Flink---11、状态管理(按键分区状态(值状态、列表状态、Map状态、归约状态、聚合状态)算子状态(列表状态、广播状态))

星光下的赶路人star的个人主页
这世上唯一扛得住岁月摧残的就是才华
文章目录
- 1、状态管理
- 1.1 Flink中的状态
- 1.1.1 概述
- 1.1.2 状态的分类
- 1.2 按键分区状态(Keyed State)
- 1.2.1 值状态(ValueState)
- 1.2.2 列表状态(ListState)
- 1.2.3 Map状态(MapState)
- 1.2.4 归约状态(ReducingState)
- 1.2.5 聚合状态(AggregatingState)
- 1.2.6 状态生存时间(TTL)
- 1.3 算子状态(Operator State)
- 1.3.1 列表状态(ListState)
- 1.3.2 联合列表状态
- 1.3.3 广播状态(BroadCastState)
1、状态管理
1.1 Flink中的状态
1.1.1 概述

1.1.2 状态的分类
1、托管状态(Managed State)和原始状态(Raw State)
Flink的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
通常我们采用Flink托管状态来实现需求。
2、算子状态(Operator)和按键分区状态(Keyed State)
接下来我们的重点就是托管状态(Managed State)。
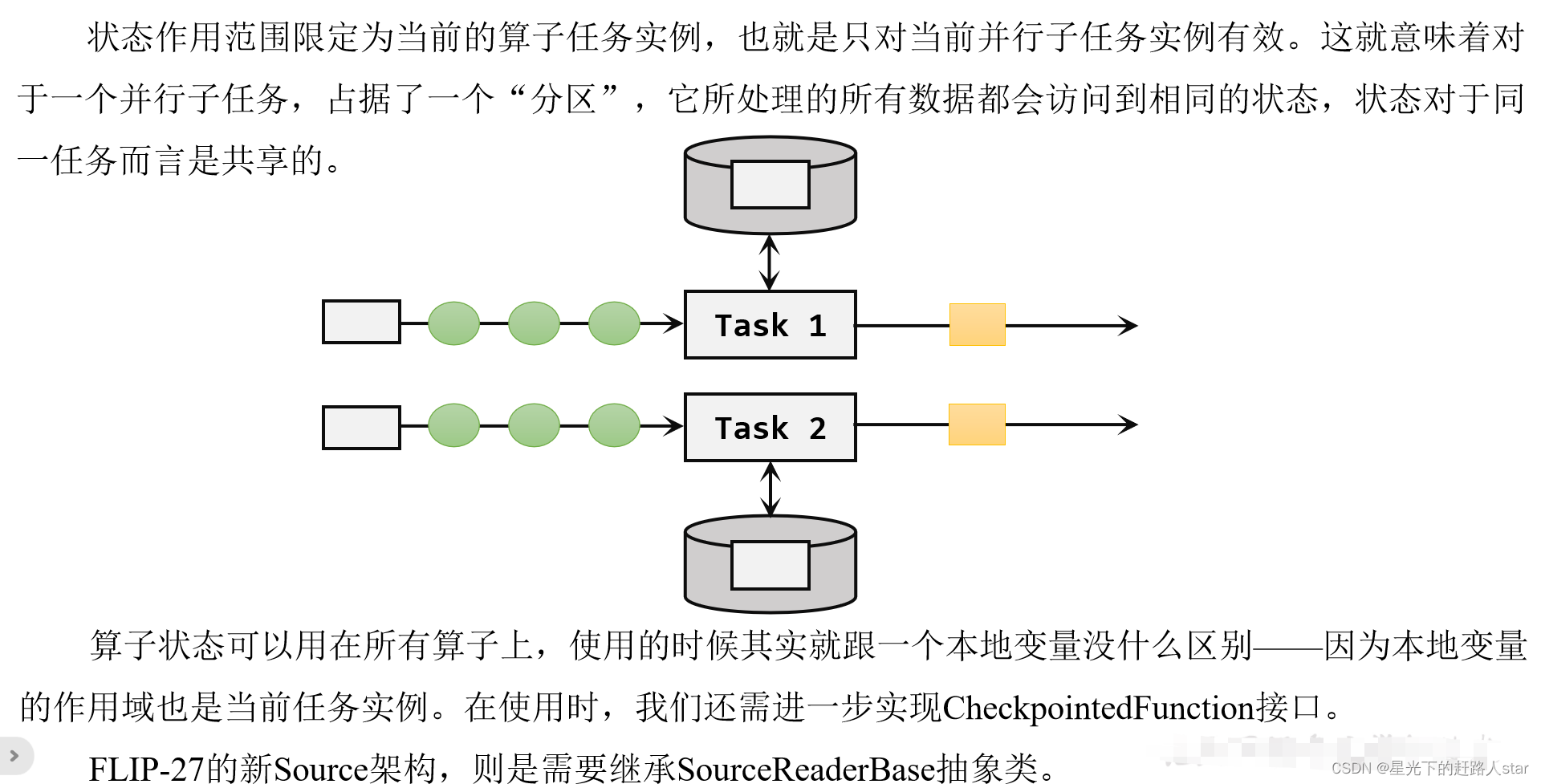
我们知道在Flink中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
而很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。在这种情况下,状态的访问方式又会有所不同。
基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
按键分区状态

另外,也可以通过富函数类(Rich Function)来自定义Keyed State,所以只要提供了富函数类接口的算子,也都可以使用Keyed State。所以即使是map、filter这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加”Keyed State。比如RichMapFunction、RichFilterFunction。在富函数中,我们可以调用.getRuntimeContext()获取当前的运行时上下文(RuntimeContext),进而获取到访问状态的句柄;这种富函数中自定义的状态也是Keyed State。从这个角度讲,Flink中所有的算子都可以是有状态的。
无论是Keyed State还是Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。
1.2 按键分区状态(Keyed State)
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以key为作用范围进行隔离。
需要注意,使用Keyed State必须基于KeyedStream。没有进行keyBy分区的DataStream,即使转换算子实现了对应的富函数类,也不能通过运行时上下文访问Keyed Stat
1.2.1 值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。ValueState本身是一个接口,源码中定义如下:
public interface ValueState<T> extends State {T value() throws IOException;void update(T value) throws IOException;
}
这里的T是泛型,表示状态的数据内容可以是任何具体的数据类型。如果想要保存一个长整型值作为状态,那么类型就是ValueState。
我们可以在代码中读写值状态,实现对于状态的访问和更新。
- T value():获取当前状态的值;
- update(T value):对状态进行更新,传入的参数value就是要覆写的状态值。
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {super(name, typeClass, null);
}
这里需要传入状态的名称和类型——这跟我们声明一个变量时做的事情完全一样。
案例
*** keyedState在使用时,只需要先keyBy* 在后续的处理函数中,自带生命周期方法* open():需要再Task启动时,从之前的备份中根据描述取出状态** 特点:每一个Task上,各种key各有各的State,互不干扰* ------------------------------------------------* ValueState储存单个值,可以是任意类型* -------------------------------------------------* 检测每种传感器的水位值,如果连续的两个水位值超过10就输出报警*/
public class Demo01_ValueState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private ValueState<Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//设置状态存储的描述器ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("state", Integer.class);//获取状态的存储state = getRuntimeContext().getState(stateDescriptor);}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {//如果状态中从来没有存储过数据,此时lastVc是nullInteger lastVc = state.value();//连续两个水位值超过10,就输出报警if (lastVc!=null&&lastVc>10&&value.getVc()>10){out.collect(ctx.getCurrentKey()+"连续两个传感器的vc("+lastVc+","+value.getVc()+")超过10.....");}state.update(value.getVc());}}).print();env.execute();}
}测试截图:

1.2.2 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在ListState接口中同样有一个类型参数T,表示列表中数据的类型。ListState也提供了一系列的方法来操作状态,使用方式与一般的List非常相似。
- Iterable get():获取当前的列表状态,返回的是一个可迭代类型Iterable;
- update(List values):传入一个列表values,直接对状态进行覆盖;
- add(T value):在状态列表中添加一个元素value;
- addAll(List values):向列表中添加多个元素,以列表values形式传入。
类似地,ListState的状态描述器就叫作ListStateDescriptor,用法跟ValueStateDescriptor完全一致。
/*** keyedState在使用时,只需要先keyBy* 在后续的处理函数中,自带生命周期方法* open():需要再Task启动时,从之前的备份中根据描述取出状态** 特点:每一个Task上,各种key各有各的State,互不干扰* ------------------------------------------------* ListState储存多个类型相同的值,可以是任意类型* -------------------------------------------------* 取水位最高的前三*/
public class Demo02_ListState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private ListState<Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//设置状态存储的描述器ListStateDescriptor<Integer> listStateDescriptor = new ListStateDescriptor<>("state", Integer.class);//获取状态的存储state = getRuntimeContext().getListState(listStateDescriptor);}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {state.add(value.getVc());List<Integer> top3 = StreamSupport.stream(state.get().spliterator(), true).sorted(Comparator.reverseOrder()).limit(3).collect(Collectors.toList());out.collect(ctx.getCurrentKey()+"最新Top水位:"+top3);state.update(top3);}}).print();env.execute();}public static class MyMapFunction implements MapFunction<String ,String>, CheckpointedFunction{//private List<String> strs = new ArrayList<>();/*把它当List集合用。添加元素:ListState.add()ListState.addAll()删除: ListState.clear()修改: ListState.update() 覆盖修改等价于 先清空,再写入读取: ListState.get()*/private ListState<String> strs;private ListState<String> strs1;private ListState<String> strs2;@Overridepublic String map(String value) throws Exception {strs.add(value);return strs.get().toString();}//备份状态 周期性(ck设置的周期)执行。@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {System.out.println("MyMapFunction.snapshotState");}//Task重启后,做初始化。为声明的状态去赋值和恢复。 在Task启动时,只执行一次@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("MyMapFunction.initializeState");//找到之前OperatorState的备份OperatorStateStore operatorStateStore = context.getOperatorStateStore();//准备要取出的状态的描述ListStateDescriptor<String> strsListStateDescriptor = new ListStateDescriptor<>("list1", String.class);//从备份中找到指定的状态,取出strs = operatorStateStore.getListState(strsListStateDescriptor);}}
}测试截图:
1.2.3 Map状态(MapState)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组key-value映射的列表。对应的MapState<UK, UV>接口中,就会有UK、UV两个泛型,分别表示保存的key和value的类型。同样,MapState提供了操作映射状态的方法,与Map的使用非常类似。
- UV get(UK key):传入一个key作为参数,查询对应的value值;
- put(UK key, UV value):传入一个键值对,更新key对应的value值;
- putAll(Map<UK, UV> map):将传入的映射map中所有的键值对,全部添加到映射状态中;
- remove(UK key):将指定key对应的键值对删除;
- boolean contains(UK key):判断是否存在指定的key,返回一个boolean值。另外,MapState也提供了获取整个映射相关信息的方法;
- Iterable<Map.Entry<UK, UV>> entries():获取映射状态中所有的键值对;
- Iterable keys():获取映射状态中所有的键(key),返回一个可迭代Iterable类型;
- Iterable values():获取映射状态中所有的值(value),返回一个可迭代Iterable类型;
- boolean isEmpty():判断映射是否为空,返回一个boolean值。
案例
/*** keyedState在使用时,只需要先keyBy* 在后续的处理函数中,自带生命周期方法* open():需要再Task启动时,从之前的备份中根据描述取出状态** 特点:每一个Task上,各种key各有各的State,互不干扰* ------------------------------------------------* mapState储存多个值,可以是任意类型* -------------------------------------------------* 统计每种传感器每种水位值出现的次数*/
public class Demo03_MapState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private MapState<Integer,Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//设置状态存储的描述器MapStateDescriptor<Integer, Integer> mapStateDescriptor = new MapStateDescriptor<>("state", Integer.class, Integer.class);//获取状态的存储state = getRuntimeContext().getMapState(mapStateDescriptor);}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {if (state.get(value.getVc())!=null){Integer nums = state.get(value.getVc());state.put(value.getVc(),nums+1);}else {state.put(value.getVc(),1);}out.collect(ctx.getCurrentKey()+":"+state.entries().toString());}}).print();env.execute();}
}测试截图:

1.2.4 归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。ReducingState这个接口调用的方法类似于ListState,只不过它保存的只是一个聚合值,所以调用.add()方法时,不是在状态列表里添加元素,而是直接把新数据和之前的状态进行归约,并用得到的结果更新状态。
归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。这里的归约函数,就是我们之前介绍reduce聚合算子时讲到的ReduceFunction,所以状态类型跟输入的数据类型是一样的。
public ReducingStateDescriptor(String name, ReduceFunction<T> reduceFunction, Class<T> typeClass) {...}
这里的描述器有三个参数,其中第二个参数就是定义了归约聚合逻辑的ReduceFunction,另外两个参数则是状态的名称和类型。
/*** 带有聚合功能的状态,需要吧数据存入状态,可以自动根据逻辑聚合* 获取状态的值,就是聚合后的结果*** 计算每个传感器的水位和**/
public class Demo04_ReduceState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private ReducingState<Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//设置状态存储的描述器ReducingStateDescriptor stateDescriptor = new ReducingStateDescriptor<>("state",new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2) throws Exception {return value1+value2;}},Integer.class);//获取状态的存储state = getRuntimeContext().getReducingState(stateDescriptor);}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {state.add(value.getVc());out.collect(ctx.getCurrentKey()+":"+state.get());}}).print();env.execute();}
}测试截图:
1.2.5 聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与ReducingState不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;这也就是之前我们讲过的AggregateFunction,里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
同样地,AggregatingState接口调用方法也与ReducingState相同,调用.add()方法添加元素时,会直接使用指定的AggregateFunction进行聚合并更新状态。
/*** 带有聚合功能的状态,需要吧数据存入状态,可以自动根据逻辑聚合* 获取状态的值,就是聚合后的结果*** 计算每个传感器的水位平均值**/
public class Demo06_AggregatingState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private AggregatingState<Integer, Double> state;@Overridepublic void open(Configuration parameters) throws Exception {//设置状态存储的描述器//获取状态的存储state = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<>("state",new AggregateFunction<Integer, Tuple2<Integer, Double>, Double>(){@Overridepublic Tuple2<Integer, Double> createAccumulator() {return Tuple2.of(0, 0d);}@Overridepublic Tuple2<Integer, Double> add(Integer value, Tuple2<Integer, Double> accumulator) {accumulator.f0 += 1;accumulator.f1 += value;return accumulator;}@Overridepublic Double getResult(Tuple2<Integer, Double> accumulator) {return accumulator.f1 / accumulator.f0;}//不用写@Overridepublic Tuple2<Integer, Double> merge(Tuple2<Integer, Double> a, Tuple2<Integer, Double> b) {return null;}},Types.TUPLE(Types.INT, Types.DOUBLE)));}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {state.add(value.getVc());//取出结果out.collect(ctx.getCurrentKey() +" avgVc:" +state.get());}}).print();env.execute();}
}测试截图:

1.2.6 状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”(time-to-live,TTL),当状态在内存中存在的时间超出这个值时,就将它清除。
具体实现上,如果用一个进程不停地扫描所有状态看是否过期,显然会占用大量资源做无用功。状态的失效其实不需要立即删除,所以我们可以给状态附加一个属性,也就是状态的“失效时间”。状态创建的时候,设置 失效时间 = 当前时间 + TTL;之后如果有对状态的访问和修改,我们可以再对失效时间进行更新;当设置的清除条件被触发时(比如,状态被访问的时候,或者每隔一段时间扫描一次失效状态),就可以判断状态是否失效、从而进行清除了。
配置状态的TTL时,需要创建一个StateTtlConfig配置对象,然后调用状态描述器的.enableTimeToLive()方法启动TTL功能。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(10)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("my state", String.class);stateDescriptor.enableTimeToLive(ttlConfig);
这里用到了几个配置项:
- .newBuilder()
状态TTL配置的构造器方法,必须调用,返回一个Builder之后再调用.build()方法就可以得到StateTtlConfig了。方法需要传入一个Time作为参数,这就是设定的状态生存时间。 - .setUpdateType()
设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的OnCreateAndWrite表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型OnReadAndWrite则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为OnCreateAndWrite。 - .setStateVisibility()
设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能继续存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的NeverReturnExpired是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
除此之外,TTL配置还可以设置在保存检查点(checkpoint)时触发清除操作,或者配置增量的清理(incremental cleanup),还可以针对RocksDB状态后端使用压缩过滤器(compaction filter)进行后台清理。这里需要注意,目前的TTL设置只支持处理时间。
/*** 程序是7*24小时一直运行* 状态是储存在内存中。如果不动手清理(Clear()),状态会越存越多。* 内存是有限的,当状态过多时,需要把一些可以清理的状态,清理掉。* 实现方式:* 自己调用clear()* 自动清理(设置一个过期时间)* ----------------------------------------------* 过期时间: ttl time to live** 1、设置一个过期对象* 2、讲对象传入在open方法中的状态描述的方法中**/
public class Demo09_Ttl{public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);//并行度env.setParallelism(1);//构造状态的过期时间对象StateTtlConfig ttlConfig = StateTtlConfig//传入状态的存活时间.newBuilder(Time.seconds(15))//状态过期了就不返回了.neverReturnExpired()/*** 清理过期状态的原理:* 如果设置了ttl,此时每个状态在存储的时候,会多储存一个lastAccessTime字段** 设置状态中存活时间的更新策略。用来更新lastAccessTime* OnCreateAndWrite:lastAccessTime会在状态被写的时候更新* OnReadAndWrite:lastAccessTime会在状态被读或写的时候更新* 如何判断过期* 没有事件时间的概念,只和物理时钟有关** 当前读写时间-lastAccessTime>ttl,此时标记这个状态已经过期* 之后会在后台启动一个清理的线程,定期把标记为过期的状态删除*/.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite).build();env.socketTextStream("hadoop102",9999).map(new WaterSensorFunction()).keyBy(WaterSensor::getId).process(new KeyedProcessFunction<String, WaterSensor, String>() {private ListState<Integer> listState;@Overridepublic void open(Configuration parameters) throws Exception {ListStateDescriptor<Integer> listStateDescriptor = new ListStateDescriptor<>("state", Integer.class);//应用存货策略listStateDescriptor.enableTimeToLive(ttlConfig);listState = getRuntimeContext().getListState(listStateDescriptor);}@Overridepublic void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {listState.add(value.getVc());Iterable<Integer> integers = listState.get();List<Integer> top3 = StreamSupport.stream(integers.spliterator(), true).sorted(Comparator.reverseOrder()).limit(3).collect(Collectors.toList());out.collect(ctx.getCurrentKey()+"最新Top3:"+top3);listState.update(top3);}}).print();env.execute();}
}测试截图:

注意:最后一条记录要在上一条记录发送之后15秒之后再发
1.3 算子状态(Operator State)
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的key无关,所以不同key的数据只要被分发到同一个并行子任务,就会访问到同一个Operator State。
算子状态的实际应用场景不如Keyed State多,一般用在Source或Sink等与外部系统连接的算子上,或者完全没有key定义的场景。比如Flink的Kafka连接器中,就用到了算子状态。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState和BroadcastState。
1.3.1 列表状态(ListState)
与Keyed State中的ListState一样,将状态表示为一组数据的列表。
与Keyed State中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的rebanlance数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-split redistribution)。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
案例实操:在map算子中计算数据的个数。
public class OperatorListStateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);env.socketTextStream("hadoop102", 7777).map(new MyCountMapFunction()).print();env.execute();}// TODO 1.实现 CheckpointedFunction 接口public static class MyCountMapFunction implements MapFunction<String, Long>, CheckpointedFunction {private Long count = 0L;private ListState<Long> state;@Overridepublic Long map(String value) throws Exception {return ++count;}/*** TODO 2.本地变量持久化:将 本地变量 拷贝到 算子状态中,开启checkpoint时才会调用** @param context* @throws Exception*/@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {System.out.println("snapshotState...");// 2.1 清空算子状态state.clear();// 2.2 将 本地变量 添加到 算子状态 中state.add(count);}/*** TODO 3.初始化本地变量:程序启动和恢复时, 从状态中 把数据添加到 本地变量,每个子任务调用一次** @param context* @throws Exception*/@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {System.out.println("initializeState...");// 3.1 从 上下文 初始化 算子状态state = context.getOperatorStateStore().getListState(new ListStateDescriptor<Long>("state", Types.LONG));// 3.2 从 算子状态中 把数据 拷贝到 本地变量if (context.isRestored()) {for (Long c : state.get()) {count += c;}}}}
}
1.3.2 联合列表状态
与ListState类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
使用方式同ListState,区别在如下部分:
state = context.getOperatorStateStore().getUnionListState(new ListStateDescriptor<Long>("union-state", Types.LONG));
1.3.3 广播状态(BroadCastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
/*** 场景单一:* 用于一个配置流在更新配置时,可以将更新的信息放入广播状态* 数据流,可以提供广播状态及时获取更新的配置信息*/
public class Demo04_BroadCastState {public static void main(String[] args) throws Exception {//创建Flink配置类(空参创建的话都是默认值)Configuration configuration = new Configuration();//修改配置类中的WebUI端口号configuration.setInteger("rest.port",3333);//创建Flink环境(并且传入配置对象)StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);env.setParallelism(2);env.enableCheckpointing(2000);//数据流SingleOutputStreamOperator<WaterSensor> dataDS = env.socketTextStream("hadoop102", 9999).map(new WaterSensorFunction());//配置流SingleOutputStreamOperator<MyConf> configDS = env.socketTextStream("hadoop102", 9998).map(new MapFunction<String, MyConf>() {@Overridepublic MyConf map(String value) throws Exception {String[] split = value.split(",");return new MyConf(split[0], split[1]);}});//只有把普通流制作为广播流,才能用广播状态MapStateDescriptor<String, MyConf> mapStateDescriptor = new MapStateDescriptor<>("config", String.class, MyConf.class);BroadcastStream<MyConf> confBroadcastStream = configDS.broadcast(mapStateDescriptor);//数据流希望读取配置流中的信息,必须让两个流连接dataDS.connect(confBroadcastStream).process(new BroadcastProcessFunction<WaterSensor, MyConf, WaterSensor>() {//处理数据流的数据@Overridepublic void processElement(WaterSensor value, BroadcastProcessFunction<WaterSensor, MyConf, WaterSensor>.ReadOnlyContext ctx, Collector<WaterSensor> out) throws Exception {//获取广播状态ReadOnlyBroadcastState<String, MyConf> broadcastState = ctx.getBroadcastState(mapStateDescriptor);MyConf myConf = broadcastState.get(value.getId());//用收到的配置信息,更新数据中的属性value.setId(myConf.getName());out.collect(value);}//处理配置流的数据@Overridepublic void processBroadcastElement(MyConf value, BroadcastProcessFunction<WaterSensor, MyConf, WaterSensor>.Context ctx, Collector<WaterSensor> out) throws Exception {//一旦收到了新的配置,就存入广播状态//当作map用BroadcastState<String, MyConf> broadcastState = ctx.getBroadcastState(mapStateDescriptor);broadcastState.put(value.id,value);}}).print();env.execute();}@Data@AllArgsConstructor@NoArgsConstructorpublic static class MyConf{private String id;private String name;}
}测试截图:

![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美
相关文章:

Flink---11、状态管理(按键分区状态(值状态、列表状态、Map状态、归约状态、聚合状态)算子状态(列表状态、广播状态))
星光下的赶路人star的个人主页 这世上唯一扛得住岁月摧残的就是才华 文章目录 1、状态管理1.1 Flink中的状态1.1.1 概述1.1.2 状态的分类 1.2 按键分区状态(Keyed State)1.2.1 值状态(ValueState)1.2.2 列表状态(ListS…...
Vue3中使用tinymce全功能演示,包括开源功能
效果图: 1、下载插件: npm i tinymce npm i tinymce/tinymce-vue 2、在node_modules文件夹中找到tinymce下的skins复制到项目public文件夹中 (可以先创建一个tinymce文件夹): 3、在tinymce官网中下载中文包,并放在刚…...
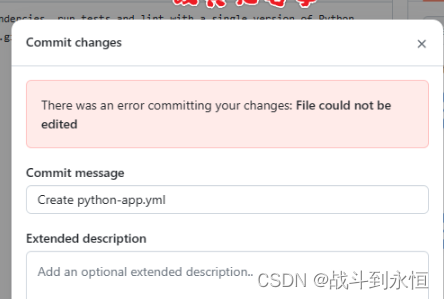
There was an error committing your changes: File could not be edited
使用github完成commit changes时报的一个错误,最终原因是没有填写Extended description...

10月9日,每日信息差
今天是2023年10月9日,以下是为您准备的14条信息差 第一、首只与规模挂钩型浮动费率基金即将面市。作为公募基金费率改革大背景下的首批浮动费率产品,华夏信兴回报混合是市场上首只管理费与管理规模挂钩的基金 第二、江北新区成立百亿产业发展母基金&am…...

【软考设计师】S01 数据结构 E01 线性结构 P01 线性表
线性表 前言——线性结构线性表线性表的定义线性表的特点线性表的存储结构顺序存储链式存储单链表双向链表循环链表静态链表 前言——线性结构 线性结构是一种基本的数据结构,主要用于对客观世界中具有单一前驱和后继的数据关系进行描述。线性结构的特点是数据元素…...

nginx配置https 访问
nginx 解压目录有configure文件 [rootoracledb10 ~]# which nginx1、检查nginx是否包含http_ssl_module 模块 如果出现 --with-http_ssl_module 就是已经安装了[rootoracledb10 sbin]# pwd /usr/local/nginx/sbin [rootoracledb10 sbin]# nginx -V nginx version: nginx/1.23…...

希亦CG声波清洗机:眼镜党福利,家庭必备清洗机
对于眼镜党来说最大的烦恼就是每天的佩戴和清洗,清洗是至关重要的,错误的清洗很容易引起镜片损坏,个人一直使用眼镜布清洗,除了费时费力之外清洁度也无法保证。希亦CG声波清洗机正是为了解决这一难题应运而生,可以彻底…...

2023年10月12日历史上的今天大事件早读
公元前539年10月12日波斯国王大流士的军队攻克巴比伦 1492年10月12日西班牙独立日 1492年10月12日哥伦布“发现新大陆” 1773年10月12日法国天文学家梅西叶首次发现具有螺旋结构的星系 1885年10月12日清政府改台湾府为行省 命刘铭传为台湾巡抚 1929年10月12日苏军向张学良…...
uCOSIII实时操作系统 五 任务API(时间片轮转API调度)
时间片轮转调度 时间片轮转法:主要用于分时系统中的进程调度。为了实现轮转调度,系统把所有就绪进程按照先入先出的原则排成一个队列的队首进程,让CPU上运行一个时间片的时间。时间片是一个小小的时间单位,通常为5~10ms数量级。当进程用完分…...

微信小程序项目如何用Hbuild启动,先让对方在微信开发平台将你的微信号添加成开发成员。
微信小程序项目如何用Hbuild启动,先让对方在微信开发平台将你的微信号添加成开发成员。然后在Hbuild官网下载,下载好后运行,点击文件导入项目,然后点击运行,模拟微信小程序,选择微信开发工具的地址…...
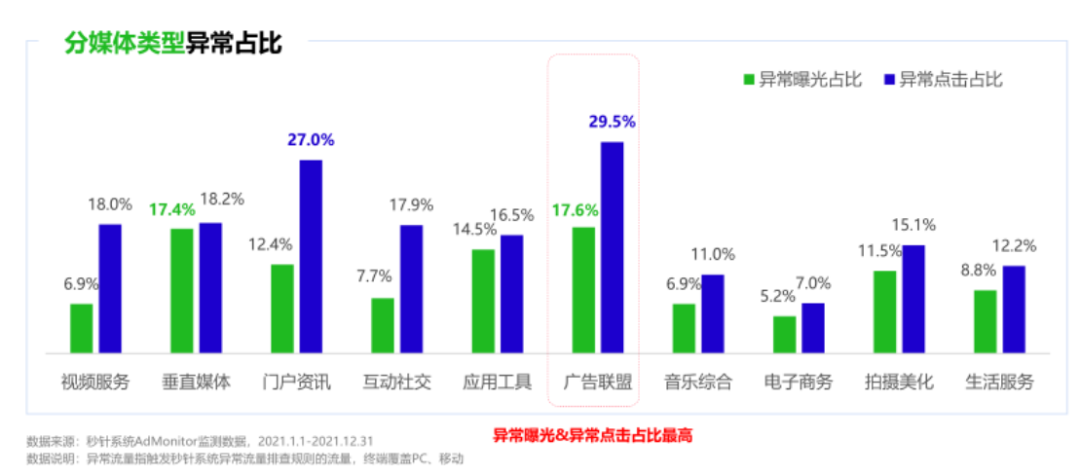
应对广告虚假流量,app广告变现该如何风控?
移动广告市场中的虚假流量一直是困扰各移动应用厂商的难题,广告作为app商业化变现最为直接快捷的途径,也引申出了流量作弊与反作弊的纷争。 根据《2021中国异常流量报告》,2021年中国品牌广告市场因异常流量造成的损失约为326亿人民币&#…...

【算法-动态规划】贝尔曼福特算法
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
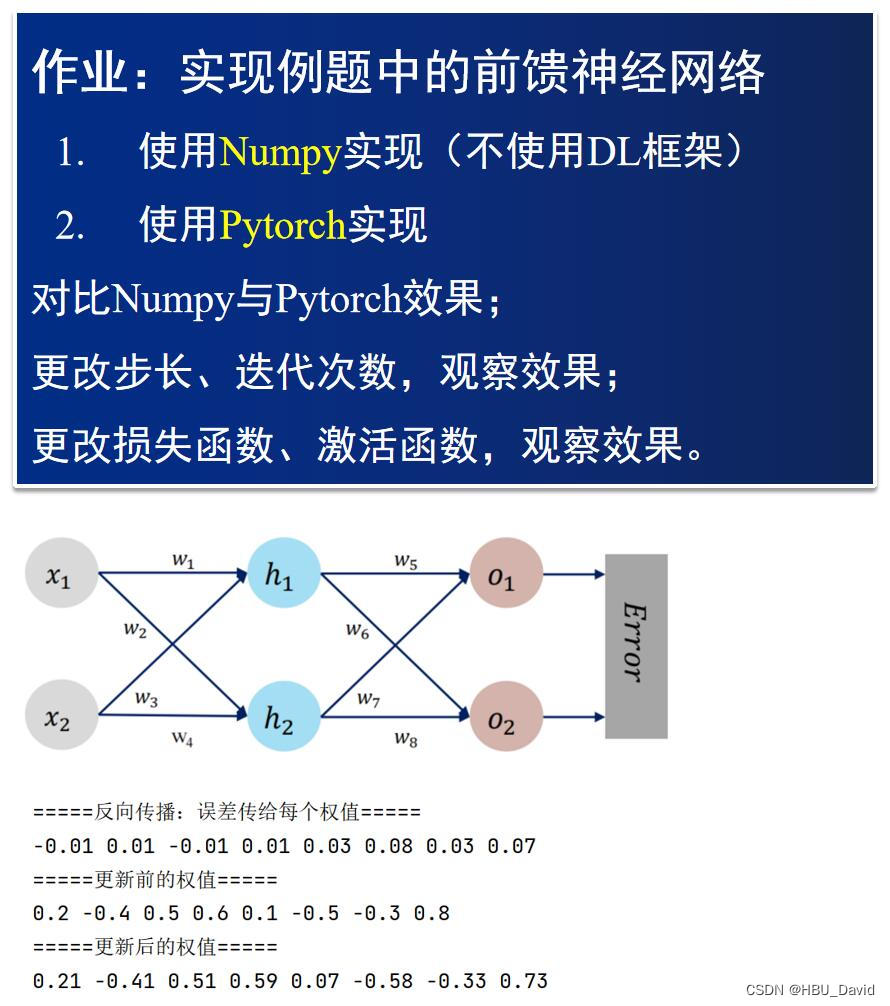
【23-24 秋学期】NNDL 作业3
过程推导 - 了解BP原理数值计算 - 手动计算,掌握细节代码实现 - numpy手推 pytorch自动 对比【numpy】和【pytorch】程序,总结并陈述。激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述。激活函数Sigmoid改变为Relu&#…...
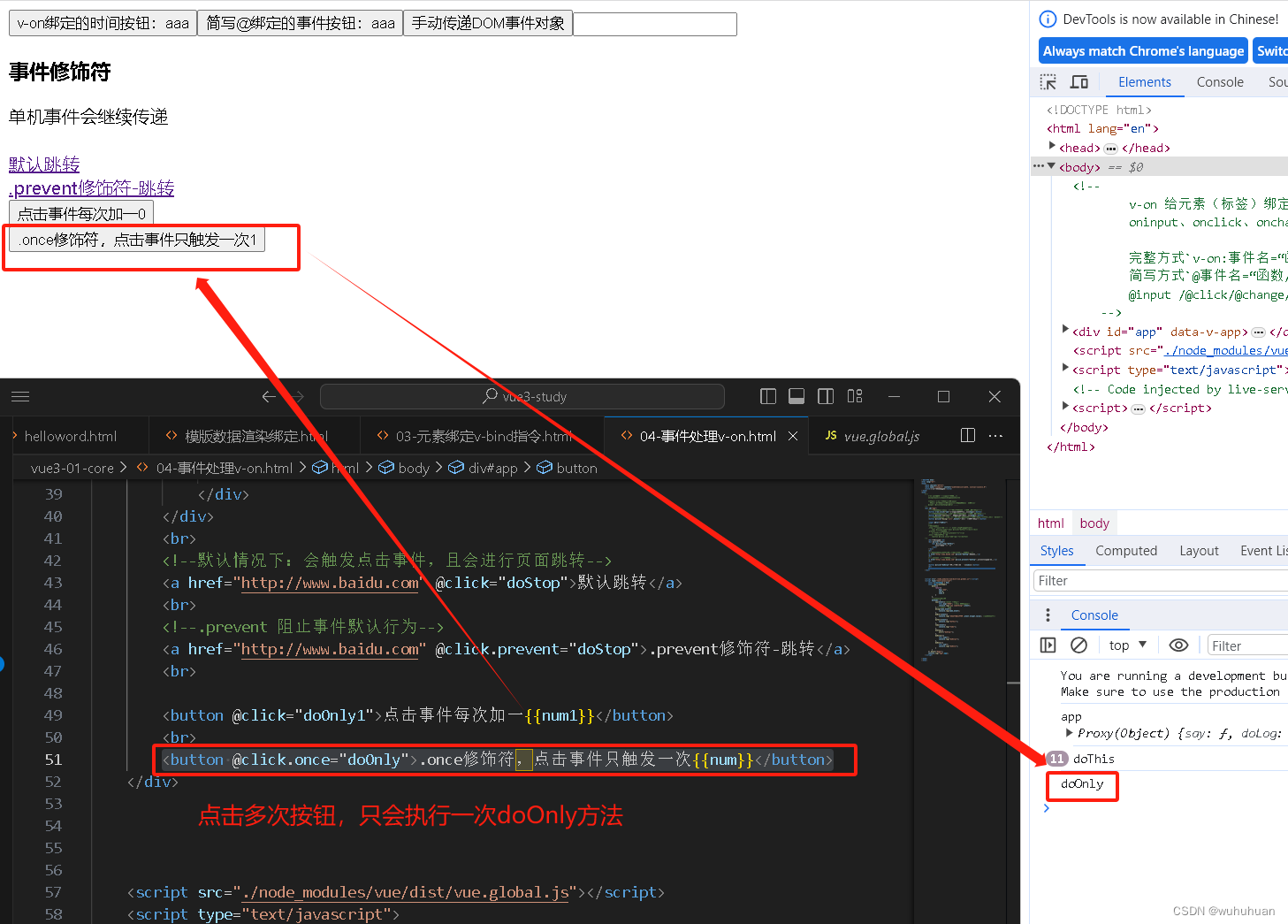
v-on/@ 事件处理指令修饰符-stop、prevent、once
v-on/事件修饰符: 一、.stop 阻止单机事件继续传播 event.stopProgagetion() eg: <h3>事件修饰符</h3> <div click"todo"> <div click.stop"doThis"> 单机事件会继续传递 </div> </div> 点击 单机事…...
macOS Sonoma 14.1beta3(23B5067a)发布
黑果魏叔10 月 11 日消息,苹果今日向 Mac 电脑用户推送了 macOS 14.1 开发者预览版 Beta 3 更新(内部版本号:23B5067a),本次更新距离上次发布隔了 7 天。 根据官方发布的macOS Sonoma 14.1beta3更新日志,此…...

这些负载均衡都解决哪些问题?服务、网关、NGINX?
在微服务项目中,有服务的负载均衡、网关的负载均衡、Nginx的负载均衡,这几个负载均衡分别用来解决什么问题呢? 一、服务的负载均衡 先抛出一个问题: 当一个微服务被多个实例部署时,如何分配和平衡请求的负载&#x…...

#力扣:344. 反转字符串@FDDLC
344. 反转字符串 一、Java class Solution {public void reverseString(char[] s) {for (int l 0, r s.length - 1; l < r; l, r--) {s[l] ^ s[r];s[r] ^ s[l];s[l] ^ s[r];}} } 二、C #include <vector> using namespace std; class Solution { public:void re…...
浅谈SSL通配符证书优势
在当今数字化时代,网络安全是一个日益重要的问题。随着越来越多的网站和应用程序被创建和部署,用户输入的敏感信息面临着潜在的风险。为了确保数据传输的机密性和完整性,SSL(Secure Sockets Layer)证书成为保护用户隐私…...
[开源]基于流程编排的自动化测试工具,插件驱动,测试无限可能
一、开源项目简介 流程编排,插件驱动,测试无限可能 一款基于流程编排的自动化测试工具 二、开源协议 使用Apache-2.0开源协议 三、界面展示 四、功能概述 在软件开发旅程中,测试流程的管理和执行常常是复杂且耗时的挑战。传统测试工具主…...

gdb的一些常见命令收录
gdb的一些常见命令收录 基本命令设置和查看调试其他 基本命令 run 运行程序。 next (n) 单步调试(不进入函数)。 step (s) 单步调试(进入函数)。 continue © 继续执行程序。 quit (q) 退出GDB。 help 获取GDB命令的帮…...

KRaft VS RocketMQ NameServer
Kafka KRaft 和 RocketMQ NameServer 是两大消息队列用于元数据/路由管理的核心组件,但设计哲学完全不同:KRaft 是强一致的共识集群(CP),NameServer 是无状态的分布式路由表(AP)。下面从架构、原理、优缺点、选型做全面对比。 一、核心定位与本质区别 Kafka KRaft 定位…...

当 95% 泳池拒绝轮椅人群时,“泳池升降机” 正在创造包容性蓝海
在一座城市的游泳馆里,坐在轮椅上的小李望着眼前的泳池,眼神中满是渴望却又带着一丝无奈。以往,他只能看着别人在水中畅游,因为大部分泳池没有适合他这样行动不便者入水的设施。但最近,这家游泳馆引入了一款便携式泳池…...

别再手动查日志了!用Skywalking 9.x快速定位Spring Boot微服务性能瓶颈
别再手动查日志了!用Skywalking 9.x快速定位Spring Boot微服务性能瓶颈 微服务架构下最令人头疼的场景莫过于:凌晨三点收到告警,某个核心接口响应时间从200ms飙升到5秒,而你面对几十个相互调用的服务和海量日志,完全不…...

Claude Code 使用秘籍大公开!从零基础到精通,字节跳动官方手册等你拿!
本文提供了一份详尽的 Claude Code 使用手册,专为从零基础到精通的学习者设计。手册采用手把手教学方式,步骤清晰,技巧实用,无需复杂代码知识即可上手。文中特别强调了对使用 Gemini3 的伙伴的适用性,并鼓励读者点赞、…...

好写作AI:本科毕业论文的“通关秘籍制造机”
对于众多本科生而言,撰写毕业论文就像是一场艰难的“冒险之旅”,从选题时的迷茫,到内容创作的绞尽脑汁,再到格式调整的繁琐,每一步都充满挑战。不过别担心,好写作AI(官网:https://ww…...

禅道最新22.0+ 手动删除无法安装之清理卸载办法
禅道项目管理软件卸载方法详解:如何彻底清除所有相关文件和配置在企业或个人开发环境中,禅道(Zentao)作为一款广受欢迎的开源项目管理工具,因其功能全面、易用性强而被广泛使用。然而,在某些情况下…...

告别重复输入:快马助你打造高效openclaw命令管理工具
最近在团队协作中频繁使用openclaw工具时,发现每次手动输入冗长的命令参数特别容易出错,尤其是当需要切换不同环境配置时,常常因为输错一个参数导致整个流程卡住。于是决定用Python开发一个小工具来提升操作效率,顺便把实现过程记…...

cursor ctrl+方法跳转
扩展中安装了python就解决了,...

4个核心预训练模型应用指南:从资源获取到问题诊断
4个核心预训练模型应用指南:从资源获取到问题诊断 【免费下载链接】so-vits-svc SoftVC VITS Singing Voice Conversion 项目地址: https://gitcode.com/gh_mirrors/so/so-vits-svc 预训练模型是so-vits-svc实现高质量语音转换的基础组件,这些经过…...

DownKyi:3分钟学会B站视频下载的终极免费方案
DownKyi:3分钟学会B站视频下载的终极免费方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)。…...