应用层协议 HTTP
一、应用层协议
我们已经学过 TCP/IP , 已然知道数据能从客户端进程经过路径选择跨网络传送到服务器端进程。
我们还需要知道的是,我们把数据从 A 端传送到 B 端, TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用,所以我们还需要一层协议,不关心通信细节,关心应用细节!这层协议叫做应用层协议。而应用是有不同的场景的,因此应用层协议经常是需要“自定义协议”的,通常情况下可以基于一些设计好的协议进行定制,HTTP 之所以应用特别广,主要原因就是可定制性特别强。
二、HTTP 报文格式
学习 HTTP 协议最主要的就是认识它的报文格式。我们可以通过抓包来获取到 HTTP 的报文格式,下面以浏览器访问百度时的请求响应为例进行抓包:
抓包原理:
抓包工具 相当于一个 “代理”。浏览器访问 www.baidu.com 时, 就会把 HTTP 请求先发给 抓包工具,抓包工具 再把请求转发给 百度 的服务器。当 百度 服务器返回数据时,抓包工具 拿到返回数据,再把数据交给浏览器。因此 抓包工具 对于浏览器和 百度 服务器之间交互的数据细节,都是非常清楚的。
HTTP 请求 抓包结果:
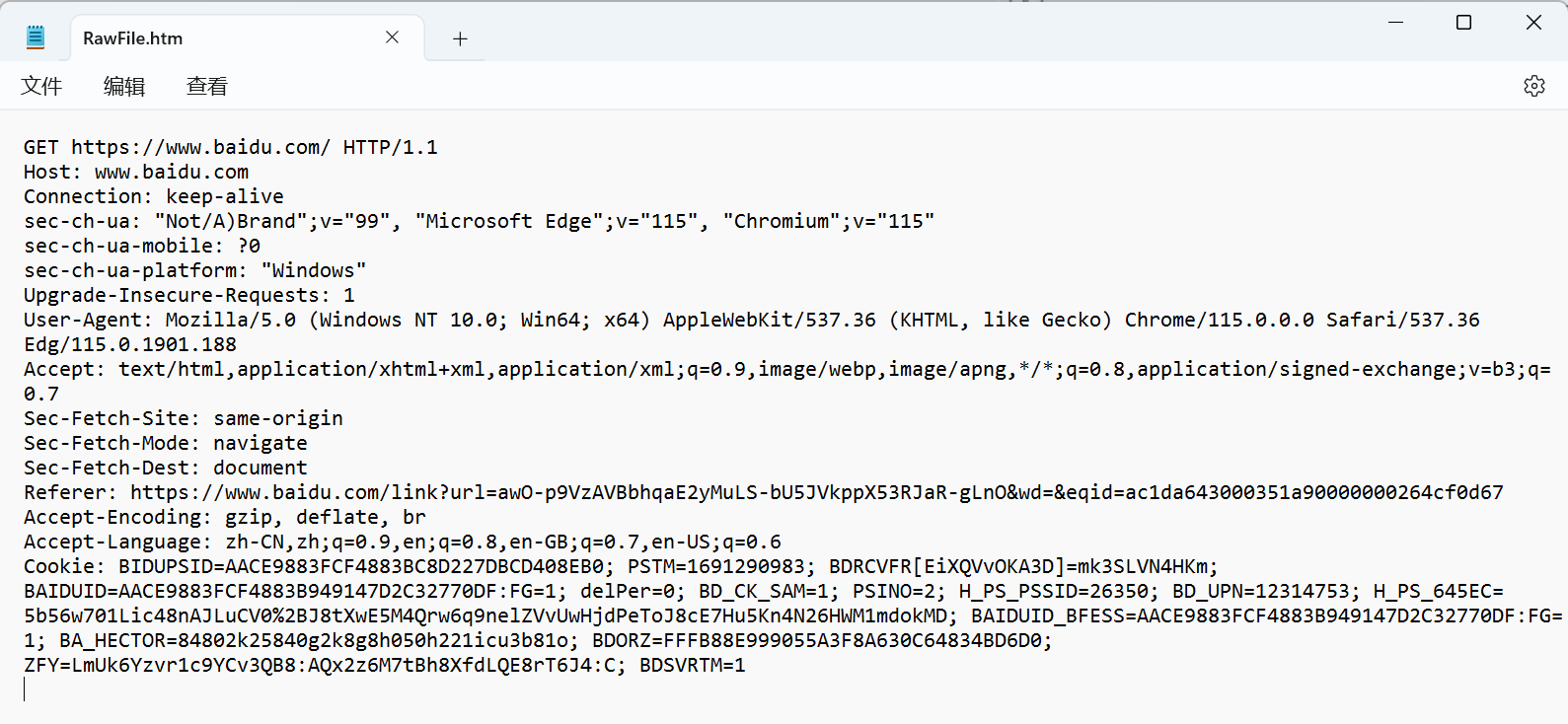
注解:
首行: [方法] + [url] + [版本]Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔空行: 遇到空行表示Header部分结束Body: 空行后面的内容都是Body。Body允许为空字符串,如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度
HTTP 响应 抓包结果:
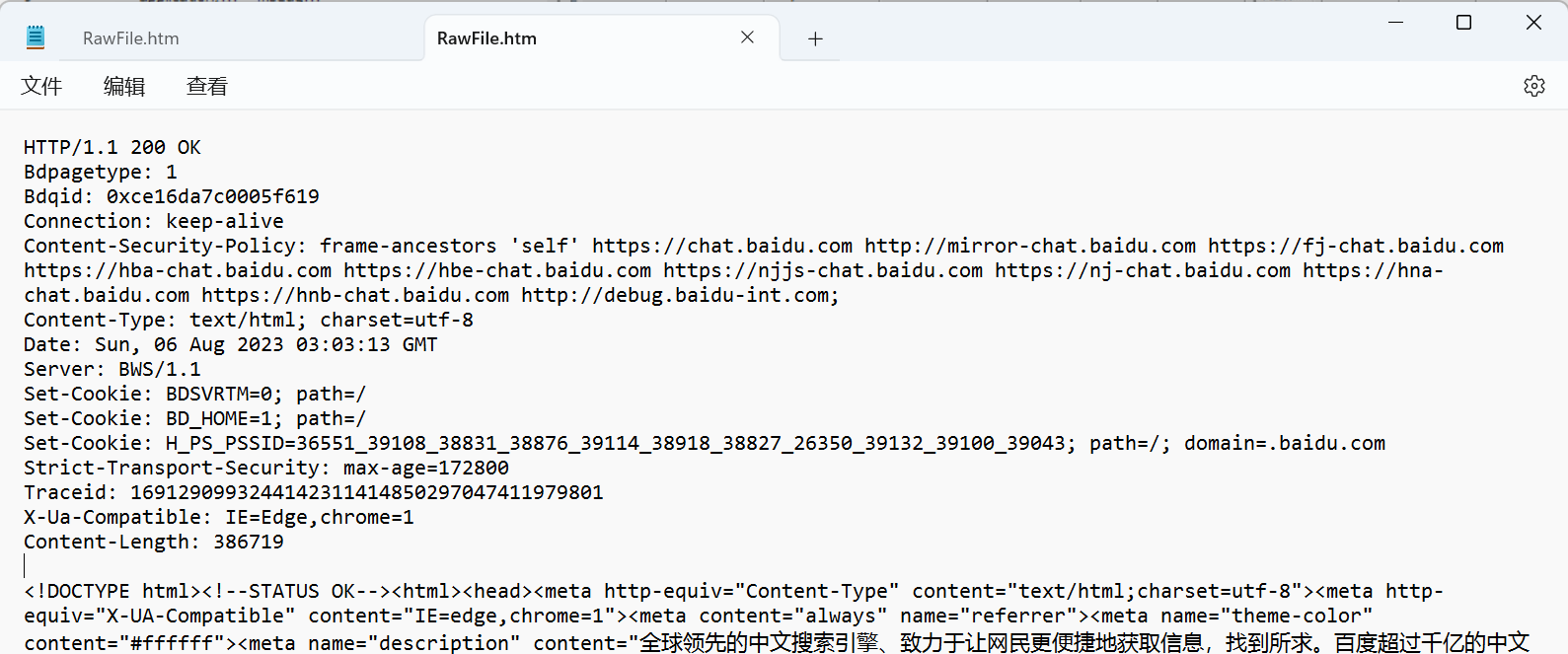
注解:
首行: [版本号] + [状态码] + [状态码解释]Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔空行: 遇到空行表示Header部分结束Body: 空行后面的内容都是Body。Body允许为空字符串,如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度
HTTP 协议格式总结:
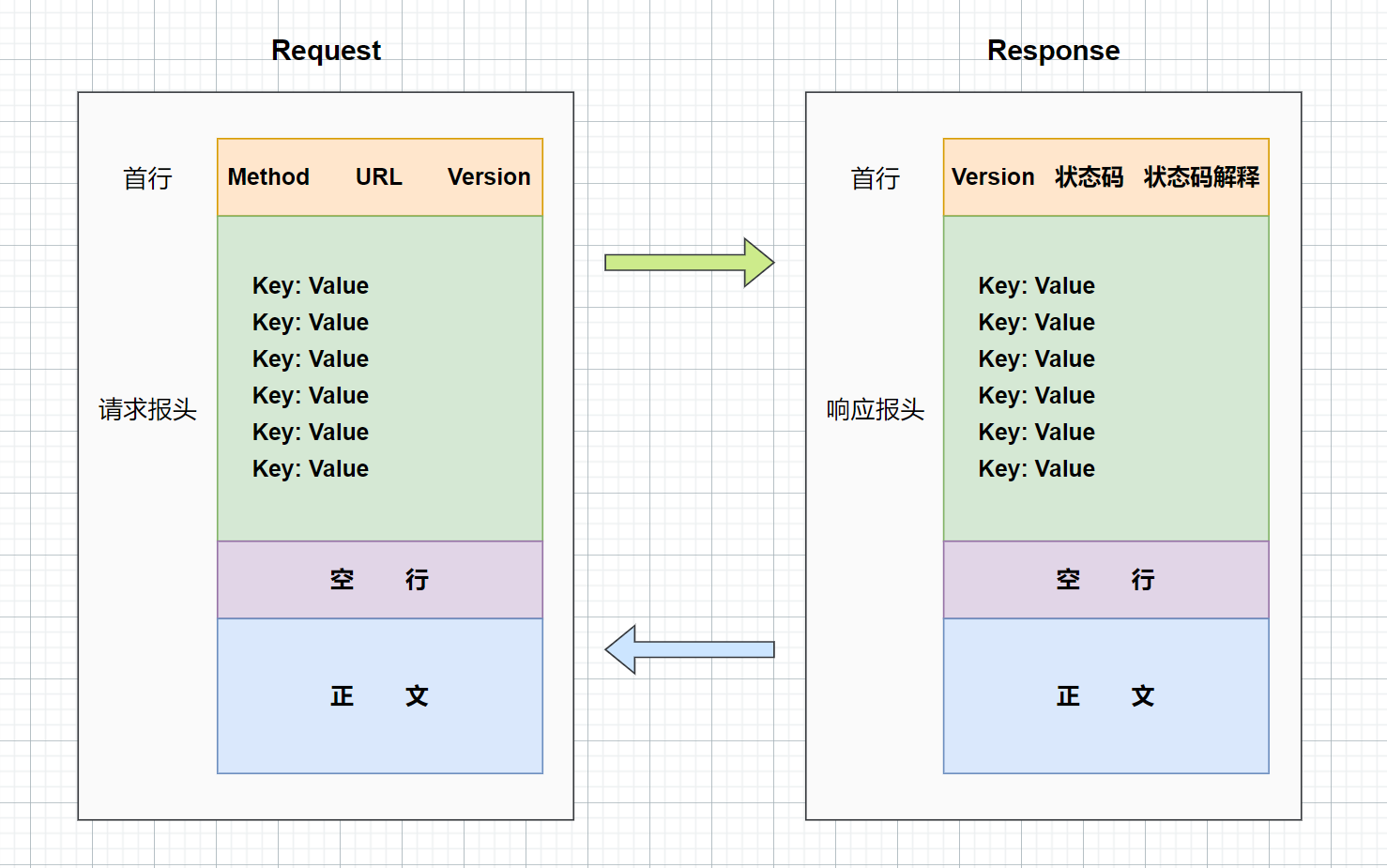
空行的作用:
HTTP 协议并没有规定报头部分的键值对有多少个,空行就相当于是 “报头的结束标记”,或者是 “报头和正文之间的分隔符”。
三、HTTP 请求详解
1、首行
(1)请求方法:
| 请求方法 | 描述 |
|---|---|
| GET | 从服务器获取资源 |
| POST | 向指定服务器资源提交数据进行处理请求(例如提交表单或上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。 |
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新。 |
HTTP的请求方法,描述了这个HTTP请求想干什么。HTTP协议有很多的请求方法,不同的方法表示不同的语义。其中 GET 方法(表示从服务器获取资源)和 POST 方法(表示向服务器提交数据资源,登录、上传文件等场景下)是常用到的方法,而 GET 又是最常用的方法,至于其他方法我们很少会用得上。
因此有这样一句话:天下HTTP请求分十斗,GET请求独占八斗,POST请求占一斗,其他方法请求共占一斗。
GET 和 POST 的区别
虽然 GET 和 POST 表示不同语义,但实际上 HTTP 的语义只是一种建议,在实际使用的时候不一定非要遵守。因此 GET 和 POST 没有本质上的区别,使用GET的场景,替换换成POST也没有问题,使用POST的场景替换成GET也可以。但是二者在使用习惯上存在区别:
- 使用 GET 请求传参到后台时,传递的参数则显示在地址栏,安全性低,且参数的长度也有限制(2048字符);POST 请求则是将传递的参数放在 request body 中,不会在地址栏显示,安全性比 GET 请求高,且参数没有长度限制。(重要区别)
- GET习惯上用来表示 获取数据,POST 用来表示提交数据。
- GET一般没有 body,需要携带的数据通常放到URL中,POST一般有 body,将需要携带的数据放到 body 中。
- GET请求可以被浏览器收藏,POST请求不可以。(当我们收藏一个链接时,浏览器会记录该链接的 URL,GET 请求可以被浏览器收藏,因为请求参数包含在 URL 中,而 POST 请求不能被浏览器直接收藏,因为请求数据位于请求体中,无法完整保存在收藏夹中)
- GET请求通常设计出幂等的,POST 请求一般是不幂等的。(如果多次请求得到的结果一样, 就视为请 求是幂等的)
- 承接上述幂等性的前提下,GET 可以被缓存,POST 不能被缓存。
(2)URL
URL(Uniform Resource Locator)是统一资源定位符的缩写。它是用于标识和定位互联网上的资源(如网页、图像、视频等)的字符串格式。
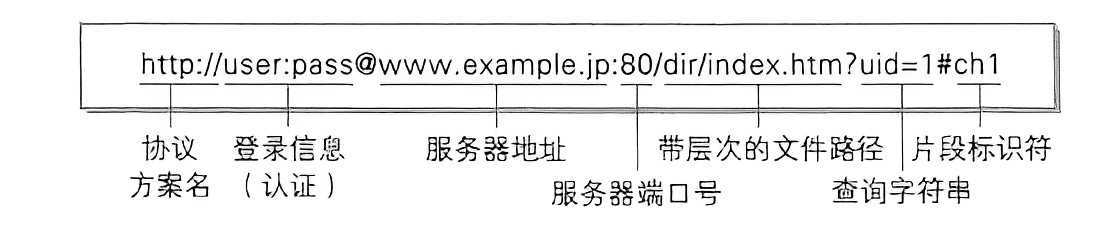
例如:
https://cn.bing.com/videos/search?q=abcde&form=Z9LH1
- 协议:常见的有 http 和 https,也有其他的类型。(例如访问 mysql 时用的jdbc:mysql )
- 登陆信息(认证):现在的网站进行身份认证一般不再通过 URL 进行了,一般都会省略
- 服务器地址:此处是一个 “域名”,域名会通过 DNS 系统解析成一个具体的 IP 地址(通过 ping 命令可以看到域名真实 IP 地址 )
- 端口号(可选):指定了与服务器建立连接时要使用的端口。当端口号省略的时候,浏览器会根据协议类型自动决定使用哪个端口。例如 http 协议默认使用 80 端口,https 协议默认使用 443 端口
- 带层次的文件路径:表示要访问的资源在服务器上的路径或文件信息
- 查询字符串(query string)(可选):对请求资源进行细节上的补充。本质是一个键值对结构,键值对之间使用& 分隔,键和值之间使用 = 分隔
- 片段标识(可选):片段标识主要用于页面内跳转
(3) 版本号
在HTTP协议的首行中还包含另一个字段,叫做“版本号”。
版本号是指明正在使用的HTTP协议版本的一部分。常见的HTTP协议版本包括
HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3等。它用于指示客户端和服务器之间所使用的协议版本,以确保双方能够正确解析和处理请求或响应。当前最主流的的版本是HTTP/1.1,绝大部分互联网上的网站用的都是 HTTP/1.1 版本。
2、请求报头 Header
通过观察上面的抓包情况,可以看到,请求头是由键值对组成的。Header中的键值对大多都是HTTP协议规定的,当然也可以添加自定义键值对,这也是HTTP定制性强的体现。对于报头中的每一个键值结构都有自己的含义,下面介绍几种比较常见的键值结构:
(1)Host:表示服务器主机的地址和端口。
大多数情况下,Host中的值和URL中的域名是一致的。那么为什么还要存在这样一个键值结构呢?这就要谈到不一样的情况了,当我们访问服务器不是直接访问,而是通过代理访问,此时的Host和URL中的域名就不一样了。
(2)Content-Length:表示 body 中的数据长度(字节)。
Content-Length依赖于Body,如果一个请求没有Body,Header中就没有这个属性。
(3)Content-Type:表示请求的 body 中的数据格式。
Content-Type 同样依赖于 Body,如果一个请求没有Body,Header 中就没有这个属性。
作为请求,Content-Type 使用最多的是下面 两种 格式:
1、
Content-Type: application/json;charset=UTF-8
这里表示数据是按照json格式组织的,并指定里数据的字符集为UTF-8
此时的body格式形如:
{"username":"xxxxx","password":"xxxxxxxx","uuid":"xxxxxxxxx","status":0}
2、
Content-Type: application/x-www-form-urlencoded;charset=UTF-8
这里表示数据是按照表单提交的数据格式组织的,并指定里数据的字符集为UTF-8
此时的body格式和 query string 格式相同,形如:
username=tz&password=xxxxxxx&uuid=xxxxxxx&status=0
(4)User-Agent (简称 UA):表示浏览器/操作系统的属性
下面是我使用本机访问百度时的UA:

早期,由于同一时期的浏览器种类繁多,功能参差不齐,UA可以在请求中告诉服务器,当前的客户端种类,服务器可以根据客户端种类推送不同的页面。随着时间的推移,浏览器之间的差异越来越小,UA存在的价值也就大打折扣了。虽然它还可以用来区分用户使用的是手机、平板还是PC,但是“响应式布局”相比之下是一种更好的方案。
(5)Referer:表示这个页面是从哪个页面跳转过来的。
下面是我在百度主页访问百度贴吧时的抓包情况:
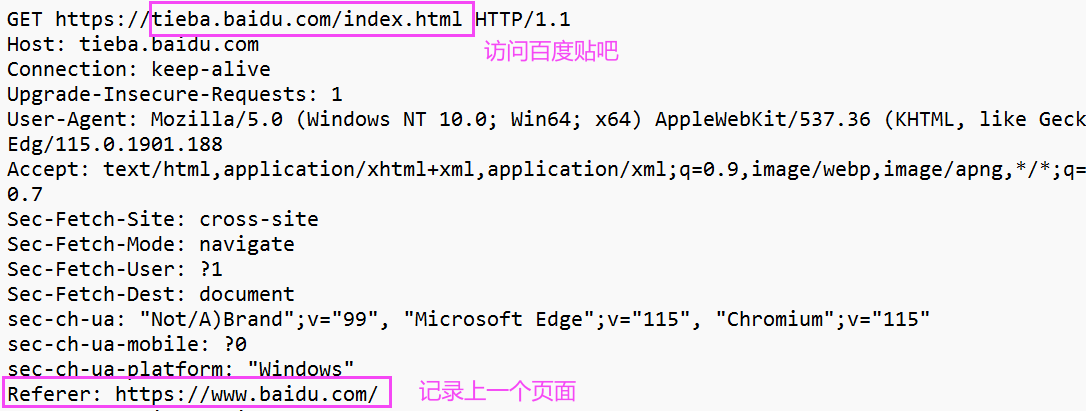
注意: 如果直接在浏览器中输入URL,或者直接通过收藏夹访问页面时是没有 Referer 的。(属于直接访问,没有经过跳转)
(6)Cookie 机制(重点)

上面是一段 Cookie 信息,虽然看起来“有亿点”扎眼,但也可以看的出 Cookie 也是由键值对组成,键和值之间使用= 分割,键值对之间使用;分割。至于这里的键值对都是程序眼自定义的数据,不同的网站有不同的键值对,也就有不同的含义和用途。
Cookie机制:是浏览器在本地存储用户自定义数据的一种关键机制。
浏览器自身也是要存储一些数据的,比如最典型的就是用户的身份信息。但是为了保证用户的上网安全,浏览器会禁止网页能够直接访问硬盘。因此引出了Cookie机制,允许网页通过浏览器提供的 API ,写入特定的文件中。
每个网站都存有自己的Cookie,Cookie是按照域名为维度进行存储的,通常同一个网站的主页、结果页、等子页面共享同一份Cookie。不同的网站则是各自享有各自的Cookie。
Cookie从哪里来?
Cookie从服务器来。当用户首次访问一个网站时,网站的服务器会在响应中包含一个Set-Cookie头部,该头部包含了一条或多条Cookie信息。浏览器接收到这些Cookie信息后,会使用Cookie机制,将其保存在用户的计算机或移动设备上。
Cookie到哪里去?
Cookie在浏览器只是暂存,真正发挥作用得由服务器来使用。当用户在浏览器中发起新的请求访问同一网站时,浏览器会自动将该网站关联的Cookie信息添加到请求的Cookie头部中,并发送给服务器。这样,服务器就能够根据Cookie中的信息对用户进行个性化处理。
Cookie有什么用?
Cookie是本地浏览器存储数据的机制。最典型的应用就是存储当前用户登录的身份标识,也称为令牌(token)。当然它存储的也不一定是身份标识信息,可以存储任何字符串数据。(Cookie存储空间有限,一般只有几k,所以不会存储较大的数据)
3、正文Body
正文中的内容格式和 header 中的 Content-Type 密切相关,这里就不过多赘述了,大家可以多抓包熟悉一下。
三、HTTP响应详解
对于HTTP响应来说,它的报文格式的绝大多数属性都和HTTP请求相同,下面我就秉承着“求同存异”的原则向大家介绍:
1、状态码与状态码描述

状态码:表示访问一个页面的结果。由三位数字组成,分为不同的类别,每个类别有特定的含义。
状态码描述:是对状态码的文字描述,用于更直观地说明该状态码所表示的含义。
但是对于HTTP提供的状态码种类是非常繁多的,我们这里不可能一一介绍,下面是几个常见的状态码及描述:
| 状态码 | 描述 | 含义 |
|---|---|---|
| 200 | OK | 请求成功 |
| 404 | Not Found | 要访问的资源不存在 |
| 403 | Forbidden | 访问被拒绝(没有权限) |
| 500 | Internal Server Error | 服务器内部错误 |
| 504 | Gateway Timeout | 服务器访问超时(服务器迟迟未响应) |
| 301 | Moved Permanently | 临时重定向 |
| 302 | Moved Temporarily (Found) | 永久重定向 |
关于重定向: 重定向就是访问旧的地址,被自动引导到新的地址上。
虽然HTTP提供的状态码繁多,但我们可以根据状态码共性进行划分:
| 状态码 | 类别 | 含义 |
|---|---|---|
| 1XX | Informational | 接收的请求正在处理 |
| 2XX | Success | 请求正常处理完毕 |
| 3XX | Redirection | 需要进行附加操作以完成请求 |
| 4XX | Client Error | 服务器无法处理请求 |
| 5XX | Server Error | 服务器处理请求出错 |
2、怎样构造HTTP请求?
这里介绍 五种 常用的HTTP请求构造方式:
(1)直接在浏览器地址栏输入URL构造出一个GET请求。
(2)HTML中的一些特殊标签也会触发GET请求。例如link、script、img、a
(3)使用 form表单 可以触发GET和POST请求。
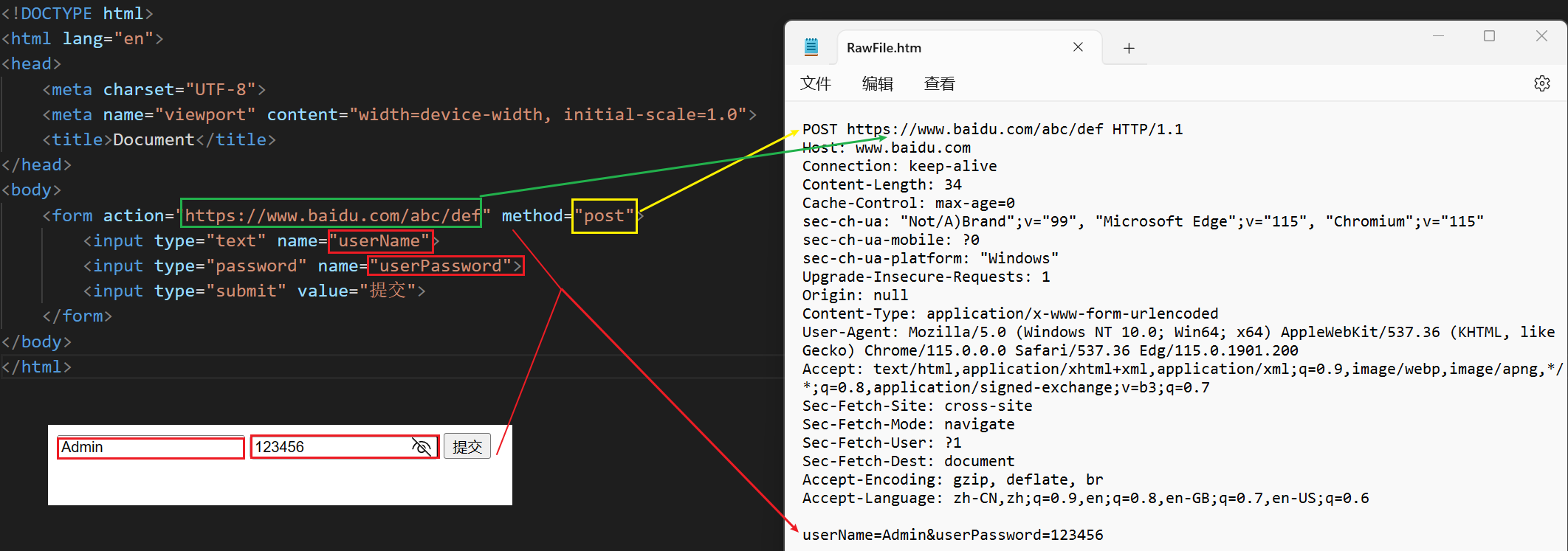
action:构造的 HTTP 请求的 URL 是什么.method:构造的 HTTP 请求的 方法 是 GET 还是 POST (form 只支持 GET 和 POST)
(4)使用AJAX可以构造任意HTTP请求。
AJAX 全称 Asynchronous JavaScript and XML 是一种用于在网页上进行异步数据交互的技术,也是目前最主流的前后端交互方式。
关于同步和异步我们可以这样理解:同步就是请求的发起者亲自拿到请求的结果;异步就是请求的发起者并不关心结果,当被请求的这一方计算出结果后,把结果推送给发起者。所以此时理解同步和异步,关键是看,结果是自己取还是别人送。
使用AJAX构造HTTP请求:
由于 JS 提供的原生 AJAX API 很难用,这里我们使用 jQuery 中提供的 AJAX API 进行操作:
$.ajax({url:"https://www.baidu.com",// http请求中的urltype:"post",// 请求的方法,还可以是get、put、delete等contentType:"text/plain",// body的数据类型,可以是application/json等// 这是一个处理响应的回调函数success: function(body) {// 处理响应的代码console.log(body);}});
上述过程中的回调函数会在服务器返回一个正确的响应的时候自动执行,这个过程就是“异步”的。
具体来说,在页面的JS中,把请求发送出去后就可以继续执行后续的代码了,直到正确的响应回来之后,浏览器会把这个响应给success回调函数,执行并处理响应的逻辑。
相比之下,ajax的功能更加丰富,但是也存在一个非常重要的问题——跨域问题。
如果我们直接在本地执行上述代码,浏览器会报错:

虽然报错了,但这并不是代码的bug,而是浏览器引入的一种保护机制,为了防止a网站的页面请求b网站的数据。
此时运行的AJAX代码运行的页面的域名是null(因为是本地的HTML文件)请求的目标域名是www.baidu.com,当前二者域名不同,即使服务器返回响应,浏览器还是不能处理。
(5)使用现成工具构造HTTP请求,如Postman。
这种现成的工具有很多,大家可以根据自己的口味,自行选择,这里就不在过多介绍了。
相关文章:
应用层协议 HTTP
一、应用层协议 我们已经学过 TCP/IP , 已然知道数据能从客户端进程经过路径选择跨网络传送到服务器端进程。 我们还需要知道的是,我们把数据从 A 端传送到 B 端, TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用…...

Springboot+vue的应急救援物资管理系统,Javaee项目,springboot vue前后端分离项目。
演示视频: Springbootvue的应急救援物资管理系统,Javaee项目,springboot vue前后端分离项目。 项目介绍: 本文设计了一个基于Springbootvue的前后端分离的应急救援物资管理系统,采用M(model)V&…...

创建properties资源文件,并由spring组件类获取资源文件
1.1 创建资源文件file-upload-dev.properties #文件上传地址 file.imageUserFaceLocation=/workspaces/images/foodie/faces #图片访问地址 file.imageServerUrl=http://localhost:8088/foodie/faces1.2 创建spring组件获取资源文件类FileUpload import org.springframework.…...

你知道npm、yarn、pnpm的区别吗?
npm 嵌套的 node_modules 结构 npm 在早期采用的是嵌套的 node_modules 结构,“node_modules” 文件夹通常包含项目依赖的模块。在项目中使用多个依赖并且这些依赖本身也有它们自己的依赖时,就会出现嵌套的 “node_modules” 结构。 嵌套的 “node_mo…...
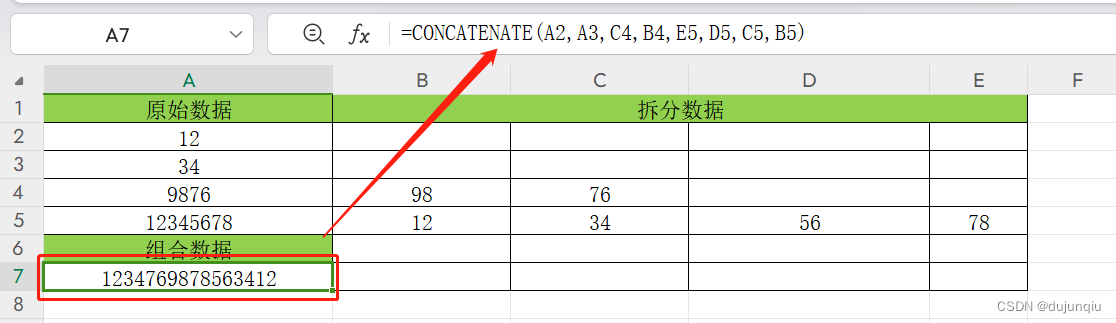
利用excel表格进行分包和组包
实际使用中,我们可能希望修改某几个数据之后,最终的数据包能够自动发动数据,类似于在给结构体变量修改数据,自动生成完整的结构体; excel语法 1:拆分数据 LEFT(A4,2) – 取A4单元格左边的两个数据 RIGHT(A4…...

Go 语言切片扩容规则是扩容2倍?1.25倍?到底几倍
本次主要来聊聊关于切片的扩容是如何扩的,还请大佬们不吝赐教 切片,相信大家用了 Go 语言那么久这这种数据类型并不陌生,但是平日里聊到关于切片是如何扩容的,很多人可能会张口就来,切片扩容的时候,如果老…...

突破封锁|华为芯片10年进化史:从K3V1到麒麟9000S
华为海思麒麟芯片过去10年研发历程回顾如下: 2009年:华为推出第一款手机芯片K3V1,采用65nm工艺制程,基于ARM11架构,主频600MHz,支持WCDMA/GSM双模网络。这款芯片搭载在华为U8800手机上,标志着华…...

vue建项目
vue3 create-vue 建vue3项目 vscode里改点东西,首先vetur禁用,这个是vue2的,下volar pinia持久化插件:npm i pinia-plugin-persistedstate 配eslint、prettier 在.eslintrc.cjs里配 rules: {// prettier专注于代码的美观度 (格…...

天龙八部服务端Public目录功能讲解
PublicDataAIScript文件夹中 script(0~210).ai怪物AI脚本设定如是否主动攻击是否使用技能 PublicDataScript文件夹中 eventbossgroupbg_BossAI_CreateMonster.lua 是BOSS群 刷小怪通用脚本 PublicDataScript文件夹中 eventbossgroupbg_CangShan.lua 苍山 BOSS群刷新脚本 Public…...

好用的Java工具类库—— Hutool
目录 一、简介 1、介绍 2、Hutool名称的由来 3、Hutool如何改变我们的coding方式 4、包含组件(核心) 5、官方文档 二、安装与使用 1、引入 import方式 exclude方式 2、安装(POM) 三、使用 1、DateUtil 2、StrUtil 3、NumberUtil 4、MapU…...
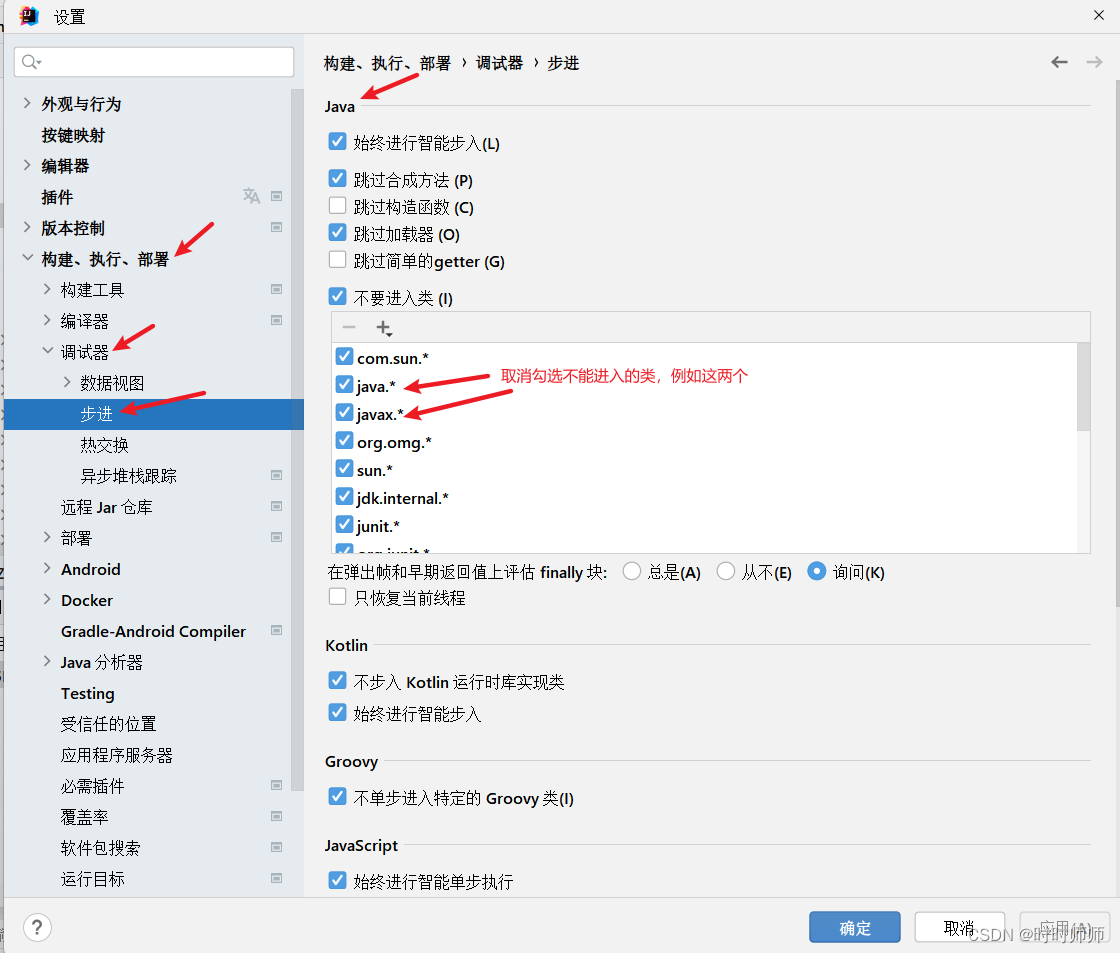
IDEA的使用(三)Debug(断点调试)(IntelliJ IDEA 2022.1.3版本)
编程过程中如果出现错误,需要查找和定位错误时,借助程序调试可以快速查找错误。 编写好程序后,可能出现的情况: 1.没有bug。 使用Debug的情况: 2.运行后,出现错误或者异常信息,但是通过日志文件…...

285_C++_web提取AI告警信息JSON格式
struct Cache_t {AIAlarmFaceInfo Face;AIAlarmPlateInfo Plate;SAISnapedObjInfo Object;SharedCArray Common;int Type; };struct Client_t {Client_t() : AlarmCnt(HA...
处(位于 xxx.exe 中)引发的异常: 0xC0000005: 读取位置 XXXXXXXX 时发生访问冲突)
(Qt5Gui.dll)处(位于 xxx.exe 中)引发的异常: 0xC0000005: 读取位置 XXXXXXXX 时发生访问冲突
最新在处理opencv的时候遇到(Qt5Gui.dll)处(位于 xxx.exe 中)引发的异常: 0xC0000005: 读取位置 XXXXXXXX 时发生访问冲突,导致上位机崩溃严重影响开发的效率。 简要代码: void show() { QImage img QImage(data,width,height,bytePerLine,QImage::For…...
AI:11-基于深度学习的鱼类识别
当今,人工智能和深度学习已经成为许多领域的关键技术。在生态学和环境保护领域,鱼类识别是一项重要的任务,因为准确识别和监测鱼类种群对于保护水生生物多样性和可持续渔业管理至关重要。基于深度学习的鱼类识别系统能够自动识别和分类不同种类的鱼类,为生态学研究和渔业管…...
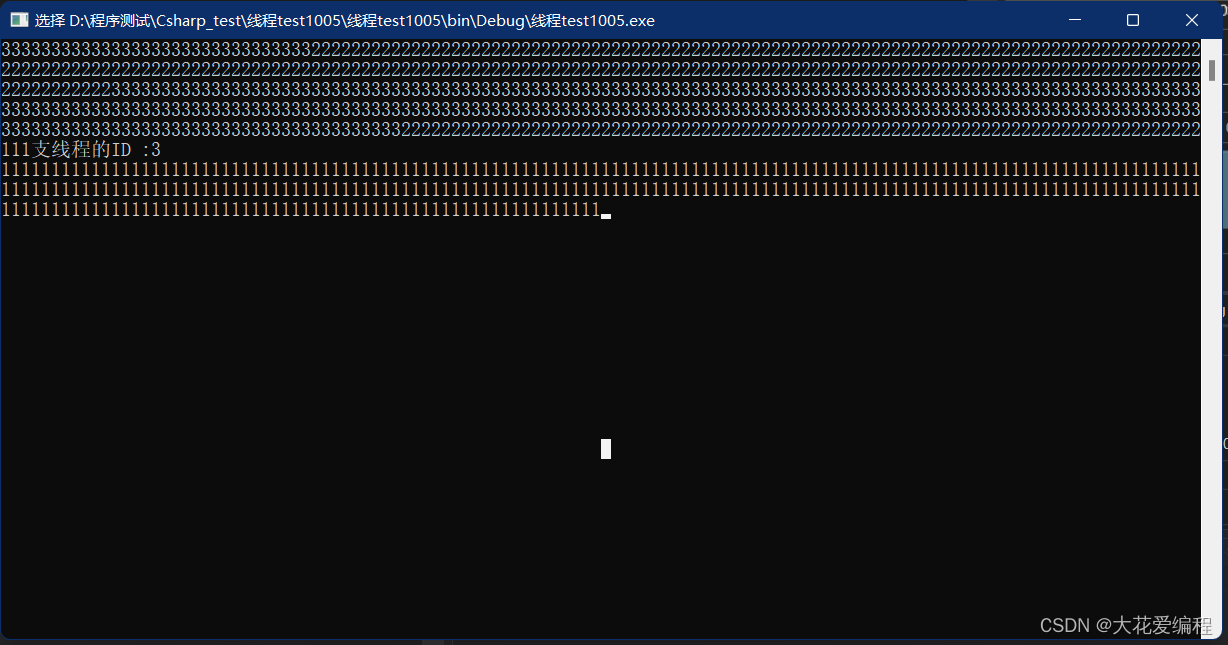
c#学习系列相关之多线程(三)----invoke和begininvoke
一、invoke和BeginInvoke的作用 invoke和begininvoke方法的初衷是为了解决在某个非某个控件创建的线程中刷新该控件可能会引发异常的问题。说的可能比较拗口,举个例子:主线程中存在一个文本控件,在一个子线程中要改变该文本的值,此…...

如何使用 ONLYOFFICE API 转换办公文档格式
作者:天哥 上一期我们介绍了 ONLYOFFICE 的文档生成器API接口函数库。这一期我们继续介绍ONLYOFFICE 的文件转换API接口函数库。 为什么要使用 ONLYOFFICE 转换API ONLYOFFICE 转换 API 有助于转换大部分类型的Office文档:文本、表格、幻灯片、表单、P…...
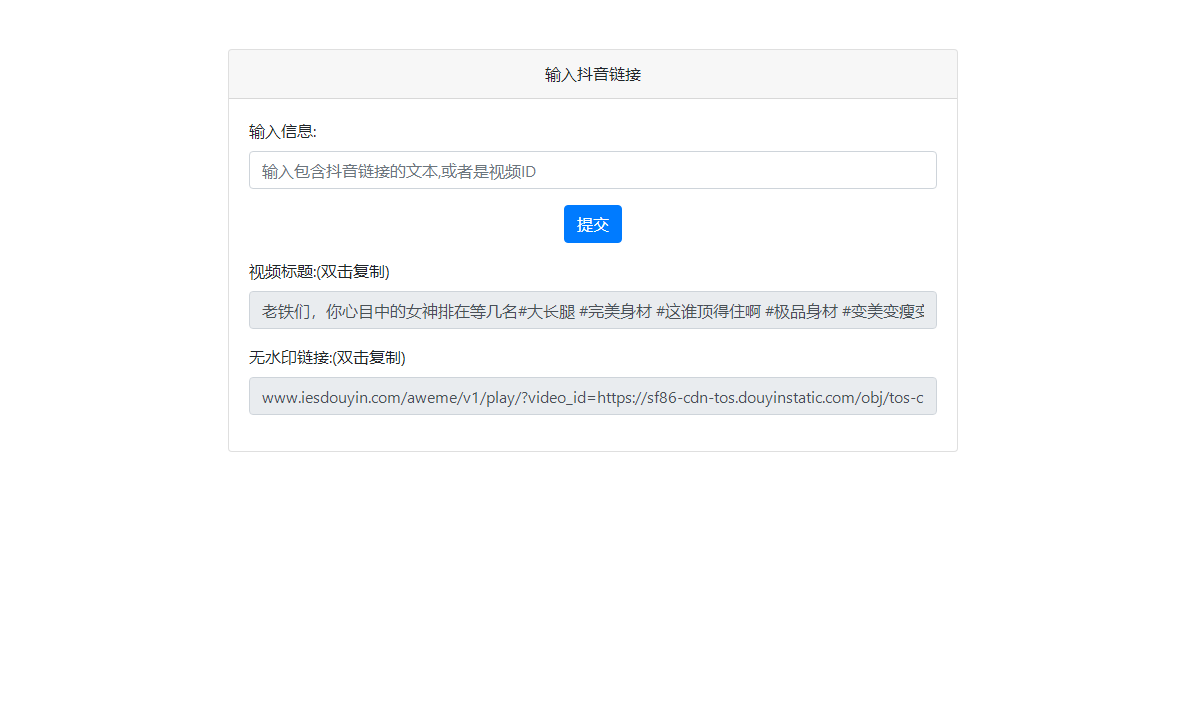
最新抖音去水印PHP源码 非第三方接口
简介: 最新抖音去水印PHP源码 非第三方接口 源码全开源 视频解析接口来自官方抖音视频接口!非第三方接口!上传PHP环境中即可运行!支持上传二级目录访问! 访问你的域名地址/douyin.php douyin.php(此文件可以自行重新命名) 支持带有文本的链接和视频ID或者分享的…...

MYSQL 高级SQL语句(二)
表连接查询 MYSQL数据库中的三种连接: inner join(内连接):只返回两个表中联结字段相等的行(有交集的值)left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录right join(右连接):返回…...

本地计算机端口显示CLOSE_WAIT、TIME_WAIT、ESTABLISHED、三种情况的区别
本地计算机端口显示 “CLOSE_WAIT”、“TIME_WAIT” 和 “ESTABLISHED” 表示不同的TCP连接状态,它们之间的区别如下: CLOSE_WAIT(关闭等待): 在此状态下,本地计算机已经接收到来自远程计算机的关闭请求&am…...

粘性文本整页滚动效果
效果展示 CSS 知识点 background 相关属性综合运用position 属性的 sticky 值运用scroll-behavior 属性运用scroll-snap-type 属性运用scroll-snap-align 属性运用 整体页面效果实现 <div class"container"><!-- 第一屏 --><div class"sec&qu…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

如何高效实现前端文件下载:FileSaver.js完整实用指南
如何高效实现前端文件下载:FileSaver.js完整实用指南 【免费下载链接】FileSaver.js An HTML5 saveAs() FileSaver implementation 项目地址: https://gitcode.com/gh_mirrors/fi/FileSaver.js FileSaver.js是一款轻量级的HTML5文件保存解决方案,…...