【MySQL】深入解析MySQL双写缓冲区
原创不易,注重版权。转载请注明原作者和原文链接
文章目录
- 为什么需要Doublewrite Buffer
- Doublewrite Buffer原理
- Doublewrite Buffer和redo log
- Doublewrite Buffer相关参数
- 总结
在数据库系统的世界中,保障数据的完整性和稳定性是至关重要的任务。为了实现这一目标,MySQL内部使用了许多精巧而高效的机制。
InnoDB是MySQL中一种常用的事务性存储引擎,它具有很多优秀的特性。其中,Doublewrite Buffer是InnoDB的一个重要特性之一,本文将介绍Doublewrite Buffer的原理和应用,帮助读者深入理解其如何提高MySQL的数据可靠性并防止可能的数据损坏。
为什么需要Doublewrite Buffer
我们常见的服务器一般都是Linux操作系统,Linux文件系统页(OS Page)的大小默认是4KB。而MySQL的页(Page)大小默认是16KB。
可以使用如下命令查看MySQL的Page大小:
SHOW VARIABLES LIKE 'innodb_page_size';
一般情况下,其余程序因为需要跟操作系统交互,所以它们的页(Page)大小都为操作系统页大小的整数倍。比如,Oracle的Page大小为8KB。
MySQL程序是跑在Linux操作系统上的,理所当然要跟操作系统交互,所以MySQL中一页数据刷到磁盘,要写4个文件系统里的页。
如图所示:
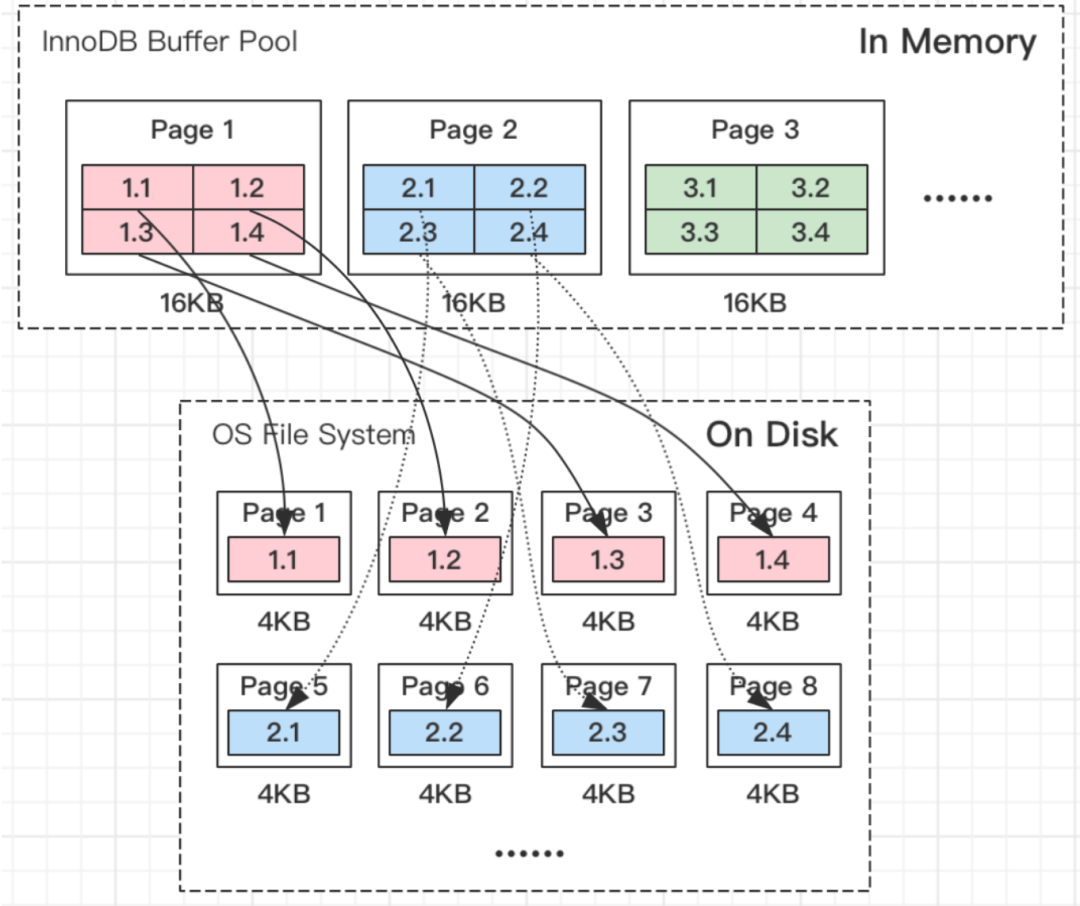
需要注意的是,这个刷页的操作并非原子操作,比如我操作系统写到第二个页的时候,Linux机器断电了,这时候就会出现问题了。造成「页数据损坏」。并且这种页数据损坏靠 redo日志是无法修复的。
redo重做日志中记录的是对页的物理操作,而不是页面的全量记录,当发生「Partial Page Write(部分页写入)」问题时,出现问题的是未修改过的数据,此时redo日志无能为力。
Doublewrite Buffer的出现就是为了解决上面的这种情况,给InnoDB存储引擎提供了数据页的可靠性,虽然名字带了Buffer,但实际上Doublewrite Buffer是「内存+磁盘」的结构。
内存结构:Doublewrite Buffer内存结构由128个页(Page)构成,大小是2MB。
磁盘结构:Doublewrite Buffer磁盘结构在系统表空间上是128个页(2个区,extend1和extend2),大小是2MB。
Doublewrite Buffer的原理是,再把数据页写到数据文件之前,InnoDB先把它们写到一个叫「doublewrite buffer(双写缓冲区)」的共享表空间内,在写doublewrite buffer完成后,InnoDB才会把页写到数据文件适当的位置。
如果在写页的过程中发生意外崩溃,InnoDB会在doublewrite buffer中找到完好的page副本用于恢复。
Doublewrite Buffer原理
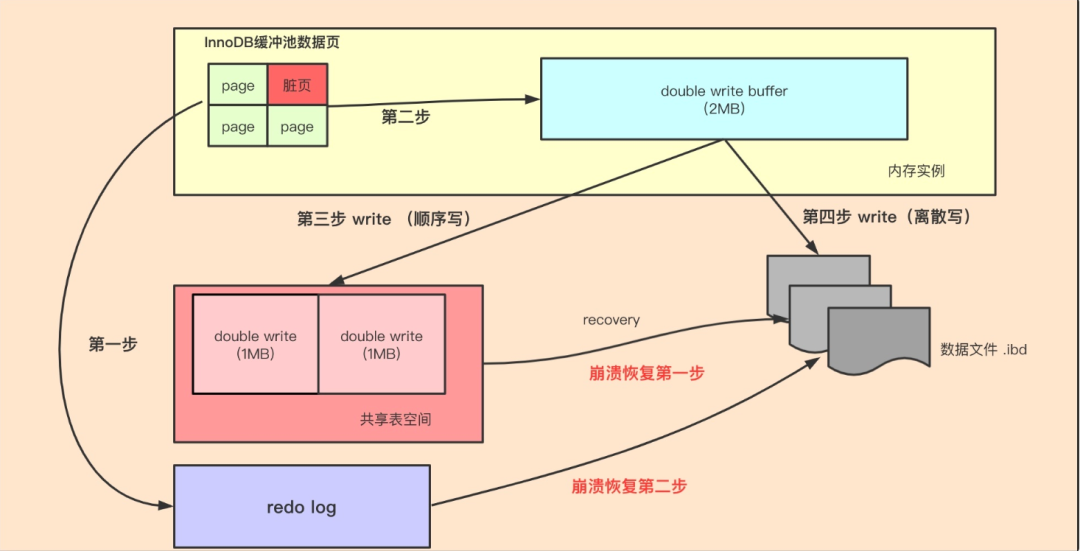
如上图所示,当有数据页要刷盘时:
-
页数据先通过
memcpy函数拷贝至内存中的Doublewrite Buffer中。 -
Doublewrite Buffer的内存里的数据页,会
fsync刷到Doublewrite Buffer的磁盘上,分两次写入磁盘共享表空间中(连续存储,顺序写,性能很高),每次写1MB。 -
Doublewrite Buffer的内存里的数据页,再刷到数据磁盘存储.ibd文件上(离散写)。
如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,InnoDB存储引擎可以从共享表空间中的Double write中找到该页的一个副本,将其复制到表空间文件,再应用redo日志。
所以在正常的情况下,MySQL写数据页时,会写两遍到磁盘上,第一遍是写到doublewrite buffer,第二遍是写到真正的数据文件中,这便是「Doublewrite」的由来。
我们可以通过如下命令来监控Doublewrite Buffer工作负载,该命令用于显示有关双写缓冲区(doublewrite buffer)的统计信息。‘%dblwr%’ 是一个通配符,匹配所有包含 ‘dblwr’ 的状态变量。
show global status like '%dblwr%';
这个命令可能会产生如下格式的输出:
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| Innodb_dblwr_writes | 1000 |
| Innodb_dblwr_pages_written | 8000 |
+------------------------+-------+
Doublewrite Buffer和redo log
在MySQL的InnoDB存储引擎中,Redo log和Doublewrite Buffer共同工作以确保数据的持久性和恢复能力。
- 当有一个DML(如INSERT、UPDATE)操作发生时, InnoDB会首先将这个操作写入redo log(内存)。这些日志被称为未检查点(uncheckpointed)的redo日志。
- 然后,在修改内存中相应的数据页之前,需要将这些更改记录在磁盘上。但是直接把这些修改的页写到其真正的位置可能会因发生故障导致页部分更新,从而导致数据不一致。因此,InnoDB的做法是先将这些修改的页按顺序写入doublewrite buffer。这就是为什么叫做 “doublewrite” —— 数据实际上被写了两次,先在doublewrite buffer,然后在它们真正的位置。
- 一旦这些页被安全地写入doublewrite buffer,它们就可以按原始的顺序写回到文件系统中。即使这个过程在写回数据时发生故障,我们仍然可以从doublewrite buffer中恢复数据。
- 最后,当事务提交时,相关联的redo log会被写入磁盘。这样即使系统崩溃,redo log也可以用来重播(replay)事务并恢复数据库。
在系统恢复期间,InnoDB会检查doublewrite buffer,并尝试从中恢复损坏的数据页。如果doublewrite buffer中的数据是完整的,那么InnoDB就会用doublewrite buffer中的数据来更新损坏的页。否则,如果doublewrite buffer中的数据不完整,InnoDB也有可能丢弃buffer内容,重新执行那条redo log以尝试恢复数据。
所以,Redo log和Doublewrite Buffer的协作可以确保数据的完整性和持久性。如果在写入过程中发生故障,我们可以从doublewrite buffer中恢复数据,并通过redo log来进行事务的重播。
Doublewrite Buffer相关参数
以下是一些与Doublewrite Buffer相关的参数及其含义:
innodb_doublewrite: 这个参数用于启用或禁用双写缓冲区。设置为1时启用,设置为0时禁用, 默认值为1。innodb_doublewrite_files: 这个参数定义了多少个双写文件被使用。默认值为2,有效范围从2到127。innodb_doublewrite_dir: 这个参数指定了存储双写缓冲文件的目录的路径。默认为空字符串,表示将文件存储在数据目录中。innodb_doublewrite_batch_size: 这个参数定义了每次批处理操作写入的字节数。默认值为0,表示InnoDB会选择最佳的批量大小。innodb_doublewrite_pages:这个参数定义了每个双写文件包含多少页面。默认值为128。
总结
Doublewrite Buffer是InnoDB的一个重要特性,用于保证MySQL数据的可靠性和一致性。
它的实现原理是通过将要写入磁盘的数据先写入到Doublewrite Buffer中的内存缓存区域,然后再写入到磁盘的两个不同位置,来避免由于磁盘损坏等因素导致数据丢失或不一致的问题。
总的来说,Doublewrite Buffer对于改善数据库性能和数据完整性起着至关重要的作用。尽管其引入了一些开销,但在大多数情况下,这些成本都被其提供的安全性和可靠性所抵消。
感谢阅读,如果本篇文章有任何错误和建议,欢迎给我留言指正。
相关文章:
【MySQL】深入解析MySQL双写缓冲区
原创不易,注重版权。转载请注明原作者和原文链接 文章目录 为什么需要Doublewrite BufferDoublewrite Buffer原理Doublewrite Buffer和redo logDoublewrite Buffer相关参数总结 在数据库系统的世界中,保障数据的完整性和稳定性是至关重要的任务。为了实现…...
u-boot 编译与运行
文章目录 u-boot 编译与运行环境配置ubuntu 版本qemu 版本u-boot 版本(master)交叉工具链版本 u-boot 源码下载生成配置文件报错情况一报错情况2 u-boot 配置编译编译脚本编译报错解决编译日志编译产物 运行 u-boot 编译与运行 本文主要介绍 u-boot 编译…...

C++QT-day2
#include <bits/stdc.h>/*自己封装一个矩形类(Rect),拥有私有属性:宽度(width)、高度(height),定义公有成员函数:初始化函数:void init(int w, int h)更改宽度的函数:set_w(int w)更改高度的函数:set_h(int h)输出该矩形的周长和面积函数:void sho…...
【Acwing187】导弹防御系统(LIS+剪枝+贪心+dfs+迭代加深)
题目描述 看本文需要准备的知识 1.最长上升子序列(lis)的算法思想和算法模板 2.acwing1010拦截导弹(lis贪心)题解 本题题解,需要知道这种贪心算法 3.简单了解dfs暴力搜索、剪枝、搜索树等概念 思路讲解 dfs求最…...
字节大佬带你五分钟掌握接口自动化测试框架
今天,我们来聊聊接口自动化测试是什么?如何开始?接口自动化测试框架怎么做? 自动化测试 自动化测试,这几年行业内的热词,也是测试人员进阶的必备技能,更是软件测试未来发展的趋势。 特别是在…...
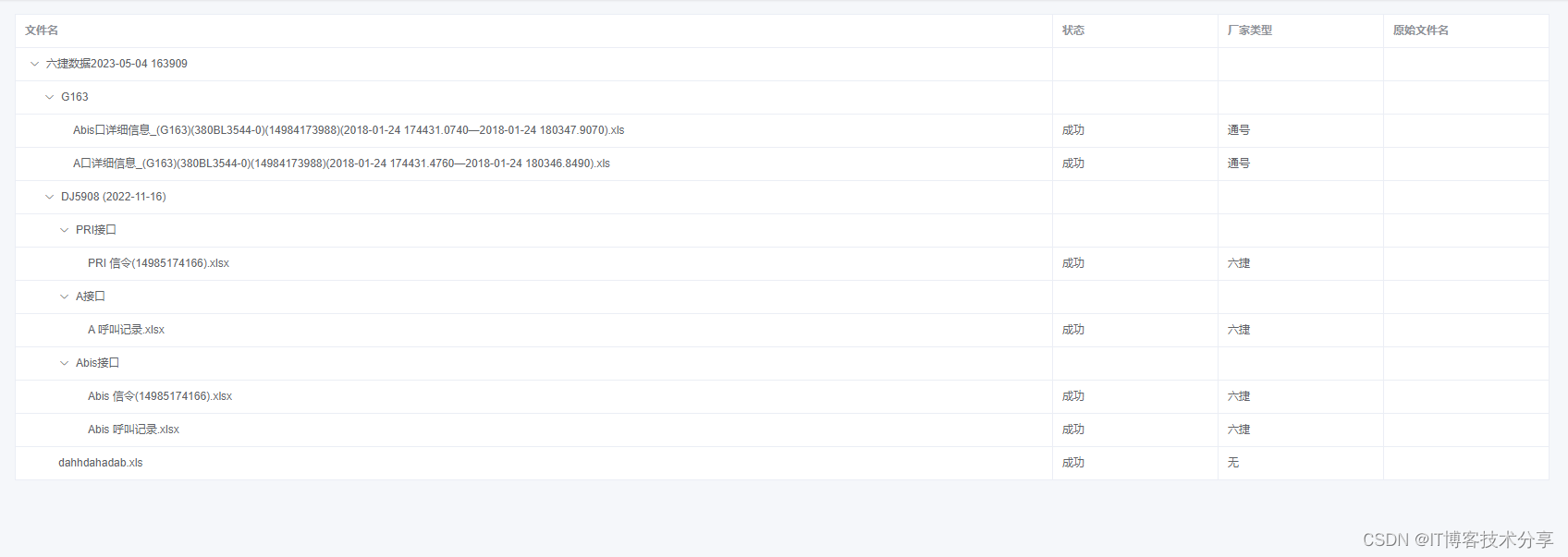
上传文件夹里面的文件后,按树结构的table表格展示
1. 先处理最简单的 原始数据大概是这样: let fileArr [{progress: 100,status: 成功,type: 通号,webkitRelativePath: "六捷数据2023-05-04 163909/G163/Abis口详细信息_(G163)(380BL3544-0)(14984173988)(2018-01-24 174431.0740—2018-01-24 180347.9070).xls"…...
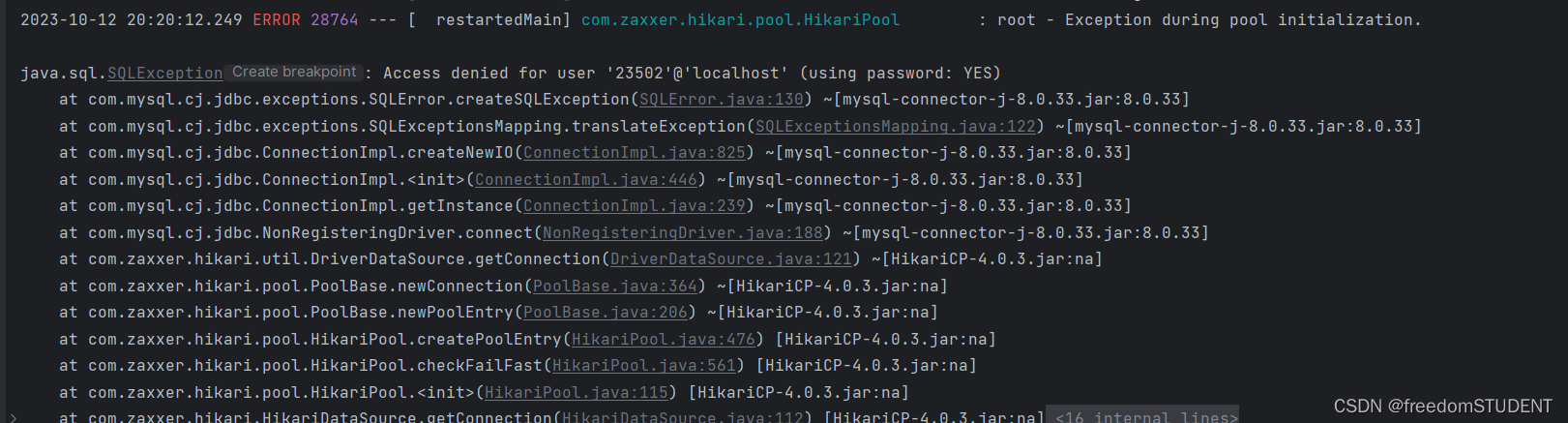
【error】root - Exception during pool initialization
报错提示:root - Exception during pool initialization. 错误原因: 配置数据库出错 我的错误配置: spring.datasource.urljdbc:mysql://localhost:3306/springboot?serverTimezoneGMT spring.datasource.nameroot spring.datasource.pass…...

【重拾C语言】九、再论函数(指针、数组、结构体作参数;函数值返回指针、结构体;作用域)
目录 前言 九、再论函数 9.1 参数 9.1.1 参数的传递规则 9.1.2 指针作参数 9.1.3 数组作参数 9.1.4 结构体作参数 a. 直接用结构体变量作函数参数 b. 用指向结构体变量的指针作函数参数 9.2 函数值 9.2.1 返回指针值 9.2.2 返回结构体值 a. 返回结构体值 b. 返回…...

Spring WebClient 基于响应式编程模型的HTTP客户端
一、简介 WebClient是一个非阻塞的、可扩展的、基于Reactive Streams规范的HTTP客户端。它提供了一种简洁的方式来进行HTTP请求,并且可以很好地与其他Spring组件集成。WebClient支持同步和异步操作,使得它非常适合用于构建响应式应用程序。 WebClient允…...

IP真人识别方法与代理IP检测技术
随着互联网的发展,IP地址在网络安全和数据分析中扮演着重要的角色。为了维护网络的安全性和识别真实用户,IP地址的真实性和来源成为了一个关键问题。 什么是IP真人识别? IP真人识别是一种技术,旨在确定IP地址背后的用户是否为真实…...
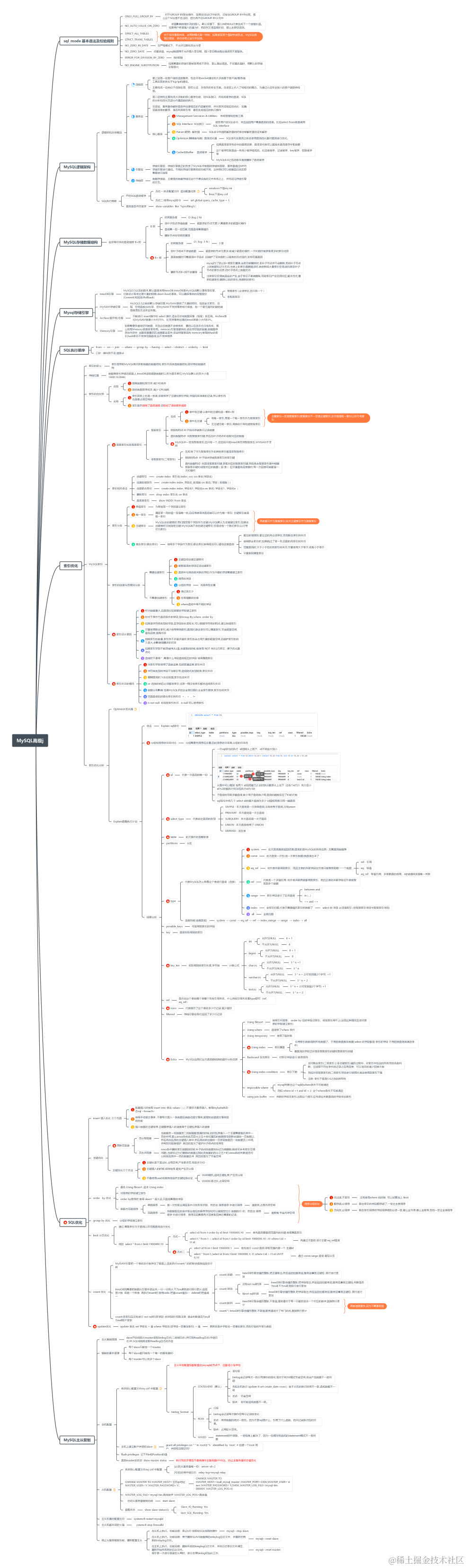
MySQL 面试知识脑图 初高级知识点
脑图下载地址:https://mm.edrawsoft.cn/mobile-share/index.html?uuid18b10870122586-src&share_type1 sql_mode 基本语法及校验规则 ONLY_FULL_GROUP_BY 对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现ÿ…...
【数据结构】二叉树的链式结构及实现
目录 1. 前置说明 2. 二叉树的遍历 2.1 前序、中序以及后序遍历 2.2 层序遍历 3. 节点个数及高度等 4. 二叉树的创建和销毁 1. 前置说明 在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二叉树结构…...

OpenCV4(C++)—— 创建窗口滑动条来调参
文章目录 创建滑动条 —— createTrackbar 创建滑动条 —— createTrackbar createTrackbar是OpenCV中的一个函数,用于创建一个可调节的滑动条(Trackbar),以便在图像处理过程中实时调整参数 int cv::createTrackbar(const String…...
深度学习基础知识 学习率调度器的用法解析
深度学习基础知识 学习率调度器的用法解析 1、自定义学习率调度器**:**torch.optim.lr_scheduler.LambdaLR2、正儿八经的模型搭建流程以及学习率调度器的使用设置 1、自定义学习率调度器**:**torch.optim.lr_scheduler.LambdaLR 实验代码: i…...

【JUC系列-12】深入理解PriorityQueue的底层原理和基本使用
JUC系列整体栏目 内容链接地址【一】深入理解JMM内存模型的底层实现原理https://zhenghuisheng.blog.csdn.net/article/details/132400429【二】深入理解CAS底层原理和基本使用https://blog.csdn.net/zhenghuishengq/article/details/132478786【三】熟练掌握Atomic原子系列基本…...
Paddle安装
Paddle安装参考 docs/tutorials/INSTALL_cn.md PaddlePaddle/PaddleDetection - Gitee.comhttps://gitee.com/paddlepaddle/PaddleDetection/blob/release/2.6/docs/tutorials/INSTALL_cn.md # 不指定版本安装paddle-gpu python -m pip install paddlepaddle-gpu# 测试安装 …...
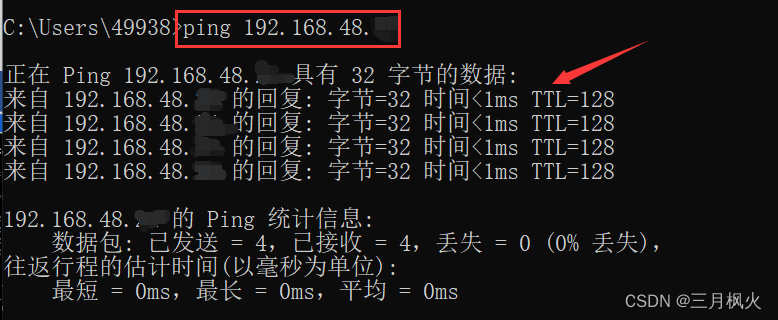
配置XP虚拟机和Win 10宿主机互相ping通
文章目录 一、关闭虚机和宿主机的防火墙1、关闭虚拟机的防火墙1.1方式一1.2方式二 2、关闭宿主机的防火墙 二、设置XP和宿主机VMnet8的IP地址、网关和DNS1、获取VMWare的虚拟网络配置信息2、设置XP的VMnet8的IP地址、网关和DNS3、设置宿主机VMnet8的IP地址、网关和DNS 三、获取…...
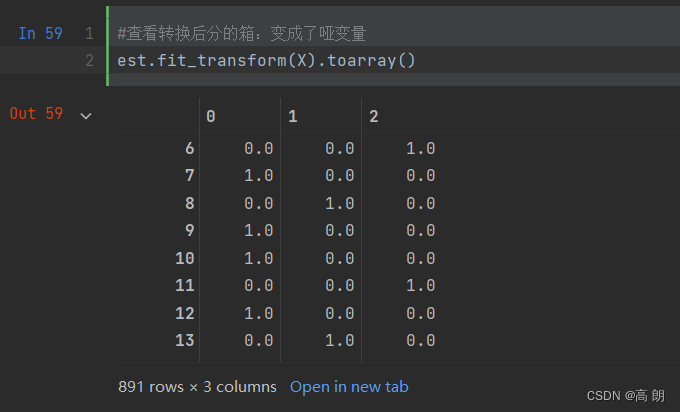
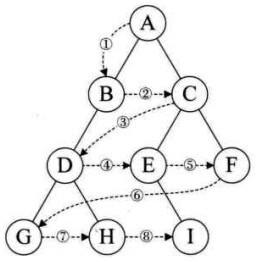
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤 数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据 通过pandas读取数据,通过head和info方法大致查…...

【智慧燃气】智慧燃气解决方案总体概述--终端层、网络层
关键词:智慧燃气、智慧燃气系统、智慧燃气平台、智慧燃气解决方案、智慧燃气应用、智能燃气 智慧燃气解决方案是基于物联网、大数据、云计算、移动互联网等先进技术,结合燃气行业特征,通过智能设备全面感知企业生产、环境、状态等信息的全方…...

Tomcat隔离web原理和热加载热部署
Tomcat 如何打破双亲委派机制 Tomcat 的自定义类加载器 WebAppClassLoader 打破了双亲委派机制,它首先自己尝试去加载某个类,如果找不到再代理给父类加载器,其目的是优先加载 Web 应用自己定义的类。具体实现就是重写 ClassLoader 的两个方法…...

5分钟掌握AMD处理器调优:新手也能轻松上手的硬件调试完整教程
5分钟掌握AMD处理器调优:新手也能轻松上手的硬件调试完整教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: htt…...

ESP32-C3 I²S实战:手把手教你驱动ES8311音频编解码器实现回声消除
ESP32-C3与ES8311音频系统实战:从硬件连接到回声消除算法优化 在智能语音交互设备、会议系统和便携式录音设备中,音频处理能力已成为核心需求。ESP32-C3作为一款高性价比的Wi-Fi/BLE双模芯片,其内置的IS接口为音频应用提供了专业级数字音频传…...

2026年AI辅助研发趋势:智能知识问答如何重塑企业知识库的未来?
在2026年的当下,大模型技术已经从最初的"聊天玩具"逐渐渗透到企业级研发的毛细血管中。作为深耕DevOps领域的架构师,我观察到一个显著的变化:企业知识库(Knowledge Base)正在从单纯的"文档存储中心&quo…...

Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案
Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案 【免费下载链接】angular-dragdrop Implementing jQueryUI Drag and Drop functionality in AngularJS (with Animation) is easier than ever 项目地址: https://gitcode.com/gh_mirrors/an/angul…...

文渊智阁:教育智能化的技术革新与实践
在人工智能技术飞速发展的今天,教育智能化已成为推动科研与教学变革的重要力量。湖北文渊智阁互联网科技有限公司(以下简称“文渊智阁”)凭借其深厚的技术积累和创新能力,在教育智能化领域取得了显著成果。本文将深入探讨文渊智阁…...

COMTool图表插件使用教程:实时数据可视化与曲线绘制完整指南
COMTool图表插件使用教程:实时数据可视化与曲线绘制完整指南 【免费下载链接】COMTool Cross platform communicate assistant(Serial/network/terminal tool)( 跨平台 串口调试助手 网络调试助手 终端工具 linux windows mac Raspberry Pi )…...
:QEMU启动方式分析)
QEMU理解与分析系列(16):QEMU启动方式分析
QEMU启动方式分析启动流程RISC-V specific│┌──────────────────┼──────────────────┐▼ ▼ ▼┌──────────────┐ ┌──────────────┐ ┌───────────…...

金融机构 一般采用是机械硬盘还是固态硬盘
金融机构现在普遍采用的是以固态硬盘(SSD)为主、机械硬盘(HDD)为辅的混合架构。可以说,一个全面向全闪存(全SSD) 演进的趋势正在所有主流银行和券商中发生。可以看一个非常直观的例子࿱…...

VirtualBox虚拟机里Win10远程桌面黑屏?手把手教你改组策略搞定它
VirtualBox虚拟机Win10远程桌面黑屏终极解决方案:从策略组到网络优化的全链路排查 当你正沉浸在VirtualBox虚拟机的Windows 10环境中进行关键开发工作,突然发现远程桌面连接后只剩一片漆黑——这种体验就像在重要会议前突然失声。不同于物理机的远程连接…...

Linux内核安全模块深入剖析【1.9】
7.3.1 基本定义1.客体类别和操作这部分策略是内核代码逻辑的重复。按照机制和策略分离的原则,内核代码实现机制,用户编写策略。但是 SELinux 策略语言中偏偏有一部分是在重复内核代码的逻辑。这部分重新定义了客体类别和操作,有些不伦不类&am…...