SentenceTransformer使用多GPU加速向量化
文章目录
- 前言
- 代码
前言
当我们需要对大规模的数据向量化以存到向量数据库中时,且服务器上有多个GPU可以支配,我们希望同时利用所有的GPU来并行这一过程,加速向量化。
代码
就几行代码,不废话了
from sentence_transformers import SentenceTransformer#Important, you need to shield your code with if __name__. Otherwise, CUDA runs into issues when spawning new processes.
if __name__ == '__main__':#Create a large list of 100k sentencessentences = ["This is sentence {}".format(i) for i in range(100000)]#Define the modelmodel = SentenceTransformer('all-MiniLM-L6-v2')#Start the multi-process pool on all available CUDA devicespool = model.start_multi_process_pool()#Compute the embeddings using the multi-process poolemb = model.encode_multi_process(sentences, pool)print("Embeddings computed. Shape:", emb.shape)#Optional: Stop the proccesses in the poolmodel.stop_multi_process_pool(pool)
注意:一定要加if __name__ == '__main__':这一句,不然报如下错:
RuntimeError: An attempt has been made to start a new process before thecurrent process has finished its bootstrapping phase.This probably means that you are not using fork to start yourchild processes and you have forgotten to use the proper idiomin the main module:if __name__ == '__main__':freeze_support()...The "freeze_support()" line can be omitted if the programis not going to be frozen to produce an executable.
其实官方已经给出代码啦,我只不过复制粘贴了一下,代码位置:computing_embeddings_multi_gpu.py
官方还给出了流式encode的例子,也是多GPU并行的,如下:
from sentence_transformers import SentenceTransformer, LoggingHandler
import logging
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdmlogging.basicConfig(format='%(asctime)s - %(message)s',datefmt='%Y-%m-%d %H:%M:%S',level=logging.INFO,handlers=[LoggingHandler()])#Important, you need to shield your code with if __name__. Otherwise, CUDA runs into issues when spawning new processes.
if __name__ == '__main__':#Set paramsdata_stream_size = 16384 #Size of the data that is loaded into memory at oncechunk_size = 1024 #Size of the chunks that are sent to each processencode_batch_size = 128 #Batch size of the model#Load a large dataset in streaming mode. more info: https://huggingface.co/docs/datasets/streamdataset = load_dataset('yahoo_answers_topics', split='train', streaming=True)dataloader = DataLoader(dataset.with_format("torch"), batch_size=data_stream_size)#Define the modelmodel = SentenceTransformer('all-MiniLM-L6-v2')#Start the multi-process pool on all available CUDA devicespool = model.start_multi_process_pool()for i, batch in enumerate(tqdm(dataloader)):#Compute the embeddings using the multi-process poolsentences = batch['best_answer']batch_emb = model.encode_multi_process(sentences, pool, chunk_size=chunk_size, batch_size=encode_batch_size)print("Embeddings computed for 1 batch. Shape:", batch_emb.shape)#Optional: Stop the proccesses in the poolmodel.stop_multi_process_pool(pool)
官方案例:computing_embeddings_streaming.py
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.105.01 Driver Version: 515.105.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800-SXM... On | 00000000:23:00.0 Off | 0 |
| N/A 58C P0 297W / 400W | 75340MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A800-SXM... On | 00000000:29:00.0 Off | 0 |
| N/A 71C P0 352W / 400W | 80672MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A800-SXM... On | 00000000:52:00.0 Off | 0 |
| N/A 68C P0 398W / 400W | 75756MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A800-SXM... On | 00000000:57:00.0 Off | 0 |
| N/A 58C P0 341W / 400W | 75994MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 NVIDIA A800-SXM... On | 00000000:8D:00.0 Off | 0 |
| N/A 56C P0 319W / 400W | 70084MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 NVIDIA A800-SXM... On | 00000000:92:00.0 Off | 0 |
| N/A 70C P0 354W / 400W | 76314MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 NVIDIA A800-SXM... On | 00000000:BF:00.0 Off | 0 |
| N/A 73C P0 360W / 400W | 75876MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A800-SXM... On | 00000000:C5:00.0 Off | 0 |
| N/A 57C P0 364W / 400W | 80404MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
嘎嘎快啊
相关文章:
SentenceTransformer使用多GPU加速向量化
文章目录 前言代码 前言 当我们需要对大规模的数据向量化以存到向量数据库中时,且服务器上有多个GPU可以支配,我们希望同时利用所有的GPU来并行这一过程,加速向量化。 代码 就几行代码,不废话了 from sentence_transformers i…...

架构师-软件工程习题选择题
架构师-软件工程习题选择题 真题案例题 真题 c 瀑布模型:针对软件需求明确的情况,将前一个阶段做完,才能开始下一个阶段 原型模型:针对需求不明确的情况,快速搭建出系统原型,然后根据系统原型和客户确认需求…...

springboot单独在指定地方输出sql
一般线上项目都是将日志进行关闭,因为mybatis日志打印,时间长了,会占用大量的内存,如果我想在我指定的地方进行打印sql情况,怎么玩呢! 下面这个场景: 某天线上的项目出bug了,日志打印…...
gpio内部结构(一)
一,GPIO内部结构 1,保护二极管 * 引脚内部加上这两个保护二级管可以防止引脚外部过高或过低的电压输入。 * 当引脚电压高于 VDD_FT 或 VDD 时,上方的二极管导通吸收这个高电压。 * 当引脚电压低于 VSS 时,下方的二极管导通&…...

【C++14保姆级教程】变量模板,Labmda泛型
文章目录 前言一、变量模板(Variable Templates)1.1 变量模板是什么1.2 泛型大概使用1.3 示例代码11.4 示例代码21.5 示例代码3 二、Lambda泛型(Lambda Generics)2.1 Lambda表达式泛型是什么?2.2 函数原型怎么写&#…...

LLM - 旋转位置编码 RoPE 代码详解
目录 一.引言 二.RoPE 理论 1.RoPE 矩阵形式 2.RoPE 图例形式 3.RoPE 实践分析 三.RoPE 代码分析 1.源码获取 2.源码分析 3.rotary_emb 3.1 __init__ 3.2 forward 4.apply_rotary_pos_emb 4.1 rotate_half 4.2 apply_rotary_pos_emb 四.RoPE 代码实现 1.Q/K/V …...

Vue之VueX知识探索(一起了解关于VueX的新世界)
目录 前言 一、VueX简介 1. 什么是VueX 2. VueX的作用及重要性 3. VueX的应用场景 二、VueX的使用准备工作 1. 下载安装VueX 2. vuex获取值以及改变值 2.1 创建所需示例 2.2 将创建好的.vue文件页面显示 2.3 创建VueX的相关文件 2.4 配置VueX四个js文件 2.5 加载到vue示…...
提升吃鸡战斗力,分享顶级作战干货!
大家好!作为一名吃鸡玩家,你是否也希望提高自己的游戏战斗力?在这里,我将为大家分享一些顶级游戏作战干货,以及方便吃鸡作图和查询装备皮肤库存的实用工具。 首先,让我们提到绝地求生作图工具推荐。通过使用…...

【rust】cargo的概念和使用方法
啥是cargo 包管理器 cargo 提供了一系列的工具,从项目的建立、构建到测试、运行直至部署,为 Rust 项目的管理提供尽可能完整的手段,与 Rust 语言及其编译器 rustc 紧密结合。 创建项目 使用cargo创建一个项目: $ cargo new wo…...

MySQL数据库——SQL优化(2)-order by 优化、group by 优化
目录 order by 优化 概述 测试 优化原则 group by 优化 测试 优化原则 order by 优化 概述 MySQL的排序,有两种方式: Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排…...
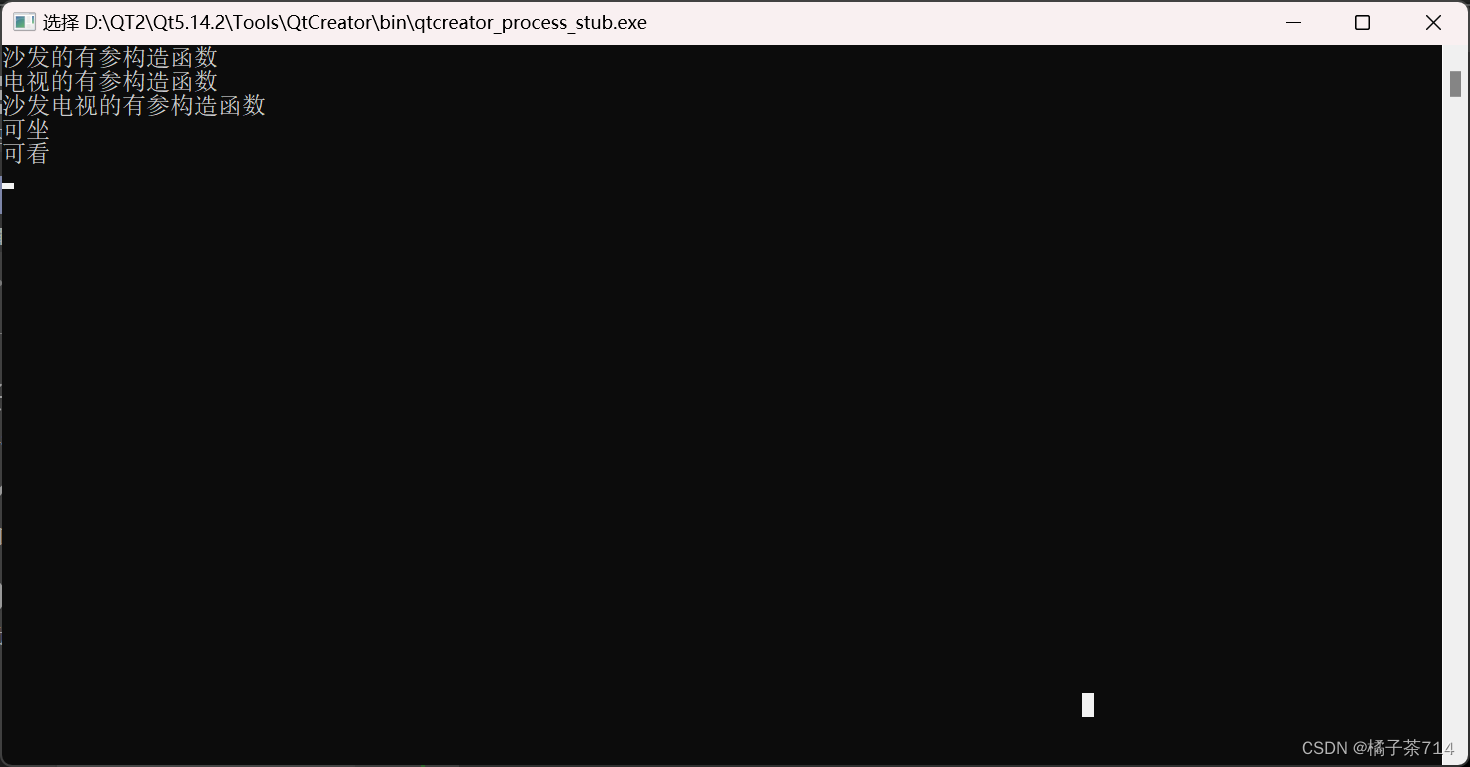
C++DAY43
#include <iostream>using namespace std;//封装 沙发 类 class Sofa { private:string living; public:Sofa(){cout << "沙发的无参构造函数" << endl;}Sofa(string l):living(l){cout << "沙发的有参构造函数" << endl;}v…...

大模型的超级“外脑”——向量数据库解决大模型的三大挑战
随着AI大模型产品及应用呈现爆发式增长,新的AI时代已经到来。向量数据库可与大语言模型配合使用,解决大模型落地过程中的痛点,已成为企业数据处理和应用大模型的必选项。在近日举行的华为全联接大会2023期间,华为云正式发布GaussDB向量数据库。GaussDB向量数据库基于GaussD…...

opencv读取摄像头并读取时间戳
下面这行代码是获取摄像头每帧的时间戳: double timestamp cap.get(cv::CAP_PROP_POS_MSEC); 改变帧率的方法是: cap.set(cv::CAP_PROP_FPS, 30); //帧率改为30 但是实际测试时发现帧率并未被改变,这个可能和VideoCapture cap(cv::CAP_V…...
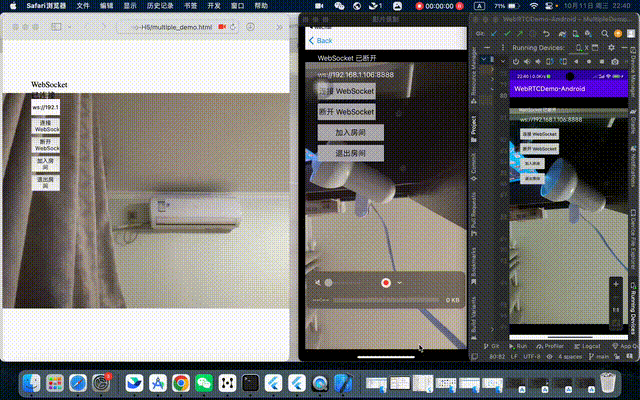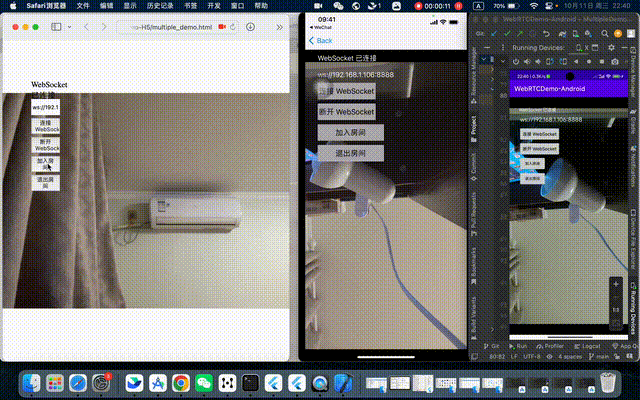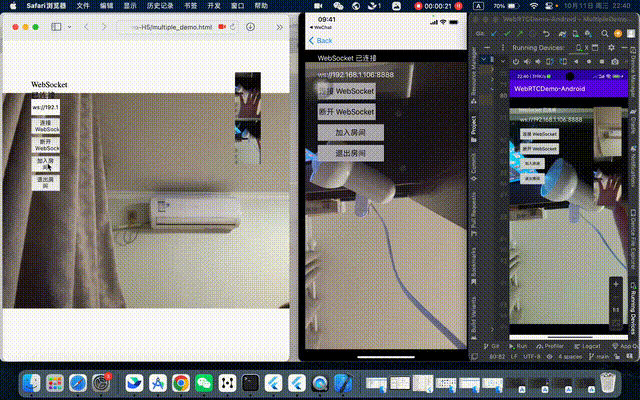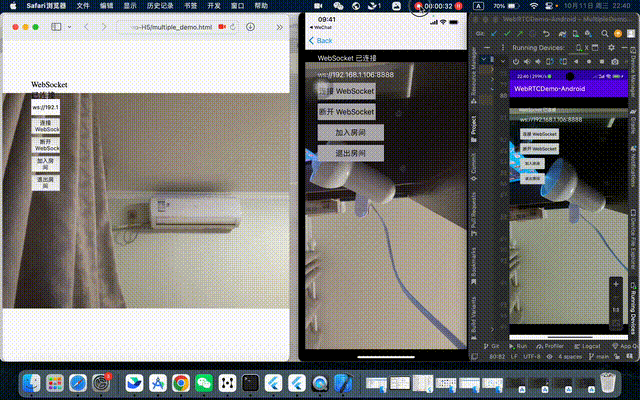
WebRTC 系列(四、多人通话,H5、Android、iOS)
WebRTC 系列(三、点对点通话,H5、Android、iOS) 上一篇博客中,我们已经实现了点对点通话,即一对一通话,这一次就接着实现多人通话。多人通话的实现方式呢也有好几种方案,这里我简单介绍两种方案…...
)
uniapp 点击 富文本元素 图片 可以预览(非nvue)
我使用的是uniapp 官方推荐的组件 rich-text,一般我能用官方级用官方,更有保障一些。 一、整体逻辑 1. 定义一段html标签字符串,里面包含图片 2. 将字符串放入rich-text组件中,绑定点击事件itemclick 3. 通过点击事件获取到图片ur…...
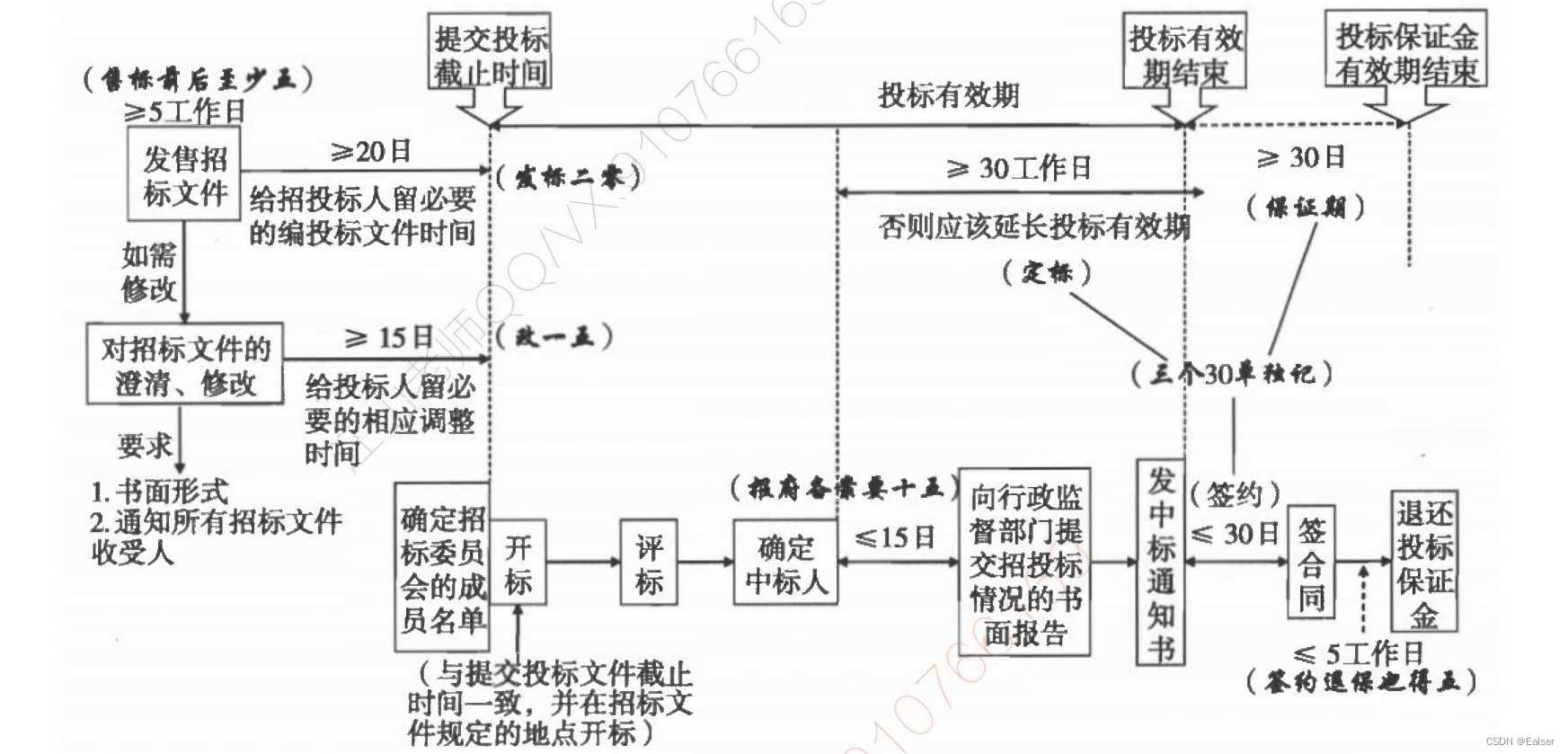
【2023年11月第四版教材】第24章《法律法规与标准规范》(合集篇)
第24章《法律法规与标准规范》(合集篇) 1 民法典(合同编)2 招标投标法2.1 关于时间的总结2.2 内容 3 政府采购法4 专利法5 著作权法6 商标法7 网络安全法8 数据安全法 1 民法典(合同编) 1、要约是希望和他人订立合同的…...

提升战斗力!吃鸡行家分享顶级游戏干货,助你轻松拿下绝地求生
作为吃鸡行家,我们都知道,在绝地求生中提高战斗力至关重要。今天我来分享一些独特的干货,帮助你成为顶级的吃鸡玩家,并分享一些方便吃鸡作图、装备皮肤库存展示和查询的技巧。 首先,让我们来谈谈绝地求生作图工具推荐。…...

C语言练习百题之宏#define命令
宏(Macro)是C语言中的一种预处理指令,它使用#define命令定义符号常量、宏函数和代码片段。下面列举了各种宏的应用场景以及相关注意事项: 定义常量: #define PI 3.14159265注意事项:使用宏定义常量可以提高…...

阿里云存储I/O性能、IOPS和吞吐量是什么意思?
云盘的存储I/O性能是什么?存储I/O性能又称存储读写性能,指不同阿里云服务器ECS实例规格挂载云盘时,可以达到的性能表现,包括IOPS和吞吐量。阿里云百科网aliyunbaike.com分享阿里云服务器云盘(系统盘或数据盘࿰…...

Linux知识点 -- 网络基础 -- 数据链路层
Linux知识点 – 网络基础 – 数据链路层 文章目录 Linux知识点 -- 网络基础 -- 数据链路层一、数据链路层1.以太网2.以太网帧格式3.重谈局域网原理4.MAC地址5.MTU6.查看硬件地址和MTU的命令7.ARP协议 二、其他重要协议或技术1.DNS(Domain Name System)2.…...

国产视频会议核心技术解析:架构、特性与全场景落地
在数字化协同办公发展与信息安全防护需求的双重推动下,视频会议国产化已经从政策导向阶段迈入技术落地的成熟期,其核心价值集中体现在自主可控、安全可靠、全场景适配三大维度。依托硬件基础、编解码技术、传输优化、安全防护以及生态兼容的全链条技术创…...

时间放大器:从亚稳态到数字训练式的硬件实现解析
1. 时间放大器的核心价值与应用场景 时间放大器(Time Amplifier)这个名词听起来有点科幻,但它的原理其实非常接地气。想象一下你用两根手指同时按下钢琴的两个琴键,如果两次按键的时间差只有几毫秒,普通人耳朵可能分辨…...

嵌入式工程师的中年危机与转型策略
1. 嵌入式工程师的中年危机:一个行业的缩影44岁的梧桐,一位拥有21年嵌入式开发经验的资深架构师,在2023年的寒冬里收到了人生第一封解约通知书。这个场景让我想起公司上周的招聘会——38岁的候选人简历被默默放进了"待定"文件夹&am…...

单片机触摸按键实现方案与优化技巧
1. 单片机实现触摸按键的核心原理在消费电子产品中,触摸按键已经成为主流交互方式。传统方案多采用专用触摸IC,但实际上许多低功耗单片机也能实现这一功能。其核心原理都是基于电容感测技术,通过检测电极电容变化来判断触摸状态。电容式触摸按…...

云原生时代的前端部署最佳实践
云原生时代的前端部署最佳实践 引言:前端部署的进化 哥们,别整那些花里胡哨的!作为一个前端开发兼摇滚鼓手,我最烦的就是部署时的各种幺蛾子。从传统的FTP上传,到现在的云原生部署,前端部署已经发生了天翻地…...

基于Python的毕业生实习管理系统
项目介绍:基于Python的毕业生实习管理系统技术栈 项目编号:本课题采用 Python 语言进行开发,系统整体基于 Web 平台实现。前端页面主要使用 HTML、CSS、JavaScript 进行构建,并结合 Bootstrap 提升页面布局与交互效果;…...

Go语言的网络编程:从TCP到WebSocket
Go语言的网络编程:从TCP到WebSocket 网络编程的重要性 在现代软件开发中,网络编程是一项基本技能。通过网络编程,我们可以: 构建客户端-服务器应用程序实现分布式系统开发 Web 应用和 API实现实时通信功能与其他服务进行集成 Go 语…...

Python脚本:一键将图片按顺序合成PDF
📌 前言在日常工作和学习中,我们经常需要将多张图片(如扫描件、截图、照片)合并成一个PDF文件。虽然有很多现成的工具可以实现,但用Python自己写一个脚本不仅灵活,还能避免上传到第三方网站带来的隐私风险。…...

10款主流施工项目管理系统对比:建筑工程企业选型参考
本文将深入对比10款建筑工程项目管理系统:Worktile、Oracle Primavera P6、Oracle Aconex、Autodesk Build、Procore、Microsoft Project、Smartsheet、monday.com、Jira Confluence、广联达数字项目管理平台。文章将从定位、适用规模、部署方式、核心模块、安全合…...
)
OpenClaw 实用指南-节假日系统巡检全自动化(下)
前言 在上一篇文章中,我们已详细讲解了节假日系统巡检全自动化的前三个核心部分,分别是:Part1:AI节假日智能判断、Part2:目标服务器稳定连接、Part3:借助“小龙虾”工具批量部署软件,并利用部署…...