大数据List去重
概述
两个超大List集合去重,时间最短的方式去实现。
详细
MaxList模块主要是对Java集合大数据去重的相关介绍。
背景: 最近在项目中遇到了List集合中的数据要去重,大概一个2500万的数据,开始存储在List中,需要跟一个2万的List去去重。
直接两个List去重
说到去重,稍微多讲一点啊,去重的时候有的小伙伴可能直接对2500万List foreach循环后直接删除,
其实这种是错误的(java.util.ConcurrentModificationException),大家可以自己去试一下;(注: for循环遍历删除不报错,但是效率低,不推荐使用)
首先你需要去看下foreach和迭代器的实现。foreach的实现就是用到了迭代器,所以你在foreach的时候对list进行删除操作,
迭代器Iterator无法感知到list删除了,所以会报错。直接贴代码解释下。
ArrayList中Iterator的实现:
private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = -1; // index of last element returned; -1 if no suchint expectedModCount = modCount;public boolean hasNext() {return cursor != size;}@SuppressWarnings("unchecked")public E next() {checkForComodification();int i = cursor;if (i >= size)throw new NoSuchElementException();Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length)throw new ConcurrentModificationException();cursor = i + 1;return (E) elementData[lastRet = i];}public void remove() {if (lastRet < 0)throw new IllegalStateException();checkForComodification();try {ArrayList.this.remove(lastRet);cursor = lastRet;lastRet = -1;expectedModCount = modCount;} catch (IndexOutOfBoundsException ex) {throw new ConcurrentModificationException();}}@Override@SuppressWarnings("unchecked")public void forEachRemaining(Consumer<? super E> consumer) {Objects.requireNonNull(consumer);final int size = ArrayList.this.size;int i = cursor;if (i >= size) {return;}final Object[] elementData = ArrayList.this.elementData;if (i >= elementData.length) {throw new ConcurrentModificationException();}while (i != size && modCount == expectedModCount) {consumer.accept((E) elementData[i++]);}// update once at end of iteration to reduce heap write trafficcursor = i;lastRet = i - 1;checkForComodification();}final void checkForComodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}}通过上述的ArrayList里面的Iterator迭代器的实现我们可以看到:
基本上ArrayList采用size属性来维护自已的状态,而Iterator采用cursor来来维护自已的状态。
当你直接在foreach里面对list进行删除操作,size出现变化时,cursor并不一定能够得到同步,除非这种变化是Iterator主动导致的。(调用list.iterator()方法的原因)
从上面的代码可以看到当Iterator.remove方法导致ArrayList列表发生变化时,他会更新cursor来同步这一变化。但其他方式导致的ArrayList变化,Iterator是无法感知的。ArrayList自然也不会主动通知Iterator们,那将是一个繁重的工作。Iterator到底还是做了努力:为了防止状态不一致可能引发的无法设想的后果,Iterator会经常做checkForComodification检查,以防有变。如果有变,则以异常抛出,所以就出现了上面的异常。
如果对正在被迭代的集合进行结构上的改变(即对该集合使用add、remove或clear方法),那么迭代器就不再合法(并且在其后使用该迭代器将会有ConcurrentModificationException异常被抛出).
如果使用迭代器自己的remove方法,那么这个迭代器就仍然是合法的。
public static void deWeightList(List<String> des, List<String> sourse){if(sourse == null || sourse.size() <= 0){return;}lIterator<String> listStr = sourse.iterator();while (listStr.hasNext()){String item = listStr.next();for (String ditem: des) {if(item.equals(ditem)){listStr.remove();break;}}}logger.info("after deWight list size: " + sourse.size());}List结合Set去重
public static void deWeightList(Set<String> des, List<String> sourse) {if (sourse == null || sourse.size() <= 0) {return;}Iterator<String> listStr = sourse.iterator();while (listStr.hasNext()) {String item = listStr.next();if (des.contains(item)) {listStr.remove();}}logger.info("after deWight list size: " + sourse.size());}List结合Set去重(不是直接对list进行删除,而是组装新list,考虑到list删除效率低)
public static void deWeightListByNewList(Set<String> des, List<String> sourse) {if (sourse == null || sourse.size() <= 0) {return;}Iterator<String> listStr = sourse.iterator();List<String> existList = new ArrayList<String>();while (listStr.hasNext()) {String item = listStr.next();if(!des.contains(item)){//TODO 对去重后的数据进行逻辑操作,不一定要删除,可以换个思路(是否可以直接逻辑操作,不一定非要再把数据写进集合后,然后遍历集合在进行逻辑操作)existList.add(item); //改成添加进新的list,考虑到list的删除效率慢(非要得到删除后的集合的情况下,否则走else)}// if (des.contains(item)) {// //listStr.remove(); //考虑到list的删除效率慢,此种方法对于大数据集合来说不合适// }}sourse.clear();sourse = existList;logger.info("after deWight list size: " + sourse.size());}遍历过程中去重
个人最为推荐的一种,因为效率最高,也能达到功能的需要。
for (String item: maxArrayList) {if(testSet.contains(item)){//TODO}}测试结果如下
下面是1000万的list和20000的list去重两种方式所花的时间,可以看出使用set去重的效率要高很多。
1.list结合list去重时间:
14:52:02,408 INFO [RunTest:37] start test list:17-11-07 14:52:02
14:59:49,828 INFO [ListUtils:66] after deWight list size: 9980000
14:59:49,829 INFO [RunTest:39] end test list:17-11-07 14:59:49
2.list结合set去重时间:
14:59:53,226 INFO [RunTest:44] start test set:17-11-07 14:59:53
15:01:30,079 INFO [ListUtils:80] after deWight list size: 9980000
15:01:30,079 INFO [RunTest:46] end test set:17-11-07 15:01:30
下面是2500万的list和20000的list去重两种方式所花的时间,可以看出使用set去重的效率要更加的高,(数据量越大越明显)。
个人对set的大小为1500万也进行了测试,方案3,4的效率也是非常的高。
1.list结合list去重时间:
15:17:47,114 INFO [RunTest:35] start test list, start time: 17-11-07 15:17:47
15:49:04,876 INFO [ListUtils:57] after deWight list size: 24980000
15:49:04,877 INFO [RunTest:39] end test list, end time: 17-11-07 15:49:04
2.list结合set去重时间:
15:49:17,842 INFO [RunTest:44] start test set, start time: 17-11-07 15:49:17
15:53:22,716 INFO [ListUtils:71] after deWight list size: 24980000
15:53:22,718 INFO [RunTest:48] end test set, end time: 17-11-07 15:53:22
3. List结合Set去重(不是直接对list进行删除,而是组装新list,考虑到list删除效率低)
17:18:44,583 INFO [RunTest:57] start test set, start time: 17-11-22 17:18:44
17:18:54,628 INFO [ListUtils:92] after deWight list size: 23500000
17:18:54,628 INFO [RunTest:61] end test set, end time: 17-11-22 17:18:48
4.遍历过程中结合set去重:(个人最为推荐的原因之一,效率高到令人爽到不行)
15:17:45,762 INFO [RunTest:24] start test foreach list directly, start time: 17-11-07 15:17:45
15:17:47,114 INFO [RunTest:32] end test foreach list directly, end time: 17-11-07 15:17:47总结
通过上述测试我们可以看出,有时候我们排重的时候,不一定要拍完重再对排重后的数据进行遍历,可以在遍历的过程中进行排重,注意用来排重的那个集合放到Set中,
可以是HashSet,或者其他Set(推荐使用HashSet),因为Set的contains效率更高,比list高很多。
然后考虑到如果非要拿到去重后的list,考虑使用方案3《List结合Set去重(不是直接对list进行删除,而是组装新list,考虑到list删除效率低)》,通过测试,这种方法效率也是非常的高。
与方案4相比,稍微慢一点点。
对于上述方案1,测试也使用过组装新list的方式,而不是list.remove。但是效率还是比较慢。
相关文章:

大数据List去重
概述 两个超大List集合去重,时间最短的方式去实现。 详细 MaxList模块主要是对Java集合大数据去重的相关介绍。 背景: 最近在项目中遇到了List集合中的数据要去重,大概一个2500万的数据,开始存储在List中,需要跟一个2万的List去…...

CentOS8.2重启网络
查看网络配置命令 # ip addr # nmcli ens160: 已连接 到 ens160"VMware VMXNET3"ethernet (vmxnet3), 00:50:56:B6:34:84, 硬件, mtu 1500ip4 默认inet4 10.3.10.111/24route4 10.3.10.0/24route4 0.0.0.0/0inet6 fe80::250:56ff:feb6:3484/64route6 ff00::/8rou…...
2023年【G1工业锅炉司炉】考试题及G1工业锅炉司炉模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 2023年G1工业锅炉司炉考试题为正在备考G1工业锅炉司炉操作证的学员准备的理论考试专题,每个月更新的G1工业锅炉司炉模拟考试祝您顺利通过G1工业锅炉司炉考试。 1、【多选题】TSGG0001-2012《锅炉安全技术监…...

观察者模式 行为型设计模式之七
1.定义 在GOF的《设计模式:可复用面向对象软件的基础》一书中对观察者模式是这样定义的:定义对象的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。当一个对象发生了变化࿰…...
)
数据结构与算法之堆: Leetcode 451. 根据字符出现频率排序 (Typescript版)
根据字符出现频率排序 https://leetcode.cn/problems/sort-characters-by-frequency/ 描述 给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。返回 已排序的字符串 。如果有多个答案,返回其…...
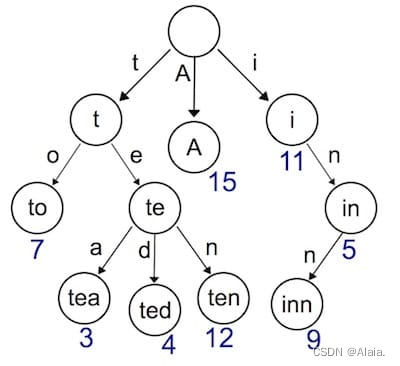
吃透底层:从路由到前缀树
前言 今天学到关于路由相关文章,发现动态路由中有一个很常见的实现方式是前缀树,很感兴趣这个算法,故进行记录。 前缀树 Trie(又被叫做字典树)可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含…...

SparkSQL外部数据源
1.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。 - CSV - JSON - Parquet - ORC - JDBC/ODBC connections - Plain-text files 1.2 读数据格式 所有读取 API 遵循以下调用格式: // …...

林沛满-TCP 是如何避免被发送方分片的?
TCP 可以避免被发送方分片,是因为它主动把数据分成小段再交给网络层。最大的分段大小称为 MSS(Maximum Segment Size),它相当于把 MTU 刨去 IP头和 TCP 头之后的大小,所以一个 MSS 恰好能装进一个 MTU 中。 图4 图 4 …...

Java中的枚举是什么?
Java枚举详解 枚举(Enum)是Java编程语言中的一种特殊数据类型,它用于表示一组具名的常量。枚举提供了一种更加类型安全和易于理解的方式来表示常量值,使代码更加清晰和可维护。 为什么需要枚举? 在介绍Java枚举的具…...
)
java学习--day24(单例模式序列化Lambda表达式)
文章目录 回顾今天的内容1.单例模式2.序列化3.Lambda表达式3.1入门案例3.2lambda表达式语法格式3.2.1无参无返回值的形式3.2.2有参无返返回值的方法3.2.3无参有返回值3.2.4有参有返回值的 回顾 1.三种创建Class对象的形式Class.forName("")类.class对象.getCalss()字…...

从0开始学go第六天
方法一:gin获取querystring参数 package main//querystring import ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/web", func(c *gin.Context) {//获取浏览器那边发请求携带的query String参数//…...
unity设计模式——代理模式
Subject类,定义了Real Subject和Proxy的共用接口,这样就在任何使用Real Subject的地方都可以使用Proxy。 abstract class Subject : MonoBehaviour {public abstract void Request(); } RealSubject类,定义Proxy所代表的真实实体。 class R…...

SpringBoot 如何使用 Grafana 进行可视化监控
使用Spring Boot Sleuth进行分布式跟踪 在现代分布式应用程序中,跟踪请求和了解应用程序的性能是至关重要的。Spring Boot Sleuth是一个分布式跟踪解决方案,它可以帮助您在分布式系统中跟踪请求并分析性能问题。本文将介绍如何在Spring Boot应用程序中使…...

【Codeforces】 CF1762E Tree Sum
题目链接 CF方向 Luogu方向 题目解法 首先考虑 n n n 为奇数的情况无解,这个可以通过乘积矛盾简单证明 接下来考虑一个结论是:偶数个点的树的形态确定之后,只有恰好 1 1 1 种染色方案,即从叶子一层一层往上面染,…...

用《斗破苍穹》的视角打开C#委托2 委托链 / 泛型委托 / GetInvocationList
委托链 经过不懈地努力,我终于成为了斗师,并成功掌握了两种斗技——八极崩和焰分噬浪尺。于是,我琢磨着,能不能搞一套连招,直接把对方带走。 using System; using System.Collections.Generic; using System.Linq; u…...

唐老师讲电赛
dc-dc电源布局要点...

[ICCV-23] DeformToon3D: Deformable Neural Radiance Fields for 3D Toonification
pdf | code 将3D人脸风格化问题拆分为几何风格化与纹理风格化。提出StyleField,学习以风格/ID为控制信号的几何形变残差,实现几何风格化。通过对超分网络引入AdaIN,实现纹理风格化。由于没有修改3D GAN空间,因此可以便捷实现Edit…...
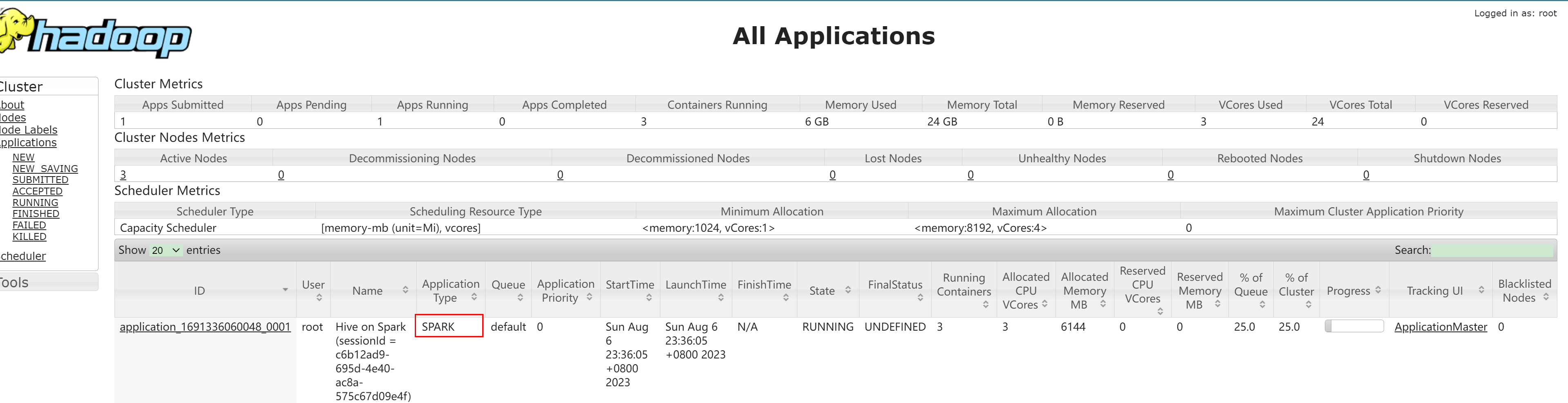
配置Hive使用Spark执行引擎
配置Hive使用Spark执行引擎 Hive引擎概述兼容问题安装SparkSpark配置Hive配置HDFS上传Spark的jar包执行测试速度对比 Hive引擎 概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早…...
)
基于FPGA的视频接口之千兆网口(五应用)
简介 相信网络上对于FPGA驱动网口的开发板、博客、论坛数不胜数,为何博主需要重新手敲一遍呢,而不是做一个文抄君呢!因为目前博主感觉网络上描述的多为应用层上的开发,非从底层开始说明,本博主的思虑还是按照老规矩,按照硬件、底层、应用等关系,使用三~四篇文章,来详细…...
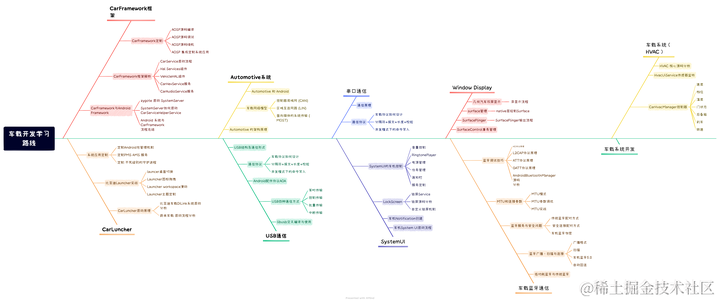
车载开发所学内容,有哪些?程序员的转岗位需求
一、高速发展的行业前景 随着全球智能汽车市场的飞速发展,车载开发行业的前景可谓一片光明。各国政府对于自动驾驶和智能交通系统的政策支持,为行业带来了前所未有的机遇。此外,人工智能、大数据、云计算等前沿技术的不断突破,为…...

多智能体协作框架Agentset:从原理到实战构建AI团队
1. 项目概述:当AI智能体开始“组队打怪”最近在AI应用开发圈里,一个词的热度持续攀升:智能体(Agent)。如果说大语言模型(LLM)是学会了“思考”的大脑,那么智能体就是具备了“感知-决…...

工业触控一体机选型与Linux应用开发全解析
1. 项目概述:当工业现场需要一块“聪明”的屏幕最近在跟进一个智慧工厂的MES(制造执行系统)终端升级项目,客户现场的老式工控机搭配笨重的显示器,不仅布线杂乱,操作响应慢,而且维护起来极其麻烦…...

CIMR-V架构:RISC-V与存内计算融合的边缘AI加速方案
1. CIMR-V架构设计背景与核心挑战在边缘AI设备领域,能效比和实时性是两个最关键的指标。传统冯诺依曼架构中"内存墙"问题尤为突出——数据在存储单元和计算单元之间的频繁搬运消耗了系统60%以上的能量。存内计算(CIM)技术通过将计算单元嵌入存储阵列&…...

OpenClaw-China:中文场景下开源大语言模型高效微调与部署实战指南
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“BytePioneer-AI/openclaw-china”。光看这个名字,你可能会有点摸不着头脑——“BytePioneer”是字节先锋,“openclaw”是开放之爪,再加上“china”的后缀&#x…...

一键部署本地大模型:基于vLLM与Hermes的AI对话服务搭建指南
1. 项目概述与核心价值最近在折腾本地大语言模型(LLM)部署的朋友,估计都绕不开一个名字:Hermes。这个名字背后,通常指的是由 NousResearch 团队发布的 Hermes 系列模型,它们以出色的指令遵循能力和对话质量…...

ISDN PRI外线故障排查实战指南
在实际运维案例中,工程师不怕故障一直出现,就怕偶尔出问题。比如客户反馈打外线时,偶尔会出现断线的情况。当然可以通过MST或Trace命令去跟踪,但如果故障发生频率过低,抓日志往往很难。我们通常需要先检查线路质量&…...

使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后模型 API 响应延迟与稳定性效果实测观察 作为一名需要频繁调用大模型 API 的开发者,模型服务的响应速…...

OpenClaw AVP:构建统一音视频协议栈,实现多协议流媒体处理
1. 项目概述:一个面向音视频处理的协议栈最近在整理一些音视频项目时,又翻到了avp-protocol/openclaw-avp这个仓库。对于从事流媒体、实时通信或者音视频编解码开发的工程师来说,看到avp这个缩写,第一反应多半是 “Audio-Video Pr…...

声明式应用编排框架Planifest:云原生时代应用交付新范式
1. 项目概述:一个面向未来的声明式应用编排框架如果你和我一样,在云原生和自动化运维领域摸爬滚打了几年,就会深刻体会到“编排”这个词的分量。从早期的Shell脚本,到Ansible、Terraform,再到Kubernetes的YAML海洋&…...

3.【Python】Python3 数据类型转换
第一步:分析与整理数据类型转换1. 数据类型转换概述 数据类型转换分为两种: 隐式类型转换:Python 自动完成,无需干预。显式类型转换:使用内置函数手动转换。2. 隐式类型转换 规则:当不同类型的数据进行运算…...