Xception:使用Tensorflow从头开始实现
一、说明
近年来,卷积神经网络已成为计算机视觉领域的主要算法,开发设计它们的方法一直是相当的关注。Inception模型似乎能够用更少的参数学习更丰富的表示。它们是如何工作的,以及它们与常规卷积有何不同?本文将用tensorflow实现,用具体实践展现它的结构。

卷积神经网络(CNN)已经走了很长一段路,从LeNet风格的AlexNet,VGG模型,它使用简单的卷积层堆栈进行特征提取,最大池化层用于空间子采样,一个接一个地堆叠,到Inception和ResNet网络,它们在每层中使用跳过连接和多个卷积和最大池块。自推出以来,计算机视觉中最好的网络之一就是Inception网络。Inception 模型使用一堆模块,每个模块包含一堆特征提取器,这允许它们使用更少的参数学习更丰富的表示。
Xception论文— https://arxiv.org/abs/1610.02357
如图 1 所示,Xception 模块有 3 个主要部分。入口流、中间流(重复 8 次)和退出流。

入口流有两个卷积层块,然后是 ReLU 激活。该图还详细提到了过滤器的数量、过滤器大小(内核大小)和步长。
还有各种可分离卷积层。还有最大池化层。当步幅与步幅不同时,还会提到步幅。还有 Skip 连接,我们使用“ADD”来合并两个张量。它还显示了每个流中输入张量的形状。例如,我们从 299x299x3 的图像大小开始,在输入流程之后,我们得到的图像大小为 19x19x728。

图3.Xception架构的中出流程
同样,对于中间流和退出流,此图清楚地解释了图像大小、各个层、滤镜数量、滤镜形状、池化类型、重复次数以及最终添加全连接层的选项。
此外,所有卷积和可分离卷积层之后都经过批量归一化。
二、可分离卷积层
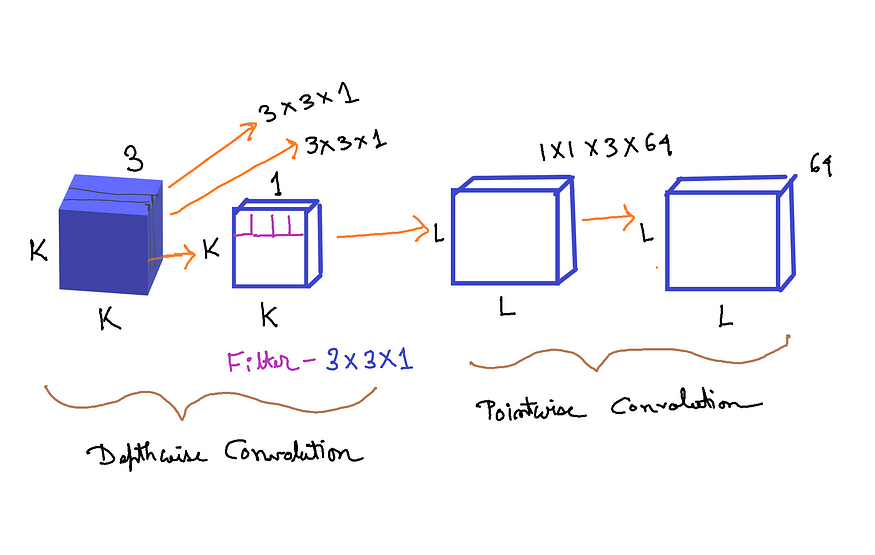
图4.可分离卷积层(来源:作者创建的图像)
可分离卷积包括首先执行深度空间卷积(分别作用于每个输入通道),然后是逐点卷积,混合生成的输出通道。 来自 Keras 文档
假设我们有一个大小为 (K, K,3) 的输入张量。K 是空间维度,3 是特征图/通道的数量。正如我们从上面的 Keras 文档中看到的,首先我们需要在每个输入通道上分别实现深度空间卷积。所以我们使用 K, K,1 — 图像/张量的第一个通道。假设我们使用大小为 3x3x1 的过滤器。并且此过滤器应用于输入张量的所有三个通道。由于有 3 个通道,所以我们得到的尺寸是 3x3x1x3。如图 4 的深度卷积部分所示。
在此之后,将所有 3 个输出放在一起,我们得到大小为 (L, L,3) 的张量。L 的维度可以与 K 相同,也可以不同,具体取决于先前卷积中使用的步幅和填充。
然后应用逐点卷积。滤波器尺寸为 1x1x3(3 个通道)。过滤器的数量可以是我们想要的任意数量的过滤器。假设我们使用 64 个过滤器。因此,总尺寸为 1x1x3x64。最后,我们得到大小为 LxLx64 的输出张量。 如图 4 的逐点卷积部分所示。
为什么可分离卷积比普通卷积更好?
如果我们在输入张量上使用法线卷积,并且我们使用 3x3x3 的过滤器/内核大小(内核大小 — (3,3) 和 3 个特征图)。我们想要的过滤器总数是 64。所以总共有 3x3x3x64。
相反,在可分离卷积中,我们首先在深度卷积中使用 3x3x1x3,在逐点卷积中使用 1x1x3x64。
区别在于过滤器的维度。
传统卷积层 = 3x3x3x64 = 1,728
可分离卷积层 = (3x3x1x3)+(1x1x3x64) = 27+192 = 219
正如我们所看到的,可分离卷积层在计算成本和内存方面都比传统的卷积层更具优势。主要区别在于,在正常卷积中,我们会多次转换图像。每次变换都会使用 3x3x3x64 = 1,728 次乘法。在可分离卷积中,我们只转换图像一次——在深度卷积中。然后,我们获取转换后的图像并将其简单地拉长到 64 个通道。无需一遍又一遍地转换图像,我们可以节省计算能力。

图5.Xception性能与ImageNet上的Inception(来源:图片来自原始论文)

Figure 6. Xception performance vs Inception on JFT dataset (Source: Image from the original paper)
Algorithm:
- 导入所有必要的图层
- 为以下各项编写所有必要的函数:
一个。转换-批处理范数块
b. 可分离卷积 - 批处理范数块
3. 为 3 个流(入口、中间和退出)中的每一个编写一个函数
4. 使用这些函数构建完整的模型
三、使用 Tensorflow 创建 Xception
#import necessary librariesimport tensorflow as tf
from tensorflow.keras.layers import Input,Dense,Conv2D,Add
from tensorflow.keras.layers import SeparableConv2D,ReLU
from tensorflow.keras.layers import BatchNormalization,MaxPool2D
from tensorflow.keras.layers import GlobalAvgPool2D
from tensorflow.keras import Model创建 Conv-BatchNorm 块:
# creating the Conv-Batch Norm blockdef conv_bn(x, filters, kernel_size, strides=1):x = Conv2D(filters=filters, kernel_size = kernel_size, strides=strides, padding = 'same', use_bias = False)(x)x = BatchNormalization()(x)
return xConv-Batch 范数块将张量 — x、过滤器数量 — 过滤器、卷积层的核大小 — kernel_size, 卷积层的步幅作为输入。然后我们将卷积层应用于 x,然后应用批量归一化。我们加上use_bias = False,这样最终模型的参数数量,将与原始论文的参数数量相同。
创建可分离的Conv-BatchNorm块:
# creating separableConv-Batch Norm blockdef sep_bn(x, filters, kernel_size, strides=1):x = SeparableConv2D(filters=filters, kernel_size = kernel_size, strides=strides, padding = 'same', use_bias = False)(x)x = BatchNormalization()(x)
return x与 Conv-Batch Norm 块的结构类似,只是我们使用 SeparableConv2D 而不是 Conv2D。
入口、中间和退出流的函数:
# entry flowdef entry_flow(x):x = conv_bn(x, filters =32, kernel_size =3, strides=2)x = ReLU()(x)x = conv_bn(x, filters =64, kernel_size =3, strides=1)tensor = ReLU()(x)x = sep_bn(tensor, filters = 128, kernel_size =3)x = ReLU()(x)x = sep_bn(x, filters = 128, kernel_size =3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=128, kernel_size = 1,strides=2)x = Add()([tensor,x])x = ReLU()(x)x = sep_bn(x, filters =256, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters =256, kernel_size=3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=256, kernel_size = 1,strides=2)x = Add()([tensor,x])x = ReLU()(x)x = sep_bn(x, filters =728, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters =728, kernel_size=3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=728, kernel_size = 1,strides=2)x = Add()([tensor,x])
return x这里我们只遵循图 2。它从两个分别具有 32 个和 64 个过滤器的 Conv 层开始。每个之后都有一个 ReLU 激活。
然后有一个跳过连接,这是通过使用 Add 完成的。
在每个跳过连接块中,有两个可分离的 Conv 层,后跟 MaxPooling。跳过连接本身具有 1x1 的 Conv 层,步幅为 2。

图7.中流(来源:原文图片)
# middle flowdef middle_flow(tensor):for _ in range(8):x = ReLU()(tensor)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)tensor = Add()([tensor,x])return tensor中间流程遵循图 7 中所示的步骤。

图8.退出流程(来源:图片来自原文)
# exit flowdef exit_flow(tensor):x = ReLU()(tensor)x = sep_bn(x, filters = 728, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters = 1024, kernel_size=3)x = MaxPool2D(pool_size = 3, strides = 2, padding ='same')(x)tensor = conv_bn(tensor, filters =1024, kernel_size=1, strides =2)x = Add()([tensor,x])x = sep_bn(x, filters = 1536, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters = 2048, kernel_size=3)x = GlobalAvgPool2D()(x)x = Dense (units = 1000, activation = 'softmax')(x)return x退出流程遵循如图 8 所示的步骤。
四、创建Xception模型:
# model codeinput = Input(shape = (299,299,3))
x = entry_flow(input)
x = middle_flow(x)
output = exit_flow(x)model = Model (inputs=input, outputs=output)
model.summary()输出代码段:

from tensorflow.python.keras.utils.vis_utils import model_to_dot
from IPython.display import SVG
import pydot
import graphvizSVG(model_to_dot(model, show_shapes=True, show_layer_names=True, rankdir='TB',expand_nested=False, dpi=60, subgraph=False).create(prog='dot',format='svg'))输出代码段:
import numpy as np
import tensorflow.keras.backend as K
np.sum([K.count_params(p) for p in model.trainable_weights])输出:22855952
上面的代码显示了可训练参数的数量。
五、完整代码
使用Tensorflow从头开始创建Xception模型的完整代码:
#import necessary librariesimport tensorflow as tf
from tensorflow.keras.layers import Input,Dense,Conv2D,Add
from tensorflow.keras.layers import SeparableConv2D,ReLU
from tensorflow.keras.layers import BatchNormalization,MaxPool2D
from tensorflow.keras.layers import GlobalAvgPool2D
from tensorflow.keras import Model
# creating the Conv-Batch Norm blockdef conv_bn(x, filters, kernel_size, strides=1):x = Conv2D(filters=filters, kernel_size = kernel_size, strides=strides, padding = 'same', use_bias = False)(x)x = BatchNormalization()(x)
return x
# creating separableConv-Batch Norm blockdef sep_bn(x, filters, kernel_size, strides=1):x = SeparableConv2D(filters=filters, kernel_size = kernel_size, strides=strides, padding = 'same', use_bias = False)(x)x = BatchNormalization()(x)
return x
# entry flowdef entry_flow(x):x = conv_bn(x, filters =32, kernel_size =3, strides=2)x = ReLU()(x)x = conv_bn(x, filters =64, kernel_size =3, strides=1)tensor = ReLU()(x)x = sep_bn(tensor, filters = 128, kernel_size =3)x = ReLU()(x)x = sep_bn(x, filters = 128, kernel_size =3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=128, kernel_size = 1,strides=2)x = Add()([tensor,x])x = ReLU()(x)x = sep_bn(x, filters =256, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters =256, kernel_size=3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=256, kernel_size = 1,strides=2)x = Add()([tensor,x])x = ReLU()(x)x = sep_bn(x, filters =728, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters =728, kernel_size=3)x = MaxPool2D(pool_size=3, strides=2, padding = 'same')(x)tensor = conv_bn(tensor, filters=728, kernel_size = 1,strides=2)x = Add()([tensor,x])
return x
# middle flowdef middle_flow(tensor):for _ in range(8):x = ReLU()(tensor)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)x = sep_bn(x, filters = 728, kernel_size = 3)x = ReLU()(x)tensor = Add()([tensor,x])return tensor
# exit flowdef exit_flow(tensor):x = ReLU()(tensor)x = sep_bn(x, filters = 728, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters = 1024, kernel_size=3)x = MaxPool2D(pool_size = 3, strides = 2, padding ='same')(x)tensor = conv_bn(tensor, filters =1024, kernel_size=1, strides =2)x = Add()([tensor,x])x = sep_bn(x, filters = 1536, kernel_size=3)x = ReLU()(x)x = sep_bn(x, filters = 2048, kernel_size=3)x = GlobalAvgPool2D()(x)x = Dense (units = 1000, activation = 'softmax')(x)return x
# model codeinput = Input(shape = (299,299,3))
x = entry_flow(input)
x = middle_flow(x)
output = exit_flow(x)model = Model (inputs=input, outputs=output)
model.summary()六、结论
如图 5 和图 6 所示,与 ImageNet 数据集相比,Xception 架构在 JFT 数据集上的性能改进比 Inception 网络要好得多。Xception的作者认为,这是因为Inception被设计为专注于ImageNet,因此可能过于适合特定任务。另一方面,这两种架构都没有针对JFT数据集进行调优。
此外,Inception 有大约 23 万个参数,而 Xception 有 6 万个参数。
如图 1 所示,Xception 架构在论文中很容易解释,这使得使用 TensorFlow 实现网络架构变得非常容易。
相关文章:
Xception:使用Tensorflow从头开始实现
一、说明 近年来,卷积神经网络已成为计算机视觉领域的主要算法,开发设计它们的方法一直是相当的关注。Inception模型似乎能够用更少的参数学习更丰富的表示。它们是如何工作的,以及它们与常规卷积有何不同?本文将用tensorflow实现…...

Practical Memory Leak Detection using Guarded Value-Flow Analysis 论文阅读
本文于 2007 年投稿于 ACM-SIGPLAN 会议1。 概述 指针在代码编写过程中可能出现以下两种问题: 存在一条执行路径,指针未成功释放(内存泄漏),如下面代码中注释部分所表明的: int foo() {int *p malloc(4 …...
淘宝天猫商品历史价格API接口
获取淘宝商品历史价格接口的步骤如下: 注册淘宝开放平台:首先在淘宝开放平台上注册一个账号,并进行登录。创建应用:在淘宝开放平台上创建一个应用,并获取该应用的App Key和App Secret,用于后续的接口调用。…...

从0开始学go第七天
gin获取表单from中的数据 模拟简单登录页面: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><title>login</title> </head><body><form action"/login" method&q…...

【牛客面试必刷TOP101】Day7.BM31 对称的二叉树和BM32 合并二叉树
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:牛客面试必刷TOP101 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!&…...
U盘怎么设置为只读?U盘怎么只读加密?
当将U盘设置为只读模式时,将只能查看其中数据,无法对其中数据进行编辑、复制、删除等操作。那么,怎么将U盘设置成只读呢? U盘如何设置成只读? 有些U盘带有写保护开关,当打开时,U盘就会处于只读…...

为什么MyBatis是Java数据库持久层的明智选择
在Java应用程序的开发中,选择合适的数据库持久层框架至关重要。一个明智的选择可以帮助开发人员更好地管理数据库交互、提高性能和简化开发工作。 (一)为什么要选MyBatis JDBCHibernate / JPAMyBatis简单直接ORM轻量动态SQL关联查询开发效率…...
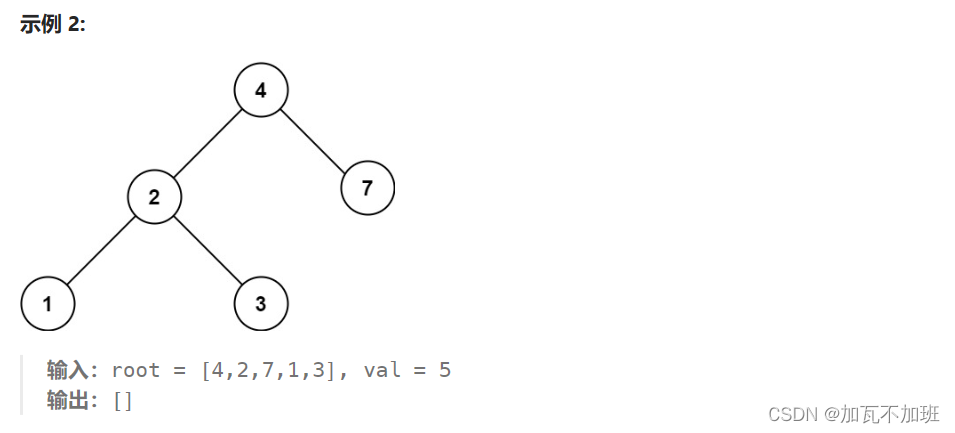
二叉搜索树--查询节点-力扣 700 题
例题细节讲过(二叉搜索树的基础操作-CSDN博客),下面给出递归实现 public TreeNode searchBST(TreeNode node, int val) {if(node null) {return null;}if(val < node.val) {return searchBST(node.left, val);} else if(node.val < val) {return searchBST(…...
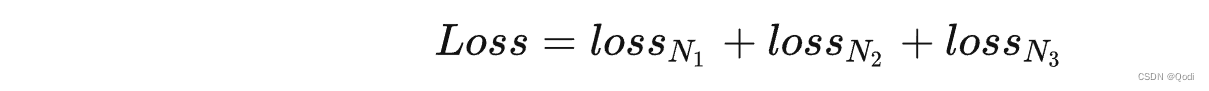
YOLOv3 | 核心主干网络,特征图解码,多类损失函数详解
https://zhuanlan.zhihu.com/p/76802514) 文章目录 1. 核心改进1.1主干网络1.2 特征图解码1.2.1 检测框(位置,宽高)解码1.2.2 检测置信度解码1.2.3 类别解码 1.3 训练损失函数1.3.1 正负样本定义1.3.2 损失函数 1. 核心改进 1.1主干网络 更…...

Java架构师API设计
目录 1 导学2 架构师的角度来审视API2.1 API狭隘理解2.2 API广义理解2.3 API的用途不同定义2.4 面向抽象编程的Java开发2.5 API在提高系统的可维护性和可扩展性方面的作用3 架构师必备的API设计原则3.1 标准化原则3.2 易用性原则3.3 扩展性原则3.4 兼容性原则3.5 抽象性原则3.6…...

.net也能写内存挂
最近在研究.net的内存挂。 写了很久的c,发现c#写出来的东西实在太香。 折腾c#外挂已经有很长时间了。都是用socket和c配合。 这个模式其实蛮成功的,用rpc调用的方式加上c#的天生await 非常好写逻辑 类似这样 最近想换个口味。注入托管dll到非托管进程 这样做只…...

python学习笔记2-数字转化为String
题目链接 str() 强制转换, sorted() 转换为有序列表,join() 将列表中的元素连接到字符串中,然后奇偶位组合成数字 class Solution:def splitNum(self, num: int) -> int:stnum "".join(sorted(str(num)))num1, num2 int(stn…...
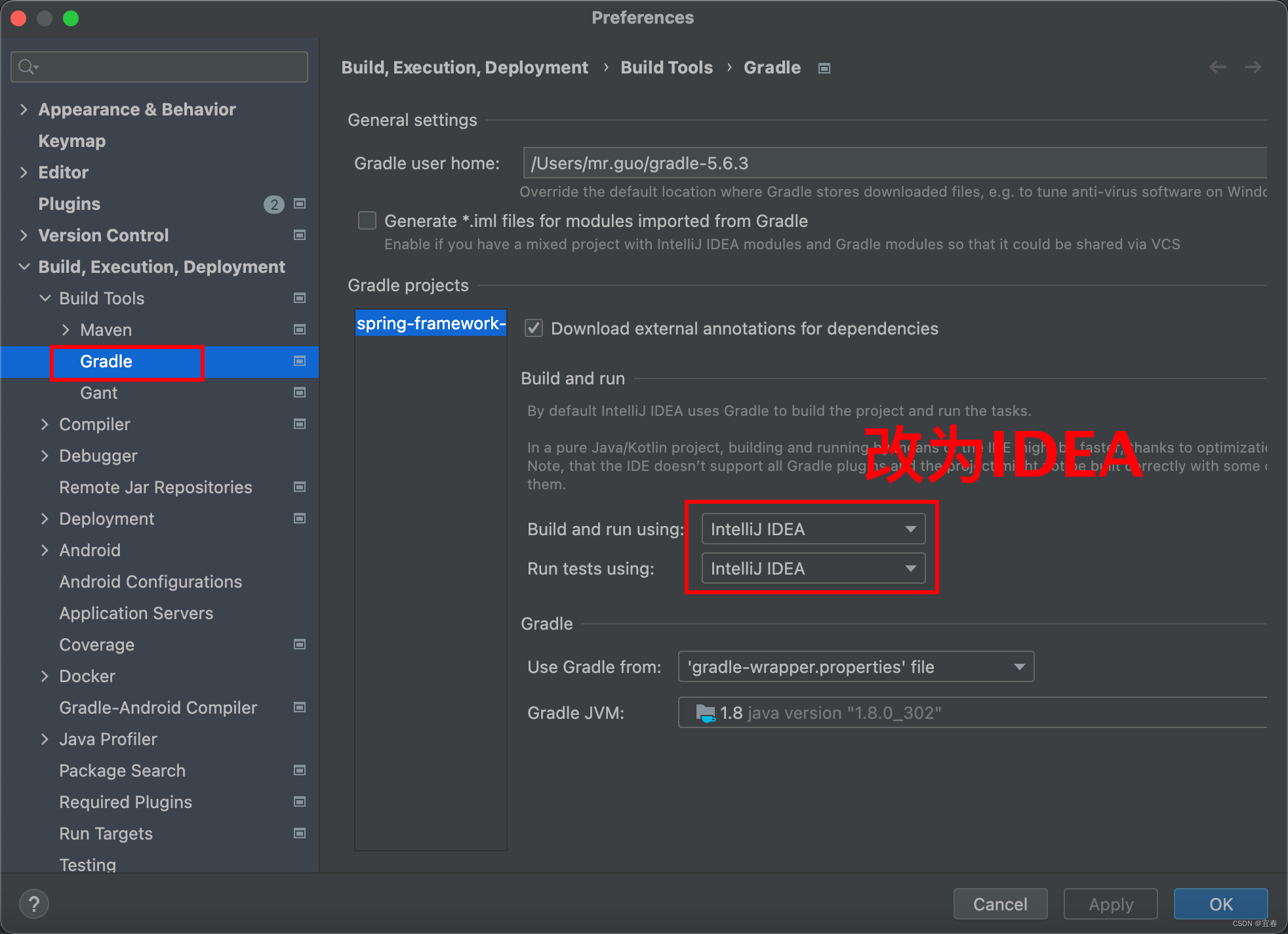
MAC版Gradle构建Spring5.X源码阅读环境
前言: 三年前鄙人有幸在现已几乎报废的Window的DELL中搭建过Spring源码环境,今天,Mac版的搭建,来了。 本篇文章环境搭建:Spring5.2.1 Gradle5.6.3-all jdk8 IDEA2022.3版本 文章目录 1、Spring源码下载2、Gradle下载…...

Linux 常用通配符
通配符是一种特殊语句,主要有星号(*)和问号(?),用来模糊搜索文件。当查找文件夹时,可以使用它来代替一个或多个真正字符;当不知道真正字符或者懒得输入完整名字时&#x…...

Python皮卡丘
系列文章 序号文章目录直达链接1浪漫520表白代码https://want595.blog.csdn.net/article/details/1306668812满屏表白代码https://want595.blog.csdn.net/article/details/1297945183跳动的爱心https://want595.blog.csdn.net/article/details/1295031234漂浮爱心https://want…...

【数据结构与算法】三种简单排序算法,包括冒泡排序、选择排序、插入排序算法
冒泡排序算法 冒泡排序他是通过双重循环对每一个值进行比较,将小的值向后移动,以达到最终排序的结果,他的时间复杂度为O(n^2)。 /*** 冒泡排序* param arr*/public static void bubbleSort(int[] arr){int l arr.length;for (int i 0; i <…...
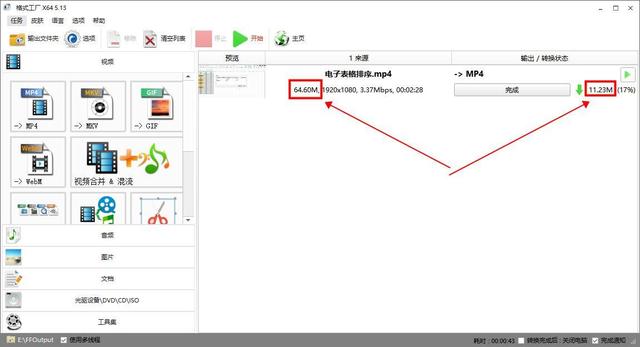
视频太大怎么压缩变小?超过1G的视频这样压缩
视频已经成为了我们日常生活中不可或缺的一部分,然而,很多时候,我们可能会遇到视频文件过大,无法在某些平台上传或保存的问题。那么,如何将过大的视频文件压缩变小呢? 下面就给大家分享三款实用的工具&…...
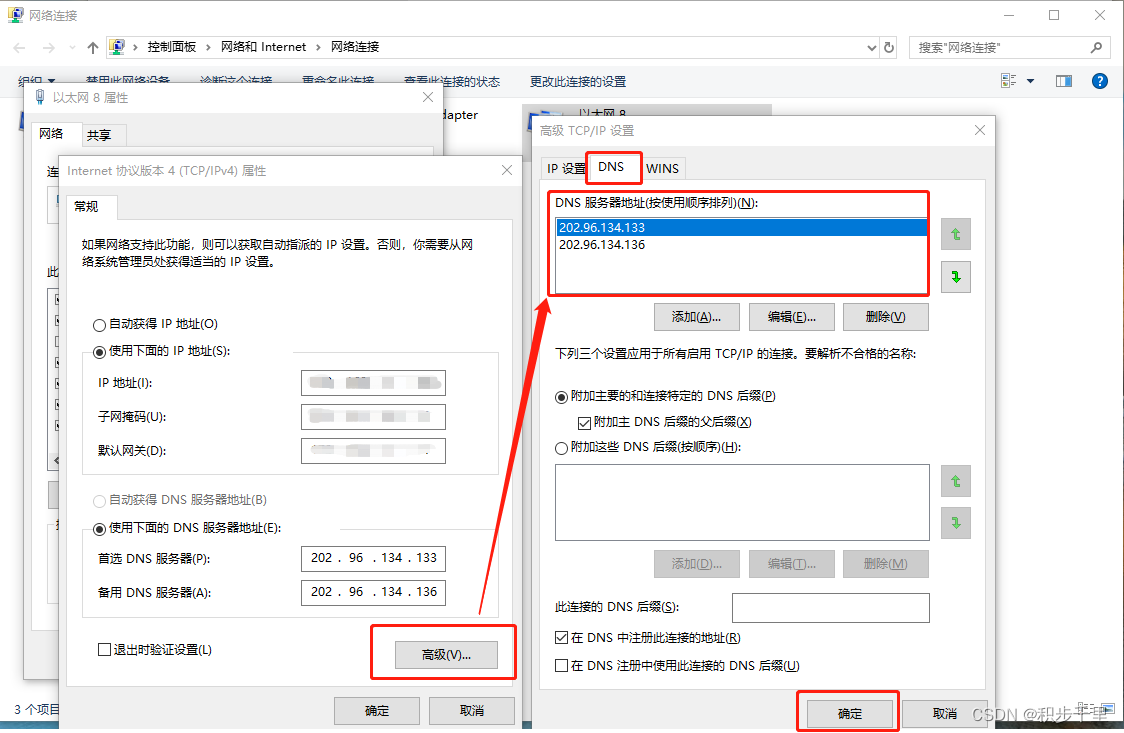
Edge 无法登录/同步问题【一招搞定】
目录 前言 一、打开 Edge 浏览器显示未同步,点击同步无效 二、Edge 登录报错 0x801901f4 或 0x80190001 解决方法 2.1 报错 0x801901f4 解决方法 2.1.0 Edge 登陆报错图示 2.1.1 添加 Edge 推荐的 DNS 地址 2.1.2 重新登录 Edge 账号成功 2.2 报错 0x801…...
ESP32-S3上手开发
1、搭建开发环境 首先搭建开发环境,这里采用了windows下集成开发环境ide进行开发,具体的安装方法:ESP-IDF安装配置 这里使用的乐鑫的esp32s3,N16R8 2、esp32s3模块 从上面图中可以看到,N16R8这里使用了外扩16M的fl…...

UE4和C++ 开发-编程基础记录(UE4+代码基础知识)
1、UE4基础元素 ①Actor 我们又见面了Actor,Actor是在一个关卡中持续存在的,通常他包含几个Actor组件。支持网络复制和多人游戏。 Actor不包含位置,方向。这些东西在Root Component中存储。对于UE3 中的Pawn也由PlayerCharacter继承了…...

微软DebugMCP:可视化调试MCP协议,解决AI与工具通信黑盒问题
1. 项目概述:当你的AI助手开始“自言自语”,你需要一个调试器 最近在折腾AI应用开发的朋友,估计没少跟各种“智能体”打交道。无论是基于OpenAI的GPTs,还是那些能联网、能调用工具的自定义助手,它们背后的核心通信协议…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

AI项目脚手架:标准化与自动化提升工程效率
1. 项目概述:一个为AI项目量身定制的“脚手架”如果你和我一样,在AI领域摸爬滚打多年,从早期的机器学习模型到现在的深度学习、大语言模型应用,肯定经历过无数次从零开始搭建项目的“阵痛”。每次新建一个项目,都要重复…...

Cursor编辑器性能优化:精准重置缓存与进程的开发者效率工具
1. 项目概述:一个被低估的开发者效率工具如果你是一名开发者,尤其是深度使用 Cursor 这类 AI 驱动的代码编辑器,那么你一定遇到过这样的场景:编辑器突然变得卡顿、代码补全失灵、AI 建议变得驴唇不对马嘴,或者插件行为…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

AI绘图技能解析:用自然语言驱动Excalidraw自动生成图表
1. 项目概述:一个为Excalidraw注入AI灵魂的绘图技能如果你经常用Excalidraw画流程图、架构图或者白板草图,那你一定体会过那种“想法很丰满,画笔很骨感”的尴尬。脑子里明明有一个清晰的系统架构,但落到画布上,光是调整…...