MySQL数据库——SQL优化(2)-order by 优化、group by 优化
目录
order by 优化
概述
测试
优化原则
group by 优化
测试
优化原则
order by 优化
概述
MySQL的排序,有两种方式:
- Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
- Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序
操作时,尽量要优化为 Using index。
测试
假设现在在tb_user表中根据年龄或电话号码来排序: (age和phone均无索引)
explain select id,age,phone from tb_user order by age ;
explain select id,age,phone from tb_user order by age, phone ; 由于 age, phone 都没有索引,所以此时再排序时,出现Using filesort, 排序性能较低。
由于 age, phone 都没有索引,所以此时再排序时,出现Using filesort, 排序性能较低。
创建索引
-- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);创建索引后,根据age和phone进行升序排序:
explain select id,age,phone from tb_user order by age,phone;
建立索引之后,再次进行排序查询,就由原来的Using filesort,变为了 Using index,性能就是比较高的了。
再根据age和phone进行降序排序:
explain select id,age,phone from tb_user order by age desc ,phone desc;
也出现 Using index, 但是此时Extra中出现了 Backward index scan,这个代表反向扫描索引,因为在MySQL中我们创建的索引,默认索引的叶子节点是从小到大排序的,而此时我们查询排序时,是从大到小,所以,在降序排序扫描时,就是反向扫描,就会出现 Backward index scan。
在MySQL8版本中,支持降序索引,我们也可以创建降序索引。
根据phone,age进行升序排序,phone在前,age在后:
explain select id,age,phone from tb_user order by phone , age;
排序时,也需要满足最左前缀法则,否则也会出现 filesort。
因为在创建索引的时候, age是第一个字段,phone是第二个字段,所以排序时也该按照这个顺序来,否则就会出现 Using filesort。
根据age, phone进行降序一个升序,一个降序:
explain select id,age,phone from tb_user order by age asc , phone desc ;因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时就会出现Using filesort。

为了解决上述的问题,我们可以创建一个索引,这个联合索引中 age 升序排序,phone 倒序排序。
创建联合索引(age 升序排序,phone 倒序排序) :
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);这时执行SQL语句就达到我们的预期了:

优化原则
由上述的测试,我们得出order by优化原则:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
group by 优化
分组操作,我们主要来看看索引对于分组操作的影响。
测试
在没有索引的情况下,执行如下SQL,查询执行计划:
explain select profession , count(*) from tb_user group by profession ; 
与order by优化类似,Using temporary也是效率比较低的,我们要利用索引将其变为Using index。
我们针对于 profession , age, status 创建一个联合索引:
create index idx_user_pro_age_sta on tb_user(profession , age , status);然后再执行前面相同的SQL查看执行计划:
explain select profession , count(*) from tb_user group by profession ; 
同样,如果仅仅根据age分组,就会出现 Using temporary ;
而如果是根据profession,age两个字段同时分组,则不会出现 Using temporary。
原因是对于分组操作,在联合索引中,也是符合最左前缀法则的。
优化原则
所以,在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是满足最左前缀法则的。
END
学习自:黑马程序员——MySQL数据库课程
相关文章:
MySQL数据库——SQL优化(2)-order by 优化、group by 优化
目录 order by 优化 概述 测试 优化原则 group by 优化 测试 优化原则 order by 优化 概述 MySQL的排序,有两种方式: Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排…...
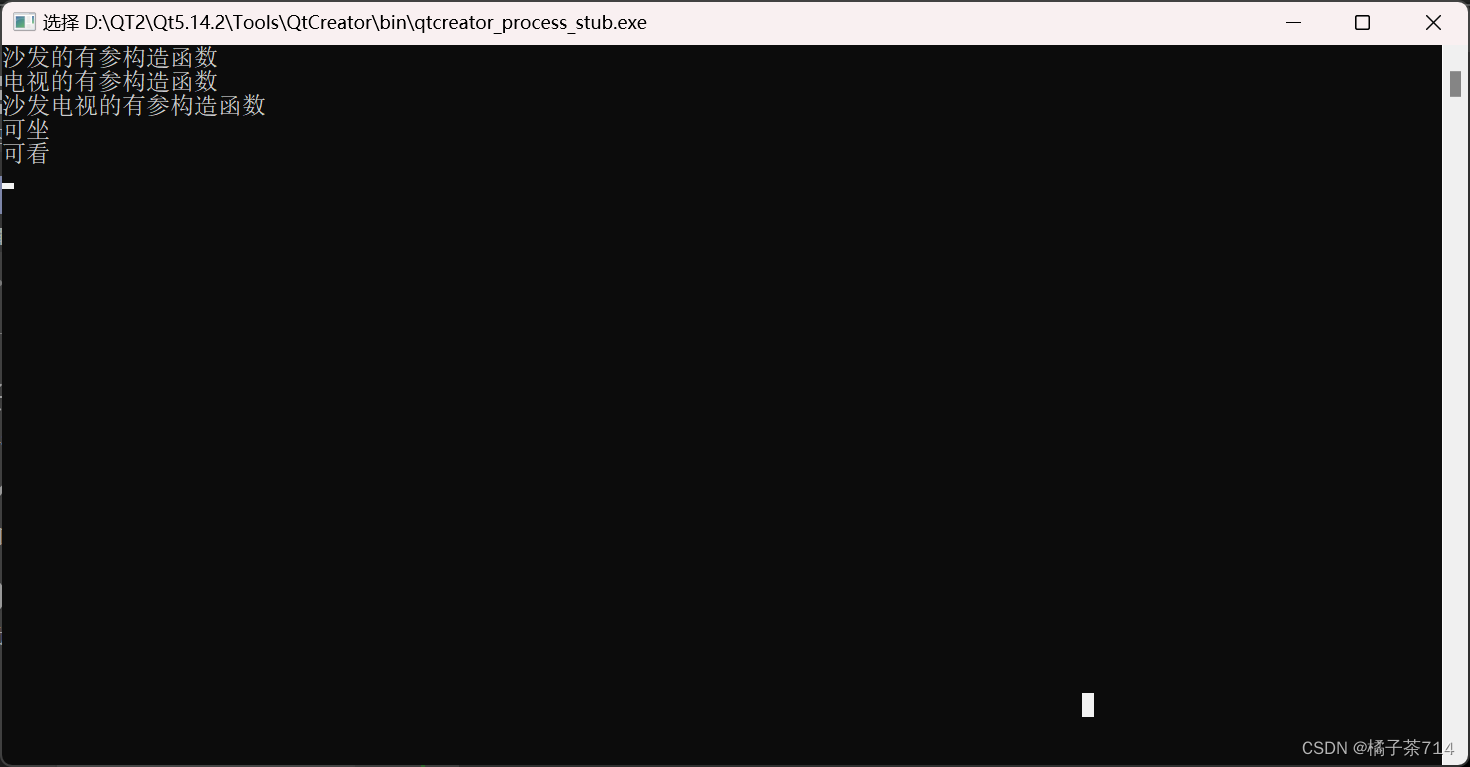
C++DAY43
#include <iostream>using namespace std;//封装 沙发 类 class Sofa { private:string living; public:Sofa(){cout << "沙发的无参构造函数" << endl;}Sofa(string l):living(l){cout << "沙发的有参构造函数" << endl;}v…...

大模型的超级“外脑”——向量数据库解决大模型的三大挑战
随着AI大模型产品及应用呈现爆发式增长,新的AI时代已经到来。向量数据库可与大语言模型配合使用,解决大模型落地过程中的痛点,已成为企业数据处理和应用大模型的必选项。在近日举行的华为全联接大会2023期间,华为云正式发布GaussDB向量数据库。GaussDB向量数据库基于GaussD…...

opencv读取摄像头并读取时间戳
下面这行代码是获取摄像头每帧的时间戳: double timestamp cap.get(cv::CAP_PROP_POS_MSEC); 改变帧率的方法是: cap.set(cv::CAP_PROP_FPS, 30); //帧率改为30 但是实际测试时发现帧率并未被改变,这个可能和VideoCapture cap(cv::CAP_V…...
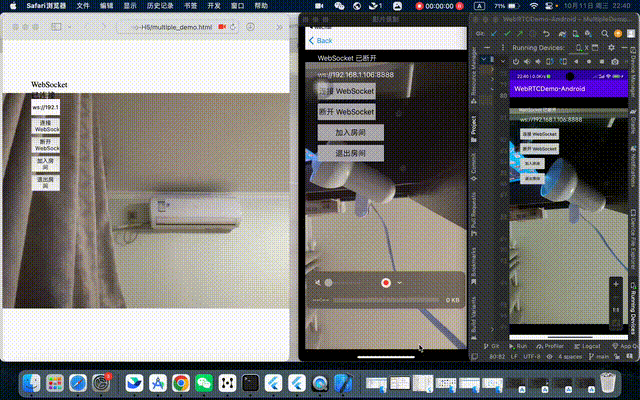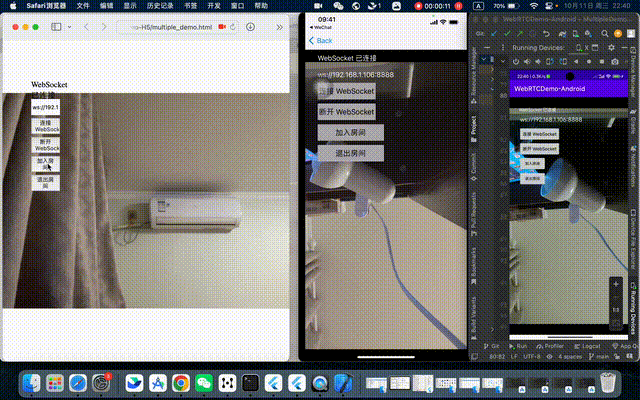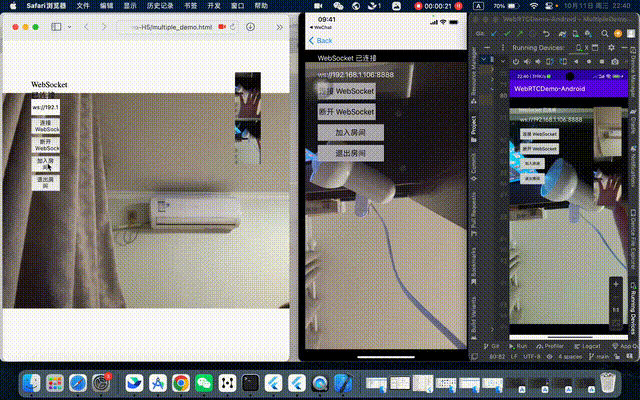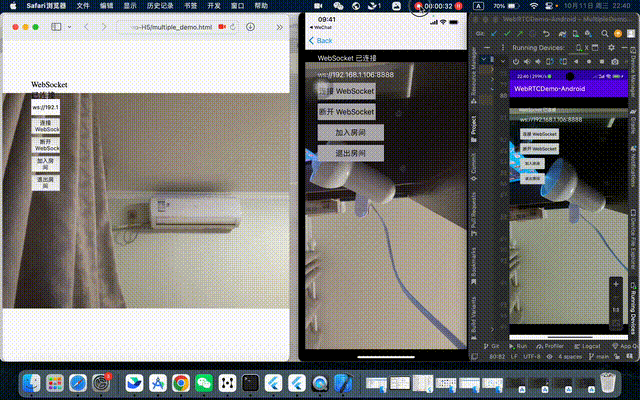
WebRTC 系列(四、多人通话,H5、Android、iOS)
WebRTC 系列(三、点对点通话,H5、Android、iOS) 上一篇博客中,我们已经实现了点对点通话,即一对一通话,这一次就接着实现多人通话。多人通话的实现方式呢也有好几种方案,这里我简单介绍两种方案…...
)
uniapp 点击 富文本元素 图片 可以预览(非nvue)
我使用的是uniapp 官方推荐的组件 rich-text,一般我能用官方级用官方,更有保障一些。 一、整体逻辑 1. 定义一段html标签字符串,里面包含图片 2. 将字符串放入rich-text组件中,绑定点击事件itemclick 3. 通过点击事件获取到图片ur…...
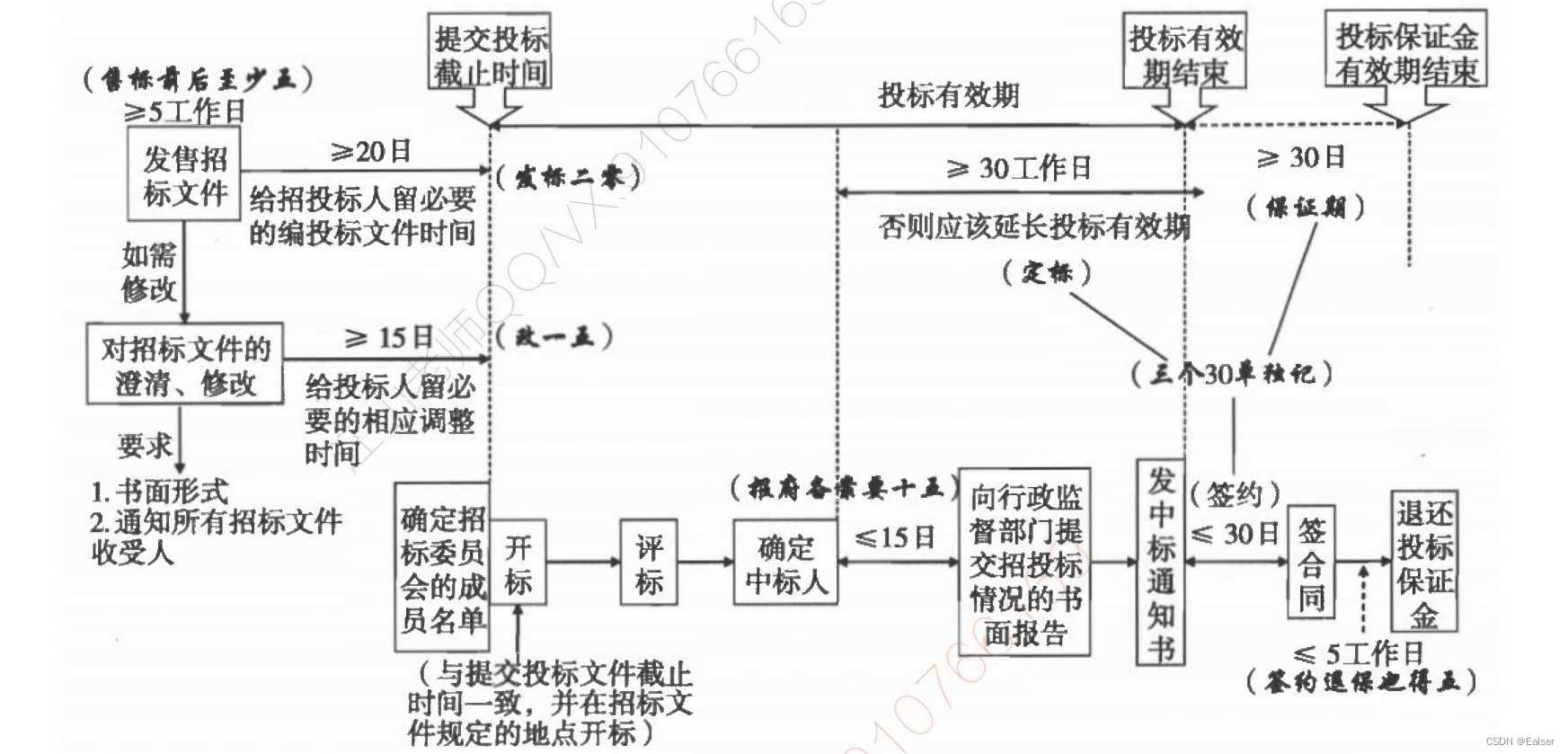
【2023年11月第四版教材】第24章《法律法规与标准规范》(合集篇)
第24章《法律法规与标准规范》(合集篇) 1 民法典(合同编)2 招标投标法2.1 关于时间的总结2.2 内容 3 政府采购法4 专利法5 著作权法6 商标法7 网络安全法8 数据安全法 1 民法典(合同编) 1、要约是希望和他人订立合同的…...

提升战斗力!吃鸡行家分享顶级游戏干货,助你轻松拿下绝地求生
作为吃鸡行家,我们都知道,在绝地求生中提高战斗力至关重要。今天我来分享一些独特的干货,帮助你成为顶级的吃鸡玩家,并分享一些方便吃鸡作图、装备皮肤库存展示和查询的技巧。 首先,让我们来谈谈绝地求生作图工具推荐。…...

C语言练习百题之宏#define命令
宏(Macro)是C语言中的一种预处理指令,它使用#define命令定义符号常量、宏函数和代码片段。下面列举了各种宏的应用场景以及相关注意事项: 定义常量: #define PI 3.14159265注意事项:使用宏定义常量可以提高…...

阿里云存储I/O性能、IOPS和吞吐量是什么意思?
云盘的存储I/O性能是什么?存储I/O性能又称存储读写性能,指不同阿里云服务器ECS实例规格挂载云盘时,可以达到的性能表现,包括IOPS和吞吐量。阿里云百科网aliyunbaike.com分享阿里云服务器云盘(系统盘或数据盘࿰…...

Linux知识点 -- 网络基础 -- 数据链路层
Linux知识点 – 网络基础 – 数据链路层 文章目录 Linux知识点 -- 网络基础 -- 数据链路层一、数据链路层1.以太网2.以太网帧格式3.重谈局域网原理4.MAC地址5.MTU6.查看硬件地址和MTU的命令7.ARP协议 二、其他重要协议或技术1.DNS(Domain Name System)2.…...
)
git服务器宕机后,怎么用本地仓库重新建立gitlab服务器(包括所有历史版本)
一、重新建立 当您的 GitLab 服务器因为某种原因宕机后,您可以使用本地仓库中的备份数据来恢复 GitLab 服务器。以下是一般的步骤,用于重新建立 GitLab 服务器: 注意: 这些步骤假定您已经定期备份了 GitLab 数据,包括…...

华为云云耀云服务器L实例评测 | 实例使用教学之综合导览
华为云云耀云服务器L实例评测 | 实例使用教学之综合导览 实例使用教学实例场景体验实例性能评测实例评测使用介绍华为云云耀云服务器 华为云云耀云服务器 (目前已经全新升级为 华为云云耀云服务器L实例) 华为云云耀云服务器是什么华为云云耀云…...

Elasticsearch 高级查询用法
ES(Elasticsearch)查询语法是用于搜索和检索文档的强大工具,它支持多种查询类型和选项。以下是一些常见的查询语法示例: 1. **Match查询**:使用match查询可以执行全文本搜索。 { "query": { …...
网络架构介绍
1 网络 7 层架构 7 层模型主要包括: 1. 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由 1、0 转化为电流强弱来进行传输,到达目的地后在转化为1、0…...

第53节——Redux Toolkit初识
一、什么是Redux Toolkit 1、概念 Redux Toolkit是一个官方支持的、用于简化Redux开发的工具集。它提供了一些简单易用的API和工具,可以帮助开发者更快速、更高效地编写Redux应用。 2、主要功能 简化Redux的配置 Redux Toolkit提供了一个createSlice函数&#…...

AndroidStudio报错:Plugin with id ‘kotlin-android‘ not found.
第一步 要在自己的项目的build.gradle的buildscript中添加ext.kotlin_version 1.3.72 第二步 然后在dependencies里添加classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version" 大体如下: buildscript {ext.kotlin_version 1.3.72r…...

【ADB】借助ADB模拟滑动屏幕,并进行循环
使用adb shell input 的swipe函数(应该是个函数) swipe x1 y1 x2 y2 time(以毫秒为单位) adb shell input swipe 1070 2200 1070 200 10000 进行循环 adb shell "for i in $(seq 1 10); do input swipe 1070 2200 1070 2…...
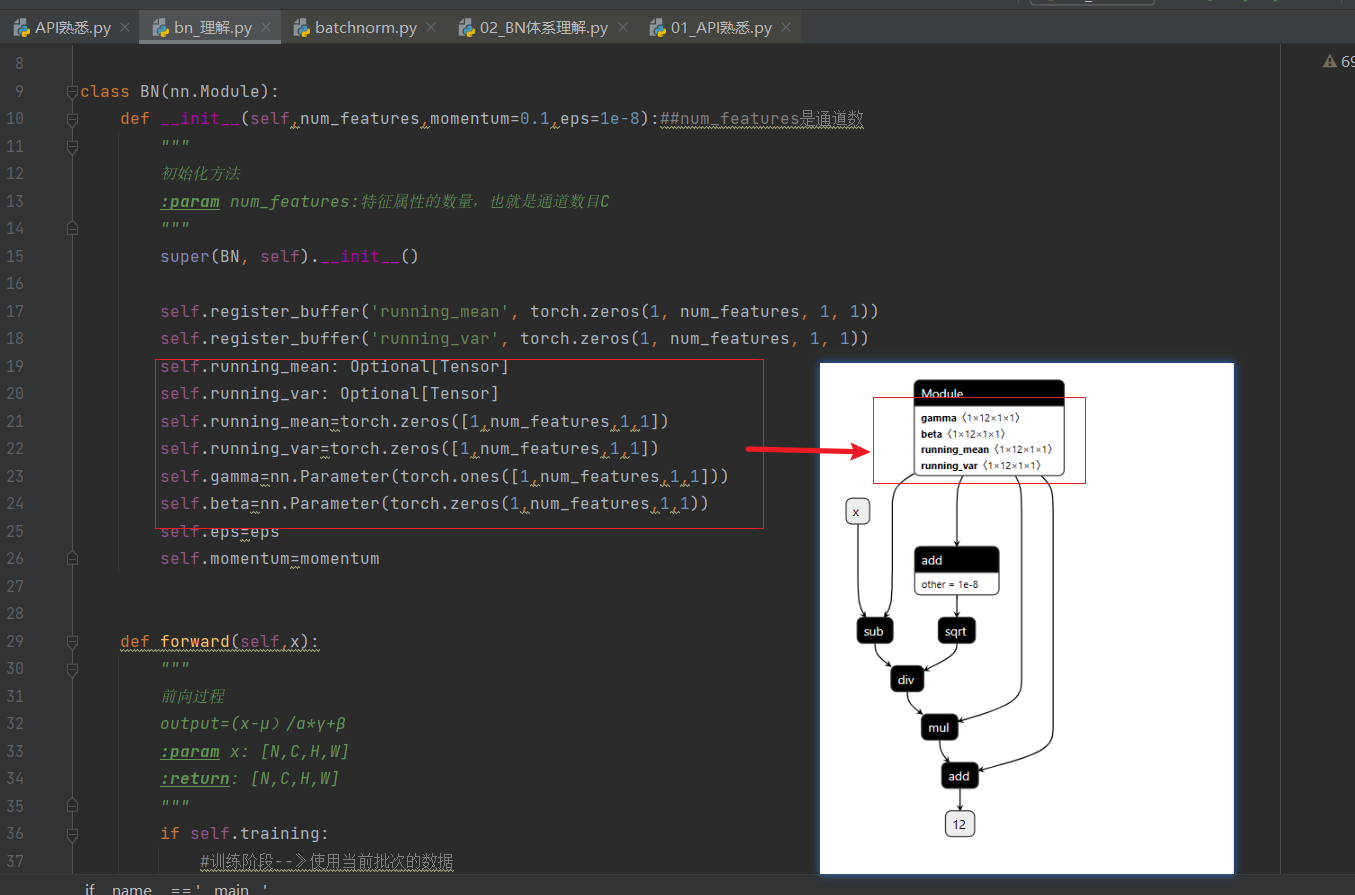
BN体系理解——类封装复现
from pathlib import Path from typing import Optionalimport torch import torch.nn as nn from torch import Tensorclass BN(nn.Module):def __init__(self,num_features,momentum0.1,eps1e-8):##num_features是通道数"""初始化方法:param num_features:特征…...

请求和响应的概述
请求:在浏览器地址栏输入地址,点击回车请求服务器,这个过程就是一个请求过程。 响应:服务器根据浏览器发送的请求,返回数据到浏览器在网页上进行显示,这个过程就称之为响应。 针对Servlet的每次请求&…...

双模型混搭方案:OpenClaw同时接入千问3.5-27B与Llama3
双模型混搭方案:OpenClaw同时接入千问3.5-27B与Llama3 1. 为什么需要多模型混搭 去年我在尝试用AI自动化处理技术文档时,发现单一模型总是存在能力短板。比如用纯文本模型生成示意图说明时,要么需要手动补充描述,要么得额外调用…...

OpenClaw学术研究助手:Qwen3-14b_int4_awq自动生成文献综述
OpenClaw学术研究助手:Qwen3-14b_int4_awq自动生成文献综述 1. 为什么需要AI辅助文献调研 作为一名计算机视觉方向的研究生,我每周需要阅读数十篇论文来跟踪领域进展。传统文献调研方式存在几个痛点:首先,手动下载和整理PDF文件…...

终极指南:At.js如何让你的应用拥有GitHub级别的智能补全功能
终极指南:At.js如何让你的应用拥有GitHub级别的智能补全功能 【免费下载链接】At.js Add Github like mentions autocomplete to your application. 项目地址: https://gitcode.com/gh_mirrors/at/At.js At.js是一款强大的智能补全库,能够为你的W…...

OpenClaw安全实践:Qwen3.5-9B本地化部署防数据泄露方案
OpenClaw安全实践:Qwen3.5-9B本地化部署防数据泄露方案 1. 为什么需要关注OpenClaw的安全问题? 去年冬天,我在整理公司财报时突然意识到一个问题:如果让AI助手帮我处理这些敏感文件,数据会不会被意外上传到云端&…...

FLAME PyTorch高效构建参数化3D人脸模型实战指南
FLAME PyTorch高效构建参数化3D人脸模型实战指南 【免费下载链接】FLAME_PyTorch 项目地址: https://gitcode.com/gh_mirrors/fl/FLAME_PyTorch 在数字内容创作、虚拟现实和影视制作等领域,3D建模技术正发挥着越来越重要的作用。其中,参数化人脸…...

AI编程实战:从零到一搭建全栈项目
1. 引入 在现代 AI 工程中,Hugging Face 的 tokenizers 库已成为分词器的事实标准。不过 Hugging Face 的 tokenizers 是用 Rust 来实现的,官方只提供了 python 和 node 的绑定实现。要实现与 Hugging Face tokenizers 相同的行为,最好的办法…...

隐私优先方案:OpenClaw+本地化Qwen3.5-9B处理敏感数据
隐私优先方案:OpenClaw本地化Qwen3.5-9B处理敏感数据 1. 为什么我们需要隐私优先的AI方案 去年我在帮一家诊所做数字化改造时,遇到了一个棘手问题:他们需要自动化处理患者病历,但又担心使用云端AI服务会导致数据泄露。这让我意识…...

【数据结构与算法】第24篇:哈夫曼树与哈夫曼编码
一、基本概念1.1 带权路径长度在二叉树中:路径长度:从一个节点到另一个节点经过的边数带权路径长度(WPL):所有叶子节点的权重 路径长度 之和示例:text叶子节点:A(7), B(5), C(2), D(4)普通树:15/ \7 8/…...
)
基于单片机的温控风扇(有完整资料)
资料查找方式:特纳斯电子(电子校园网):搜索下面编号即可编号:T4272204C设计简介:本设计是基于单片机的语音控制温控风扇,主要实现以下功能:1、可通过LCD1602显示温度和档位ÿ…...

OpenClaw高Token消耗解决方案:Qwen3-4B-Thinking本地化部署指南
OpenClaw高Token消耗解决方案:Qwen3-4B-Thinking本地化部署指南 1. 当OpenClaw遇上Token消耗困境 上周我尝试用OpenClaw自动整理半年的技术笔记时,遇到了一个棘手问题——任务执行到一半突然中断了。查看日志才发现,仅仅是"读取文件→…...