Insight h2database 执行计划评估以及 Selectivity
生成执行计划是任何一个数据库不可缺少的过程。通过本文看执行计划生成原理。
最优的执行计划就是寻找最小计算成本的过程。
本文侧重 BTree 索引的成本计算的实现 以及 基础概念选择度的分析。
寻找最优执行计划
找到最佳的索引,实现最少的遍历,得到想要的结果
单表查询情况
/*** 根据查询条件,获取最佳执行计划.** @param masks per-column comparison bit masks, null means 'always false',* see constants in IndexCondition* @return the plan item* @see org.h2.table.Table#getBestPlanItem*/
public PlanItem getBestPlanItem(Session session, int[] masks, TableFilter filter, SortOrder sortOrder) {// 以扫描索引作为执行计划的默认索引PlanItem item = new PlanItem();item.setIndex(getScanIndex(session));// 表的近似行数 * 10 作为默认成本,最差情况的 Cost 。// long cost = 10 * (tableData.getRowCountApproximation() + Constants.COST_ROW_OFFSET);item.cost = item.getIndex().getCost(session, null, null, null);// 获取 table 包含的所有索引ArrayList<Index> indexes = getIndexes();if (indexes != null && masks != null) {// 跳过扫描索引(上述的 ScanIndex )for (int i = 1, size = indexes.size(); i < size; i++) {Index index = indexes.get(i);// 计算当前索引的成本, 不同的索引有不同的成本计算公式。double cost = index.getCost(session, masks, filter, sortOrder);// 记录/更新最小成本的索引,以此作为最佳执行计划if (cost < item.cost) {item.cost = cost;item.setIndex(index);}}}return item;
}
多表查询情况
/*** 使用穷举策略寻找最佳执行计划* 前提:少于 7 个表关联的情况下。 关联表太多的情况下,会采用随机 + 贪心算法,得出次优的执行计划* @see org.h2.command.dml.Optimizer#calculateBestPlan*/
private void calculateBruteForceAll() {TableFilter[] list = new TableFilter[filters.length];// 关联表(filters) 排列组合 穷举策略,试算各种组合执行计划的成本Permutations<TableFilter> p = Permutations.create(filters, list);// 如果组合遍历次数超过 127 次((x & 127) == 0),或者寻找的耗时超过 cost 的10倍,证明优化过程本末倒置,则停止这个过程。for (int x = 0; !canStop(x) && p.next(); x++) {testPlan(list);}
}
BTree 索引的成本计算
/*** 计算 B-tree 索引中搜索数据所需的预估成本。* Calculate the cost for the given mask as if this index was a typical* b-tree range index. This is the estimated cost required to search one* row, and then iterate over the given number of rows.** @param masks the search mask. condition.getMask(indexConditions), 根据查询条件确定是哪种比较(EQUALITY、RANGE、START、END)* @param rowCount the number of rows in the index, 数据总行数* @see org.h2.index.BaseIndex#getCostRangeIndex*/
protected long getCostRangeIndex(int[] masks, long rowCount, TableFilter filter, SortOrder sortOrder) {rowCount += Constants.COST_ROW_OFFSET;long cost = rowCount;long rows = rowCount;// 总选择度,针对联合索引的情况,计算各个 column 综合参数int totalSelectivity = 0;// 没有查询条件的情况,预估成本是 rowCount, 等于全表扫描if (masks == null) {return cost;}// 遍历索引的 columns, 做两件事:查询条件是否匹配索引列,匹配的成本计算for (int i = 0, len = columns.length; i < len; i++) {Column column = columns[i];int index = column.getColumnId();int mask = masks[index];if ((mask & IndexCondition.EQUALITY) == IndexCondition.EQUALITY) {// 等值比较情况下,如果是 unique 索引,cost 相比以下是最小的。if (i == columns.length - 1 && getIndexType().isUnique()) {cost = 3;break;}// 动态计算总选择度,查询条件与索引 column 重合度越高,选择越大// 为了便于理解,公式还可以改写为:totalSelectivity = totalSelectivity + (100 - totalSelectivity) * column.getSelectivity() / 100;// 也就是:总选择度 = 已有的选择度 + 已有的非选择度中再次用 column 选择度计算的增量totalSelectivity = 100 - ((100 - totalSelectivity) * (100 - column.getSelectivity()) / 100);// 估算当前选择度下的非重复的数据行数(假设索引的选择性是均匀分布的)long distinctRows = rowCount * totalSelectivity / 100;if (distinctRows <= 0) {distinctRows = 1;}// 选择度越大,这里的 rows,也就是 cost 越小。rows = Math.max(rowCount / distinctRows, 1);// cost >= 3cost = 2 + rows;} else if ((mask & IndexCondition.RANGE) == IndexCondition.RANGE) {cost = 2 + rows / 4;break;} else if ((mask & IndexCondition.START) == IndexCondition.START) {cost = 2 + rows / 3;break;} else if ((mask & IndexCondition.END) == IndexCondition.END) {cost = rows / 3;break;} else {// 如果索引的 columns 不支持匹配,则直接终止计算。对于联合索引的情况,如果首列不支持匹配,那么认定此索引失效。break;}}// 当查询中的 ORDER BY 与索引的排序顺序匹配时,// 使用这个索引进行查询通常比使用其他索引更加高效,因此查询优化器会相应地调整这个索引的成本。if (sortOrder != null) {boolean sortOrderMatches = true;int coveringCount = 0;int[] sortTypes = sortOrder.getSortTypes();for (int i = 0, len = sortTypes.length; i < len; i++) {// 匹配计算...coveringCount++;}if (sortOrderMatches) {// 当有两个或更多的覆盖索引可供选择时,查询优化器会倾向于选择覆盖更多列的索引。// 覆盖更多列的索引 cost 更少来体现。cost -= coveringCount;}}return cost;
}
Selectivity
概念
Selectivity is used by the cost based optimizer to calculate the estimated cost of an index.
Selectivity 100 means values are unique, 10 means every distinct value appears 10 times on average.
人工指定 Selectivity
-- sets the selectivity (1-100) for a column.
ALTER TABLE TEST ALTER COLUMN NAME SELECTIVITY 100;
人工更新 Selectivity
-- Updates the selectivity statistics of tables.
ANALYZE SAMPLE_SIZE 1000;
自动更新 Selectivity
随着表数据的更新操作,对应列的 Selectivity 也在发生变化。基于累计值 analyzeAuto 来决定什么时候触发Analysis, 也就是更新 Selectivity。
/*** 默认为 2000 ,也就是说,对表进行大约 2000 次更改后,将对每个用户表运行 ANALYZE。* 自数据库启动以来,每次运行 ANALYZE 的时间间隔都会加倍。* 它不会在本地临时表上运行,也不会在 SELECT 触发器的表上运行。* @see org.h2.engine.DbSettings#analyzeAuto*/
public final int analyzeAuto = get("ANALYZE_AUTO", 2000);
相关文章:

Insight h2database 执行计划评估以及 Selectivity
生成执行计划是任何一个数据库不可缺少的过程。通过本文看执行计划生成原理。 最优的执行计划就是寻找最小计算成本的过程。 本文侧重 BTree 索引的成本计算的实现 以及 基础概念选择度的分析。 寻找最优执行计划 找到最佳的索引,实现最少的遍历,得到想要…...

[天翼杯 2021]esay_eval - RCE(disabled_function绕过||AS_Redis绕过)+反序列化(大小写wakeup绕过)
[天翼杯 2021]esay_eval 1 解题流程1.1 分析1.2 解题1.2.1 一阶段1.2.2 二阶段二、思考总结题目代码: <?php class A{public $code = "";...
基于SSM+Vue的在线作业管理系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用Vue技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...
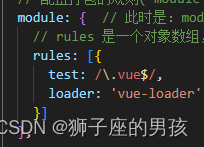
Webapck 解决:[webpack-cli] Error: Cannot find module ‘vue-loader/lib/plugin‘ 的问题
1、问题描述: 其一、报错为: [webpack-cli] Error: Cannot find module vue-loader/lib/plugin 中文为: [webpack-cli] 错误:找不到模块“vue-loader/lib/plugin” 其二、问题描述为: 在项目打包的时候 npm run …...

使用UiPath和AA构建的解决方案 5. 使用UiPath ReFramework处理采购订单
在本章中,我们将使用UiPath Robotic Enterprise Framework(简称ReFramework)创建自动化。ReFramework是一个快速构建强大的UiPath自动化的模板。它可以作为所有UiPath项目的起点。 模板可以满足您在任何自动化中的大部分核心需求——在配置文件中读取和存储数据,强大的异常…...

SQL基本语法用例大全
文章目录 SQL语法概述简单查询计算列查询条件查询范围查询使用逻辑运算符过滤数据使用IN操作符过滤数据格式化结果集模糊查询行数据过滤数据排序数据统计分析分组总计简单子查询多行子查询多表链接插入数据更新和删除数据使用视图数据库管理数据表管理 SQL语法概述 SQL(Struct…...

MAX17058_MAX17059 STM32 iic 驱动设计
本文采用资源下载链接,含完整工程代码 MAX17058-MAX17059STM32iic驱动设计内含有代码、详细设计过程文档,实际项目中使用代码,稳定可靠资源-CSDN文库 简介 MAX17058/MAX17059 IC是微小的锂离子(Li )在手持和便携式设备的电池电量计。MAX170…...
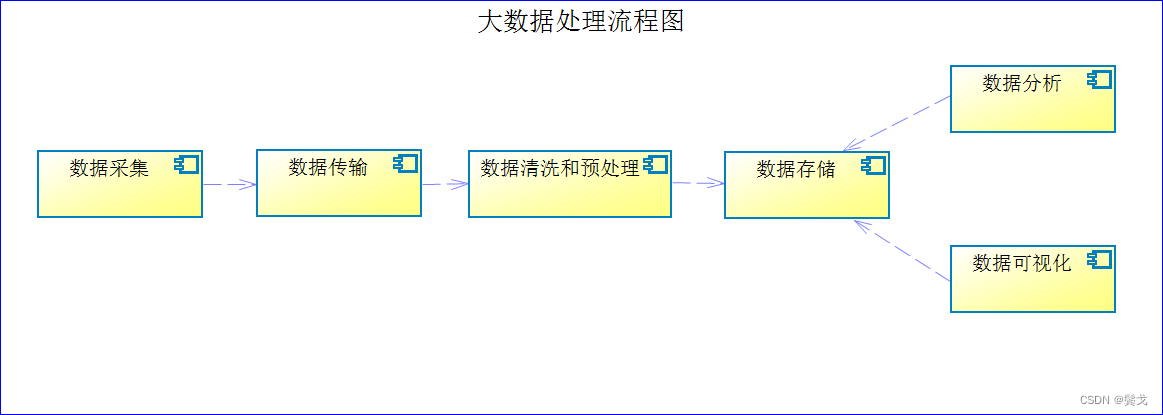
大数据笔记-大数据处理流程
大家对大数据处理流程大体上认识差不多,具体做起来可能细节各不相同,一幅简单的大数据处理流程图如下: 1)数据采集:数据采集是大数据处理的第一步。 数据采集面对的数据来源是多种多样的,包括各种传感器、社…...

wps演示时图片任意位置拖动
wps演示时图片任意位置拖动 1.wps11.1版本,其他版本的宏插件可以自己下载。2.先确认自己的wps版本是不是11.13.检查是否有图像工具4.检查文件格式和安全5.开发工具--图像6.选中图像控件,右击选择查看代码,将原有代码删除,将下边代…...
NodeJs中使用JSONP和Cors实现跨域
跨域是为了解决浏览器请求域名,协议,端口不同的接口,相同的接口是不需要实现跨域的。 1.使用JSONP格式实现跨域 实现步骤 动态创建一个script标签 src指向接口的地址 定义一个函数和后端调用的函数名一样 实现代码 -- 在nodejs中使用http内…...
Typora for Mac:优雅的Markdown文本编辑器,提升你的写作体验
Typora是一款强大的Markdown文本编辑器,专为Mac用户设计。无论你是写作爱好者,还是专业作家或博客作者,Typora都能为你提供无与伦比的写作体验。 1. 直观的界面设计 Typora的界面简洁明了,让你专注于写作,而不是被复…...
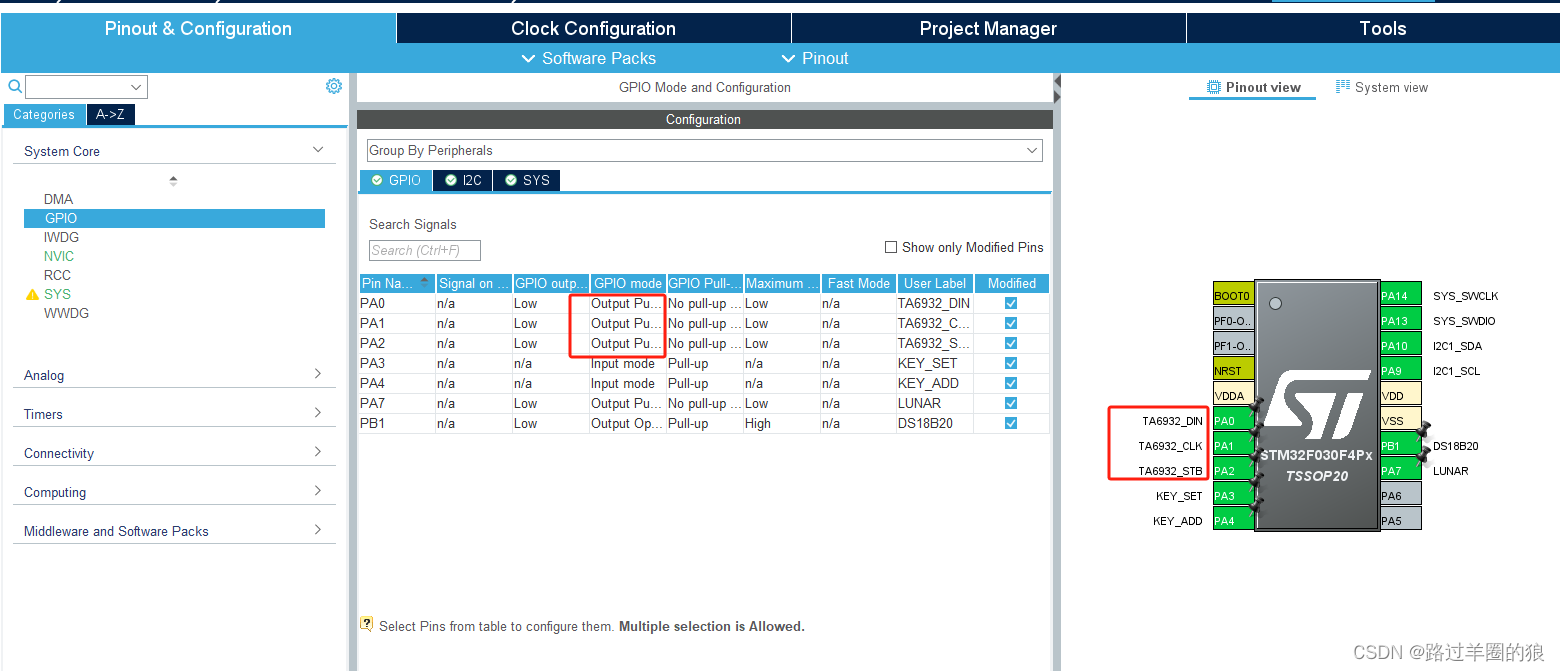
STM32使用HAL库驱动TA6932数码管驱动芯片
TA6932介绍 8段16位,支持共阴共阳LED数码管。 2、STM32CUBEMX配置引脚 推挽配置即可。 3、头文件 /******************************************************************************************** * TA6932:8段16位数码管驱动 *******************…...
day25--JS进阶(递归函数,深浅拷贝,异常处理,改变this指向,防抖及节流)
目录 浅拷贝 1.拷贝对象①Object.assgin() ②展开运算符newObj {...obj}拷贝对象 2.拷贝数组 ①Array.prototype.concat() ② newArr [...arr] 深拷贝 1.通过递归实现深拷贝 2.lodash/cloneDeep实现 3.通过JSON.stringify()实现 异常处理 throw抛异常 try/catch捕获…...

Python爬虫(二十三)_selenium案例:动态模拟页面点击
本篇主要介绍使用selenium模拟点击下一页,更多内容请参考:Python学习指南 #-*- coding:utf-8 -*-import unittest from selenium import webdriver from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup import timeclass douyuSelenium…...
nodejs+vue宠物店管理系统
例如:如何在工作琐碎,记录繁多的情况下将宠物店管理的当前情况反应给管理员决策,等等。在此情况下开发一款宠物店管理系统小程序, 困扰管理层的许多问题当中,宠物店管理也是不敢忽视的一块。但是管理好宠物店又面临很多麻烦需要解决,于是乎变得非常合乎时…...

ceph版本和Ceph的CSI驱动程序
ceph版本和Ceph的CSI驱动程序 ceph查看ceph版本Ceph的CSI驱动程序 ceph ceph版本和Ceph的CSI驱动程序 查看ceph版本 官网ceph-releases-index Ceph的CSI驱动程序 Ceph的CSI驱动程序 https://github.com/ceph/ceph-csi...
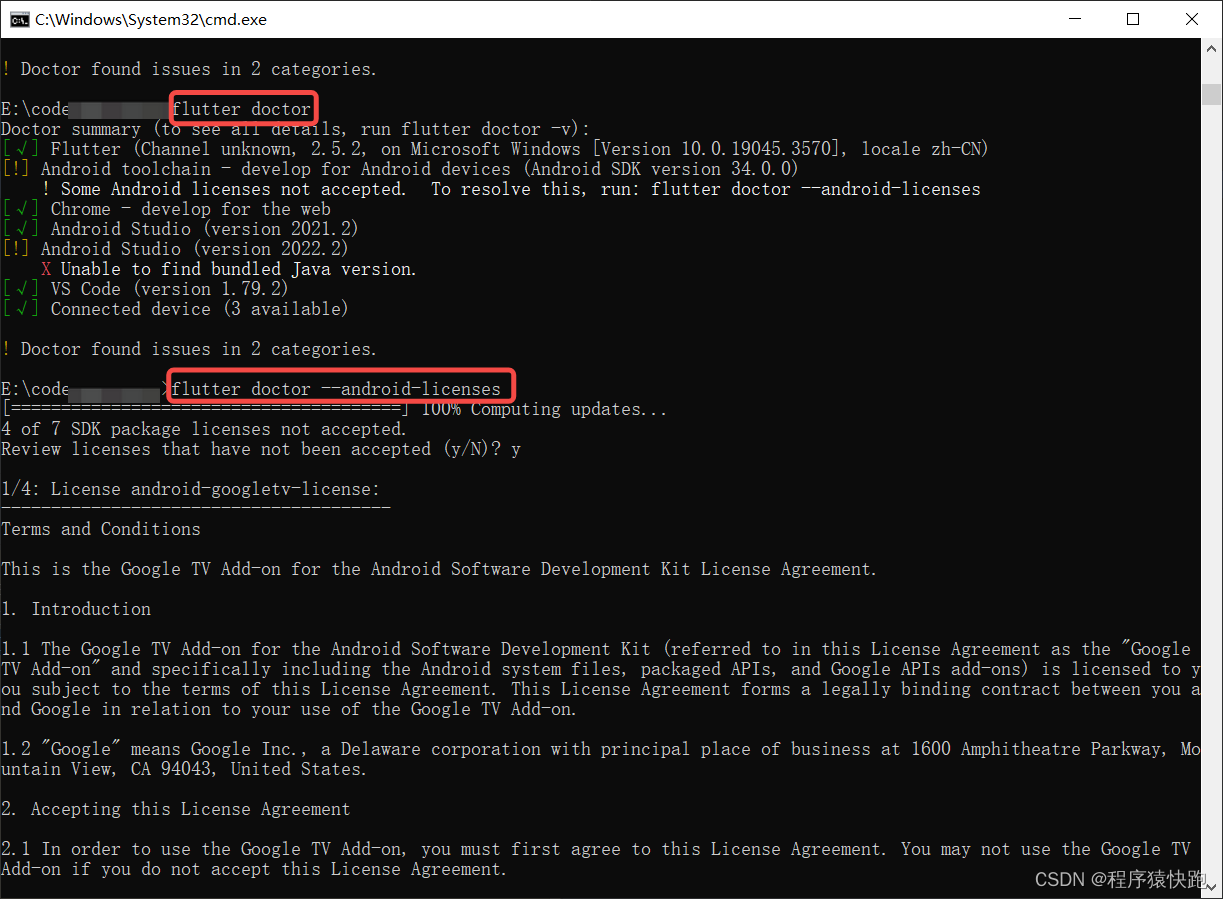
Android Studio Flutter真机调试错误
错误:Could not locate aapt. Please ensure you have the Android buildtools installed. No application found for TargetPlatform.android_arm64. Is your project missing an android/app/src/main/AndroidManifest.xml? Consider running "flutter crea…...

MQ - 41 容灾:跨地域、跨可用区的容灾和同步的方案设计
文章目录 导图概述容灾能力的理论基础集群内和集群间容灾RTO 和 RPO集群内容灾方案的原理分析RTO 和 RPO跨集群容灾方案的原理分析三种复制方式客户端连接集群主备切换方式一 直连 Broker方式二 域名方式三 虚拟 IP (推荐)双向同步RTO 和 RPOApache Kafka MirrorMaker (V2版…...
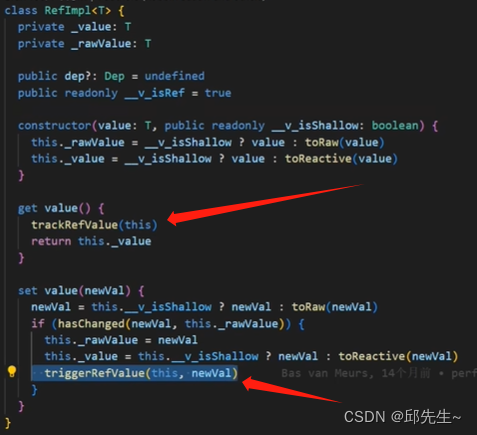
vue3学习(二)--- ref和reactive
文章目录 ref1.1 ref将基础类型和对象类型数据转为响应式1.2 ref()获取id元素1.3 isRef reactive1.1 reactive()将引用类型数据转为响应式数据,基本类型无效1.2 ref和reactive的联系 toRef 和 toRefs1.1 如果原始对象是非响应式的就不会更新视图 数据是会变的 ref …...
网络-HTTPS
文章目录 前言一、HTTPS简介优点SSL/TSL工作流程 加密1、对称加密2、非对称加密 二、使用HTTPS1.openSSL生成私钥(1)node服务端(2)nginx配置https服务(前端) nginx服务 总结 前言 Http 存在不安全、无状态…...

Vim 快捷键手册
Vim 快捷键手册 模式说明 普通模式(Normal):默认模式,用于导航和命令执行插入模式(Insert):输入文本可视模式(Visual):选择文本命令模式(Command&…...

用快马平台十分钟复刻lostlife:快速构建你的首个交互式游戏原型
最近想尝试做个简单的交互式游戏原型,正好看到InsCode(快马)平台可以快速生成项目代码,就试了试复刻类似lostlife的玩法。整个过程比想象中顺利,分享下我的实现思路: 确定核心交互逻辑 游戏的核心是点击角色触发反馈,所…...

如何突破登录壁垒?多登录系统让所有玩家畅玩同一游戏服务器
如何突破登录壁垒?多登录系统让所有玩家畅玩同一游戏服务器 【免费下载链接】MultiLogin 外置共存 项目地址: https://gitcode.com/gh_mirrors/mu/MultiLogin 在游戏服务器管理中,管理员常常面临一个棘手问题:如何让使用不同账号系统的…...

cbindgen高级配置指南:自定义类型映射与导出规则详解
cbindgen高级配置指南:自定义类型映射与导出规则详解 【免费下载链接】cbindgen A project for generating C bindings from Rust code 项目地址: https://gitcode.com/gh_mirrors/cb/cbindgen cbindgen 是 Rust 生态系统中最强大的 C/C 绑定生成工具&#x…...

Windows 11安装终极指南:5分钟绕过所有硬件限制
Windows 11安装终极指南:5分钟绕过所有硬件限制 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat 还在为Wind…...

Nunchaku FLUX.1-dev 开发环境配置:Anaconda虚拟环境创建与管理指南
Nunchaku FLUX.1-dev 开发环境配置:Anaconda虚拟环境创建与管理指南 想玩转Nunchaku FLUX.1-dev这类前沿的AI模型,第一步也是最关键的一步,就是把它的“家”给搭好。这个“家”就是Python虚拟环境。你可能听过不少因为环境依赖冲突ÿ…...

StructBERT模型监控方案:性能与质量实时追踪
StructBERT模型监控方案:性能与质量实时追踪 1. 引言 当你把StructBERT模型部署到生产环境后,最担心的是什么?是服务突然崩溃,还是响应速度变慢,或者是模型预测质量下降?这些问题如果等到用户投诉才发现&…...
)
WSL2+VSCode+Github Copilot开发环境配置全指南(避坑版)
WSL2VSCodeGithub Copilot开发环境配置全指南(避坑版) 在当今的开发环境中,Windows Subsystem for Linux 2 (WSL2) 已经成为许多开发者的首选工具,它完美结合了Windows的易用性和Linux的强大功能。而Visual Studio Code (VSCode)…...

GitHub中文界面终极指南:5分钟告别英文恐惧症
GitHub中文界面终极指南:5分钟告别英文恐惧症 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 还在为GitHub满屏的英文而烦…...

在Ubuntu中通过命令行下载和安装Android Studio最新版本
在Ubuntu中通过命令行下载和安装Android Studio最新版本,有以下几种方法: 方法一:直接下载官方最新版本(推荐) 1. 安装Java JDK依赖 sudo apt update sudo apt install openjdk-11-jdk -y2. 安装64位系统所需的32位库 …...