【JUC系列-12】深入理解PriorityQueue的底层原理和基本使用
JUC系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解JMM内存模型的底层实现原理 | https://zhenghuisheng.blog.csdn.net/article/details/132400429 |
| 【二】深入理解CAS底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132478786 |
| 【三】熟练掌握Atomic原子系列基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132543379 |
| 【四】精通Synchronized底层的实现原理 | https://blog.csdn.net/zhenghuishengq/article/details/132740980 |
| 【五】通过源码分析AQS和ReentrantLock的底层原理 | https://blog.csdn.net/zhenghuishengq/article/details/132857564 |
| 【六】深入理解Semaphore底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132908068 |
| 【七】深入理解CountDownLatch底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133343440 |
| 【八】深入理解CyclicBarrier底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133378623 |
| 【九】深入理解ReentrantReadWriteLock 读写锁的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133629550 |
| 【十】深入理解ArrayBlockingQueue的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133692023 |
| 【十一】深入理解LinkedBlockingQueue的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133723652 |
| 【十二】深入理解PriorityQueue的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133788655 |
深入理解PriorityQueue的底层实现
- 一,深入理解PriorityQueue的底层原理
- 1,PriorityQueue的基本使用
- 2,priorityBlockingQueue的底层源码
- 2.1,priorityBlockingQueue类的属性
- 2.2,priorityBlockingQueue入队操作
- 2.2.1,数组扩容操作
- 2.2.2,数组的入队并排序(重点)
- 2.3,priorityBlockingQueue出队操作
- 2.3.1,数组出队并重新排序
- 3,总结
一,深入理解PriorityQueue的底层原理
前面讲解了关于数组和链表的方式实现阻塞队列,但是在实际开发中,这两种队列并不能满足全部的需求,如在某些场景下需要会员优先,vip优先等活动,如购物场景中、或者一些办理业务的逻辑中。
为了更好的支持这种优先级排队的情况,在现有的数据结构中,PriorityQueue 选择的是采用二叉堆的方式来实现,相对于数组实现的阻塞队列,PriorityQueue支持数组的扩容,因此这个PriorityQueue又是一个无界的阻塞队列,总而言之就是:优先级实现的阻塞队列,可以在出队的时候,优先级最高的可以先出,优先级依次排序
1,PriorityQueue的基本使用
在了解一个PriorityQueue的底层原理之前,来先了解一下这个队列的基本使用。假设一个需求,就是会有一个文件类,接下来要将文件的大小加入到阻塞队列,在输出时文件小的先输出
首先先定义一个文件的实体类 FileData,里面的属性相对比较简单,够用就行
/*** 文件信息* @Author: zhenghuisheng* @Date: 2023/10/12 6:22*/
@Data
public class FileData implements Serializable {private Integer id;//文件名称private String fileName;//文件大小private Integer fileSize;
}随后创建一个生产者的线程任务类Producer,用于将文件加入到阻塞队列中阻塞,并且排好队
/*** 生产者线程* @Author: zhenghuisheng* @Date: 2023/10/12 6:22*/
@Data
public class Producer implements Runnable {//全局的阻塞队列private PriorityBlockingQueue<FileData> priorityBlockingQueue;//需要添加的文件private FileData fileData;public Producer(PriorityBlockingQueue queue,FileData fileData){this.priorityBlockingQueue = queue;this.fileData = fileData;}//添加文件@Overridepublic void run() {try {//加入阻塞队列priorityBlockingQueue.put(fileData);System.out.println("文件" + fileData.getFileName() + "加入完毕");} catch (Exception e) {e.printStackTrace();}}
}随后创建一个消费者的线程任务类Consumer,用于将文件从阻塞队列中取出
/*** 消费者线程* @Author: zhenghuisheng* @Date: 2023/10/8 20:21*/
@Data
public class Consumer implements Runnable {private PriorityBlockingQueue<FileData> queue;public Consumer(PriorityBlockingQueue priorityBlockingQueue){this.queue = priorityBlockingQueue;}@Overridepublic void run() {//消费者消费try {System.out.println(queue.take());} catch (InterruptedException e) {e.printStackTrace();}}
}
随后创建一个线程池的工具类,用于定义线程池中的各个参数
/*** 线程池工具* @author zhenghuisheng* @date : 2023/3/22*/
public class ThreadPoolUtil {/*** io密集型:最大核心线程数为2N,可以给cpu更好的轮换,* 核心线程数不超过2N即可,可以适当留点空间* cpu密集型:最大核心线程数为N或者N+1,N可以充分利用cpu资源,N加1是为了防止缺页造成cpu空闲,* 核心线程数不超过N+1即可* 使用线程池的时机:1,单个任务处理时间比较短 2,需要处理的任务数量很大*/public static synchronized ThreadPoolExecutor getThreadPool() {if (pool == null) {//获取当前机器的cpuint cpuNum = Runtime.getRuntime().availableProcessors();log.info("当前机器的cpu的个数为:" + cpuNum);int maximumPoolSize = cpuNum * 2 ;pool = new ThreadPoolExecutor(maximumPoolSize - 2,maximumPoolSize,5L, //5sTimeUnit.SECONDS,new LinkedBlockingQueue<>(), //数组有界队列Executors.defaultThreadFactory(), //默认的线程工厂new ThreadPoolExecutor.AbortPolicy()); //直接抛异常,默认异常}return pool;}
}
由于在这个PriorityBlockingQueue中默认是直接比较元素的值的,而这里的元素是文件实体,因此需要自定义一个实现了Comparator的类,并重写一个compare的比较方法,从而实现文件大小的比较
/*** @Author: zhenghuisheng* @Date: 2023/10/12 6:43*/
public class ComparatorFileSize implements Comparator {@Overridepublic int compare(Object o1, Object o2) {FileData firstFileData = (FileData)o1;FileData endFileData = (FileData)o2;return firstFileData.getFileSize()-endFileData.getFileSize();}
}最后来一个带有Main方法的主线程类,用于测试
/*** @Author: zhenghuisheng* @Date: 2023/10/12 6:29*/
public class PriorityBlockingQueueDemo {//创建一个线程池static ThreadPoolExecutor pool = ThreadPoolUtil.getThreadPool();//Comparator比较器类的具体实现,加入二叉堆时需要的比较器static ComparatorFileSize comparatorFileSize = new ComparatorFileSize();//创建一个全局阻塞队列private static PriorityBlockingQueue queue = new PriorityBlockingQueue(16,comparatorFileSize);public static void main(String[] args) throws Exception {//生产者任务for (int i = 0; i < 10; i++) {//创建文件类FileData fileData = new FileData();fileData.setId(i);fileData.setFileSize(10000 + new Random().nextInt(10000));fileData.setFileName("文件" + i);//创建生产者任务Producer producer = new Producer(queue, fileData);//任务加入线程池pool.execute(producer);}Thread.sleep(1000);//消费者消费for (int i = 0; i < 10 ; i++) {Consumer consumer = new Consumer(queue);pool.execute(consumer);}
// Thread.sleep(10000);
// System.exit(0);}
}在输出时就可以发现已经满足了一个堆的结构了
2,priorityBlockingQueue的底层源码
根据前面这么多篇JUC的源码分析以及基本使用,相信本人分析源码的方式各位已经习惯了,就是先学会怎么使用,随后看底层源码,先看这个类的基本属性和构造方法,随后再看对应的put方法的逻辑和take方法的逻辑
2.1,priorityBlockingQueue类的属性
首先是先看这一步,该类依旧是继承了一个抽象类,并且BlockingQueue的一个具体实现
public class PriorityBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>
接下来继续看内部的属性,根据其大概得属性就能知道很多东西,看下面两个东西,不难猜出这个也是和数组实现的方式一样,采用的是一把互斥锁来实现,并且在出队时需要判断是否为空,如果为空则要将这个线程加入到条件队列中,由于PriorityBlockingQueue是无界的,因此在加入队列时是不需要考虑是否为满的情况,因此这个时使用ReentrantLock+一个条件队列 实现AQS的
private final ReentrantLock lock; //互斥锁
private final Condition notEmpty; //出对判断队列是否为空,空则阻塞
还有就是优先级实现的阻塞队列底层是通过数组的方式实现的,数组初始的默认容量为11,最大容量为整型最大值减8
private transient Object[] queue; //数组的方式实现队列
private transient int size; //容量大小
private static final int DEFAULT_INITIAL_CAPACITY = 11; //数组的默认容量为11
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //最大容量
最后再看看这个优先级队列的构造方法,内部就是对上面的这些属性进行复赋值的操作
public PriorityBlockingQueue(int initialCapacity,Comparator<? super E> comparator) {if (initialCapacity < 1) throw new IllegalArgumentException();this.lock = new ReentrantLock(); //初始化互斥锁this.notEmpty = lock.newCondition(); //初始化条件队列this.comparator = comparator; //比较器this.queue = new Object[initialCapacity]; //初始化容量
}
2.2,priorityBlockingQueue入队操作
在上面的案例中使用的是put方法,put方法中又是通过offer方法实现具体的入队操作的,因此直接来看这个offer方法。主要分为扩容,数组入队,入队时排序,唤醒因为队列为空而加入到条件队列的结点,解锁
public boolean offer(E e) {if (e == null) throw new NullPointerException();final ReentrantLock lock = this.lock; //获取到这把互斥锁lock.lock(); //加锁int n, cap; Object[] array; //如果此时数组的长度大于等于原先设置的长度,则会进行扩容操作while ((n = size) >= (cap = (array = queue).length))tryGrow(array, cap);try {Comparator<? super E> cmp = comparator;if (cmp == null)siftUpComparable(n, e, array);elsesiftUpUsingComparator(n, e, array, cmp);size = n + 1;notEmpty.signal();} finally {lock.unlock();}return true;
}
2.2.1,数组扩容操作
接下来查看一下这个tryGrow 的扩容操作时如何实现的,首先会有一个释放锁的操作,但是在后文又有一个加锁操作,因此也解决了并发的阻塞问题。
重点还是看这个扩容操作,假设此时的容量小于64,则扩大原来的容量+2,如果大于64,则扩大原来的容量一倍,就是说假设此时容量为16,那么第一次扩容就是 16+16+2为34,第二次扩容为34 + 34 + 2为70,第三次扩容为70 + 70*2 = 210。 最后创建一个新的数组,将旧值复制到新的数组,将新数组返回
private void tryGrow(Object[] array, int oldCap) {lock.unlock(); // must release and then re-acquire main lockObject[] newArray = null;if (allocationSpinLock == 0 &&UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,0, 1)) {try {//重点还是看这里int newCap = oldCap + ((oldCap < 64) ?(oldCap + 2) : // grow faster if small(oldCap >> 1));//数组超过最大值抛异常if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflowint minCap = oldCap + 1;if (minCap < 0 || minCap > MAX_ARRAY_SIZE)throw new OutOfMemoryError();newCap = MAX_ARRAY_SIZE;}if (newCap > oldCap && queue == array)newArray = new Object[newCap];} finally {allocationSpinLock = 0;}}if (newArray == null) // back off if another thread is allocatingThread.yield();lock.lock();if (newArray != null && queue == array) {queue = newArray; //获取新数组System.arraycopy(array, 0, newArray, 0, oldCap); //将原值copy到新数组}
}
2.2.2,数组的入队并排序(重点)
接下里重点进入这个入队的方法,首先先看这个默认的 siftUpComparable 方法。从下面可以看出该队列时通过小顶堆 的方式实现的,就是通过一个while循环+一个赋值的方式实现
private static <T> void siftUpComparable(int k, T x, Object[] array) {Comparable<? super T> key = (Comparable<? super T>) x; //创建一个比较构造器while (k > 0) { //队列的元素值int parent = (k - 1) >>> 1; //获取当前结点的父节点的索引,左移一位即可Object e = array[parent]; //根据索引下标取值if (key.compareTo((T) e) >= 0) //比较和交换,如果当前值大于父节点则不动break;array[k] = e; //如果当前结点的值小于父结点,则将当前结点改成父结点的值(默认使用的是小顶堆)k = parent; //k在这个while循环下一定会等于0,因此会走最下面的赋值,就是不断地通过while循环将最小的交换到最上面}array[k] = key; //如果队列的长度为0,则直接将堆顶元素赋值
}
在入队之后,数组的size+1,并且最后会唤醒因为数组为空而被加入到条件队列的线程
notEmpty.signal();
最后会通过unlock方法,唤醒同步队列中的线程结点数据
lock.unlock();
2.3,priorityBlockingQueue出队操作
在出队操作中,依旧是通过这个take方法来进行分析,其源码如下,内部主要是出队的操作,如果队列为空,则直接调用这个await进行阻塞,并加入条件队列中
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();E result;try {//出队操作while ( (result = dequeue()) == null)notEmpty.await(); //阻塞,加入条件队列} finally {lock.unlock();}return result;
}
随后继续查看这个 dequeue() 方法,就是获取当前队列,先获取第一个堆顶元素和最后一个元素,将最后一个元素值清空
private E dequeue() {int n = size - 1; if (n < 0) return null; //如果初始值为空则小于0else {Object[] array = queue; //获取当前队列E result = (E) array[0]; //获取第一个数据E x = (E) array[n]; //获取最后一个数据array[n] = null; //清除最后一个数据Comparator<? super E> cmp = comparator; //获取比较构造器if (cmp == null)siftDownComparable(0, x, array, n); //出队操作elsesiftDownUsingComparator(0, x, array, n, cmp);size = n;return result;}
}
2.3.1,数组出队并重新排序
随后真正的调用这个出队的方法 siftDownComparable ,其具体实现如下。首先第一步是头结点出队,然后将尾结点作为头结点;其次是递归的比较当前结点的左结点和右结点谁小,谁小则和当前结点比较,如果比当前结点还小则继续交换,直到当前结点没有子结点
private static <T> void siftDownComparable(int k, T x, Object[] array,int n) {if (n > 0) {//x是最后一个数据Comparable<? super T> key = (Comparable<? super T>)x;int half = n >>> 1; // 二分while (k < half) { //判断当前结点int child = (k << 1) + 1; // 获取当前结点的左结点Object c = array[child]; int right = child + 1; //获取当前结点的右结点if (right < n && //左节点右结点比较和交换((Comparable<? super T>) c).compareTo((T) array[right]) > 0)c = array[child = right]; //谁小谁和头结点交换if (key.compareTo((T) c) <= 0)break;array[k] = c; k = child;}array[k] = key;}
}
这样就成功的实现了小顶堆的出队操作了,在最后会调用这个unlock()方法进行解锁,并唤醒同步队列中线程结点
lock.unlock();
3,总结
优先级的阻塞队列依旧是采用ReentrantLock+条件队列的方式实现,底层采用二叉堆的数据结构,从而实现有序的数组形式。该阻塞队列为无界队列,并且内部有对应的扩容机制,在一些需要优先级的场景中,可以采用这种实现方式。
相关文章:

【JUC系列-12】深入理解PriorityQueue的底层原理和基本使用
JUC系列整体栏目 内容链接地址【一】深入理解JMM内存模型的底层实现原理https://zhenghuisheng.blog.csdn.net/article/details/132400429【二】深入理解CAS底层原理和基本使用https://blog.csdn.net/zhenghuishengq/article/details/132478786【三】熟练掌握Atomic原子系列基本…...
Paddle安装
Paddle安装参考 docs/tutorials/INSTALL_cn.md PaddlePaddle/PaddleDetection - Gitee.comhttps://gitee.com/paddlepaddle/PaddleDetection/blob/release/2.6/docs/tutorials/INSTALL_cn.md # 不指定版本安装paddle-gpu python -m pip install paddlepaddle-gpu# 测试安装 …...
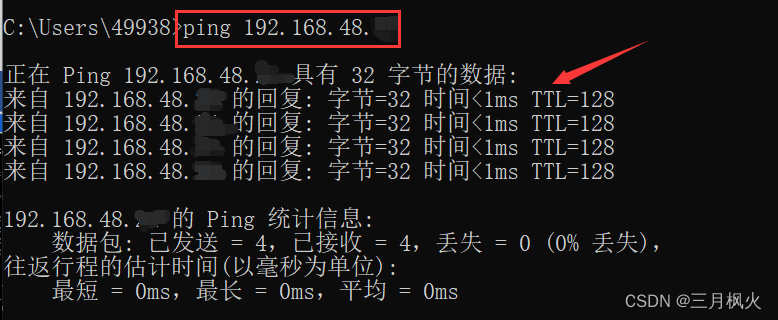
配置XP虚拟机和Win 10宿主机互相ping通
文章目录 一、关闭虚机和宿主机的防火墙1、关闭虚拟机的防火墙1.1方式一1.2方式二 2、关闭宿主机的防火墙 二、设置XP和宿主机VMnet8的IP地址、网关和DNS1、获取VMWare的虚拟网络配置信息2、设置XP的VMnet8的IP地址、网关和DNS3、设置宿主机VMnet8的IP地址、网关和DNS 三、获取…...
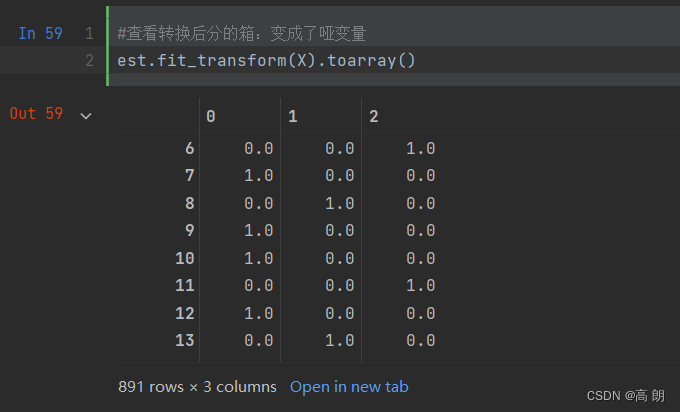
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤 数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据 通过pandas读取数据,通过head和info方法大致查…...

【智慧燃气】智慧燃气解决方案总体概述--终端层、网络层
关键词:智慧燃气、智慧燃气系统、智慧燃气平台、智慧燃气解决方案、智慧燃气应用、智能燃气 智慧燃气解决方案是基于物联网、大数据、云计算、移动互联网等先进技术,结合燃气行业特征,通过智能设备全面感知企业生产、环境、状态等信息的全方…...

Tomcat隔离web原理和热加载热部署
Tomcat 如何打破双亲委派机制 Tomcat 的自定义类加载器 WebAppClassLoader 打破了双亲委派机制,它首先自己尝试去加载某个类,如果找不到再代理给父类加载器,其目的是优先加载 Web 应用自己定义的类。具体实现就是重写 ClassLoader 的两个方法…...
使用ffmpeg和python脚本下载网络视频m3u8(全网最全面)
网上给娃找了些好看的电影和一些有趣的短视频,如何保存下来呢?从网上找各种工具?都不方便。于是想到何不编程搞定,搞个脚本。对程序员来说这都不是事儿。且我有华为云服务器,完全可以把地址记下,后台自动下…...
【考研408常用数据结构】C/C++实现代码汇总
文章目录 前言数组多维数组的原理、作用稀疏数组 链表单向链表的增删改查的具体实现思路约瑟夫环问题(可不学)双向链表 树二叉搜索树中序线索二叉树哈夫曼树的编码与译码红黑树B树B树 堆顺序与链式结构队列实现优先队列排序算法(重点…...

Flink学习笔记(二):Flink内存模型
文章目录 1、配置总内存2、JobManager 内存模型3、TaskManager 内存模型4、WebUI 展示内存5、Flink On YARN 模式下内存分配6、Flink On Yarn 集群消耗资源估算6.1、资源分配6.2、Flink 提交 Yarn 集群的相关命令6.3、Flink On Yarn 集群的资源计算公式 1、配置总内存 Flink J…...
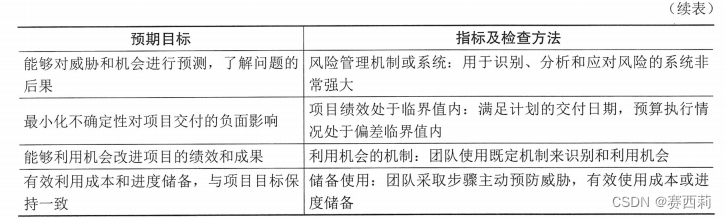
信息系统项目管理师第四版学习笔记——项目绩效域
干系人绩效域 干系人绩效域涉及与干系人相关的活动和职能。在项目整个生命周期过程中,有效执行本绩效域可以实现的预期目标主要包含:①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度…...

PyTorch 深度学习之加载数据集Dataset and DataLoader(七)
1. Revision: Manual data feed 全部Batch:计算速度,性能有问题 1 个 :跨越鞍点 mini-Batch:均衡速度与性能 2. Terminology: Epoch, Batch-Size, Iteration DataLoader: batch_size2, sheffleTrue 3. How to define your Dataset 两种处…...

小谈设计模式(26)—中介者模式
小谈设计模式(26)—中介者模式 专栏介绍专栏地址专栏介绍 中介者模式分析角色分析抽象中介者(Mediator)具体中介者(ConcreteMediator)抽象同事类(Colleague)具体同事类(C…...

7种设计模式
1. 工厂模式 优点:封装了对象的创建过程,降低了耦合性,提供了灵活性和可扩展性。 缺点:增加了代码的复杂性,需要创建工厂类。 适用场景:当需要根据不同条件创建不同对象时,或者需要隐藏对象创建…...
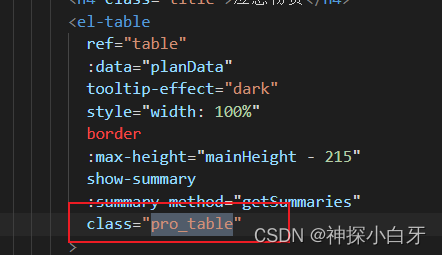
el-table合计行合并
效果如下 因为合计el-table的合并方法是不生效的,所以需要修改css下手 watch: {// 应急物资的合计合并planData: {immediate: true,handler() {setTimeout(() > {const tds document.querySelectorAll(".pro_table .el-table__footer-wrapper tr>td");tds[0]…...

新手如何快速上手HTTP爬虫IP?
对于刚接触HTTP爬虫IP的新手来说,可能会感到有些困惑。但是,实际上HTTP爬虫IP并不复杂,只要掌握了基本的操作步骤,就可以轻松使用。本文将为新手们提供一个快速上手HTTP爬虫IP的入门指南,帮助您迅速了解HTTP爬虫IP的基…...
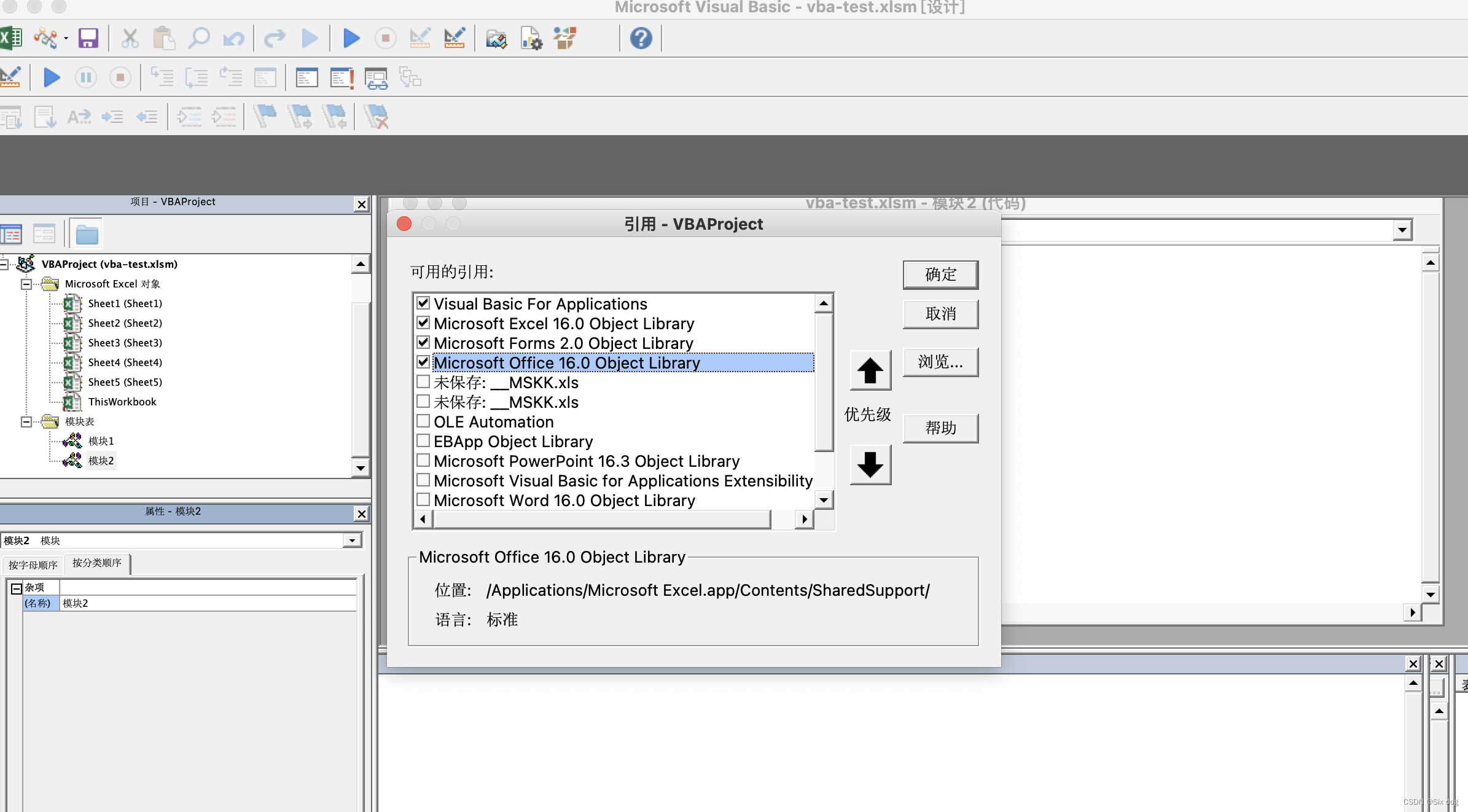
(十五)VBA常用基础知识:正则表达式的使用
vba正则表达式的说明 项目说明Pattern在这里写正则表达式,例:[\d]{2,4}IgnoreCase大小写区分,默认false:区分;true:不区分Globaltrue:全体检索;false:最小匹配Test类似p…...

vue配置@路径
第一步:安装path,如果node_module文件夹中有path就不用安装了 安装命令:npm install path --save 第二步:在vue.config.js文件(如果没有就新建)中配置 const path require("path"); function …...
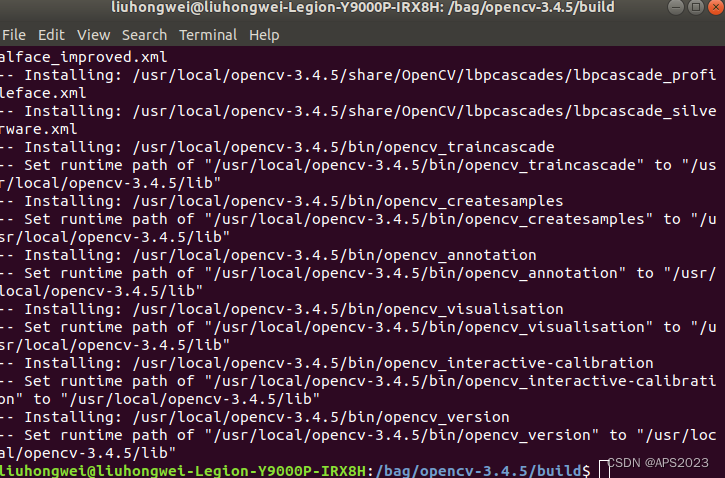
Ubuntu 18.04 OpenCV3.4.5 + OpenCV3.4.5 Contrib 编译
目录 1 依赖安装 2 下载opencv3.4.5及opencv3.4.5 contrib版本 3 编译opencv3.4.5 opencv3.4.5_contrib及遇到的问题 1 依赖安装 首先安装编译工具CMake,命令安装即可: sudo apt install cmake 安装Eigen: sudo apt-get install libeigen3-…...

【网络基础】IP 子网划分(VLSM)
目录 一、 为什么要划分子网 二、如何划分子网 1、划分两个子网 2、划分多个子网 一、 为什么要划分子网 假设有一个B类IP地址172.16.0.0,B类IP的默认子网掩码是 255.255.0.0,那么该网段内IP的变化范围为 172.16.0.0 ~ 172.16.255.255,即…...

【OCR】合同上批量贴印章
一、需求 OCR算法在处理合同等文件时,会由于印章等遮挡导致文本误识别。因此在OCR预处理时,有一个很重要的步骤是“去除印章”。其中本文主要聚焦在“去除印章”任务中的数据构建步骤:“合同伪印章”的数据构建。下面直接放几张批量合成后效果…...

关联查询,左连接,inner join笔记,BNL,NLJ
文章目录left join的最大值和最小值3个表的inner join关联查询时的is_del处理cross join(full join)NLJ 性能高BNL 性能低blj会导致什么问题?left join的最大值和最小值 假设左表m条,右表n条 最小值是m: 当一条也匹配不到右表时,或者右表中…...

免费解锁WeMod完整功能:Wand-Enhancer终极指南
免费解锁WeMod完整功能:Wand-Enhancer终极指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的功能限制而烦恼吗&#x…...
)
2026年第六届FIC全国网络空间取证大赛-初赛详细版Writeup(服务器+互联网+二进制)
2026年第六届FIC全国网络空间取证大赛-初赛详细版Writeup(服务器互联网二进制) 前言:服务器:1. 该服务器主机操作系统版本为2. 该服务器根分区硬盘的uuid号为3. 该服务器中最新的docker镜像创建时间为4. 该服务器根分区快照路径为…...

保姆级教程:手把手教你用Python搭建HTTP服务器,为安信可BL602模组OTA升级铺路
从零构建Python HTTP服务器:物联网开发者的OTA升级基石 在物联网设备开发中,固件升级(OTA)是产品生命周期管理的关键环节。想象一下这样的场景:当您需要为部署在数百公里外的设备更新功能时,无需物理接触设备,只需通过…...

从SDF反标失败说起:为什么PBA模式的结果不能写进标准延迟文件?
从SDF反标失败看PBA与GBA的本质差异:芯片设计中的精度与效率博弈 当你在PrimeTime中完成了一次精细的PBA模式时序分析,确认设计满足所有时序约束后,尝试将结果导出为SDF文件用于后仿验证时,工具却报错或生成的SDF文件无法正确反映…...

别再乱配了!H3C交换机上给不同VLAN打QoS标签和限速,这篇保姆级教程讲透了
H3C交换机QoS实战:精准标记与智能限速配置指南 在企业网络环境中,不同业务部门对网络质量的需求差异显著——研发部门需要稳定的文件传输带宽,高管团队依赖流畅的视频会议,而访客网络则要限制其对核心资源的占用。这种场景下&…...

从MVC到DDD:微服务架构下应对业务复杂性的实战演进
1. 从“造到飞起”到“稳如老狗”:一个老码农的架构心路干了十几年开发,带过不少团队,也趟过无数坑。要说这些年最大的感受是什么,那就是:变化是常态,混乱是必然,而架构的价值,就是在…...

Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案
Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案 【免费下载链接】angular-dragdrop Implementing jQueryUI Drag and Drop functionality in AngularJS (with Animation) is easier than ever 项目地址: https://gitcode.com/gh_mirrors/an/angul…...

别再死记硬背ELMo、GPT、BERT的区别了!一张图带你搞懂它们的核心差异与适用场景
一图胜千言:ELMo、GPT、BERT技术差异与实战选型指南 刚接触NLP时,我也曾被各种预训练模型绕得头晕眼花——它们看起来都能处理文本,但面试官一问"为什么用BERT不用GPT"就瞬间语塞。直到我把这些模型拆解成汽车零件,才真…...

当流程图XML“损坏”时:手把手教你用Activiti API解析与修复BPMN文件
当BPMN文件遭遇“数据灾难”:Activiti深度修复实战指南 凌晨三点,服务器警报突然响起——核心业务流程引擎拒绝加载最新上传的BPMN文件。这不是简单的格式错误,而是一个从老旧系统迁移来的、经过多次手工编辑的流程定义文件。作为技术负责人&…...