[MySQL]基础篇
文章目录
- 1. MySQL基本使用
- 1.1 MySQL的启动和登录
- 1.1.1 MySQL的启动
- 1.1.2 MySQL的客户端连接
- 1.2 数据模型
- 2. SQL
- 2.1 SQL类型
- 2.1.1 数值类型
- 2.1.2 字符串类型
- 2.1.3 日期类型
- 2.2 DDL
- 2.2.1 数据库操作
- 2.2.2 表操作 - 查询
- 2.2.3 表操作 - 创建表
- 2.2.4 表操作 - 修改
- 2.3 DML
- 2.3.1 添加数据
- 2.3.2 修改数据
- 2.3.3 删除数据
- 2.4 DQL
- 2.4.1 基本查询
- 2.4.2 条件查询
- 2.4.3 聚合函数
- 2.4.4 分组查询
- 2.4.5 排序查询
- 2.4.6 分页查询
- 2.4.7 执行顺序
- 2.5 DCL
- 2.5.1 管理用户
- 2.5.2 权限控制
- 3. 函数
- 3.1 字符串函数
- 3.2 数值函数
- 3.3 日期函数
- 3.4 流程控制函数
- 4. 约束
- 4.1 概念
- 4.2 案例
- 4.3 外键约束
- 5. 多表查询
- 5.1 连接查询
- 5.1.1 内连接
- 5.1.2 外连接
- 5.1.3 自连接
- 5.2 联合查询
- 5.3 子查询
- 5.3.1 标量子查询
- 5.3.2 列子查询
- 5.3.3 行子查询
- 5.3.4 表子查询
- 5.4 多表查询案例
- 6. 事务
- 6.1 事务的基本操作
- 6.2 并发事务问题
- 6.3 事务的隔离级别
1. MySQL基本使用
1.1 MySQL的启动和登录
1.1.1 MySQL的启动
1. 管理员身份打开cmd
net start mysql80 ##启动MySQL
net stop mysql80 ##关闭MySQL
1.1.2 MySQL的客户端连接
1. 管理员身份打开cmd
mysql [-h 127.0.0.1] [-P 3306] -u root -p
使用这种方法需要配置环境变量,MySQL的bin目录
2. 打开mysql命令行客户端,输入密码以打开
1.2 数据模型
关系型数据库 (RDBMS)
- 概念 : 建立在关系模型基础上,由多张相互连接的二维表组成的数据库
- 特点 :
- 使用表存储数据,格式同意,便于维护
- 使用SQL语言操作,标准统一,使用方便
2. SQL
SQL通用语法
- SQL语句可以单行或多行书写,
以分号结尾- SQL依据可以使用空格/TAB增强可读
- MySQL数据库的SQL语句
不区分大小写,关键字建议大写- 注释:
- 单行注释 : --注释内容 / # 注释内容(MySQL特有)
- 多行注释: /*注释内容*/
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
如果您需要其他格式或有其他问题,请随时告诉我。
2.1 SQL类型
2.1.1 数值类型
| 类型 | 大小 | 有符号范围 | 无符号范围 | 描述 |
|---|---|---|---|---|
| tinyint | 1 byte | (-128,127) | (0, 255) | 小整数值 |
| smallint | 2 bytes | (-32768,32767) | (0, 65535) | 大整数值 |
| mediumint | 3 bytes | (-8388608,8388607) | (0, 16777215) | 大整数值 |
| int/integer | 4 bytes | (-2147483648,2147483647) | (0, 4294967295) | 大整数值 |
| bigint | 8 bytes | (-263,263-1) | (0, 2^64-1) | 极大整数值 |
| float | 4 bytes | (-3.402823466 E+38,3.402823466351 E+38) | (0, 3.402823466 E+38) | 单精度浮点数值 |
| double | 8 bytes | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | (0, 1.7976931348623157 E+308) | 双精度浮点数值 |
| decimal | 依赖于M和D的值 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值(精确定点数) |
ps :
- decimal : 123.45 精度(M)为5,标度(D)为2
- 无符号类型写法: tinyint unsigned
double(4,1)
4代表整体长度,1代表小数点后的位数
2.1.2 字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0-255 bytes | 定长字符串 |
| varchar | 0-65535 bytes | 变长字符串 |
| tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 |
| tinytext | 0-255 bytes | 短文本字符串 |
| blob | 0-65,535 bytes | 二进制形式的长文本数据 |
| text | 0-65,535 bytes | 长文本数据 |
| mediumblob | 0-16,777,215 bytes | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16,777,215 bytes | 中等长度文本数据 |
| longblob | 0-4,294,967,295 bytes | 二进制形式的极大文本数据 |
| longtext | 0-4,294,967,295 bytes | 极大文本数据 |
ps :
- char性能优与varchar
变长是指,在不超过最大容量时,1就是1,2就是2
定长是指,哪怕是1,也要占用最大容量
2.1.3 日期类型
| 类型 | 大小 | 范围 | 格式 |
|---|---|---|---|
| date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD |
| time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS |
| year | 1 | 1901 至 2155 | YYYY |
| datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS |
| timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS |
2.2 DDL
2.2.1 数据库操作
#查询
show databases; # 查询所有数据库
select database(); #查询当前数据库#创建
create database [if not exists] 数据库名 [default charset 字符集] [collate 排序规则];#eg:
creat datebase if not exists emp default charset utf8mb4;#删除
drop database [if exists] 数据库名;#使用
use 数据库名
MySQL里实现的utf8最长使用3个字节,utf8mb4 是 utf8 的超集并完全兼容utf8,能够用四个字节存储更多的字符。
比如:最常见的就算现在手机端常用的表情字符 emoji和一些不常用的汉字,如 “墅” ,这些需要四个字节才能编码出来。
2.2.2 表操作 - 查询
show tables; # 查询当前数据库的所有表desc 表名; # 查询表结构show create table 表名; # 查询指定表的建表语句
2.2.3 表操作 - 创建表
语法:
create table 表名(字段1 字段1的类型 [comment '注释内容'], #逗号...字段2 字段2的类型 [comment '注释内容'])
eg:创建一个如下表
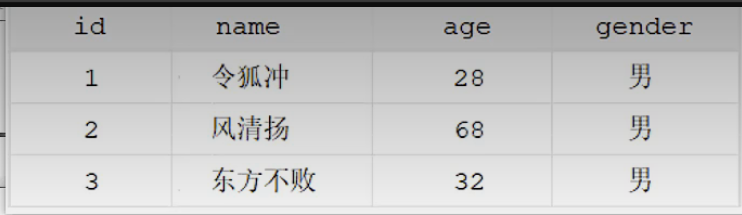
create table tb_user(id int comment '编号',name varchar(50) comment '名字',age int comment '年龄',gender char(1) comment '性别',)comment '用户表';
eg: 根据需求创建表
员工信息表,要求:
- 编号(纯数字)
- 员工工号(字符串类型,长度不超过10位)
- 员工姓名(字符串类型,长度不超过10位)
- 性别
- 年龄
- 身份证号
- 入职时间(取值年月日即可)
create table emp(id int comment'编号',worknum varchar(10),name varchar(10),gender char(1),age tinyint unsigned,idcard char(18),entrydate date)
2.2.4 表操作 - 修改
#添加字段
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]; #添加字段#eg : 为emp表增加一个新的字段 "昵称" 为nickname,类型为varchar(20)
alter table emp add nickname varchar(20) comment '昵称';#修改字段
alter table 表名 modify 字段名 新数据类型(长度) # 修改数据类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束]; #修改字段名和字段类型#eg : 将emp表的nickname字段修改为username,类型为varchar(30)
alter table emp change nickname username varchar(30) comment'昵称';#删除字段
alter table 表名 drop 字段名;#eg : 将emp表的字段username删除
alter table emp drop username;#修改表名
alter table 表名 rename to 新表名;#eg : 将emp表的表名修改为employee
alter table emp rename to employee;#删除表
drop table [if exists] 表名;
truncate table 表名; ##删除指定表,并重新创建该表
2.3 DML
2.3.1 添加数据
insert into 表名(字段名1,字段名2,...) values(值1,值2,...); #给指定字段添加数据
#eg:
insert into emp(id,worknum,name,gender,age) values(1,'1','9tse','男',19);insert into 表名 values(值1,值2,...); #给全部字段添加数据
#eg:
insert into emp values(2,'2','sewerperson','男',20);insert into 表名(字段名1,字段名2,...) values(值1,值2,...),(值1,值2,...)...;
insert into 表名 values(值1,值2,...),(值1,值2,...)...;
#eg:
insert into emp values(1,'1','9tse','男',19),(2,'2','sewerperson','男',20);
ps:
- 插入数据时,指定的字段顺序需要与值的顺序对应
- 字符串和日期数据应该包含在引号中
- 插入数据大小,应在字段的规定范围内
2.3.2 修改数据
update 表名 set 字段名1 = 值1,字段名2 = 值2,... [where 条件];#eg: 修改id为1的数据,将name修改为9tse
update emp set name = '9tse' where id = 1;
# 修改id为1的数据,将name修改为 sewer,gender修改为 女
update emp set name = 'sewer',gender = '女' where id = 1;
# 将所有员工的入职日期修改为2008-01-01
update emp set entrydate = '2008-01-01';
ps:
- 修改语句的条件如果没有,默认修改整张表的所有数据
2.3.3 删除数据
delete from 表名 [where 条件];
#eg:删除gender为女的员工
delete from emp where gender = '女';
# 删除所有员工
delete from emp;
ps:
- delete语句的条件如果没有,默认作用于整张表的所有数据
- delete语句不能删除某一个字段的值(可以使用update)
2.4 DQL
语法:
select字段列表
from表名列表
where条件列表
group by分组字段列表
having分组后条件判断
order by排序字段列表
limit分页参数
- 基本查询
- 条件查询(where)
- 聚合函数(count,max,min,avg,sum)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
2.4.1 基本查询
#查询多个字段
select 字段1,字段2,字段3,... from 表名;
select * from 表名; #效率较低#设置别名
select 字段1[as] 别名1,字段2[as] 别名2 ... from 表名;#去除重复记录
select distinct 字段列表 from 表名;
eg:
#查询指定字段返回
select name,worknum,age from emp; #查询所有字段返回
select id,worknum,name,gender,age;
select * from emp; #尽量不写*,影响效率#查询所有员工工作地址,起别名
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp;#查询工作员工的上班地址(不要重复)
select distinct workaddress '工作地址' from emp;
2.4.2 条件查询
语法:
select 字段列表 from 表名 where 条件列表;
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between…and… | 在某范围内(含最小,最大) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单字符,%匹配任意个字符) |
| is null | 是NULL |
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非不是 |
eg:
#查询年龄等于88的员工
select * from emp where age = 88;#小于20
select * from emp where age < 20;#查询没有身份证号的员工
select * from emp where idcard is null;#有身份证号的员工
select * from emp where idcard is not null;#年龄在15到20(包含)的员工
select * from emp where age >= 15 && age <= 20;
select * from emp where age between 15 and 20;# 性别女且小于25
select * from emp where gender = '女' and age < 25;#18 20 40 的
select * from emp where age = 18 || age = 20 || age = 40;
select * from emp where age in(18,20,40);#名字是两个字的
select * from emp where name like '__';#身份证号最后一位为X的
select from emp where idcard like '%X';
2.4.3 聚合函数
介绍: 将一列数据作为一个整体,进行纵向计算
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
语法
select 聚合函数(字段列表) from 表名;
ps : null值不参与聚合函数的运算
#统计员工数量
select count(*) from emp;
select count(idcard) from emp;#统计平均年龄
select avg(age) from emp;#最大年龄
select max(age) from emp;#最小
select min(age) from emp;#西安地区员工年龄之和
select sum(age) from emp where workaddress = '西安';
2.4.4 分组查询
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
where和having的区别
- 执行实际不同:
where是分组之前进行过滤,不满足where条件,不参与分组;
having是分组后对结果进行过滤- 判断条件不同
where不能对聚合函数进行判断
having可以执行顺序 : where > 聚合函数 > having
分组后,查询的字段一般为聚合函数和分组字段,查询其他字段无意义
#根据性别分组,统计男性员工和女性员工的数量
select gender,count(*) from emp group by gender;#根据性别分组,统计男女平均年龄
select gender,avg(age) from emp group by gender;#查询年龄小于45,根据工作地址分组,获取员工数量大于3的工作地址
select workaddress,count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3;
2.4.5 排序查询
语法
select 字段列表 from 表名 group by 字段1 排序方式1, 字段2 排序方式2;
排序方式:
- asc : 升序(默认值)
- desc : 降序
ps: 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序;
eg:
#根据年龄升序
select * from emp order by age asc;
select * from emp order by age;#入职时间降序
select * from emp order by entrydate desc;#年龄升序,相同则入职时间降序
select * from emp order by age asc , entrydate desc;
2.4.6 分页查询
语法
select 字段列表 from 表名 limit 起始索引,查询记录数;
ps:
- 起始索引从0开始,
起始索引 = (查询页码-1) * 每页显示记录数 - 分页查询时数据库方言,不同数据库由不同的实现,MySQL时limit
- 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10
eg:
#查询第一页员工数据,每页10条
select * from emp limit 0,10;
select * from emp limit 10;#查询第二页,每页10
select * from emp limit 10,10;#查询年龄为20,21,22,23岁的女性员工信息。
select * from emp where gender ='女' and age in(20,21,22,23);#查询性别为 男 ,并且年龄在 20-40 岁(含)以内的姓名为三个字的员工。
select * from emp where gender = '男' and ( age between 20 and 40 ) and name like '___';#统计员工表中,年龄小于60岁的 ,男性员工和女性员工的人数。
select gender,count(*) from emp where age < 60 group by gender;#查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序
select name , age from emp where age <= 35 order by age asc , entrydate desc;#查询男,20-40 岁(含)以内的前5个员工信息 按年龄升序,相同按入职时间升序排序。
select * from emp where gender = '男' and age between 20 and 40 order by age asc , entrydate asc limit 5 ;
2.4.7 执行顺序
#查询年龄大于15的员工的姓名、年龄,并根据年龄进行升序排序
#通过设置别名和使用别名的方法进行验证
select e.name ename , e.age eage from emp e where e.age > 15 order by age asc;
#编写顺序
select字段列表
from表名列表
where条件列表
group by分组字段列表
having分组后条件判断
order by排序字段列表
limit分页参数
#执行顺序,selec跑到having后
from表名列表
where条件列表
group by分组字段列表
having分组后条件判断
select字段列表
order by排序字段列表
limit分页参数
2.5 DCL
2.5.1 管理用户
语法
#查询用户
use mysql;
select * from user;#创建用户
create user '用户名'@'主机名' identified by '密码';#修改用户密码
alter user '用户名'@'主机名' identified with mysal_native_password by '新密码';#删除用户
drop user '用户名'@'主机名'
ps :
- 主机名可以使用 % 通配
使用这类SQL开发人员操作的比较少,主要是DBA (Database Administrator数据库管理员)
eg:
#创建用户 9tse ,只能够在当前主机Localhost访间,密码123456;
create user '9tse'@'localhost' identified by '123456':#创建用户 sewer ,可以在任意主机访问该数据库,密码123456 ;
create user 'sewer'@'%' identified by '123456';#修改用户 9tse 的访问密码为 1234 ;
alter user '9tse'@'%' identified with mysql_native_password by '1234';#删除9tse@localhost用户
drop user'9tse'@'localhost'
2.5.2 权限控制
常用权限如下
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
语法
#查询权限
show grants for '用户名'@'主机名';#授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';#撤销权限
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
ps:
- 多个授权之间逗号隔开
- 授权时,数据库名和表名可以用通配符*表示所有;
eg:
-- 查询权限
show grants for '9tse'@'%';-- 授予权限
grant all on sewerperson.* to '9tse'@'%';-- 撤销权限
revoke all on sewerperson.* from '9tse'@'%';
3. 函数
3.1 字符串函数
| 函数 | 功能 |
|---|---|
| concat(s1, s2, … sn) | 字符串拼接,将s1,s2,… sn拼接成一个字符串 |
| lower(str) | 将字符串str全部转为小写 |
| upper(str) | 将字符串str全部转为大写 |
| lpad(str, n, pad) | 左填充,用字符串pad对str的左边进行填充,达到n个字符串长度 |
| rpad(str, n, pad) | 右填充,用字符串pad对str的右边进行填充,达到n个字符串长度 |
| trim(str) | 去掉字符串头部和尾部的空格 |
| substring(str, start, len) | 返回从字符串str从start位置起的len个长度的字符串 |
字符串函数的基本使用
-- concat
select concat('Hello''MysQL');-- Tower
select lower('Hello'):-- upper
select upper('Hello');-- lpad
select Lpad('01',5,'-'); # ---01-- rpad
select rpad('01',5,'-');-- trim
select trim(' HelloMysQL');-- substring
select substring('Hello MySL',1,5); # Hello
案例
-- 业务需求变更,员工的工号统一5位数,不足5位数的全部在前面补0。比如: 1号员工的工号应该为00001.
update emp set workno = lpad(workno,5,'0');
3.2 数值函数
| 函数 | 功能 |
|---|---|
| ceil(x) | 向上取整 |
| floor(x) | 向下取整 |
| mod(x; y) | 返回 x/y 的模 |
| rand() | 返回 0~1 内的随机数 |
| round(x; y) | 求参数 x 的四舍五入的值,保留 y 位小数 |
数值函数的基本利用
-- ceil
select ceil(1.1):-- floor
select floor(1.9);-- mod
select mod(7,4);-- rand
select rand();- round
select round(2.344,2);
案例
-- 案例:通过数据库的函数,生成一个六位数的随机验证码。select
lpad(round(rand()*1000000, 0), 6, '0');
3.3 日期函数
| 函数 | 功能 |
|---|---|
| curdate() | 返回当前日期 |
| curtime() | 返回当前时间 |
| now() | 返回当前日期和时间 |
| year(date) | 获取指定 date 的年份 |
| month(date) | 获取指定 date 的月份 |
| day(date) | 获取指定 date 的日期 |
| date_add(date, interval expr type) | 返回一个日期/时间值加上一个时间间隔 expr 后的时间值 |
| datediff(date1, date2) | 返回起始时间 date1 和结束时间 date2 之间的天数 |
日期函数的基本使用
-- curtime()
select curtime();-- now()
select now();-- YEAR,MONTH,DAY
select YEAR(now());
select MONTH(now());
select DAY(now()); -- date_add
select date_add(now(), interval 70 year); -- datediff
select datediff('2021-10-01', '2021-12-01');
案例
-- 案例:查询所有员工的入职天数,并根据入职天数倒序排序。
select name, datediff(curdate(), entrydate) as 'entrydays' from emp order by entrydays desc;
3.4 流程控制函数
| 函数 | 功能 |
|---|---|
| if(value , t, f) | 如果 value 为 true,则返回 t,否则返回 f |
| ifnull(value1, value2) | 如果 value1 不为空,返回 value1,否则返回 value2 |
| case when [val1] then [res1] … else [default] end | 如果 val1 为 true,则返回 res1,… 否则返回 default 默认值 |
| case [expr] when [val1] then [res1] … else [default] end | 如果 expr 的值等于 val1,则返回 res1,… 否则返回 default 默认值 |
流程控制函数的基本使用
--if
select if(false, '0k', 'Error'); -- ifnull
select ifnull('0k','Default');
select ifnull('','Default');
select ifnull(null,'Default');
案例
-- case when then elserend-- 需求:查询emp表的员工姓名和工作地址(北京/上海————>一线城市,其他————>二线城市)
selectname,(case workaddress when '北京' then '一线城市' when'上海' then '一线城市' else '二线城市'end)as'工作地址'
from emp;
--案例: 统计班级各个学员的成绩,展示的规则如下:
-->= 85,展示松秀
-->= 60,展示及格
--否则,展示不及格selectid,name,(case when math >= 85 then '优秀' when math >=60 then '及格' else '不及格' end)'数学',(case when english >= 85 then '优秀' when english >=60 then '及格' else '不及格' end)'英语',(case when chinese >= 85 then '优秀' when chinese >=60 then '及格' else '不及格' end)'语文',
from score;
4. 约束
4.1 概念
概念 : 约束时作用于表中字段上的规则,用于限制存储在表中的数据
目的 : 保证数据库中数据的正确,有效性和完整性
注意: 约束时作用于表中的字段上的,可以在创建表/修改表的时候添加约束.
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为 null | not null |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | default |
| 检查约束 | 检查约束 (8.0.16 版本之后) 保证字段值满足某一个条件 | check |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | foreign key |
4.2 案例
建表要求:
| 字段名 | 字段含义 | 字段类型 | 约束条件 | 约束关键字 |
|---|---|---|---|---|
| id | ID唯一标识 | int | 主键,并且自动增长 | primary key auto increment |
| name | 姓名 | varchar(10) | 不为空,并且唯一 | not null, unique |
| age | 年龄 | int | 大于0,并且小于等于120 | check (age > 0 and age <= 120) |
| status | 状态 | char(1) | 如果没有指定该值,默认为1 | default ‘1’ |
| gender | 性别 | char(1) | 无 |
create table user(id int primary key auto_increment comment '主键',name varchar(10) not null unique comment '姓名' ,age int check ( age > && age <= 120 ) comment'年龄'status char(1) default '1' comment'状态',gender char(1) comment '性别'
)comment'用户表';
insert into user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男');
insert into user(name,age,status,gender) values ('Tom3',19,1'男');insert into user(name,age,status,gender) values (null,19,'1','男');
insert into user(name,age,status,gender) values ('Tom3',19,'1','男');insert into user(name,age,status,gender) values ('Tom4',80,1',男');
insert into user(name,age,status,gender) values ('Tom5',-1,1',男');
insert into user(name,age,status,gender) values ('Tom5',121,'1','男');
insert into user(name,age,gender) values ('Tom5',120,'男');
当不满足建表约束时就会报错 : 无法插入数据
4.3 外键约束
语法
#添加外键
create table 表名(字段名 数据类型,...[constraint] [外键名称] foreign key(外键字段名) references 主表(主表列名)
);alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);#删除外键
alter table 表名 drop foreign key 外键名称;
案例
-- 添加外键
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
-- 删除外键
alter table emp drop foreign key fk_emp_dept_id;
实际中并不常用外键,会导致耦合度较高
删除更新行为的函数
| 行为 | 说明 |
|---|---|
| no action | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与restrict一致) |
| restrict | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除/更新。(与no action 一致) |
| cascade | 当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则也删除/更新外键在子表中的记录。 |
| set null | 当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null (这就要求该外键允许取null)。 |
| set default | 父表有变更时,子表将外键列设置成一个默认的值(Innodb不支持)。 |
alter table 表名 add constraint 外键名称 foreign key (外键字段) references 主表名(主表字段名) on update cascade on delete cascade;
案例
-- 外键的删除和更新行为
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade;
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null;
5. 多表查询
先拿一段案例展示一下表之间的外键连接
多对多 中间以外键相连
create table student_course(id int auto increment comment '主键' primary key,studentid int not null comment '学生ID',courseid int not null comment '课程ID',constraint fk_courseid foreign key (courseid) references counse (id),constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4);
一对一 中间多创建一个表(tb_user_edu) 相连两个表
create table tb_user(id int auto_increment primary key comment comment '主键ID',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '1: 男 ,2: 女',phone char(11) comment '手机号'
)comment '用户基本信息表';create table tb_user_edu(id int auto_increment primary key comment '主键ID',degree varchar(20) comment '学历',major varchar(50) comment '专业',primaryschool varchar(50) comment'小学'middleschool varchar(50) comment'中学'university varchar(50) comment'大学',userid int unique comment'用户ID',constraint fk_userid foreign key (userid) references tb_user(id)
)comment'用户教育信息表';
多表查询概述
- 概述:指从多张表中查询数据
- 笛卡尔积:笛卡尔乘积是指在数学中,两个集合A集合和B集合的所有组合情况。(在多表查询时,需要消除无效的笛卡尔积)
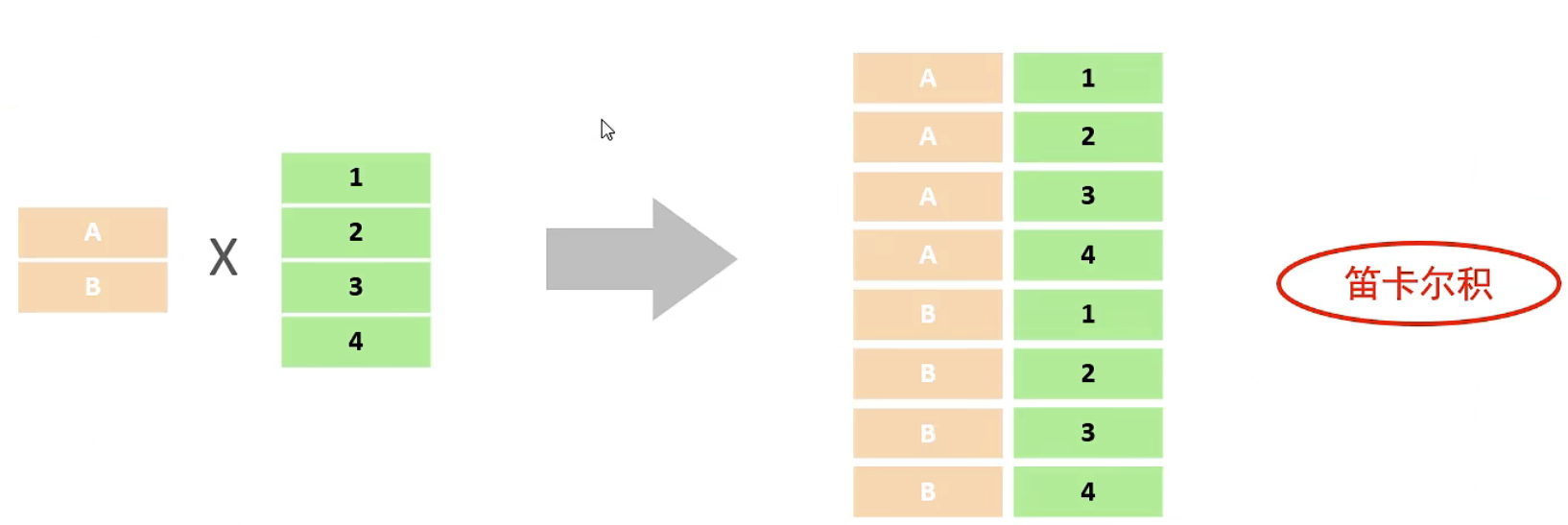
可以通过where来消除笛卡尔积
select * from emp,dept where emp.dept_id = dept.id;
多表查询可以分为
- 连接查询
- 内连接
- 外连接
- 左外连接
- 右外连接
- 自连接
- 子查询
具体含义在小章节会简述
5.1 连接查询
5.1.1 内连接
内连接查询的是两张表交集的部分
#内连接查询语法
-- 隐式内连接
select 字段列表 from 表1,表2 where 条件...;-- 显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件...;
eg:
-- 1.查询每一个员工的姓名,及关联的部门的名称(隐式内连接实现)
-- 表结构:emp,dept
-- 连接条件:emp.dept_id=dept.id
select emp.name,dept.name from emp,dept where emp.dept_id = dept.id;
select e.name,d.name from emp e , dept d where e.dept_id = d.id;-- 2.查询每一个员工的姓名,及关联的部门的名称(显式内连接实现)---- INNER JOIN..ON//
-- 表结构:emp,dept
-- 连接条件:emp.dept_id=dept.id
select e.name,d.name from emp e inner join dept done.dept_id =d.id;
select e.name,d.name from emp e join dept d on e.dept_id = d.id;
5.1.2 外连接
#外连接查询语法
-- 左外连接
select 字段列表 from 表1 left [outer] join 表2 on 条件...;
#相当于查询表1(左表)的所有数据包含表1和表2交集部分的数据-- 右外连接
select 字段列表 from 表1 right [outer] join 表2 on 条件...;
#相当于查询表2(右表)的所有数据包含表1和表2交集部分的数据
eg
-- 1 查询emp表的所有数据,和对应的部门信息(左外连接
-- 表结构:emp,dept
-- 连接条件:emp.dept_id=dept.id
select e.*,d.name from emp e left outer join dept d on e.dept_id = d.id;
select e.*,d.name from emp e left join dept d on e.dept_id =d.id;-- 2 查询dept表的所有数据,和对应的员工信息(右外连接)
select d.* , e. from emp e right outer join dept d on e.dept_id = d.id;
select d.* , e. from dept d left outer join emp e on e.dept_id = d.id;
5.1.3 自连接
#自连接查询语法:
select 字段列表 from 表A 别名A join 表A 别名B on 条件...;
#自连接查询,可以是内连接查询,也可以是外连接查询
eg:
-- 1.查询员工及其所属领导的名字
-- 表结构:emp
select a.name , b.name from emp a , emp b where a.managerid = b.id;-- 2,查询所有员工emp及其领导的名字emp,如果员工没有领导,也需要查询出来
-- 表结构:emp a,emp b
select a.name '员工' , b.name '领导' from emp a left join emp b on a.managerid = b.id;
5.2 联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
select 字段列表 from 表a ...
union [all]
select 字段列表 from 表b ...;
ps :
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- unionall会将全部的数据直接合并在一起, union会对合并之后的数据去重。
eg :
-- union all , union
-- 1.将薪资低于50的员工,和年龄大于50岁的员工全部查询出来。
select * from emp Where salary<500
union all
select * from emp where age>50;
# 查询出的结果有可能出现重复的行select * from emp where salary< 5000
union
select * from emp where age > 50;
#去掉 all 就可以去重
5.3 子查询
5.3.1 标量子查询
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询
常用的操作符:= ,<> , > , < , >= , <=
eg :
-- 标量子查询
-- 1. 查询“销售部”的所有员工信息
-- a. 查询“销售部”部门ID
select id from dept where name = '销售部';-- b. 根据销售部部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');-- 2. 查询在“方东白”入职之后的员工信息
-- a. 查询方东白的入职日期
select entrydate from emp where name = '方东白';-- b.查询指定入职日期之后入职的员工信息
select * from emp where entrydate >(select entrydate from emp where name = '方东白');
5.3.2 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为
列子查询
常用的操作符:IN、NOT IN、ANY、SOME、ALL
| 操作符 | 描述 |
|---|---|
| in | 在指定的集合范围之内,多选一 |
| not in | 不在指定的集合范围之内 |
| any | 子查询返回列表中,有任意一个满足即可 |
| some | 与 any 等同,使用 some 的地方都可以使用 any |
| all | 子查询返回列表的所有值都必须满足 in |
eg :
-- 列子查询
-- 1. 查询“销售部”和“市场部”的所有员工信息
-- a. 查询“销售部”和“市场部”的部门ID
select id from dept where name = '销售部' or name = '市场部';
-- b. 根据部门ID,查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');-- 2. 查询比财务部所有工资都高的员工信息
-- a. 查询所有财务部人员工资
select id from dept where name = '财务部';
select salary from emp where dept_id =(select id from dept where name = '财务部');
-- b.比财务部所有人工资都高的员工信息
select * from emp where salary > all (select salary from emp where dept_id = (select id from dept where name = '财务部'));-- 3. 查询比研发部其中任意一人工资高的员工信息
-- a. 查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');
-- b. 比研发部其中任意一人工资高的员工信息
select * from emp Where salary > some (select salary from emp where dept_id = (select id from dept where name '研发部'));
5.3.3 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为
行子查询
常用的操作符:= , <> , in , not in
eg :
-- 1. 查询与“张无”的薪资及直属领导相同的员工信息
-- a. 查询“张无”的薪资及直属领导
select salary,managerid from emp where name = '张无'
-- b. 查询与“张无”的薪资及直属领导相同的员工信息
select from emp where (salary,managerid)=( select salary, managerid from emp where name = '张无');
5.3.4 表子查询
子查询返回的结果是多行多列,这种子查询称为
表子查询
常用的操作符:IN
eg :
-- 表子查询
-- 1. 查询与“鹿客”“宋远桥”的职位和薪资相同的员工信息
-- a. 查询“鹿枝客”,“宋远桥”的职位和薪资
select job,salary from emp where name = '鹿客' or name = '宋远桥';
-- b. 查询与“鹿客”,“宋远桥”的职位和薪资相同的员工信息
select * from emp where (job,salary) in (select job,salary from emp where name = '鹿杖客' or name = '宋远桥');-- 2. 查询入职日期是“2086-01-01之后的员工信息,及其部门信息
-- a. 入职日期是“206-1-01”之后的员工信息
select * from emp where entrydate > '2006-01-01';
-- b. 查询这部分员工,对应的部门信息
select e.*,d.* from (select from emp where entrydate > '2006-01-01')e left join dept d on e.dept_id = d.id;
5.4 多表查询案例
-- 1. 查询员工的姓名、年龄、职位、部门信息 (隐式内连接)
-- 表:emp,dept
-- 连接条件:emp.dept_id = dept.id
select e.name , e.age , e.job , d.name from emp e , dept d where e.dept_id=d.id;-- 2. 查询年龄小于3岁的员工的姓名、年龄、职位、部门信息(显式内连接)
-- 表:emp,dept
-- 连接条件:emp.dept_id=dept.id
select e.name , e.age , e.job , d.name from emp e inner join dept d on e.dept_id = d.id where e.age < 30;-- 3.查询拥有员工的部门ID、部门名称
-- 表:emp,dept
-- 连接条件:emp.dept_id=dept.i
select distinct d.id , d.name from emp e , dept d where e.dept_id = d.id;-- 4. 查询所有年龄大于4岁的员工,及其归属的部门名称;如果员工没有分配部门,也需要展示出来
-- 表:emp,dept
-- 连接条件:emp.dept_id=dept.id
-- 外连接
select e.* , d.name from emp e Left join dept d on e.dept_id = d.id where e.age > 40;-- 5. 查询所有员工的工资等级
-- 表:emp,sagrade
-- 连接条件:emp.salary>= salgrade.losal and demp.salary <= sagrade.hisal
select e.* , s.grade , s.losal , s.hisal from emp e , salgrade s where e.salary >= s.losa and e.salary <= s.hisal;
select e.* , s.grade , s.losal , s.hisal from emp e , salgrade s where e.salary between s.losal and s.hisal;-- 6. 查询“研发部”所有员工的信息及工资等级
-- 表:emp,salgrade,dept
-- 连接条件:emp.salary between salgrade.losal and salgrade.hisal , emp.dept_id = dept.id
-- 查询条件:dept.name= '研发部'
select e.* , s.grade from emp e , dept d , salgrade s where e.dept_id = d.id and (e.salary between s.losal and s.hisal) and d.name = '研发部';-- 7. 查询“研发部”员工的平均工资
-- 表:emp,dept
-- 连接条件: emp.dept_id = dept.id
select avg(e.salary) from emp e , dept d where e.dept_id = d.id and d.name = '研发部';-- 8. 查询工资比“灭绝”高的员工信息
-- a. 查询“灭绝”的薪资
select salary from emp where name = '灭绝';
-- b. 查询比她工资高的员工数据
select * from emp where salary > (select salary from emp where name = '灭绝');-- 9. 查询比平均薪资高的员工信息
-- a. 查询员工的平均薪资
select avg(salary) from emp;
-- b. 查询比平均薪资高的员工信息
select * from emp where salary > (select avg(salary) from emp);-- 10. 查询低于本部门平均工资的员工信息
-- a. 查询指定部门平均薪资
select avg(e1.salary) from emp e1 Where e1.dept_id = 1;
select avg(e1.salary) from emp e1 where e1.dept_id = 2;
-- b. 查询低于本部门平均工资的员工信息
select * from emp e2 where e2.salary < (select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id );-- 11. 查询所有的部门信息,并统计部门的员工人数
select d.id , d.name , (select count(*) from emp e where e.dept_id = d.id) '人数' from dept d;
select count(*) from emp where dept_id = 1;-- 12. 查询所有学生的选课情况,展示出学生名称,学号,课程名称
-- 表 : student , course , student_course
-- 连接条件:student.id = student_course.studentid , course.id = student_course.courseid
select s.name , s.no , c.name from student s , student_course sc , course c where s.id = sc.studentid and sc.courseid = c.id;
6. 事务
事务的四大特性(ACID)
- 原子性(
Atomicity) : 事务是不可分割的最小操作单元,要么全部成功,要么全部失败. - 一致性(
Consistency) : 事务完成时,必须使所有的数据都保持一致状态. - 隔离性(
Isolation) : 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行. - 持久性(
Durability) : 事务一旦提交或回滚,他对数据库中的数据的改变就是永久的.
6.1 事务的基本操作
#查看/设置事务提交方式
select @@autocommit;
set @@autoccommit = 0; --0是自动提交,1是手动提交,即使用commit#提交事务
commit;#回滚事务
rollback;
eg : 方式一
select @@autocommit;set @@autocommit = 0; --设置为手动提交-- 转账操作(张三给李四转账1088)
-- 1.查询张三账户余额
select * from account where name = '张三';-- 2.将张三账户余额-1080
update account set money = money - 1000 where name = '张三';程执行报错... #手动报错-- 3.将李四账户余额+1000
update account set money = money+1000 where name = '李四';--提交事务
commit;--回滚事务
rollback;
eg : 方式二
#开启事务
start transaction 或 begin;#提交事务
commit;#回滚事务
rollback;
已经设置为自动提交
-- 方式二
-- 转账操作(张三给李四转账1000
start transaction;-- 1. 查询张三账户余额
select * from account where name = '张三';-- 2. 将张三账户余额-18
update account set money = money - 1000 where name = '张三';手动执行报错...-- 3.将季四账户余额+1000
update account set money = money + 1000 where name = '李四';-- 提交事务
commit;--回滚事务
rollback;
6.2 并发事务问题
| 问题 | 描述 |
|---|---|
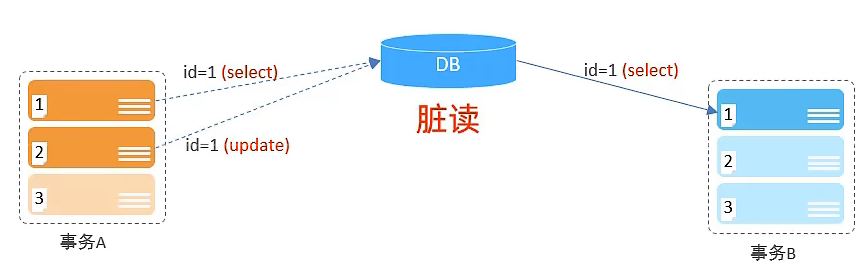
| 脏读 | 一个事务读到另外一个事务还没有提交的数据 |
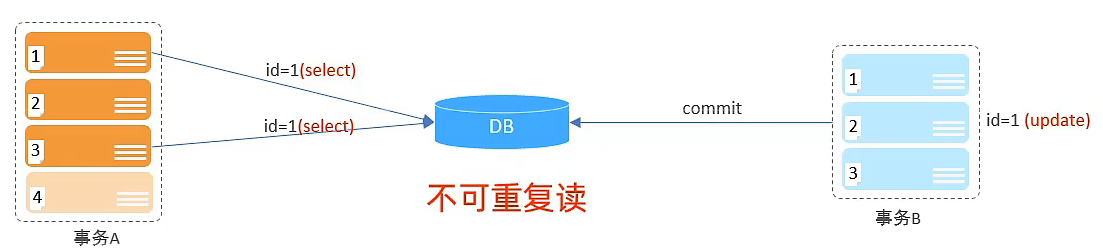
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 “幻影”。 |
- 脏读
B事务读取到了A事务还没有提交的数据
- 不可重复读
事务A用同样的方法读到了不一样的数据
- 幻读
事务A插入不进去,也读不出来,可以理解为,脏写,hhh
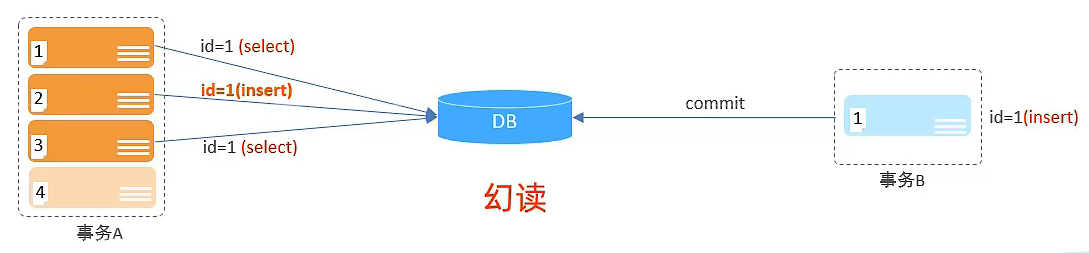
6.3 事务的隔离级别
| 隔离级别 | 读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted | false | false | false |
| read committed (oracle 的默认) | true | false | false |
| repeatable read (默认) | true | true | false |
| serializable | true | true | true |
#查看事务隔离级别
select @@transaction_isolation;#是指事务隔离级别
set [session|global] transaction isolation level [read uncommitted | read committed | repeatable read | serializable ];
-- 查看事务隔离级别
select @@atransaction_isoation-- 设置事务隔离级别
set session transaction isolation level read uncommitted ;
set session transaction isolation Level repeatable read ;
需要注意的是 : 事务隔离级别越高,数据越安全,但是性能会越低
相关文章:
[MySQL]基础篇
文章目录 1. MySQL基本使用1.1 MySQL的启动和登录1.1.1 MySQL的启动1.1.2 MySQL的客户端连接 1.2 数据模型 2. SQL2.1 SQL类型2.1.1 数值类型2.1.2 字符串类型2.1.3 日期类型 2.2 DDL2.2.1 数据库操作2.2.2 表操作 - 查询2.2.3 表操作 - 创建表2.2.4 表操作 - 修改 2.3 DML2.3.…...

Meta Semantic Template for Evaluation of Large Language Models
本文是LLM系列文章,针对《Meta Semantic Template for Evaluation of Large Language Models》的翻译。 大型语言模型评估的元语义模板 摘要1 引言2 相关工作3 方法4 实验5 结论 摘要 大型语言模型(llm)是否真正理解语言的语义,或者只是记住训练数据?…...
Git相关知识(1)
目录 1.初识Git 1.基础知识 2.centos中下载 2.基本操作 1.创建本地仓库 2.配置本地仓库 3.版本库、工作区、暂存区 4.添加文件 5.add和commit对git文件的作用 6.修改文件 7.版本回退 8.撤销修改 9.删除文件 3.分支操作 1.HEAD与分支 2.创建分支 3.删除分支 …...
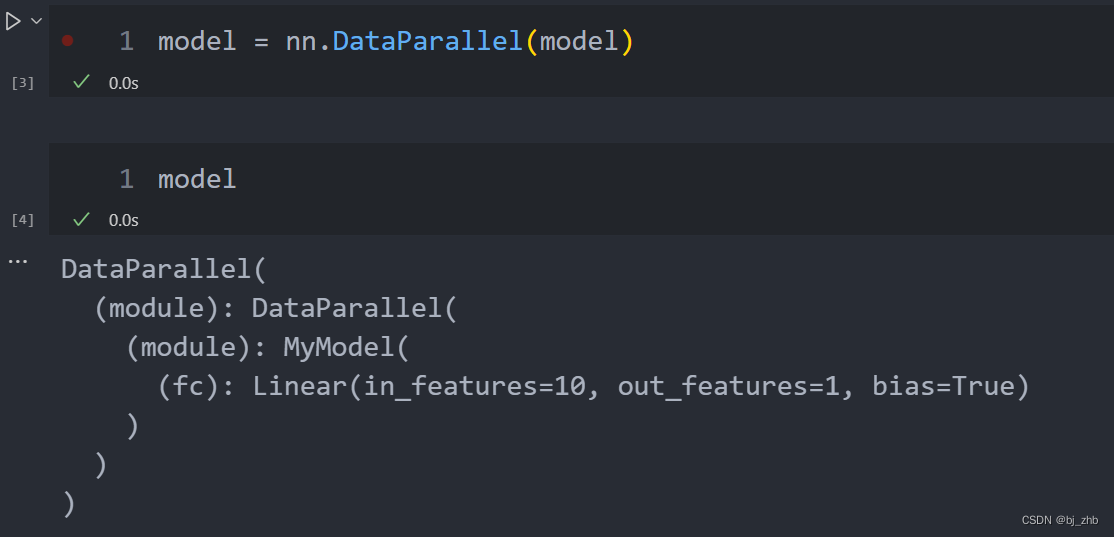
pytorch中nn.DataParallel多次使用
pytorch中nn.DataParallel多次使用 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader# 定义模型 class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc nn.Linear(10, 1)def forwa…...
制作电商页面(Html)
任务 制作一个电商页面,要求所卖物品清晰,页面色调清晰,要有主页和详情页。 网站所买物品:书籍 色调:#FF2400 橙红色 代码 主页HTML代码: <html><head><meta charset"utf-8"…...

Android Sutdio依赖Snapshot版本,无法同步最新的包
起因 局域网中搭建了Nexus托管本地打包的aar,正常情况下,把修改完成的库推送到仓库后,其他项目引用Snapshot版本的依赖,同步后会马上下载最新的包,但是当第二次推送后,就没有重新下载最新的包,…...

Feign调用异常触发降级捕获异常
通过配置fallbackFactory来捕获异常信息,代码如下 FeignClient(name "user", fallbackFactory UserFallBackFactory.class) public interface UserFeign {PostMapping("/get/list")Map getList();}Component public class UserFallBackFacto…...
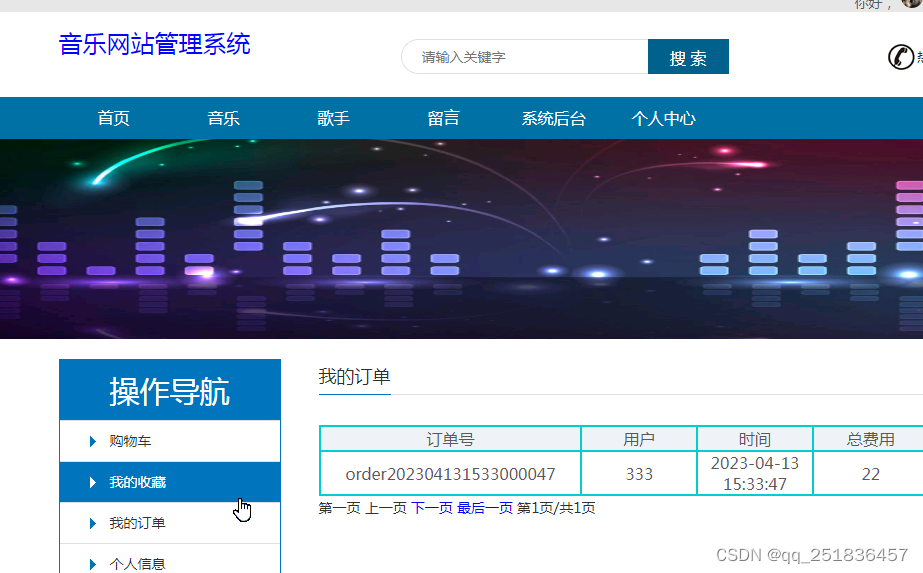
Springboot 音乐网站管理系统idea开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 音乐网站管理系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发),系统 具有完整的源代码和数据库&…...
微信支付v2-02
...

企业的销售活动是什么?CRM销售管理系统给你答案
在企业业务中,销售活动是实现企业业绩目标的基本单元,起着奠基石的作用。CRM销售管理系统是销售活动管理的必备工具,帮助企业更好地开展销售活动。下面来说说企业的销售活动是什么? 什么是销售活动 简单来说,销售人员…...

【PG】PostgreSQL参数格式 配置文件格式
目录 一 PG参数格式 二 通过配置文件修改参数 postgresql.auto.conf文件 三 通过SQL修改参数 四 通过shell修改参数 五 管理配置文件内容 一 PG参数格式 所有参数名都是大小写不敏感的。每个参数都可以接受五种类型之一的值: 布尔、字符串、整数、 浮点数或枚…...
应用层协议 HTTP
一、应用层协议 我们已经学过 TCP/IP , 已然知道数据能从客户端进程经过路径选择跨网络传送到服务器端进程。 我们还需要知道的是,我们把数据从 A 端传送到 B 端, TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用…...

Springboot+vue的应急救援物资管理系统,Javaee项目,springboot vue前后端分离项目。
演示视频: Springbootvue的应急救援物资管理系统,Javaee项目,springboot vue前后端分离项目。 项目介绍: 本文设计了一个基于Springbootvue的前后端分离的应急救援物资管理系统,采用M(model)V&…...

创建properties资源文件,并由spring组件类获取资源文件
1.1 创建资源文件file-upload-dev.properties #文件上传地址 file.imageUserFaceLocation=/workspaces/images/foodie/faces #图片访问地址 file.imageServerUrl=http://localhost:8088/foodie/faces1.2 创建spring组件获取资源文件类FileUpload import org.springframework.…...

你知道npm、yarn、pnpm的区别吗?
npm 嵌套的 node_modules 结构 npm 在早期采用的是嵌套的 node_modules 结构,“node_modules” 文件夹通常包含项目依赖的模块。在项目中使用多个依赖并且这些依赖本身也有它们自己的依赖时,就会出现嵌套的 “node_modules” 结构。 嵌套的 “node_mo…...
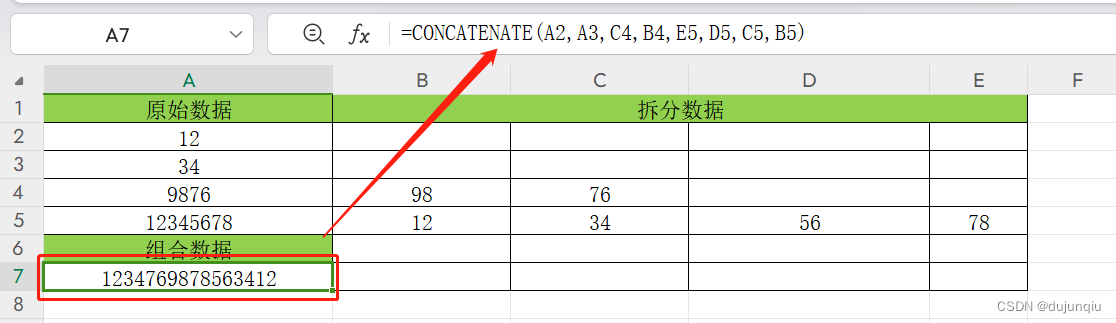
利用excel表格进行分包和组包
实际使用中,我们可能希望修改某几个数据之后,最终的数据包能够自动发动数据,类似于在给结构体变量修改数据,自动生成完整的结构体; excel语法 1:拆分数据 LEFT(A4,2) – 取A4单元格左边的两个数据 RIGHT(A4…...

Go 语言切片扩容规则是扩容2倍?1.25倍?到底几倍
本次主要来聊聊关于切片的扩容是如何扩的,还请大佬们不吝赐教 切片,相信大家用了 Go 语言那么久这这种数据类型并不陌生,但是平日里聊到关于切片是如何扩容的,很多人可能会张口就来,切片扩容的时候,如果老…...

突破封锁|华为芯片10年进化史:从K3V1到麒麟9000S
华为海思麒麟芯片过去10年研发历程回顾如下: 2009年:华为推出第一款手机芯片K3V1,采用65nm工艺制程,基于ARM11架构,主频600MHz,支持WCDMA/GSM双模网络。这款芯片搭载在华为U8800手机上,标志着华…...

vue建项目
vue3 create-vue 建vue3项目 vscode里改点东西,首先vetur禁用,这个是vue2的,下volar pinia持久化插件:npm i pinia-plugin-persistedstate 配eslint、prettier 在.eslintrc.cjs里配 rules: {// prettier专注于代码的美观度 (格…...

天龙八部服务端Public目录功能讲解
PublicDataAIScript文件夹中 script(0~210).ai怪物AI脚本设定如是否主动攻击是否使用技能 PublicDataScript文件夹中 eventbossgroupbg_BossAI_CreateMonster.lua 是BOSS群 刷小怪通用脚本 PublicDataScript文件夹中 eventbossgroupbg_CangShan.lua 苍山 BOSS群刷新脚本 Public…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...