【机器学习】sklearn对数据预处理
文章目录
- 数据处理步骤
- 观察数据
- 数据无量纲化
- 缺失值处理
- 处理分类型特征
- 处理连续型特征
数据处理步骤
- 数据无量纲化
- 缺失值处理
- 处理分类型特征:编码与哑变量
- 处理连续型特征:二值化与分段
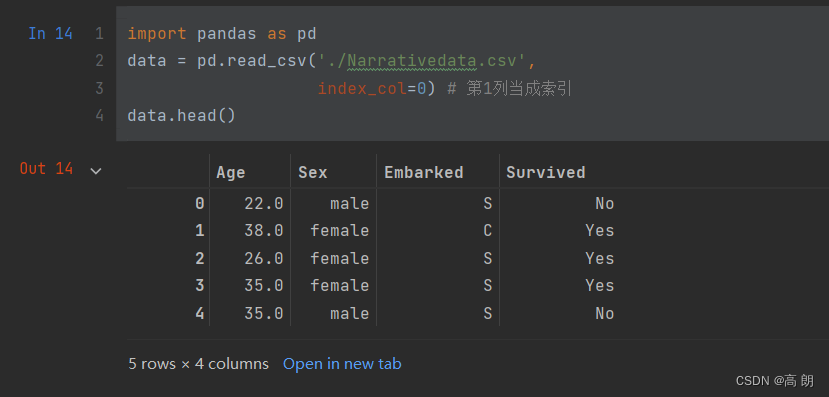
观察数据
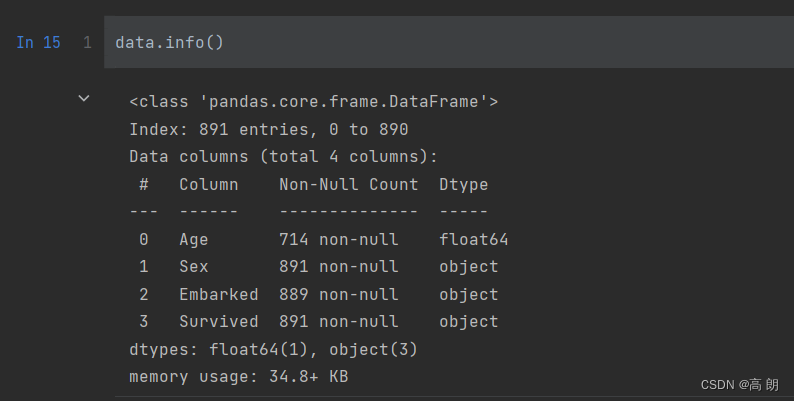
通过pandas读取数据,通过head和info方法大致查看一下数据
 结论:
结论:
- 暂时无需进行无量纲化处
Age和Embarked需要进行缺失值处理- 处理分类型特征:
Sex,Embarked,Survived这几个特征的数据只有几类可以转换为数值型变量。 - 处理连续型特征:
Age连续型可以进行段处理成几类。
数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”。
无量纲化后可以加快求解速度。
数据的无量纲化可以是线性的,也可以是非线性的。
线性的无量纲化包括中心化(Zero-centered或者Meansubtraction)处理和缩放处理(Scale)。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到某个位置。缩放的本质是通过除以一个固定值,将数据固定在某个范围之中,取对数也算是一种缩放处理。
由于上述无需该处理,这个进行构造数据进行操作:
- 归一化
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。
x ∗ = x i − m i n ( x ) m a x ( x ) − m a x ( x ) x^*=\frac{ x_i-min(x)}{max(x)-max(x) } x∗=max(x)−max(x)xi−min(x)
preprocessing.MinMaxScaler
(1) 构造数据
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
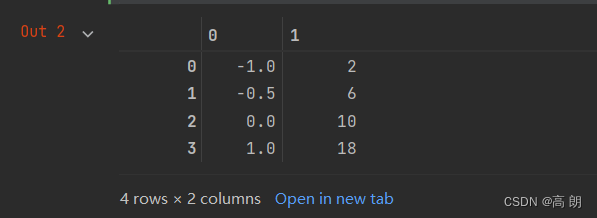
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
pd.DataFrame(data)
 (2)归一化
(2)归一化
scaler = MinMaxScaler() #实例化
result_ = scaler.fit_transform(data) #训练和导出结果一步达成
result_
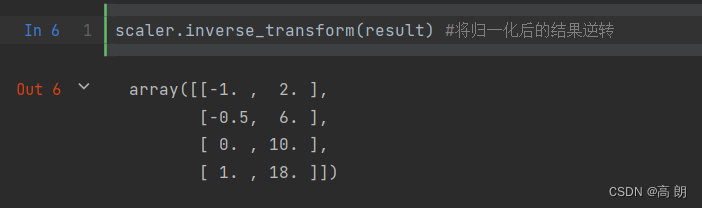
 可以逆转,把归一化的数据变回原来数据
可以逆转,把归一化的数据变回原来数据
scaler.inverse_transform(result) #将归一化后的结果逆转
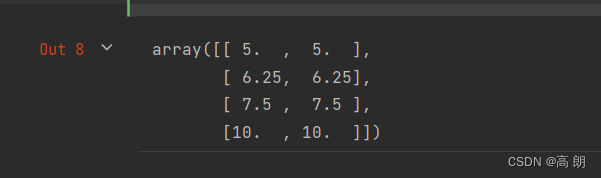
MinMaxScaler类有一个很重要的参数feature_range默认是元组(0,1):把数据压缩到的范围。
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=(5,10)) #依然实例化
result = scaler.fit_transform(data) #fit_transform一步导出结果
result
 当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了,此时使用partial_fit作为训练接口
当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了,此时使用partial_fit作为训练接口scaler = scaler.partial_fit(data)
- 数据标准化
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
x ∗ = x − μ σ x^*=\frac{ x-μ}{σ} x∗=σx−μ
preprocessing.StandardScaler
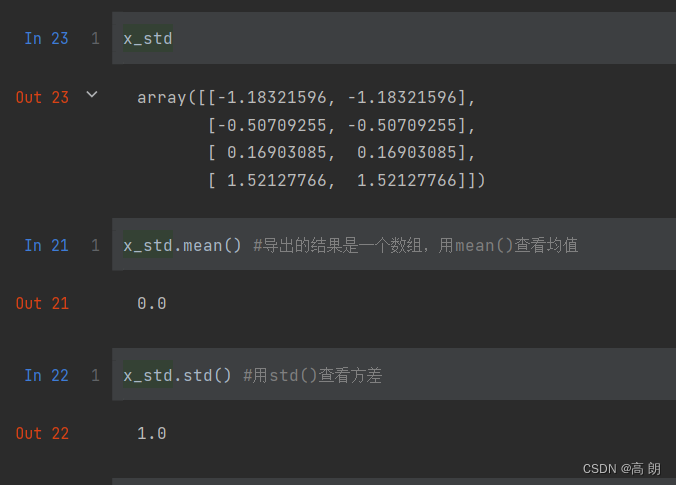
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() #实例化
x_std = scaler.fit_transform(data)
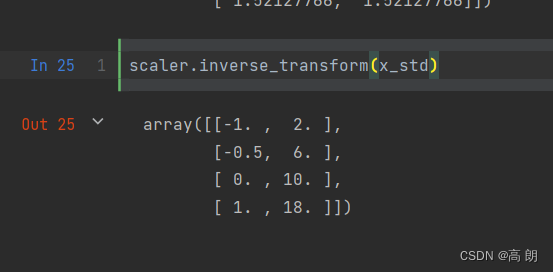
 一样可以逆转:
一样可以逆转:
scaler.inverse_transform(x_std)
- 总结
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候保持缺失NaN的状态显示。并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数组,一维数组导入会报错。
大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。

缺失值处理
sklearn库中处理缺失值的类是SimpleImputer,这个类的相关参数:
| 参数 | 含义&输入 |
|---|---|
| missing_values | 告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan |
| strategy | 我们填补缺失值的策略,默认均值。 输入“ mean”使用均值填补(仅对数值型特征可用)输入“ median"用中值填补(仅对数值型特征可用)输入" most_frequent”用众数填补(对数值型和字符型特征都可用)输入“ constant"表示请参考参数“fill_value"中的值(对数值型和字符型特征都可用) |
| fill_value | 当参数startegy为”constant"的时候可用,可输入字符串或数字表示要填充的值,常用0 |
| copy | 默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去。 |
Age 和Embarked需要进行缺失值处理:
(1)Age
Age = data.loc[:,"Age"].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维
reshape方法将其由一维处理到二维,sklearn对特征的处理,必须二维,不然会报错。
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填补
实例化3种方式填充。
imp_mean = imp_mean.fit_transform(Age) #fit_transform一步完成调取结果
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
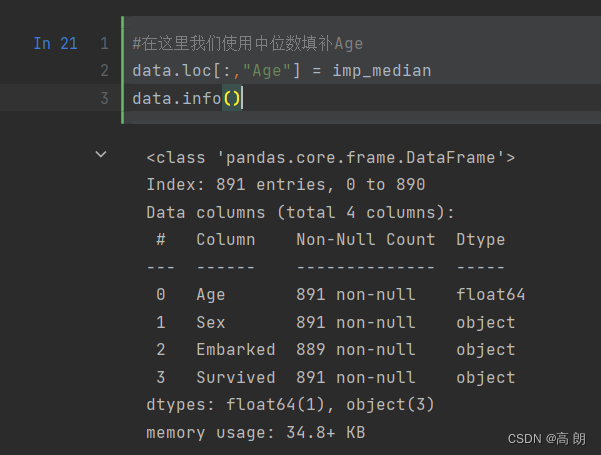
#在这里我们使用中位数填补Age
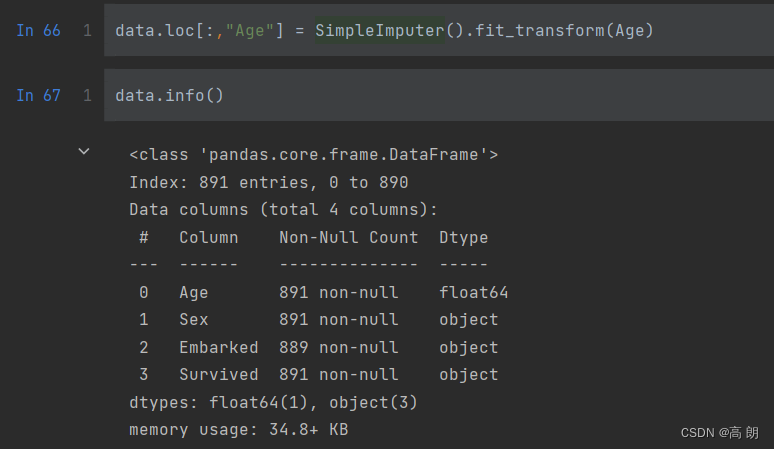
data.loc[:,"Age"] = imp_median
data.info()
也可以一步完成:
data.loc[:,"Age"] = SimpleImputer().fit_transform(Age)
 (2)Embarked
(2)Embarked
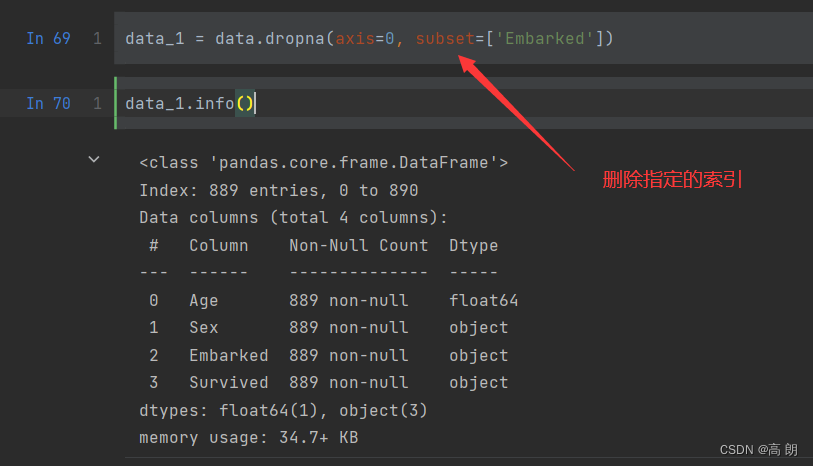
这个特征只缺了2个数据,可以直接删掉,影响不大。但是如果面对缺失较多的文字型数据可以使用众数进行填充most_frequent
data.loc[:,"Embarked"] = SimpleImputer(strategy = "most_frequent").fit_transform(Embarked)
补:pandas填充更方便:
data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median())
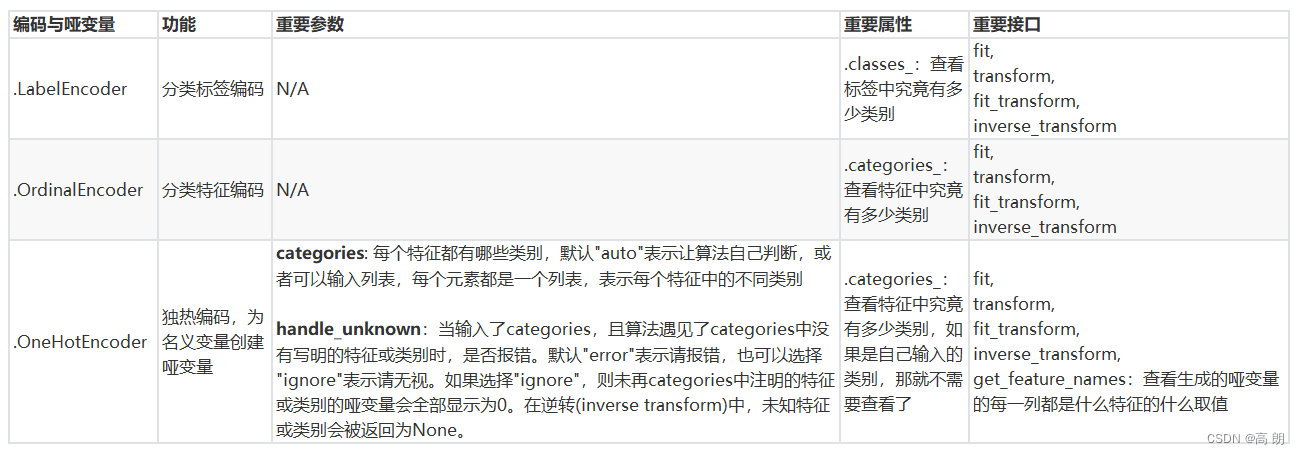
处理分类型特征
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
将文字型数据转换为数值型:
- 标签数据[Yes,No,Unkown]=>[0,1,2] ,
LabelEncoder类专门处理标签,可以输入一维向量,特征类的必须是二维及以上。
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维
le = LabelEncoder() #实例化
le = le.fit(y) #导入数据
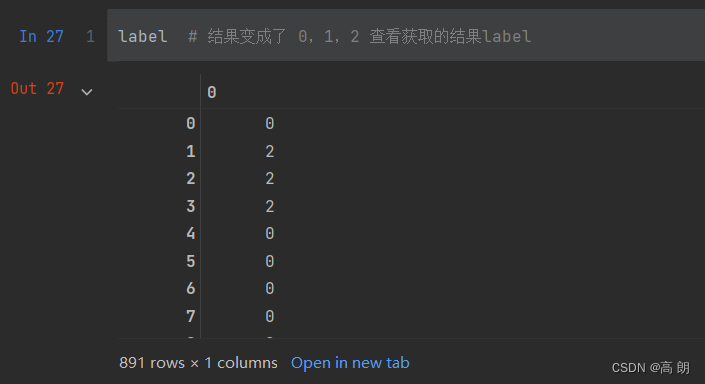
label = le.transform(y) #transform接口调取结果
label就是我们处理后的数据:
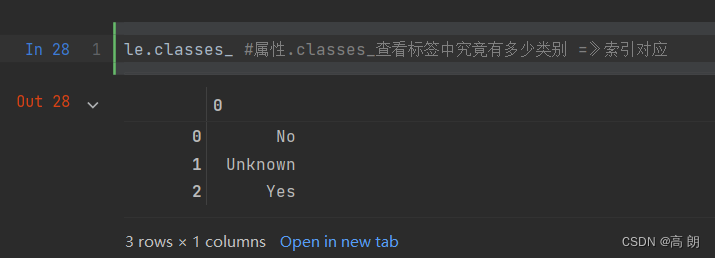
 可以通过
可以通过classes_看原有的类别:
 也和其他的一样,可以一步到位,或者逆转:
也和其他的一样,可以一步到位,或者逆转:
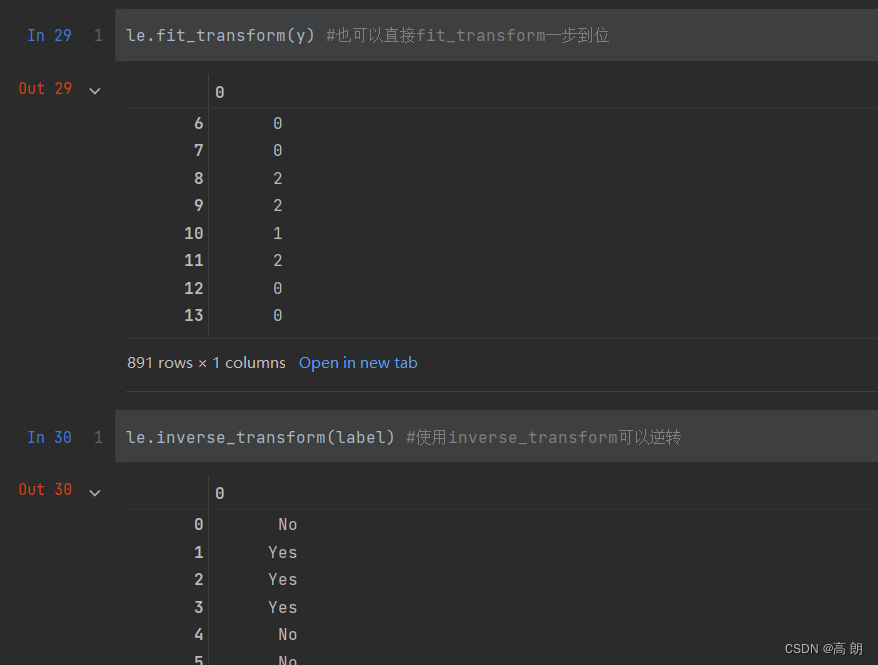
data.iloc[:,-1] = label #让标签等于我们运行出来的结果
data.head()
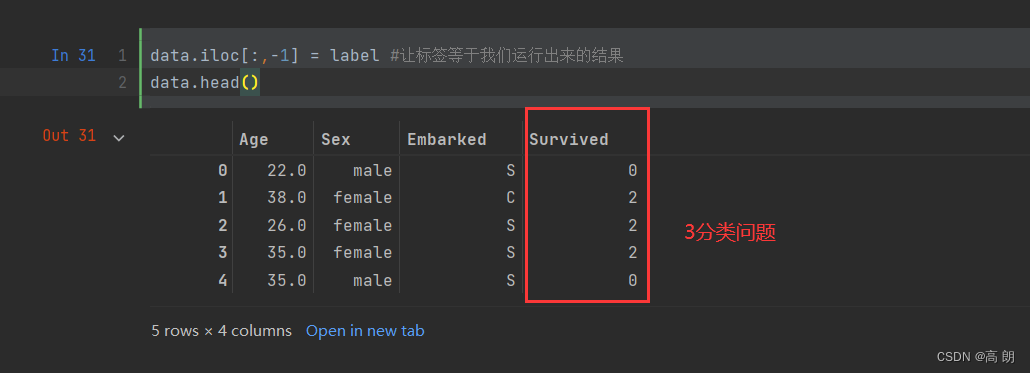 一步到位:
一步到位:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
Sex,Embarked特征变量处理:OrdinalEncoder类
from sklearn.preprocessing import OrdinalEncoder
#接口categories_对应LabelEncoder的接口classes_,一模一样的功能
data_ = data.copy()
data_.head()
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_

data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head()
【这样做不太对,原本毫无关联的文字型变量,现在变成有数学含义的数字型,赋予了大小等其他数学含义】
直接pass掉OrdinalEncoder类处理特征数据,采用OneHotEncoder独热编码:
 由原本的一列变成变成多列,列数为类别数。
由原本的一列变成变成多列,列数为类别数。
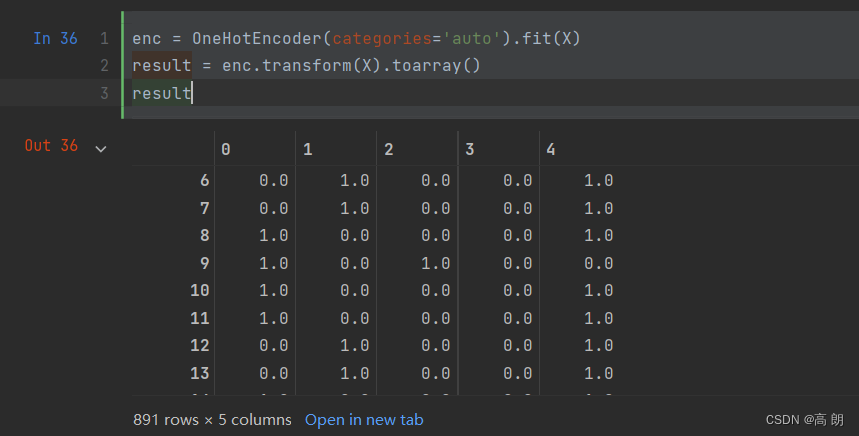
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
result
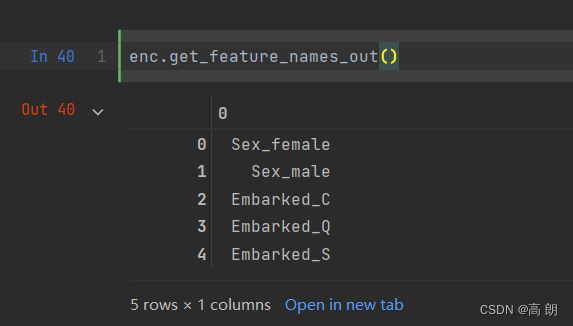
 可以查看每一列的含义:
可以查看每一列的含义:
enc.get_feature_names_out()
 也可以还原到原来的两列:
也可以还原到原来的两列:
 然后需要做的就是,给原数据拼接上面的数据,删除独热编码之前的类,重命名索引名:
然后需要做的就是,给原数据拼接上面的数据,删除独热编码之前的类,重命名索引名:
#axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)
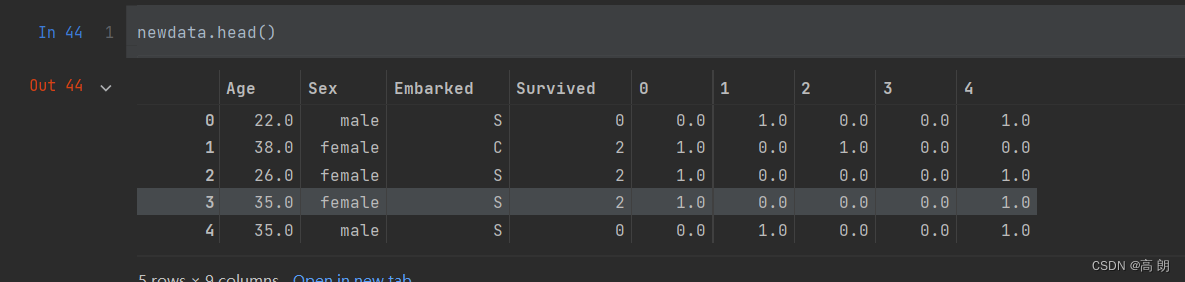
newdata.drop(["Sex","Embarked"],axis=1,inplace=True)
newdata.columns =["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"]
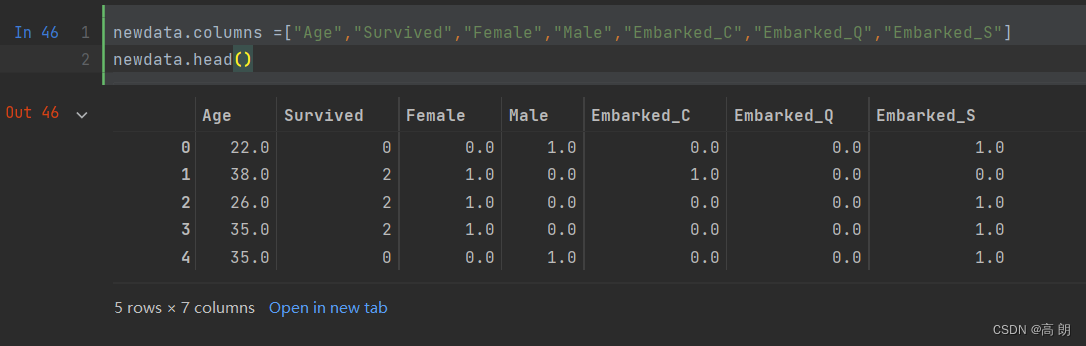
总结:
处理连续型特征
- 二值化:
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X)
transformer
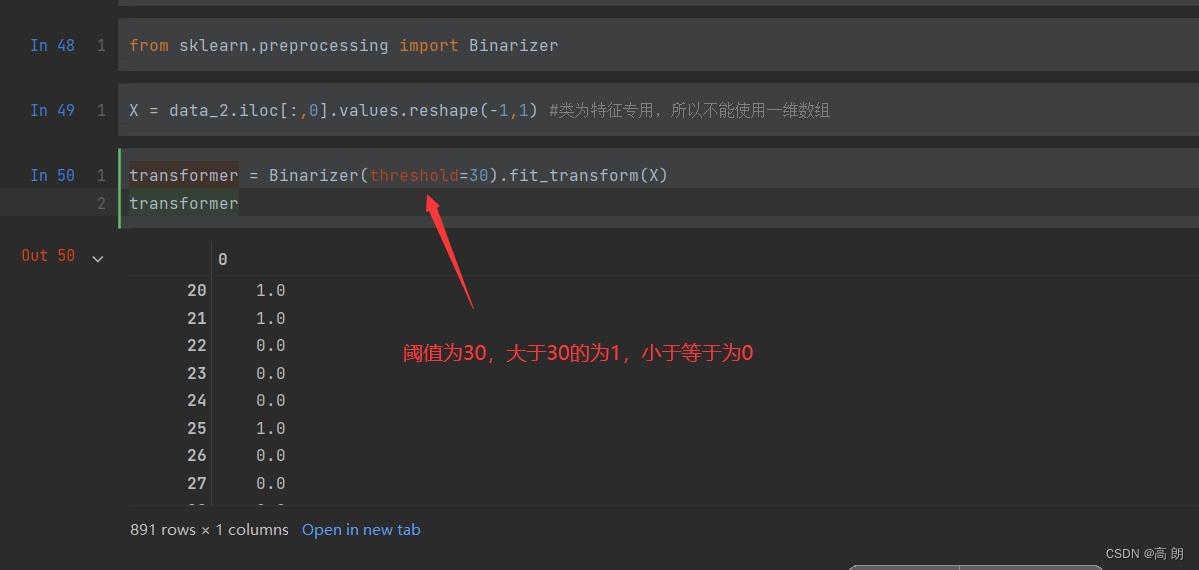
data_2.iloc[:,0] = transformer
- 分段:
KBinsDiscretizer
这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。总共包含三个重要参数:
| 参数 | 含义&输入 |
|---|---|
| n_bins | 每个特征中分箱的个数,默认5,一次会被运用到所有导入的特征 |
| encode | 编码的方式,默认“onehot” “ onehot”:做哑变量,之后返回一个稀疏矩阵,每一列是一个特征中的一个类别,含有该类别的样本表示为1,不含的表示为0 “ ordinal”:每个特征的每个箱都被编码为一个整数,返回每一列是一个特征,每个特征下含有不同整数编码的箱的矩阵“ onehot-dense”:做哑变量,之后返回一个密集数组。 |
| strategy | 用来定义箱宽的方式,默认"quantile" “uniform”:表示等宽分箱,即每个特征中的每个箱的最大值之间的差为(特征.max() - 特征.min())/(n_bins) “quantile”:表示等位分箱,即每个特征中的每个箱内的样本数量都相同 “kmeans”:表示按聚类分箱,每个箱中的值到最近的一维k均值聚类的簇心得距离都相同 |
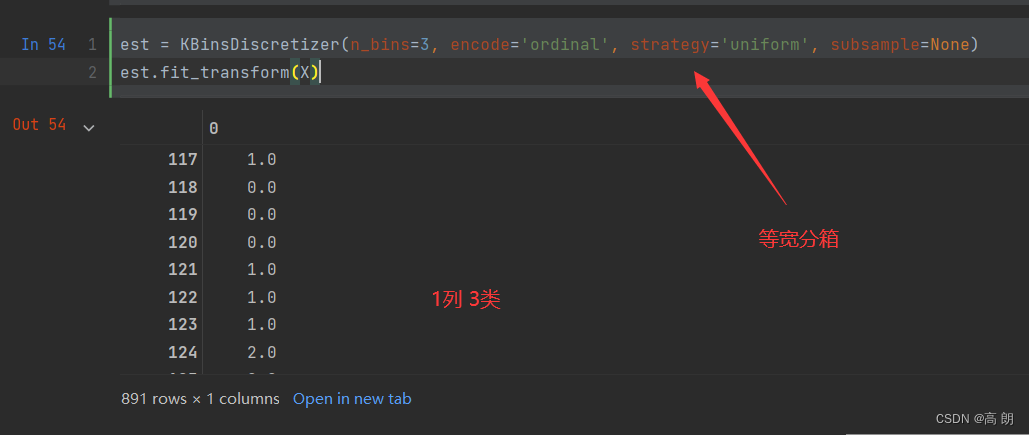
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform', subsample=None)
est.fit_transform(X)
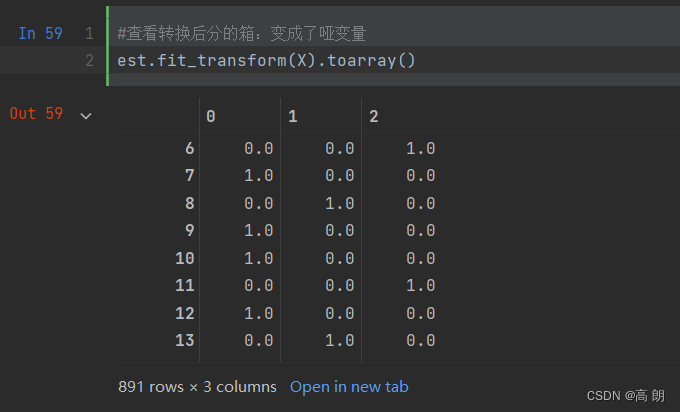
 采用独热编码分成多列:
采用独热编码分成多列:
est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform', subsample=None)
#查看转换后分的箱:变成了哑变量
est.fit_transform(X).toarray()
相关文章:
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤 数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据 通过pandas读取数据,通过head和info方法大致查…...

【智慧燃气】智慧燃气解决方案总体概述--终端层、网络层
关键词:智慧燃气、智慧燃气系统、智慧燃气平台、智慧燃气解决方案、智慧燃气应用、智能燃气 智慧燃气解决方案是基于物联网、大数据、云计算、移动互联网等先进技术,结合燃气行业特征,通过智能设备全面感知企业生产、环境、状态等信息的全方…...

Tomcat隔离web原理和热加载热部署
Tomcat 如何打破双亲委派机制 Tomcat 的自定义类加载器 WebAppClassLoader 打破了双亲委派机制,它首先自己尝试去加载某个类,如果找不到再代理给父类加载器,其目的是优先加载 Web 应用自己定义的类。具体实现就是重写 ClassLoader 的两个方法…...
使用ffmpeg和python脚本下载网络视频m3u8(全网最全面)
网上给娃找了些好看的电影和一些有趣的短视频,如何保存下来呢?从网上找各种工具?都不方便。于是想到何不编程搞定,搞个脚本。对程序员来说这都不是事儿。且我有华为云服务器,完全可以把地址记下,后台自动下…...
【考研408常用数据结构】C/C++实现代码汇总
文章目录 前言数组多维数组的原理、作用稀疏数组 链表单向链表的增删改查的具体实现思路约瑟夫环问题(可不学)双向链表 树二叉搜索树中序线索二叉树哈夫曼树的编码与译码红黑树B树B树 堆顺序与链式结构队列实现优先队列排序算法(重点…...

Flink学习笔记(二):Flink内存模型
文章目录 1、配置总内存2、JobManager 内存模型3、TaskManager 内存模型4、WebUI 展示内存5、Flink On YARN 模式下内存分配6、Flink On Yarn 集群消耗资源估算6.1、资源分配6.2、Flink 提交 Yarn 集群的相关命令6.3、Flink On Yarn 集群的资源计算公式 1、配置总内存 Flink J…...
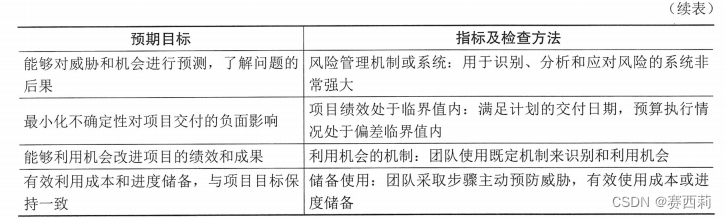
信息系统项目管理师第四版学习笔记——项目绩效域
干系人绩效域 干系人绩效域涉及与干系人相关的活动和职能。在项目整个生命周期过程中,有效执行本绩效域可以实现的预期目标主要包含:①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度…...

PyTorch 深度学习之加载数据集Dataset and DataLoader(七)
1. Revision: Manual data feed 全部Batch:计算速度,性能有问题 1 个 :跨越鞍点 mini-Batch:均衡速度与性能 2. Terminology: Epoch, Batch-Size, Iteration DataLoader: batch_size2, sheffleTrue 3. How to define your Dataset 两种处…...

小谈设计模式(26)—中介者模式
小谈设计模式(26)—中介者模式 专栏介绍专栏地址专栏介绍 中介者模式分析角色分析抽象中介者(Mediator)具体中介者(ConcreteMediator)抽象同事类(Colleague)具体同事类(C…...

7种设计模式
1. 工厂模式 优点:封装了对象的创建过程,降低了耦合性,提供了灵活性和可扩展性。 缺点:增加了代码的复杂性,需要创建工厂类。 适用场景:当需要根据不同条件创建不同对象时,或者需要隐藏对象创建…...
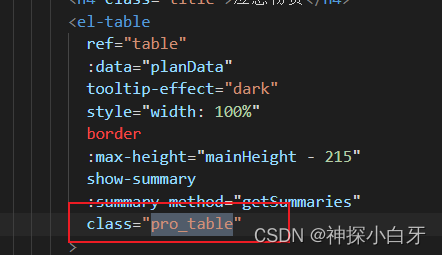
el-table合计行合并
效果如下 因为合计el-table的合并方法是不生效的,所以需要修改css下手 watch: {// 应急物资的合计合并planData: {immediate: true,handler() {setTimeout(() > {const tds document.querySelectorAll(".pro_table .el-table__footer-wrapper tr>td");tds[0]…...

新手如何快速上手HTTP爬虫IP?
对于刚接触HTTP爬虫IP的新手来说,可能会感到有些困惑。但是,实际上HTTP爬虫IP并不复杂,只要掌握了基本的操作步骤,就可以轻松使用。本文将为新手们提供一个快速上手HTTP爬虫IP的入门指南,帮助您迅速了解HTTP爬虫IP的基…...
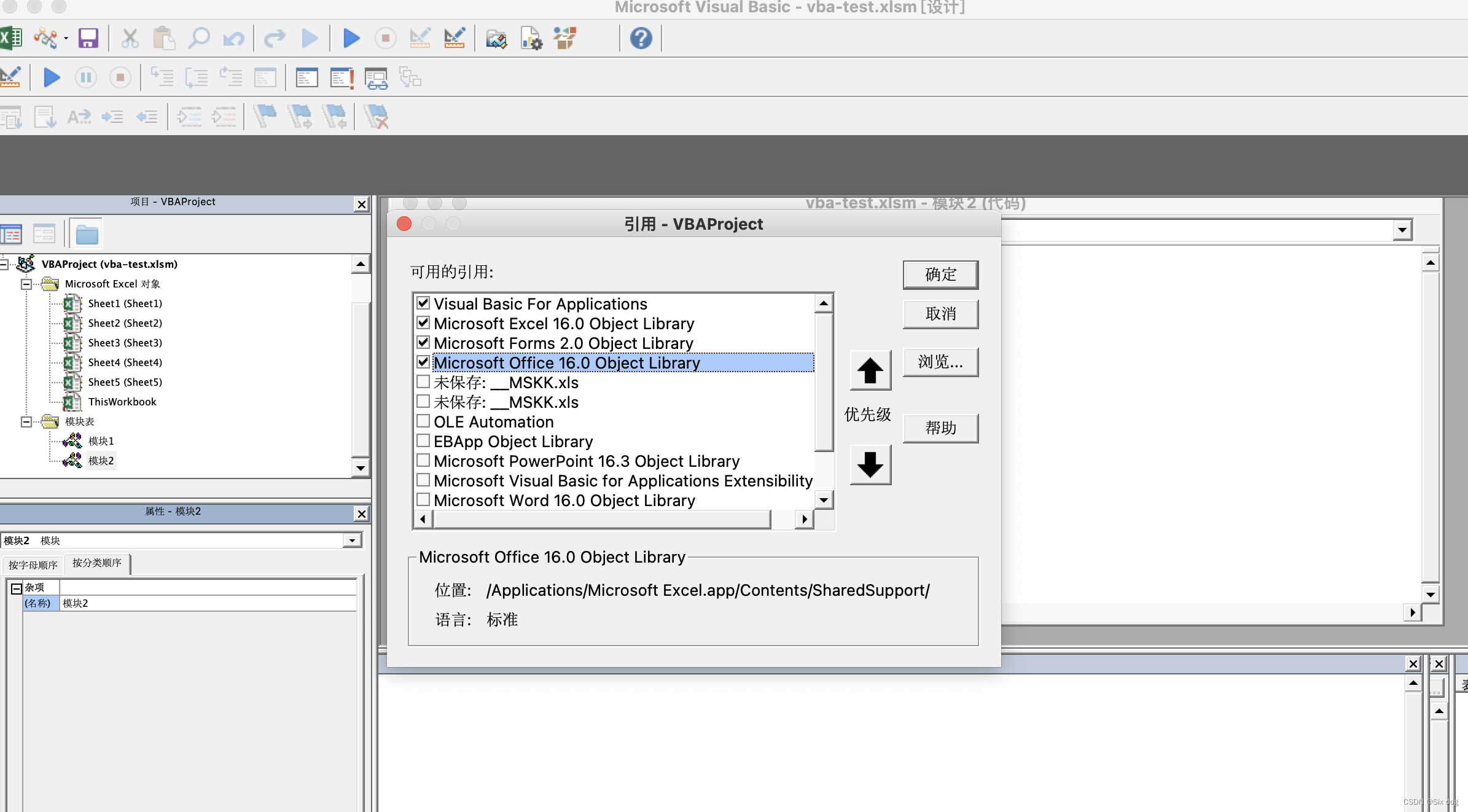
(十五)VBA常用基础知识:正则表达式的使用
vba正则表达式的说明 项目说明Pattern在这里写正则表达式,例:[\d]{2,4}IgnoreCase大小写区分,默认false:区分;true:不区分Globaltrue:全体检索;false:最小匹配Test类似p…...

vue配置@路径
第一步:安装path,如果node_module文件夹中有path就不用安装了 安装命令:npm install path --save 第二步:在vue.config.js文件(如果没有就新建)中配置 const path require("path"); function …...
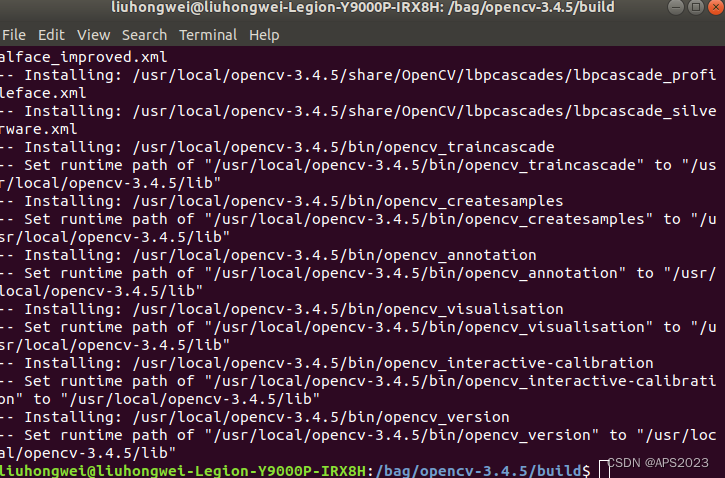
Ubuntu 18.04 OpenCV3.4.5 + OpenCV3.4.5 Contrib 编译
目录 1 依赖安装 2 下载opencv3.4.5及opencv3.4.5 contrib版本 3 编译opencv3.4.5 opencv3.4.5_contrib及遇到的问题 1 依赖安装 首先安装编译工具CMake,命令安装即可: sudo apt install cmake 安装Eigen: sudo apt-get install libeigen3-…...

【网络基础】IP 子网划分(VLSM)
目录 一、 为什么要划分子网 二、如何划分子网 1、划分两个子网 2、划分多个子网 一、 为什么要划分子网 假设有一个B类IP地址172.16.0.0,B类IP的默认子网掩码是 255.255.0.0,那么该网段内IP的变化范围为 172.16.0.0 ~ 172.16.255.255,即…...

【OCR】合同上批量贴印章
一、需求 OCR算法在处理合同等文件时,会由于印章等遮挡导致文本误识别。因此在OCR预处理时,有一个很重要的步骤是“去除印章”。其中本文主要聚焦在“去除印章”任务中的数据构建步骤:“合同伪印章”的数据构建。下面直接放几张批量合成后效果…...

Stable diffusion 用DeOldify给黑白照片、视频上色
老照片常常因为当时的技术限制而只有黑白版本。然而现代的 AI 技术,如 DeOldify,可以让这些照片重现色彩。 本教程将详细介绍如何使用 DeOldify 来给老照片上色。. 之前介绍过基于虚拟环境的 基于DeOldify的给黑白照片、视频上色,本次介绍对于新手比较友好的在Stable diff…...

在服务器上解压.7z文件
1. 更新apt sudo apt-get update2. 安装p7zip sudo apt-get install p7zip-full3. 解压.7z文件 7za x WN18RR.7z...

【opencv】windows10下opencv4.8.0-cuda C++版本源码编译教程
【opencv】windows10下opencv4.8.0-cuda C版本源码编译教程 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【opencv】windows10下opencv4.8.0-cuda C版本源码编译教程前言准备工具cuda/cudnncmakeopencv4.8.0opencv_contrib CMake编译VS2019编…...

低代码平台表单设计器 unione form editor 布局组件 — 折叠面板
低代码平台表单设计器 unione-form-editor 布局组件 —— 折叠面板 在企业级表单越来越长、内容越来越多的今天,如何让表单保持简洁、可收起、可展开、层级清晰,成为提升填写体验的关键。继栅格、卡片、标签、段落布局之后,今天为大家介绍 折…...

如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南
如何深度优化Wand应用体验:Wand-Enhancer配置增强实践指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 在游戏修改工具的使用过程中&…...

MounRiver Studio编译优化实战:如何为你的RISC-V项目选择-O0到-O3?
MounRiver Studio编译优化实战:RISC-V项目-O0到-O3的深度选择指南 当你在MounRiver Studio中点击那个小小的"Optimization"下拉框时,是否曾对着-O0、-O1、-O2、-Os、-O3这些选项犹豫不决?作为一位经历过数十个RISC-V项目的老手&am…...

2026年阿里云OpenClaw/Hermes Agent配置Token Plan新手友好流程
2026年阿里云OpenClaw/Hermes Agent配置Token Plan新手友好流程。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

Pearcleaner:彻底清理Mac应用残留文件的开源解决方案
Pearcleaner:彻底清理Mac应用残留文件的开源解决方案 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾经在Mac上删除应用后,发…...

当Abaqus自带模型不够用:3D Hashin失效准则VUMAT开发心路与参数调试经验谈
突破Abaqus复合材料仿真边界:三维Hashin失效准则开发实战全解析 当面对纤维增强复合材料的复杂失效行为时,Abaqus内置的二维Hashin准则常常显得力不从心。作为一名长期深耕复合材料损伤模拟的工程师,我曾花费六个月时间从理论推导到代码实现完…...

20260520 OVN网络整体实验
OVN网络整体实验 [rootcontroller ~ 16:26:09]# source keystonerc_admin [rootcontroller ~(keystone_admin)]# openstack network agent list --------------------------------------------------------------------------------------------------------------------------…...
)
手把手教你用W25Q32 SPI Flash:从波形图看懂擦除、写入和读取(附完整代码)
手把手教你用W25Q32 SPI Flash:从波形图看懂擦除、写入和读取(附完整代码) 在嵌入式开发中,SPI Flash存储器因其高性价比、大容量和简单接口而广受欢迎。W25Q32作为一款32Mb的SPI Flash芯片,被广泛应用于物联网设备、消…...
)
别再硬编码了!ABAP Text Elements 三分钟搞定报表字段中文显示(附图标添加技巧)
ABAP文本元素实战:告别硬编码的报表开发艺术 每次看到报表界面上那些冷冰冰的字段名——MATNR、WERKS、VBELN——你是不是也感到一丝尴尬?业务用户可不懂这些技术缩写,他们需要的是直观的"物料编号"、"工厂"和"销售…...

PEMS交通数据实战:用Python从原始TXT到可视化分析的完整Pipeline
PEMS交通数据实战:用Python构建端到端分析管道的深度指南 当清晨第一缕阳光洒在加州高速公路上,数以万计的感应器已经开始悄无声息地记录着每辆车的轨迹。这些来自PEMS(Performance Measurement System)的海量数据,正等待着被转化为改善城市交…...