k8s中如何使用gpu、gpu资源讲解、nvidia gpu驱动安装
前言
环境:centos7.9、k8s 1.22.17、docker-ce-20.10.9
gpu资源也是服务器中常见的一种资源,gpu即显卡,一般用在人工智能、图文识别、大模型等领域,其中nvidia gpu是nvidia公司生产的nvidia类型的显卡,amd gpu则是adm公司生产的amd类型gpu。企业中服务器最常见的就是英伟达gpu服务器了。
本篇也主要讲解英伟达驱动相关的知识。
nvidia gpu驱动安装
nvidia gpu驱动安装只是涉及物理节点的驱动安装,不涉及k8s,这里简单讲解一下gpu服务器如何安装nvidia驱动。
环境确认、卸载nouveau
#查看服务器是否有gpu
[root@gpu ~]# lspci | grep -i nvidia
0b:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)
13:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)
#查看服务器是否已经安装有gpu英伟达驱动
lsmod | grep -i nvidia
#查看gpu型号、gpu驱动版本等,能列出信息说明驱动已经安装成功,没有信息则说明还没安装驱动
nvidia-smi
#查看是否安装有默认驱动,没有跳过该步骤,有显示内容则说明安装有默认驱动,需要卸载掉,不然会和nvidia冲突,卸载步骤如下
lsmod | grep nouveau
centos6:vim /etc/modprobe.d/blacklist.conf
centos7:vim /usr/lib/modprobe.d/dist-blacklist.conf
#centos 7直接使用命令修改
ls /usr/lib/modprobe.d/dist-blacklist.conf && echo $?
sed -i -e '/blacklist viafb/ablacklist nouveau' -e '/blacklist viafb/aoptions nouveau modeset=0' /usr/lib/modprobe.d/dist-blacklist.conf && echo $?
echo "检查是否修改成功:";grep 'nouveau' /usr/lib/modprobe.d/dist-blacklist.conf
#或者手动编辑文件亦可,在blacklist viafb等列的文件末尾添加下面两句
blacklist nouveau
options nouveau modeset=0
#备份原来的镜像,重新生成镜像文件,可以临时禁用,重启,再次确认是否已经禁用/卸载
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)
modprobe -r nouveau
reboot
lsmod | grep nouveau
确认当前英伟达显卡的型号
lspci | grep -i nvidia #复制下面的1eb8
0b:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)
13:00.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)打开网站查询:https://admin.pci-ids.ucw.cz/read/PC/10de
拖到底部的查询框输出1eb8,点击查询即可,输出显示类似的如下信息即可得知gpu型号是Tesla T4
Name: TU104GL [Tesla T4]
Discussion
Name: TU104GL [Tesla T4]
T4CFantasy
下载nvidia驱动
英伟达驱动官网:https://www.nvidia.cn/Download/index.aspx?lang=cn
在下拉列表中进行选择,针对NVIDIA产品确定合适的驱动,这里我就这样选择:
产品类型: Data Center / Tesla
产品系列: T-Series
产品家族: Tesla T4
操作系统: Linux 64-bit
CUDA Toolkit: 11.4
语言: Chinese (Simplified)选择好之后点击搜索,显示驱动的版本是:470.199.02,然后点击下载即可,在产品支持列表中可以看到,我们选择的这个470.199.02版本驱动其实还可以支持很多版本的显卡,如下:
A-Series:
NVIDIA A800, NVIDIA A100, NVIDIA A40, NVIDIA A30, NVIDIA A16, NVIDIA A10, NVIDIA A2
RTX-Series:
RTX 8000, RTX 6000, NVIDIA RTX A6000, NVIDIA RTX A5000, NVIDIA RTX A4000, NVIDIA T1000, NVIDIA T600, NVIDIA T400
HGX-Series:
HGX A800, HGX A100
T-Series:
Tesla T4
V-Series:
Tesla V100
P-Series:
Tesla P100, Tesla P40, Tesla P6, Tesla P4
K-Series:
Tesla K80, Tesla K520
M-Class:
M60, M40 24GB, M40, M6, M4
所以,基本上470.199.02这个版本的驱动就可以支持Tesla T4、NVIDIA A800、NVIDIA A100、Tesla V100、Tesla P4等常见的显卡.
注意:
选择不同的CUDA下载的驱动包会不同,比如CUDA选择的是11.4,搜索结果显示的是驱动包是470.199.02
如果CUDA选择的是11.6,搜索结果显示的驱动包是510.108.03.
所以这个需要根据业务上支持的cuda版本来选择下载对应的显卡驱动和cuda.
nvidia gpu驱动安装
#将下载的gpu驱动文件上传到服务器安装即可
yum install gcc make -y
#直接安装即可,视情况加参数
chmod a+x NVIDIA-Linux-x86_64-470.199.02.run
./NVIDIA-Linux-x86_64-470.199.02.run
gpu资源的使用限制
在k8s中,gpu资源的名称叫做nvidia/gpu或者amd/gpu,其中是nvidaia公司的生产的nvidaia类型的gpu,后者是amd公司生产的amd类型gpu。
注意,目前对gpu的使用配置有如下限制:
1、gpu资源只能在limits字段设置,不可以仅指定 requests 而不指定 limits,可以同时指定 limits 和 requests,不过这两个值必须相等,
2、可以指定 gpu 的 limits 而不指定其 requests,则pod默认将requests值等价于limits 值;
3、 pod中的容器之间是不共享 gpu 的,gpu 也不可以超量分配(注:cpu可以超量使用);
4、每个容器可以请求一个或者多个 gpu,但是必须是整数,用小数值来请求部分 gpu 是不允许的。
安装nvidia-docker(不推荐)
nvidia-docker是一个工具,用于在gpu启用的Linux系统上运行Docker容器。它提供了一个命令行接口,使得在gpu上运行深度学习和机器学习任务的容器变得更为方便。通过使用nvidia-docker,可以轻松地配置和管理gpu容器环境,而无需手动安装和配置各种依赖项。
nvidia-docker并不会与已经安装好的Docker冲突。nvidia-docker是一个额外的工具,用于在Docker中更方便地使用gpu,它与Docker共存并为其提供额外的功能。在安装过程中,nvidia-docker会检测系统是否安装了Docker,并会自动地与Docker进行集成,以提供对gpu容器的支持。因此,安装nvidia-docker后,可以继续使用已经安装好的Docker工具,并能够在Docker中更方便地使用gpu。
nvidia-docker属于旧一代的工具,适用于docker19.3以下版本,目前,官方推荐使用nvidia-container-toolkit,这是github最新的支持方案,nvidia docker2已被nvidia container toolkits取代,所以更推荐使用nvidia container toolkits。
#以下仅显示如何安装nvidia-docker2,建议使用nvidia container toolkits
#复制一份原始的docker配置文件,nvidia-docker2安装后会覆盖原始的docker配置文件
cp /etc/docker/daemon.json /etc/docker/daemon.json.bak
#下载仓库
wget https://nvidia.github.io/nvidia-docker/centos7/x86_64/nvidia-docker.repo && mv nvidia-docker.repo /etc/yum.repos.d/
或者
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \sudo tee /etc/yum.repos.d/nvidia-docker.repo#安装nvidia-docker
#安装的时候发现如下报错,可能是镜像仓库不存在的问题,但是更新缓存之后又正常下载gpgkey,可以正常安装
#报错:https://nvidia.github.io/libnvidia-container/centos7/x86_64/repodata/repomd.xml: [Errno 14] HTTPS Error 404 - Not Found
yum makecache
yum search --showduplicates nvidia-docker
yum install -y nvidia-docker2
#安装后发现docker配置文件被覆盖了,所以手动修改还原
[root@gpu ~]# cd /etc/docker/
-rw-r--r-- 1 root root 136 Mar 31 2023 daemon.json
-rw-r--r-- 1 root root 119 Oct 11 23:28 daemon.json.rpmorig
[root@gpu docker]# cat daemon.json #这个是nvidia-docker2后自动创建的
{"runtimes": {"nvidia": {"path": "nvidia-container-runtime","runtimeArgs": []}}
}
[root@gpu docker]# cat daemon.json.rpmorig #原始的docker配置文件
{"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"]
}
# 最终的docker配置文件
[root@gpu docker]# cat daemon.json
{"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],"exec-opts": ["native.cgroupdriver=systemd"],"default-runtime": "nvidia", #新加一行,指定docker的默认运行时"runtimes": {"nvidia": {"path": "nvidia-container-runtime","runtimeArgs": []}}
}
#注:docker需要运行时为nvidia才能使用gpu,故设置默认运行时为nvidia
#重启docker
[root@gpu docker]# systemctl restart docker
#查看docker默认运行时
docker info | grep -i 'Default Runtime'
#验证,能正常显示gpu显卡信息即说明成功
docker run --rm --runtime=nvidia nvidia/cuda:9.0-base nvidia-smi
安装nvidia-container-toolkit(推荐)
#复制一份docker配置文件,以防被覆盖
cp /etc/docker/daemon.json /etc/docker/daemon.json.bak
#根据官网步骤安装nvidia-container-toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#installing-with-yum-or-dnf
Configure the repository:
#下载仓库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
#安装NVIDIA Container Toolkit
yum search --showduplicates nvidia-container-toolkit
yum install -y nvidia-container-toolkit
#配置容器运行时
#nvidia-ctk命令将会修改/etc/docker/daemon.json文件以便Docker可以使用nvidia容器运行时
nvidia-ctk runtime configure --runtime=docker
#实际上,上面nvidia-ctk命令是往/etc/docker/daemon.json文件追加了如下参数"runtimes": {"nvidia": {"args": [],"path": "nvidia-container-runtime"}}#重启dockers
systemctl restart docker#测试容器中使用gpu
#使用下面的任意一条命令运行一个简单的容器测试,可以正常显卡的信息则说明配置成功
#--gpus N 表示分配多少gpu显卡到容器,all表示全部gpu显卡
#--runtime指定运行时为nvidia,要使用nvidia运行时才能正常使用gpu,当前默认运行时是runc
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
docker run --rm --runtime=nvidia nvidia/cuda:9.0-base nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.199.02 Driver Version: 470.199.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| gpu Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | gpu-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:0B:00.0 Off | 0 |
| N/A 34C P0 25W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:13:00.0 Off | 0 |
| N/A 35C P0 26W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+#修改docker默认运行时
#docker要使用nvidia运行时才能正常使用gpu,以上我们使用docker run命令临时设置启动容器的运行时,但在k8s中,kubelet调用docker,所以要将docker默认运行时设置为nvidia.
#查看当前docker默认运行时
docker info | grep -i 'Default Runtime'Default Runtime: runc
#修改docker默认运行时
vim /etc/docker/daemon.json
{"exec-opts": ["native.cgroupdriver=systemd"],"default-runtime": "nvidia", #设置默认运行时"runtimes": {"nvidia": {"args": [],"path": "nvidia-container-runtime"}}
}
#重启docker并确认默认运行时生效
systemctl restart docker
docker info | grep -i 'Default Runtime'
k8s安装nvidia-device-plugin插件
#查看节点资源情况
#这说明k8s节点没有识别到gpu资源,即使当前节点有gpu资源
kubectl describe nodes gpu
Capacity:cpu: 40ephemeral-storage: 51175Mihugepages-1Gi: 0hugepages-2Mi: 0memory: 16417696Kipods: 110#k8s中要识别gpu资源,需要安装nvidia-device-plugin插件,注册分配gpu主要由device-plugin插件完成
#官网:https://github.com/NVIDIA/k8s-device-plugin
wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
#vim nvidia-device-plugin.yml #该文件存在hostpath的卷,确认kubelet的安装路径正确
kubectl apply -f nvidia-device-plugin.yml
kubectl get pod -n kube-system | grep nvidia-device-plugin
#再次查看k8s的gpu节点资源情况就可以显示gpu资源了
kubectl describe nodes gpu
...........
Capacity:cpu: 40ephemeral-storage: 51175Mihugepages-1Gi: 0hugepages-2Mi: 0memory: 16417696Kinvidia.com/gpu: 2 #2个gpu显卡pods: 110
pod中使用gpu
#为gpu节点打标签
kubectl label node gpu gpu-node=true
#创建pod测试
cat >>gpu-deploy.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:name: gpu-deployment
spec:replicas: 1selector:matchLabels:app: gputemplate:metadata:labels:app: gpuspec:containers:- name: gpu-containerimage: nvidia/cuda:9.0-basecommand: ["sleep"]args: ["100000"]resources:limits:nvidia.com/gpu: 1nodeSelector:gpu-node: "true"
EOF
kubectl apply -f gpu-deploy.yaml
#pod中正常显示gpu显卡信息,说明已经可以正常使用gpu资源了
kubectl exec -it $(kubectl get pod | grep gpu-deployment | awk '{print $1}') -- nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.199.02 Driver Version: 470.199.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| gpu Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | gpu-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:0B:00.0 Off | 0 |
| N/A 27C P8 8W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
.........
k8s集群gpu虚拟化
#前面我们说过,分配的gpu资源必须是整数,如下,gpu-deployment中的资源gpu限制设置为0.5
resources:limits:nvidia.com/gpu: "0.5"
报错:
# deployments.apps "gpu-deployment" was not valid:
# * spec.template.spec.containers[0].resources.limits[nvidia.com/gpu]: Invalid value: resource.Quantity{i:resource.int64Amount{value:5, scale:-1}, d:resource.infDecAmount{Dec:(*inf.Dec)(nil)}, s:"", Format:"DecimalSI"}: must be an integer
#在实际使用场景中,我们需要将gpu虚拟化以实现更小粒度的资源分配
#开源的虚拟化gpu解决方案https://github.com/AliyunContainerService/gpushare-scheduler-extender#1、部署gpu扩展器
kubectl create -f https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
#2、修改调度器scheduler,不同的k8s版本使用的配置文件不相同,选择自己的k8s版本来部署
#2.1、适用于Kubernetes v1.23之前的版本
cd /etc/kubernetes
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/scheduler-policy-config.json
#复制一份备份
cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/kube-scheduler.yaml
#添加下面的command参数和挂载卷、挂载点参数
vim /etc/kubernetes/manifests/kube-scheduler.yaml
- --policy-config-file=/etc/kubernetes/scheduler-policy-config.json
- mountPath: /etc/kubernetes/scheduler-policy-config.jsonname: scheduler-policy-configreadOnly: true
- hostPath:path: /etc/kubernetes/scheduler-policy-config.jsontype: FileOrCreatename: scheduler-policy-config#2.2、适用于Kubernetes v1.23+的版本(含v1.23)
kubectl create -f https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
cd /etc/kubernetes
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/scheduler-policy-config.yaml
#复制一份备份
cp /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/kube-scheduler.yaml
#添加下面的command参数和挂载卷、挂载点参数
vim /etc/kubernetes/manifests/kube-scheduler.yaml
- --config=/etc/kubernetes/scheduler-policy-config.yaml
- mountPath: /etc/kubernetes/scheduler-policy-config.yamlname: scheduler-policy-configreadOnly: true
- hostPath:path: /etc/kubernetes/scheduler-policy-config.yamltype: FileOrCreatename: scheduler-policy-config#3、部署gpu device-plugin
#如果之前部署过nvidia-device-plugin,请卸载,可使用kubectl delete ds -n kube-system nvidia-device-plugin-daemonset删除
#为gpu节点打gpushare=true标签,因为下面安装的ds定义了节点标签选择器
kubectl label node <target_node> gpushare=true
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-rbac.yaml
kubectl create -f device-plugin-rbac.yaml
# 默认情况下,GPU显存以GiB为单位,若需要使用MiB为单位,需要在这个文件中,将--memory-unit=GiB修改为--memory-unit=MiB
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-ds.yaml
vim device-plugin-ds.yaml #将--memory-unit=GiB修改为--memory-unit=MiB
kubectl create -f device-plugin-ds.yaml#4、安装kubectl扩展
#安装kubectl
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.12.1/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/bin/kubectl
#安装kubectl扩展
cd /usr/bin/
wget https://github.com/AliyunContainerService/gpushare-device-plugin/releases/download/v0.3.0/kubectl-inspect-gpushare
chmod u+x /usr/bin/kubectl-inspect-gpushare#查看gpu资源
kubectl describe nodes master1 | grep -i -A10 'Capacity'
Capacity:aliyun.com/gpu-count: 2 #gpu资源aliyun.com/gpu-mem: 30218 #gpu资源,30218MiB,刚好是2张卡15109MiB相加之和#创建pod,可以正常创建
cat >gpu-deploy.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:name: gpu-deployment
spec:replicas: 1selector:matchLabels:app: gputemplate:metadata:labels:app: gpuspec:containers:- name: gpu-containerimage: nvidia/cuda:9.0-basecommand: ["sleep"]args: ["100000"]resources:limits:aliyun.com/gpu-mem: 14nodeSelector:gpu-node: "true"
EOF
#使用kubectl inspect gpushare命令查看gpu使用资源情况
[root@master1 data]# kubectl inspect gpushare 或kubectl inspect gpushare -d
NAME IPADDRESS GPU0(Allocated/Total) GPU1(Allocated/Total) GPU Memory(MiB)
master1 192.168.244.1 0/15109 0/15109 0/30218
------------------------------------------------------------------
Allocated/Total GPU Memory In Cluster:
0/30218 (0%)
[root@master1 data]#
#存在的问题
#ds中设置了--memory-unit=MiB参数,那pod中的aliyun.com/gpu-mem的单位是什么,是GiB还是MiB
aliyun.com/gpu-mem: 20
#如果是G,设置为20,应该是满足资源的,如果是Mib,设置为15109MiB也应该是满足的呀,设置为14000MiB也应该是满足的
#但是就是一直报错:Warning FailedScheduling 3m44s default-scheduler 0/1 nodes are available: 1 Insufficient GPU Memory in one device.
#为什么这里显示one device
相关文章:

k8s中如何使用gpu、gpu资源讲解、nvidia gpu驱动安装
前言 环境:centos7.9、k8s 1.22.17、docker-ce-20.10.9 gpu资源也是服务器中常见的一种资源,gpu即显卡,一般用在人工智能、图文识别、大模型等领域,其中nvidia gpu是nvidia公司生产的nvidia类型的显卡,amd gpu则是adm…...
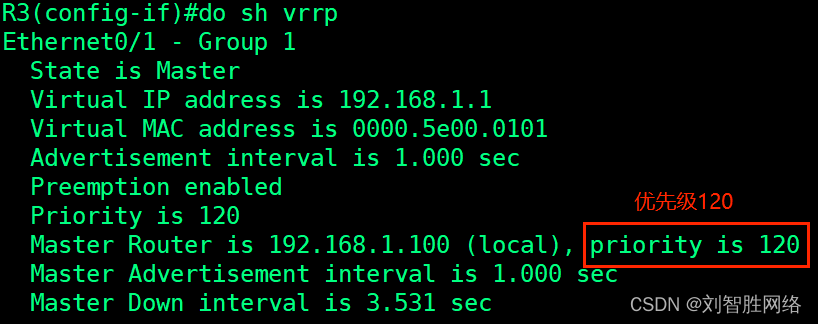
VRRP 虚拟路由器冗余协议的解析和配置
VRRP的解析 个人简介 原理和HSRP的差不多,少了一些状态就只有了三种状态 还有不同的就是VRRP严格按照抢占要求 一个VRRP组中具有最高优先级的设备成为Master路由器缺省优先级为100若优先级相同,具有最高接口IP地址最大的路由器成为Master路由器抢占(Pr…...
旅游网站HTML
代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>旅游网</title> </head> <body><!--采用table编辑--> <!--最晚曾table,用于整个页面那布局--><table width&q…...
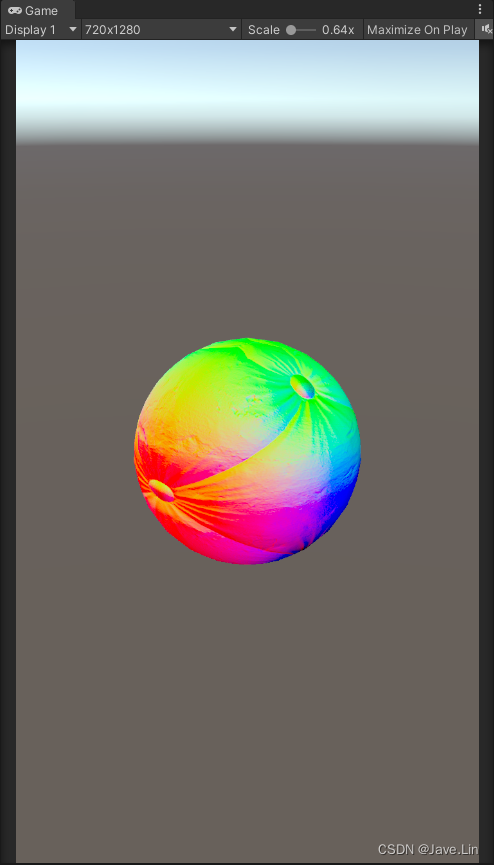
Unity - Normal mapping - Reoriented normal mapping - 重定向法线、混合法线
文章目录 目的核心代码PBR - Filament - Normal mappingShader效果BlendNormal_Hill12BlendNormal_UDNBlendNormals_Unity_Native - 效果目前最好 ProjectReferences 目的 备份、拾遗 核心代码 half3 blended_normal normalize(half3(n1.xy n2.xy, n1.z*n2.z));PBR - Filam…...

CSS 常用样式background背景属性
一、背景颜色 background-color CSS中的background-color是用来设置HTML元素的背景颜色的一个属性。它可以接受各种颜色值,包括具有名称的颜色和十六进制颜色值。 以下是一些示例代码: 设置元素的背景颜色为红色: background-color: red…...
Java开发利器,让你事半功倍!
Java是一种广泛使用的编程语言,它具有跨平台、面向对象、安全性高等特点,因此在企业级应用开发中得到了广泛的应用。在Java开发过程中,选择合适的开发工具可以大大提高工作效率,本文将为大家介绍几款Java开发利器,帮助…...

Redis面临的挑战
Redis的数据结构丰富,一般不会在功能性上造成困扰。但随着请求量的增加,SLA要求的提高,我们势必会对Redis进行一些改造和定制性开发。 高可用挑战 Redis提供了主从、哨兵、cluster等三种集群模式,其中cluster模式为目前大多数公…...

10月12日
3个按键中断 key_it.h #ifndef __KEY_IT_H__ #define __KEY_IT_H__ #include "stm32mp1xx_rcc.h" #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_exti.h" #include "stm32mp1xx_gic.h" void key_it_config(); void led_init()…...
)
Windows 下 Qt 可执行程序添加默认管理员权限启动(QMAKE、MinGW MSVC)
记录 Qt/QMAKE 为可执行程序添加管理员权限 MSVC Windows下 MSVC 套件地位超然,只需要在 .pro 文件中加入: QMAKE_LFLAGS /MANIFESTUAC:\"level\requireAdministrator\ uiAccess\false\\"重新构建 MinGW 与MSVC相比,MinGW所需…...

深度思考面试常考sql题
1 推荐工具 在线运行SQL 2 阿里一面 3 百度一面 sql题 学生表student(id,name) 课程表course(id,name) 学生课程表student_course(sid,cid,score) CREATE TABLE student (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL ); CREATE TABLE course (id INT AU…...

使用springboot服务端远程调试? 试试HTTP实现服务监听
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《初阶数据结构》《C语言进阶篇》 ⛺️生活的理想,就是为了理想的生活! 文章目录 前言1. 本地环境搭建1.1 环境参数1.2 搭建springboot服务项目 2. 内网穿透2.1 安装配置cpolar内网穿透2.1.1 wi…...

CSS图文悬停翻转效果完整源码附注释
实现效果截图 HTML页面源码 <!DOCTYPE html> <html><head><meta http-equiv="content-type...
MQTT C库下载
方法一、从Eclipse paho下载 https://eclipse.dev/paho/index.php?pagedownloads.php 方法二,从MQTT官网下载 https://mqtt.org/software/ https://os.mbed.com/teams/mqtt/code/MQTTPacket/ MQTTPacket源码和paho下载的差不多 方法三、从Keil5 包管理工具…...
android U广播详解(一)
概念介绍 进程队列 BroadcastQueueModernImpl 的设计围绕着为设备上的每个潜在进程维护一个单独的 BroadcastProcessQueue 实例。表明用于传送到特定进程的Pending {link BroadcastRecord} 条目队列。整个类都标记为 {code NotThreadSafe},因为调用者有责任始终与…...

input标签的23种type类型
一、概述 随着html5的出现,input标签新增了多种类型,用以接收各种类型的用户输入。其中传统输入控件有10种,新增输入控件有13种。 二、传统类型 传统输入控件有10种,如下所示。 text 定义单行文本输入框 password 定…...
分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测
分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测 目录 分类预测 | MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输入分类预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于RF-Adaboost随机森林结合AdaBoost多输…...
解决echarts配置滚动(dataZoom)后导出图片数据不全问题
先展现一个echarts,并配置dataZoom,每页最多10条数据,超出滚动 <div class"echartsBox" id"echartsBox"></div>onMounted(() > {nextTick(() > {var chartDom document.getElementById(echartsBox);…...
【vue3+ts】项目初始化
1、winr呼出cmd,输入构建命令 //用vite构建 npm init vitelatest//用cli脚手架构建 npm init vurlatest2、设置vscode插件 搜索volar,安装前面两个 如果安装了vue2的插件vetur,要禁用掉,否则插件会冲突...

c++视觉图像----扩充边界
图像扩充边界 #include <opencv2/opencv.hpp> #include <opencv2/highgui/highgui.hpp>int main() {// 读取图像cv::Mat image cv::imread("1.jpg", cv::IMREAD_COLOR);if (image.empty()) {std::cerr << "Could not open or find the imag…...
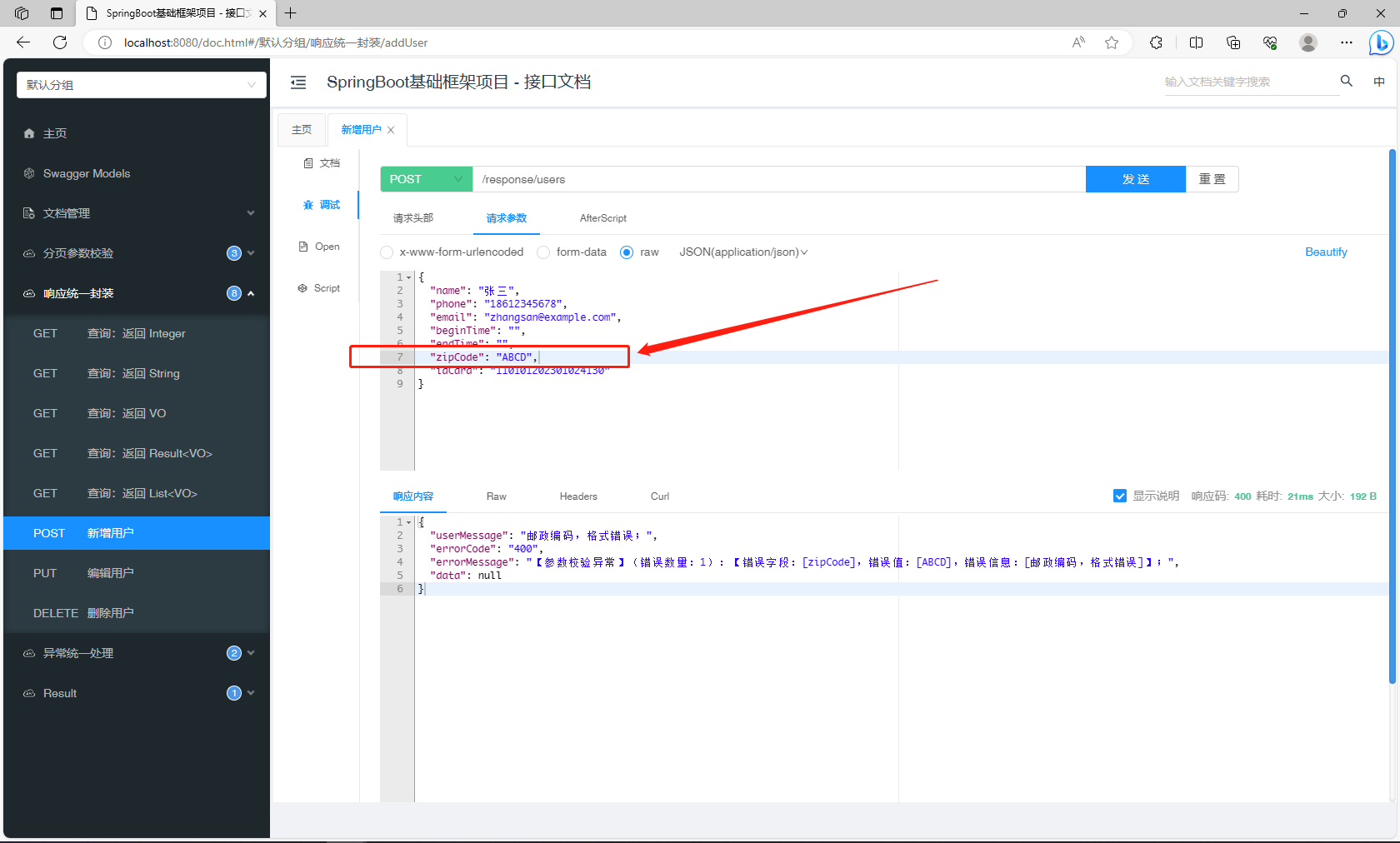
邮政编码,格式校验:@ZipCode(自定义注解)
目标 自定义一个用于校验邮政编码格式的注解ZipCode,能够和现有的 Validation 兼容,使用方式和其他校验注解保持一致(使用 Valid 注解接口参数)。 校验逻辑 有效格式 不能包含空格;应为6位数字; 不校验…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...
搞定Linux视频编解码缓冲区)
别再为嵌入式设备大内存发愁了!手把手教你用CMA(连续内存分配器)搞定Linux视频编解码缓冲区
嵌入式多媒体开发中的连续内存优化实战:CMA技术深度解析 在嵌入式多媒体开发领域,视频编解码、图像处理等任务对内存管理提出了严苛要求。当你在树莓派上部署视频监控系统,或在工业摄像头中实现实时H.264编码时,是否经常遇到这样的…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...

Claude模型思维链评估框架claweval:原理、实战与高级定制指南
1. 项目概述:一个专为Claude模型设计的“思维链”评估框架最近在AI应用开发圈里,一个名为claweval的项目开始被频繁提及。如果你正在使用Anthropic的Claude系列模型(无论是Claude 3 Opus、Sonnet还是Haiku)来构建需要复杂推理能力…...

三维重建下半场,拼的全是底层基建实力!
三维重建已从算法创新竞赛正式迈入基础设施比拼新阶段,主流技术路线逐步收敛,单纯算法红利见顶,行业竞争核心转向数据、算力、平台、生态等底层综合能力。当下竞争不再只比模型效果,而是聚焦四大核心基建维度:采集传感…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...