探讨的是"在Go语言中,我们是否可以使用读取管道时的第二个返回值来判断管道是否关闭?" 样例 在Go语言中,我们是否可以使用读取管道时的第二个返回值来判断管道是否关闭? 可以看下面的代码 package mainimport "fmt"…...
如何轻松使用 ChatGPT 进行论文大纲和创作
ChatGPT能够编写复杂的代码、博客文章等,它可以帮助我们做很多事情。今天本篇文章分享的主要内容如何利用 ChatGPT 来撰写论文文章。下面会介绍如何轻松使用 ChatGPT 进行论文大纲和创作! 1、使用 ChatGPT 确定主题 文章非常重要的一个部分就是主题。如…...

【深蓝学院】手写VIO第6章--视觉前端--笔记
第5章相关内容,还是CSDN的传统Markdown编辑器好用。 视觉前段在14讲课程中已经讲过,这里再简单复习一下。 1. 前端工作的定性比较,分析 这一节讲了很多关于前端的方法框架的对比讨论,后面看完了相关的论文之后强烈建议再回来听一…...
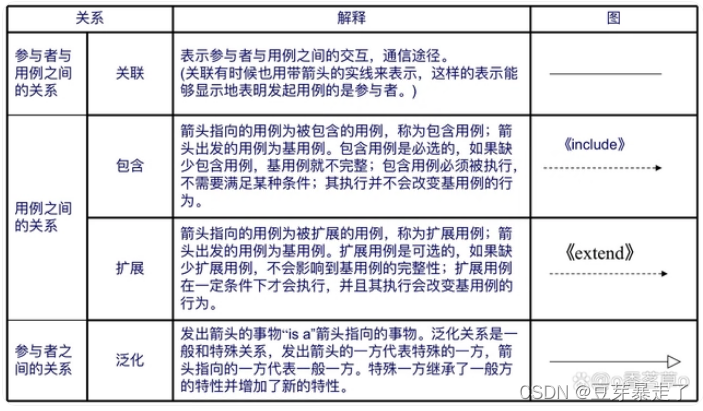
用例图 UML从入门到放弃系列之三
1.说明 关于用例图,这篇文章我将直接照搬罗伯特.C.马丁老爷子在《敏捷开发》一书种的第17章,并配上自己的理解,因为这一章写的实在是太精彩了,希望能够分享给大家,共勉。以下是老爷子的原文中文翻译以及豆芽的个人解读…...

NLP大模型
大模型 1、大模型的模型结构 一般指一亿参数以上的模型。 目前以Transformer为基础自回归生成大致可以分为三种架构: Encoder-only的模型,如BERT Encoder-Decoder的模型,如T5。 Decoder-Only的模型,如GPT系列。...

Python- 将一个字符串列表连接成一个单独的字符串
Python中一个常用的技巧:将一个字符串列表连接成一个单独的字符串。 ,.join(list) 是使用Python的 str.join() 方法。 详细解析: join() 方法: 是一个字符串方法,意味着在一个字符串上调用它。它需要一个参数,通常是一个列表或任…...

深眸科技自研AI视觉分拣系统,实现物流行业无序分拣场景智慧应用
在机器视觉应用环节中,物体分拣是建立在识别、检测之后的一个环节,通过机器视觉系统对图像进行处理,并结合机械臂的使用实现产品分类。 通过引入视觉分拣技术,不仅可以实现自动化作业,还能提高生产线的生产效率和准确…...

吴恩达《微调大型语言模型》笔记
微调(fine-tuning)就是利用特有数据和技巧将通用模型转换为能执行具体任务的一种方式。例如,将 GPT-3 这种通用模型转换为诸如 ChatGPT 这样的专门用于聊天的模型。或者将 GPT-4 转换为诸如 GitHub Coplot 这样的专门用于写代码的模型。 这里…...

Java中的Servlet
Java中的Servlet 在Java中,Servlet是一种用于处理Web请求的服务器端组件。Servlet生命周期是Servlet在运行时所经历的一系列阶段,每个阶段都调用特定的方法。以下是Servlet生命周期内调用的方法过程: 初始化阶段(Initialization&…...

Flutter配置Android SDK路径
在使用VSCode作为开发Flutter的工具时,当选择调试设备时,通常看不到android的模拟器,只能看到Chrome之类的。 原因就是Flutter找不到Android的SDK路径,所以无法识别模拟器,我们用flutter doctor命令检查环境时…...
jwt的基本介绍
说出我的悲惨故事给大家乐呵乐呵:公司刚来了一个实习生,老板让他写几个接口给我,我页面还没画完呢。他就把接口给我了,我敲开心,第一次见这么高效率的后端。但我很快就笑不出来了。他似乎不知道HTTP通信是无状态的。他…...

常见Vue事件修饰符浅析
一、.stop修饰符 .stop修饰符代表event.stopPropagation(),加上这个修饰符,就等于在方法中加上了这句代码。 <!--阻止单击事件继续传播--> <a click.stop"doThis"></a>上面的代码等同于如下代码。 <!--阻止单击事件继…...

怎样开始用selenium进行自动化测试?
如果您刚开始使用 Selenium 进行自动化测试,以下是建议的步骤。 1、安装 Selenium 首先,您需要安装 Selenium。Selenium 支持多种编程语言,如 Python、Java、C# 等。可以通过 pip 命令在 Python 中安装 Selenium: pip install …...

二维数组多次排序 或 嵌套list多次排序
可以排序int[ ][ ]的顺序,也可以排序List<List<Integer>> 顺序 为便于理解,以力扣原题为例:1333.餐厅过滤器 原题中给了一个双重数组,并要求返回一个List<Integer>。 方法1: 会用流的,…...
Flutter - 波浪动画和lottie动画的使用
demo 地址: https://github.com/iotjin/jh_flutter_demo 代码不定时更新,请前往github查看最新代码 波浪动画三方库wave lottie动画 Lottie 是 Airbnb 开发的一款能够为原生应用添加动画效果的开源工具。具有丰富的动画效果和交互功能。 # 波浪动画 https://pub-web…...
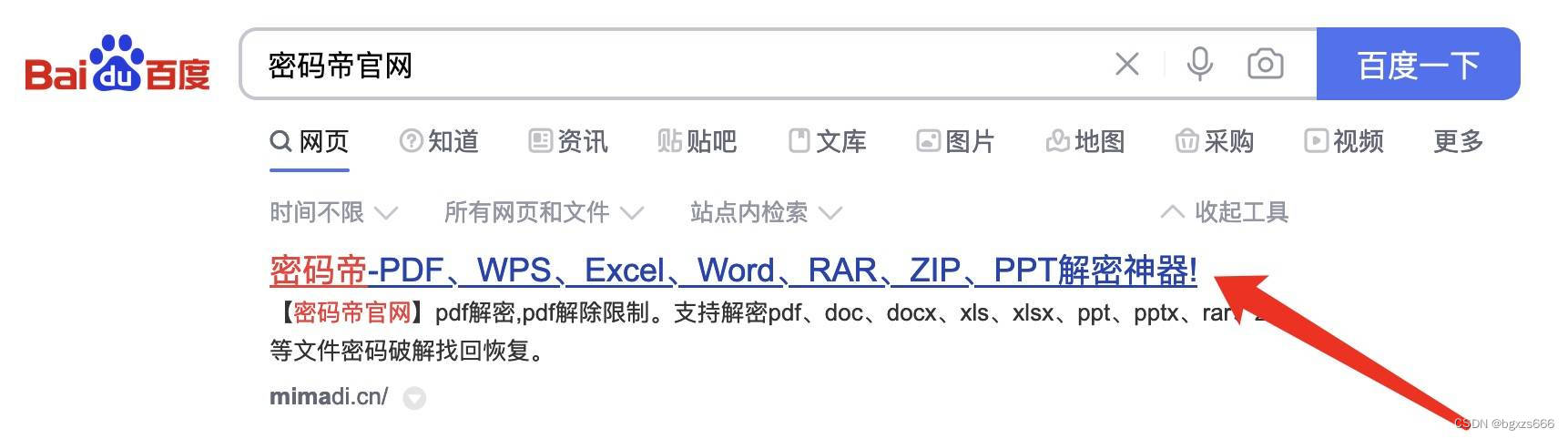
忘记压缩包密码?解决方法一键找回,省时又便捷!
使用在线rar/zip解密工具,找回rar/zip密码并解密压缩包的方法非常简单。具体步骤如下:首先,在百度上搜索“密码帝官网”,这是一个专业的解密服务网站。然后,点击搜索结果中的链接,进入官网首页。在页面上方…...

CursorTouch/Web-Use:用JavaScript在桌面端模拟移动端触摸交互
1. 项目概述:当光标变成你的手指你有没有想过,在电脑上浏览网页时,如果能像在手机上那样,直接用手指滑动、点击、缩放,体验会不会更流畅?尤其是在处理一些需要精细操作或快速浏览长文档的场景时,…...

大疆M4系列+YOLOV8识别算法 如何训练无人机罂粟识别检测数据集 让非法种植无处可藏:无人机+AI罂粟识别数据集发布,覆盖花期_果期多阶段检测 无人机俯拍+AI识别罂粟
无人机俯拍AI识别罂粟,准确率超95%!,助力禁毒攻坚》 《科技禁毒再升级!YOLO实测mAP 83.9%》 《让非法种植无处可藏:无人机AI罂粟识别数据集发布,覆盖花期/果期多阶段检测 智慧巡检 {专业级AI巡查无人机…...

PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案
PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案 【免费下载链接】PPO-PyTorch Minimal implementation of clipped objective Proximal Policy Optimization (PPO) in PyTorch 项目地址: https://gitcode.com/gh_mirrors/pp/PPO-PyTorch PPO-PyTorc…...

扩展卡尔曼滤波锂电池SOC估算【附代码】
✨ 长期致力于锂离子电池、SOC估算、锂离子电池建模、EKF算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)二阶RC等效电路建模与温度自适应参数修正…...

FreeRTOS信号量实战:从同步到互斥的嵌入式设计模式
1. FreeRTOS信号量基础概念与核心价值 第一次接触FreeRTOS信号量时,我盯着开发板愣了半天——这玩意儿不就是个带计数功能的开关吗?后来踩过几次坑才明白,信号量是嵌入式多任务系统的"交通警察",它用最简单的0和1控制着…...

caj2pdf深度解析:如何将中国知网CAJ文件转换为可搜索PDF的完整技术指南
caj2pdf深度解析:如何将中国知网CAJ文件转换为可搜索PDF的完整技术指南 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https:…...

基于CircuitPython的电机动态性能测试系统:从原理到实践
1. 项目概述与核心价值搞电机驱动,最怕的就是“凭感觉”。你手上有个直流有刷电机,数据手册上写着空载转速12000转,堵转扭矩50mNm,但实际装到你的机器人关节或者小车上,带上传动机构,性能到底怎么样&#x…...

Midjourney立体主义风格生成成功率骤降?这5个隐藏变量正在 silently corrupt 你的构图——资深提示工程师紧急诊断报告
更多请点击: https://intelliparadigm.com 第一章:Midjourney立体主义风格生成失效的系统性现象确认 近期大量用户反馈,在 Midjourney v6 及后续快速迭代版本中,使用经典立体主义(Cubism)提示词࿰…...

书成紫微动,律定凤凰驯:一破一立,铁哥的两部作品如何构成完整的文化闭环
书成紫微动,律定凤凰驯。 —— 唐《开元占经》卷一〇三 引言:千年谶语里的文明算法 无破则旧局不死,无立则新局不生。 一句千古古句,藏着文明迭代最严谨的底层逻辑: 先破后立,破立相生,方能形成…...

基于节点电价的电网对电动汽车接纳能力评估模型研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...