Hadoop分布式集群搭建教程
目录
- 前言
- 环境准备
- 一、创建虚拟机
- 二、虚拟机网络配置
- 三、克隆虚拟机
- 四、Linux系统配置
- 五、Hadoop的部署配置
- 六、Hadoop集群的启动
前言
大数据课程需要搭建Hadoop分布式集群,在这里记录一下搭建过程
环境准备
搭建Haoop分布式集群所需环境:
- VMware:VMware-workstation-full-17.0.2-21581411
- CentOS:CentOS-7-x86_64-DVD-2003,
- Hadoop:hadoop-3.1.3.tar
- JDK:jdk-8u212-linux-x64.tar.gz
一、创建虚拟机
新建虚拟机
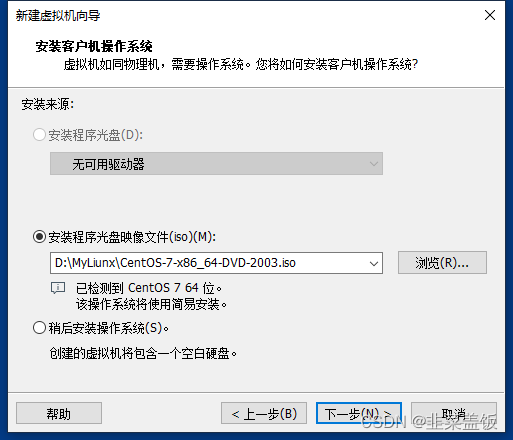
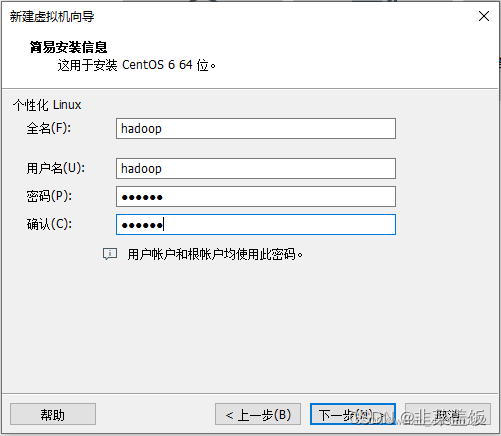
设置用户
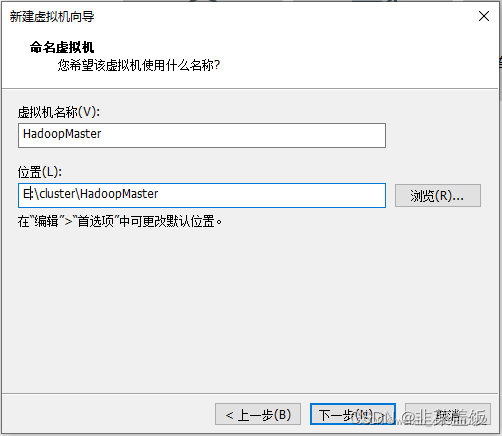
命名虚拟机
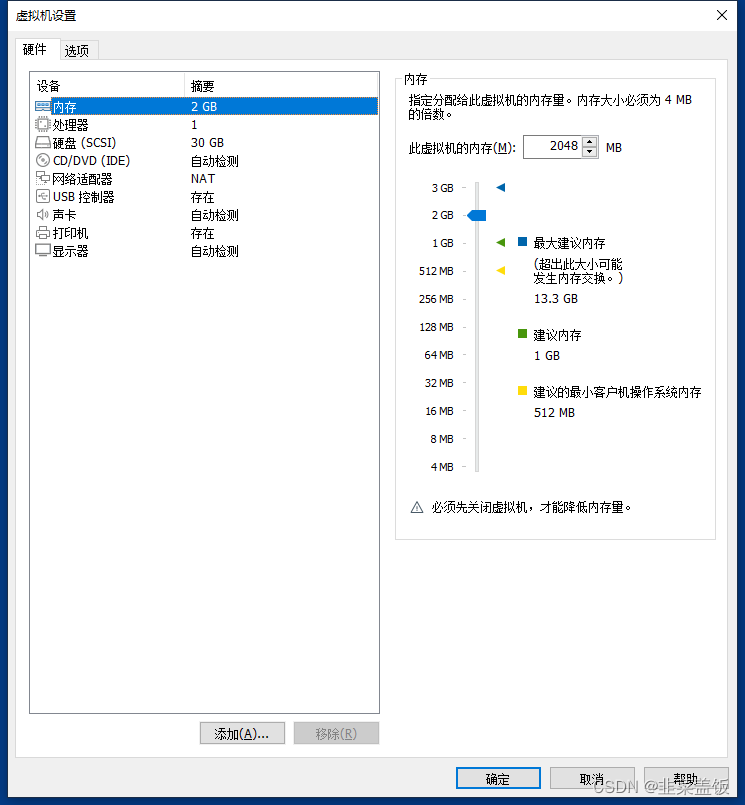
自定义硬件,完成虚拟机创建
开始启动虚拟机,并安装CentOS
二、虚拟机网络配置
NAT网络模式:
- 宿主机可以看做一个路由器,虚拟机通过宿主机的网络来访问 Internet;
- 可以安装多台虚拟机,组成一个小型局域网,例如:搭建 hadoop 集群、分布式服务。
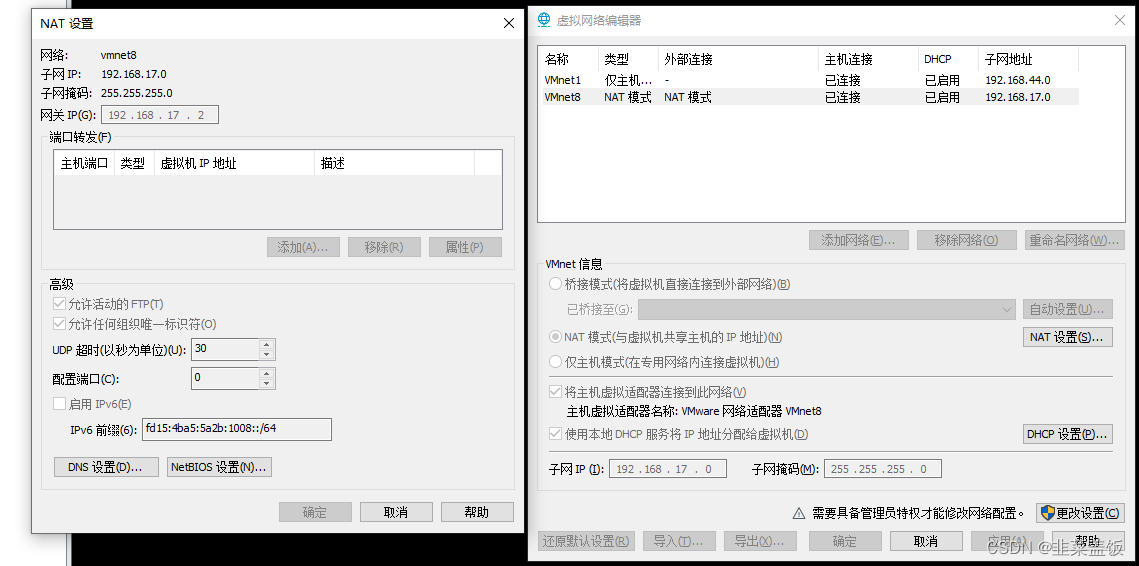
VMnet8 设置静态 IP
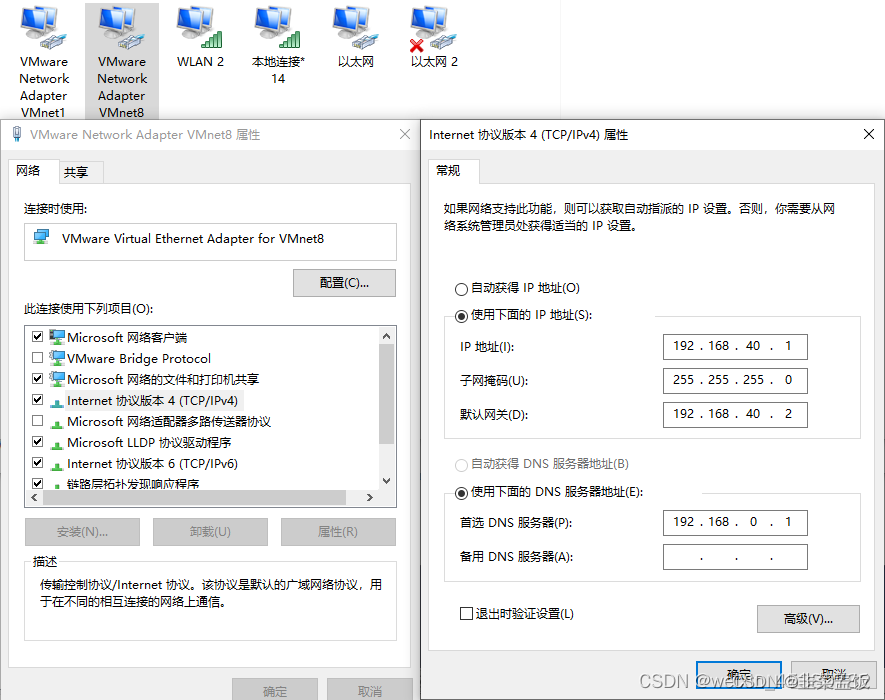
Centos 网络设配器为 NAT 模式
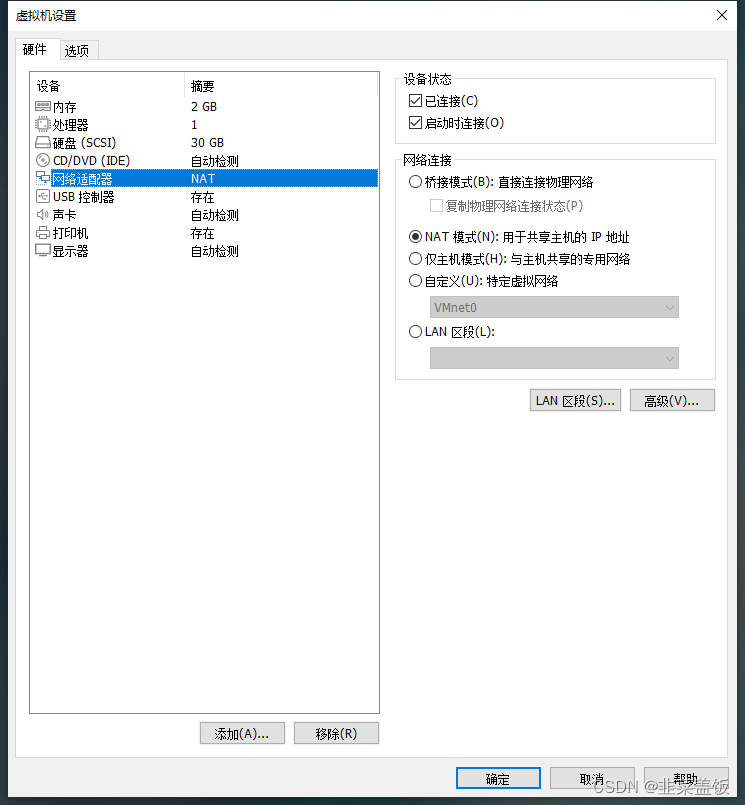
VMware 虚拟网络设置
验证结果
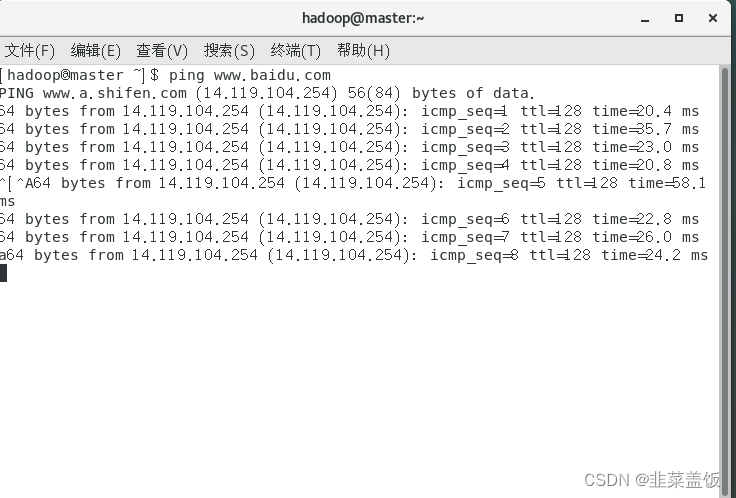
因为网络这里一块,老早之前就配置过了,如果觉得不详细,可以参看以下文章:https://blog.csdn.net/ruiqu1650914788/article/details/124973841
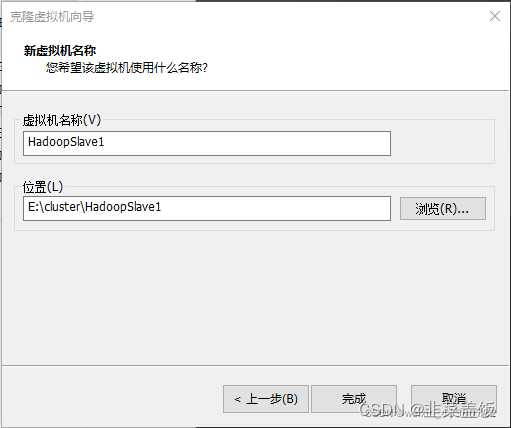
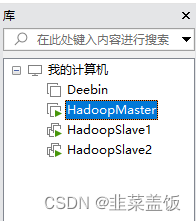
三、克隆虚拟机
集群搭建需要至少三台服务器,这里我们再克隆两台虚拟机克HadoopSlave1与HadoopSlave2,
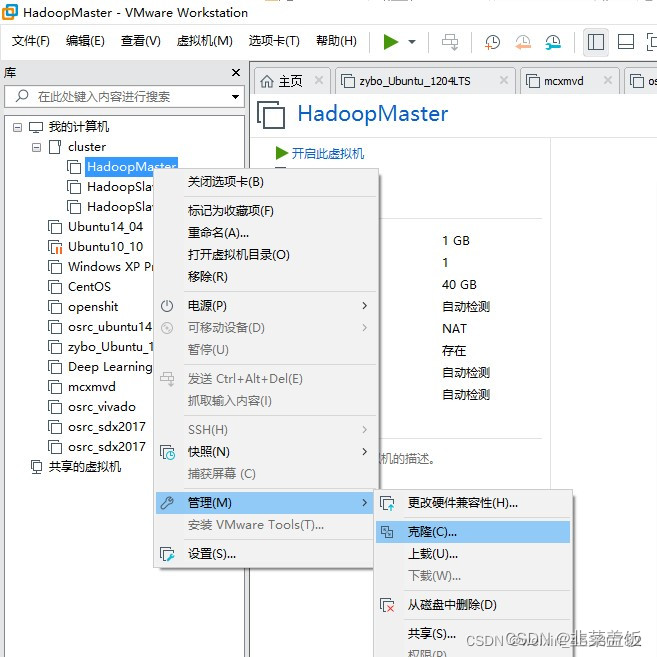
直接无脑下一步,记得修改名称
四、Linux系统配置
1、配置时钟同步
三台虚拟机都需要配置
yum install ntpdate
ntpdate ntp5.aliyun.com2、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service3、配置主机名
三台虚拟机都需要配置
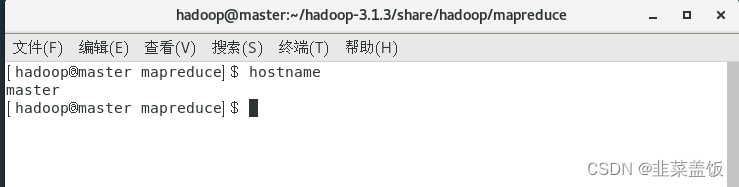
以root用户身份登录HadoopMaster节点,直接使用vim编辑器打开network网络配置文件,命令如下:
vim /etc/sysconfig/network
打开network文件,配置信息如下,将HadoopMaster节点的主机名修改为master,即下面第二行代码所示:
NETWORKING=yes #启动网络HOSTNAME=master #主机名
两个子节点分别为:
NETWORKING=yes #启动网络HOSTNAME=slave1 #主机名
NETWORKING=yes #启动网络HOSTNAME=slave2 #主机名
测试
4、 配置Hosts列表
主机列表的作用是让集群中的每台服务器彼此之间都知道对方的主机名和IP地址。因为在Hadoop分布式集群中,各服务器之间会频繁通信,做数据的同步和负载均衡。
以root用户身份登录三个节点,将下面3行代码添加到主机列表/etc/hosts 文件中。
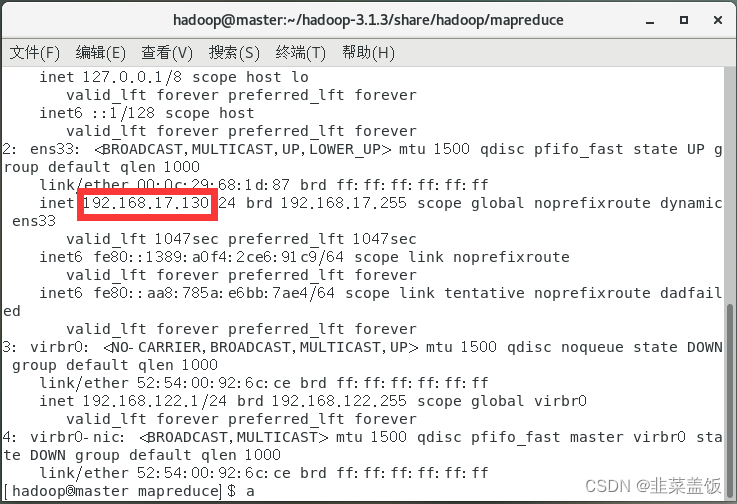
192.168.17.130 master192.168.17.131 slave1192.168.17.132 slave2
ip地址可以使用命令:ip addr查看
验证主机hosts是否配置成功
ping masterping slave1ping slave2
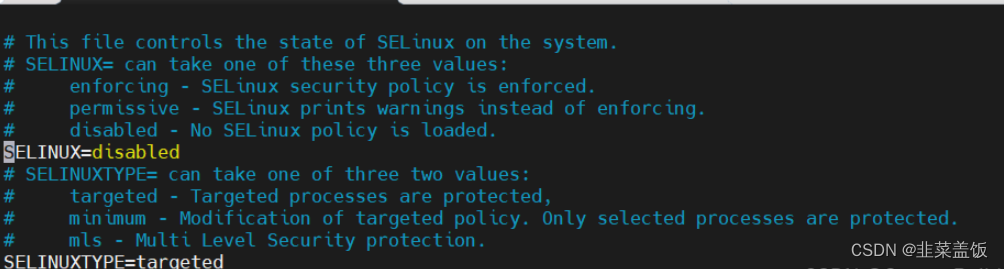
5、关闭selinux
vim /etc/selinux/config
修改为 SELINUX=disabled
6、免密钥登录配置
免密钥登录是指从一台节点通过SSH方式登录另外一台节点时,不用输入该节点的用户名和密码,就可以直接登录进去,对其中的文件内容直接进行操作。没有任何校验和拦截。
从root用户切换到hadoop用户,输入su hadoop,在终端生成密钥,输入以下命令:
ssh-keygen –t rsa
一直回车即可
复制公钥文件到authorized_keys文件中,命令如下:
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
修改authorized_keys文件的权限,只有当前用户hadoop有权限操作authorized_keys文件,命令如下:
chmod 600 /home/hadoop/.ssh/authorized_keys
将HadoopMaster主节点生成的authorized_keys公钥文件复制到HadoopSlave1和HadoopSlave2从节点,命令如下:
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/
如果出现提示,则输入yes并按回车键,输入密码
以hadoop用户身份登录HadoopSlave1、HadoopSlave2节点,进入到/home/hadoop/.ssh目录,修改authorized_keys文件的权限为当前用户可读可写,输入以下命令:
chmod 600 /home/hadoop/.ssh/authorized_keys
在HadoopMaster节点的Terminal终端上输入以下命令验证免密钥登录
ssh slave1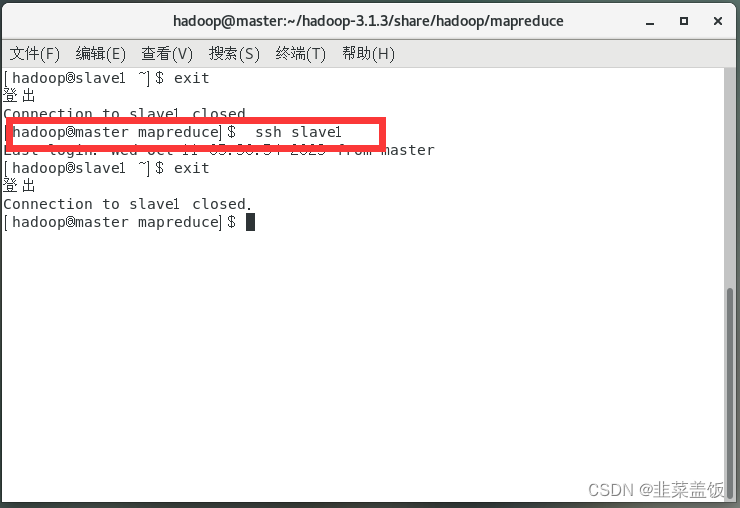
五、Hadoop的部署配置
1、安装JDK
三台虚拟机都需要配置
卸载现有JDK
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
将JDK文件复制到新建的/usr/java 目录下解压,修改用户的系统环境变量文件/etc/profile
tar –zxvf xxx
vi /etc/profile
写入以下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_212export JRE_HOME=/usr/java/jdk1.8.0_212/jreexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/libexport PATH=$JRE_HOME/bin:$JAVA_HOME/bin:$PATH使配置生效
source /etc/profile
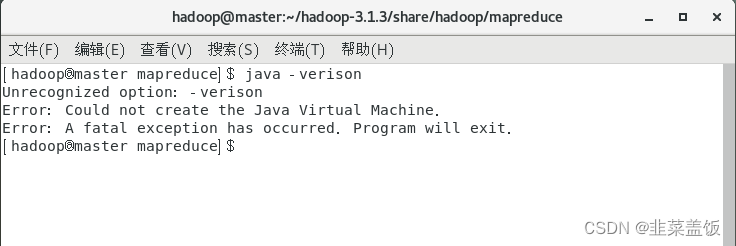
测试
java -version
2、安装Hadoop
将Hadoop安装文件通过SSH工具上传到HadoopMaster节点hadoop用户的主目录下。进入hadoop用户主目录,输入以下命令进行解压:
tar –zxvf hadoop-3.1.3.tar.gz
3、配置环境变量hadoop-env.sh
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
在文件靠前的部分找到以下代码(没有就自己添加):
export JAVA_HOME=${JAVA_HOME}
将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_212
保存文件,此时Hadoop具备了运行时的环境。
4、配置环境变量yarn-env.sh
YARN主要负责管理Hadoop集群的资源。这个模块也是用Java语言开发出来的,所以也要配置其运行时的环境变量JDK。
打开Hadoop的YARN模块的环境变量文件yarn-env.sh,只需要配置JDK的路径。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/yarn-env.sh
#export JAVA_HOME
将这行代码修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_212
5、配置核心组件core-site.xml
Hadoop集群的核心配置,是关于集群中分布式文件系统的入口地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置。
分布式文件系统(Hadoop Distributed FileSystem,HDFS)是集群中分布式存储文件的核心系统,将在后面章节详细介绍,其入口地址决定了Hadoop集群架构的主节点,其值为hdfs://master:9000,协议为hdfs,主机为master,即HadoopMaster节点,端口号为9000。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/core-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入:
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoopdata</value></property></configuration>
HDFS文件系统数据落地到本地磁盘的路径信息/home/hadoop/hadoopdata,该目录需要单独创建。
在三个虚拟机上的目录/home/hadoop下创建目录hadoopdata
mkdir hadoopdata
6、 配置文件系统hdfs-site.xml
在分布式的文件系统中,由于集群规模很大,所以集群中会频繁出现节点宕机的问题。分布式的文件系统中,可通过数据块副本冗余的方式来保证数据的安全性,即对于同一块数据,会在HadoopSlave1和HadoopSlave2节点上各保存一份。这样,即使HadoopSlave1节点宕机导致数据块副本丢失,HadoopSlave2节点上的数据块副本还在,就不会造成数据的丢失。
配置文件hdfs-site.xml有一个属性,就是用来配置数据块副本个数的。在生产环境中,配置数是3,也就是同一份数据会在分布式文件系统中保存3份,即它的冗余度为3。也就是说,至少需要3台从节点来存储这3份数据块副本。在Hadoop集群中,主节点是不存储数据副本的,数据的副本都存储在从节点上,由于现在集群的规模是3台服务器,其中从节点只有两台,所以这里只能配置成1或者2。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
在<!-- Put site-specific property overrides in this file. --> 下方,输入:
<configuration><property><!--配置数据块的副因子(即副本数)为2--><name>dfs.replication</name><value>2</value></property></configuration>
7、 配置YARN资源系统yarn-site.xml
YARN的全称是Yet Another Resource Negotiator,即另一种资源协调者,运行在主节点上的守护进程是ResourceManager,负责整个集群资源的管理协调;运行在从节点上的守护进程是NodeManager,负责从节点本地的资源管理协调。
YARN的基本工作原理:每隔3秒,NodeManager就会把它自己管理的本地服务器上的资源使用情况以数据包的形式发送给主节点上的守护进程ResourceManager,这样,ResourceManager就可以随时知道所有从节点上的资源使用情况,这个机制叫“心跳”。当“心跳”回来的时候,ResourceManager就会根据各个从节点资源的使用情况,把相应的任务分配下去。“心跳”回来时,携带了ResourceManager分配给各个从节点的任务信息,从节点NodeManager就会处理主节点ResourceManager分配下来的任务。客户端向整个集群发起具体的计算任务,ResourceManager是接受和处理客户端请求的入口。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/yarn-site.xml
在<!-- Site specific YARN configuration properties -->下方,输入:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>master:18040</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:18030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:18025</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:18141</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:18088</value>
</property>
8、 配置计算框架mapred-site.xml
YARN主要负责分布式集群的资源管理,将Hadoop MapReduce分布式并行计算框架在运行中所需要的内存、CPU等资源交给YARN来协调和分配,通过对mapred-site.xml配置文件的修改来完成这个配置。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/mapred-site.xml
在<!-- Put site-specific property overrides in this file. -->下方,输入:
<configuration><!—MapReduce计算框架的资源交给YARN来管理--><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
在这里可能出现以下Bug
处理方式:
先运行shell命令:hadoop classpath
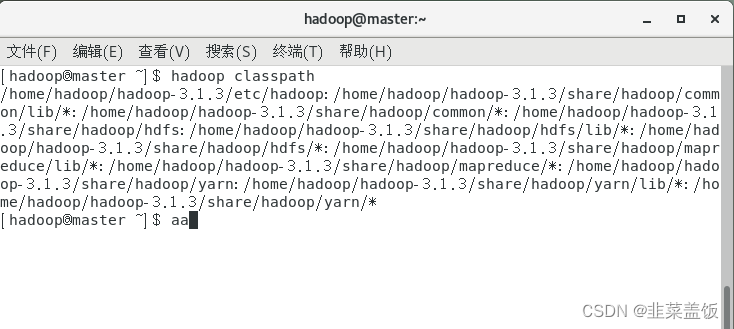
在mapred-site.xml添加以下配置
<property><name>yarn.application.classpath</name><value>hadoop classpath返回的信息</value>
</property>9、复制hadoop到从节点
主节点的角色HadoopMaster已在配置HDFS分布式文件系统的入口地址时进行了配置说明,从节点的角色也需要配置,此时,workers文件就是用来配置Hadoop集群中各个从节点角色。
打开workers配置文件。
vim /home/hadoop/hadoop-3.1.3/etc/hadoop/workers
用下面的内容替换workers文件中的内容:
slave1slave2
在Hadoop集群中,每个节点上的配置和安装的应用都是一样的,这是分布式集群的特性,所以,此时已经在HadoopMaster节点上安装了Hadoop-3.1.3的应用,只需要将此应用复制到各个从节点(即HadoopSlave1节点和HadoopSlave2节点)即可将主节点的hadoop复制到从节点上。
scp –r /home/hadoop/hadoop-3.1.3 hadoop@slave1:~/scp –r /home/hadoop/hadoop-3.1.3 hadoop@slave2:~/
10、配置Hadoop启动的系统环境变量
和JDK的配置环境变量一样,也要配置一个Hadoop集群的启动环境变量PATH。
此配置需要同时在三台虚拟机上进行操作,操作命令如下:
vi /etc/profile
将下面的代码追加到文件的末尾:
#Hadoop Path configurationexport HADOOP_HOME=/home/hadoop/hadoop-2.5.2export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
输入:wq保存退出,并执行生效命令:
source /etc/profile
登录HadoopSlave1和HadoopSlave2节点,依照上述配置方法,配置Hadoop启动环境变量。
这里存在一个问题:CentOS 7 每次进入要重新加载环境变量
解决方式:
进入系统配置文件
vim ~/.bashrc
末尾添加如下代码
source /etc/profile
保存即可
六、Hadoop集群的启动
启动集群时,首先要做的就是在HadoopMaster节点上格式化分布式文件系统HDFS:
hadoop namenode -format
启动Hadoop
cd /home/hadoop/hadoop-3.1.3
sbin/start-all.sh
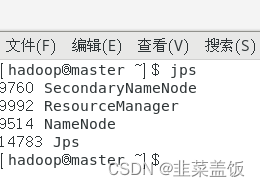
查看进程是否启动
在HadoopMaster的Terminal终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode。
在HadoopSlave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps。
注意:jps是JDK的命令,如果没有该命令,请检查JDK是否配置正确
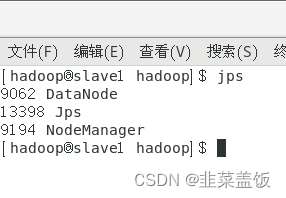
如果子节点不存在DataNode,参考以下文章:https://blog.csdn.net/m0_61232019/article/details/129324464
也可以删除hadoopdata目录里面的内容重新启动Hadoop来解决
检查NameNode和DataNode是否正常
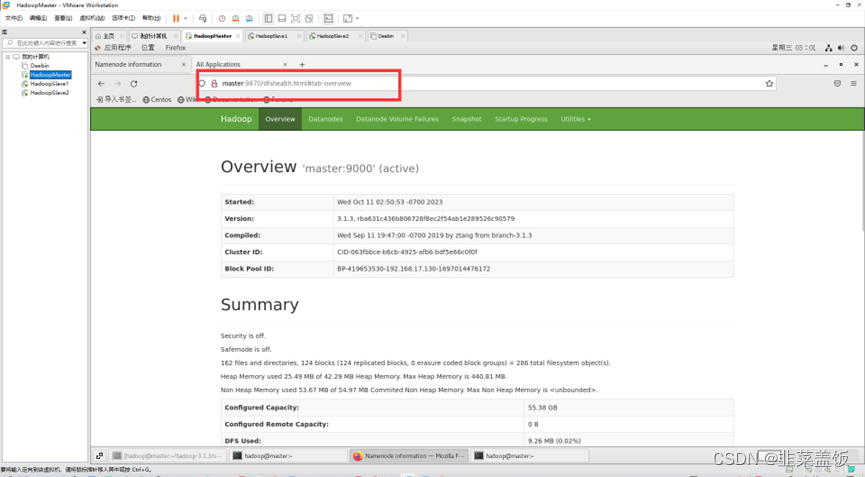
检查YARN是否正常
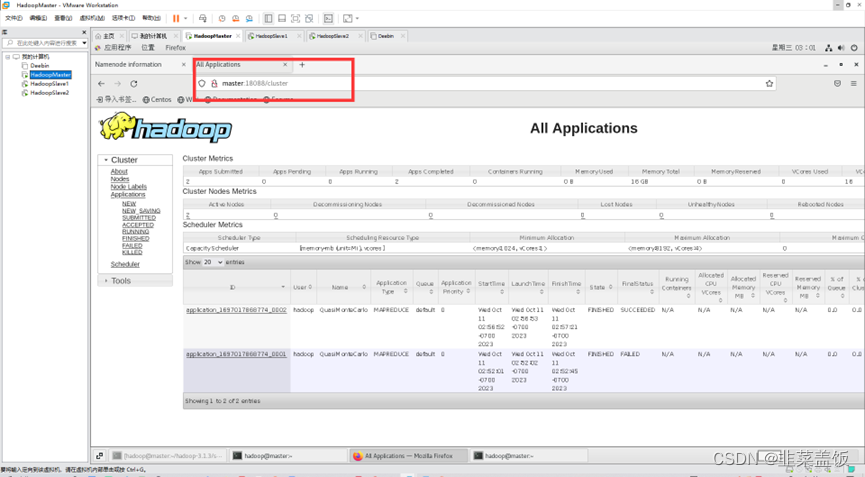
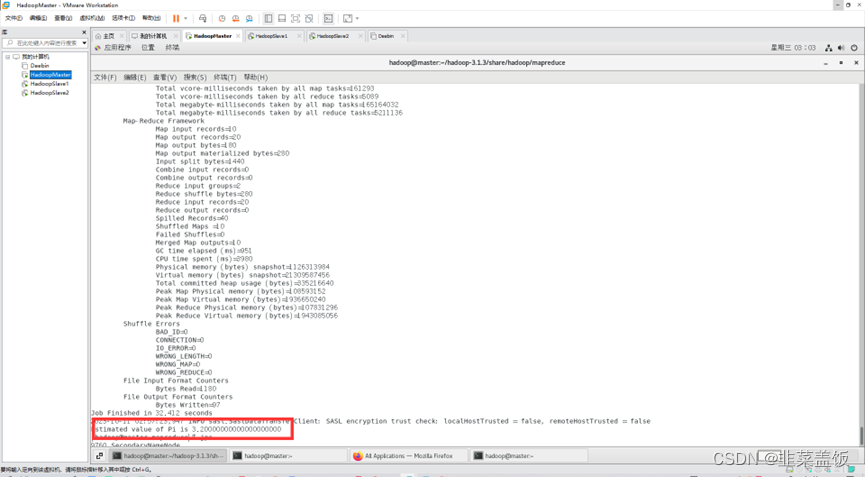
运行PI实例检查集群是否启动成功
相关文章:
Hadoop分布式集群搭建教程
目录 前言环境准备一、创建虚拟机二、虚拟机网络配置三、克隆虚拟机四、Linux系统配置五、Hadoop的部署配置六、Hadoop集群的启动 前言 大数据课程需要搭建Hadoop分布式集群,在这里记录一下搭建过程 环境准备 搭建Haoop分布式集群所需环境: VMware&a…...

学习函数式编程、可变参数及 defer - GO语言从入门到实战
函数是⼀等公⺠、学习函数式编程、可变参数及 defer - GO语言从入门到实战 函数是⼀等公⺠ 在Go语言中,函数可以分配给一个变量,可以作为函数的参数,也可以作为函数的返回值。这样的行为就可以理解为函数属于一等公民。 与其他主要编程语⾔…...
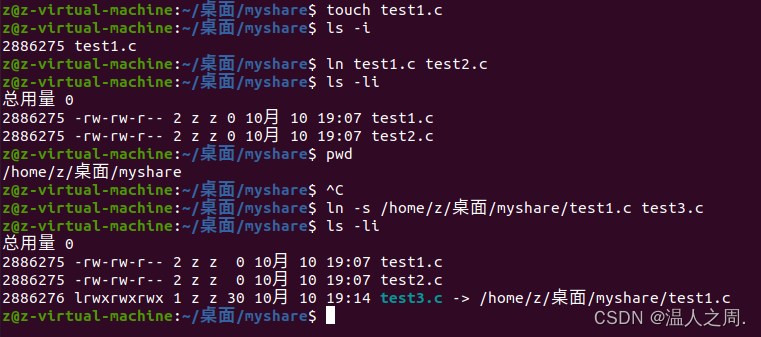
Linux 文件链接
Linux 下的文件链接有两类。一个是类似于 win 电脑的快捷方式,我们称为软链接,软链接也可以叫做符号链接。另一种是通过文件系统的 inode 连接来产生的,类似于 windows 电脑的复制,但是不产生新的文件,我们称为硬链接。…...

1.go web之gin框架
Gin框架 一、准备 1.下载依赖 go get -u github.com/gin-gonic/gin2.引入依赖 import "github.com/gin-gonic/gin"3. (可选)如果使用诸如 http.StatusOK 之类的常量,则需要引入 net/http 包 import "net/http"二、基…...

工程物料管理信息化建设(十二)——关于工程物料管理系统最后的思考
目录 1 功能回顾1.1 MTO模块1.2 请购模块1.3 采购模块1.4 催交模块1.5 现场管理模块1.6 数据分析和看板模块1.7 其它模块 2 最后几个问题2.1 按管线发料和直接发料重叠2.2 YHA 材料编码的唯一性问题2.3 “合同量单-箱单-入库单” 数据映射 3 关于未来的思考3.1 三个专业之间的关…...
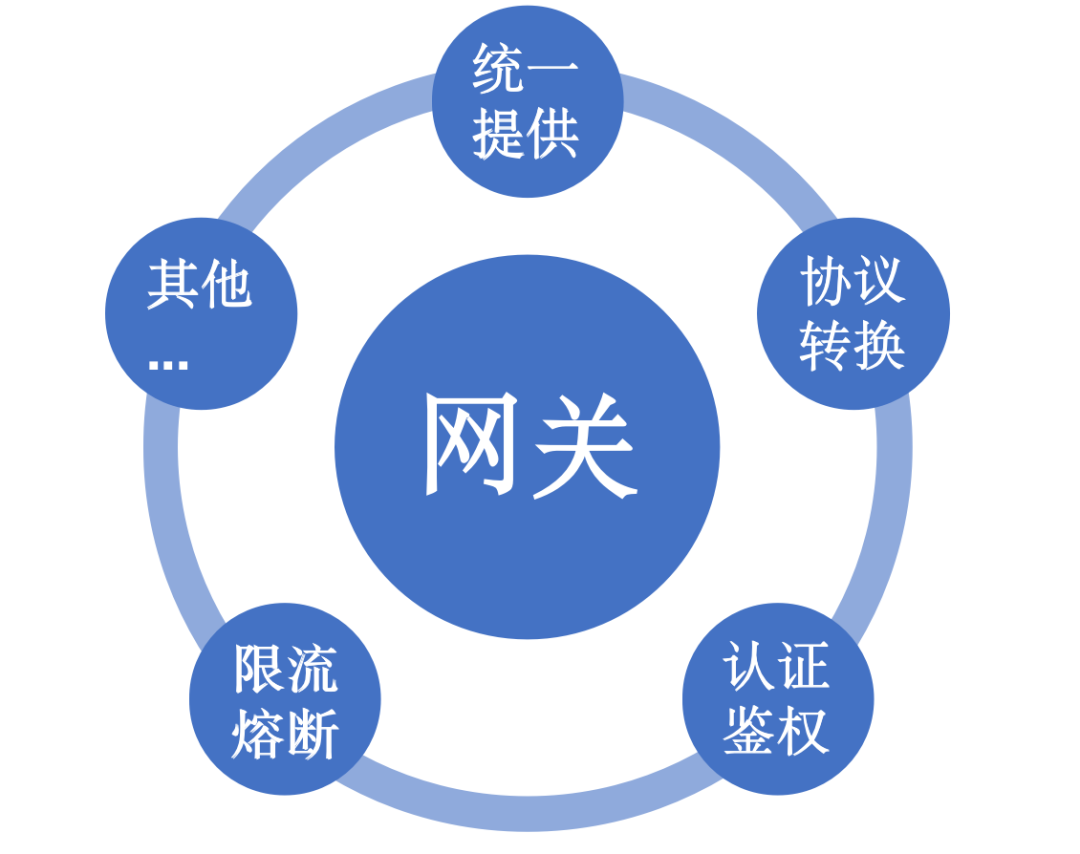
什么是API网关?——驱动数字化转型的“隐形冠军”
什么是API网关 API网关(API Gateway)是一个服务器,位于应用程序和后端服务之间,提供了一种集中式的方式来管理API的访问。它是系统的入口点,负责接收并处理来自客户端的请求,然后将请求路由到相应的后端服…...
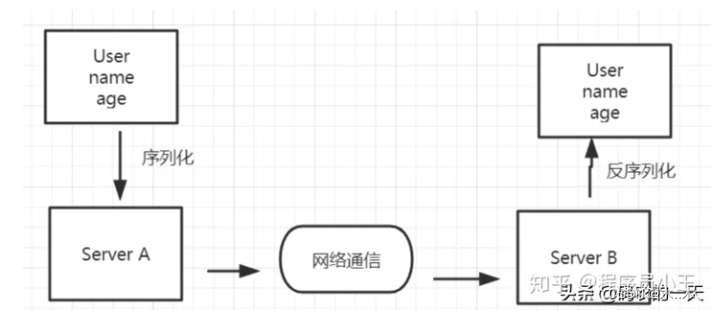
Java 序列化和反序列化为什么要实现 Serializable 接口?
序列化和反序列化 序列化:把对象转换为字节序列的过程称为对象的序列化. 反序列化:把字节序列恢复为对象的过程称为对象的反序列化. 什么时候需要用到序列化和反序列化呢或者对象序列化的两种用途… : (1) 对象持久化:把对象的…...

【【萌新的SOC学习之GPIO学习 水】】
萌新的SOC学习之GPIO学习 General Purpose I/O 通用I/O zynq-7000 SOC PS 分为四大部分 APU application Processor UintMemoryIO外设Interconnect 内部互联 PL : IO外设 GPIO可以连接通用的设备(比如按键) 也可以用GPIO模拟其他的协议 GP…...

10-Node.js入门
01.什么是 Node.js 目标 什么是 Node.js,有什么用,为何能独立执行 JS 代码,演示安装和执行 JS 文件内代码 讲解 Node.js 是一个独立的 JavaScript 运行环境,能独立执行 JS 代码,因为这个特点,它可以用来…...
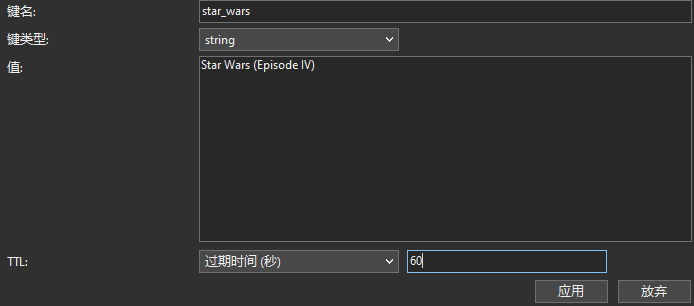
Redis 的过期键 | Navicat 技术干货
Redis 是一种高性能的内存数据存储,以其速度和多功能性而闻名。其中一个有用的特性是为键设置过期时间的功能。在 Redis 中,为键设置过期时间对于管理数据和确保过时或临时数据自动从数据库中删除是至关重要的。在本文中,我们将探讨在 redis-…...

IDC服务器商是如何保护服务器的数据安全
服务器是作为一个公司存储数据和管理服务的设备,随着网络的不断发展大数据的普遍性,所以数据安全问题也越来越受到企业和个体的重视,那么IDC服务器商家是如何对服务器的数据进行安全保护的呢? 配置防火墙。防火墙是服务器的必备工…...
c++中什么时候用double?
c中什么时候用double? 在C中,通常使用double数据类型来表示浮点数,特别是当需要更高的精度时。以下是一些情况下可以考虑使用double的示例: 1. **需要高精度的计算**:当您需要进行精确的浮点数计算时,double通常比flo…...

TCP/IP(四)TCP的连接管理(一)三次握手
一 tcp连接回顾 部分内容来自小林coding TCP篇 记录的目的: 亲身参与进来,加深记忆 ① 引入 前面我们知道: TCP 是面向连接 [点对点的单播]的、可靠的、基于字节流的传输层通信协议面向连接意味着:在使用TCP之前,通信双方必须先建立一…...
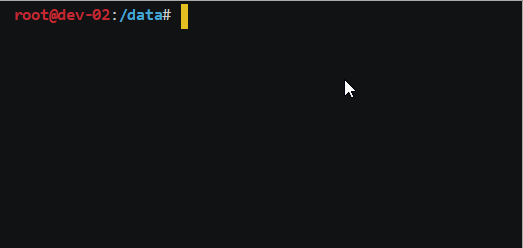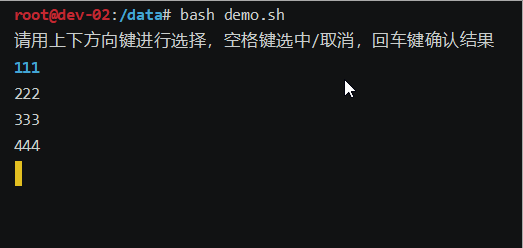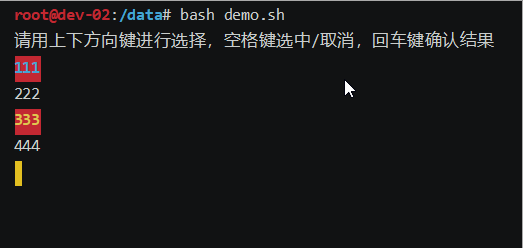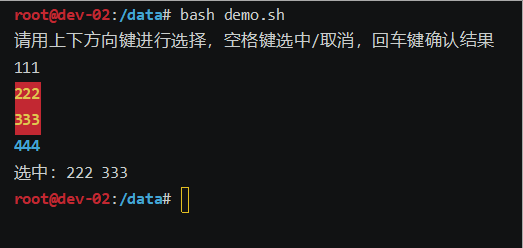
bash上下键选择选项demo脚本
效果如下: 废话不多说,上代码: #!/bin/bashoptions("111" "222" "333" "444") # 选项列表 options_index0 # 默认选中第一个选项 options_len${#options[]}echo "请用上下方向键进行选择&am…...

cf 1886A
题目是输入一个数字,分解成三个数字的和,这三个数字都不相同,并且都不可以被三整除,如果存在输出YES并且输出任意一组可能的三个数字,否则输出NO 代码 #include<bits/stdc.h> using namespace std;int main() …...

Spring5应用之事务属性
作者简介:☕️大家好,我是Aomsir,一个爱折腾的开发者! 个人主页:Aomsir_Spring5应用专栏,Netty应用专栏,RPC应用专栏-CSDN博客 当前专栏:Spring5应用专栏_Aomsir的博客-CSDN博客 文章目录 参考文献前言事务…...

C# 搭建一个简单的WebApi项目23.10.10
一、创建Web API 1、创建一个新的web API项目 启动VS 2019,并在“开始页”选择“创建新项目”。或从“文件”菜单选择“新建”,然后选择“项目”。 选择ASP.NET Web应用程序(.NET Framework) 2.点击下一步,到这个页面时选择Web API。 3.选中…...
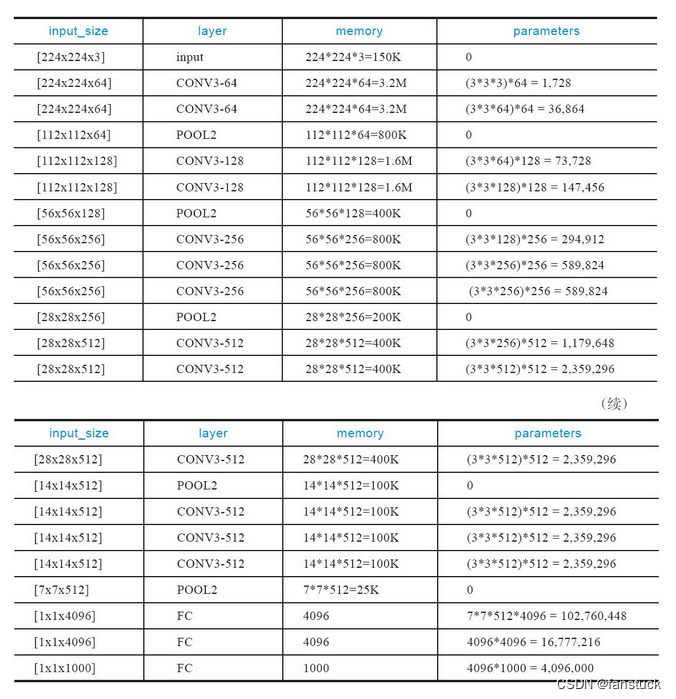
VGG卷积神经网络实现Cifar10图片分类-Pytorch实战
前言 当涉足深度学习,选择合适的框架是至关重要的一步。PyTorch作为三大主流框架之一,以其简单易用的特点,成为初学者们的首选。相比其他框架,PyTorch更像是一门易学的编程语言,让我们专注于实现项目的功能࿰…...

CentOS 7文件系统中的软链接和硬链接
软链接(Symbolic Link) 软链接,也称为符号链接,是一个指向另一个文件或目录的特殊类型的文件。它是一个指向目标文件的符号,就像快捷方式一样。软链接的创建和使用非常灵活,适用于各种情况。 创建软链接 …...
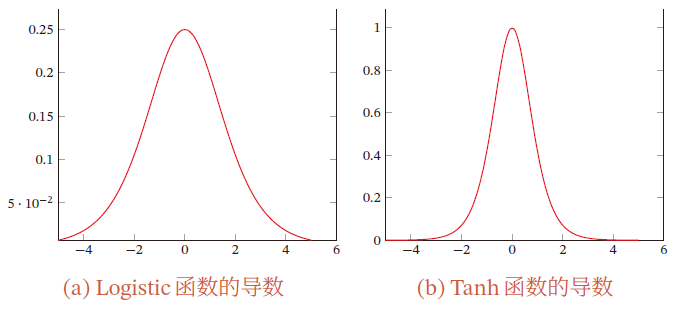
【AI】深度学习——前馈神经网络——全连接前馈神经网络
文章目录 1.1 全连接前馈神经网络1.1.1 符号说明超参数参数活性值 1.1.2 信息传播公式通用近似定理 1.1.3 神经网络与机器学习结合二分类问题多分类问题 1.1.4 参数学习矩阵求导链式法则更为高效的参数学习反向传播算法目标计算 ∂ z ( l ) ∂ w i j ( l ) \frac{\partial z^{…...

Obsidian本地图片终极管理指南:5步打造永不失效的笔记图片库
Obsidian本地图片终极管理指南:5步打造永不失效的笔记图片库 【免费下载链接】obsidian-local-images-plus This repo is a reincarnation of obsidian-local-images plugin which main aim was downloading images in md notes to local storage. 项目地址: http…...
)
告别VPN切换!用Docker在Windows上同时挂载两个EasyConnect(保姆级图文教程)
Windows双开EasyConnect的容器化解决方案:告别VPN切换烦恼 早上九点,刚泡好的咖啡还冒着热气,你正通过公司内网VPN处理OA系统里的报销流程。突然钉钉弹出消息——项目服务器出现异常,需要立即排查。你不得不退出办公VPNÿ…...

零基础玩转UI-TARS-desktop:用自然语言控制电脑的保姆级教程
零基础玩转UI-TARS-desktop:用自然语言控制电脑的保姆级教程 1. 什么是UI-TARS-desktop? UI-TARS-desktop是一款革命性的AI助手工具,它让你可以用最自然的方式与电脑对话。想象一下,你只需要像和朋友聊天一样说出需求࿰…...

3步突破显存限制:FP8量化技术让普通电脑也能运行AI绘画模型
3步突破显存限制:FP8量化技术让普通电脑也能运行AI绘画模型 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev 价值主张:让每台电脑都成为创作工具 你是否曾因显卡配置不足而与AI绘画擦肩而过&…...

提升五倍效率:基于快马平台优化openclaw数据采集工作流
最近在做一个数据采集项目时,发现传统的手动编写爬虫脚本效率实在太低了。每次遇到反爬机制或者需要调整采集策略时,都要花大量时间修改代码。后来尝试用openclaw结合InsCode(快马)平台来优化工作流,效率直接提升了五倍多,这里分享…...

SecGPT-14B模型量化部署:为OpenClaw节省50%显存占用
SecGPT-14B模型量化部署:为OpenClaw节省50%显存占用 1. 为什么需要量化SecGPT-14B 当我第一次尝试在本地部署SecGPT-14B模型来驱动OpenClaw时,显存不足的问题立刻给了我当头一棒。我的RTX 3090显卡24GB显存,在加载完整模型后几乎被占满&…...

s2-pro语音后处理集成:合成结果自动降噪+响度标准化Pipeline教程
s2-pro语音后处理集成:合成结果自动降噪响度标准化Pipeline教程 1. 引言与背景 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,已经为众多开发者提供了高质量的文本转语音服务。但在实际应用中,我们常常会遇到两个关键问题:…...

3个维度解析Ryujinx:开源Switch模拟器的技术实现与实战应用
3个维度解析Ryujinx:开源Switch模拟器的技术实现与实战应用 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx 在游戏开发与逆向工程领域,开源项目往往成为技术创新…...

OpenLayers调用天地图服务--一站式可复用代码【开箱即用】
1. 为什么选择OpenLayers天地图组合 最近两年在WebGIS项目开发中,我越来越频繁地使用OpenLayers天地图的组合方案。这个搭配就像是前端开发里的"瑞士军刀"——OpenLayers提供强大的地图渲染和交互能力,而天地图则提供了稳定可靠的基础地图服务…...

Local SDXL-Turbo保姆级教学:处理‘Out of Memory’错误的3种显存优化技巧
Local SDXL-Turbo保姆级教学:处理‘Out of Memory’错误的3种显存优化技巧 1. 引言:当“实时绘画”遇上“显存不足” 想象一下,你刚部署好Local SDXL-Turbo,正期待体验“打字即出图”的丝滑快感。你输入了第一个提示词ÿ…...