DiffusionDet:第一个用于物体检测的扩散模型(DiffusionDet: Diffusion Model for Object Detection)
提出了一种新的框架——DiffusionDet,它将目标检测定义为一个从有噪声的盒子到目标盒子的去噪扩散过程。在训练阶段,目标盒从真实值盒扩散到随机分布,模型学会了逆转这个噪声过程。
在推理中,该模型以渐进的方式将一组随机生成的框细化为输出结果。
贡献:
- 我们将目标检测制定为生成式去噪过程,这是据我们所知第一个将扩散模型应用于目标检测的研究。
- 我们的噪声到框检测范例具有几个吸引人的特性,例如动态框的解耦训练和评估阶段以及迭代评估。
- 我们对COCO、CrowdHuman 和LVIS 基准进行了广泛的实验。与之前成熟的检测器相比,DiffusionDet 取得了良好的性能,尤其是跨不同场景的zero-shot transferring。
1、介绍
之前存在的问题:
DETR提出了可学习的目标查询,消除了手工设计的组件,建立了端到端检测管道,引起了极大的关注。虽然这些工作实现了简单而有效的设计,但它们仍然依赖于一组固定的可学习查询。一个自然的问题是:有没有一种更简单的方法,甚至不需要可学习查询的代理?
为了回答这个问题,我们设计了一个新的框架,它可以直接从一组随机盒子中检测对象。从纯随机盒子开始,不包含训练阶段需要优化的可学习参数,我们期望逐步细化这些盒子的位置和大小,直到它们完美覆盖目标对象。这种噪声盒方法既不需要启发式目标先验,也不需要可学习查询,进一步简化了目标候选,并推动了检测基线的发展。
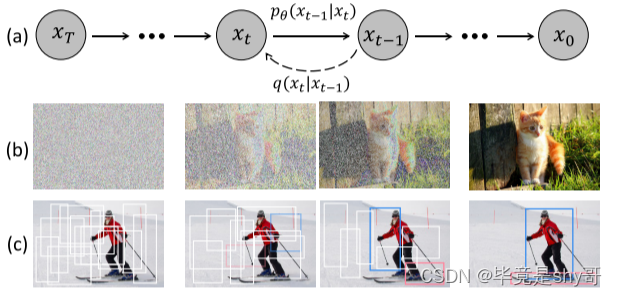
图1。用于目标检测的扩散模型。(a)扩散模型,其中q是扩散过程,pθ是相反过程。(b)图像生成任务的扩散模型。©我们建议将目标检测作为去噪扩散过程,从有噪声的箱子到目标箱子。
我们的动机如图1所示。我们认为noise-to-box范式的原理类似于去噪扩散模型中的noise-to-image过程,这是一类基于似然的模型,通过学习的去噪模型逐渐去除图像中的噪声,从而生成图像。扩散模型在许多生成任务中都取得了很大的成功,并开始在图像分割等感知任务中得到探索。然而,就我们所知,还没有先前技术成功地将其应用于目标检测。
在这项工作中,我们提出了 DiffusionDet,它通过将检测任务作为 图像中 边界框的位置(中心坐标)和大小(宽度和高度)在空间上的 生成任务,使用扩散模型来处理对象检测任务。
在训练阶段,将由方差表控制的高斯噪声添加到真实图片框以获得噪声框。
然后,这些噪声框用于从主干编码器的输出特征图中裁剪 感兴趣区域(RoI)的特征,例如 ResNet 、Swin Transformer 。
最后,这些 RoI 特征被送到检测解码器,该解码器经过训练可以预测无噪声的真实框。通过这个训练目标,DiffusionDet 能够从随机框中预测真实框。
在推理阶段,DiffusionDet 通过反转学习的扩散过程来生成边界框,该过程将噪声先验分布调整为边界框上的学习分布。
作为一种概率模型,DiffusionDet 具有令人着迷的灵活性优势,即我们可以训练一次网络,并在推理阶段的不同设置下使用相同的网络参数,主要包括:
(1)动态框数。利用随机框作为候选对象,我们解耦了 DiffusionDet 的训练和评估阶段,即我们可以用 N t r a i n \ N_ {train}\, Ntrain 个随机框训练 DiffusionDet,同时用 N e v a l \ N_ {eval}\, Neval 个随机框评估它,其中 N e v a l \ N_ {eval}\, Neval 是任意的,不需要等于 N t r a i n \ N_ {train}\, Ntrain。
(2)迭代评估。受益于扩散模型的迭代去噪特性,DiffusionDet可以迭代地重用整个检测头,进一步提高其性能。
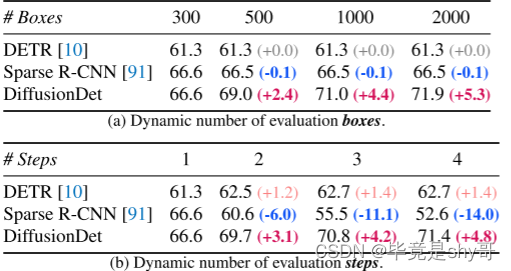
表 1. Zero-shot transfer from COCO to CrowdHuman visible box detection.所有模型均使用 300 个盒子进行训练,并使用不同数量的盒子和步骤进行测试。
DiffusionDet的灵活性使得它在探测不同场景(如稀疏或拥挤)中的对象时具有很大的优势,而无需进行额外的微调。具体来说,从表1可以看出,在CrowdHuman数据集上直接对COCOpretraiend模型进行评估时,difffusiondet通过调整评估框的数量和迭代步骤,获得了显著的收益。相比之下,以前的方法只能获得边际增益,甚至性能下降。
此外,我们在 COCO 数据集上评估 DiffusionDet。借助 ResNet-50 主干,DiffusionDet 使用单个采样步骤和 300 个随机框实现了 45.8 AP,显着优于 Faster RCNN (40.2 AP)、DETR (42.0 AP),与 Sparse R 相当-CNN (45.0 AP)。此外,我们可以通过增加采样步骤和随机框的数量,将 DiffusionDet 进一步提高到 46.8 AP。
2、方法
2.1 扩散模型介绍
在本工作中,我们的目标是通过扩散模型来解决目标检测任务。
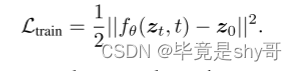
在我们的设置中,数据样本是一组包围框 z 0 \ z_0\, z0 = b,其中b∈ R N X 4 \R^{NX4}\, RNX4是一组N个框。
训练神经网络 f θ \ f_θ\, fθ(zt, t, x),以对应的图像x为条件,从噪声箱 z t \ z_t\, zt预测 z 0 \ z_0\, z0,并相应地产生相应的类别标签c。
在训练过程中,训练神经网络 f θ \ f_θ\, fθ(zt, t)通过使训练目标loss最小化,从 z t \ z_t\, zt预测 z 0 \ z_0\, z0.
在推理阶段,利用模型fθ和更新规则对噪声 z t \ z_t\, zt进行数据样本 z 0 \ z_0\, z0.的迭代重构,即:zT→zT−∆→…→z0。
在本工作中,我们的目标是通过扩散模型来解决目标检测任务。在我们的设置中,数据样本是一组包围框z0 = b,其中b∈RN×4是一组N个框。训练神经网络fθ(zt, t, x),以对应的图像x为条件,从噪声箱zt预测z0,并相应地产生相应的类别标签c。
2.2 模型架构
由于扩散模型迭代生成数据样本,在推断阶段需要多次运行模型Fθ。 然而,在每一个迭代步骤中直接对原始图像应用fθ在计算上是困难的。 因此,我们提出将整个模型分为图像编码器和检测解码器两个部分,前者只运行一次,从原始输入图像X中提取深度特征表示,后者以该深度特征为条件,而不是原始图像,从噪声盒ZT中逐步细化盒预测。
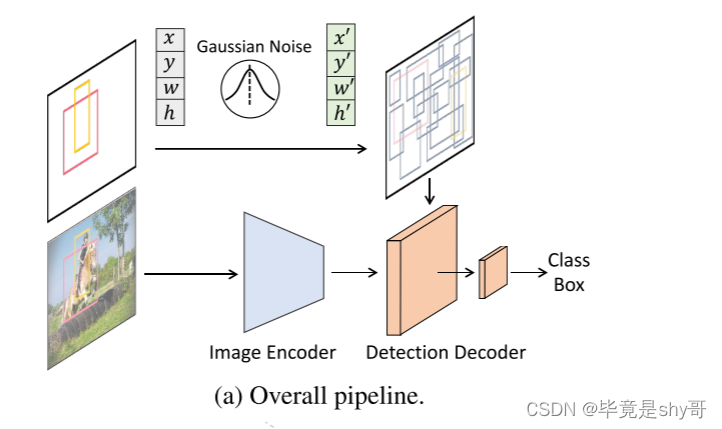
DiffusionDet 框架。 (a) 图像编码器从输入图像中提取特征表示。检测解码器将噪声框作为输入并预测类别分类和框坐标。
2.2.1 图像编码器
图像编码器将原始图像作为输入,提取其高级特征用于后续检测解码器。
我们使用卷积神经网络(如ResNet)和基于基于Transformer模型(如Swin)实现了扩散。
特征金字塔网络用于生成ResNet和Swin骨干网的多尺度特征特征图。
2.2.2 检测解码器
检测解码器借鉴Sparse R-CNN,将一组proposal box作为输入,从图像编码器生成的feature map中裁剪RoI-feature,并将这些RoI-feature发送到检测头,得到box回归和分类结果。
对于扩散问题,这些建议盒在训练阶段受到真实标记的图像盒的干扰,在评估阶段直接从高斯分布中采样。
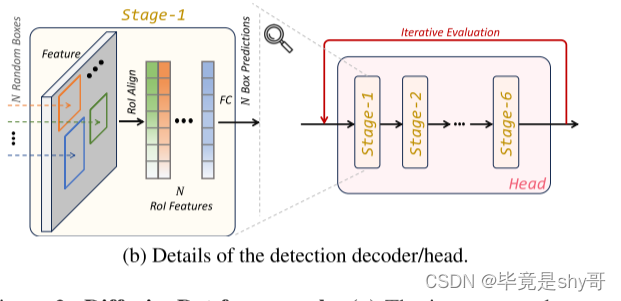
(b) 检测解码器在一个检测头中有 6 个阶段,遵循 DETR 和 Sparse R-CNN。此外,DiffusionDet可以多次重复使用这个检测头(有6个阶段),这被称为“迭代评估”。
在DETR或sparse r-cnn或deformable DETR之后,我们的检测解码器由6个级联阶段组成(图b)。
我们的解码器与Sparse R-CNN解码器的不同之处在于:
(1)DiffusionDet从随机的盒子开始,而Sparse R-CNN在推理中使用的是一组固定的学习的盒子;
(2)稀疏RCNN将建议盒及其对应建议特征作为输入对,DiffusionDet只需要建议盒;
(3) difffusiondet可以以迭代的方式重用检测器头进行评估,在不同的步骤中共享参数,每个步骤通过时间步嵌入指定为扩散过程,称为迭代评估,而Sparse R-CNN在前向传递中只使用一次检测解码器。
2.3 训练
在训练过程中,我们首先构建从真实框到噪声框的扩散过程,然后训练模型来反转该过程。算法 1 提供了 DiffusionDet 训练过程的伪代码。
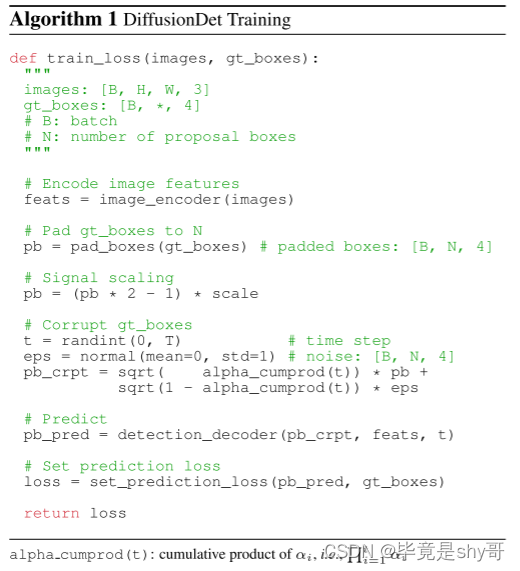
输入参数:
images: 输入图像数据,形状为[B, H, W, 3],表示批次中的图像数量及其高度、宽度以及通道数。
gt_boxes: 真实边界框数据,形状为[B, *, 4],表示批次中每个图像所对应的真实边界框数量(可以是不同数量),每个边界框包含四个坐标。
算法步骤:
对输入图像进行特征编码(通过图像编码器)得到特征表示feats。
将gt_boxes进行填充到同样数量N(proposal boxes的数量)的边界框pb(通过pad_boxes函数),使得每个图像具有相同数量的边界框。
对pb进行信号缩放,将其值从[0, 1]范围内映射到[-scale, scale]范围内。
随机选择一个时间步长t(从0到T)。
生成服从正态分布的噪声eps(均值为0,标准差为1),其维度为[B, N, 4],用于损坏(corrupt)gt_boxes。
基于当前的时间步长t和信号缩放后的gt_boxes(pb),使用DiffusionDet中的alpha_cumprod函数生成混合因子,对pb和eps进行组合得到损坏的边界框pb_crpt。
基于损坏的边界框pb_crpt和特征表示feats,通过检测解码器detection_decoder生成预测的边界框pb_pred。
计算预测边界框pb_pred与真实边界框gt_boxes之间的损失(通过set_prediction_loss函数)。
返回计算得到的损失(loss)作为训练损失。
3.3.1 图片真实框填充(Ground truth boxes padding)
对于现代目标检测基准,感兴趣的实例数量通常因图像而异。因此,我们首先将一些额外的框填充到原始的groundtruth框,使得所有框加起来为固定数量的Ntrain。我们探索了几种填充策略,例如,重复现有的地面实况框、连接随机框或图像大小的框。连接随机框效果最好。
3.3.2 Box corruption.
我们将高斯噪声添加到填充的真实框中。噪声尺度由αt控制,αt在不同时间步t中采用单调递减的余弦时间表。值得注意的是,地面实况框坐标也需要缩放,因为信噪比对扩散模型的性能有显着影响。我们观察到,与图像生成任务相比,目标检测有利于相对较高的信号缩放值。
3.3.3 训练损失
检测检测器将被破坏的框作为输入,并预测类别分类和框坐标的Ntrain预测。我们将预测损失集应用于 Ntrain 预测集。我们通过最佳传输分配方法选择成本最低的前 k 个预测,为每个基本事实分配多个预测 。
3.4 推断
DiffusionDet的推理过程是从噪声到目标框的去噪采样过程。从高斯分布中采样的框开始,模型逐步完善其预测,如算法 2 所示。

输入参数:
images: 输入图像数据,形状为[B, H, W, 3],表示批次中的图像数量及其高度、宽度以及通道数。
steps: 采样步数,即需要采样多少个时间步长。
T: 总时间步长。
算法步骤:
对输入图像进行特征编码(通过图像编码器)得到特征表示feats。
生成服从正态分布的噪声pb_t(均值为0,标准差为1),其维度为[B, N, 4],用于初始化边界框预测。
使用linespace生成一个等分线段,其从 -1 开始,到 T 结束,等分成steps份。并且在[0, T]内生成随机时间t_now。
对每个时间区间(t_now, t_next)执行如下操作: a. 基于当前的时间步长t_now和噪声pb_t,通过检测解码器detection_decoder生成预测的边界框pb_pred。 b. 基于预测边界框pb_pred和当前时间t_now以及向前时间t_next,使用ddim_step函数估计t_next时刻的边界框pb_t。 c. 使用box_renewal函数更新边界框pb_t(指将pb_t中的值限制在[0, 1]内)。
返回最终的预测结果pb_pred。
3.4.1 取样步骤
在每个采样步骤中,上一个采样步骤的随机框或估计框被发送到检测解码器以预测类别分类和框坐标。
获得当前步骤的框后,采用DDIM来估计下一步的框。
我们注意到,将没有 DDIM 的预测框发送到下一步也是一种可选的渐进式细化策略。但它会带来显着的恶化。
3.4.2 Box更新
在每个采样步骤之后,预测框可以粗略地分为两种类型:期望的预测和不需要的预测。
所需的预测包含正确位于相应对象处的框,而不需要的预测则任意分布。
直接将这些不需要的框发送到下一次采样迭代不会带来任何好处,因为它们的分布不是由训练中的框损坏构建的。
为了使推理更好地与训练保持一致,我们提出了框更新策略,通过用随机框替换这些不需要的框来恢复它们。
具体来说,我们首先过滤掉分数低于特定阈值的不需要的框。
然后,我们将剩余的框与从高斯分布中采样的新随机框连接起来。
3.4.3 灵活运用
由于随机框的设计,我们可以使用任意数量的随机框和迭代次数来评估 DiffusionDet,而无需等于训练阶段。
作为比较,以前的方法在训练和评估期间依赖相同数量的处理框,并且它们的检测解码器在前向传递中仅使用一次。
3.5 讨论
我们对 DiffusionDet 和之前的多级检测器进行了比较分析 。
Cascade R-CNN 采用三阶段预测细化过程,其中三个阶段不共享参数,并且在推理阶段仅用作完整的头一次。
最近的工作采用了与Cascade R-CNN类似的结构,但具有更多阶段(即六个),遵循DETR的默认设置。
虽然 DiffusionDet 的头部也采用了六级结构,但其显着特点是 DiffusionDet 可以多次重复使用整个头部,以实现进一步的性能提升。
然而,现有的工作在大多数情况下无法通过重复使用检测头来提高性能,或者只能实现有限的性能提升。
4、实验
数据集:coco、LVIS v1.0、CrowdHuman
4.1 参数设置处理
ResNet 和 Swin 主干网分别使用 ImageNet-1K 和 ImageNet-21K 上的预训练权重进行初始化。
新添加的检测解码器由 Xavier init 初始化。
我们使用 AdamW 优化器训练 DiffusionDet,初始学习率为 2.5 × 10−5,权重衰减为 10−4。
所有模型均在 8 个 GPU 上使用大小为 16 的小批量进行训练。
默认训练计划是 450K 迭代,学习率在 350K 和 420K 迭代时除以 10。
数据增强策略包括随机水平翻转、调整输入图像大小的尺度抖动(使最短边至少为 480 且最多 800 像素,而最长边最多为 1333 )以及随机裁剪增强。
我们不使用 EMA 和一些强大的数据增强,如 MixUp 或 Mosaic 。
在推理阶段,我们报告了 DiffusionDet 在不同设置下的性能,这些设置是不同数量的随机框和迭代步骤的组合。每个采样步骤的预测由 NMS 集成在一起以获得最终预测。
4.2 性能
DiffusionDet 的主要特性在于对所有推理案例进行一次训练。
模型训练完成后,可以通过改变框的数量和推理中的迭代步数来使用它,如图 3 和表 1 所示。因此,我们可以将单个 DiffusionDet 部署到多个场景并获得所需的速度- 无需重新训练网络即可进行准确性权衡。
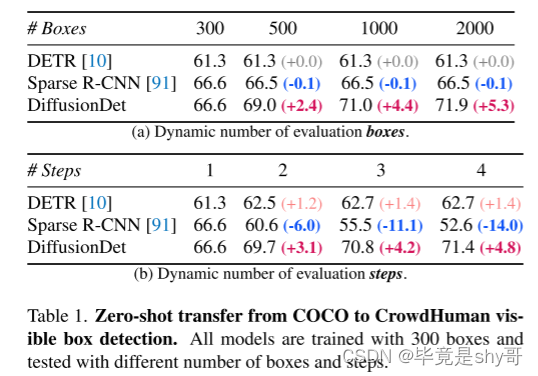
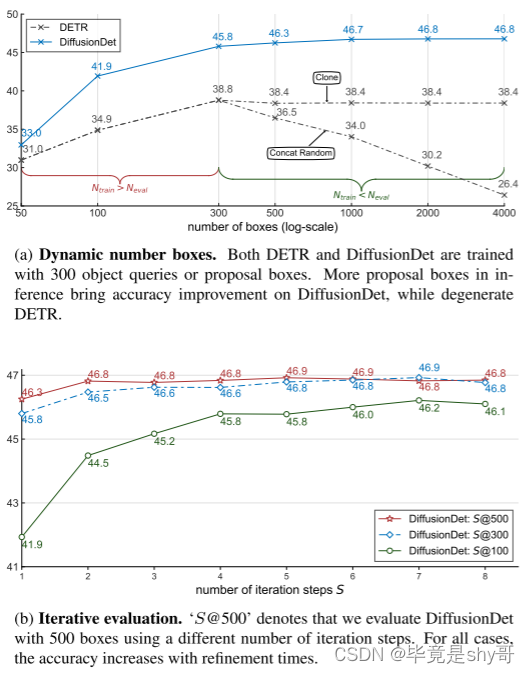
图 3.DiffusionDet 的灵活性。所有实验均在 COCO 2017 训练集上进行训练,并在 COCO 2017 验证集上进行评估。 DiffusionDet 对图 3a 和 3b 中的所有设置使用相同的网络参数。我们提出的 DiffusionDet 能够使用相同的网络参数从更多的提案框和迭代步骤中受益。
4.2.1 动态盒子数量
我们将 DiffusionDet 与 DETR 进行比较,以展示动态框的优势。我们使用官方代码和默认设置进行 300 个训练周期,通过 300 个对象查询重现 DETR 。我们用 300 个随机框训练 DiffusionDet,使候选数量与 DETR 一致,以进行公平比较。评估针对 {50, 100, 300, 500, 1000, 2000, 4000} 个查询或框。
由于可学习的查询在 DETR 的原始设置中训练后是固定的,因此我们提出了一种简单的解决方法,使 DETR 能够处理不同数量的查询:当 Neval < Ntrain 时,我们直接从 Ntrain 查询中选择 Neval 查询;当 Neval > Ntrain 时,我们将现有的 Ntrain 查询克隆到 Neval(也称为克隆)。我们为 DETR 配备了 NMS,因为克隆查询将产生与原始查询相似的检测结果。如图 3a 所示,DiffusionDet 的性能随着用于评估的框数量的增加而稳定增长。例如,当框数从 300 增加到 4000 时,DiffusionDet 可以实现 1.0 AP 增益。相反,克隆更多 DETR 查询(Neval > 300)会导致 DETR 性能从 38.8 略微下降到 38.4 AP,然后是使用更多查询时保持不变。
当 Neval > Ntrain 时,我们还实现了另一种 DETR 方法,连接额外的 Neval − Ntrain 随机初始化查询(也称为连接随机)。采用这种策略,当 Neval 与 Ntrain 不同时,DETR 的性能会明显下降。此外,当 Neval 和 Ntrain 之间的差异增大时,这种性能下降会变得更大。例如,当框数增加到4000时,采用concat随机策略的DETR只有26.4个AP,比峰值低12.4(即300个查询时的38.8个AP)。
4.2.2 迭代评估
我们通过将迭代步骤数从 1 增加到 8 来进一步研究我们提出的方法的性能,相应的结果如图 3b 所示。
我们的研究结果表明,随着迭代次数的增加,采用 100、300 和 500 个随机框的 DiffusionDet 模型表现出一致的性能改进。
此外,我们观察到具有较少随机框的 DiffusionDet 往往通过细化获得更实质性的收益。
例如,使用 100 个随机框的 DiffusionDet 实例的 AP 从 41.9(1 步)提高到 46.1(8 步),绝对提高了 4.2 AP。
4.2.3 Zero-shot transferring.
为了进一步验证泛化的有效性,我们在 CrowdHuman 数据集上对 COCOpretrained 模型进行了评估,无需任何额外的微调。
具体来说,我们的重点是 [person] 类的最终平均精度 (AP) 性能。
实验结果如表 1 所示。我们的观察表明,当转移到场景比 COCO 更密集的新数据集时,我们提出的方法(即 DiffusionDet)通过增加评估框或迭代步骤的数量表现出了显着的优势。例如,通过将框的数量从 300 个增加到 2000 个,并将迭代步骤从 1 增加到 4,DiffusionDet 分别实现了 5.3 和 4.8 的显着 AP 增益。
相比之下,以前的方法表现出有限的增益或严重的性能下降,AP 降低了 14.0。 DiffusionDet 令人印象深刻的灵活性意味着它对于各种场景(包括人口稀少和拥挤的环境)的对象检测任务来说是宝贵的资产,而无需任何额外的微调要求。
4.3 检测数据集的基准测试
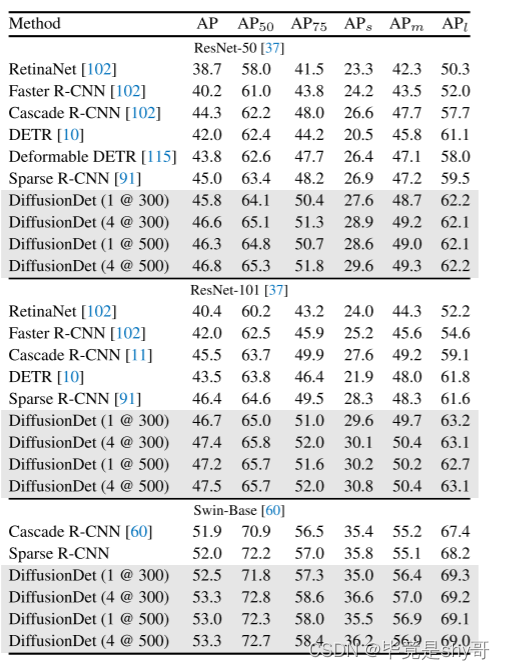
表 2. COCO 2017 验证集上不同物体检测器的比较。 [S@Neval]表示迭代步数S和评估框Neval的数量。每个方法后面的参考文献表明其结果的来源。没有引用的方法就是我们的实现。
在表 2 中,我们将 DiffusionDet 与 COCO 数据集上的几种最先进的检测器进行了比较。。值得注意的是,我们的 DiffusionDet (1 @ 300) 采用单个迭代步骤和 300 个评估框,在 ResNet-50 主干上实现了 45.8 的 AP,超越了 Faster R-CNN、RetinaNet 等几种成熟方法的性能、DETR 和 Sparse R-CNN 具有相当大的优势。而且,DiffusionDet可以通过增加迭代次数和评估框来进一步增强其优越性。此外,当主干尺寸扩大时,DiffusionDet 显示出稳定的改进。 DiffusionDet 与 ResNet-101 (1 @ 300) 达到 46.7。当使用 ImageNet-21k 预训练的 Swin-Base [60] 作为主干时,DiffusionDet 获得了 52.5 AP,优于 Cascade R-CNN 和 Sparse R-CNN 等强基线。
我们当前的模型仍然落后于一些成熟的作品,如 DINO ,因为它使用了一些更先进的组件,例如可变形注意力 、更宽的检测头。其中一些技术与 DiffusionDet 正交,我们将探索将这些技术合并到我们当前的流程中以进一步改进。
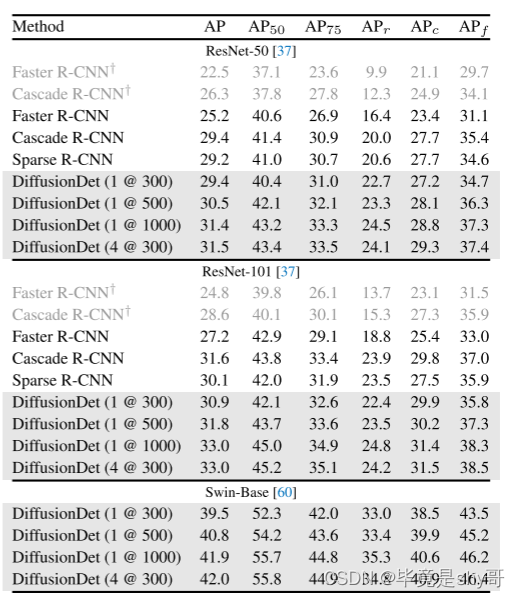
表 3. LVIS v1.0 验证集上不同目标检测器的比较。我们使用联合损失[112]重新实现所有检测器,除了浅灰色的行(带†)。
LVIS 上的实验结果如表 3 所示。我们基于 detectorron2重现 Faster R-CNN 和 Cascade R-CNN,而稀疏 R-CNN 则基于其原始代码。我们首先使用 detectorron2 的默认设置重现 Faster R-CNN 和 Cascade RCNN,使用 ResNet50/101 主干网络分别实现 22.5/24.8 和 26.3/28.8 AP(表 3 中的 †)。此外,我们使用中的联合损失来提高它们的性能。由于 LVIS 中的图像以联合方式进行注释[34],因此负类别注释稀疏,这会恶化训练梯度,特别是对于稀有类别。提出联合损失来缓解这个问题,方法是对每个训练图像的类子集 S 进行采样,其中包括所有正注释和负注释的随机子集。我们选择|S|所有实验中 = 50。 Faster R-CNN 和 Cascade R-CNN 通过联合损失获得大约 3 AP 增益。以下所有比较均基于此损失。
我们看到 DiffusionDet 使用更多的评估步骤(无论是小主干还是大主干)都取得了显着的成果。此外,我们注意到,与 COCO 相比,迭代评估为 LVIS 带来了更多收益。例如,它在 COCO 上的性能从 45.8 增加到 46.6(+ 0.8 AP),而在 LVIS 上从 29.4 增加到 31.5(+2.1 AP),这表明我们的 DiffusionDet 对于更具挑战性的基准测试将变得更有帮助。
4.4. 消融实验

表 4. COCO 上的 DiffusionDet 消融实验。我们报告 AP、AP50 和 AP75。如果不指定,默认设置为:主干网为ResNet-50[37]和FPN[55],信号尺度为2.0,ground-truth框填充方法为连接高斯随机框,采样时使用DDIM和框更新步。默认设置以灰色标记。
我们在 COCO 上进行消融实验来详细研究 DiffusionDet。所有实验均使用以 FPN 为骨干的 ResNet-50 和 300 个随机框进行推理,无需进一步说明。
4.4.1 信号缩放
信号缩放因子控制扩散过程的信噪比 (SNR)。
我们研究了表 4a 中比例因子的影响。
结果表明,缩放因子 2.0 实现了最佳 AP 性能,优于图像生成任务中的标准值 1.0 [14, 38] 和用于全景分割的标准值 0.1 。
我们解释说,这是因为一个框只有四个表示参数,即中心坐标(cx,cy)和框大小(w,h),这大致类似于图像生成中只有四个像素的图像。
框表示比密集表示更脆弱,例如全景分割中的 512 × 512 掩模表示。
因此,与图像生成和全景分割相比,DiffusionDet 更喜欢具有更高信噪比的更简单的训练目标。
4.4.2 GT盒子填充策略
我们需要将额外的框填充到原始的真实框,以便每个图像具有相同数量的框。
我们研究了表4b中不同的填充策略,包括
(1)均匀地重复原始的ground Truth box,直到总数达到预定义值Ntrain;
(2)填充遵循高斯分布的随机框;
(3) 填充遵循均匀分布的随机框;
(4)与整个图像大小相同的填充框。连接高斯随机框最适合 DiffusionDet,我们默认使用此填充策略。
4.4.3 抽样策略
我们在表 4c 中比较了不同的采样策略。
在评估不使用DDIM的DiffusionDet时,我们直接将当前步骤的输出预测作为下一步的输入。
我们发现,当既不采用 DDIM 也不采用盒子更新时,DiffusionDet 的 AP 会随着迭代步数的增加而降低。
此外,仅使用 DDIM 或盒子更新会在 3 个迭代步骤中带来轻微的好处。
此外,当配备 DDIM 和更新时,我们的 DiffusionDet 获得了显着的收益。
这些实验共同验证了采样步骤中 DDIM 和盒子更新的必要性。
4.4.4 Ntrain 和 Neval 之间的匹配
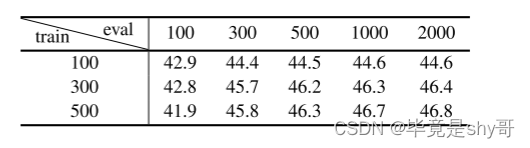
表 5. COCO 上训练和推理框数量之间的匹配。 DiffusionDet 在训练和推理阶段解耦了盒子的数量,并且可以很好地进行灵活的组合。
DiffusionDet 具有使用任意数量的随机框进行评估的吸引人的特性。
为了研究训练框的数量如何影响推理性能,我们分别使用 Ntrain ∈ {100, 300, 500} 随机框训练 DiffusionDet,然后使用 Neval ∈ {100, 300, 500, 1000, 2000} 评估每个模型。
结果总结在表5中。
首先,无论DiffusionDet使用多少个随机框进行训练,准确率都会随着Neval的增加而稳定增加,直到在2000个随机框左右达到饱和点。
其次,当 Ntrain 和 Neval 相互匹配时,DiffusionDet 往往会表现得更好。例如,当 Neval = 100 时,使用 Ntrain = 100 个框训练的 DiffusionDet 表现优于 Ntrain = 300 和 500。
4.4.5 运行时间与准确性
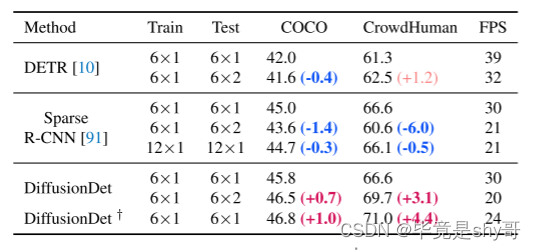
表 6. 运行时间与性能。 † 表示具有 1000 个盒子的 DiffusionDet。 #Stages×#Heads表示训练和测试阶段使用的阶段和头的数量。 Stage 和 Head 的定义如图 2b 所示。
我们研究了 DiffusionDet 在多种设置下的运行时间,这些设置是在小批量大小为 1 的单个 NVIDIA A100 GPU 上进行评估的。我们使用符号 #Stages×#Heads 来指示训练期间使用的阶段和头的数量和测试阶段,如图 2b 所示,我们的调查结果如表 6 所示。
首先,我们的研究结果表明,具有单个迭代步骤和 300 个评估框的 DiffusionDet 表现出与 Sparse R-CNN 相当的速度,分别实现了 30 和 31 帧每秒 (FPS)。 DiffusionDet 还在 CrowdHuman 上展示了类似的零样本传输性能,同时以 45.8 AP 优于 Sparse R-CNN,而 COCO 上的 AP 为 45.0。此外,Sparse R-CNN 两次利用这六个阶段导致 COCO 上的 AP 下降了 1.4(从 45.0 到 43.6),而 CrowdHuman 上的 AP 下降了 6.0(从 66.6 到 60.6)。同样,DETR 在 COCO 上的性能下降了 0.4,但在 CrowdHuman 上的性能却提高了 1.2。
当增加迭代步数时,DiffusionDet 在 COCO 上实现了 0.7 AP 增益,在 CrowdHuman 上实现了 3.1 AP 增益。 DiffusionDet 通过 1000 个评估框获得了明显的性能提升。然而,DETR 和 Sparse R-CNN 都无法通过额外的迭代步骤实现性能提升。即使我们将级数扩大到 12,也会导致 Sparse R-CNN 的性能下降。
值得注意的是,在这项工作中,我们利用了最基本的扩散策略 DDIM 来开创性地探索使用生成模型进行感知任务。与生成任务中使用的 Diffusion 模型类似,DiffusionDet 可能会遇到采样速度相对较慢的问题。尽管如此,最近提出了一系列工作来提高扩散模型的采样效率。例如,最新的一致性模型提出了一种扩散模型的快速一步生成方法。我们相信,更先进的扩散策略可能会解决 DiffusionDet 速度性能下降的问题,我们计划在未来的工作中对此进行探索。
4.4.6 随机种子
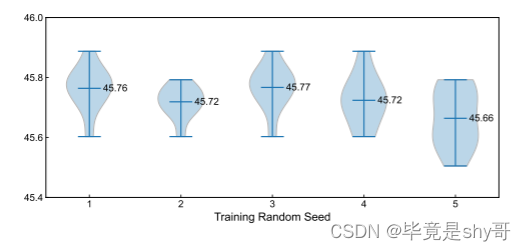
图 4. 5 个独立训练实例的统计结果,每个实例使用不同的随机种子评估 10 次。
由于 DiffusionDet 在推理开始时被给予随机框作为输入,因此人们可能会问不同随机种子之间是否存在较大的性能差异。我们通过使用除随机种子之外的相同配置独立训练五个模型来评估 DiffusionDet 的稳定性。然后,受前人的启发,我们使用十个不同的随机种子评估每个模型实例,以测量性能分布。如图4所示,大多数评估结果都紧密分布在45.7 AP上。此外,不同模型实例之间的性能差异很小,这表明 DiffusionDet 对随机框具有鲁棒性并产生可靠的结果。
4.5.对 CrowdHuman 进行全面调整
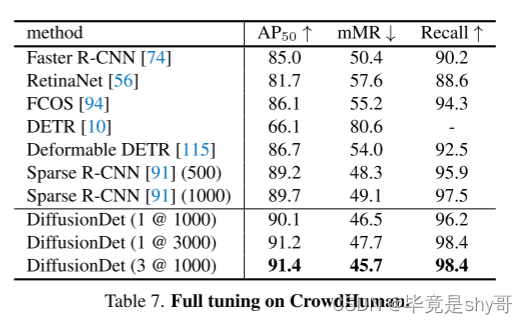
除了4.2节中讨论的从COCO到CrowdHuman的跨数据集泛化评估之外,我们进一步在CrowdHuman上全面调整DiffusionDet。比较结果如表7所示。我们看到,与之前的方法相比,DiffusionDet 取得了更优越的性能。例如,通过单步和 1000 个框,DiffusionDet 获得 90.1 AP50,优于具有 1000 个框的稀疏 RCNN。此外,进一步将盒子增加到3000个和迭代步骤都可以带来性能提升。
5.结论
在这项工作中,我们提出了一种新颖的检测范例,DiffusionDet,将对象检测视为从噪声框到对象框的去噪扩散过程。我们的噪声到盒子管道具有几个吸引人的特性,包括盒子的动态数量和迭代评估,使我们能够使用相同的网络参数进行灵活的评估,而无需重新训练模型。标准检测基准的实验表明,与成熟的检测器相比,DiffusionDet 实现了良好的性能。
相关文章:
DiffusionDet:第一个用于物体检测的扩散模型(DiffusionDet: Diffusion Model for Object Detection)
提出了一种新的框架——DiffusionDet,它将目标检测定义为一个从有噪声的盒子到目标盒子的去噪扩散过程。在训练阶段,目标盒从真实值盒扩散到随机分布,模型学会了逆转这个噪声过程。 在推理中,该模型以渐进的方式将一组随机生成的框…...
④. GPT错误:导入import pandas as pd库,存储输入路径图片信息存储错误
꧂ 问题最初꧁ 用 import pandas as pd 可是你没有打印各种信息input输入图片路径 print图片尺寸 大小 长宽高 有颜色占比>0.001的按照大小排序将打印信息存储excel表格文件名 表格路径 图片大小 尺寸 颜色类型 占比信息input输入的是文件就处理文件 是文件夹Ὄ…...

和鲸 ModelWhale 与华为 OceanStor 2910 计算型存储完成兼容性测试
数智化时代,数据总量的爆炸性增长伴随着人工智能、云计算等技术的发展,加速催化了公众对于数据存储与应用的多元化需求。同时,数据也是重要的基础资源和战略资源,需要严格保障其安全性、完整性。搭建国产数据基础设施底座…...

c++中单例模式的实现和问题
单例模式定义 单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供了一个全局访问点来访问该实例。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对…...

如何选购高效便捷的软件行业项目管理系统
如何选择一个高效便捷的软件行业项目管理系统?推荐一款好用的项目管理软件Zoho Projects,Zoho Projects是少数可以给客户开通权限的项目管理软件,相信Zoho Projects权限管理功能会受到题主的欢迎。有了这个功能,项目外的客户可以参…...

用“和美”丈量中国丨走进酒博物馆系列⑨
五粮液酒文化博览馆始建于1988年,是中国酒业最早的酒文化博览馆,于2020年启动升级改造。 现在我们看到的五粮液酒文化博览馆,采用了当今博览馆最前沿的展陈方式,展陈设计与空间布局更具灵动性和多元性,蕴含传统文化氛围…...

树莓派 Raspberry Pi 与YOLOv8 结合进行目标检测
文章大纲 使用树莓派摄像头 提供视频流前置文章libcamera树莓派安装与部署YOLOv8硬件需求 PrerequisitesYOLO Version: YOLOv5 or YOLOv8硬件的选择,树莓派5的YOLOv8支持呼之欲出,Hardware Specifics: At a GlanceYOLOv8 在树莓派上的配置与安装Install Necessary PackagesIn…...

centos 安装 percona-xtrabackup
一、yum安装 1.安装Percona yum存储库 yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm 2.启用Percona Server 8.0存储库 percona-release setup ps57 3.输出如下则安装成功 [rootlocalhost ~]# percona-release setup ps80 * Disabling all…...

机器学习1:k 近邻算法
k近邻算法(k-Nearest Neighbors, k-NN)是一种常用的分类和回归算法。它基于一个简单的假设:如果一个样本的k个最近邻居中大多数属于某一类别,那么该样本也很可能属于这个类别。 k近邻算法的步骤如下: 输入:…...
知识图谱系列4:neo4j学习
这是一篇还不错的教程,我将会针对其中的Cypher语法在这篇帖子内提出问题,以便学习与复习。 MATCH是什么操作? 小括号()代表什么?(n)代表什么? MATCH (n) DETACH DELETE n是什么含义࿱…...

Mainflux IoT:Go语言轻量级开源物联网平台,支持HTTP、MQTT、WebSocket、CoAP协议
Mainflux是一个由法国的创业公司开发并维护的安全、可扩展的开源物联网平台,使用 Go语言开发、采用微服务的框架。Mainflux支持多种接入设备,包括设备、用户、APP;支持多种协议,包括HTTP、MQTT、WebSocket、CoAP,并支持…...
怎样提取视频中的音频?分享一个一学就会的方法~
每次遇到视频中有好听的背景音乐都会想要保存下来,用于自己的视频创作。于是怎样单独提取视频中的音频部分就成了难题,今天教大家一个简单实用的视频提取音频办法,看完记得点赞收藏哦~ 第一步:打开【音分轨】APP&#…...
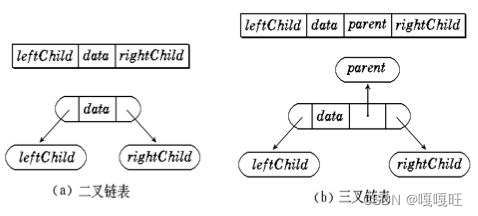
【数据结构】二叉树的基本概念
1.树概念及结构 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的 子树不能有交集࿰…...

数据可视化实战:如何给毛*易的歌曲做词云展示?
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

智能文本纠错API的崭露头角:革命性的写作辅助工具
前言 在数字化时代,文字是我们日常生活和工作中的不可或缺的一部分。不论是在社交媒体上发帖、撰写商务邮件还是完成学术论文,文字表达都是沟通的核心。然而,字词错误、语法错误和敏感信息却是许多人常常面临的挑战,它们不仅会影…...
读书笔记:多Transformer的双向编码器表示法(Bert)-3
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 第3章 Bert实战 学习如何使用预训练的BERT模型: 如何使用预训练的BERT模型作为特征提取器;探究Hugging Face的Transforme…...

jpsall脚本
当一个集群的节点数量增多时,使用jps查看每一个节点的进程这个过程非常繁琐,因此我们可以写一个jpsall脚本,使用循环迭代的方式,在多台远程主机上执行相同的命令,这样就可以节省在每台主机上手动执行命令的时间和精力。…...
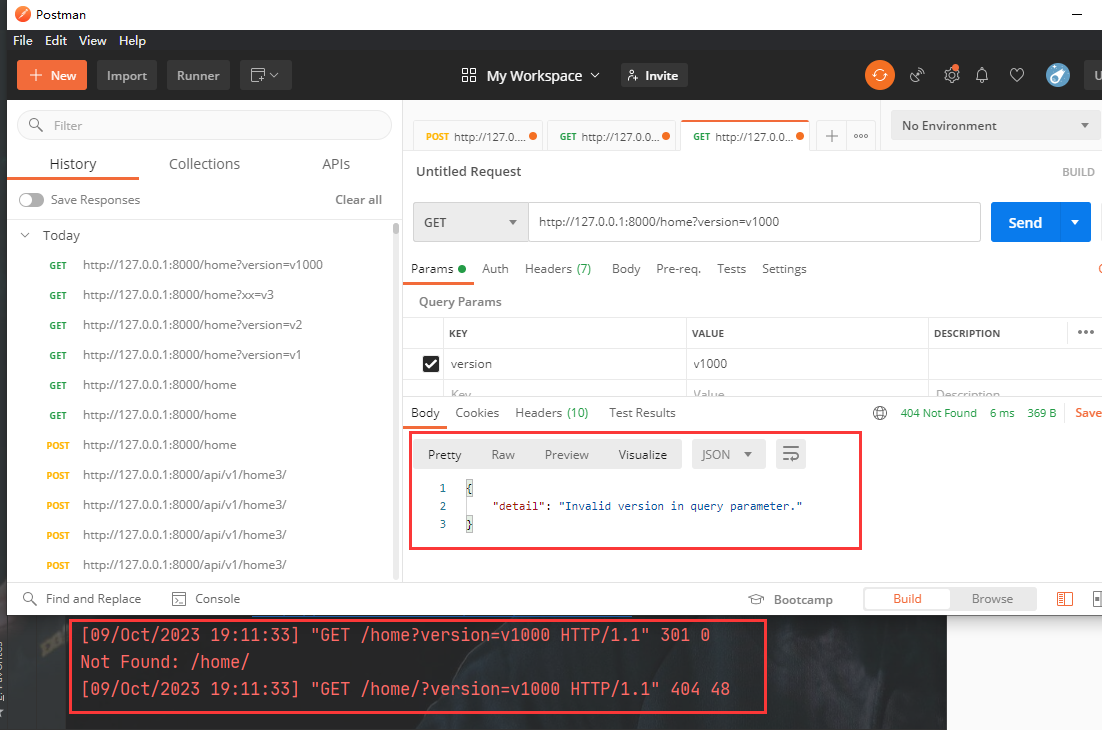
Django REST framework API版本管理【通过GET参数传递】
API版本 在开发过程中可能会有多版本的API,因此需要对API进行管理。django drf中对于版本的管理也很方便。 http://www.example.com/api/v1/info http://www.example.com/api/v2/info 上面这种形式就是很常见的版本管理 在restful规范中,后端的API需…...

归并排序 nO(lgn)
大家好,我是蓝胖子,我一直相信编程是一门实践性的技术,其中算法也不例外,初学者可能往往对它可望而不可及,觉得很难,学了又忘,忘其实是由于没有真正搞懂算法的应用场景,所以我准备出…...
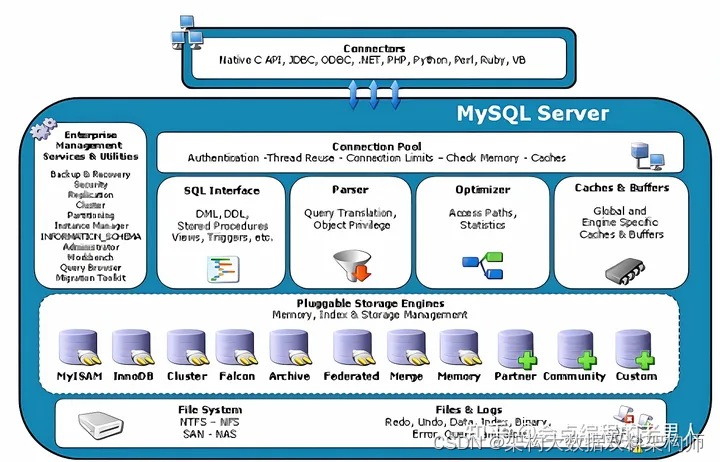
数据库Mysql三大引擎(InnoDB、MyISAM、 Memory)与逻辑架构
MySQL数据库及其分支版本主要的存储引擎有InnoDB、MyISAM、 Memory等。简单地理解,存储引擎就是指表的类型以及表在计算机上的存储方式。存储引擎的概念是MySQL的特色,使用的是一个可插拔存储引擎架构,能够在运行的时候动态加载或者卸载这些存…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...