Hadoop作业篇(一)
一、选择题
1. 以下哪一项不属于Hadoop可以运行的模式__C____。
A. 单机(本地)模式
B. 伪分布式模式
C. 互联模式
D. 分布式模式
C. 互联模式 不属于Hadoop可以运行的模式。
Hadoop主要有四种运行模式:
A. 单机(本地)模式:在单个计算机上运行,适用于开发和测试。
B. 伪分布式模式:模拟真实分布式环境,但实际上所有组件都在单个计算机上运行。
C. 互联模式:不是Hadoop支持的一种运行模式,因此不属于Hadoop可以运行的模式。
D. 分布式模式:真正的分布式环境,将Hadoop组件分布在多台计算机上,可以处理大规模数据。
2. Hadoop的作者是下面哪一位___B___。
A. Martin Fowler
B. Doug cutting
C. Kent Beck
D. Grace Hopper
3. 下列哪个程序通常与 NameNode 在同一个节点启动___D__。
A. TaskTracker
B. DataNode
C. SecondaryNameNode
D. Jobtracker
- A. TaskTracker:TaskTracker是在工作节点上运行的组件,负责执行由JobTracker分配的任务。它不需要与NameNode在同一个节点上启动。
- B. DataNode:DataNode是负责存储实际数据块的组件,它不需要与NameNode在同一个节点上启动。
- C. SecondaryNameNode:SecondaryNameNode负责辅助NameNode,它通常不在同一节点上启动,而是在单独的节点上运行以提供备份和辅助功能。
- D. JobTracker:JobTracker是Hadoop中的一个主要组件,负责接收作业的提交,将作业拆分成任务,并将任务分配给TaskTracker执行。通常,JobTracker与NameNode运行在同一节点上,以便更有效地管理作业的执行。
4. HDFS 默认 Block Size的大小是___B___。
A.32MB
B.64MB
C.128MB
D.256M
HDFS将大文件分割成多个固定大小的数据块存储,这个固定大小就是Block Size。在HDFS中,默认的Block Size是64MB(或者在较新的版本中也可以是128MB)。
5. 下列哪项通常是集群的最主要瓶颈__C____。
A. CPU
B. 网络
C. 磁盘IO
D. 内存
在大数据集群中,磁盘IO往往是性能瓶颈之一。由于大量的数据存储和读写操作,磁盘IO速度的限制可能导致整个集群的性能下降。
6. 下列关于MapReduce说法不正确的是____C__。
A. MapReduce是一种计算框架
B. MapReduce来源于google的学术论文
C. MapReduce程序只能用java语言编写
D. MapReduce隐藏了并行计算的细节,方便使用
C. MapReduce程序只能用java语言编写
- 这个说法不正确。MapReduce程序可以使用多种编程语言编写,不仅限于Java。Hadoop支持多种语言的API,如Streaming API可以支持Python,Ruby等编程语言。
7. HDFS是基于流数据模式访问和处理超大文件的需求而开发的,具有高容错、高可靠性、高可扩展性、高吞吐率等特征,适合的读写任务是 __D____。
A.一次写入,少次读
B.多次写入,少次读
C.多次写入,多次读
D.一次写入,多次读
HDFS是基于流数据模式访问和处理超大文件的需求而开发的,适合的读写任务是:D. 一次写入,多次读
- HDFS适合一次写入多次读取的场景。数据一次写入HDFS后,可以多次读取,适合大数据处理和分析的应用场景。
8. HBase依靠__A___存储底层数据。
A. HDFS
B. Hadoop
C. Memory
D. MapReduce
A. HDFS 存储底层数据
- HBase是建立在HDFS上的分布式数据库,它依赖HDFS来存储底层数据。 HBase将数据存储在HDFS上,提供高速随机访问和强大的扩展性。
9. HBase依赖__D___提供强大的计算能力。
A. Zookeeper
B. Chubby
C. RPC
D. MapReduce
- D. MapReduce 提供强大的计算能力
- HBase可以利用MapReduce进行大规模数据分析和计算。MapReduce是一种用于大规模数据集的并行计算框架,能够在Hadoop集群上进行高效的数据处理和计算,为HBase提供了强大的计算能力。
解释其他选项:
A. Zookeeper:
- Zookeeper是一个分布式协调服务,用于管理和协调分布式系统中的节点。HBase通常使用Zookeeper来协调集群中的各个节点,管理集群的状态信息,以确保高可用性和稳定性。
B. Chubby:
- Chubby是Google开发的分布式锁服务,用于实现分布式系统的同步和协调。与Zookeeper类似,Chubby也用于分布式系统的协调和管理。
C. RPC (Remote Procedure Call):
- RPC是一种通信协议,允许程序在网络上请求服务而不必了解底层网络细节。在Hadoop生态系统中,RPC用于通信,包括HDFS、HBase等组件之间的通信
10. HBase依赖___A___提供消息通信机制
A. Zookeeper
B. Chubby
C. RPC
D. Socket
- A. Zookeeper 提供消息通信机制
- Zookeeper是一个分布式协调服务,提供了分布式系统中节点之间的协调和通信机制。HBase可以利用Zookeeper来实现集群中各个节点之间的通信,包括分布式锁、集群状态的监控和管理等。
解释其他选项:
B. Chubby:
- Chubby是Google开发的分布式锁服务,主要用于分布式系统的同步和协调。Chubby不是HBase的直接依赖项,但类似于Zookeeper,它也可以用于实现分布式系统的通信和同步。
C. RPC (Remote Procedure Call):
- RPC是一种通信协议,允许程序在网络上请求服务而不必了解底层网络细节。在Hadoop生态系统中,RPC用于通信,包括HDFS、HBase等组件之间的通信。
D. Socket:
- Socket是用于实现网络通信的编程接口,可以实现不同设备间的通信。虽然Socket可以用于通信,但HBase更多地依赖于更高层次的协调服务(如Zookeeper)来提供稳定和可靠的消息通信机制。
总结:HBase依赖Zookeeper来提供稳定的消息通信机制和集群节点间的协调,Chubby和RPC也可以用于通信,但HBase通常使用Zookeeper作为消息通信机制的依赖。 Socket是通用的网络通信编程接口,可以用于通信,但不是HBase特定的依赖项。
11. 关于 SecondaryNameNode 哪项是正确的?C
A.它是 NameNode 的热备
B.它对内存没有要求
C.它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间
D.SecondaryNameNode 应与 NameNode 部署到一个节点。
A. 它是 NameNode 的热备:
- 这是错误的。SecondaryNameNode不是NameNode的热备。它有不同的功能和角色。
B. 它对内存没有要求:
- 这是相对正确的。SecondaryNameNode不要求很高的内存,但它需要足够的内存来执行其任务,尤其是在合并编辑日志时可能需要较大内存。
C. 它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间:
- 这是相对正确的。SecondaryNameNode的主要目的是帮助NameNode合并编辑日志(也称为fsimage和edits),以减少NameNode启动时间。它定期将这些日志合并,然后将其发送给NameNode,以减少NameNode的启动时间。
D. SecondaryNameNode 应与 NameNode 部署到一个节点:
- 这是错误的。SecondaryNameNode通常不应该与NameNode部署在同一节点上。在现代Hadoop架构中,建议将SecondaryNameNode与NameNode分开部署,以提高系统的容错性和性能。将这两者分开可以确保在一个节点发生故障时不影响另一个节点的正常运行
12. 下面与HDFS类似的框架是___C____?
A. NTFS
B. FAT32
C. GFS
D. EXT3
A. NTFS:
- NTFS(New Technology File System)是Microsoft Windows操作系统中使用的文件系统。它提供了对文件和目录的高级处理,但不是与HDFS类似的分布式文件系统。
B. FAT32:
- FAT32(File Allocation Table 32)也是Windows操作系统使用的一种文件系统。它用于管理文件和存储设备上的数据,但不是分布式文件系统,也不类似于HDFS。
C. GFS:
- GFS(Google File System)是与HDFS类似的分布式文件系统,由Google开发。它是HDFS的前身,用于在大规模集群上存储大量数据。HDFS受到了GFS的启发,因此与HDFS类似。
D. EXT3:
- EXT3(Third Extended File System)是Linux操作系统中常用的文件系统,但它不是分布式文件系统,也不类似于HDFS。
13. 关于 SecondaryNameNode 下面哪项是正确的___C___。
A. 它是 NameNode 的热备
B. 它对内存没有要求
C. 它的目的是帮助 NameNode 合并编辑日志,减少 NameNode 启动时间
D. SecondaryNameNode 应与 NameNode 部署到一个节点
14. 大数据的特点不包括下面哪一项__D____。
A. 巨大的数据量
B. 多结构化数据
C. 增长速度快
D. 价值密度高
A. 巨大的数据量:
- 大数据的特点之一是数据量巨大,传统的数据处理技术难以处理如此大量的数据。
B. 多结构化数据:
- 大数据通常涉及多种数据类型和格式,包括结构化、半结构化和非结构化数据。
C. 增长速度快:
- 大数据的增长速度非常快,数据量在快速积累,这要求新的技术和方法来处理和分析这些数据。
D. 价值密度高:
- 这个说法与大数据的特点不符。通常,大数据的价值密度相对较低,因为大数据集中包含大量的冗余、噪音或非关键信息,需要进行处理和分析以提取有价值的信息
15.Doug Cutting所创立的项目的名称都受到其家人的启发,以下项目不是由他创立的项目是 D
A. Hadoop
B. Nutch
C. Lucene
D. Solr
A. Hadoop:
- Doug Cutting是Hadoop的共同创始人之一。Hadoop最初是以他儿子的玩具大象命名的,取名自他儿子的玩具大象名叫Hadoop。这个名字也反映了Hadoop的分布式、可伸缩性,类似大象一样坚固的特性。
B. Nutch:
- Doug Cutting是Nutch项目的创始人。Nutch是一个开源的网络搜索引擎项目。
C. Lucene:
- Doug Cutting也是Lucene项目的创始人之一。Lucene是一个全文搜索引擎库。
D. Solr:
- Solr是由Yonik Seeley开发的,而不是Doug Cutting创立的。
16.配置Hadoop时,JAVA_HOME包含在哪一个配置文件中 B
A. hadoop-default.xml
B. hadoop-env.sh
C. hadoop-site.xml
D. configuration.xsl
A. hadoop-default.xml:
- 这个文件包含了Hadoop的默认配置参数。它通常用于指定Hadoop的默认设置,但不包括
JAVA_HOME。B. hadoop-env.sh:
- 正确答案。
hadoop-env.sh是Hadoop的环境设置脚本,用于设置Hadoop的环境变量,包括JAVA_HOME。在这里可以配置Java的路径,这样Hadoop就知道在哪里找到Java环境。C. hadoop-site.xml:
- 这个文件用于配置Hadoop的特定参数。通常在这里配置Hadoop集群的特定属性,但不包括
JAVA_HOME。D. configuration.xsl:
- 这个文件不是Hadoop的配置文件,而是可能与XML配置相关的样式表。
17.Hadoop配置文件中,hadoop-site.xml显示覆盖hadoop-default.xml里的内容。在版本0.20中,hadoop-site.xml被分离成三个XML文件,不包括 A
A. conf-site.xml
B. mapred-site.xml
C. core-site.xml
D. hdfs-site.xml
A. conf-site.xml:
- 这不是标准的Hadoop配置文件。通常,Hadoop配置文件命名为
*-site.xml格式,而不是conf-site.xml。B. mapred-site.xml:
- 正确答案。在Hadoop 0.20及以后版本,
mapred-site.xml用于配置MapReduce相关的属性,它是Hadoop配置的一部分。C. core-site.xml:
- 这个文件用于配置Hadoop核心属性。它包括诸如文件系统默认方案、Hadoop运行环境等的设置。
D. hdfs-site.xml:
- 这个文件用于配置HDFS(Hadoop分布式文件系统)的属性,如块大小、复制因子等。
18.HDFS默认的当前工作目录是/user/$USER,fs.default.name的值需要在哪个配置文件内说明 B
A. mapred-site.xml
B. core-site.xml
C. hdfs-site.xml
D. 以上均不是
A. mapred-site.xml:
- 这个配置文件主要用于配置MapReduce的属性,不涉及HDFS的配置。
B. core-site.xml:
- 正确答案。
core-site.xml是Hadoop配置中的一个重要文件,用于配置Hadoop核心属性,包括文件系统默认方案和Hadoop运行环境的参数。C. hdfs-site.xml:
- 这个配置文件用于配置HDFS(Hadoop分布式文件系统)的属性,但不涉及
fs.default.name的设置。D. 以上均不是:
- 错误选项。实际上,HDFS默认工作目录和
fs.default.name的设置在core-site.xml文件中。
19.关于Hadoop单机模式和伪分布式模式的说法,正确的是 D
A. 两者都起守护进程,且守护进程运行在一台机器上
B. 单机模式不使用HDFS,但加载守护进程
C. 两者都不与守护进程交互,避免复杂性
D. 后者比前者增加了HDFS输入输出以及可检查内存使用情况
A. 两者都起守护进程,且守护进程运行在一台机器上:
- 错误。单机模式和伪分布式模式都可以运行守护进程,但伪分布式模式模拟分布式环境,因此守护进程运行在一台机器上是不准确的。
B. 单机模式不使用HDFS,但加载守护进程:
- 部分正确。单机模式不使用真正的HDFS,但是会加载守护进程(如NameNode、DataNode等),但这些进程在单机模式下并不实际工作。
C. 两者都不与守护进程交互,避免复杂性:
- 错误。单机模式和伪分布式模式都涉及守护进程,尽管在单机模式下,它们可能不实际工作,但它们会被加载。
D. 后者比前者增加了HDFS输入输出以及可检查内存使用情况:
- 部分正确。伪分布式模式模拟了一个真实的分布式环境,可以进行HDFS输入输出,并且能够检查内存使用情况。相比之下,单机模式不涉及真实的HDFS输入输出,也不需要检查内存使用情况。
综上所述,正确答案是 D. 后者比前者增加了HDFS输入输出以及可检查内存使用情况。
20.下列关于Hadoop API的说法错误的是 A
A. Hadoop的文件API不是通用的,只用于HDFS文件系统
B. Configuration类的默认实例化方法是以HDFS系统的资源配置为基础的
C. FileStatus对象存储文件和目录的元数据
D. FSDataInputStream是java.io.DataInputStream的子类
A. Hadoop的文件API不是通用的,只用于HDFS文件系统:
- 错误。Hadoop的文件API是通用的,可以用于不仅仅是HDFS,还可以用于其他文件系统,如本地文件系统(file://)等。
B. Configuration类的默认实例化方法是以HDFS系统的资源配置为基础的:
- 部分正确。
Configuration类的默认实例化方法会加载默认配置,这些配置可能包括HDFS系统的配置,也可能包括其他Hadoop组件的配置。但并非仅基于HDFS系统的配置。C. FileStatus对象存储文件和目录的元数据:
- 正确。
FileStatus对象用于存储文件和目录的元数据,包括文件大小、权限、所有者等信息。D. FSDataInputStream是java.io.DataInputStream的子类:
- 正确。
FSDataInputStream是java.io.DataInputStream的子类,用于从Hadoop文件系统中读取数据。综上所述,错误的说法是 A. Hadoop的文件API不是通用的,只用于HDFS文件系统。
21.HDFS的NameNode负责管理文件系统的命名空间,将所有的文件和文件夹的元数据保存在一个文件系统树中,这些信息也会在硬盘上保存成以下文件: C
A.日志
B.命名空间镜像
C.两者都是
A. 日志: HDFS的NameNode会记录一些重要的操作和元数据更改,这些记录保存在日志文件中,以便在发生故障时进行恢复。
B. 命名空间镜像: NameNode会将命名空间的元数据保存为命名空间镜像,该镜像存储了文件系统树的结构以及相关的元数据信息。这个命名空间镜像是在磁盘上持久保存的,用于在NameNode启动时恢复文件系统的状态。
22.HDFS的namenode保存了一个文件包括哪些数据块,分布在哪些数据节点上,这些信息也存储在硬盘上。 B
A.正确
B.错误
23.Secondary namenode就是namenode出现问题时的备用节点 B
A.正确
B.错误
24.出现在datanode的VERSION文件格式中但不出现在namenode的VERSION文件格式中的是B
A. namespaceID
B. storageID
C. storageType
D. layoutVersion
25.Client在HDFS上进行文件写入时,namenode根据文件大小和配置情况,返回部分datanode信息,谁负责将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块 A
A. Client
B. Namenode
C. Datanode
D. Secondary namenode
27.HDFS无法高效存储大量小文件,想让它能处理好小文件,比较可行的改进策略不包括 D
A. 利用SequenceFile、MapFile、Har等方式归档小文件
B. 多Master设计
C. Block大小适当调小
D. 调大namenode内存或将文件系统元数据存到硬盘里
28.关于HDFS的文件写入,正确的是 C
A. 支持多用户对同一文件的写操作
B. 用户可以在文件任意位置进行修改
C. 默认将文件块复制成三份存放
D. 复制的文件块默认都存在同一机架上
29.Hadoop fs中的-get和-put命令操作对象是 C
A. 文件
B. 目录
C. 两者都是
30.Namenode在启动时自动进入安全模式,在安全模式阶段,说法错误的是 D
A. 安全模式目的是在系统启动时检查各个DataNode上数据块的有效性
B. 根据策略对数据块进行必要的复制或删除
C. 当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式
D. 文件系统允许有修改
A. 安全模式目的是在系统启动时检查各个DataNode上数据块的有效性: 这是安全模式的目的之一。在安全模式下,NameNode会检查各个数据块的有效性,确保数据块可以正常访问。
B. 根据策略对数据块进行必要的复制或删除: 在安全模式下,可以根据复制策略对数据块进行复制或删除,以确保数据块的副本数符合预定的要求。
C. 当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式: 这是安全模式自动退出的条件之一。当数据块的最小百分比数满足最小副本数条件时,系统会自动退出安全模式。
D. 文件系统允许有修改: 在安全模式期间,文件系统是只读的,不允许进行修改操作,以确保数据的一致性和安全
31.MapReduce框架提供了一种序列化键/值对的方法,支持这种序列化的类能够在Map和Reduce过程中充当键或值,以下说法错误的是 C
A. 实现Writable接口的类是值
B. 实现WritableComparable<T>接口的类可以是值或键
C. Hadoop的基本类型Text并不实现WritableComparable<T>接口
D. 键和值的数据类型可以超出Hadoop自身支持的基本类型
A. 实现Writable接口的类是值: 正确。实现Writable接口的类可以作为值。
B. 实现WritableComparable<T>接口的类可以是值或键: 正确。实现WritableComparable<T>接口的类可以作为键或值。
C. Hadoop的基本类型Text并不实现WritableComparable<T>接口: 错误。Hadoop的基本类型Text实现了Writable接口和WritableComparable接口。
D. 键和值的数据类型可以超出Hadoop自身支持的基本类型: 正确。键和值的数据类型可以是用户自定义的类型,不限于Hadoop自身支持的基本类型。
32.以下四个Hadoop预定义的Mapper实现类的描述错误的是 B
A. IdentityMapper<K, V>实现Mapper<K, V, K, V>,将输入直接映射到输出
B. InverseMapper<K, V>实现Mapper<K, V, K, V>,反转键/值对
C. RegexMapper<K>实现Mapper<K, Text, Text, LongWritable>,为每个常规表达式的匹配项生成一个(match, 1)对
D. TokenCountMapper<K>实现Mapper<K, Text, Text, LongWritable>,当输入的值为分词时,生成(taken, 1)对
A. IdentityMapper<K, V>实现Mapper<K, V, K, V>,将输入直接映射到输出: 正确。IdentityMapper直接映射输入到输出。
B. InverseMapper<K, V>实现Mapper<K, V, K, V>,反转键/值对: 错误。没有Hadoop预定义的InverseMapper,这个描述不正确。
C. RegexMapper<K>实现Mapper<K, Text, Text, LongWritable>,为每个常规表达式的匹配项生成一个(match, 1)对: 正确。RegexMapper用于生成常规表达式匹配项的键/值对。
D. TokenCountMapper<K>实现Mapper<K, Text, Text, LongWritable>,当输入的值为分词时,生成(token, 1)对: 正确。TokenCountMapper用于生成分词的键/值对。
33.下列关于HDFS为存储MapReduce并行切分和处理的数据做的设计,错误的是 B
A. FSDataInputStream扩展了DataInputStream以支持随机读
B. 为实现细粒度并行,输入分片(Input Split)应该越小越好
C. 一台机器可能被指派从输入文件的任意位置开始处理一个分片
D. 输入分片是一种记录的逻辑划分,而HDFS数据块是对输入数据的物理分割
A. FSDataInputStream扩展了DataInputStream以支持随机读: 正确。FSDataInputStream允许对HDFS文件进行随机读取。
B. 为实现细粒度并行,输入分片(Input Split)应该越小越好: 错误。输入分片应该适中,不宜过小也不宜过大,以充分利用集群资源和避免任务过多或过少。
C. 一台机器可能被指派从输入文件的任意位置开始处理一个分片: 正确。MapReduce任务可以在输入文件的任意位置开始处理一个分片。
D. 输入分片是一种记录的逻辑划分,而HDFS数据块是对输入数据的物理分割: 正确。输入分片是逻辑划分,而HDFS数据块是物理分割。
34.针对每行数据内容为”Timestamp Url”的数据文件,在用JobConf对象conf设置conf.setInputFormat(WhichInputFormat.class)来读取这个文件时,WhichInputFormat应该为以下B
A. TextInputFormat
B. KeyValueTextInputFormat
C. SequenceFileInputFormat
D. NLineInputFormat
A. TextInputFormat: 适用于文本文件,将文件的每一行作为记录。
B. KeyValueTextInputFormat: 适用于键值对形式的文本文件,每行被解析成键和值。
C. SequenceFileInputFormat: 适用于Hadoop的二进制序列文件格式。
D. NLineInputFormat: 适用于按行分割的文本文件,每次读取N行作为一个输入分片。
35.有关MapReduce的输入输出,说法错误的是 B
A. 链接多个MapReduce作业时,序列文件是首选格式
B. FileInputFormat中实现的getSplits()可以把输入数据划分为分片,分片数目和大小任意定义
C. 想完全禁止输出,可以使用NullOutputFormat
D. 每个reduce需将它的输出写入自己的文件中,输出无需分片
B. FileInputFormat中实现的getSplits()可以把输入数据划分为分片,分片数目和大小任意定义。
解释每个选项:
A. 链接多个MapReduce作业时,序列文件是首选格式: 正确。序列文件是一种通用的、可扩展的二进制文件格式,常用于链式MapReduce作业。
B. FileInputFormat中实现的getSplits()可以把输入数据划分为分片,分片数目和大小任意定义: 错误。FileInputFormat的
getSplits()方法用于将输入数据划分为分片,但分片数目和大小受到HDFS块大小等因素的影响。C. 想完全禁止输出,可以使用NullOutputFormat: 正确。NullOutputFormat用于禁止输出。
D. 每个reduce需将它的输出写入自己的文件中,输出无需分片: 正确。Reduce的输出默认写入HDFS的文件中,不需要分片。
选项B中的描述不准确,
getSplits()方法会根据HDFS的块大小等划分输入数据为分片。
36.以下说法不正确的是 D
A. Hadoop Streaming使用Unix中的流与程序交互
B. Hadoop Streaming允许我们使用任何可执行脚本语言处理数据流
C. 采用脚本语言时必须遵从UNIX的标准输入STDIN,并输出到STDOUT
D. Reduce没有设定,上述命令运行会出现问题
A. Hadoop Streaming使用Unix中的流与程序交互: 正确。Hadoop Streaming通过标准输入输出与程序进行交互。
B. Hadoop Streaming允许我们使用任何可执行脚本语言处理数据流: 正确。Hadoop Streaming支持多种脚本语言,可以用于处理数据流。
C. 采用脚本语言时必须遵从UNIX的标准输入STDIN,并输出到STDOUT: 正确。Hadoop Streaming要求遵循UNIX标准输入输出方式。
D. Reduce没有设定,上述命令运行会出现问题: 错误。Hadoop Streaming作业中,Reduce阶段是可选的,可以没有Reduce设定。如果没有Reduce,那么就只有Map阶段,不会出现问题。
37.在高阶数据处理中,往往无法把整个流程写在单个MapReduce作业中,下列关于链接MapReduce作业的说法,不正确的是 D
A.Job和JobControl类可以管理非线性作业之间的依赖
B.ChainMapper和ChainReducer类可以用来简化数据预处理和后处理的构成
C.使用ChainReducer时,每个mapper和reducer对象都有一个本地JobConf对象
D.ChainReducer.addMapper()方法中,一般对键/值对发送设置成值传递,性能好且安全性高
A. Job和JobControl类可以管理非线性作业之间的依赖: 正确。JobControl类可以用于管理作业之间的依赖关系。
B. ChainMapper和ChainReducer类可以用来简化数据预处理和后处理的构成: 正确。ChainMapper和ChainReducer允许将多个Mapper或Reducer连接起来形成一个处理链。
C. 使用ChainReducer时,每个mapper和reducer对象都有一个本地JobConf对象: 正确。每个Mapper和Reducer在ChainReducer中都有一个本地JobConf对象。
D. ChainReducer.addMapper()方法中,一般对键/值对发送设置成值传递,性能好且安全性高: 错误。在Hadoop中,键/值对是以引用传递的方式传递的,而不是通过值传递。这个选项描述是错误的。
38.下面哪个程序负责 HDFS 数据存储。C
a)NameNode
b)Jobtracker
c)Datanode
d)secondaryNameNode
e)tasktracker
a) NameNode: NameNode负责管理HDFS的命名空间,记录文件的元数据信息。
b) Jobtracker: JobTracker负责接收来自客户端的MapReduce作业,分配任务给TaskTracker并监控任务的执行。
c) Datanode: Datanode负责实际存储HDFS中的数据块,以及处理读取和写入请求。
d) SecondaryNameNode: SecondaryNameNode辅助NameNode,用于合并编辑日志,减少NameNode启动时间,但不负责实际数据存储。
e) TaskTracker: TaskTracker负责执行MapReduce任务,它接收来自JobTracker的任务分配,并执行相应的Map或Reduce任务。
39.配置机架感知的下面哪项正确:ABC
a)如果一个机架出问题,不会影响数据读写
b)写入数据的时候会写到不同机架的 DataNode 中
c)MapReduce 会根据机架获取离自己比较近的网络数据
a) 如果一个机架出问题,不会影响数据读写: 这描述了容错能力,但与机架感知无直接关系。
b) 写入数据的时候会写到不同机架的 DataNode 中: 这是机架感知的目标,以确保数据冗余和可靠性。
c) MapReduce 会根据机架获取离自己比较近的网络数据: 这描述了MapReduce作业的优化,利用机架感知来降低网络传输延迟。
40.Client 端上传文件的时候下列哪项正确?B
a)数据经过 NameNode 传递给 DataNode
b)Client 端将文件切分为 Block,依次上传
c)Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
在 HDFS 中,当 Client 端要上传文件时,它会将文件切分成适当大小的 Block,并将这些 Block 逐一上传到不同的 DataNode 上。这样可以实现数据的分布存储,提高数据的并行传输效率和容错性。 NameNode 负责记录每个 Block 的位置信息。
41.Cloudera 提供哪几种安装 CDH 的方法?ABCD
a)Cloudera manager
b)Tarball
c)Yum
d)Rpm
a) Cloudera Manager: Cloudera Manager 是一种强大的集成管理工具,可用于自动化、简化和管理 CDH 的安装、配置、监控和优化。
b) Tarball: CDH 软件也以 Tarball 形式提供,可以通过手动下载并解压缩进行安装。
c) Yum: Cloudera 提供了基于 Yum 的安装方式,可以通过配置 Yum 源来安装 CDH。
d) Rpm: CDH 组件也可以通过 RPM 包进行安装,这是一种常用的 Linux 软件包管理方式。
二、判断题
1. Ganglia 不仅可以进行监控,也可以进行告警。( √)
Ganglia是一个监控系统,它可以用于实时监控集群中各种指标,并提供告警功能,以便在特定条件满足时通知管理员。
2. Block Size 是不可以修改的。(× )
Block Size可以通过Hadoop的配置进行修改,以适应特定需求,通常以MB或GB为单位。
3. Nagios 不可以监控 Hadoop 集群,因为它不提供 Hadoop 支持。(× )
Nagios可以通过特定的插件扩展来监控Hadoop集群,提供Hadoop相关的监控和报警。
4. 如果 NameNode 意外终止,SecondaryNameNode 会接替它使集群继续工作。( ×)
SecondaryNameNode不会自动接替NameNode的功能。它主要用于辅助NameNode进行编辑日志合并,不会在NameNode意外终止时自动接管其功能。
5. Cloudera CDH 是需要付费使用的。( √ )
Cloudera Distribution for Hadoop(CDH)有企业版和免费的开源版,但企业版需要付费获取更多高级功能和支持。
6. Hadoop 是 Java 开发的,所以 MapReduce 只支持 Java 语言编写。(× )
Hadoop是用Java开发的,但MapReduce可以用多种编程语言编写,不仅限于Java。
7. Hadoop 支持数据的随机读写。(× )
Hadoop主要支持顺序读写,不是随机读写。HDFS不适合频繁的随机读写操作。
8. NameNode 负责管理 metadata,client 端每次读写请求,它都会从磁盘中读取或则会写入 metadata 信息并反馈 client 端。(× )
NameNode负责管理文件系统的metadata,但Client端每次请求不会直接访问NameNode,而是通过DataNode访问数据。
9. Hadoop 自身具有严格的权限管理和安全措施保障集群正常运行。( × )
Hadoop提供基本的权限管理,但需要结合其他安全措施,如Kerberos等,以保障集群的安全运行。
10. Slave 节点要存储数据,所以它的磁盘越大越好。( ×)
磁盘大小适应实际需求即可,不是越大越好。过大的磁盘可能会导致过多的数据分布在单个节点上,影响负载均衡。
11. hadoop dfsadmin –report 命令用于检测 HDFS 损坏块。(× )
hadoop dfsadmin -report命令用于获取HDFS的集群报告,但不是用于检测损坏块的。
12. Hadoop 默认调度器策略为 FIFO( √)
Hadoop的默认调度器是FIFO(First In, First Out),即先到先服务。
13. 集群内每个节点都应该配 RAID,这样避免单磁盘损坏,影响整个节点运行。( ×)
RAID是一种磁盘冗余技术,可以提高数据的可靠性和冗余度,但并不是每个节点都必须配备。
14.因为 HDFS 有多个副本,所以 NameNode 是不存在单点问题的。( ×)
NameNode是HDFS的单点故障,即使有多个副本,如果NameNode出现问题,仍然会影响文件系统的访问。
15. 每个 map 槽就是一个线程。( ×)
每个Map Task是一个线程,不是"map槽"。"map槽"通常指的是可用于运行Map Task的资源。
16. Mapreduce 的 input split 就是一个 block。(× )
Input Split不一定是一个block,它是对输入数据进行逻辑划分的单位。
17. DataNode 首次加入 cluster 的时候,如果 log 中报告不兼容文件版本,那需要 NameNode执行“Hadoop namenode -format”操作格式化磁盘。( ×)
DataNode首次加入集群时,不需要执行“Hadoop namenode -format”操作,这是初始化NameNode时的操作。
18. NameNode 的 Web UI 端口是 50030,它通过 jetty 启动的 Web 服务。(× )
NameNode的Web UI默认端口是50070,而不是50030。
19. Hadoop 环境变量中的 HADOOP_HEAPSIZE 用于设置所有 Hadoop 守护线程的内存。它默认是 200 GB。(× )
HADOOP_HEAPSIZE用于设置Hadoop守护进程的堆大小,并非默认为200 GB。
相关文章:
)
Hadoop作业篇(一)
一、选择题 1. 以下哪一项不属于Hadoop可以运行的模式__C____。 A. 单机(本地)模式 B. 伪分布式模式 C. 互联模式 D. 分布式模式 C. 互联模式 不属于Hadoop可以运行的模式。 Hadoop主要有四种运行模式: A. 单机(本地…...
)
SpringCloud中的分布式锁用法详解(Java+Redis SETNX命令)
前言: 在分布式系统中,保证数据的一致性和并发控制是至关重要的。分布式锁能够解决多个进程/线程同时访问共享资源的问题,确保只有一个进程/线程能够获得锁。本文将介绍如何使用Java和Redis实现分布式锁,并提供示例代码和注意事项…...

初学者如何选择:前端开发还是后端开发?
#开发做前端好还是后端好【话题征文】# 作为一名有多年开发经验的过来人,我认为前端开发和后端开发都有其独特的魅力和挑战。下面我将就我的个人经历和观点来分享一些关于前端开发和后端开发的看法。 首先,让我们将编程世界的大城市比作前端开发和后端开…...

从php页面插入MySQL的数据变为乱码如何解决?
在 PHP 页面中向 MySQL 数据库插入数据时,如果数据出现乱码,可能是因为字符集设置不正确或者字符编码不匹配。 数据库字符集设置不正确: 确保数据库的字符集设置与您的应用程序所使用的字符集一致。通常情况下,UTF-8 是一个通用的…...
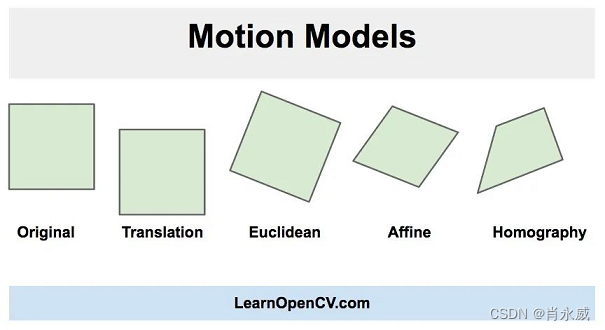
OpenCV防抖实践及代码解析笔记
视频防抖是指用于减少摄像机运动对最终视频的影响的一系列方法。摄像机的运动可以是平移(比如沿着x、y、z方向上的运动)或旋转(偏航、俯仰、翻滚)。 正如你在上面的图片中看到的,在欧几里得运动模型中,图像…...

函数栈帧的创建与销毁剖析
目录 一、前言 二、基础知识介绍 2.1 寄存器介绍 2.2、汇编指令介绍 三、函数栈帧的创建销毁过程 3.1 调用main函数的函数 3.2 main函数开辟栈帧 3.3 在main函数中创建变量 3.4 调用Add函数前的准备 3.5 为Add函数开辟栈帧 3.6 在Add函数中创建变量并运算 3.7 Add函…...
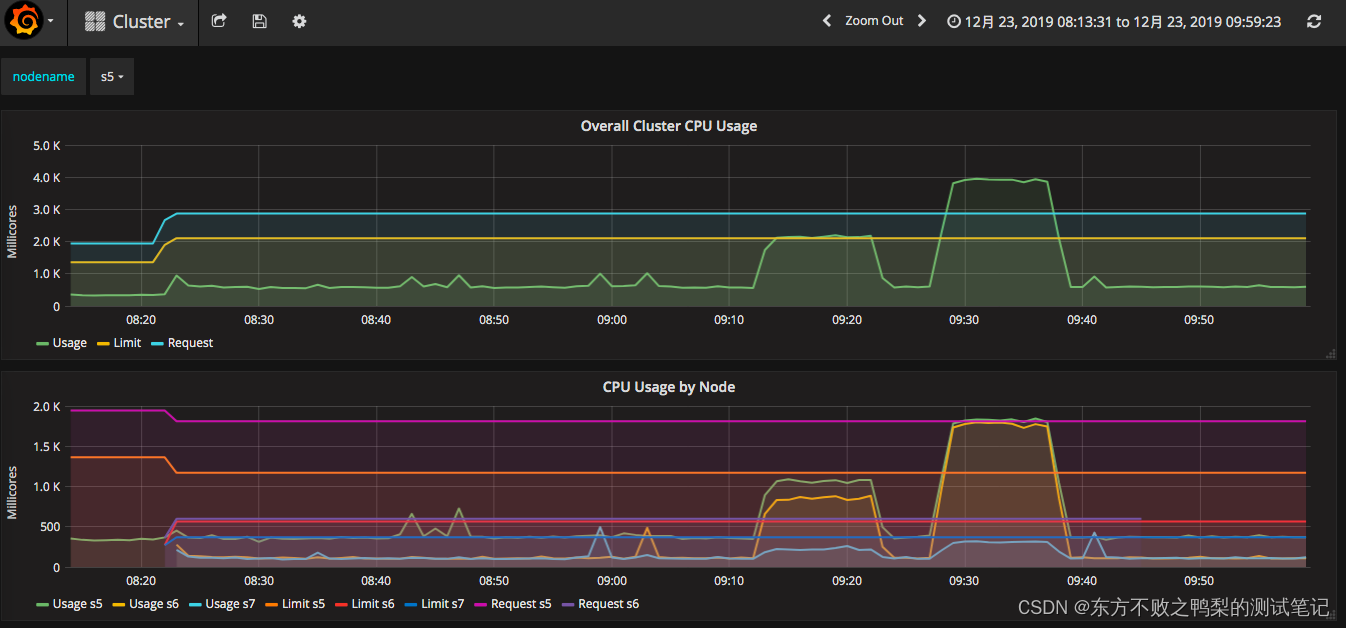
性能测试-如何进行监控设计
监控设计步骤 首先,你要分析系统的架构。在知道架构中使用的组件之后,再针对每个组件进行监控。 其次,监控要有层次,要有步骤。先全局,后定向定量分析。 最后,通过分析全局、定向、分层的监控数据做分析…...

大数据List去重
概述 两个超大List集合去重,时间最短的方式去实现。 详细 MaxList模块主要是对Java集合大数据去重的相关介绍。 背景: 最近在项目中遇到了List集合中的数据要去重,大概一个2500万的数据,开始存储在List中,需要跟一个2万的List去…...

CentOS8.2重启网络
查看网络配置命令 # ip addr # nmcli ens160: 已连接 到 ens160"VMware VMXNET3"ethernet (vmxnet3), 00:50:56:B6:34:84, 硬件, mtu 1500ip4 默认inet4 10.3.10.111/24route4 10.3.10.0/24route4 0.0.0.0/0inet6 fe80::250:56ff:feb6:3484/64route6 ff00::/8rou…...
2023年【G1工业锅炉司炉】考试题及G1工业锅炉司炉模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 2023年G1工业锅炉司炉考试题为正在备考G1工业锅炉司炉操作证的学员准备的理论考试专题,每个月更新的G1工业锅炉司炉模拟考试祝您顺利通过G1工业锅炉司炉考试。 1、【多选题】TSGG0001-2012《锅炉安全技术监…...

观察者模式 行为型设计模式之七
1.定义 在GOF的《设计模式:可复用面向对象软件的基础》一书中对观察者模式是这样定义的:定义对象的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。当一个对象发生了变化࿰…...
)
数据结构与算法之堆: Leetcode 451. 根据字符出现频率排序 (Typescript版)
根据字符出现频率排序 https://leetcode.cn/problems/sort-characters-by-frequency/ 描述 给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。返回 已排序的字符串 。如果有多个答案,返回其…...
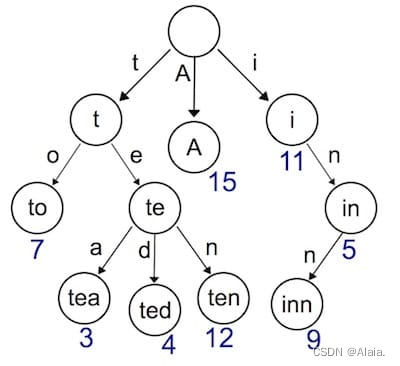
吃透底层:从路由到前缀树
前言 今天学到关于路由相关文章,发现动态路由中有一个很常见的实现方式是前缀树,很感兴趣这个算法,故进行记录。 前缀树 Trie(又被叫做字典树)可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含…...

SparkSQL外部数据源
1.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。 - CSV - JSON - Parquet - ORC - JDBC/ODBC connections - Plain-text files 1.2 读数据格式 所有读取 API 遵循以下调用格式: // …...

林沛满-TCP 是如何避免被发送方分片的?
TCP 可以避免被发送方分片,是因为它主动把数据分成小段再交给网络层。最大的分段大小称为 MSS(Maximum Segment Size),它相当于把 MTU 刨去 IP头和 TCP 头之后的大小,所以一个 MSS 恰好能装进一个 MTU 中。 图4 图 4 …...

Java中的枚举是什么?
Java枚举详解 枚举(Enum)是Java编程语言中的一种特殊数据类型,它用于表示一组具名的常量。枚举提供了一种更加类型安全和易于理解的方式来表示常量值,使代码更加清晰和可维护。 为什么需要枚举? 在介绍Java枚举的具…...
)
java学习--day24(单例模式序列化Lambda表达式)
文章目录 回顾今天的内容1.单例模式2.序列化3.Lambda表达式3.1入门案例3.2lambda表达式语法格式3.2.1无参无返回值的形式3.2.2有参无返返回值的方法3.2.3无参有返回值3.2.4有参有返回值的 回顾 1.三种创建Class对象的形式Class.forName("")类.class对象.getCalss()字…...

从0开始学go第六天
方法一:gin获取querystring参数 package main//querystring import ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/web", func(c *gin.Context) {//获取浏览器那边发请求携带的query String参数//…...
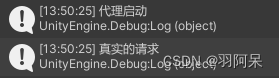
unity设计模式——代理模式
Subject类,定义了Real Subject和Proxy的共用接口,这样就在任何使用Real Subject的地方都可以使用Proxy。 abstract class Subject : MonoBehaviour {public abstract void Request(); } RealSubject类,定义Proxy所代表的真实实体。 class R…...

SpringBoot 如何使用 Grafana 进行可视化监控
使用Spring Boot Sleuth进行分布式跟踪 在现代分布式应用程序中,跟踪请求和了解应用程序的性能是至关重要的。Spring Boot Sleuth是一个分布式跟踪解决方案,它可以帮助您在分布式系统中跟踪请求并分析性能问题。本文将介绍如何在Spring Boot应用程序中使…...

不只是安装:在龙芯2k1000LA上为Loongnix配置WiFi、蓝牙与触摸屏驱动的完整流程
龙芯2k1000LA开发板外设驱动深度配置指南:从WiFi到触摸屏的全栈解决方案 在国产化硬件开发领域,龙芯2k1000LA开发板凭借其完全自主的LoongArch架构,正成为物联网和嵌入式设备开发者的重要选择平台。不同于x86架构的"开箱即用"体验&…...

智能体技能库构建指南:从基础工具到复杂工作流编排
1. 项目概述:智能体技能库的构建与价值最近在探索AI智能体(Agent)的开发与应用时,我一直在思考一个问题:一个真正“智能”的智能体,其核心能力究竟体现在哪里?是背后的大语言模型(LL…...

粒子物理实验中的异构计算与AI技术应用
1. 粒子物理实验的计算挑战与机遇 粒子物理实验正经历前所未有的数据爆炸时代。以大型强子对撞机(HL-LHC)为例,其升级后的数据采集率将达到每秒数PB级别,这相当于每天产生约1亿张高清照片的数据量。传统基于CPU的串行计算架构已无…...

从开源模型到API服务:OpenClaw部署实战与Docker+FastAPI方案解析
1. 项目概述:从开源模型到可部署服务的跨越最近在折腾大语言模型本地部署的朋友,可能都绕不开一个名字:OpenClaw。这个由智源研究院开源的模型,以其在代码生成和数学推理上的出色表现,吸引了不少开发者和研究者的目光。…...

桌面图标混乱终结者:用NoFences免费开源工具实现高效桌面管理
桌面图标混乱终结者:用NoFences免费开源工具实现高效桌面管理 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的桌面图标而烦恼吗?每天…...

STM32L4实战:用RTC唤醒定时器实现33秒超长待机,实测功耗从52mA降到2.2mA
STM32L4超低功耗实战:从52mA到2.2mA的RTC唤醒优化全解析 当一块STM32L4开发板的功耗从52mA骤降到2.2mA,这不仅仅是数字的变化——它意味着智能穿戴设备的续航从1天延长到3周,工业传感器节点可以摆脱电源线的束缚,便携医疗设备的安…...

Boss-Key终极指南:一键隐藏窗口,打造高效安全的办公环境
Boss-Key终极指南:一键隐藏窗口,打造高效安全的办公环境 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办…...

数字电路小白也能懂:用Logisim搞定LED计数电路,从真值表到封装测试保姆级教程
数字电路零基础实战:用Logisim构建LED计数器的完整指南 从困惑到清晰:为什么选择Logisim作为数字电路入门工具 第一次接触数字电路时,面对密密麻麻的逻辑门和抽象的真值表,大多数初学者都会感到无从下手。传统教材中复杂的公式推导…...

告别论文焦虑:Paperxie 为本科毕业论文搭建的「全流程写作脚手架」
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 毕业季的凌晨三点,宿舍台灯下亮着的电脑屏幕,是无数本科生共同的记忆。当 10000 字的毕业…...

为啥大模型都要用 Token 调用,不能直接扒网页端接口?
1. 网页端接口是「给人用的」,随时会改 网页版(比如官网聊天页)的接口: 参数、请求头、加密算法、签名天天变 前端一改版,接口地址、加密方式直接作废 你好不容易扒完,过两天就挂,还要重新抓包、逆向 而官方开放的 API + Token 是稳定商用接口,几年都不换格式,专门给…...