Python3操作Redis最新版|CRUD基本操作(保姆级)

Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战
Python3数据科学包系列(三):数据分析实战
Win11查看安装的Python路径及安装的库
Python PEP8 代码规范常见问题及解决方案
Python3操作MySQL8.XX创建表|CRUD基本操作
Python3操作SQLite3创建表主键自增长|CRUD基本操作
anaconda3最新版安装|使用详情|Error: Please select a valid Python interpreter
Python函数绘图与高等代数互融实例(一):正弦函数与余弦函数
Python函数绘图与高等代数互融实例(二):闪点函数
Python函数绘图与高等代数互融实例(三):设置X|Y轴|网格线
Python函数绘图与高等代数互融实例(四):设置X|Y轴参考线|参考区域
Python函数绘图与高等代数互融实例(五): 则线图综合案例
Python3操作MongoDb7最新版创建文档及CRUD基本操作
Python3操作Redis官方详细文档
Java OR Mapping Redis文档:
Adding Redis OM Spring Java对象到Redis对象关系映射高级应用
对象关系映射Maven三角坐标
Python操作Redis高级方式: 异步操作Redis|管道|事务等操作
找准文档,对症下药,精准匹配,求人不如求文档,码农小菜鸟
精准扶贫|保姆服务
一: Redis连接
认知升维
Python3连接Redis操作 StrictRedis跟Redis的区别在于,StrictRedis用于实现大部分官方命令,并使用官方的语法和命令,Redis是StrictRedis的子类,兼容一些老版本。 Redis连接实例是线程安全的,可以直接将redis连接实例设置为一个全局变量,直接使用。
import redis"""Python3连接Redis操作StrictRedis跟Redis的区别在于,StrictRedis用于实现大部分官方命令,并使用官方的语法和命令,Redis是StrictRedis的子类,兼容一些老版本。Redis连接实例是线程安全的,可以直接将redis连接实例设置为一个全局变量,直接使用。
"""
print("当前python引入的Redis版本", redis.__version__)
linkRedis = None
try:linkRedis = redis.StrictRedis(host='192.168.1.111', port=6379, db=0) # 指定IP地址、端口、指定存放数据库# 如果指定一些其他参数,可以看源码,将需要的参数进行指定。print(linkRedis.dbsize())
except Exception as err:print("redis连接异常: ", err)
finally:if linkRedis is not None:print("释放连接资源")linkRedis.close()print("""连接池:redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。每个redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
""")pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)
redisLink = None
try:redisLink = redis.Redis(connection_pool=pool)
except Exception as err:print("redis连接异常: ", err)
finally:if linkRedis is not None:print("redis连接还给连接池")redisLink.close()运行效果:D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorLinkcreate.py
当前python引入的Redis版本 5.0.1
0
释放连接资源连接池:redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。每个redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。redis连接还给连接池Process finished with exit code 0二: Python操作Redis插入数据
import timeimport redis"""Python3连接Redis插入数据
"""
pool = None
redisLink = None
try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool)result = redisLink.set('key', '你好,欢迎来到Python3操作(Redis7.2.0)Redis应用') # key 代表是键 value:hello redis 代表是值print("""
字符串操作,redis中的String再内存中按照一个name对应一个value来存储。
set(name, value, ex=None, px=None, nx=False, xx=False)
再Redis中设置值,不存在则创建、存在即修改
参数:ex:过期时间(秒)px:过期时间(毫秒)nx:如果为True,当name不存在时,当前set操作会执行xx:如果为True,当name存在时,当前set操作会执行""")print(result) # 打印结果:True 说明设置成功print("获取Key对应的值: ", redisLink.get('key'))# ex: 设置过期时间(单位:秒) name为Key '老杨' 为valueredisLink.set("name", "老杨", ex=3)time.sleep(1)resultValue = redisLink.get('name')print("请叫我:%s" % resultValue)time.sleep(3)print("3秒后请叫我无名小卒")print('name = %s' % (redisLink.get('name')))except Exception as err:print("redis连接异常: ", err)
finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()运行效果:D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorInsert.py 字符串操作,redis中的String再内存中按照一个name对应一个value来存储。
set(name, value, ex=None, px=None, nx=False, xx=False)
再Redis中设置值,不存在则创建、存在即修改
参数:ex:过期时间(秒)px:过期时间(毫秒)nx:如果为True,当name不存在时,当前set操作会执行xx:如果为True,当name存在时,当前set操作会执行True
获取Key对应的值: 你好,欢迎来到Python3操作(Redis7.2.0)Redis应用
请叫我:老杨
3秒后请叫我无名小卒
name = None释放资源,连接还给连接池Process finished with exit code 0
三: Python3操作Redis查询数据
import time
import redis"""Python3连接Redis查询数据
"""
pool = None
redisLink = None
try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""getrange(key, start, end):获取子序列(根据字节获取,非字符)一个汉字3个字节 1个字母一个字节 每个字节8bit参数:name:redis的namestart:起始位置(字节)end:结束位置(字节)""")redisLink.set('detail', '详情信息')# 取索引号是0-2 前3位字节print(redisLink.getrange('detail', 0, 2))# 取所有的信息print(redisLink.getrange('detail', 0, -1))# 输出结果:详情信息redisLink.set('title', 'good')print(redisLink.getrange('title', 0, 2))# 输出结果:gooprint(redisLink.getrange('title', 0, -1))# 输出结果:goodprint()print("""incr(name, amount=1):自增name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自增数(必须是整数)""")print()# 自增name='incr' 每次自增 +1redisLink.incr('incr', amount=1)print(redisLink.get('incr'))# 输出结果:+1# 应用场景:记录页面的点击次数。print()print("""incrbyfloat(name, amount=1.0):自增name对应得值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自然数(浮点数)""")# 设置name='num'redisLink.set('num', '0.00')print(redisLink.get('num'))# 输出结果:0.00# 自增浮点数redisLink.incrbyfloat('num', amount=1.0)print(redisLink.get('num'))print("""decr(name, amout=1):自减name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自减数(整数)""")# 先查询name='num' 是否存在, 若存在 将对应的value 自减 1 ,不存在创建redisLink.decr('num', amount=1)print(redisLink.get('num'))# 输出结果: -1print()print("""append(key, value):再redis name对应的值后面追加内容参数:key:redis的namevalue:追加的字符串""")# 原name='name' 对应的value='老杨'redisLink.append('name', 'laogao')print('拼接后的字符串为: ', redisLink.mget('name'))# 输出结果:['老杨laogao'] 将value 拼接再一起print("操作列表")print()print("""lpush(name, values):从左边新增加,不存在就新建""")# 往name='list' 中从左添加value=[11, 22, 33]redisLink.lpush('list', 11, 22, 33)print(redisLink.lrange('list', 0, -1))# 输出结果:['33', '22', '11'] 保存顺序为 33,22,11print("""rpush(name, values):从右边新增加,不存在就新建""")# name='list1' 中从右添加value=[66, 55, 44]redisLink.rpush('list1', 66, 55, 44)print(redisLink.lrange('list1', 0, -1))# 输出结果:['66', '55', '44']print("""llen(name):获取列表长度""")# 获取name='list1' 列表中的长度 value=[66, 55, 44]print(redisLink.llen('list1'))# 输出结果: 3print("""lpushx(name, value):往已经有的name的列表的左边添加元素,没有的话无法创建""")# 首先redis数据库中没有name='list2'redisLink.lpushx('list2', 10)print(redisLink.lrange('list2', 0, -1))# 输出结果: []print("""rpushx(name, value):往已经有的name的列表的右边添加元素,没有的话无法创建""")# 首先redis数据库中没有name='list2'redisLink.rpushx('list2', '10')print(redisLink.lrange('list2', 0, -1))# 输出结果: []print("""linsert(name, where, refvalue, value):在name对应的列表的某一个值前或后插入一个新值参数:name:redis的namewhere:BEFORE或AFTERrefvalue:标杆值 (以它为基础, 前后插入新值)value:要插入的数据""")# 往列表中左边第一个出现的元素"66"前插入元素"77", 若name不存在, 不会新创建, 会返回[]redisLink.linsert('list1', 'before', '66', '77') # 目前数据库list1=[66, 55, 44]print(redisLink.lrange('list1', 0, -1))# 输出结果: ['77', '66', '55', '44']print("""lset(name, index, value):对name对应的list中的某一个索引位置重新赋值参数:name:redis的nameindex:list的索引位置value:要设置的新值""")# 将list1中索引为3, 替换成'33', list1=['77', '66', '55', '44']redisLink.lset('list1', 3, '33')print(redisLink.lrange('list1', 0, -1))# 输出结果: ['77', '66', '55', '33']print("""lrem(name, value, num):name对应的list中删除指定的值参数:name:redis的namevalue:要删除得值num:num=0,删除列表中所有的值num=2,从前向后,删除2个;num=-2, 从后向前,删除2个;""")# list1=['77', '66', '55', '33']# 从左向右, 找到value='66' 删除一个redisLink.lrem("list1", 1, "66")print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '55', '33']# list1=['77', '55', '33']# 从右向左, 找到value='55', 删除一个redisLink.lrem('list1', -1, '55')print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '33']# list1=['77', '77', '33']# 删除name='list1'中 value='77'的所有值redisLink.lrem('list1', 0, '77')print(redisLink.lrange('list1', 0, -1))# 输出结果:print("""lpop(name) 、rpop(name):在name对应的列表的左侧/右侧获取第一个元素并在列表中移除,返回值则是第一个元素""")# list1 = ['77', '66', '55']result = redisLink.lpop('list1')print(result) # 输出结果:77print(redisLink.lrange('list1', 0, -1)) # 输出结果:['66', '55']# list1 = ['66', '55']result = redisLink.rpop('list1')print(result) # 输出结果:55print(redisLink.lrange('list1', 0, -1)) # 输出结果:['66']print("""ltrim(name, start, end):name对应的列表中移除没有在start-end索引之间的值参数:name:redis的namestart:索引的起始位置end:索引的结束位置""")# list1=['77', '66', '55', '44', '33']# 删除name='list1'中, 不包含索引0-2的valueredisLink.ltrim('list1', 0, 2)print(redisLink.lrange('list1', 0, -1))# 输出结果:['77', '66', '55']print()print("""lindex(name, index):在name对应的列表中根据索引获取列表元素""")# list1=['77', '66', '55']# 取出name='list1'中索引为1的值print(redisLink.lindex('list1', 1)) # 输出结果:66print()print("""brpoplpush(src, dst, timeout=0):从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧参数:src:取出并要移除元素的列表对应的namedst:要插入元素的列表对应的nametimeout:当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞""")# list = ['33', '22', '11']# list1 = ['77', '66', '55']# 将name='list1' 中的Value 全部插入到name='list'中redisLink.brpoplpush('list1', 'list', timeout=2)print(redisLink.lrange('list', 0, -1))# 输出结果:['77', '66', '55', '33', '22', '11']except Exception as err:print("redis连接异常: ", err)
finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()运行效果:D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorQuery.py getrange(key, start, end):获取子序列(根据字节获取,非字符)一个汉字3个字节 1个字母一个字节 每个字节8bit参数:name:redis的namestart:起始位置(字节)end:结束位置(字节)详
详情信息
goo
goodincr(name, amount=1):自增name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自增数(必须是整数)26incrbyfloat(name, amount=1.0):自增name对应得值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自然数(浮点数)0.00
1decr(name, amout=1):自减name对应的值,当name不存在时,创建name=amount,存在则自增参数:name:redis的nameamount:自减数(整数)0append(key, value):再redis name对应的值后面追加内容参数:key:redis的namevalue:追加的字符串拼接后的字符串为: ['老杨laogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogaolaogao']
操作列表lpush(name, values):从左边新增加,不存在就新建['33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']rpush(name, values):从右边新增加,不存在就新建['33', '44', '33', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']llen(name):获取列表长度36lpushx(name, value):往已经有的name的列表的左边添加元素,没有的话无法创建[]rpushx(name, value):往已经有的name的列表的右边添加元素,没有的话无法创建[]linsert(name, where, refvalue, value):在name对应的列表的某一个值前或后插入一个新值参数:name:redis的namewhere:BEFORE或AFTERrefvalue:标杆值 (以它为基础, 前后插入新值)value:要插入的数据['33', '44', '33', '44', '55', '44', '77', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']lset(name, index, value):对name对应的list中的某一个索引位置重新赋值参数:name:redis的nameindex:list的索引位置value:要设置的新值['33', '44', '33', '33', '55', '44', '77', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']lrem(name, value, num):name对应的list中删除指定的值参数:name:redis的namevalue:要删除得值num:num=0,删除列表中所有的值num=2,从前向后,删除2个;num=-2, 从后向前,删除2个;['33', '44', '33', '33', '55', '44', '77', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '55', '44']
['33', '44', '33', '33', '55', '44', '77', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']
['33', '44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']lpop(name) 、rpop(name):在name对应的列表的左侧/右侧获取第一个元素并在列表中移除,返回值则是第一个元素33
['44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66', '44']
44
['44', '33', '33', '55', '44', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '55', '44', '66', '44', '66', '66']ltrim(name, start, end):name对应的列表中移除没有在start-end索引之间的值参数:name:redis的namestart:索引的起始位置end:索引的结束位置['44', '33', '33']lindex(name, index):在name对应的列表中根据索引获取列表元素33brpoplpush(src, dst, timeout=0):从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧参数:src:取出并要移除元素的列表对应的namedst:要插入元素的列表对应的nametimeout:当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞['33', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']释放资源,连接还给连接池Process finished with exit code 0
四: Python3操作Redis删除数据
import time
import redis"""Python3连接Redis删除数据
"""
pool = None
redisLink = None
try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""delete(*names) :根据删除redis中的任意数据类型(string、hash、list、set、有序set)""")result = redisLink.delete('hash1') # 删除key为hash1的键值对print(result)result = redisLink.delete('name') # 删除key为name的值对print(result)result = redisLink.delete('list1') # 删除key为list1的值对print(result)
except Exception as err:print("redis连接异常: ", err)
finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()运行效果D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorDelete.py delete(*names) :根据删除redis中的任意数据类型(string、hash、list、set、有序set)0
1
1释放资源,连接还给连接池Process finished with exit code 0五: Python3操作Redis常规操作
import redis"""Python3常规操作数据
"""
pool = None
redisLink = None
try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""exists(name):检测redis的name是否存在,存在就是True,False 不存在""")print(redisLink.exists('hash1')) # 输出结果:False 说明key 不存在print(redisLink.exists('set1')) # 输出结果:True 说明key存在print(redisLink.exists('list1')) # 输出结果:True 说明key存在print(redisLink.exists('name')) # 输出结果:True 说明key存在print()print("""expire(name ,time) :为某个redis的某个name设置超时时间""")redisLink.lpush('list5', 11, 22)redisLink.expire('list5', time=3)print(redisLink.lrange('list5', 0, -1))# 输出结果:['22', '11']import timetime.sleep(3)print(redisLink.lrange('list5', 0, -1))# 输出结果:[]print()print("""rename(src, dst) :对redis的name重命名""")redisLink.lpush('list5', 11, 22)print(redisLink.rename('list5', 'list-5'))# 输出结果: True 说明重命名成功print("""type(name) :获取name对应值的类型""")print("""查看所有元素""")print(redisLink.hscan("hash"))print(redisLink.sscan("set"))print(redisLink.zscan("zset"))print(redisLink.getrange("string", 0, -1))print(redisLink.lrange("list", 0, -1))print(redisLink.smembers("set3"))print(redisLink.zrange("zset3", 0, -1))print(redisLink.hgetall("hash1"))
except Exception as err:print("redis连接异常: ", err)
finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()运行效果:D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorUpdate.py exists(name):检测redis的name是否存在,存在就是True,False 不存在0
0
0
1expire(name ,time) :为某个redis的某个name设置超时时间['22', '11']
[]rename(src, dst) :对redis的name重命名Truetype(name) :获取name对应值的类型查看所有元素(0, {})
(0, [])
(0, [])['33', '33', '22', '11', '33', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11', '33', '22', '11']
set()
[]
{}释放资源,连接还给连接池Process finished with exit code 0
六: Python3操作Redis对Set集合操作
import time
import redis"""Python3连接Redis集合Set数据操作
"""
pool = None
redisLink = None
try:pool = redis.ConnectionPool(host='192.168.1.111', port=6379, decode_responses=True)redisLink = redis.Redis(connection_pool=pool, encoding='UTF-8')print("""sadd(name, values):name对应的集合中添加元素""")# 往集合中添加元素 name='set1'redisLink.sadd('set1', 1, 2, 3, 4, 5, 6)print(redisLink.smembers('set1'))# 输出结果:set(['1', '3', '2', '5', '4', '6'])print("""scard(name):name对应集合中元素个数""")# 'set1' = set(['1', '3', '2', '5', '4', '6'])print(redisLink.scard('set1'))# 输出结果: 6print("""smembers(name):name对应的集合所有成员""")# 获取name='set1' 中的所有values值print(redisLink.smembers('set1'))# 输出结果: set(['1', '3', '2', '5', '4', '6'])print("""sscan(name, cursor=0, match=None, count=None):name对应集合所有成员(元组形式)""")print(redisLink.sscan('set1'))# 输出结果:(0L, ['1', '2', '3', '4', '5', '6'])print("""sscan_iter(name, match=None, count=None):name对应集合所有成员(迭代器的方式)""")for item in redisLink.sscan_iter('set1'):print(item)print("""sdiff(key, *args):求集合中的差集""")# name是set1、set2中values的值# set1 = set(['1', '3', '2', '5', '4', '6'])# set2 = set(['8', '5', '7', '6'])# 在集合set1中但是不在集合set2中的values值print(redisLink.sdiff('set1', 'set2'))# 输出结果:set(['1', '3', '2', '4'])# 在集合set2中但是不在集合set1中的values值print(redisLink.sdiff('set2', 'set1'))# 输出结果:set(['8', '7'])print("""sdiffstore(dest, keys, *args):将两个集合中的差集,存储到第三个集合中""")# 在集合set1但是不再集合set3中的values值, 存储到set3集合中redisLink.sdiffstore('set3', 'set1', 'set2')print(redisLink.smembers('set3'))# 输出结果:set(['1', '3', '2', '4'])print("""sinter(keys,*args):获取两个集合中的交集""")# 求集合set1与set2的交集print(redisLink.sinter('set1', 'set2'))print("""sunion(keys, *args):获取多个name对应的集合并集""")# 获取set1与set2集合中的并集print(redisLink.sunion('set1', 'set2'))# 输出结果:set(['1', '3', '2', '5', '4', '7', '6', '8'])print("""sunionstore(dest, keys, *args):将两个集合中的并集,存储到第三个集合中""")# 将set1与set2集合中的并集, 存储到set3中print(redisLink.sunionstore('set3', 'set1', 'set2'))print(redisLink.smembers('set3'))# 输出结果:set(['1', '3', '2', '5', '4', '7', '6', '8'])print("""sismember(name, value):判断是否是集合的成员""")# 校验value=3 是否在name=set1集合中print(redisLink.sismember('set1', 3))# 输出结果:True表示在集合中print(redisLink.sismember('set1', 33))# 输出结果: False表示不在集合中print("""smove(src, dst, value):将某个成员从一个集合中移动到另外一个集合""")# 目前集合set1、set2中的元素# set1=set(['1', '3', '2', '5', '4', '6'])# set2=set(['8', '5', '7', '6'])# 将set1中的value=4的元素, 移动到set2集合中redisLink.smove('set1', 'set2', 4)print(redisLink.smembers('set1'))# 输出结果:set(['1', '3', '2', '5', '6'])print(redisLink.smembers('set2'))# 输出结果:set(['8', '5', '4', '7', '6'])print("""spop(name):从集合移除一个成员, 并将其返回(集合是无序的,所有移除也是随机的)""")# 目前set1集合中元素 set1=set(['1', '3', '2', '5', '6'])# 随机删除'set1'中的Value值print(redisLink.spop('set1'))# 输出结果:1 说明删除的个数print(redisLink.smembers('set1'))# 输出结果:set(['3', '2', '5', '6'])print("""srem(name, values):在name对应的集合中删除某些值""")# 目前set1=set(['3', '2', '5', '6'])print(redisLink.srem('set1', 2))# 输出结果:1print(redisLink.smembers('set1'))# 输出结果:set(['3', '5', '6'])except Exception as err:print("redis连接异常: ", err)
finally:print()if redisLink is not None:print("释放资源,连接还给连接池")redisLink.close()运行效果:D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\ClassGrammarRedisExecutorSet.py sadd(name, values):name对应的集合中添加元素{'1', '4', '6', '2', '5', '3'}scard(name):name对应集合中元素个数6smembers(name):name对应的集合所有成员{'1', '4', '6', '2', '5', '3'}sscan(name, cursor=0, match=None, count=None):name对应集合所有成员(元组形式)(0, ['1', '2', '3', '4', '5', '6'])sscan_iter(name, match=None, count=None):name对应集合所有成员(迭代器的方式)1
2
3
4
5
6sdiff(key, *args):求集合中的差集{'1', '6', '2', '5', '3'}
set()sdiffstore(dest, keys, *args):将两个集合中的差集,存储到第三个集合中{'1', '6', '2', '5', '3'}sinter(keys,*args):获取两个集合中的交集{'4'}sunion(keys, *args):获取多个name对应的集合并集{'1', '4', '6', '2', '5', '3'}sunionstore(dest, keys, *args):将两个集合中的并集,存储到第三个集合中6
{'1', '4', '6', '2', '5', '3'}sismember(name, value):判断是否是集合的成员1
0smove(src, dst, value):将某个成员从一个集合中移动到另外一个集合{'1', '6', '2', '5', '3'}
{'4'}spop(name):从集合移除一个成员, 并将其返回(集合是无序的,所有移除也是随机的)1
{'5', '3', '2', '6'}srem(name, values):在name对应的集合中删除某些值1
{'5', '3', '6'}释放资源,连接还给连接池Process finished with exit code 0
忙着去耍帅, 后期有时间补充完整......................
相关文章:
Python3操作Redis最新版|CRUD基本操作(保姆级)
Python3中类的高级语法及实战 Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案 Python3数据科学包系列(一):数据分析实战 Python3数据科学包系列(二):数据分析实战 Python3数据科学包系列(三):数据分析实战 Win11查看安装的Python路…...

微信又被吐槽了,委屈啊
昨天的时候,一打开微博热搜榜,一看,微信又被吐槽了,微信占用存储这件事几乎年年会被骂,几乎也会年年被吐槽。 这次的起因呢,是一个人整理了一个方法:「微信内存从 126G 清理到 75G 我是怎么做到…...

刷题笔记27——并查集
很长一段时间,我的生活看似马上就要开始了。但是总有一些障碍阻挡着,有些事得先解决,有些工作还有待完成,时间貌似不够用,还有一笔债务8要去付清,然后生活就会开始。最后我终于明白,这些障碍&am…...

Python 模拟类属性
文章目录 模拟类属性的原因模拟类属性的可能解决方案使用 PropertyMock 模拟类属性在不使用 PropertyMock 的情况下模拟类属性Python 模拟类构造函数使用 patch.object 装饰器来修补构造函数本文的主要目的是介绍如何使用 python 单元测试模块 unittest 操作类属性以进行测试和…...
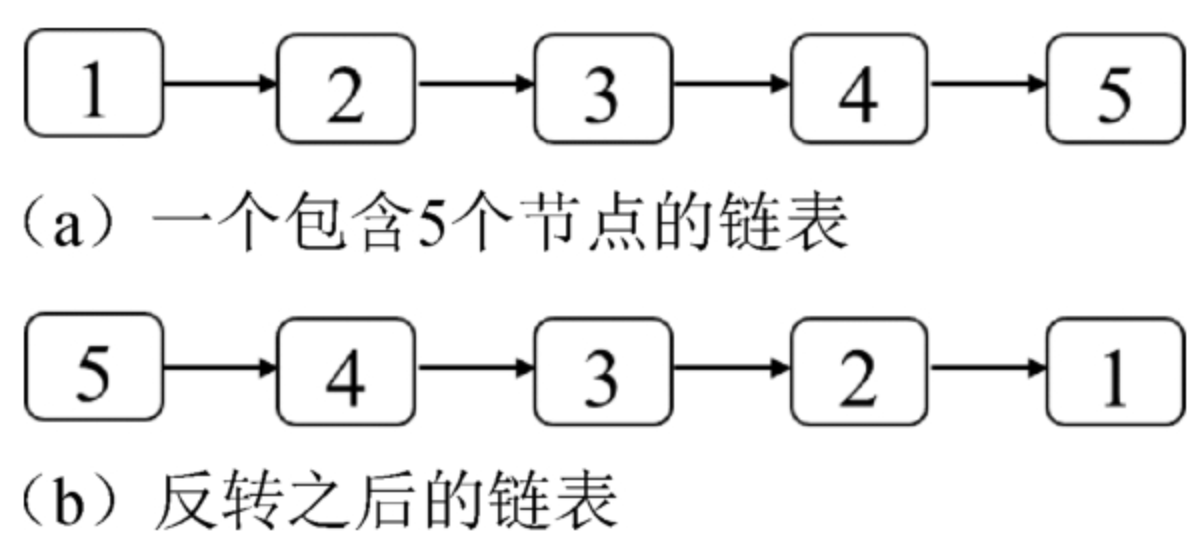
面试算法24:反转链表
题目 定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。例如,把图4.8(a)中的链表反转之后得到的链表如图4.8(b)所示。 分析 由于节点j的next指针指向了它的前一个节…...
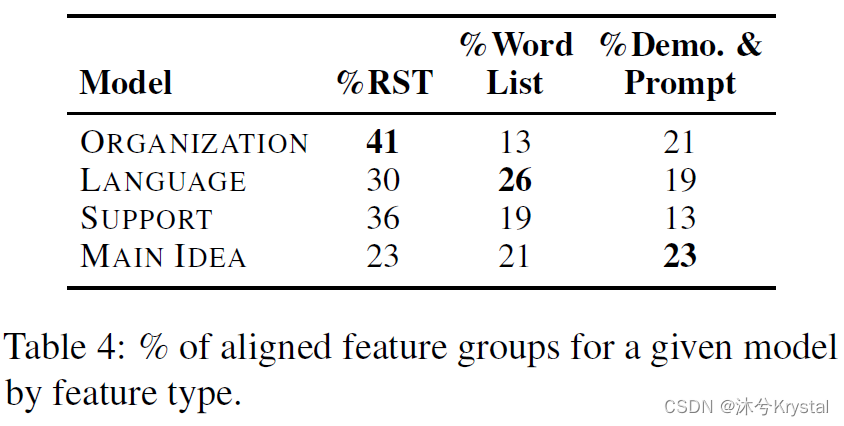
【论文阅读】面向抽取和理解基于Transformer的自动作文评分模型的隐式评价标准(实验结果部分)
方法 结果 在这一部分,我们展示对于每个模型比较的聚合的统计分析当涉及到计算特征和独立的特征组(表格1),抽取功能组和对齐重要功能组(表格2),并且最后,我们提供从模型比较&#x…...
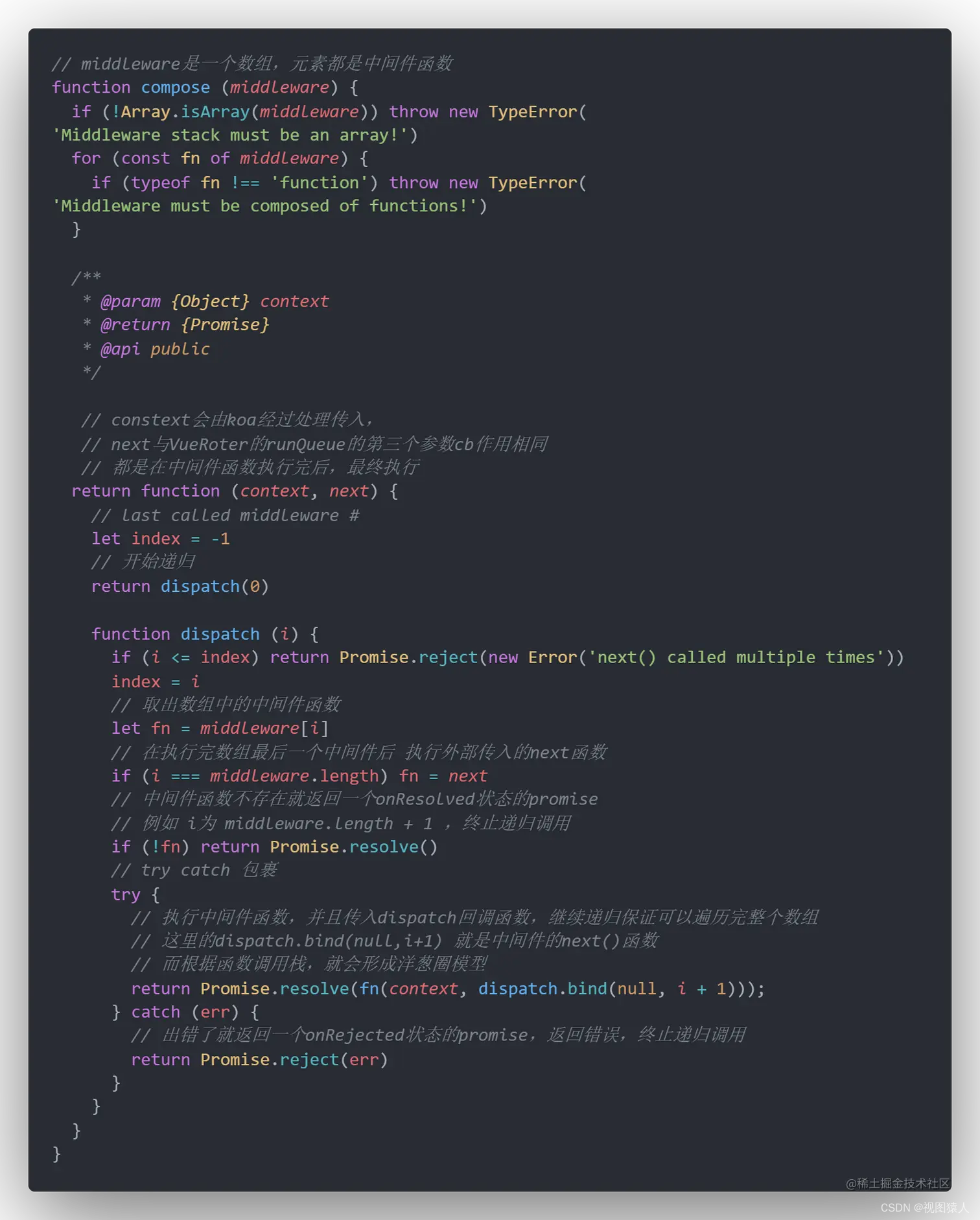
VueRouter与expres/koa中间件的关联
ueRouter: runQueue 路由守卫都是有三个参数to,from,next。其中next就是下方的fn执行时候传入的第二个参数(回调函数),只有该回调执行后才会挨个遍历queue内的守卫。 中间件的作用 隔离基础设施与业务逻辑之间的细节。详细的内容位于《深入浅出Node.js》P210 另外一…...
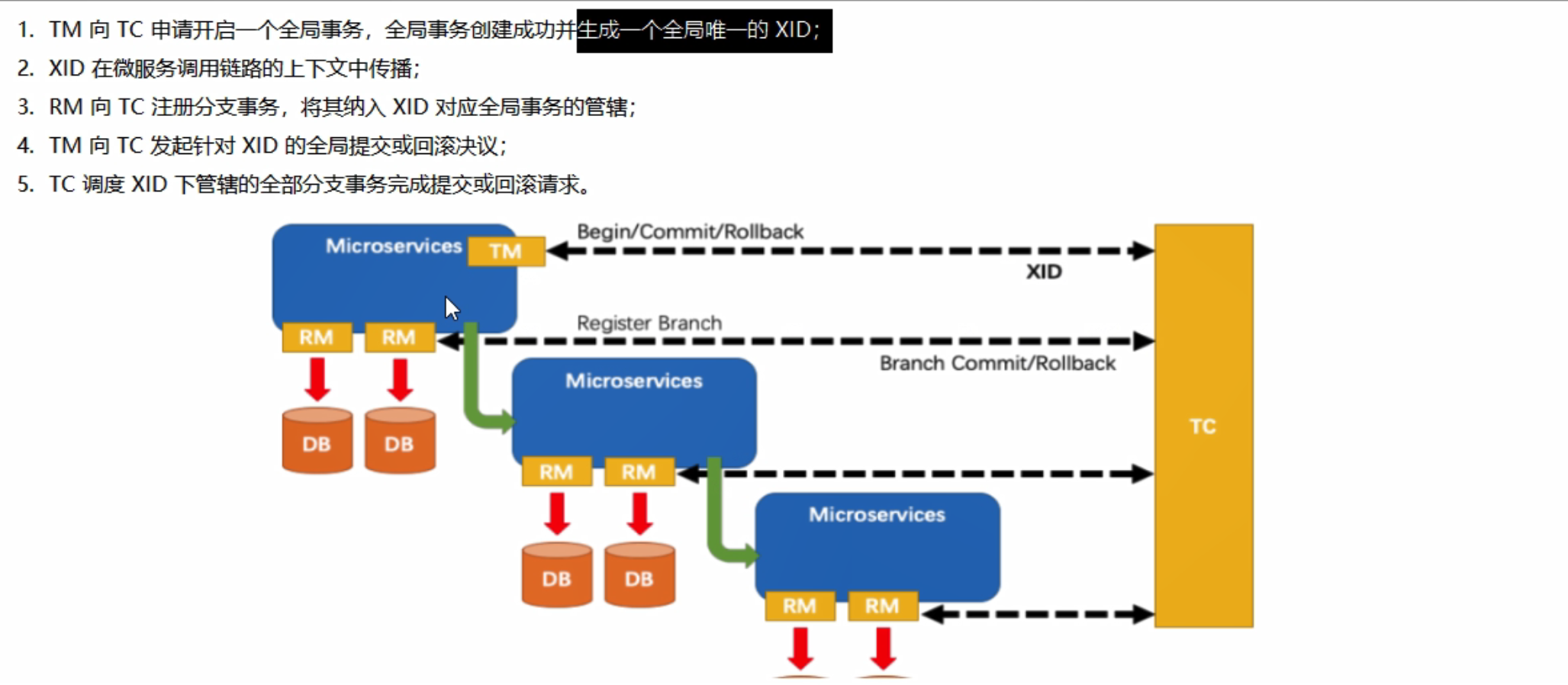
二十、SpringCloud Alibaba Seata处理分布式事务
目录 一、分布式事务问题1、分布式之前2、分布式之后 二、Seata简介1、Seata是什么?2、Seata能干嘛?3、去拿下?4、怎么玩 三、Seata-server安装四、订单、库存、账户业务数据库准备五、订单、库存、账户业务微服务准备六、Seata原理介绍 一、…...

标准误与聚类稳健标准误的理解
1 标准误 1.1 定义 标准误(Standard Error)是用来衡量统计样本估计量(如均值、回归系数等)与总体参数之间的差异的一种统计量。标准误衡量了样本估计量的变异程度,提供了对总体参数的估计的不确定性的度量。标准误越…...

【Github】将本地仓库同步到github上
许久没有用GitHub了,怎么传仓库都忘记了。在这里记录一下 If you have a local folder on your machine and you want to transform it into a GitHub repository, follow the steps below: 1. Install Git (if not already installed) Make sure you have Git in…...

c++视觉--通道分离,合并处理,在分离的通道中的ROI感兴趣区域里添加logo图片
c视觉–通道分离,合并处理 通道分离: split()函数 #include <opencv2/opencv.hpp>int main() {// 读取图像cv::Mat image cv::imread("1.jpg");// 检查图像是否成功加载if (image.empty()) {std::cerr << "Error: Could not read the…...

python爬虫:多线程收集/验证IP从而搭建有效IP代理池
目录 一、前言 二、IP池的实现 1. 收集代理IP 2. 验证代理IP可用性 3. 搭建IP代理池 三、多线程实现 四、代理IP的使用 五、总结 一、前言 在网络爬虫中,IP代理池的作用非常重要。网络爬虫需要大量的IP地址来发送请求,同时为了降低被封禁的风险…...

阻塞队列以及阻塞队列的一个使用
阻塞队列以及阻塞队列的一个使用 阻塞队列简介 阻塞队列(Blocking Queue)是一种常见的队列数据结构,它具有特殊的行为,可以用于多线程编程中,以协调不同线程之间的任务执行和数据传递。阻塞队列在多线程环境中非常有…...
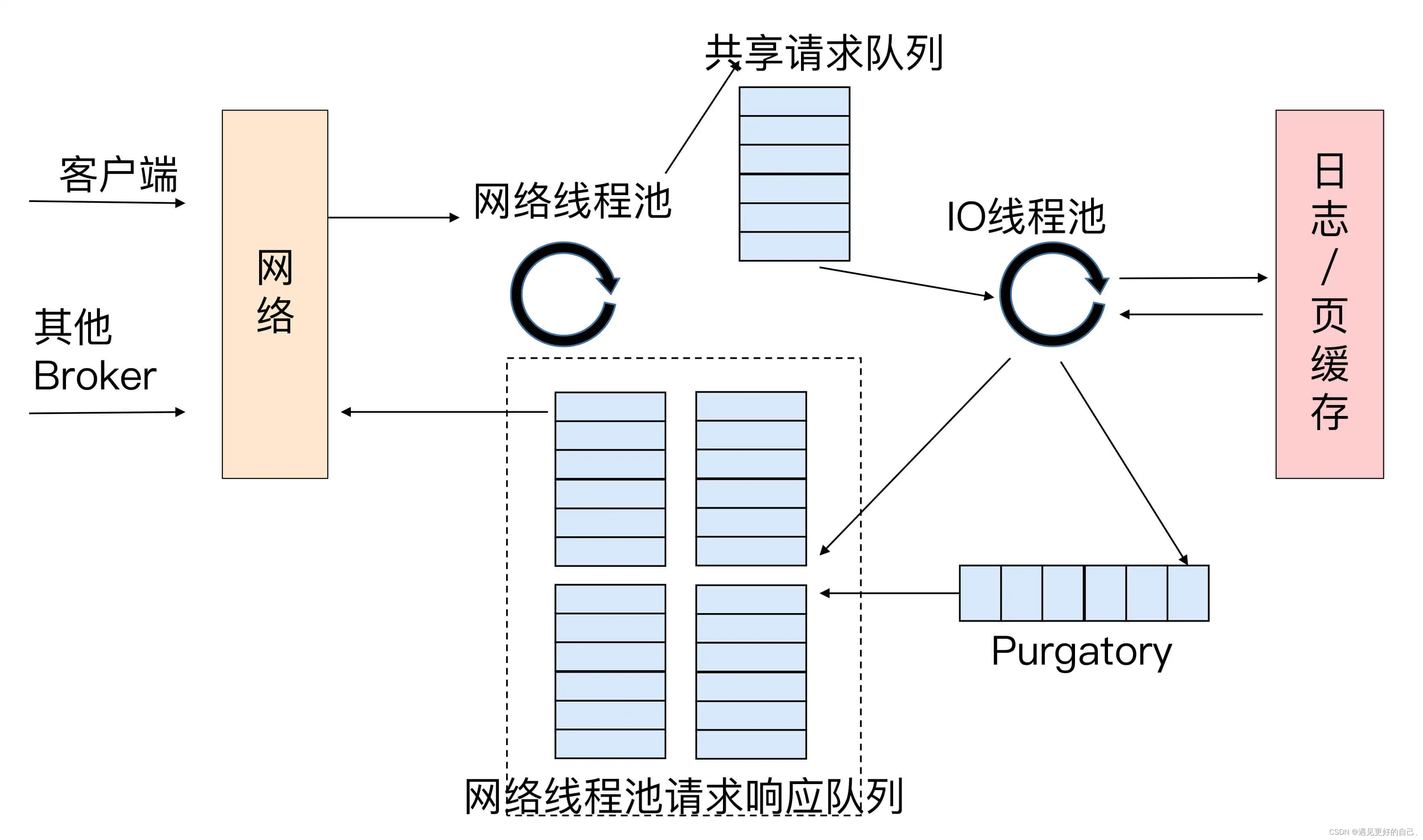
kafka的请求处理机制
目录 前言: kafak是如何处理请求的? 控制请求与数据类请求 参考资料 前言: 无论是 Kafka 客户端还是 Broker 端,它们之间的交互都是通过“请求 / 响应”的方式完成的。比如,客户端会通过网络发送消息生产请求给 B…...
Linux系统管理:虚拟机Centos Stream 9安装
目录 一、理论 1.Centos Stream 9 二、实验 1.虚拟机Centos Stream 9安装准备阶段 2.安装Centos Stream 9 3.进入系统 一、理论 1.Centos Stream 9 (1) 简介 CentOS Stream 是一种 Linux 操作系统。安装此操作系统的难题在于,在安装此系统之前,…...

5种排序算法
文章目录 一,排序算法时间复杂度比较二,插入排序三,冒泡排序四,快速排序五,堆排序六,二分归并排序 一,排序算法时间复杂度比较 算法最坏情况下平均情况下插入排序O(n )O(n)冒泡排序O(n)O(n)快速…...
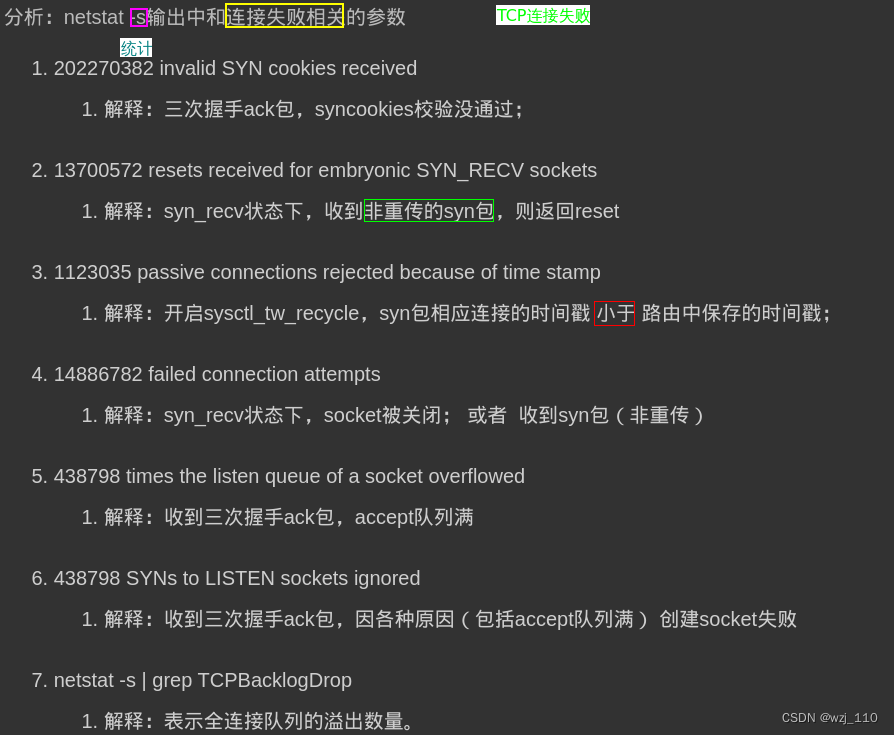
TCP/IP(七)TCP的连接管理(四)
一 全连接队列 nginx listen 参数backlog的意义 nginx配置文件中listen后面的backlog配置 ① TCP全连接队列概念 全连接队列: 也称 accept 队列 ② 查看应用程序的 TCP 全连接队列大小 实验1: ss 命令查看 LISTEN状态下 Recv-Q/Send-Q 含义附加:…...
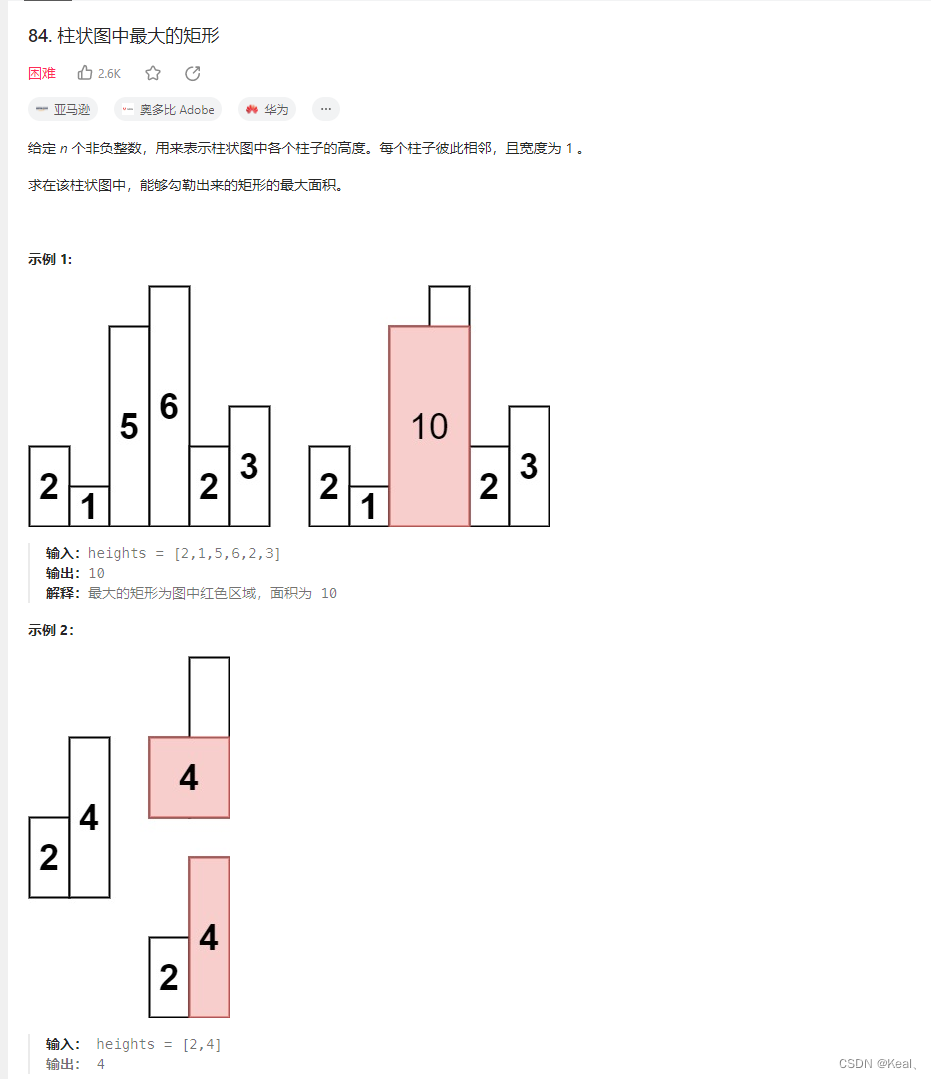
LeetCode【84】柱状图中的最大矩形
题目: 思路: https://blog.csdn.net/qq_28468707/article/details/103682528 https://www.jianshu.com/p/2b9a36a548fa 清晰 代码: public int largestRectangleArea(int[] heights) {int[] heightadd new int[heights.length 1];for (i…...

C++:关于模拟实现vector和list中迭代器模块的理解
文章目录 list和vector的迭代器对比list的实现过程完整代码 本篇是关于vector和list的模拟实现中,关于迭代器模块的更进一步理解,以及在前文的基础上增加对于反向迭代器的实现和库函数的对比等 本篇是写于前面模拟实现的一段时间后,重新回头…...
HTML 笔记 表格
1 表格基本语法 tr:table row th:table head 2 表格属性 2.1 基本属性 表格的基本属性是指表格的行、列和单元格但并不是每个表格的单元格大小都是统一的,所以需要设计者通过一些属性参数来修改表格的样子,让它们可以更更多样…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣
NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为NS模拟器的复杂配置而头疼吗?每次想玩Swit…...

yuzu模拟器:在PC上完美运行Switch游戏的终极解决方案
yuzu模拟器:在PC上完美运行Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想要在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器作为目前最成熟的开源Switch模拟…...

如何永久备份微信聊天记录:3步完成数据导出的终极指南
如何永久备份微信聊天记录:3步完成数据导出的终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...