联邦学习综述
《Advances and Open Problems in Federated Learning》
- 选题:Published 10 December 2019-Computer Science-Found. Trends Mach. Learn.
联邦学习定义
联邦学习是一种机器学习设置,其中多个客户端在中央服务器或服务提供商的协调下协作解决机器学习问题。客户端的数据不动,让模型动。从而实现数据保护,并且实现模型的训练。
- 第一种分类
- 横向
- 纵向
- 迁移
- 第二种分类
- 跨设备
- 跨孤岛
过程定义
- 客户端的选择:服务器从符合条件中的客户端进行抽取。
- 传播:将选定的模型下发到客户端
- 客户端计算:选定的客户端进行模型的训练和本地模型的更新
- 聚合:客户端将训练结果传送到服务器端,服务器更新汇总,根据具体算法思想进行聚合。
- 模型选择:服务器根据客户端的聚合的结果计算出聚合更新后的模型。
- 重复2~4步

联邦学习所面临的挑战
-
非独立同分布的数据
-
什么是非独立同分布数据(Non-IID)
-
非独立同分布数据(Non-Independent and Identically Distributed, Non-IID)是指在数据集中,样本之间不满足独立同分布的特性。独立同分布是指样本之间独立且具有相同的概率分布。
-
在非独立同分布数据中,样本之间可能存在相关性或者具有不同的概率分布。这种情况常见于某些特定的数据场景,例如时间序列数据、空间数据或者群体数据。对非独立同分布数据进行建模和分析时,需要考虑样本之间的相关性或者概率分布差异,以确保模型的准确性和可靠性。
-
在机器学习和统计分析中,非独立同分布数据的存在可能会影响模型的选择和结果的解释。因此,在处理非独立同分布数据时,需要采用特定的建模方法和统计推断技术,以适应数据的特点和需求。
-
当数据集中的样本不独立同分布时,通常会出现以下一些情况:
-
相关性:样本之间存在相关性,即一个样本的出现可能会影响其他样本的出现。例如,时间序列数据中的前一时刻的观测结果可能会对后一时刻的观测结果产生影响。
-
异方差性:样本的概率分布可能不相同,即样本的方差可能存在差异。例如,某项测量在不同场景下可能具有不同的方差,导致数据不满足同方差性的要求。
-
非平稳性:样本的概率分布可能随着时间、空间或其他因素的改变而发生变化。例如,金融市场中的股票价格可能随着时间的推移而呈现出非平稳性的特征。
- 处理非独立同分布数据的方法取决于具体的数据特点和分析目的。通常可以采用以下方法:
-
建立适当的模型:根据数据的特点选择适当的模型,例如时间序列模型、混合模型或因子模型等,以捕捉数据的相关性和非均匀性。
-
引入随机效应:对于群体数据或者面板数据,可以引入随机效应模型或混合效应模型,以考虑不同样本之间的相关性。
-
数据转换:通过对数据进行差分、标准化或者变换等方法,使数据满足独立同分布的假设,从而适用于传统的统计方法。
-
-
-
常见的方式
- 特征分布倾斜(协变量飘移):即使共享P ( y ∣ x ) ,不同客户端上的边缘分布P i ( x )也可能不同。
- 标签分布倾斜(先验概率飘移):即使P ( x ∣ y )是相同的,对于不同客户端上的边缘分布P i ( y ) 也可能不同。
- 标签相同,特征不同(概念飘移):即使共享P ( y ) ,不同客户端上的条件分布P i ( x ∣ y ) 也可能是不同。由于文化差异,天气影响,生活水平等因素,对于相同的标签y yy,对于不同的客户端可能对应着差异非常大的特征x。
- 特征相同,标签不同(概念飘移):即使P ( X ) 是相同的,对于不同客户端上的条件分布P i ( y ∣ x )也可能不同。由于个人偏好,训练数据项中的相同特征向量可能具有不同的标签。
- 数量倾斜或者不平衡:不同的客户可以拥有着样本数量差异很大的数据。
-
-
通信带宽
-
不可靠的设备
研究方向
-
Non-IID数据的处理
- 非独立同分布数据的处理方法,包括可用客户端的数据分布i ∼ Q (针对客户端采样分布不均匀)和客户端的数据分布( x , y ) ∼ P i ( x , y )都是Non-IID的,现在已经有了一些解决方法,例如通过全局共享的数据集给客户端补足数据;或者是专门设计针对Non-IID的优化算法,或者为不同客户端提供不同的模型。
-
IID和Non-IID在FL中收敛率的研究
- 研究IID和Non-IID数据集的收敛率,不管联邦学习的数据是否为IID,目前FedAvg都已经被证明是收敛的。
-
其他优化
- 个性化:增加输入特征。
- 多任务学习:在所有任务中共享一些参数(一般底层),在特定任务层(顶层)使用自己独有参数,可以考虑将任务作为客户端的子集然后与FL结合。
- 元学习:Meta Learning(元学习)希望使得模型获取一种“学会学习”的能力,使其可以在获取已有“知识”的基础上快速学习新的任务,目前已经有模型不可知元学习算法(MAML)可以与FL结合,但领域较新,还存在诸多问题。
- 改进FL的训练机制:可以考虑是否能以全局模型为每个客户端定制化自己的模型。
-
传统机器学习在FL中存在的问题
- 神经网络结构设计:对于non-IID数据分布,可能会有更好的网络体系结构设计。
- 训练过程中的调试:在传统机器学习中,经验丰富的建模人员可以直接检查子数据集的任务,比如调试错误分类\发现异常值\手动标记样本或检测训练集中的偏差。然而这在联邦学习中是行不通的,开发隐私保护技术来解决此类去中心的问题是主要的开放性问题上。
- 中心服务器分发初始模型时参数的设置:在资源有限的移动设备上使用不同的超参数进行多轮培训可能会受到限制。对于小型设备,这可能导致过度使用有限的通信和计算资源。
-
提高通信效率
- 梯度压缩,减少从客户端到服务器通信的对象的大小,该对象用于更新全局模型;
- 模型广播压缩,减小从服务器向客户端广播的模型的大小,客户端从该模型开始本地训练;
- 减少本地计算(其实也是一种算法压缩),修改整体训练算法,使本地训练过程在计算上更加高效。
-
常见的压缩方法
- 量化方法:降低更新参数的分辨率
- 知识蒸馏:将大模型知识迁移到小模型
- 低秩矩阵:将通信内容结构化,低秩分解。
- 稀疏化:只传递足够重要的信息
隐私计算
-
抵御的威胁
-
在联邦学习中,数据通常分布在不同的设备或机构中,这使得联邦学习面临一些特定的威胁和挑战。以下是一些常见的威胁:
- 隐私泄露:联邦学习的一个主要威胁是隐私泄露,因为原始数据存储在各个设备中,并且数据可能包含敏感信息。攻击者可能通过拦截和分析模型更新、参数传输或梯度信息,来推断出原始数据的一些敏感特征。
- 黑盒攻击:黑盒攻击是指攻击者试图通过仅基于模型的输入和输出来推断出敏感数据。攻击者可能通过向模型提供恶意数据来观察模型行为,或者通过查询模型输出来推断出输入数据的特性。
- 模型倾斜:联邦学习中的数据分布可能不均衡,有些设备可能只有少量的数据样本,而其他设备可能有大量的数据样本。这可能导致在模型聚合过程中,对于拥有更多数据的设备的贡献权重过高,使得其他设备的数据被较少考虑。
- 恶意参与者:联邦学习中的每个设备都可以参与模型训练和更新,但其中可能存在恶意参与者,他们可能故意篡改或损害模型的性能。这些恶意参与者可能试图提供错误的更新,传播恶意代码,或者泄漏数据。
- 为了应对这些威胁,可以采取以下防护措施:
-
隐私保护技术:采用差分隐私、加密技术等方法来保护数据隐私,例如在模型训练中添加噪声,或者使用安全多方计算来保护数据的敏感信息。
-
安全通信和模型聚合:使用安全的通信协议来保护模型参数、梯度和更新的传输,以防止中间攻击者获取敏感信息。同时,在模型聚合过程中使用权重分配策略,以平衡各个设备的数据贡献。
-
模型鲁棒性与防御方法:设计鲁棒的深度学习模型,可以抵抗对抗性样本和恶意攻击。使用模型压缩、聚合学习和模型修复技术,以提高模型的强健性和鲁棒性。
-
参与者验证和信任建立:在联邦学习中,对参与者进行身份验证和信任建立是关键的,在参与者选择和评估过程中要充分考虑参与者的信誉和可靠性。
-
-
涉及研究方向
-
安全计算
- 可信执行环境
- 安全多方计算
- 安全聚合、安全shuffle等
- 安全shuffle是一种密码学概念,用于在计算机安全领域中实现数据的随机化和保护。它主要用来加密敏感数据,确保数据在传输过程中不容易被破解和分析。安全shuffle的基本原理是通过对数据进行混淆和重新排列来隐藏数据的原始顺序。通常使用密码学中的随机数生成算法来生成随机化的数据顺序,从而实现对数据的保护。安全shuffle可以应用在多个领域,如加密通信、数据库安全和隐私保护等。通过安全shuffle,可以增加数据的难以猜测性,降低敏感信息泄露和数据被攻击者窃取的风险。它在保护数据隐私和确保数据传输安全方面发挥着重要的作用。
-
隐私保护
- 本地差分隐私
- 分布式差分隐私
- 通过安全聚合实现分布式差分隐私
- 通过安全shuffling实现分布式差分隐私
-
混合差分隐私
- 通过允许多种模型共存,与纯本地DP或纯中央DP机制相比,混合模型机制可以在给定用户群中实现更高的实用性
-
可验证性
- 零知识证明(ZKPs)
- 零知识证明(Zero-Knowledge Proof)是一种密码学协议,用于验证某个陈述的真实性,而不需要向验证方透露除必要信息之外的任何额外知识。在零知识证明中,证明者能够向验证者证明某个陈述为真,但无需向验证者透露关于该陈述如何成立的任何具体信息。零知识证明的目标是确保证明的有效性,同时最大限度地保护证明所涉及的隐私和机密信息。它通过利用一系列巧妙的互动过程,在不透露实际的解决方案或答案的情况下,向验证者证明陈述的正确性。零知识证明的基本思想是,证明者可以通过进行一系列互动来向验证者证明某个陈述的真实性。这些互动通常会涉及一些具有特定性质的数学计算,使得验证者能够在互动的过程中逐步确信陈述的真实性,而无需获得陈述的具体解决方案。使用零知识证明可以实现一系列应用,如身份验证、密码学协议、匿名交易等。其中的关键点是确保在证明过程中保护个人隐私和敏感信息,同时能够有效证明某个陈述的真实性。总之,零知识证明是一种在证明某个陈述的真实性时最大限度保护隐私和机密信息的密码学协议。通过巧妙的互动过程,证明者能够让验证者相信陈述的真实性,而无需透露陈述的解决方案或答案。
- 可信执行环境中的远程证明
- 主要作用:
- 证明服务器已经进行了聚合,shuffle或者添加差分隐私的操作。
- 证明client输入的数据符合某项规范
- 主要作用:
- 零知识证明(ZKPs)
-
针对客户端恶意操作的保护
-
量化联邦学习模型对特定攻击的效果
- 最常用的量化方法是使用特定数据集模拟对模型的攻击,然后评估模型的效果(该数据集与实际中预期的数据集类似)。如果代理数据集确实与最终用户数据相似,那么这就可以量化模型的攻击敏感性。通过这种方法可以确定数据集对模型的影响效果。
-
中心式差分隐私
- 中心式差分隐私(Centralized Differential Privacy)是一种隐私保护技术,主要应用于中心化的数据收集和分析场景中。它的目标是在保护用户隐私的前提下,对数据进行统计分析。中心式差分隐私通过在数据发布之前对原始数据进行噪声添加,以保护个体的隐私信息。具体来说,中心式差分隐私会对数据添加一定的噪声,使得在数据集中的个体的隐私信息不易被恢复或追溯。同时,通过在多次查询中添加不同的噪声,可以进一步加强隐私保护。在中心式差分隐私中,数据的收集和分析是由数据中心或第三方服务提供商进行的。这些服务提供商负责对用户数据进行汇总和分析,并确保隐私数据的安全性和保密性。中心式差分隐私技术可以应用于各种场景,如健康数据分析、社交网络分析、市场调查等。通过采用中心式差分隐私技术,可以在保护用户隐私的同时,为数据分析提供可信的统计结果。
- 非均匀抽样对隐私保护的影响
- 客户端随机数的来源安全
- 如何评估差分隐私的实现效果
-
模型迭代过程中的安全问题
- 模型迭代(即每轮训练后模型的更新版本)被假定为对系统中的多个参与者可见,包括选择参与该轮的服务器和客户端。为了向客户端隐藏迭代,每个客户端都可以在提供保密特性的TEE中运行其联邦学习的本地部分,服务器将验证预期的联邦学习代码是否在TEE中运行(依赖于TEE的认证和完整性功能),然后将加密的模型迭代结果传输到设备,以便它只能在TEE中解密。最后,模型更新将在返回到服务器之前在TEE内部加密,使用仅在安全环境内部和服务器上已知的密钥。
- 使用TEE来进行训练/发布(发布是指服务器的操作也在TEE环境中运行),不过目前终端算力较弱,TEE成本过高。
- 使用MPC技术,密钥由分析师和客户端持有,或者可信第三方,采用同态加密加密模型,但是MPC需要较高的硬件条件。
-
动态数据库或时间序列数据的差分隐私
- 随时间变化的收集到的一系列数据也存在隐私泄露的风险。
-
防止模型被滥用
-
在联邦学习中,防止模型被滥用是一个重要的问题。由于联邦学习涉及多个参与方共同训练模型,担心有恶意参与者滥用模型或操纵结果是合理的。以下是几种防止模型被滥用的方法:
- 访问控制和身份验证:在联邦学习中,采取适当的访问控制措施,确保只有被授权的参与者才能访问模型和数据。通过使用身份验证和授权机制,只有合法的参与者才有权参与模型的训练和评估过程。
- 安全聚合和加密计算:采用安全聚合机制,确保在模型训练过程中,每个参与者的贡献被正确聚合,而不暴露个体数据。使用加密计算技术,可以在不泄露原始数据的情况下进行模型训练和推断,从而保护数据隐私。
- 模型审核和监控:对参与者提交的模型进行审核和监控,以确保模型没有被篡改或植入恶意代码。监控模型在运行时的行为和输出,及时发现异常或不当使用的情况。
- 对抗性训练和鲁棒性检测:为了防止模型被针对性的攻击和滥用,可以采用对抗性训练方法,使模型对抗各种攻击。同时,进行鲁棒性检测,以确保模型在面对攻击时仍能保持良好的性能。
- 泛化能力和差分隐私:设计具有良好泛化能力的模型,能够在未知数据上具有较好的表现,而不是过度拟合个体数据。另外,采用差分隐私技术,向模型训练中引入随机噪声,以保护个体数据的隐私。
- 法律和合规性考虑:应当遵守相关法律法规和隐私政策,将合规性作为设计和实施联邦学习系统的基本原则,并确保数据使用符合法律和道德要求。
-
-
针对服务器恶意操作的保护
-
对于联邦学习中的服务器,保护免受恶意操作的影响也是非常重要的。以下是一些针对服务器恶意操作的保护措施,特别适用于联邦学习环境:
- 安全联盟选择:在建立联邦学习联盟时,选择可信赖和安全的参与方。验证参与方的身份和可信度,并确保其具备适当的安全措施和良好的安全记录。
- 安全通信:采用加密通信协议来保护联邦学习系统中的数据传输。例如,使用安全套接层(SSL)协议或传输层安全(TLS)协议来加密数据传输,并防止数据在传输过程中被拦截或篡改。
- 隐私保护:在联邦学习中,参与方通常只分享模型的更新参数而不是原始数据。确保在共享参数时对其进行适当的匿名化和去标识化处理,以保护用户的隐私。
- 安全聚合:在联邦学习中,参与方将在服务器上进行模型参数的聚合。确保在聚合期间对数据进行安全存储和处理,以防止未经授权的访问或篡改。
- 安全审计和监控:建立服务器日志记录和监控机制,以跟踪和检测恶意操作。定期审查服务器活动日志,并设置警报系统来及时发现可疑活动。
- 异常检测和入侵防御:使用入侵检测系统(IDS)和入侵防御系统(IPS)等工具,监测和识别潜在的恶意操作,并采取适当的措施,如阻止或隔离恶意行为。
- 安全更新和漏洞管理:定期更新和修补服务器上的软件、应用程序和操作系统,以防止已知漏洞被利用。执行漏洞管理流程,及时处理新发现的漏洞。
- 应急响应计划:建立用于应对可能的安全事件和恶意操作的应急响应计划。准备好应急响应团队,定义响应流程,并进行演练和测试。
-
目前方案的缺点
- 1.本地差分隐私(LDP)如果要实现与传统的中心式差分隐私效果相同的话(即由中央服务器进行加密或者可信第三方加密操作),就需要相对较大的用户群或较大的保密参数选择(意思为隐私级别较低)
- 2.混合差分隐私(HDP)
目前的研究都是基于独立同分布的。 - 3.shuffle模型
shuffle模型需要中介或可信第三方来执行shuffle操作。 - 4.安全聚合模型
该协议比较适合FL,是为FL量身定制的,但是也存在一些局限性。- 它假设服务器并不完全是恶意的
- 允许服务器查看聚合后的结果
- 聚合效率不高
- 无法检测客户端输入格式是否正确
-
-
分布式差分隐私
- 可以使用本节刚开始介绍的分布式差分隐私来保证FL的安全性,在安全聚合协议、差分隐私的实现方法、用户掉线等问题还存在诸多研究的空间。
-
保证用户在训练子模型时的选择隐私性
- 客户将在参与时下载完整模型,使用与他们相关的子模型,然后提交涵盖整个模型参数的集合的模型更新(即,除了与相关子模型相对应的条目中,其余所有地方都为零)。这样我们需要,在保持客户的子模型选择私密性的同时,实现沟通效率高的子模型联合学习,即,不能让服务器观察到客户端选择了哪个子模型。
用户体验
-
用户隐私需求
-
行为研究
- 用户偏好
- 用户行为
-
鲁棒性
-
·对模型的攻击
-
模型更新中毒
-
拜占庭攻击
拜占庭用户可以给服务器发送任意值,而非发送本地更新后的模型。这会导致全局模型在局部最优处收敛,甚至会导致模型发散。可以采用基于中值的,或者其他的等更加健壮的聚合方法来减弱这类攻击。另一种模型更新中毒防御机制使用冗余和洗牌数据来减轻拜占庭式攻击。
-
针对性模型更新攻击
攻击者控制一小部分客户端,比如10%,通过将毒药数据发送给服务器从而给模型留下后门。中毒模型更新的外观和行为(在很大程度上)类似于没有受到目标攻击的模型,这使得单单是检测后门的存在就十分困难。此外,由于对手的目标是只影响少量数据点的分类结果,同时保持全局学习模型的整体准确性,因此针对非目标攻击的防御通常无法解决目标攻击。现有的针对后门攻击的防御要么需要仔细检查训练数据、访问一组类似分布式数据的保留集,要么需要完全控制服务器上的训练过程,而在联邦学习设置中这些都不可能实现。未来工作可以尝试的一个有趣途径是探索使用零知识证明来确保用户提交的更新属性是预先确定的属性。基于硬件认证的解决方案也可以考虑。例如,用户的手机可能有能力证明共享的模型更新是使用手机摄像头生成的图像正确计算的。
-
-
数据中毒
数据中毒是一种比模型更新中毒更具潜在限制性的攻击类型。在这种模式下,对手不能直接损坏到发送到中心节点的信息。相反,对手只能通过替换数据的标签或特定特征来操作客户端数据。与模型更新中毒一样,数据中毒可以分为针对攻击和非针对攻击。数据中毒会导致模型更新中毒,在联邦学习中,即便只是检测有毒数据的存在(不要求对其纠正或用有毒数据标识被入侵的客户端)也是一项挑战。当该数据中毒攻击企图安装后门时,该困难还将进一步增大,因为就算是全局训练精度或单用户训练精度这些性能指标也不足以探测出后门的存在。相比模型更新中毒,数据中毒可能实现起来非常简单,可以执行数据中毒攻击的客户端的最大数量可能比能执行模型更新中毒攻击的数量高得多。
-
推理阶段的攻击
攻击者可以通过观察模型(黑盒模型)或者直接获取模型参数(白盒模型)来定制化数据,使得模型输出错误的结果,对抗性训练(adversarial training)被证明应对这种攻击是有效的。但是,将对抗性学习方法引入到联邦学习环境中的需求引发了许多新的问题。例如,对抗训练在获得显著的稳健性之前可能需要许多时间。然而,在联邦式学习,尤其是跨设备的联邦式学习中,每一种训练样本的学习次数是有限的。一般来说,对抗性训练主要是针对IID数据开发的,尚不清楚它在非IID环境下的表现。其次生成对抗性样本相对昂贵。虽然一些对抗性训练框架试图通过重用对抗性样本来最小化这一成本,但这些方法仍然需要大量客户端计算资源。这在算力较弱的客户端中可能存在问题,在这种情况下,对抗性样本生成可能会加剧内存或电量的使用。目前想要同时解决推理阶段的攻击和训练阶段的攻击,更复杂的解决方案可能是将训练时间防御(如健壮聚合或差异隐私)与对抗训练结合起来
-
-
非恶意的意外错误
-
客户端的不稳定性
客户端在训练过程中出现故障,目前看来,使用安全聚合的方式实现FL时,当大量设备掉线时可能存在影响隐私风险。这其中降低故障的方法就是提高安全聚合的效率,这样可以降低时间窗口。另一种方法是开发一种异步的安全聚合方法,还有一种想法是每次采用多轮训练的参数,这样掉队的客户端可能会在后续聚合中。
-
数据管道故障
数据管道存在于客户端,主要用于将原始数据处理为适应FL训练的训练数据,此管道中的错误或意外操作可能会极大地改变联邦学习过程。
-
保护隐私和鲁棒性之间存在矛盾关系
-
模型参数带噪(失真,由于网络不稳定或其他原因)
即使不存在攻击者,发送到服务器的模型更新也可能由于网络和体系结构因素而失真。这在跨客户端设置中尤其可能,在这些设置中,单独的实体控制服务器、客户端和网络。由于客户端数据可能会发生类似的失真。即使客户端上的数据不是故意恶意的,它也可能具有噪声特征。无论是由于网络因素还是噪声数据,上述的污染都可能损害联邦学习过程的收敛性。一种缓解策略将是使用防御措施来对抗模型更新和数据中毒攻击。鉴于目前在联邦环境下缺乏明显的健壮训练方法,这可能不是一个实际的选择。即使存在这样的技术,它们对于许多联邦学习应用来说可能过于计算密集。这里的开放性工作涉及开发对小到中等水平的噪声具有鲁棒性的训练方法。例如,标准联邦训练方法,如联邦平均法对少量噪声具有内在的鲁棒性。
-
-
公平性
机器学习模型通常会表现出令人惊讶和意想不到的行为。 当此类行为导致对用户产生不良影响的模式时,我们可能会根据一些标准将模型归类为“不公平”。
-
训练数据存在偏差
- 机器学习模型中不公平的一个驱动因素是训练数据中的偏差,包括认知,抽样,报告和确认偏差。一种常见的场景是训练数据中少数民族或边缘化社会群体的代表不足,因此学习者在训练期间对这些群体的加权较小[222],导致对这些群体成员的预测质量较差,这可能会引发一些种族歧视或者其他的问题。由于联邦学习中的数据是非独立同分布的,那么这种类型的偏差存在十分普遍。对于联邦学习研究和机器学习研究而言,调查可识别或减轻数据生成过程中偏差的程度是一个关键问题。同样,尽管有限的先前研究已经证明了在联邦环境中识别和纠正已经收集的数据中的偏差的方法,但仍需要在这一领域进行进一步的研究。
-
确保模型部署的公平性
- 明确地使用属性无关的方法来确保公平的模型性能对于未来的联邦学习研究是一个开放的机会,尤其重要的是,随着联邦学习达到成熟,当看到更多的采用真实的用户群进行部署,过程中不需要了解用户的敏感身份。
-
其他
- 利用联邦学习来提高模型多样性。
- 联邦学习为公平研究者提供了独特的机会和挑战。
总结
- 联邦学习使分布式客户端设备可以协作学习共享的预测模型,同时将所有训练数据保留在设备上,去除了进行机器学习的能力与数据需要存储在云中的条件。
- 近年来,无论是在工业界还是在学术界,该主题的兴趣都呈爆炸性增长。大型技术公司已经在生产中部署了联邦学习,并且成立了许多初创公司,目的是使用联邦学习来解决各个行业中的隐私和数据收集挑战。此外,在这项工作中调查的论文的广泛性表明,联邦学习正在广泛的跨学科领域中获得关注:从机器学习到优化到信息理论和统计再到密码学,公平性和隐私性。
相关文章:
联邦学习综述
《Advances and Open Problems in Federated Learning》 选题:Published 10 December 2019-Computer Science-Found. Trends Mach. Learn. 联邦学习定义 联邦学习是一种机器学习设置,其中多个客户端在中央服务器或服务提供商的协调下协作解决机器学习…...

几行cmd命令,轻松将java文件打包成jar文件
1. 在任意目录下建立一个.java文件 2. 在当前目录下使用cmd命令: javac filename编译 如果报错则使用此命令javac -encoding UTF-8 filename 3.此时已成功生成.class文件 4. 可以手动添加MANIFEST.MF文件 Manifest-Version: 1.0 Main-Class: fileName 5.直接一…...

BuyVM 卢森堡 VPS 测评
description: 发布于 2023-07-05 BuyVM 卢森堡 VPS 测评 产品链接:https://my.frantech.ca/cart.php?gid39 1G口不限流量,续约3个月后升级为10G口突发。抗DMCA版权投诉。抗一般投诉。 大陆连通性还可以,延迟略高,不绕美。 CP…...
JavaScript 编写一个 数值转换函数 万以后简化 例如1000000 展示为 100万 万以下原来数值返回
很多时候 我们看一些系统 能够比较只能的展示过大的数值 例如 到万了 他就能展示出 多少 多少万 看着很奇妙 但实现确实非常的基础 我们只需要一个这样的函数 //数值转换函数 convertNumberToString(num) {//如果传入的数值 不是数字 且也无法转为数字 直接扔0回去if (!parse…...
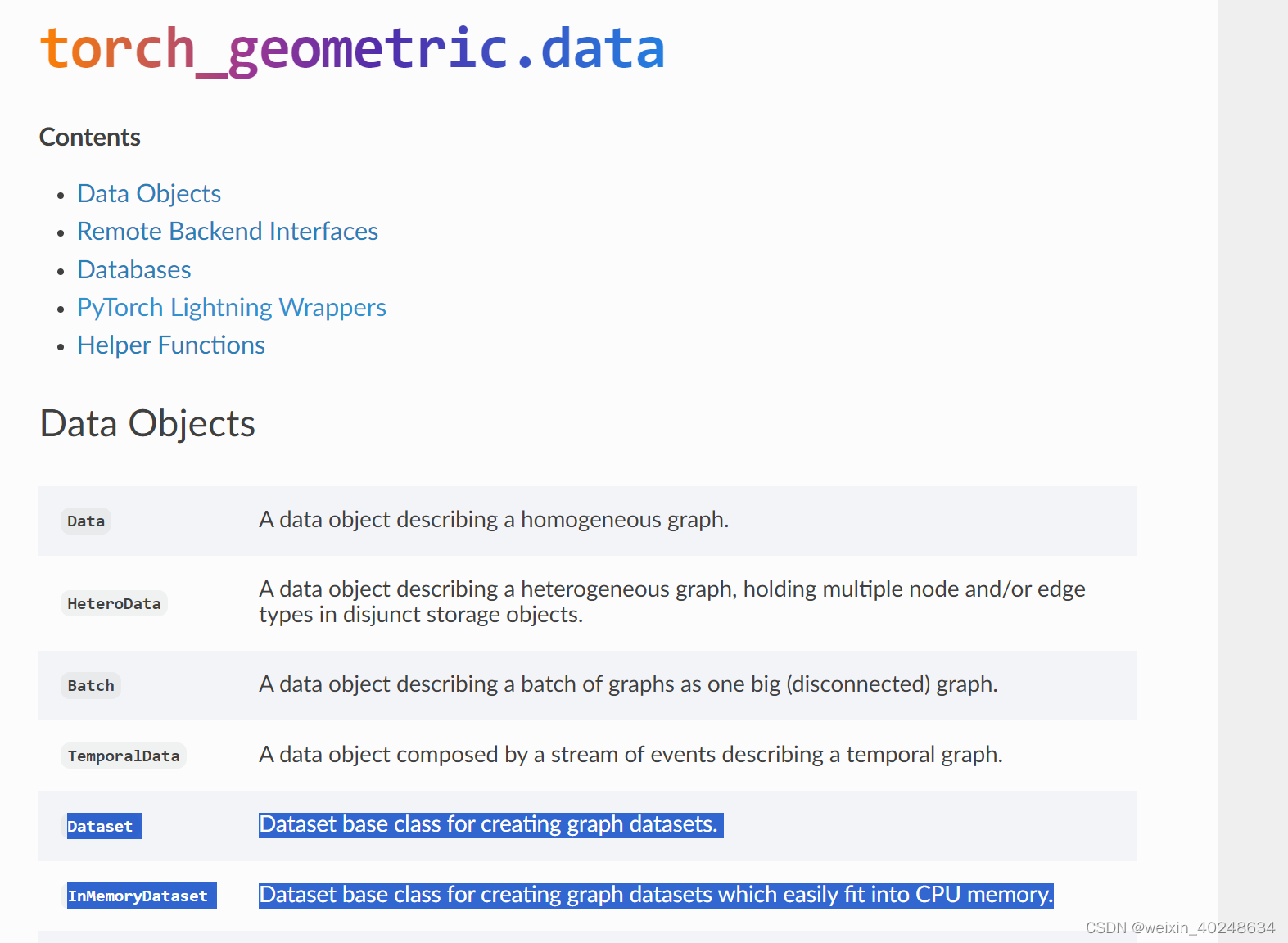
PyG两个data Datsaset v.s. InMemoryDataset
可以看到InMemoryDataset 对CPU更加友好 https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#pytorch-lightning-wrappers...

ArcGIS Engine:视图菜单的创建和鹰眼图的实现
目录 01 创建项目 1.1 通过ArcGIS-ExtendingArcObjects创建窗体应用 1.2 通过C#-Windows窗体应用创建窗体应用 1.2.1 创建基础项目 1.2.2 搭建界面 02 创建视图菜单 03 鹰眼图的实现 3.1 OnMapReplaced事件的触发 3.2 OnExtentUpdated事件的触发 04 稍作演示 01 创建项目…...
POI 和 EasyExcel 操作 Excel
一、概述 目前操作 Excel 比较流行的就是 Apache POI 和阿里巴巴的 easyExcel。 1.1 POI 简介 Apache POI 是用 Java 编写的免费开源的跨平台的 Java API,Apache POI 提供 API 给 Java 程序对 Microsoft Office 格式文档读和写的常用功能。POI 为 “Poor Obfuscati…...

pytorch算力与有效性分析
pytorch Windows中安装深度学习环境参考文档机器环境说明3080机器 Windows11qt_env 满足遥感CS软件分割、目标检测、变化检测的需要gtrs 主要是为了满足遥感监测管理平台(BS)系统使用的,无深度学习环境内容swin_env 与 qt_env 基本一致od 用于…...

Sublime text启用vim模式
官方教程:https://www.sublimetext.com/docs/vintage.html vintage的github:https://github.com/sublimehq/Vintage...
)
爬虫进阶-反爬破解6(Nodejs+Puppeteer实现登陆官网+实现滑动验证码全自动识别)
一、NodejsPuppeteer实现登陆官网 1.环境说明 Nodejs——直接从官网下载最新版本,并安装 使用npm安装puppeteer:npm install puppeteer npm install xxx -registry https://registry.npm.taobao.org Chromium会自动下载,前提是网络通畅 2.实践操作…...
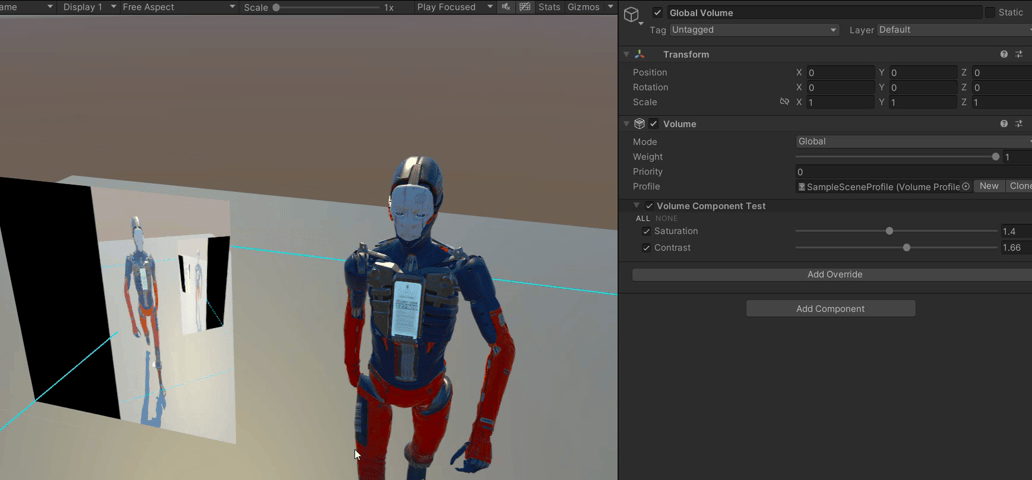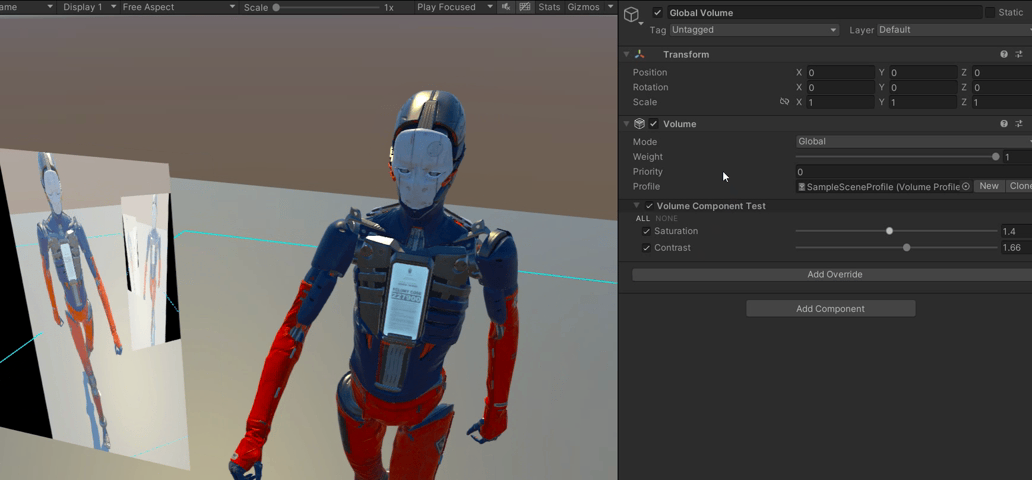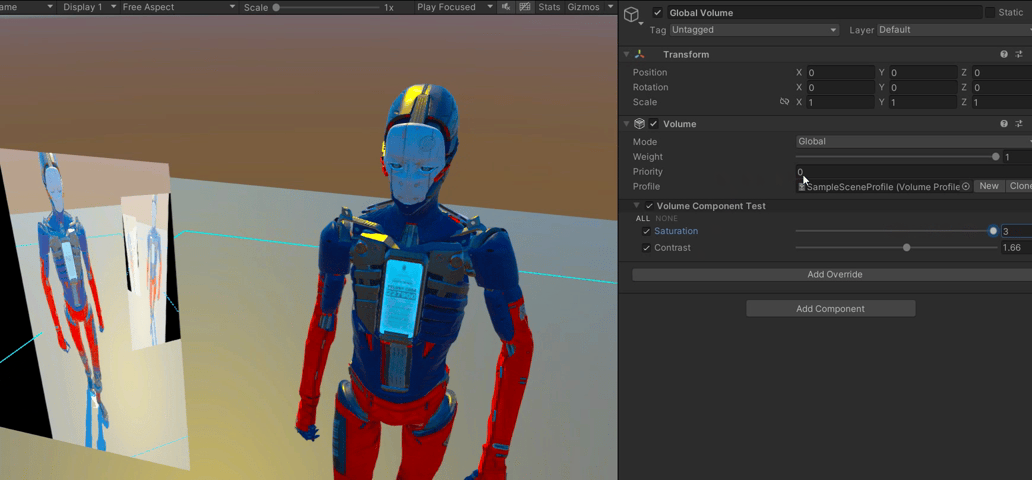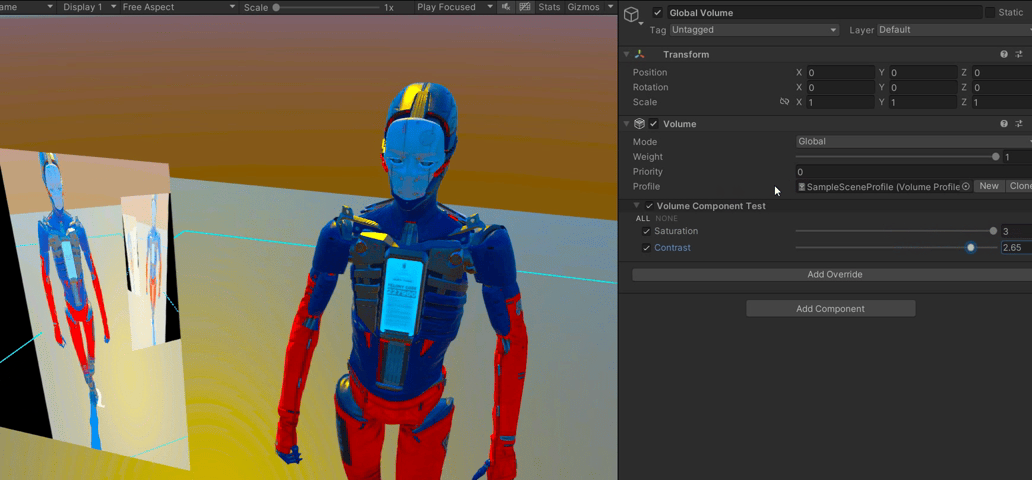
【Unity】RenderFeature笔记
【Unity】RenderFeature笔记 RenderFeature是在urp中添加的额外渲染pass,并可以将这个pass插入到渲染列队中的任意位置。内置渲染管线中Graphics 的功能需要在RenderFeature里实现,常见的如DrawMesh和Blit 可以实现的效果包括但不限于 后处理,可以编写…...
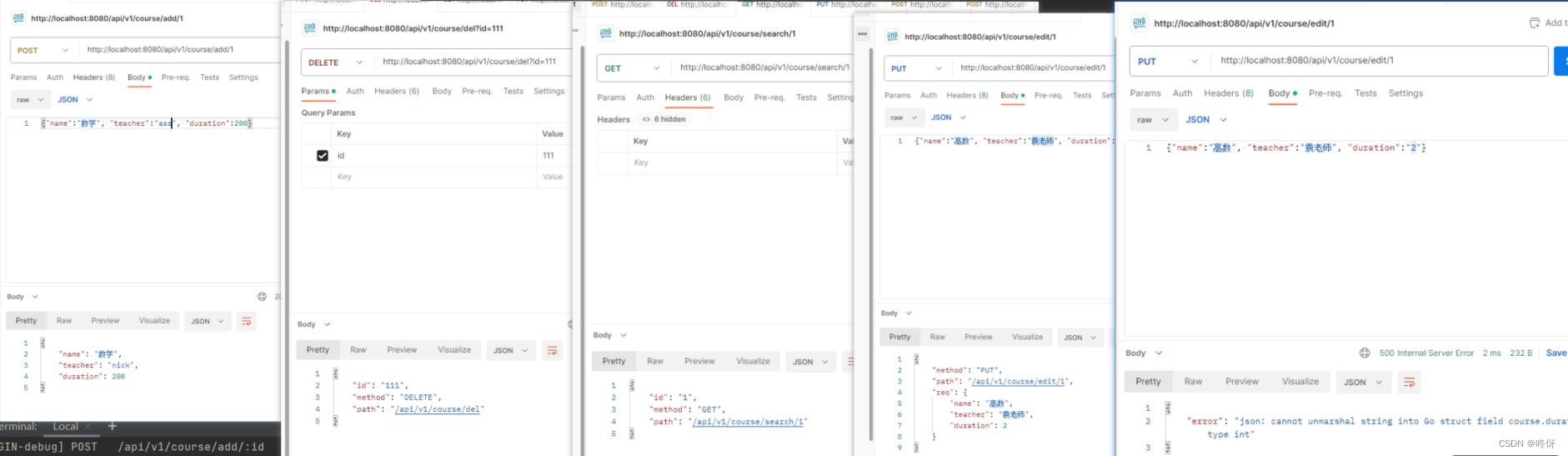
golang gin——controller 模型绑定与参数校验
controller 模型绑定与参数校验 gin框架提供了多种方法可以将请求体的内容绑定到对应struct上,并且提供了一些预置的参数校验 绑定方法 根据数据源和类型的不同,gin提供了不同的绑定方法 Bind, shouldBind: 从form表单中去绑定对象BindJSON, shouldB…...

办公技巧:Excel日常高频使用技巧
目录 1. 快速求和?用 “Alt ” 2. 快速选定不连续的单元格 3. 改变数字格式 4. 一键展现所有公式 “CTRL ” 5. 双击实现快速应用函数 6. 快速增加或删除一列 7. 快速调整列宽 8. 双击格式刷 9. 在不同的工作表之间快速切换 10. 用F4锁定单元格 1. 快速求…...
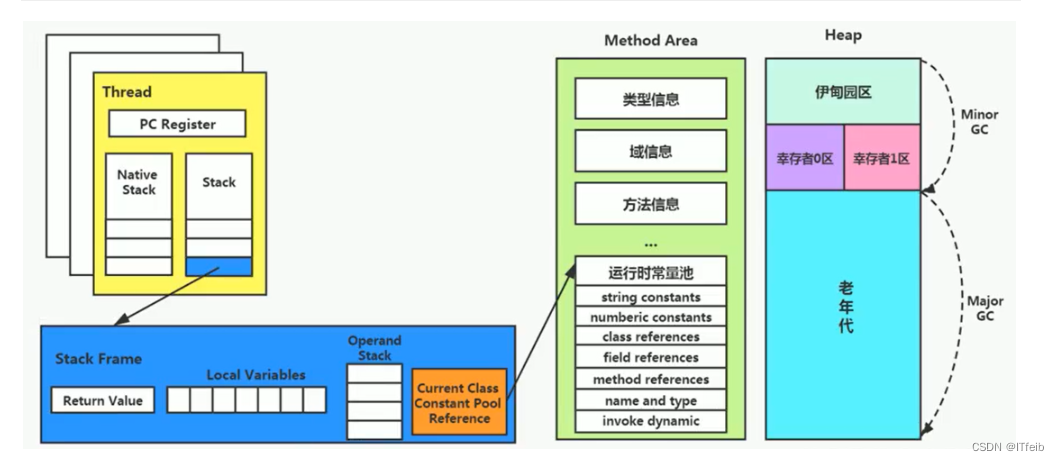
【jvm--方法区】
文章目录 1. 栈、堆、方法区的交互关系2. 方法区的内部结构3. 运行时常量池4. 方法区的演进细节5. 方法区的垃圾回收 1. 栈、堆、方法区的交互关系 方法区的基本理解: 方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区…...

智慧楼宇3D数据可视化大屏交互展示实现了楼宇能源的高效、智能、精细化管控
智慧园区是指将物联网、大数据、人工智能等技术应用于传统建筑和基础设施,以实现对园区的全面监控、管理和服务的一种建筑形态。通过将园区内设备、设施和系统联网,实现数据的传输、共享和响应,提高园区的管理效率和运营效益,为居…...
算法题:摆动序列(贪心算法解决序列问题)
这道题是一道贪心算法题,如果前两个数是递增,则后面要递减,如果不符合则往后遍历,直到找到符合的。(完整题目附在了最后) 代码如下: class Solution(object):def wiggleMaxLength(self, nums):…...

接口自动化测试yaml+requests+allure技术,你学会了吗?
前言 接口自动化测试是在软件开发过程中常用的一种测试方式,通过对接口进行自动化测试,可以提高测试效率、降低测试成本。在接口自动化测试中,yaml、requests和allure三种技术经常被使用。 一、什么是接口自动化测试 接口自动化测试是指通…...

android 获取局域网其他设备ip
Android 通过读取本地Arp表获取当前局域网内其他设备信息_手机查看arp-CSDN博客...

angular中使用 ngModel 自定义组件
要创建一个自定义的 Angular 组件,并使用 ngModel 进行双向数据绑定,您可以按照以下步骤操作: 创建自定义组件:首先,使用 Angular CLI 或手动创建一个新的组件。在组件的模板中,添加一个输入元素或其他适合…...

kubernetes pod日志查看用户创建
目录 1.创建用户 1.1证书创建 1.2创建用户 1.3允许用户登陆 1.4切换用户 1.5删除用户 2.RBAC 1.创建用户 1.1证书创建 进入证书目录 # cd /etc/kubernetes/pki创建key # openssl genrsa -out user1.key 2048 Generating RSA private key, 2048 bit long modulus .....…...

BepInEx启动失败完整指南:从IL2CPP兼容性到游戏正常运行
BepInEx启动失败完整指南:从IL2CPP兼容性到游戏正常运行 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏插件框架,在IL2CPP编译模式下…...

3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案
3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中寻找文件而烦恼吗ÿ…...

如何5分钟完成专业电路图:Draw.io ECE插件完全指南
如何5分钟完成专业电路图:Draw.io ECE插件完全指南 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/d…...

FinalBurn Neo终极指南:如何轻松搭建经典街机游戏模拟器
FinalBurn Neo终极指南:如何轻松搭建经典街机游戏模拟器 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo FinalBurn Neo(简称FBNeo)是一款开源街机游戏模拟器…...

G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制
G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

从公式到代码:傅里叶级数系数的完整推导与实现
1. 从三角函数到傅里叶级数:数学基础回顾 第一次接触傅里叶级数时,我被那一堆积分符号和三角函数搞得头晕眼花。后来才发现,理解它的关键其实藏在高中数学课本里——那些看似简单的三角函数公式,正是打开傅里叶变换大门的钥匙。 让…...

开发者必备:从聊天记录到结构化知识库的自动化工具实践
1. 项目概述:一个面向开发者的轻量级对话记录工具最近在整理几个开源项目的技术讨论记录时,我又一次陷入了混乱。Slack、Discord、Telegram、微信……不同平台的聊天记录散落各处,格式五花八门,想回溯一个关键的技术决策或一个报错…...

开源工作流引擎ByteChef:从组件化架构到自动化编排实战
1. 项目概述:一个面向开发者的自动化工作流引擎如果你是一名开发者,或者经常需要处理跨系统、跨应用的数据同步、定时任务、API调用编排,那么你大概率对“自动化”有着强烈的需求。我们可能都经历过这样的场景:每天手动从A系统导出…...

港大开源 【OpenHarness】 深度剖析:1.1 万行代码解构 Agent 架构,把黑盒变白盒
港大开源 【OpenHarness】 深度剖析:1.1 万行代码解构 Agent 架构,把黑盒变白盒 写在前面:香港大学数据科学研究所(HKUDS)开源的 OpenHarness 项目,上线两天斩获 1.9K Star,10 天突破 9.5K Star…...

在ARM架构Windows上,用Hyper-V快速部署Ubuntu Server 22.04 LTS
1. 为什么选择ARM架构WindowsHyper-V跑Ubuntu? 最近两年ARM架构的Windows设备越来越多了,像Surface Pro X这样的设备用起来确实轻便省电。但很多开发者发现,想在ARM电脑上跑个Linux环境测试代码,总会遇到各种兼容性问题。我自己用…...