Flink学习笔记(二):Flink内存模型
文章目录
- 1、配置总内存
- 2、JobManager 内存模型
- 3、TaskManager 内存模型
- 4、WebUI 展示内存
- 5、Flink On YARN 模式下内存分配
- 6、Flink On Yarn 集群消耗资源估算
- 6.1、资源分配
- 6.2、Flink 提交 Yarn 集群的相关命令
- 6.3、Flink On Yarn 集群的资源计算公式
1、配置总内存
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。详细的配置参数:https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/deployment/config.html

配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:
| 配置项 | TaskManager 配置参数 | JobManager 配置参数 |
|---|---|---|
| Flink 总内存 | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 进程总内存 | taskmanager.memory.process.size | jobmanager.memory.process.size |
Flink 启动需要明确配置:
| TaskManager | JobManager |
|---|---|
| taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| taskmanager.memory.process.size | jobmanager.memory.process.size |
| taskmanager.memory.task.heap.size 和 taskmanager.memory.managed.size | jobmanager.memory.heap.size |
不建议同时设置进程总内存和 Flink 总内存。 这可能会造成内存配置冲突,从而导致部署失败。 额外配置其他内存部分时,同样需要注意可能产生的配置冲突。

2、JobManager 内存模型
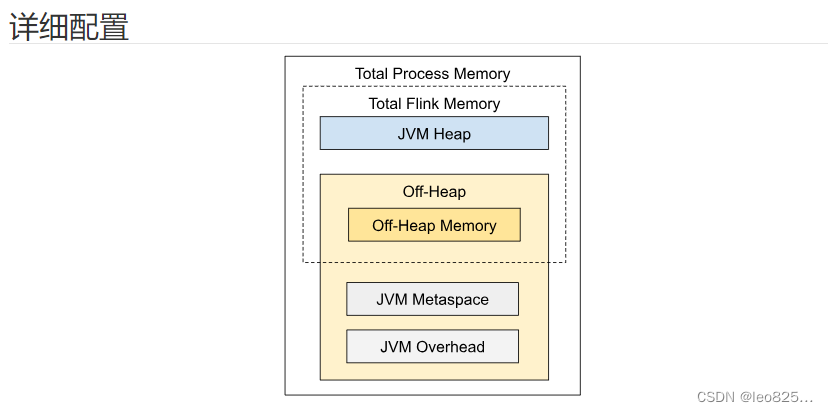
如上图所示,下表中列出了 Flink JobManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存)。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | jobmanager.memory.jvm-overhead.min、jobmanager.memory.jvm-overhead.max、jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
如配置总内存中所述,另一种配置 JobManager 内存的方式是明确指定 JVM 堆内存的大小(jobmanager.memory.heap.size)。 通过这种方式,用户可以更好地掌控用于以下用途的 JVM 堆内存大小。
3、TaskManager 内存模型
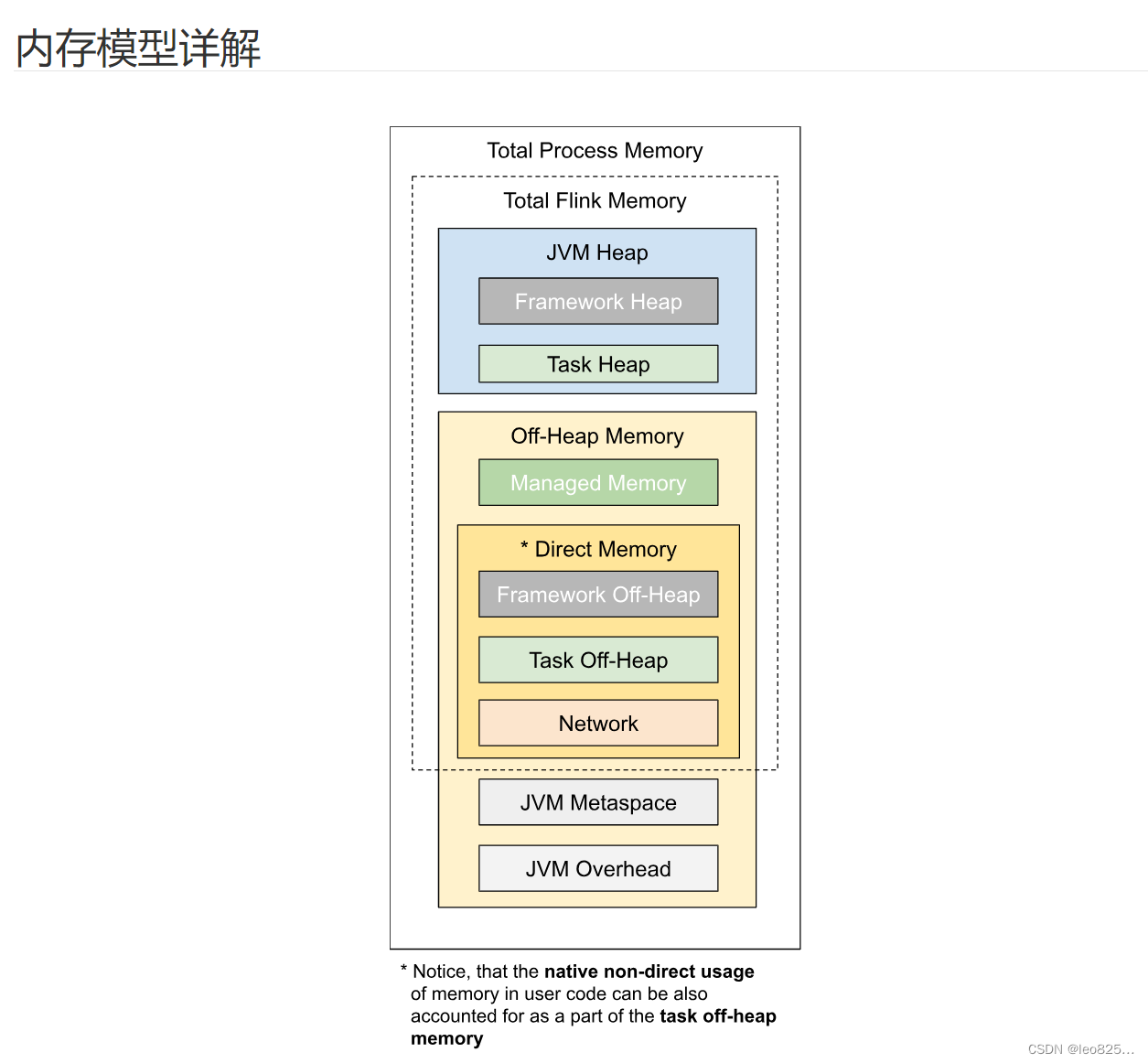
如上图所示,下表中列出了 Flink TaskManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存(进阶配置)。 |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存。 |
| 托管内存(Managed memory) | taskmanager.memory.managed.size、taskmanager.memory.managed.fraction | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 |
| 网络内存(Network Memory) | taskmanager.memory.network.min、taskmanager.memory.network.max、taskmanager.memory.network.fraction | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | taskmanager.memory.jvm-overhead.min、taskmanager.memory.jvm-overhead.max、taskmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。通常情况下,不建议对框架堆内存和框架堆外内存进行调整。 除非你非常肯定 Flink 的内部数据结构及操作需要更多的内存。 这可能与具体的部署环境及作业结构有关,例如非常高的并发度。 此外,Flink 的部分依赖(例如 Hadoop)在某些特定的情况下也可能会需要更多的直接内存或本地内存。
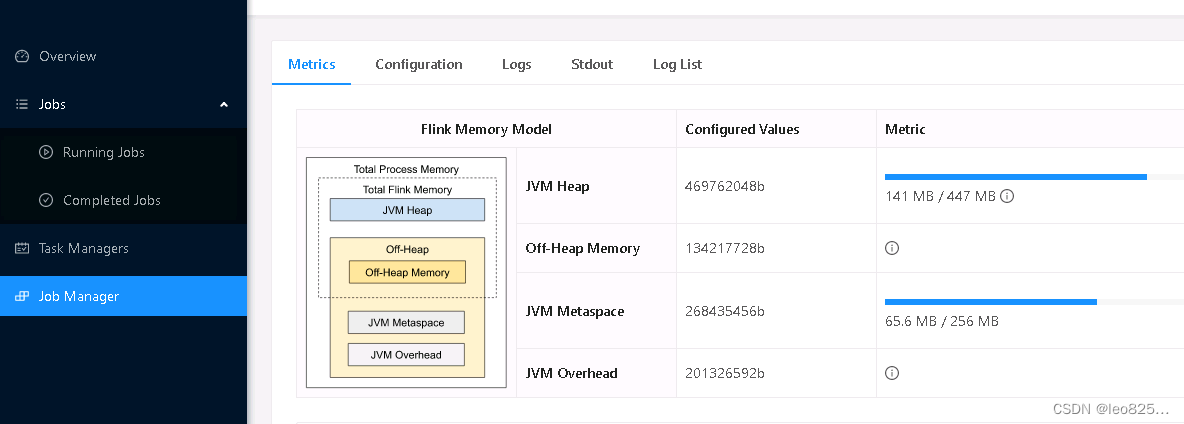
4、WebUI 展示内存
JobManager 内存直观展示
TaskManager 内存直观展示
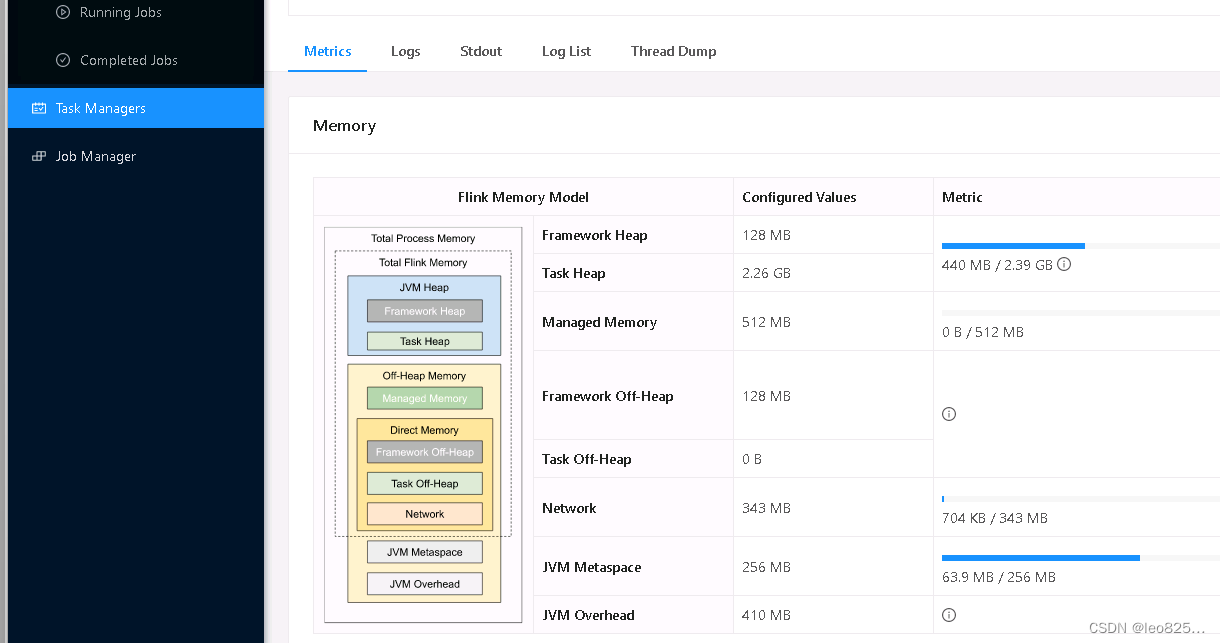
树状图表示:
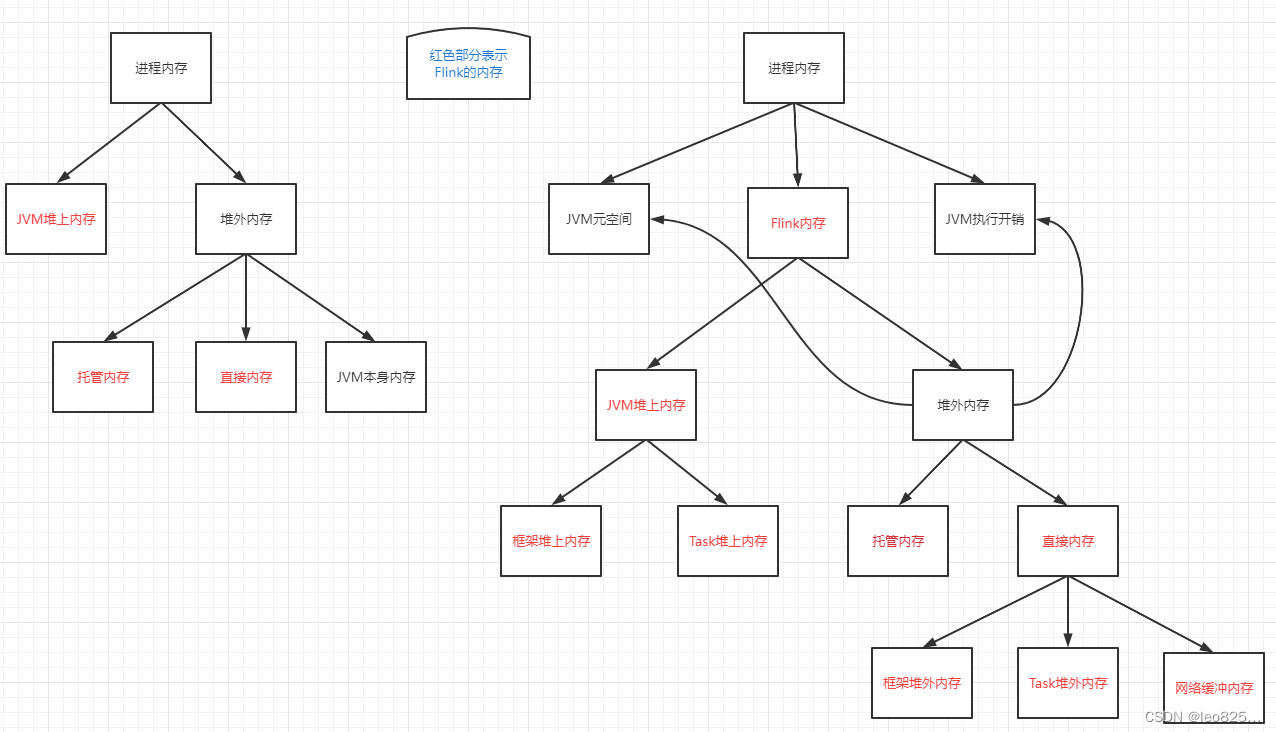
5、Flink On YARN 模式下内存分配
如果是 Flink On YARN 模式下:
taskmanager.memory.process.size = 4096 MB = 4G
taskmanager.memory.network.fraction = 0.15
taskmanager.memory.managed.fraction = 0.45
然后根据以上参数,就可以计算得到各部分的内存大小:
taskmanager.memory.jvm-overhead = 4096 * 0.1 = 409.6 MB
taskmanager.memory.flink.size = 4096 - 409.6 - 256 = 3430.4 MB
taskmanager.memory.network = 3430.4 * 0.15 = 514.56 MB
taskmanager.memory.managed = 3430.4 * 0.45 = 1543.68 MB
taskmanager.memory.task.heap.size = 3430.4 - 128 * 2 - 1543.68 - 514.56 = 1116.16 MB

6、Flink On Yarn 集群消耗资源估算
6.1、资源分配
- 每一个 Flink Application 都包含 至少一个 JobManager (若 HA 配置则可包含多个 JobManagers)。若有多个 JobManagers ,则 有且仅有一个 JobManager 处于 Running 状态,其他的 JobManager 则处于 Standby 状态;
- 每一个处于 Running 状态的 JobManager 管理着 一个或多个 TaskManager。TaskManager 的本质是一个 JVM 进程,可以执行一个或多个线程。TaskManager 可以用于对 Memory 进行隔离;
- 每一个 TaskManager 可以执行 一个或多个 Slot。Slot 的本质是由 JVM 进程所生成的线程。每个 Slot 可以将 TaskManager 管理的的 Total Memory 进行平均分配,但不会对 CPU 进行隔离。在同一个 TaskManager 中的 Slots 共享 TCP 连接 (through multiplexing) 、心跳信息、数据集和数据结构;
- 每一个 Slot 内部可以执行 零个或一个 Pipeline。 每一个 Pipeline 中又可以包含 任意数量的 有前后关联关系的 Tasks。注意一个 Flink Cluster 所能达到的最大并行度数量等于所有 TaskManager 中全部 Slot 的数量的总和。
6.2、Flink 提交 Yarn 集群的相关命令
在使用 Yarn 作为集群资源管理器时,时常会使用如下命令对 Flink Application 进行提交,主要参数如下:
flink run -m yarn-cluster -ys 2 -p 1 -yjm 1G -ytm 2G
| 参数 | 解释 | 说明 |
|---|---|---|
| -yjm,–yarnjobManagerMemory | Memory for JobManager Container with optional unit (default: MB) | JobManager 内存容量 (在一个 Flink Application 中处于 Running 状态的 JobManager 只有一个) |
| -ytm,–yarntaskManagerMemory | Memory per TaskManager Container with optional unit (default: MB) | 每一个 TaskManager 的内存容量 |
| -ys,–yarnslots | Number of slots per TaskManager | 每一个 TaskManager 中的 Slot 数量 |
| -p,–parallelism | The parallelism with which to run the program. Optional flag to override the default value specified in the configuration. | 任务执行的并行度 |
该命令的各个参数表示的含义如下 (使用 flink --help 命令即可阅读)。
Flink 启动参考配置参数(带有 kerberos 认证可根据实际情况需要删减):
/home/dev/soft/flink/bin/flink run \-m yarn-cluster \-yD akka.ask.timeout='360 s' \-yD akka.framesize=20485760b \-yD blob.fetch.backlog=1000 \-yD blob.fetch.num-concurrent=500 \-yD blob.fetch.retries=50 \-yD blob.storage.directory=/data1/flinkdir \-yD env.java.opts.jobmanager='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=300 -XX:InitiatingHeapOccupancyPercent=50 -XX:+ExplicitGCInvokesConcurrent -XX:+AlwaysPreTouch -XX:AutoBoxCacheMax=20000 -XX:G1HeapWastePercent=5 -XX:G1ReservePercent=25 -Dfile.encoding=UTF-8' \-yD env.java.opts.taskmanager='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=1024m -XX:+UseG1GC -XX:MaxGCPauseMillis=300 -XX:InitiatingHeapOccupancyPercent=50 -XX:+ExplicitGCInvokesConcurrent -XX:+AlwaysPreTouch -XX:AutoBoxCacheMax=20000 -Dsun.security.krb5.debug=false -Dfile.encoding=UTF-8' \-yD env.java.opts='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=1024m -Dfile.encoding=UTF-8' \-yD execution.attached=false \-yD execution.buffer-timeout='1000 ms' \-yD execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \-yD execution.checkpointing.interval='30 min' \-yD execution.checkpointing.max-concurrent-checkpoints=1 \-yD execution.checkpointing.min-pause='2 min' \-yD execution.checkpointing.mode=EXACTLY_ONCE \-yD execution.checkpointing.timeout='28 min' \-yD execution.checkpointing.tolerable-failed-checkpoints=8 \-yD execution.checkpointing.unaligned=true \-yD execution.checkpointing.unaligned.forced=true \-yD heartbeat.interval=60000 \-yD heartbeat.rpc-failure-threshold=5 \-yD heartbeat.timeout=340000 \-yD io.tmp.dirs=/data1/flinkdir \-yD jobmanager.heap.size=1024m \-yD jobmanager.memory.jvm-metaspace.size=268435456b \-yD jobmanager.memory.jvm-overhead.max=1073741824b \-yD jobmanager.memory.jvm-overhead.min=1073741824b \-yD jobmanager.memory.network.fraction=0.2 \-yD jobmanager.memory.network.max=6GB \-yD jobmanager.memory.off-heap.size=134217728b \-yD jobmanager.memory.process.size='18360 mb' \-yD metrics.reporter.promgateway.deleteOnShutdown=true \-yD metrics.reporter.promgateway.factory.class=org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporterFactory \-yD metrics.reporter.promgateway.filter.includes=\*:dqc\*,uptime,taskSlotsTotal,numRegisteredTaskManagers,taskSlotsAvailable,numberOfFailedCheckpoints,numRestarts,lastCheckpointDuration,Used,Max,Total,Count,Time:gauge,meter,counter,histogram \-yD metrics.reporter.promgateway.groupingKey="yarn=${yarn};hdfs=${hdfs};job_name=TEST-broadcast-${jobName//./-}-${provId}" \-yD metrics.reporter.promgateway.host=172.17.xxxx.xxxx \-yD metrics.reporter.promgateway.interval='60 SECONDS' \-yD metrics.reporter.promgateway.jobName="TEST-broadcast-${jobName//./-}-${provId}" \-yD metrics.reporter.promgateway.port=10080 \-yD metrics.reporter.promgateway.randomJobNameSuffix=true \-yD pipeline.name="TEST-broadcast-${jobName//./-}-${provId}" \-yD pipeline.object-reuse=true \-yD rest.flamegraph.enabled=true \-yD rest.server.numThreads=20 \-yD restart-strategy.failure-rate.delay='60 s' \-yD restart-strategy.failure-rate.failure-rate-interval='3 min' \-yD restart-strategy.failure-rate.max-failures-per-interval=3 \-yD restart-strategy=failure-rate \-yD security.kerberos.krb5-conf.path=/home/dev/kerberos/krb5.conf \-yD security.kerberos.login.contexts=Client,KafkaClient \-yD security.kerberos.login.keytab=/home/dev/kerberos/xxxx.keytab \-yD security.kerberos.login.principal=xxxx \-yD security.kerberos.login.use-ticket-cache=false \-yD state.backend.async=true \-yD state.backend=hashmap \-yD state.checkpoints.dir=hdfs://xxxx/flink/checkpoint/${jobName//.//}/$provId \-yD state.checkpoint-storage=filesystem \-yD state.checkpoints.num-retained=3 \-yD state.savepoints.dir=hdfs://xxxx/flink/savepoint/${jobName//.//}/$provId \-yD table.exec.hive.fallback-mapred-writer=false \-yD task.manager.memory.segment-size=4mb \-yD taskmanager.memory.framework.off-heap.size=1GB \-yD taskmanager.memory.managed.fraction=0.2 \-yD taskmanager.memory.network.fraction=0.075 \-yD taskmanager.memory.network.max=16GB \-yD taskmanager.memory.process.size='50 gb' \-yD taskmanager.network.netty.client.connectTimeoutSec=600 \-yD taskmanager.network.request-backoff.max=120000 \-yD taskmanager.network.retries=100 \-yD taskmanager.numberOfTaskSlots=10 \-yD web.timeout=900000 \-yD web.upload.dir=/data1/flinkdir \-yD yarn.application.name="TEST-broadcast-${jobName//./-}-${provId}" \-yD yarn.application.queue=$yarnQueue \-yD yarn.application-attempts=10 \
6.3、Flink On Yarn 集群的资源计算公式
-
JobManager 的内存计算
JobManager 的数量 = 1 (固定,由于一个 Flink Application 只能有一个 JobManager)
JobManager 的内存总量 = 1 * JobManager 的内存大小 = 1 * yjm -
TaskManager 的内存计算
TaskManager 的数量 = (设置的并行度总数 / 每个 TaskManager 的 Slot 数量) = (p / ys) (Ps: p / ys 有可能为非整数,故需要向下取整)
TaskManager 的内存总量 = TaskManager 的数量 * 每个 TaskManager 的内存容量 = TaskManager 的数量 * ytm -
Slot 所占用的内存计算
每个 Slot 的内存容量 = 每个 TaskManager 的内存容量 / 每一个 TaskManager 中的 Slot 数量 = ytm / ys
Slot 的总数量 = 最大并行度数量 = p
Slot 所占用的总内存容量 = TaskManager 的内存总量 = (p / ys) * ytm -
yarn vcore 总数量计算
yarn vcore 总数量 = Slot 的总数量 + JobManager 占用的 vcore 数量 (与 Yarn 的 minimum Allocation 有关) = p + m (不足则取 Yarn 的最小 vcore 分配数量) -
yarn container 的总数量计算
yarn container 的总数量 = TaskManager 的数量 + JobManager 的数量 = 1 + (p / ys) = (p / ys) + 1
yarn 的内存总量 = JobManager 的数量 * yjm (与 Yarn 的 minimum Allocation 有关) + TaskManager 的数量 * ytm = 1 * yjm (不足则取 Yarn 的最小 Memory 分配数量) + (p / ys) * ytm
Ps: 根据实际应用经验,一般 Yarn 的一个 vcore 搭配 2G 内存是最为有效率的配置方法。
实战应用:
flink-conf.yaml 配置项:
# Total size of the JobManager (JobMaster / ResourceManager / Dispatcher) process.
jobmanager.memory.process.size: 2048m
# Total size of the TaskManager process.
taskmanager.memory.process.size: 20480m
# Managed Memory size for TaskExecutors. This is the size of off-heap memory managed by the memory manager, reserved for sorting, hash tables, caching of intermediate results and RocksDB state backend. Memory consumers can either allocate memory from the memory manager in the form of MemorySegments, or reserve bytes from the memory manager and keep their memory usage within that boundary. If unspecified, it will be derived to make up the configured fraction of the Total Flink Memory.
taskmanager.memory.managed.size: 4096m
# The number of parallel operator or user function instances that a single TaskManager can run. If this value is larger than 1, a single TaskManager takes multiple instances of a function or operator. That way, the TaskManager can utilize multiple CPU cores, but at the same time, the available memory is divided between the different operator or function instances. This value is typically proportional to the number of physical CPU cores that the TaskManager's machine has (e.g., equal to the number of cores, or half the number of cores).
taskmanager.numberOfTaskSlots: 10
Yarn 集群相关配置项:
Minimum Allocation <memory:4096, vCores:2>
Maximum Allocation <memory:163840, vCores:96>
假设 Flink 流任务在 FlinkSQL 中设置的并行度为 10 (parallelism = 10)。根据计算公式:
JobManager 的数量 = 1
TaskManager 的数量 = (p / ys) = 1 (注:ys 配置是 taskmanager.numberOfTaskSlots = 10)
Slot 的总数量 = p = 10
yarn vcore 的总数量 = Slot 的总数量 + 1 = p + 1 = p + 2 (向上取至 Yarn 最小分配 vcore 数) = 12
yarn container 的总数量 = TaskManager 的数量 + JobManager 的数量 = 2
yarn 的内存总量 = JobManager 的数量 * yjm + TaskManager 的数量 * ytm = 1 * 2048m + 1 * 20480m = 1 * 4096m (向上取至 Yarn 最小分配内存数) + 1 * 20480m = 24576m
相关文章:
Flink学习笔记(二):Flink内存模型
文章目录 1、配置总内存2、JobManager 内存模型3、TaskManager 内存模型4、WebUI 展示内存5、Flink On YARN 模式下内存分配6、Flink On Yarn 集群消耗资源估算6.1、资源分配6.2、Flink 提交 Yarn 集群的相关命令6.3、Flink On Yarn 集群的资源计算公式 1、配置总内存 Flink J…...
信息系统项目管理师第四版学习笔记——项目绩效域
干系人绩效域 干系人绩效域涉及与干系人相关的活动和职能。在项目整个生命周期过程中,有效执行本绩效域可以实现的预期目标主要包含:①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度…...

PyTorch 深度学习之加载数据集Dataset and DataLoader(七)
1. Revision: Manual data feed 全部Batch:计算速度,性能有问题 1 个 :跨越鞍点 mini-Batch:均衡速度与性能 2. Terminology: Epoch, Batch-Size, Iteration DataLoader: batch_size2, sheffleTrue 3. How to define your Dataset 两种处…...

小谈设计模式(26)—中介者模式
小谈设计模式(26)—中介者模式 专栏介绍专栏地址专栏介绍 中介者模式分析角色分析抽象中介者(Mediator)具体中介者(ConcreteMediator)抽象同事类(Colleague)具体同事类(C…...

7种设计模式
1. 工厂模式 优点:封装了对象的创建过程,降低了耦合性,提供了灵活性和可扩展性。 缺点:增加了代码的复杂性,需要创建工厂类。 适用场景:当需要根据不同条件创建不同对象时,或者需要隐藏对象创建…...
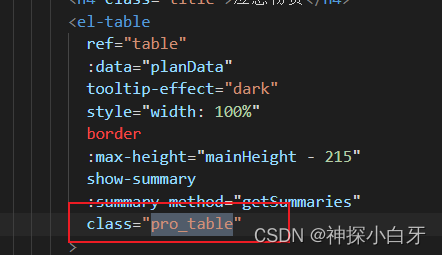
el-table合计行合并
效果如下 因为合计el-table的合并方法是不生效的,所以需要修改css下手 watch: {// 应急物资的合计合并planData: {immediate: true,handler() {setTimeout(() > {const tds document.querySelectorAll(".pro_table .el-table__footer-wrapper tr>td");tds[0]…...

新手如何快速上手HTTP爬虫IP?
对于刚接触HTTP爬虫IP的新手来说,可能会感到有些困惑。但是,实际上HTTP爬虫IP并不复杂,只要掌握了基本的操作步骤,就可以轻松使用。本文将为新手们提供一个快速上手HTTP爬虫IP的入门指南,帮助您迅速了解HTTP爬虫IP的基…...
(十五)VBA常用基础知识:正则表达式的使用
vba正则表达式的说明 项目说明Pattern在这里写正则表达式,例:[\d]{2,4}IgnoreCase大小写区分,默认false:区分;true:不区分Globaltrue:全体检索;false:最小匹配Test类似p…...

vue配置@路径
第一步:安装path,如果node_module文件夹中有path就不用安装了 安装命令:npm install path --save 第二步:在vue.config.js文件(如果没有就新建)中配置 const path require("path"); function …...
Ubuntu 18.04 OpenCV3.4.5 + OpenCV3.4.5 Contrib 编译
目录 1 依赖安装 2 下载opencv3.4.5及opencv3.4.5 contrib版本 3 编译opencv3.4.5 opencv3.4.5_contrib及遇到的问题 1 依赖安装 首先安装编译工具CMake,命令安装即可: sudo apt install cmake 安装Eigen: sudo apt-get install libeigen3-…...

【网络基础】IP 子网划分(VLSM)
目录 一、 为什么要划分子网 二、如何划分子网 1、划分两个子网 2、划分多个子网 一、 为什么要划分子网 假设有一个B类IP地址172.16.0.0,B类IP的默认子网掩码是 255.255.0.0,那么该网段内IP的变化范围为 172.16.0.0 ~ 172.16.255.255,即…...

【OCR】合同上批量贴印章
一、需求 OCR算法在处理合同等文件时,会由于印章等遮挡导致文本误识别。因此在OCR预处理时,有一个很重要的步骤是“去除印章”。其中本文主要聚焦在“去除印章”任务中的数据构建步骤:“合同伪印章”的数据构建。下面直接放几张批量合成后效果…...

Stable diffusion 用DeOldify给黑白照片、视频上色
老照片常常因为当时的技术限制而只有黑白版本。然而现代的 AI 技术,如 DeOldify,可以让这些照片重现色彩。 本教程将详细介绍如何使用 DeOldify 来给老照片上色。. 之前介绍过基于虚拟环境的 基于DeOldify的给黑白照片、视频上色,本次介绍对于新手比较友好的在Stable diff…...

在服务器上解压.7z文件
1. 更新apt sudo apt-get update2. 安装p7zip sudo apt-get install p7zip-full3. 解压.7z文件 7za x WN18RR.7z...

【opencv】windows10下opencv4.8.0-cuda C++版本源码编译教程
【opencv】windows10下opencv4.8.0-cuda C版本源码编译教程 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【opencv】windows10下opencv4.8.0-cuda C版本源码编译教程前言准备工具cuda/cudnncmakeopencv4.8.0opencv_contrib CMake编译VS2019编…...
软碟通制作启动盘
一、下载并安装软碟通 二、插入U盘,打开软碟通; 三、在软碟通中选择“文件”-“打开镜像文件”,选择要制作成启动盘的ISO镜像文件; 1.打开要制作的iso文件 选择对应的iso文件 四、在软碟通中选择“启动”-“写入硬盘”ÿ…...
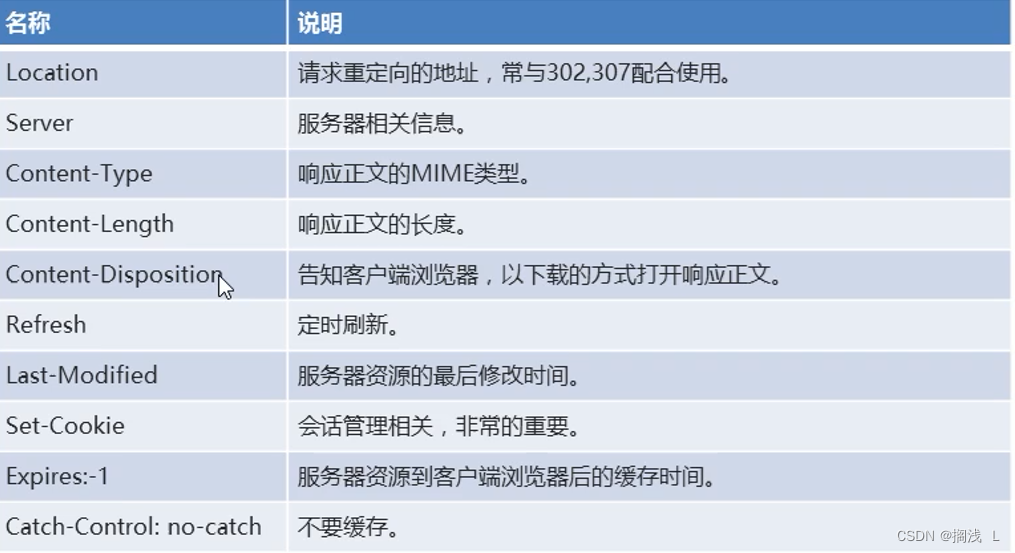
Tomcat和HPPT协议
1.介绍 1.Java EE 规范 JavaEE(java Enterprise Edition):java企业版 JavaEE 规范是很多的java开发技术的总称。这些技术规范都是沿用自J2EE的。一共包括了13个技术规范 2.WEB概述 WEB在计算机领域中代表的是网络 像我们之前所用的WWW&…...
)
Acwing.4736步行者(模拟)
题目 约翰参加了一场步行比赛。 比赛为期 N 天,参赛者共 M 人(包括约翰)。 参赛者编号为 1∼M,其中约翰的编号为 P。 每个参赛者的每日步数都将被赛事方记录并公布。 每日步数最多的参赛者是当日的日冠军(可以有并…...
前端预览、下载二进制文件流(png、pdf)
前端请求设置 responseType: “blob” 后台接口返回的文件流如下: 拿到后端返回的文件流后: 预览 <iframe :src"previewUrl" frameborder"0" style"width: 500px; height: 500px;"></iframe>1、预览 v…...
:ESD干扰耦合路径深入分析(一))
搞定ESD(三):ESD干扰耦合路径深入分析(一)
文章目录 一、外部测试环境引发的电场耦合1.1 静电枪枪体的电场耦合1.2 垂直耦合板与水平耦合板的电场耦合二、静电电流泄放路径中的电场耦合2.1 金属平面与敏感信号之间的电场耦合2.2 参考平面与敏感信号布线之间的电场耦合2.3 芯片散热片电场耦合分析2.3.1 散热片静电耦合机理…...

3步解锁Godot游戏黑盒:PCK资源解包实战指南
3步解锁Godot游戏黑盒:PCK资源解包实战指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 还在为Godot游戏的神秘资源包而困惑吗?面对那些看似不可访问的.pck文件࿰…...

终极碧蓝航线自动化脚本:Alas智能辅助工具完整指南
终极碧蓝航线自动化脚本:Alas智能辅助工具完整指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript AzurLaneAuto…...

三个00后给母校捐了“20亿”,全网炸了——结果这20亿可能就值几百块?
整件事最魔幻的地方在于:你第一眼看到“20亿”,脑子里自动补上的单位是“人民币”。然后一算账,发现可能连捐的那个展示牌都不如。这事到底是怎么回事?前几天,郑州西亚斯学院搞了一场挺隆重的捐赠仪式。三个00后校友—…...

3分钟上手ncmdumpGUI:网易云音乐NCM文件轻松转换的完整指南
3分钟上手ncmdumpGUI:网易云音乐NCM文件轻松转换的完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM格式文件无法在其…...

碧蓝航线自动化助手:3小时解放你的游戏时间
碧蓝航线自动化助手:3小时解放你的游戏时间 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝航线中重复…...

Sora 2生成帧精度达99.7%的LUT匹配方案,DaVinci色彩科学全链路对齐指南
更多请点击: https://kaifayun.com 第一章:Sora 2与DaVinci整合的底层逻辑与技术共识 Sora 2 作为新一代视频生成基础模型,其核心能力建立在时空联合建模与长程依赖捕获之上;DaVinci 则是面向专业影视工作流的高性能非线性编辑与…...
)
K3s离线安装保姆级避坑指南:从镜像准备到集群验证(含Harbor私有仓库配置)
K3s离线安装全流程实战:从私有仓库搭建到集群高可用 在金融、军工、政务等对网络安全要求极高的领域,离线环境部署Kubernetes集群已成为刚需。作为轻量级Kubernetes发行版,K3s凭借其小于50MB的二进制体积和内置组件简化设计,成为隔…...

CANN/asc-devkit float2到half2向上取整转换函数
__float22half2_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitc…...

如何构建高效的Azure事件驱动架构:Go SDK Messaging模块的实时消息处理指南 [特殊字符]
如何构建高效的Azure事件驱动架构:Go SDK Messaging模块的实时消息处理指南 🚀 【免费下载链接】azure-sdk-for-go This repository is for active development of the Azure SDK for Go. For consumers of the SDK we recommend visiting our public de…...

终极性能释放指南:3步解锁暗影精灵完整潜力,告别臃肿官方软件
终极性能释放指南:3步解锁暗影精灵完整潜力,告别臃肿官方软件 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Ome…...