运维大数据平台的建设与实践探索
随着企业数字化转型的推进,运维管理面临着前所未有的挑战和机遇。为应对日益复杂且严峻的挑战,数字免疫系统和智能运维等概念应运而生。数字免疫系统和智能运维作为新兴技术,正引领着运维管理的新趋势。数字免疫系统和智能运维都借助大数据运维平台,实现数据驱动的运维策略,实时监控分析系统状态,自动识别异常行为、威胁和攻击,提供智能决策和预防性维护建议,实现自我保护和自我修复等,从根本上提高了系统安全性、稳定性和可用性。本文主要探讨运维大数据平台的建设和实践方法,旨在帮助组织构建数字免疫系统,实现智能化运维。
**数字免疫(Digital Immune System):**未来充满了不确定性,但企业仍然需要明确的推进战略目标和举措。Gartner 在最新的重要战略技术趋势中提出了“数字免疫系统”(如图1所示)的概念。“数字免疫系统”的概念最早是在上世纪90年代的时候被提出,当时指的是一套完全自动化的防病毒解决方案。但是今天的“数字免疫系统”指的是一套用来构建稳定系统的软件设计、开发、运营和分析的一系列技术和实践。数字免疫系统保护应用程序和服务,使它们更具弹性和健壮性,以便从故障中能快速恢复,降低连续性风险。Gartner 预计,到 2025 年,投资构建数字免疫力的组织将通过减少 80% 的停机时间来提高客户满意度。
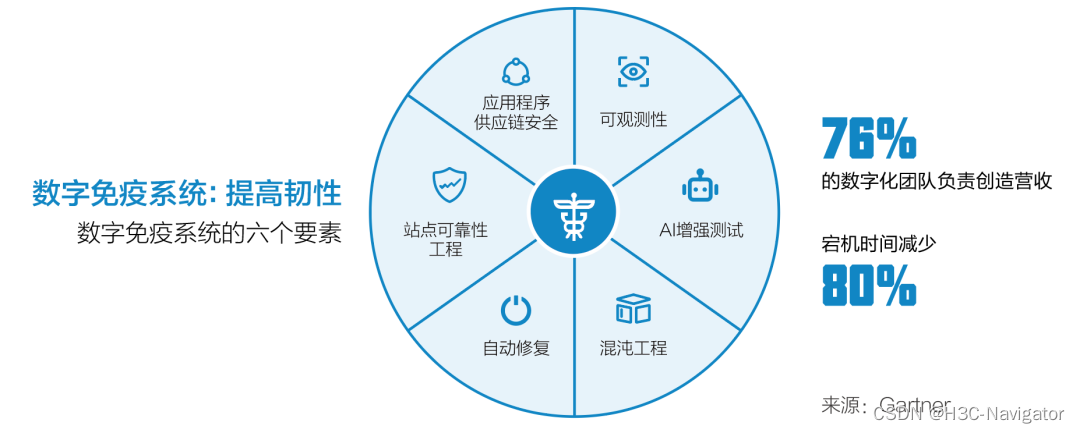
图1:数字免疫系统
**智能运维(AIOps):**智能运维(如图2所示)是基于人工智能和大数据等高级分析技术,采用机器学习和数据科学来解决IT运维领域问题的应用,实现运维管理的自动化、智能化。智能运维通过对系统中产生的大量可观测性数据进行建模和分析,识别出系统中的问题点并进行响应,提高运维的效率和准确性,提高系统的稳定性和可靠性。
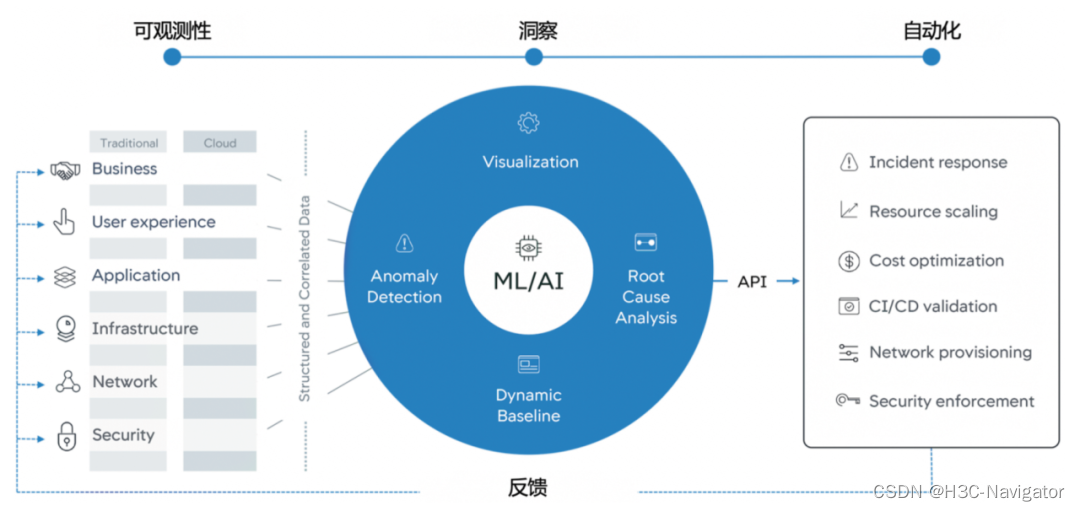
图2:智能运维
数字免疫系统与智能运维是寻求系统稳定性和故障恢复能力的两个关键要素,有着密切的关系(如图3所示),共同致力于减缓故障、保障应用程序和服务的连续性,并确保遇到问题时实现快速恢复。二者的结合在构建和维护高效、稳定并具有自愈能力的系统方面发挥着重要作用。数字免疫系统作为智能运维的核心组件之一,有助于建立自动化、实时且富有反应力的运维策略。数字免疫系统强调的是软件设计的鲁棒性、弹性和恢复能力,而智能运维通过人工智能、大数据分析及场景感知等技术手段来提高整个 IT 系统的管理效率和运行水平。
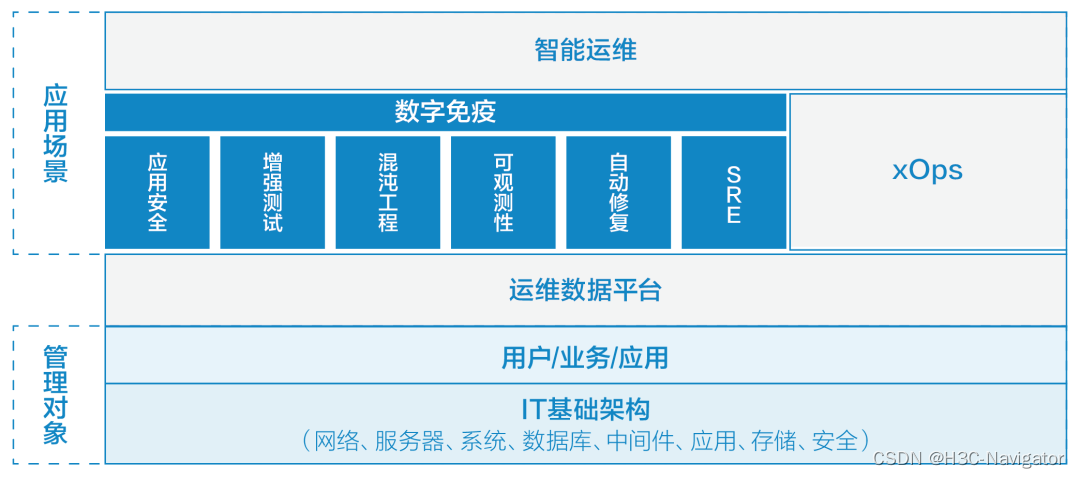
图3:数字免疫和智能运维的关系
数字免疫系统和智能运维都依赖于运维大数据平台和数据分析,通过收集和分析大量运行数据,我们能更好地掌握系统状况,可以对潜在的安全威胁和运维问题做出快速、准确的预测和响应,并提炼出最佳实践,不断完善数字免疫系统和运维策略,提高系统稳定性和安全性。接下来,我们将深入分析各场景和运维数据平台之间的关系。
SRE
它的核心思路是通过引入软件工程的方法和思维模式,实现对系统运行过程的优化和预测故障。在运维大数据平台中,这意味着我们需要收集关键业务指标(如:延迟、错误率、吞吐量等)的数据,并通过分析这些数据,找出潜在风险和故障的根源。可以说,大数据分析能力是SRE实现运维自动化和高效解决问题的基础。
混沌工程
这是一种通过主动注入故障,模拟系统失效来提高系统抵抗力的实践。运维大数据平台可以实时监控模拟实验的结果,分析故障注入对系统性能的影响。通过这些数据,开发者和运维团队能更好地了解系统的弱点和容错能力,并提出相应的优化措施。
AI增强测试
利用人工智能技术对软件进行测试,从而提高测试覆盖率和准确性。运维大数据平台可以为AI测试提供海量的数据来源,以便AI能更好地理解系统行为和正常的性能水平,并从中发现潜在的风险。数据分析结果还可为AI训练模型提供指导,实现测试效果的持续优化。
可观测性
是理解系统内部状态和性能的关键因素。运维大数据平台通过汇总日志、指标、追踪等多种数据源,提供了一种全面的系统状态视角。这样,团队就能发现异常行为、确定故障原因,从而快速响应和解决问题。
自动修复
是指在检测到故障后,自动触发相应的修复措施。运维大数据平台可以实时监测系统状态,当检测到异常或故障时,自动触发相应的预案或修复策略。通过对大量数据进行历史分析,运维团队还能持续优化自动修复的策略,以降低系统故障对业务的影响。
应用程序供应链安全
关注整个软件开发、部署、运维过程中的安全性。运维大数据平台可以从多个维度(如:代码、环境、配置等)收集数据,实时监测潜在的安全风险。通过大数据分析,我们能够更及时、更准确地识别并修复潜在威胁,保证整个应用程序供应链的安全性。
智能运维
智能运维概念提出后,行业对运维内涵的理解也在发生变化,运维的边界由服务于IT拓展到服务于业务,运维的定位也由成本中心转向服务中心,智能运维演进的过程,更是IT运维向运营演进的过程。过去的运维是小数据,每一个运维模块都是一个数据孤岛,仅能满足传统运维的使用场景。而发展至今我们所关注的“新运维”,需要基于完整的大数据、AI算法来提供全栈式运维,面向泛运维甚至涵盖非运维的场景。
通过以上分析来看,不管是数字免疫场景还是智能运维场景都需要全面的可观测性数据,需要智能运维大数据平台来实现数据的拉通、整合和赋能,实现跨领域的协同,实现复杂系统中高效、稳定、安全运维。
智能运维大数据平台(如图4所示)是一个集数据收集、存储、处理、分析、可视化、数据服务和应用于一体的一站式平台,用于支持数据中心系统的可观测性、数字免疫和智能运维需求。运维大数据平台可以帮助企业有效地管理海量的运维数据,洞察系统运行状况,发现潜在问题,为运维团队提供有价值的洞察和建议。
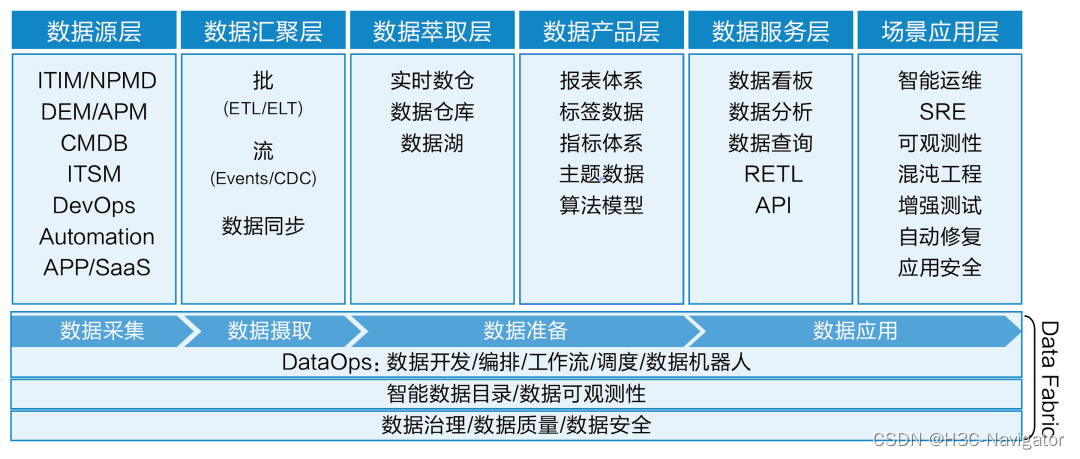
图4:智能运维大数据平台
运维领域不缺乏数据,但普遍缺乏对如何提取数据、整合数据并以可操作的方式使用数据的理解。现代智能运维大数据平台需要一种全新的、囊括所有形式的数据架构,能解决运维数据多样性、分散性、规模和复杂性不断增加带来的一系列问题。Data Fabric和DataOps是数据管理和数据操作的两个关键概念。Data Fabric可以被描述为一个数据整合和管理平台,它可以帮助企业自动化管理和操作数据,结合了数据目录、数据治理、数据集成、数据管道和数据编排等关键的数据管理技术,进而形成高效可靠的数据资产化体系和数据服务化能力。而DataOps是一种数据操作方法论,其目标是能够让数据开发更敏捷、高效。
数据源层及采集技术
运维领域的数据源层包含了各种系统、网络、应用的监控数据以及日志数据,对不同层次的各种数据进行采集与分析可以为系统维护、故障排查、性能优化和运营管理等方面提供重要参考依据。数据源的可靠性和实时性对运维决策影响极大,因此需要充分考虑数据源的选择、采集方式、协议、标准等方面的因素,确保数据的准确性和及时性。数据采集技术有很多种,例如代理收集器、日志转发器、SDK等。代理收集器通常部署在需要收集数据的主机上。这些代理会定期收集指标数据并发送给数据存储。其中可观测性数据采集技术是问题的关键。可观测数据的三大分类包括日志(记录)、指标(度量)和跟踪(请求调用链)。
• 日志(Log): 系统和应用运行产生的记录,包含事件、事务和出错信息。常用的日志收集工具有Logstash、Fluentd等。
• 指标(Metrics): 衡量系统及其各组件的性能、容量、状态等关键性能指标。常用指标收集工具包括Prometheus、Zabbix等。
• 链路追踪(Tracing): 跟踪请求在分布式系统中的调用情况,帮助诊断性能问题。典型的链路追踪工具如Skywalking、Jaeger等。
数据汇聚层及数据摄取技术
数据汇聚层指收集、预处理和存储来自不同数据源的数据,以便进一步处理和分析。主要通过以下几种数据摄取技术来实现:
**• 批量摄取(Batch Ingestion)😗*用于定时按批次导入数据,适用于数据量较大且不要求实时处理的场景。常用工具包括Apache Nifi、Sqoop等。
• 实时摄取(Streaming Ingestion): 用于侦听不同数据源生成的事件,并立即进行处理,满足实时分析及快速反应业务需求。典型的实时摄取工具包括Kafka、Apache Flink等。
• 数据同步(Data Synchronization): 实时或定时将源数据同步到目标数据系统。例如,使用Apache Kafka Connect实现数据同步。
数据摄取工具通过不同的连接器、过滤器等插件,可以转换、清洗、归一化和丰富数据,提高数据质量。
数据存储整合及萃取技术
在现代运维数据环境中,我们通常会遇到来自不同来源、结构化和非结构化,离线的和实时的大量数据。为了统一管理这些数据并从中获取有价值的信息,我们需要采用一种高效、灵活的数据存储和处理架构。数据湖、数据仓库和实时数仓是这一架构的关键组成部分,它们共同支撑着数据分级加工、存储、整合和数据萃取的需求。数据湖是一种庞大的数据存储系统,允许将原始数据以任意格式存储起来,是非结构化、半结构化和结构化数据的集合地。数据湖典型解决方案有Hadoop、Hudi等。相比之下,数据仓库则是一种高度结构化的数据存储方式,支持快速查询报表以及多维分析,如何进行数据存储和数据组织,其核心是标准规范的数据仓库和数据模型建设,也就是说数据仓库是实现数据资产化的呈现载体。引入OneData数据萃取技术,确保数据一致性和准确性:
• OneData技术旨在确保企业数据的一致性和准确性。通过对数据定义和标准进行统一管理,消除数据不一致、重复和错误,从而实现对所有数据的单一视图。
• OneModel是通过统一的数据模型进行数据分析和挖掘,以确保结果的可靠性和准确性。这可以通过创建通用的数据模型、指标和维度来实现。
• OneMetric则是通过对关键指标(KPI)和度量(如延迟、吞吐量和错误率等)进行统一定义和度量,以确保业务目标的准确实现。
数据产品层
数据产品层负责将数据内在价值表现为可视化、报表、指标和标签等具体形式,推动数据在组织内的应用和价值提升。运维领域涉及到的数据产品包括运维主题域数据、指标体系、标签体系和可应用的AI模型等。主题域数据指按特定领域或业务场景提炼出的数据子集;指标体系是对数据进行可视化表达的一种方法,使得业务理解和分析更容易;我们可以根据不同的业务场景来定义相应的运维指标,以客观、全面地评估运维水平,以便关注的领域得以持续优化。常见的运维指标包括故障率、系统性能、可用性、恢复时间等。通过这些指标,我们可以获取运维团队的整体表现和风险点,从而提升运维工作的效率和精细化程度;标签体系则是基于属性或行为将用户或对象分类的方法,有助于数据分析和用户画像。一个完善的标签体系可以帮助建立更加科学的数据挖掘和分析模型,满足不同业务场景的需求。
数据服务层及实现技术
数据服务层为各类数据产品提供统一的访问、处理和交互入口。常见的数据服务技术如 RESTful API、GraphQL、WebSockets和RETL等,使得各类应用和服务方便地使用、查询和获取所需数据。通过这些技术,用户可以根据需求自主选择数据、过滤筛选条件,以及个性化数据交互方式。此外,数据服务层也会提供权限管理和数据安全等功能,确保数据高效共享的同时杜绝潜在风险。这些技术允许用户快速、灵活地获取所需数据,支撑数据驱动的决策、运营和产品创新,实现数据价值的最大化。
以数据为中心数据场景化应用
有了标准化的数据体系以后,针对数据进行分析和使用又是需要关心的另一个维度的问题,这也是数据驱动的关键环节,也即以数据为中心进行决策,驱动业务行为。数据驱动型AIOps平台(如图5所示),可利用全栈可观测性仪表板获取价值和洞察力,普及AI和数据在不同运维领域的应用。
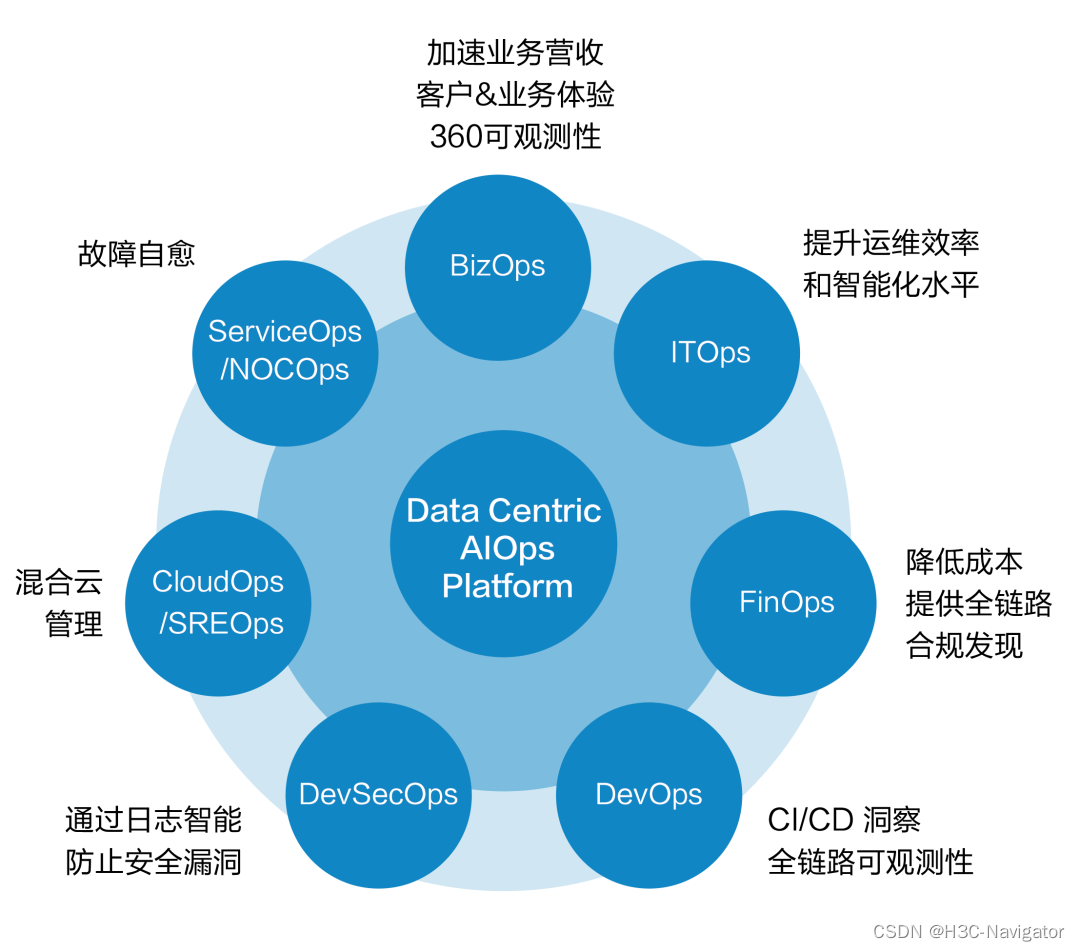
图5:数据驱动型AIOps平台
通过数据平台提供的数据服务API,对相关数据进行多维度、深层次的分析挖掘,支撑业务相关的数据应用场景,持续让数据用起来,真正发挥数据平台的业务价值。下面来看看某头部券商通过数据驱动型AIOps平台来构建智能化事件治理体系(如图6所示)的应用场景案例:
该客户IT中心最显而易见的一大挑战就是运维事件的治理问题,一面是“海量”的告警信息需要处理,一面是故障被动应对,响应处置效率低下,业务部门诟病IT部门支撑不力,影响业务目标。运维告警事件管理的痛点包括:
• 太多告警,告警漏报、误报多,可读性差;95%以上告警缺乏有价值的信息;应用运维人员无法用、用不好、不想用。
• 告警故障发生时没有上下文信息,>45% 故障处置需要涉及多线人员,但缺乏高效精准的告警协同处理体系。
• 缺乏预警机制,故障发现“后知后觉”,>73% 故障由用户首先报告,当故障被发现时,用户体验已经受到极大影响。
• 系统故障根因定位困难主要依靠专家经验或手工分析,排障各自为政,耗时耗力,无法快速判定故障点。
• 太多工单,> 60%工单是垃圾。
该复杂问题的解决之道就在于用数据思维,以数据为中心的运维事件数据治理方案:统一整合各类运维数据,构建事件的治理体系,增强数据质量,将可观察性数据和AI更好地结合在一起,实现告警事件的智能化分析、自动化响应、可视化影响分析及告警溯源,及时准确联动响应人员进行高效协作处置。
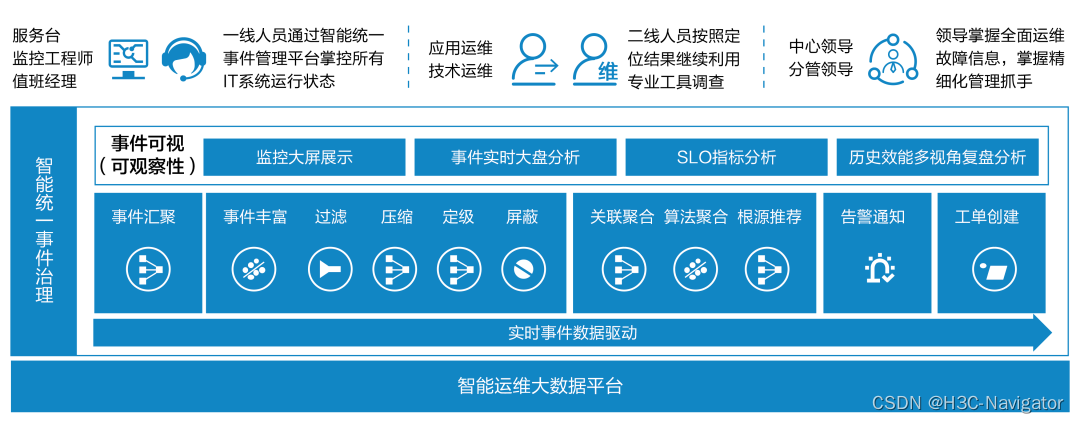
图6: 智能统一事件治理
通过智能统一事件治理服务,每天的告警量降到40个左右,整体压缩率达99.77% (如图7所示),告警的平均响应、有效跟进处理时间缩短75%以上,业务故障的平均恢复时间缩短了80%以上,做到了准确告警、主动运维,有效大幅降低了运维压力。

图7: 智能统一事件治理
结束语
智能数据平台作为智能运维的基石,未来将更紧密地结合在一起,先进的大数据技术和人工智能算法深度融合。运用“数智”思想推动运维工作的发展,依托智能数据平台,以数据场景为驱动,推动企业运维系统的整体升级、高质量发展,引领企业步入智能、高效、绿色的数字化新时代。
相关文章:
运维大数据平台的建设与实践探索
随着企业数字化转型的推进,运维管理面临着前所未有的挑战和机遇。为应对日益复杂且严峻的挑战,数字免疫系统和智能运维等概念应运而生。数字免疫系统和智能运维作为新兴技术,正引领着运维管理的新趋势。数字免疫系统和智能运维都借助大数据运…...

【Java 进阶篇】创建 HTML 注册页面
在这篇博客中,我们将介绍如何创建一个简单的 HTML 注册页面。HTML(Hypertext Markup Language)是一种标记语言,用于构建网页的结构和内容。创建一个注册页面是网页开发的常见任务之一,它允许用户提供个人信息并注册成为…...
【JVM系列】- 启航·JVM概论学习
启航JVM概论 😄生命不息,写作不止 🔥 继续踏上学习之路,学之分享笔记 👊 总有一天我也能像各位大佬一样 🏆 博客首页 怒放吧德德 To记录领地 🌝分享学习心得,欢迎指正,…...

Windows技巧
Windows应用 Windows应用无限延长Windows10 自动更新时间管理员身份打开cmd输入以下代码设置暂停更新时间 Windows应用 无限延长Windows10 自动更新时间 管理员身份打开cmd 输入以下代码 这里设置的是3000天,需要恢复更新可以将其设置为1天 reg add “HKEY_LOCA…...

Git 应用小记
常用命令 git reset 3种模式 --soft:将HEAD引用指向给定提交,索引(暂存区)和工作目录的内容不变 --mixed(默认,可不写):将HEAD引用指向给定提交,索引(暂存区…...

APT攻击与零日漏洞
APT攻击 当谈到网络安全时,APT(高级持续性威胁)攻击是最为复杂和难以检测的攻击类型之一。APT攻击通常涉及到高度的技术和策略性,而且它们的目标是深入地渗透和长时间地隐藏在目标网络中。 1. 什么是APT攻击? 高级持续…...

leetCode 1143.最长公共子序列 动态规划 + 滚动数组
1143. 最长公共子序列 - 力扣(LeetCode) 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串…...

【C++ Miscellany】继承体系非尾端类设计为抽象类
部分赋值问题 用软件来处理两种动物:蜥蜴和鸡 class Animal { public:Animal& operator (const Animal& rhs);... };class Lizard: public Animal { public:Lizard& operator (const Lizard& rhs);... };class Chicken: public Animal {Chicken…...
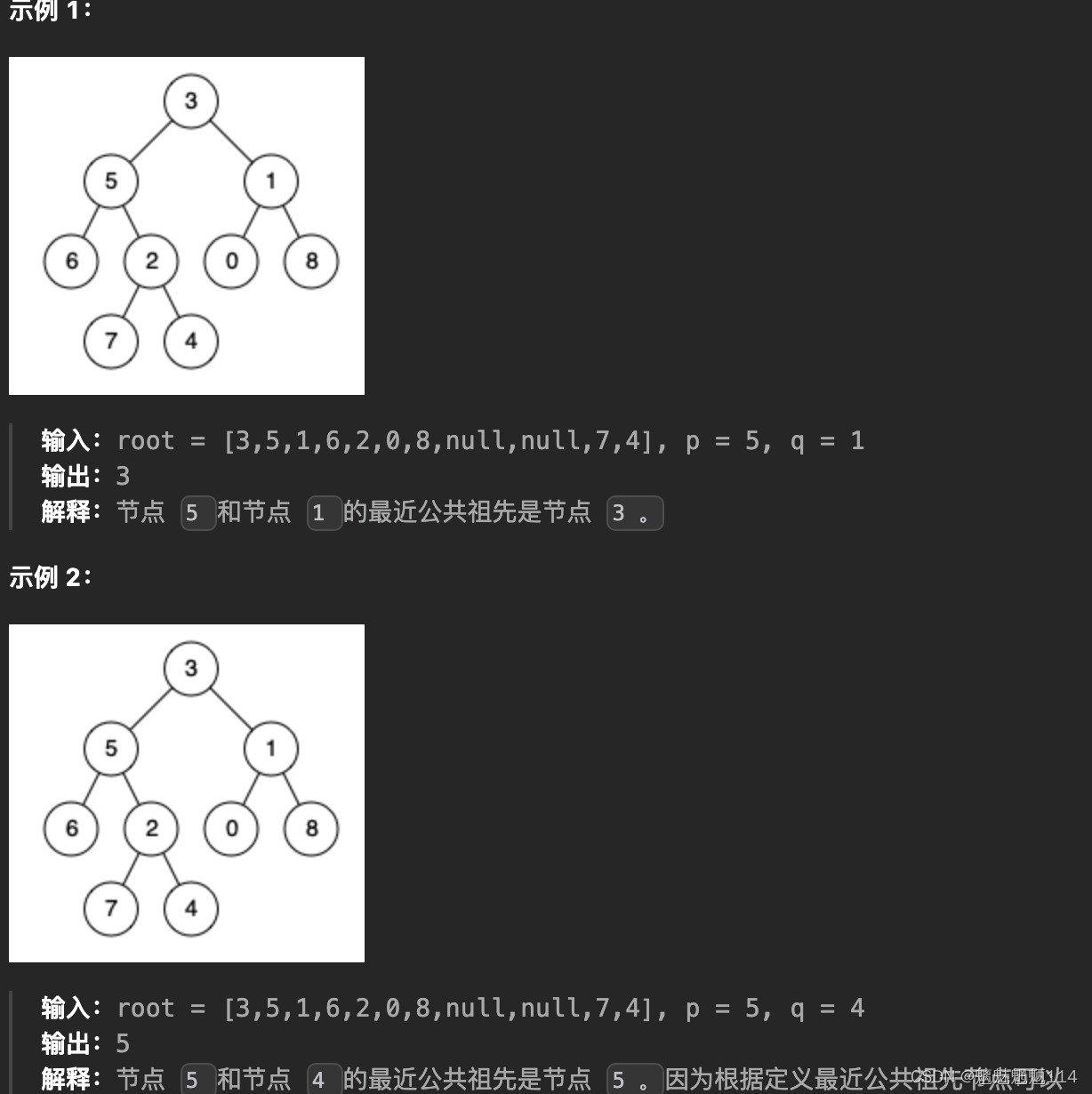
Leetcode236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖…...
Swift SwiftUI CoreData 过滤数据 2
预览 Code import SwiftUI import CoreDatastruct HomeSearchView: View {Environment(\.dismiss) var dismissState private var search_value ""FetchRequest(entity: Bill.entity(),sortDescriptors: [NSSortDescriptor(keyPath: \Bill.c_at, ascending: false)…...
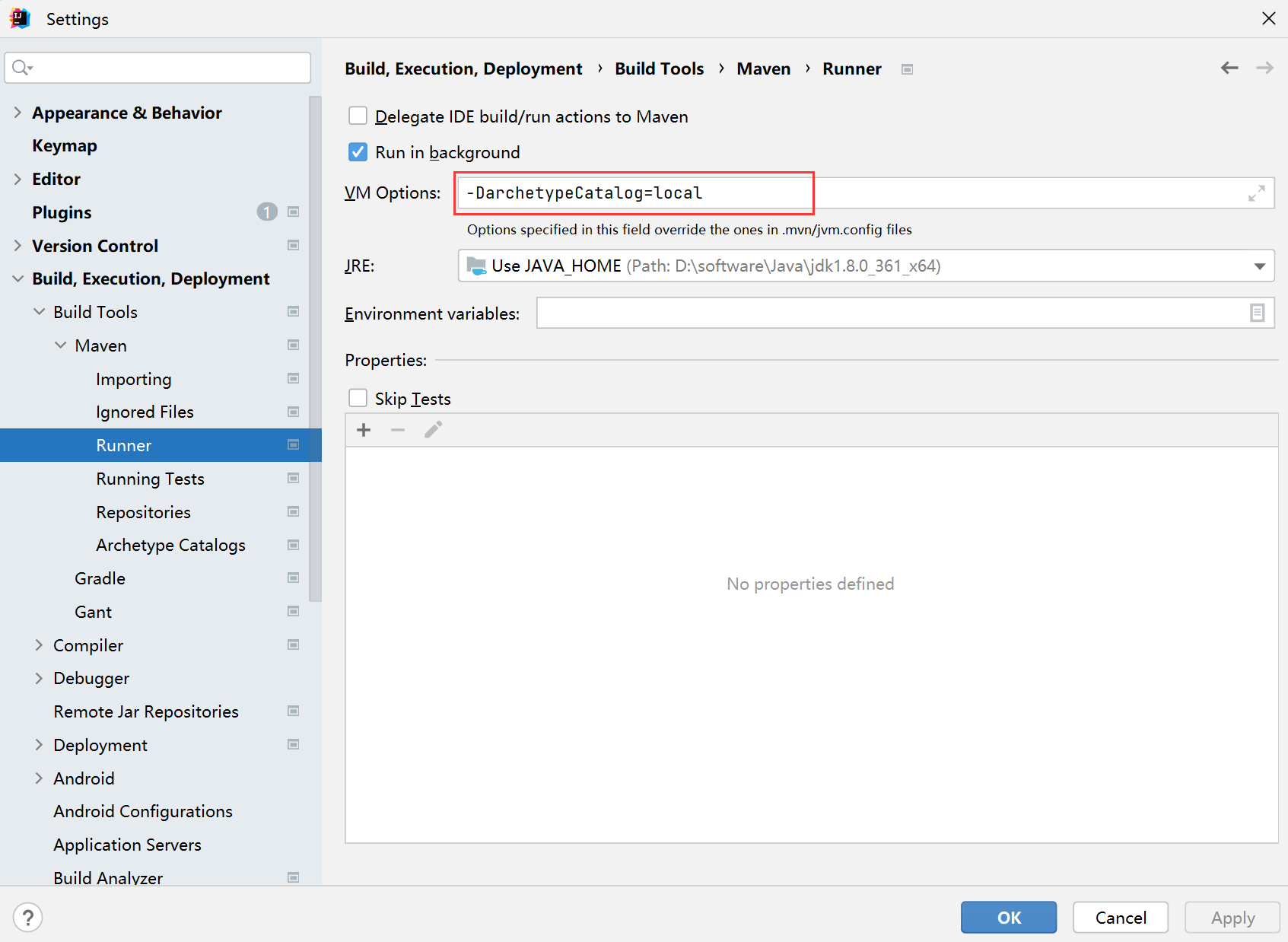
解决maven骨架加载慢问题(亲测解决)
1、下载archetype-catalog.xml 网站 : https://repo.maven.apache.org/maven2/ 2、放在这个文件夹下面 3、setting–>build–>Runner : -DarchetypeCataloglocal...

Android---java内存模型与线程
Java 内存模型翻译自 Java Memory Model,简称 JMM。它所描述的是多线程并发、CPU 缓存等方面的内容。 在每一个线程中,都会有一块内部的工作内存,这块内存保存了主内存共享数据的拷贝副本。但在 Java 线程中并不存在所谓的工作内存࿰…...

23.10.7.sql 里面的DISTINCT
例如: SELECT DISTINCT t.container_no FROM biz_inventory_task_detail t 这里distinct干嘛的 解释: DISTINCT是一个关键字,用于在SELECT语句中返回唯一不重复的值。 在这个查询中,使用DISTINCT关键字,是为了返回biz…...

mysql面试题38:count(1)、count(*) 与 count(列名) 的区别
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官: count(1)、count(*) 与 count(列名) 的区别 当使用COUNT函数进行数据统计时&…...

nodejs+vue+elementui大学生心理健康管理系统
简单的说 Node.js 就是运行在服务端的 JavaScript。 前端技术:nodejsvueelementui 前端:HTML5,CSS3、JavaScript、VUE本大学生心理健康管理系统使用简洁的框架结构,专门用于用户咨询心理专家,系统具有方便性、灵活性、应用性。于是…...
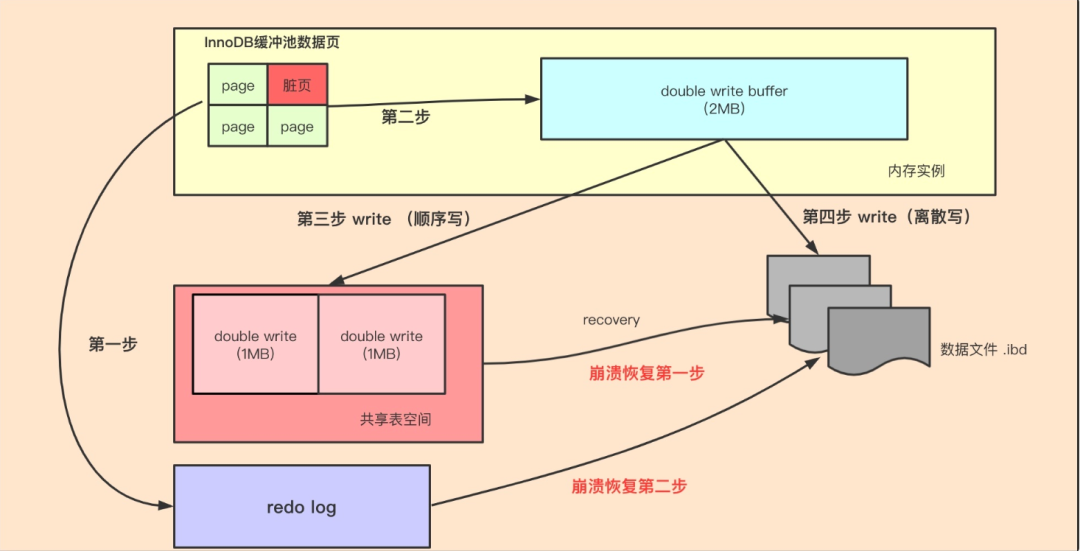
【MySQL】深入解析MySQL双写缓冲区
原创不易,注重版权。转载请注明原作者和原文链接 文章目录 为什么需要Doublewrite BufferDoublewrite Buffer原理Doublewrite Buffer和redo logDoublewrite Buffer相关参数总结 在数据库系统的世界中,保障数据的完整性和稳定性是至关重要的任务。为了实现…...
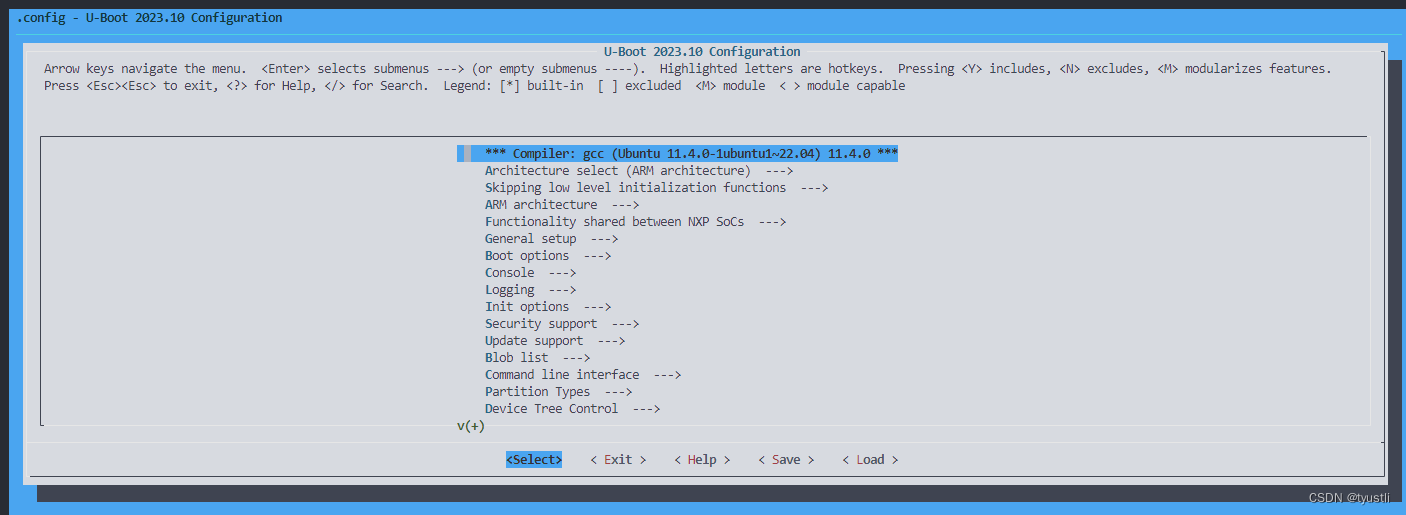
u-boot 编译与运行
文章目录 u-boot 编译与运行环境配置ubuntu 版本qemu 版本u-boot 版本(master)交叉工具链版本 u-boot 源码下载生成配置文件报错情况一报错情况2 u-boot 配置编译编译脚本编译报错解决编译日志编译产物 运行 u-boot 编译与运行 本文主要介绍 u-boot 编译…...

C++QT-day2
#include <bits/stdc.h>/*自己封装一个矩形类(Rect),拥有私有属性:宽度(width)、高度(height),定义公有成员函数:初始化函数:void init(int w, int h)更改宽度的函数:set_w(int w)更改高度的函数:set_h(int h)输出该矩形的周长和面积函数:void sho…...
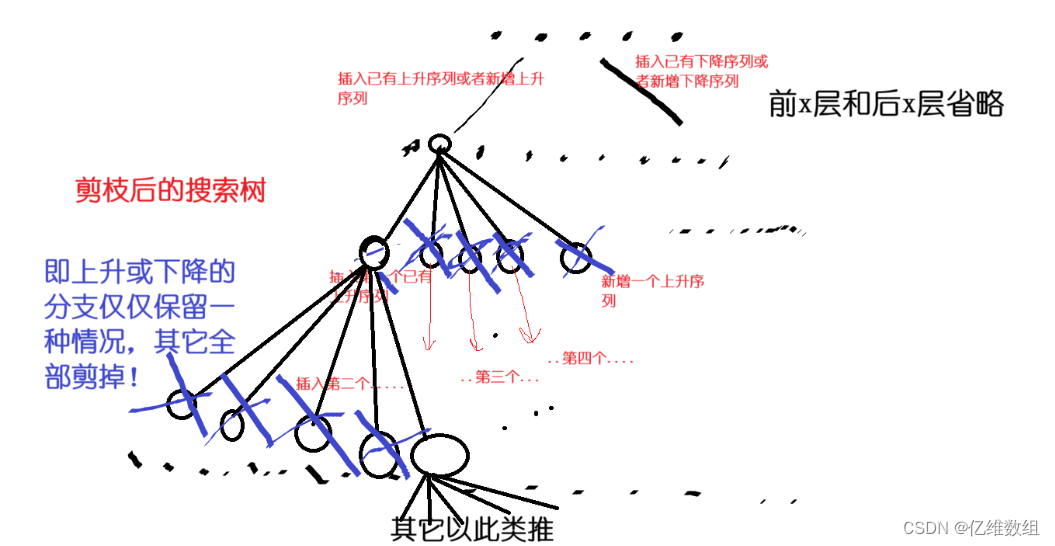
【Acwing187】导弹防御系统(LIS+剪枝+贪心+dfs+迭代加深)
题目描述 看本文需要准备的知识 1.最长上升子序列(lis)的算法思想和算法模板 2.acwing1010拦截导弹(lis贪心)题解 本题题解,需要知道这种贪心算法 3.简单了解dfs暴力搜索、剪枝、搜索树等概念 思路讲解 dfs求最…...
字节大佬带你五分钟掌握接口自动化测试框架
今天,我们来聊聊接口自动化测试是什么?如何开始?接口自动化测试框架怎么做? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发展的趋势。 特别是在…...

N5105 4口2.5g V3 Intel i225 PVE 6.2下的Openclaw安装
一、Ubuntu 26.04安装 1. 从官网上下载ubuntu 26.04 LTS版本 下载地址:Download Ubuntu Desktop | Ubuntu 2. 将下载好的iso文件上传到pve中,登录PVE后台,点击local->ISO镜像->上传 3. 创建虚拟机 其他按默认配置即可。 4. 安装Ubu…...

从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活
从手机信号到CT扫描:一张图看懂电磁波如何改变我们的生活 清晨醒来,你按下智能手机的闹钟关闭按钮,这个简单的动作背后是无线电波在基站与设备间的无声对话;早餐时微波炉加热牛奶的嗡嗡声,本质上是特定频率电磁场对水分…...
)
Qt项目实战:用CryptoPP库给本地配置文件做AES加密(C++保姆级教程)
Qt项目实战:用CryptoPP库实现本地配置文件AES加密(C完整指南) 在桌面应用开发中,配置文件的安全性常常被忽视。想象一下,当用户打开你的应用目录,轻易就能用记事本查看到数据库密码或API密钥——这种赤裸裸…...

港科大沈劭劼、谭平团队最新成果:开源280万全景数据集,实现零样本立体匹配
「一举攻克全景3D视觉两大瓶颈」 目录 01 行业痛点:数据匮乏与畸变失效的双重桎梏 1. 数据集稀缺,泛化能力受限 2. 球面畸变破坏单目先验一致性 02 核心突破:超大数据与航向对齐先验双驱动 1. 280万级合成数据集,打破数据壁…...

终极Windows驱动清理指南:3分钟快速释放C盘隐藏空间
终极Windows驱动清理指南:3分钟快速释放C盘隐藏空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否发现Windows系统越用越慢,C盘空间莫名其妙消失&#x…...
)
别再只会点灯了!用Arduino和WS2812B灯带做个会呼吸的桌面氛围灯(附完整代码)
用Arduino打造会呼吸的WS2812B智能氛围灯系统 你是否已经厌倦了简单的LED闪烁效果?想让你的工作台或游戏空间拥有更高级的光效体验?今天我们将突破基础点灯的局限,用Arduino和WS2812B灯带打造一套具备呼吸效果的智能氛围灯系统。这不仅仅是一…...

给 AI 写一份老厨师的菜谱:从传统文档到 Skill 知识体系
大家好,我是程序员小策。 先跟你讲三个故事—— 故事一: 你点了一份红烧肉,菜谱上写着"五花肉 500g,酱油适量,冰糖少许,小火慢炖"。你照着做了,出来的肉又柴又腥。为什么?…...
)
图吧工具箱下载安装和使用保姆级教程(2026实测)
图吧工具箱全名图拉丁吧硬件检测工具箱,简称 “图吧工具箱”,是国内硬件爱好者社区 “图拉丁吧” 开发维护的免费开源工具合集,2014 年首发,至今持续更新,是 DIY 玩家、装机员、普通用户公认的 “电脑硬件全能管家”。…...

基于哪吒D1与Node-RED的机械臂视觉控制边缘计算方案
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,核心是把一块搭载了全志D1芯片的哪吒开发板,变成一个能同时控制机械臂和拍照的智能边缘节点。这个想法的源头,其实挺实际的:在很多自动化测试、小型分拣或者教育演示的场景里&…...

避坑指南:UE5 GAS技能系统中,角色转向功能的两种实现方案与接口设计思考
UE5 GAS技能系统中角色转向功能的架构设计与实战优化 在动作角色扮演游戏开发中,技能释放时的角色朝向处理往往成为影响战斗体验的关键细节。当火球需要精准飞向目标、剑刃应当准确劈砍敌人时,角色朝向的瞬间调整不仅关乎视觉表现,更直接影响…...