大模型推理框架概述
从 ChatGPT 面世以来,引领了大模型时代的变革,除了大模型遍地开花以外,承载大模型进行推理的框架也是层出不穷,大有百家争鸣的态势。本文主要针对业界知名度较高的一些大模型推理框架进行相应的概述。
简介
vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高14-24倍的吞吐量。
PagedAttention 是 vLLM 的核心技术,它解决了LLM服务中内存的瓶颈问题。传统的注意力算法在自回归解码过程中,需要将所有输入Token的注意力键和值张量存储在GPU内存中,以生成下一个Token。这些缓存的键和值张量通常被称为KV缓存。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关资料、数据、技术交流提升,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群
主要特性
-
通过PagedAttention对 KV Cache 的有效管理
-
传入请求的continus batching,而不是static batching
-
支持张量并行推理
-
支持流式输出
-
兼容 OpenAI 的接口服务
-
与 HuggingFace 模型无缝集成
与其他框架(HF、TGI)的性能对比
vLLM 的吞吐量比 HF 高 14 - 24 倍,比 TGI 高 2.2 - 2.5 倍。
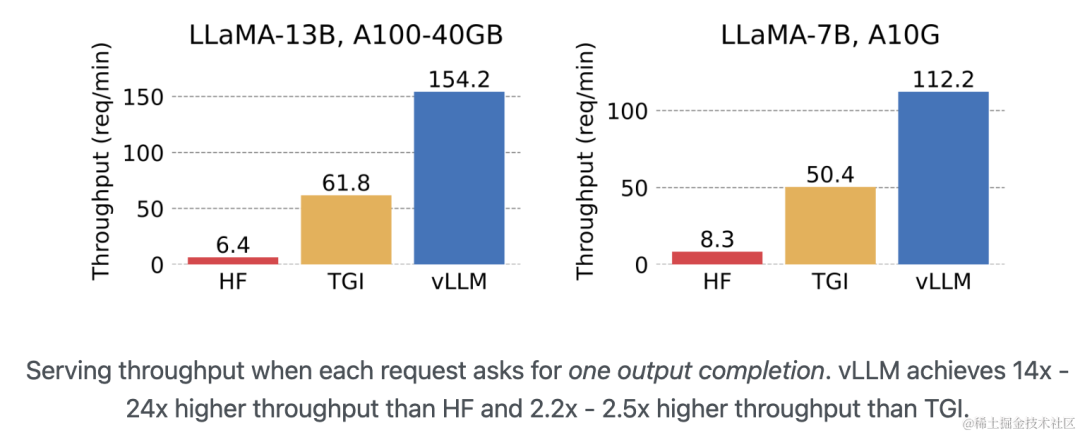
image.png
存在的问题
- 同样的模型、参数和prompt条件下,vLLM推理和Huggingface推理结果不一致。具体请参考:https://zhuanlan.zhihu.com/p/658780653
业界案例
vLLM 已经被用于 Chatbot Arena 和 Vicuna 大模型的服务后端。
HuggingFace TGI
- GitHub: https://github.com/huggingface/text-generation-inference
简介
Text Generation Inference(TGI)是 HuggingFace 推出的一个项目,作为支持 HuggingFace Inference API 和 Hugging Chat 上的LLM 推理的工具,旨在支持大型语言模型的优化推理。
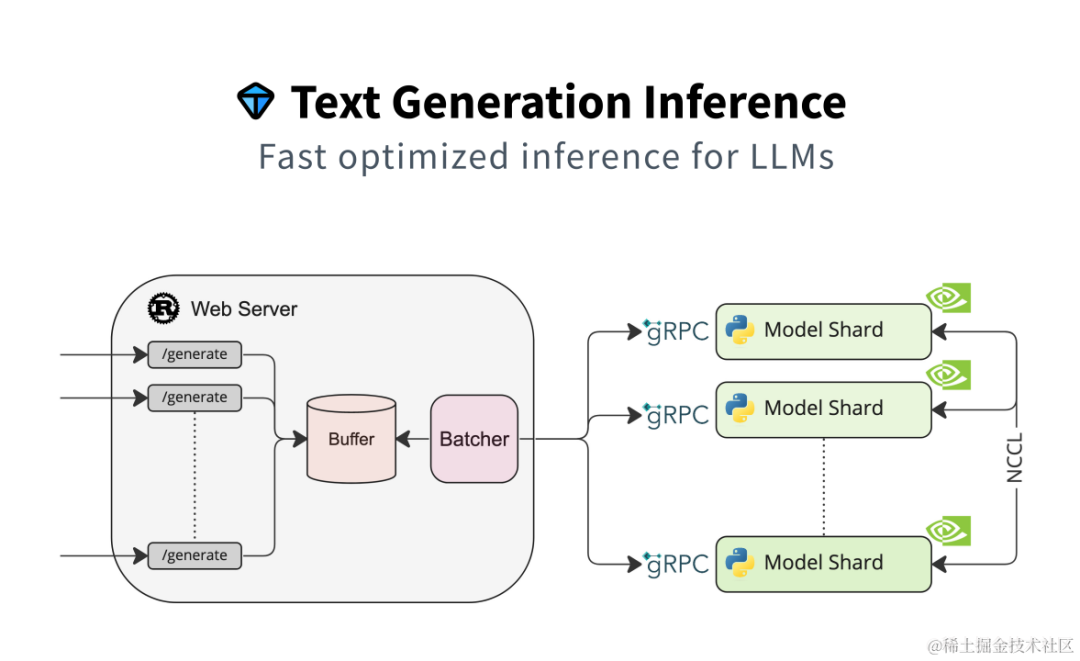
image.png
主要特性
-
支持张量并行推理
-
支持传入请求 Continuous batching 以提高总吞吐量
-
使用 flash-attention 和 Paged Attention 在主流的模型架构上优化用于推理的 transformers 代码。注意:并非所有模型都内置了对这些优化的支持。
-
使用bitsandbytes(
LLM.int8())和GPT-Q进行量化 -
内置服务评估,可以监控服务器负载并深入了解其性能
-
轻松运行自己的模型或使用任何 HuggingFace 仓库的模型
-
自定义提示生成:通过提供自定义提示来指导模型的输出,轻松生成文本
-
使用 Open Telemetry,Prometheus 指标进行分布式跟踪
支持的模型
-
BLOOM
-
FLAN-T5
-
Galactica
-
GPT-Neox
-
Llama
-
OPT
-
SantaCoder
-
Starcoder
-
Falcon 7B
-
Falcon 40B
-
MPT
-
Llama V2
-
Code Llama
适用场景
依赖 HuggingFace 模型,并且不需要为核心模型增加多个adapter的场景。
FasterTransformer
- GitHub: https://github.com/NVIDIA/FasterTransformer
简介
NVIDIA FasterTransformer (FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。它包含Transformer块的高度优化版本的实现,其中包含编码器和解码器部分。使用此模块,您可以运行编码器-解码器架构模型(如:T5)、仅编码器架构模型(如:BERT)和仅解码器架构模型(如:GPT)的推理。
FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,这使您可以在 GPU 上进行快速的 Transformer 推理。
与 NVIDIA TensorRT 等其他编译器相比,FT 的最大特点是它支持以分布式方式进行 Transformer 大模型推理。
下图显示了如何使用张量并行 (TP) 和流水线并行 (PP) 技术将基于Transformer架构的神经网络拆分到多个 GPU 和节点上。
-
当每个张量被分成多个块时,就会发生张量并行,并且张量的每个块都可以放置在单独的 GPU 上。在计算过程中,每个块在不同的 GPU 上单独并行处理;最后,可以通过组合来自多个 GPU 的结果来计算最终张量。
-
当模型被深度拆分,并将不同的完整层放置到不同的 GPU/节点上时,就会发生流水线并行。
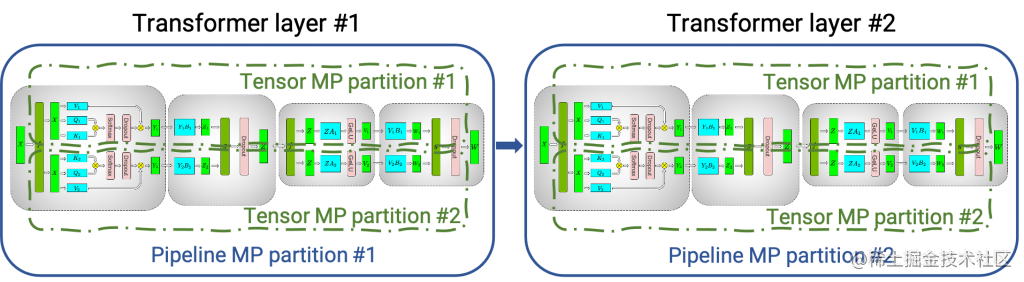
image.png
在底层,节点间或节点内通信依赖于 MPI 、 NVIDIA NCCL、Gloo等。因此,使用FasterTransformer,您可以在多个 GPU 上以张量并行运行大型Transformer,以减少计算延迟。同时,TP 和 PP 可以结合在一起,在多 GPU 节点环境中运行具有数十亿、数万亿个参数的大型 Transformer 模型。
除了使用 C ++ 作为后端部署,FasterTransformer 还集成了 TensorFlow(使用 TensorFlow op)、PyTorch (使用 Pytorch op)和 Triton 作为后端框架进行部署。当前,TensorFlow op 仅支持单 GPU,而 PyTorch op 和 Triton 后端都支持多 GPU 和多节点。
FasterTransformer 中的优化技术
与深度学习训练的通用框架相比,FT 使您能够获得更快的推理流水线以及基于 Transformer 的神经网络具有更低的延迟和更高的吞吐量。FT 对 GPT-3 和其他大型 Transformer 模型进行的一些优化技术包括:
- 层融合(Layer fusion)
这是预处理阶段的一组技术,将多层神经网络组合成一个单一的神经网络,将使用一个单一的核(kernel)进行计算。这种技术减少了数据传输并增加了数学密度,从而加速了推理阶段的计算。例如, multi-head attention 块中的所有操作都可以合并到一个核(kernel)中。
- 自回归模型的推理优化(激活缓存)
为了防止通过Transformer重新计算每个新 token 生成器的先前的key和value,FT 分配了一个缓冲区来在每一步存储它们。
虽然需要一些额外的内存使用,但 FT 可以节省重新计算的成本。该过程如下图所示,相同的缓存机制用于 NN 的多个部分。
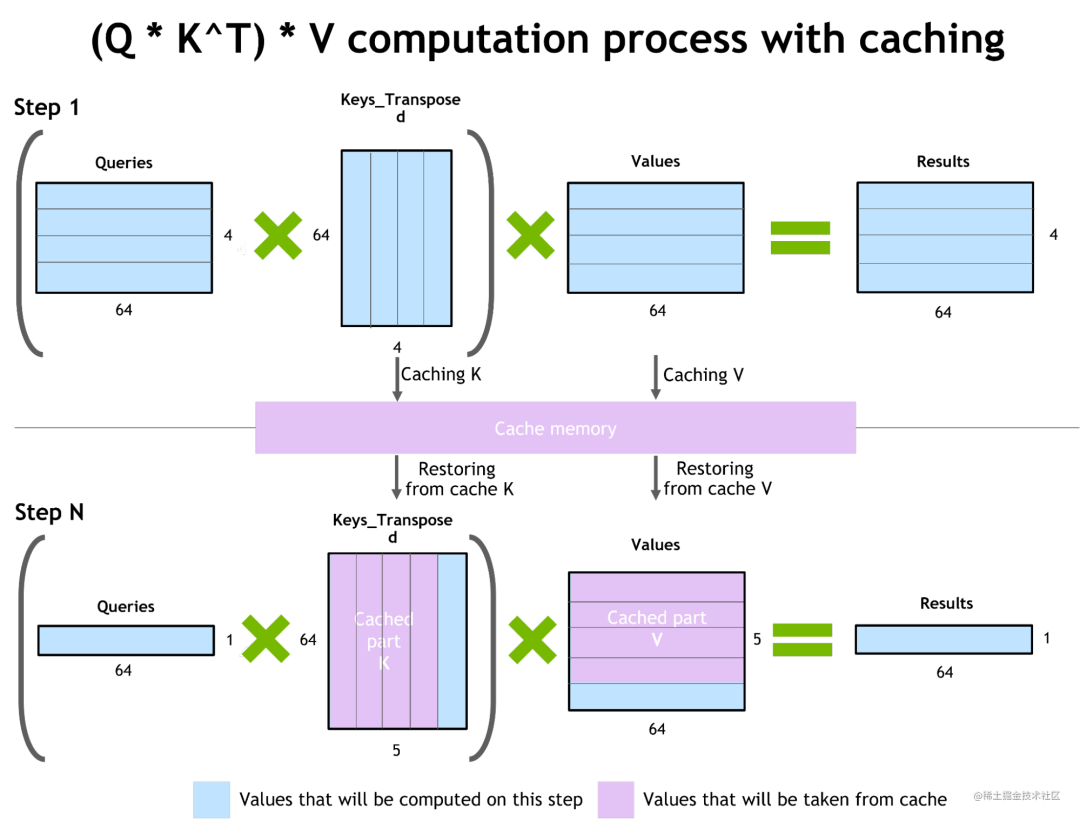
image.png
- 内存优化
与 BERT 等传统模型不同,大型 Transformer 模型具有多达数万亿个参数,占用数百 GB 存储空间。即使我们以半精度存储模型,GPT-3 175b 也需要 350 GB。因此有必要减少其他部分的内存使用。
例如,在 FasterTransformer 中,我们在不同的解码器层重用了激活/输出的内存缓冲(buffer)。由于 GPT-3 中的层数为 96,因此我们只需要 1/96 的内存量用于激活。
- 使用 MPI 和 NCCL 实现节点间/节点内通信并支持模型并行
FasterTransormer 同时提供张量并行和流水线并行。对于张量并行,FasterTransformer 遵循了 Megatron 的思想。对于自注意力块和前馈网络块,FT 按行拆分第一个矩阵的权重,并按列拆分第二个矩阵的权重。通过优化,FT 可以将每个 Transformer 块的归约(reduction)操作减少到两次。
对于流水线并行,FasterTransformer 将整批请求拆分为多个微批,隐藏了通信的空泡(bubble)。FasterTransformer 会针对不同情况自动调整微批量大小。
- MatMul 核自动调整(GEMM 自动调整)
矩阵乘法是基于 Transformer 的神经网络中最主要和繁重的操作。FT 使用来自 CuBLAS 和 CuTLASS 库的功能来执行这些类型的操作。重要的是要知道 MatMul 操作可以在“硬件”级别使用不同的底层(low-level)算法以数十种不同的方式执行。
GemmBatchedEx 函数实现了 MatMul 操作,并以cublasGemmAlgo_t作为输入参数。使用此参数,您可以选择不同的底层算法进行操作。
FasterTransformer 库使用此参数对所有底层算法进行实时基准测试,并为模型的参数和您的输入数据(注意层的大小、注意头的数量、隐藏层的大小)选择最佳的一个。此外,FT 对网络的某些部分使用硬件加速的底层函数,例如:__expf、__shfl_xor_sync。
- 低精度推理
FT 的核(kernels)支持使用 fp16 和 int8 等低精度输入数据进行推理。由于较少的数据传输量和所需的内存,这两种机制都会加速。同时,int8 和 fp16 计算可以在特殊硬件上执行,例如:Tensor Core(适用于从 Volta 开始的所有 GPU 架构)。
除此之外还有快速的 C++ BeamSearch 实现、当模型的权重部分分配到八个 GPU 之间时,针对 TensorParallelism 8 模式优化的 all-reduce。
支持的模型
目前,FT 支持了 Megatron-LM GPT-3、GPT-J、BERT、ViT、Swin Transformer、Longformer、T5 和 XLNet 等模型。您可以在 GitHub 上的 FasterTransformer库中查看最新的支持矩阵。
与其他框架(PyTorch)的性能对比
FT 适用于计算能力 >= 7.0 的 GPU,例如: V100、A10、A100 等。
下图展示了 GPT-J 6B 参数的模型推断加速比较:
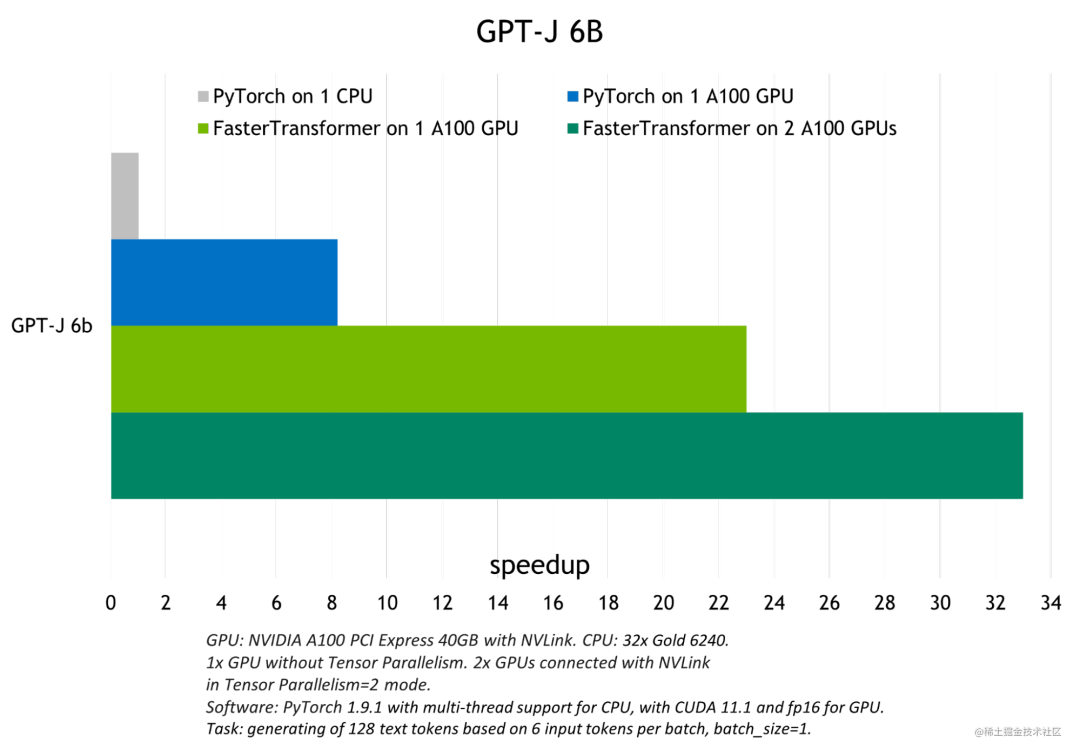
image.png
存在的问题
- 英伟达新推出了TensorRT-LLM,相对来说更加易用,后续FasterTransformer将不再为维护了。
DeepSpeed-MII
- GitHub: https://github.com/microsoft/DeepSpeed-MII
简介
DeepSpeed-MII 是 DeepSpeed 的一个新的开源 Python 库,旨在使模型不仅低延迟和低成本推理,而且还易于访问。
-
MII 提供了对数千种广泛使用的深度学习模型的高度优化实现。
-
与原始PyTorch实现相比,MII 支持的模型可显著降低延迟和成本。
-
为了实现低延迟/低成本推理,MII 利用 DeepSpeed-Inference 的一系列广泛优化,例如:transformers 的深度融合、用于多 GPU 推理的自动张量切片、使用 ZeroQuant 进行动态量化等。
-
MII 只需几行代码即可通过 AML 在本地和 Azure 上低成本部署这些模型。
MII 工作流程
下图显示了 MII 如何使用 DS-Inference 自动优化 OSS 模型;然后,使用 GRPC 在本地部署,或使用 AML Inference 在 Microsoft Azure 上部署。
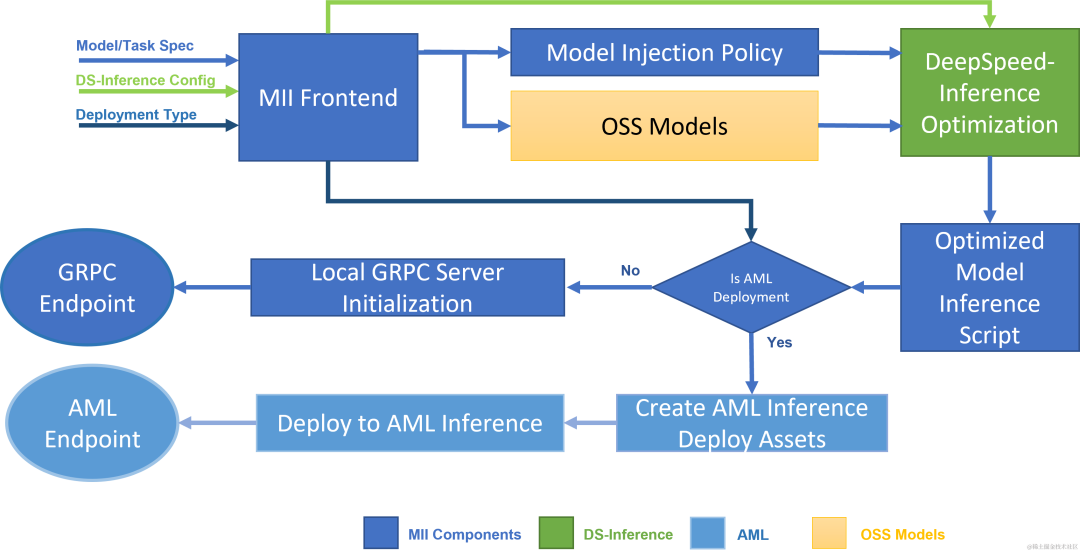
image.png
MII 的底层由 DeepSpeed-Inference 提供支持。根据模型类型、模型大小、批量大小和可用硬件资源,MII 自动应用 DeepSpeed-Inference 中的一组适当的系统优化,以最大限度地减少延迟并最大限度地提高吞吐量。它通过使用许多预先指定的模型注入策略之一来实现这一点,该策略允许 MII 和 DeepSpeed-Inference 识别底层 PyTorch 模型架构并用优化的实现替换它。在此过程中,MII 使 DeepSpeed-Inference 中一系列的优化自动可用于其支持的数千种流行模型。
支持的模型和任务
MII 目前支持超过 50,000 个模型,涵盖文本生成、问答、文本分类等一系列任务。MII 加速的模型可通过 Hugging Face、FairSeq、EluetherAI 等多个开源模型存储库获取。我们支持基于 Bert、Roberta 或 GPT 架构的稠密模型,参数范围从几亿参数到数百亿参数。除此之外,MII将继续扩展该列表,支持即将推出的大规模千亿级以上参数稠密和稀疏模型。
目前 MII 支持以下 HuggingFace Transformers 模型系列:
| model family | size range | ~model count |
|---|---|---|
| llama | 7B - 65B | 1,500 |
| bloom | 0.3B - 176B | 480 |
| stable-diffusion | 1.1B | 3,700 |
| opt | 0.1B - 66B | 460 |
| gpt_neox | 1.3B - 20B | 850 |
| gptj | 1.4B - 6B | 420 |
| gpt_neo | 0.1B - 2.7B | 700 |
| gpt2 | 0.3B - 1.5B | 11,900 |
| xlm-roberta | 0.1B - 0.3B | 4,100 |
| roberta | 0.1B - 0.3B | 8,700 |
| distilbert | 0.1B - 0.3B | 4,700 |
| bert | 0.1B - 0.3B | 23,600 |
与其他框架(PyTorch)的性能对比
MII 将 Big-Science Bloom 176B 模型的延迟降低了 5.7 倍,同时将成本降低了 40 倍以上。同样,它将部署 Stable Diffusion 的延迟和成本降低了 1.9 倍。
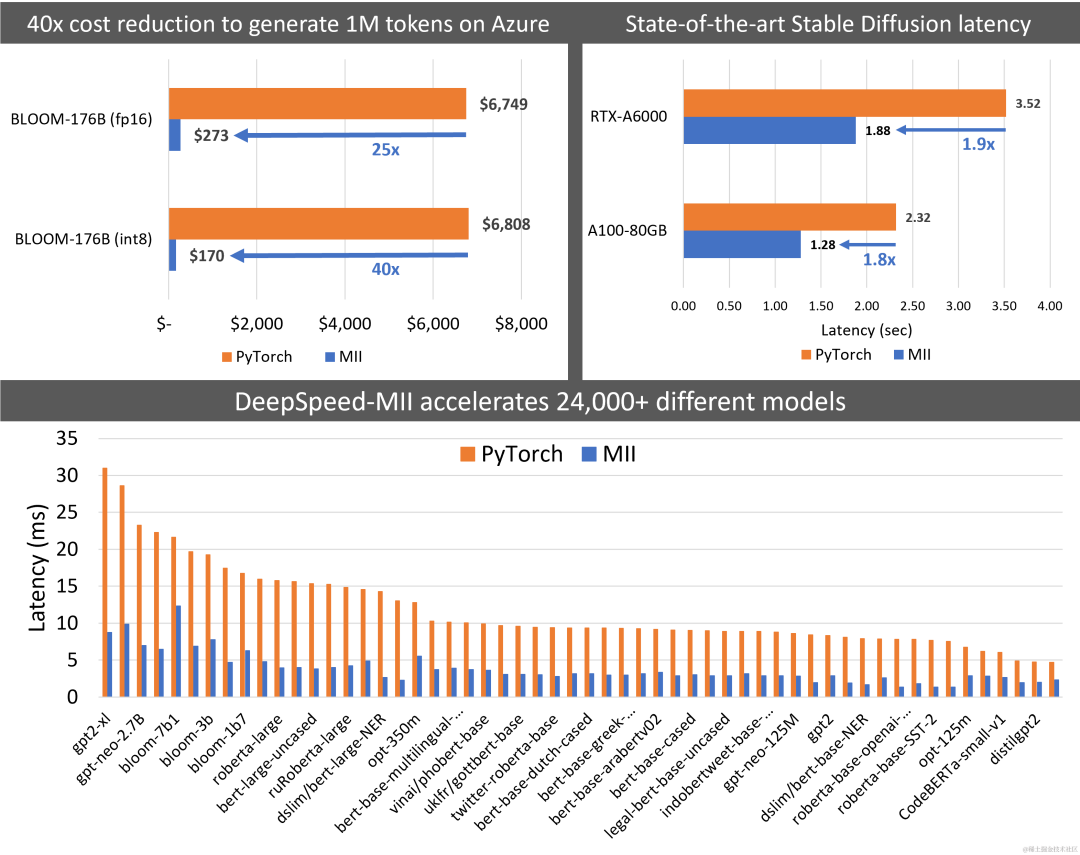
image.png
FlexFlow Server
- GitHub: https://github.com/flexflow/FlexFlow/tree/inference
简介
FlexFlow Serve 是一个开源编译器和分布式系统,用于低延迟、高性能 LLM 服务。
主要特征
投机(Speculative) 推理
使 FlexFlow Serve 能够加速 LLM 服务的一项关键技术是Speculative推理,它结合了各种集体boost-tuned的小型投机模型 (SSM) 来共同预测 LLM 的输出;
预测被组织为token树,每个节点代表一个候选 token 序列。使用一种新颖的基于树的并行解码机制,根据 LLM 的输出并行验证由 token 树表示的所有候选 token 序列的正确性。
FlexFlow Serve 使用 LLM 作为 token 树验证器而不是增量解码器,这大大减少了服务生成 LLM 的端到端推理延迟和计算要求,同时,可证明保持模型质量。
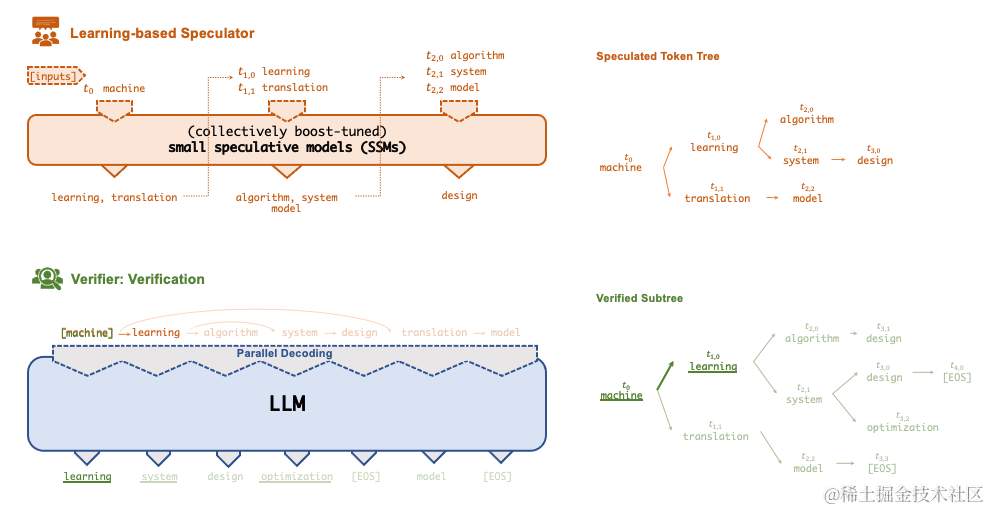
image.png
CPU Offloading
FlexFlow Serve 还提供基于Offloading的推理,用于在单个 GPU 上运行大型模型(例如:llama-7B)。
CPU Offloading是将张量保存在CPU内存中,并且在计算时仅将张量复制到GPU。
注意:
现在我们有选择地offload最大的权重张量(线性、注意力中的权重张量)。此外,由于小模型占用的空间要少得多,如果不构成GPU内存瓶颈,offload会带来更多的运行空间和计算成本,因此,我们只对大模型进行offload。可以通过启用 -offload 和 -offload-reserve-space-size 标志来运行offloading。
支持量化
FlexFlow Serve 支持 int4 和 int8 量化。压缩后的张量存储在CPU端, 一旦复制到 GPU,这些张量就会进行解压缩并转换回其原始精度。
支持的 LLMs 和 SSMs
FlexFlow Serve 当前支持以下模型架构的所有Hugingface模型:
-
LlamaForCausalLM/LLaMAForCausalLM(例如:LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, …) -
OPTForCausalLM(OPT家族模型) -
RWForCausalLM(Falcon家族模型) -
GPTBigCodeForCausalLM(Starcoder家族模型)
以下是我们已经测试过并且可以使用 SSM 的模型列表:
| 模型 | 在 HuggingFace 中的模型 id | Boost-tuned SSMs |
|---|---|---|
| LLaMA-7B | decapoda-research/llama-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-13B | decapoda-research/llama-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-30B | decapoda-research/llama-30b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-65B | decapoda-research/llama-65b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-7B | meta-llama/Llama-2-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-13B | meta-llama/Llama-2-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-70B | meta-llama/Llama-2-70b-hf | LLaMA-68M , LLaMA-160M |
| OPT-6.7B | facebook/opt-6.7b | OPT-125M |
| OPT-13B | facebook/opt-13b | OPT-125M |
| OPT-30B | facebook/opt-30b | OPT-125M |
| OPT-66B | facebook/opt-66b | OPT-125M |
| Falcon-7B | tiiuae/falcon-7b | |
| Falcon-40B | tiiuae/falcon-40b | |
| StarCoder-15.5B | bigcode/starcoder | |
与其他框架(vLLM、TGI、FasterTransformer)的性能对比
FlexFlow Serve 在单节点多 GPU 推理方面比现有系统高 1.3-2.0 倍,在多节点多 GPU 推理方面比现有系统高 1.4-2.4 倍。
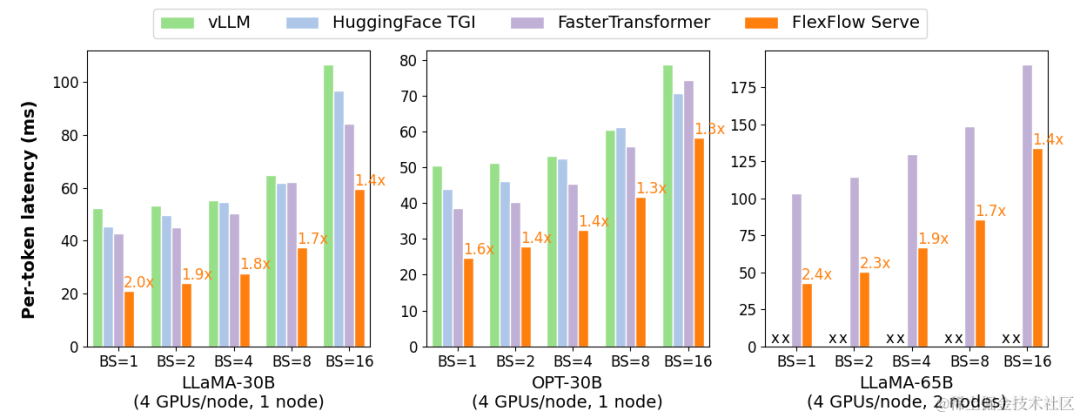
image.png
提示数据集
FlexFlow 提供了五个用于评估 FlexFlow Serve 的提示数据集:
-
Chatbot 指令提示:https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatbot.json
-
ChatGPT 提示:https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatgpt.json
-
WebQA:https://specinfer.s3.us-east-2.amazonaws.com/prompts/webqa.json
-
Alpaca:https://specinfer.s3.us-east-2.amazonaws.com/prompts/alpaca.json
-
PIQA:https://specinfer.s3.us-east-2.amazonaws.com/prompts/piqa.json
未来的规划
FlexFlow Serve 正在积极开发中,主要专注于以下任务:
-
AMD 基准测试。目前正在积极致力于在 AMD GPU 上对 FlexFlow Serve 进行基准测试,并将其与 NVIDIA GPU 上的性能进行比较。
-
Chatbot prompt 模板和多轮对话
-
支持 FastAPI
-
与LangChain集成进行文档问答
LMDeploy
- GitHub: https://github.com/InternLM/lmdeploy
简介
LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。这个强大的工具箱提供以下核心功能:
-
高效推理引擎 TurboMind:基于 FasterTransformer推理引擎,实现了高效推理引擎 TurboMind,支持 InternLM、LLaMA、vicuna等模型在 NVIDIA GPU 上的推理。
-
交互推理方式:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。
-
多 GPU 部署和量化:提供了全面的模型部署和量化(支持使用AWQ算法对模型权重进行 INT4 量化,支持 KV Cache INT8 量化)支持,已在不同规模上完成验证。
-
persistent batch 推理:进一步优化模型执行效率。
-
支持张量并行推理(注意:量化部署时不支持进行张量并行)
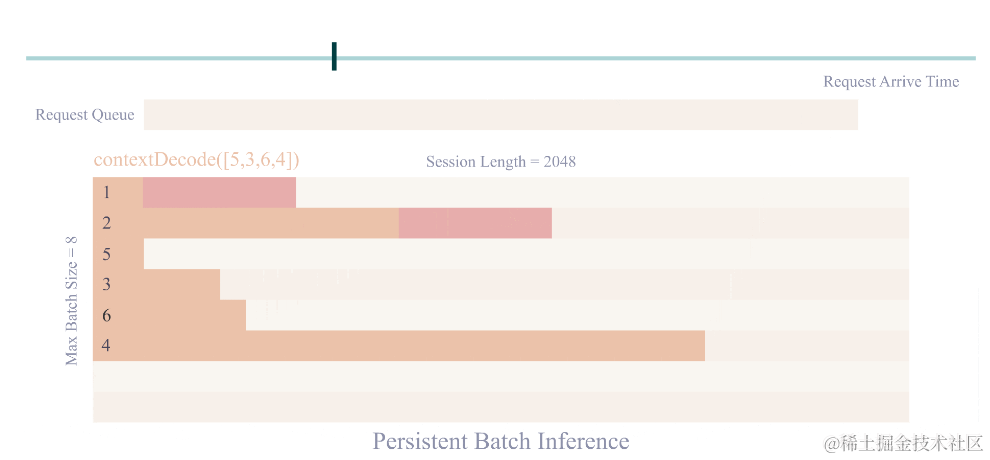
image.png
支持的模型
LMDeploy 支持 TurboMind 和 Pytorch 两种推理后端。
TurboMind
注意:
W4A16 推理需要 Ampere 及以上架构的 Nvidia GPU
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | Yes | Yes | No |
| Llama2 | Yes | Yes | Yes | Yes | No |
| InternLM-7B | Yes | Yes | Yes | Yes | No |
| InternLM-20B | Yes | Yes | Yes | Yes | No |
| QWen-7B | Yes | Yes | Yes | No | No |
| Baichuan-7B | Yes | Yes | Yes | Yes | No |
| Baichuan2-7B | Yes | Yes | No | No | No |
| Code Llama | Yes | Yes | No | No | No |
Pytorch
| 模型 | 模型并行 | FP16 | KV INT8 | W4A16 | W8A8 |
|---|---|---|---|---|---|
| Llama | Yes | Yes | No | No | No |
| Llama2 | Yes | Yes | No | No | No |
| InternLM-7B | Yes | Yes | No | No | No |
与其他框架(HF、DeepSpeed、vLLM)的性能对比
场景一: 固定的输入、输出token数(1,2048),测试 output token throughput
场景二: 使用真实数据,测试 request throughput
测试配置:LLaMA-7B, NVIDIA A100(80G)
TurboMind 的 output token throughput 超过 2000 token/s, 整体比 DeepSpeed 提升约 5% - 15%,比 huggingface transformers 提升 2.3 倍 在 request throughput 指标上,TurboMind 的效率比 vLLM 高 30%。
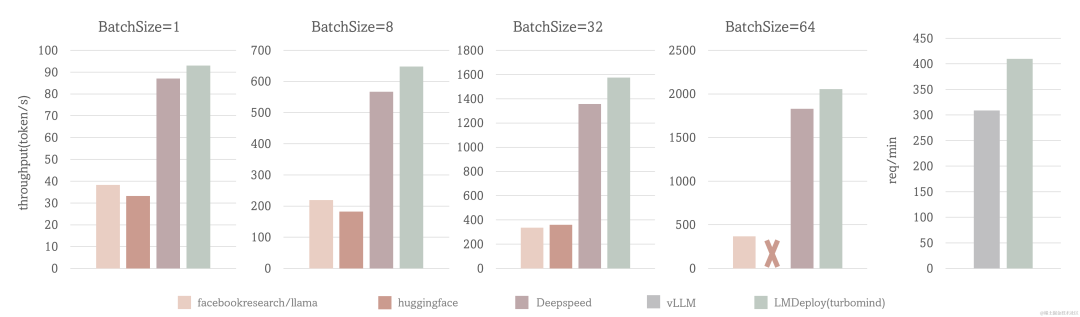
image.png
结语
总而言之,大模型推理框架的核心目标都是为了降低延迟;同时,尽可能地提升吞吐量;从上面的框架中可以看到,每个框架各有优缺点,但是目前来看,还没有一个LLM推理框架有一统天下的态势,大家都在加速迭代。
相关文章:
大模型推理框架概述
从 ChatGPT 面世以来,引领了大模型时代的变革,除了大模型遍地开花以外,承载大模型进行推理的框架也是层出不穷,大有百家争鸣的态势。本文主要针对业界知名度较高的一些大模型推理框架进行相应的概述。 简介 vLLM是一个开源的大模…...
抖音商品详情数据接口,抖音商品详情API接口
抖音商品详情API接口获取数据,接口对接可获取到商品标题,商品价格,商品优惠价,优惠券信息,店铺昵称,sku信息,sku主图,视频链接,详情主图,库存,数量…...

睿趣科技:抖音开网店怎么开通
在当前的数字时代,电子商务已经成为一种主流的商业模式。抖音作为中国最大的短视频平台,也提供了这种能力,让商家能够在平台上开设自己的网店。那么,如何在抖音上开通网店呢?下面是详细的步骤: 注册抖音账号 首先&…...
体育场馆能源消耗监测管理平台,为场馆提供能源服务
随着能源问题的不断重视,体育场馆能源问题也被人们广泛的关注。为了让体育场馆的能源高效利用,体育场馆能源消耗监测管理平台应用而生。 该平台通过采集、监测场内数据,并对数据进行实时分析与反馈,从而帮助管理者了解到场内能源…...
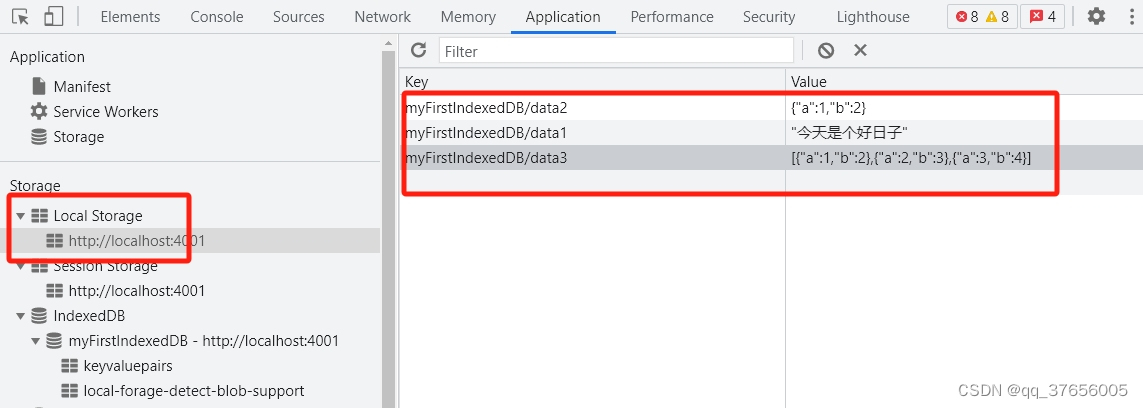
前端本地存储方案-localForage-vue3中使用
前言 前端有多种本地存储方案可供选择,常见的有: Cookie:小型的文本文件,存储少量数据Web Storage :包括:localStorage和sessionStorage,存储数据有上限(5M)左右Indexe…...

vivo年度新“机皇”X100系列要来了!
据供应链消息,vivo X90系列为满足旺盛的市场需求,曾经两次加单生产。 X90系列发布至今已超过11个月,竟然还保持着如此火爆大卖的状态,,令行业关注。而X系列即将发布的下一代产品X100系列,则让中高端消费者们更加期待。…...

滴滴发布十一大数据:延边出行需求上涨280% 西部省份成旅游热点
今年十一假期适逢中秋佳节,在亲友团聚和长假出游的多重期盼下,超级黄金周展现强劲内需,带动多样化的消费趋势,出行热情也随之高涨。滴滴出行数据显示,打车需求相比去年同期上涨80%,高峰时段每分钟呼叫突破1…...

Allegro如何查看器件的管脚号?
Allegro在默认情况下,器件是不显示管脚号的。 Allegro默认情况下,器件不显示管脚编号。 在PCB布局时,有时候我们需要看器件的管脚号,然后才能方便布局。那如何查看器件的管脚号呢? 这里介绍两种查看器件的管脚编号的方法。 方法一: (1)选择菜单Display→Color/Visi…...
苹果电脑用什么清理软件比较好?
很多人都会有这样的误解:mac系统不用清理。实际上mac只是将系统垃圾隐藏了,并且需要通过特定的方式打开。但其实在我们日常工作不用这么麻烦,我们只需用苹果电脑专业的清理软件就好了。今天小编就给大家分享一下mac用什么清理软件好 一、mac用…...
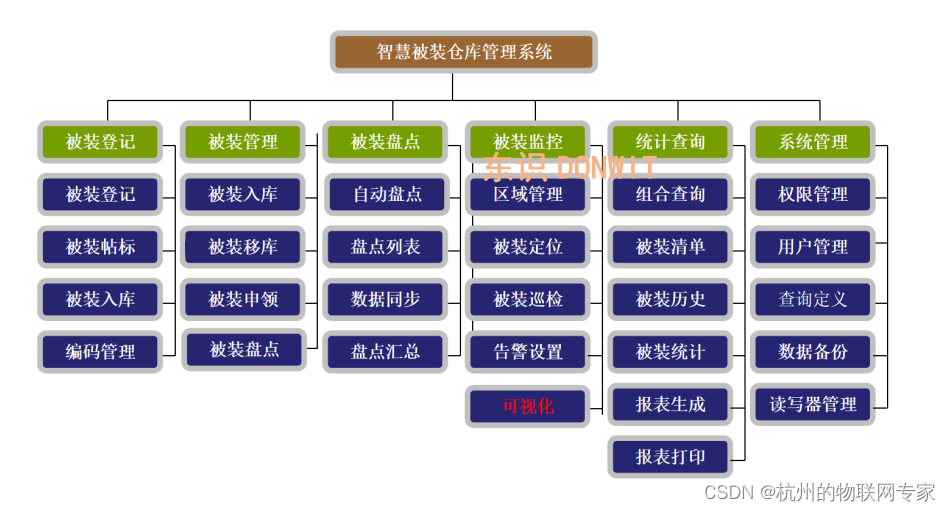
被装超市管理系统-智被装DW-S305系统组成项目背景
项目背景 被装管理是JD后勤管理的一个重要组成部分,现在的被装管理的手工方式已不能适应被装管理现代化的需求,存在诸多问题,还需要依托大量的人力物力,对于一些品规较多、出入库频率较高的仓库,这样的管理方式显得捉…...

使用“Apple 诊断”测试你的 Mac(查看电池是否到达更换标准)
使用“Apple 诊断”测试你的 Mac “Apple 诊断”(以前称为“Apple Hardware Test”)可以检查你的 Mac 是不是存在硬件问题。 如果你认为你的 Mac 可能存在硬件问题,可以使用“Apple 诊断”来帮助确定可能存在故障的硬件组件。“Apple 诊断”…...
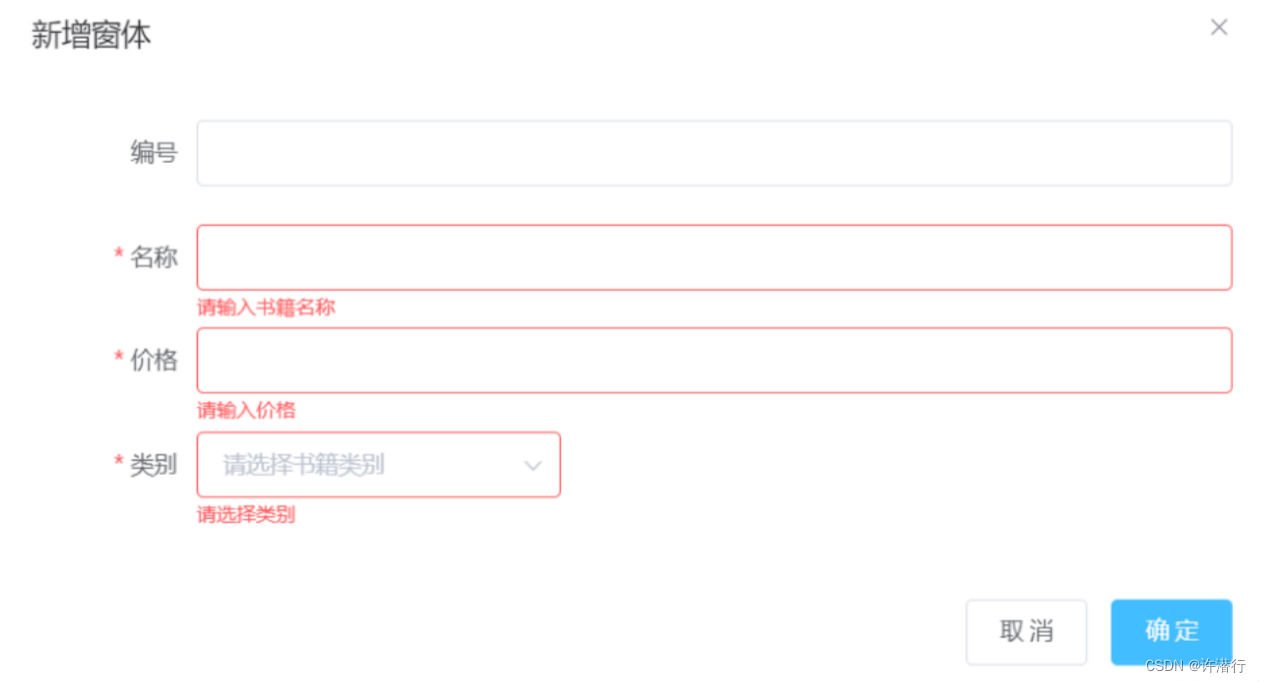
ElementUI增删改的实现及表单验证
文章目录 一、准备二、添加功能2.1 新增添加按钮2.2 添加弹出框2.3 data中添加内容2.4 methods中添加相关方法 三、编辑功能3.1 表格中添加编辑和删除按钮3.2 methods中添加方法3.3 修改methods中clear方法3.4 修改methods中的handleSubmit方法 四、删除书籍功能4.1 往methods的…...

基于Google‘s FCM实现消息推送
当然,下面是一个简单的示例,演示了如何使用 Service Worker 和 Googles Firebase Cloud Messaging(FCM)来实现 Web 推送通知。 1. HTML 文件(index.html) <!DOCTYPE html> <html> <head&g…...
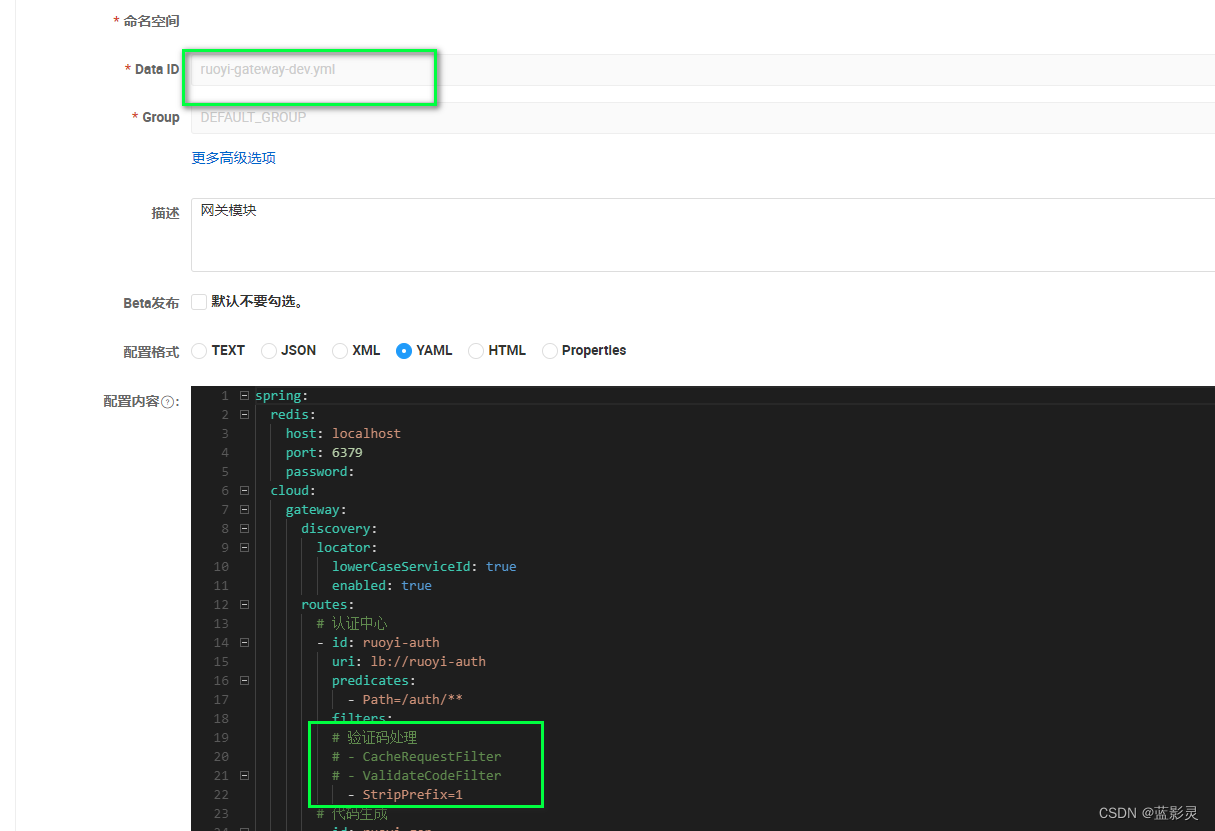
若依微服务前后端部署启动流程(只记录)
若依官网:https://www.ruoyi.vip/ 若依源码下载,直接zip既可:RuoYi-Cloud: 🎉 基于Spring Boot、Spring Cloud & Alibaba的分布式微服务架构权限管理系统,同时提供了 Vue3 的版本 下载解压,导入 idea&…...

docker创建nginx容器
前言:当直接run运行nginx容器时,如果命令带有-v 映射出配置文件目录,则会报错,提示无法初始化,原因是没有配置文件,docker会同步主机文件到容器内,而主机文件又是空白的,所以无法启动…...

nio 文件传输
transferto方法一次只能传输2个g的数据 文件大于2个g时...

2023-10-09 python-安装psd_tools-记录
摘要: 2023-10-09 python-安装psd_tools-记录 安装python3 yum install -y python3 yum install -y python3-devel psd-tools相关文档 psd-tools — psd-tools 1.9.28 documentation GitHub - psd-tools/psd-tools: Python package for reading Adobe Photoshop PSD files psd…...

【Python目标识别】目标检测的原理及常见模型的介绍
1 概述 目标检测(Object Detection)是计算机视觉领域的一个重要研究方向,其目的是在图像或视频中定位并识别出特定的物体。目标检测模型通常需要同时确定物体的位置和类别。在深度学习之前,目标检测算法主要基于传统计算机视觉方法…...
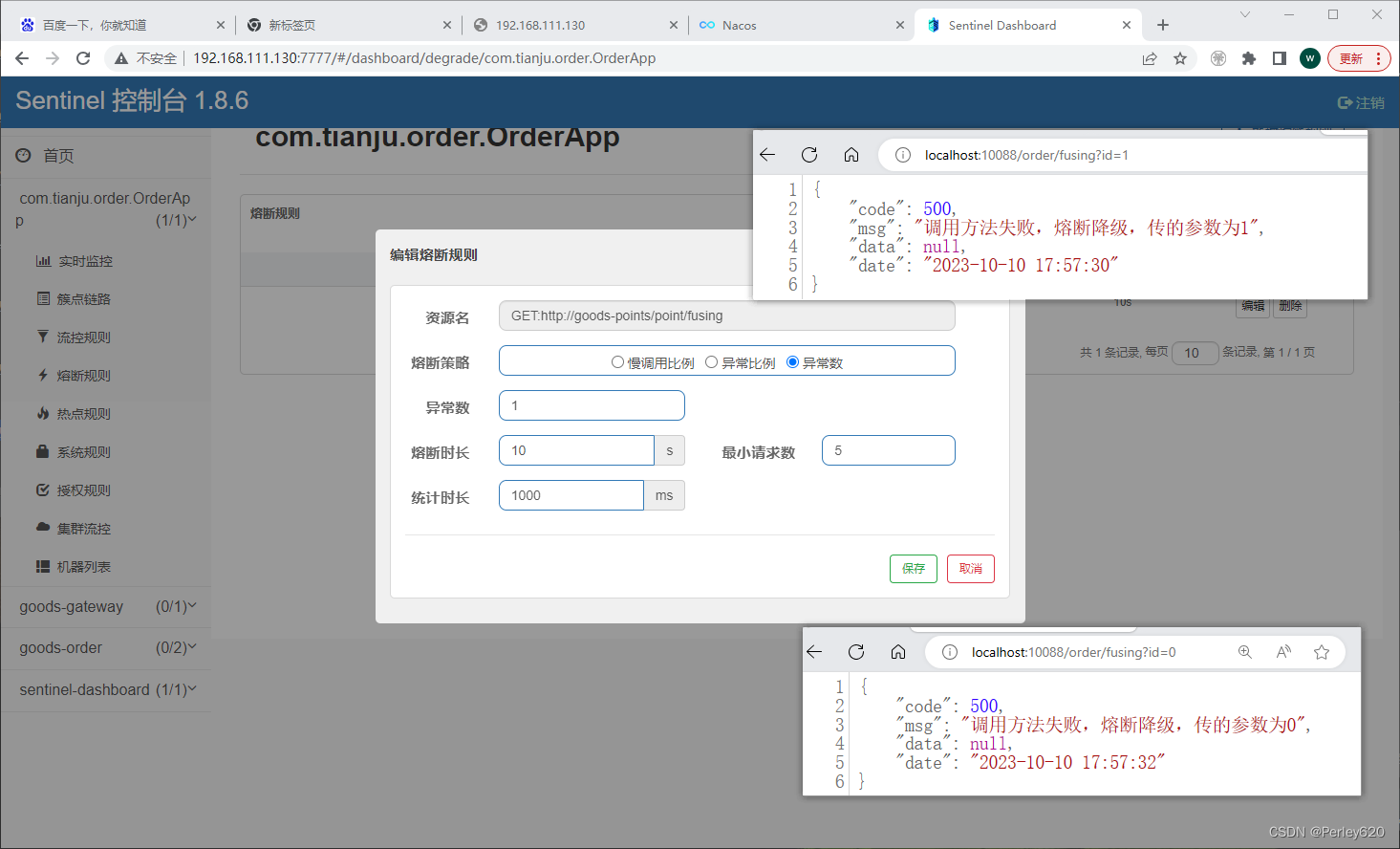
SpringCloud小项目——订单积分商城 使用Nacos、Open Feign、Gateway、Sentinel技术栈
目录 引出小项目要求创建极简数据库表订单表,订单明细表商品表积分表 相关微服务积分微服务产品微服务订单微服务调用积分和订单微服务 网关微服务登陆认证通过网关实现对外提供接口API走网关功能 sentinel相关使用Sentinel限流,流量整形Sentinel降级服务…...

澳大利亚教育部宣布ChatGPT将被允许在澳学校使用!
教育部长最近宣布,从 2024 年起,包括 ChatGPT 在内的人工智能将被允许在所有澳大利亚学校使用。 (图片来源:卫报) 而早些时候,澳洲各高校就已经在寻找与Chatgpt之间的平衡了。 之前,悉尼大学就…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...