MySQL 面试知识脑图 初高级知识点
脑图下载地址:https://mm.edrawsoft.cn/mobile-share/index.html?uuid=18b10870122586-src&share_type=1
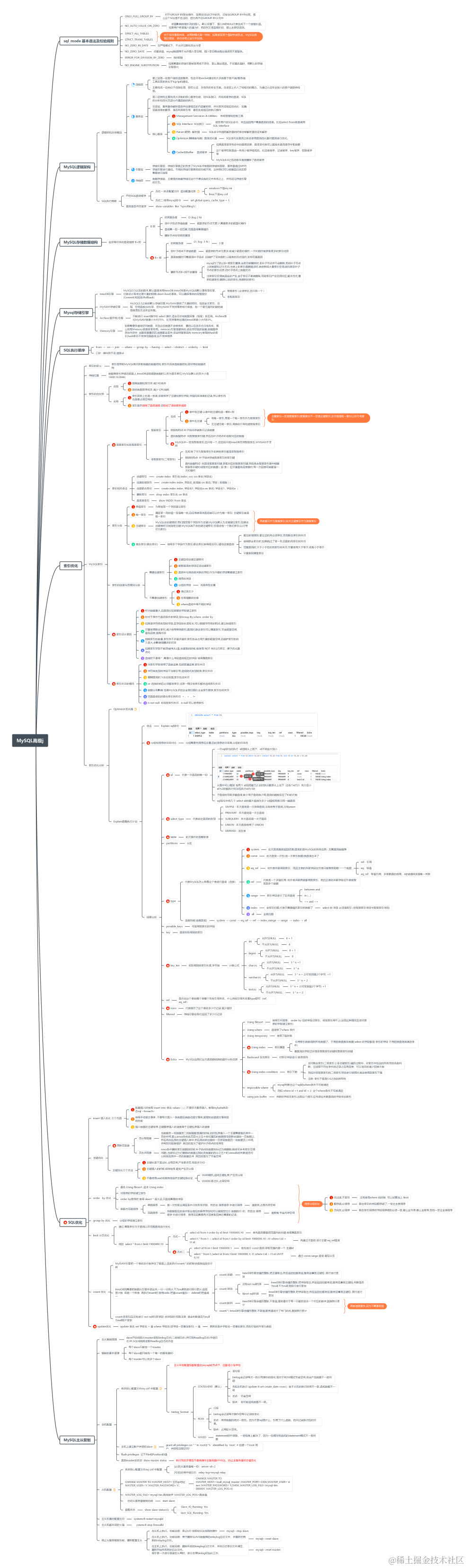
sql_mode 基本语法及校验规则
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中
NO_AUTO_VALUE_ON_ZERO
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户希望插入的值为0,而该列又是自增长的,那么去掉该选项。
STRICT_ALL_TABLES
STRICT_TRANS_TABLES
NO_ZERO_IN_DATE
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。
ERROR_FOR_DIVISION_BY_ZERO
除0报错
NO_ENGINE_SUBSTITUTION
如果需要的存储引擎被禁用或不存在,那么抛出错误。不设置此值时,用默认的存储引擎替代
MySQL逻辑架构
逻辑架构总体概览
连接层
最上层是一些客户端和连接服务,包含本地socket通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。
主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。
在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化:如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作
核心服务
Management Serveices & Utilities: 系统管理和控制工具
SQL Interface: SQL接口
- 接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
Parser(破搜): 解析器
- SQL命令传递到解析器的时候会被解析器验证和解析
Optimizer(啊噗偷马贼): 查询优化器
- SQL语句在查询之前会使用查询优化器对查询进行优化。
Cache和Buffer: 查询缓存
- 如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据
- 这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
- MySQL8.0之后的版本直接删除了查询缓存
引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取
存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
SQL执行周期
开启SQL查询缓存
方式一:修改配置文件 追加配置信息
query_cache_type = 1
query_cache_size = 600000
windows下是my.ini
linux下是my.cnf
方式二:使用mysql命令
set global query_cache_type = 1;
查询是否开启缓存
show variables like ‘%profiling%’;
MySQL存储数据结构
追求高效率的查询速度 B+树
B 树
时间复杂度
O (log 2 N)
非叶子结点存储数据
磁盘存的节点元素少,需要更多的磁盘IO操作
查询需一层一层匹配,范围查询需要遍历
删除节点将导致树重排
B+ 树
时间复杂度
O ( log 3 N )
- 3 度
非叶子结点不存储数据
磁盘存的节点元素多,能减少磁盘IO操作,一次IO操作能获取更多的索引信息
查询数据时只需查询叶子结点 且维护了双向指针,以链表的方式组织,支持范围查询
删除节点B+树不会重排
mysql为了防止B+树索引重排,当索引被删除时,非叶子节点并不会删除,而将叶子节点上的数据标记为无效,当表上的索引越删越多时,就会照成大量索引空洞,能找到非叶子节点的索引信息,但叶子结点上数据无效
注意索引空洞就是由此产生,由于索引不断被删除,导致索引产生空洞效应,解决方式:重新构建索引(删除以前的索引,再建新的索引)
Mysql存储引擎
InnoDB引擎
MySQL5.5之后的版本,默认都是采用InnoDB,InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。可以确保事务的完整提交(Commit)和回滚(Rollback)
聚蔟索引 (必须存在,且只有一个 )
非聚蔟索引
MyISAM存储引擎
MySQL5.5之前的默认存储引擎,MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM不支持事务和行级锁,有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
Archive(爱开悟)引擎
只能进行 insert操作和 select 操作,适合日志和数据采集(档案)类应用。Archive表比MyISAM表要小大约75%,比支持事务处理的InnoDB表小大约83%。
Memory引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表是非常有用。memory引擎是最快的,适合存放临时数据,数据都保存在内存中 当服务器重启后,数据都会丢失,但会保留表结构 memory使用的hash索引,hash索引不支持范围查询,且不支持排序
SQL执行顺序
from -> on -> join -> where -> group by ->having -> select ->distinct -> orderby -> limit
口诀 : 佛叫我干活.速度ol
索引优化
索引的定义:
索引是帮助MySQL高效获取数据的数据结构.索引本质就是数据结构,排好序的数据结构
存储位置
数据库索引存储在磁盘上,InnoDB读取磁盘数据时以页为基本单位,MySQL默认的页大小是16KB(16384K)
索引的优劣势
优势
提高数据检索效率,减少IO成本
降低数据排序成本,减少 CPU消耗
劣势
索引实际上也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
降低了表的更新速度
MySQL索引
聚蔟索引和非聚蔟索引
聚蔟索引
生成
-
表中有主键:以表中的主键构造一颗B+树
-
表中无主键
- 有唯一索引,用第一个唯一索引作为聚蔟索引
- 无主键无唯一索引,用表的行号构建聚蔟索引
树结构特点:叶子结点存储表行记录数据
查找数据特点: 找到聚蔟索引键,然后在叶子结点IO读取对应的数据
MySQL中一定有聚蔟索引,且只有一个,但目前只有InnoDB支持聚蔟索引,MYISAM不支持
非聚蔟索引(二级索引)
生成:除了作为聚蔟索引外的其他索引都是非聚蔟索引
树结构特点: 叶子结点存储聚蔟索引的索引键
查找数据特点: 找到非聚蔟索引键,获取对应的聚蔟索引键,然后再去聚蔟索引表中根据聚蔟索引键IO读取对应的数据 ( 回 表 ) 应尽量避免回表操作,每一次回表可能都是一次IO操作
索引相关语法
创建索引
create index 索引名(index_xxx) on 表名(字段名)
创建前缀索引
create index index字段名前缀数 on 表名( 字段 ( 前缀数 ) )
创建联合索引
create index index字段名1字段名n on 表名( 字段名1 , 字段名n )
删除索引
drop index 索引名 on 表名
查询表索引
show INDEX from 表名
索引分类
单值索引
为单独某一个字段建立索引
唯一索引
确定某一列的值一定是唯一的,且经常被用来查询就可以作为唯一索引. 主键索引就是唯一索引
主键索引
MySQL在创建表时,我们指定那个字段作为主键,MySQL默认为主键建立索引,如果在创建表时没有指定主键,MySQL就不会创建主键索引.但是会有一个隐式索引(以行号作为索引)
复合索引(联合索引)
使用多个字段作为索引,联合索引使用得当可以避免回表查询
- 最左前缀原则 最左边的列必须存在,否则联合索引将失效
- 使用联合索引时,如果跳过了某一列,后面的列索引将失效
- 范围查询时,大于小于后的列索引将失效,尽量使用大于等于,或者小于等于
- 尽量做到覆盖索引
索引的创建与否情况分类
需要创建索引
主键自动创建主键索引
频繁查询的字段应该创建索引
查询中与其他表关联的字段,作为外键的字段需要建立索引
排序的字段
分组的字段
- 先排序后去重
不需要创建索引
表记录太少
经常增删改的表
where查询中用不到的字段
索引设计原则
针对数据量大,且查询比较频繁的字段建立索引
针对于常作为查询条件的字段,如Group By,where ,order by
如果是字符串类型的字段,且字段的长度较长,可以根据字符串的特点,建立前缀索引
尽量使用联合索引,减少使用单例索引,查询时,联合索引可以覆盖索引,节省磁盘空间,避免回表,提高效率
控制索引的数量,索引并不多越多越好,索引也会占用大量的磁盘空间,且维护索引的待久很大,会影响增删改的效率
如果索引字段不能存储NULL值,在建表的时候,就使用 NOT NULL约束它 . 便于优化器优化
查询时不要用 * ,需要什么字段查询相应的字段 使用覆盖索引
索引失效的情况
对索引字段使用了函数运算,包括普通运算,索引失效
字符串类型的字段不加单引号,造成隐式类型转换,索引失效
模糊查询时,%加在前面,索引也会失效
or 连接的前后必须都有索引,任意一侧没有索引都将造成索引失效
数据分布影响 如果MySQL评估走全表扫描比走全索引更快,索引也将失效
范围查询后的联合索引将失效 < , > , !=
is not null 将导致索引失效 , is null 可以使用索引
索引优化分析
Optimizer优化器
处理掉一些常量表达式的预算,直接换算成常量值。并对 Query 中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等
Explain查看执行计划
语法
Explain sql语句
分组和排序的效率对比
分组需要先排序后去重,因此排序的效率高,分组的效率低
结果分析
id
-
代表一次查询的唯一ID
- 一次sql语句的执行 id相同从上到下,id不同由大到小
- 从图中可以看到 有两个 id相同都为2 此时执行顺序从上往下 还有个id为1 先大后小 id为2的都执行完毕后执行id为1的
- 子查询将导致多躺查询,能少用子查询就少用,查询的趟数反应了IO的次数
- sql语句中有几个 select id的最大值就为多少 id值相同表示同一趟查询
select_type
-
代表此处查询的类型
- SIMPLE : 本次查询是一次简单查询,没有使用子查询,没有union
- PRIMARY : 本次查询是一次主查询
- SUBQUERY : 本次查询是一次子查询
- UNION : 本次查询使用了 UNION
- DERIVED : 派生表
table
- 此次操作的是哪张表
partitions
- 分区
type
-
代表MySQL怎么带着这个表进行查询(连接)
-
system
- 此次查询直接返回结果(查询的是MySQL的系统信息) ,无需查询数据库
-
const
- 此次查询一次性(读一次索引数据)就查询出来了
-
eq_ref
-
和外表关联用到索引,而且主表的关联字段在外表只能搜索到唯一一个数据
- ref:引用
- eq:等值
- eq_ref:等值引用;多表联查的使用,A的数据和B是唯一关联
-
-
ref
- 代表是一个多值引用. 和外表关联两者都用到索引,而且主表的关联字段在外表能搜索到多个数据
-
range
-
索引字段进行了区间查询
- between and
- in (…)
-
= and <=
-
-
index
-
全索引扫描,代表只需要遍历索引树就够了
- select 的 字段 必须是索引 (非聚蔟索引字段与聚蔟索引字段)
-
-
all
- 全表扫描
-
-
连接性能(由高到底)
- system -> const -> eq_ref -> ref -> index_merge -> range -> index -> all
possible_keys
- 可能用到索引的字段
key
- 查询实际用到的索引
key_len
-
实际用到的索引长度,字节数
-
计算公式
-
int
-
允许为NULL
- 4 + 1
-
不允许为NULL
- 4
-
-
bigint
-
允许为NULL
- 8 + 1
-
不允许为NULL
- 8
-
-
char(n)
-
允许为NULL
- 3 * n +1
-
不允许为NULL
- 3 * n
-
-
varchar(n)
-
允许为NULL
- 3 * n + 2(可变预留2个字节) +1
-
不允许为NULL
- 3 * n + 2
-
-
text(n)
-
允许为NULL
- 3 * n + 2(可变预留2个字节) +1
-
不允许为NULL
- 3 * n + 2
-
-
-
ref
- 显示出这个表和哪个表哪个列有引用关系,什么样的引用关系看type即可(ref、eq_ref)
rows
- 代表操作了这个表的多少行记录,越少越好
filtered
- 存储引擎给我们返回了多少行记录
Extra
-
MySQL给我们这次查询提供其他额外分析信息
-
Using filesort
- 使用文件排序; order by 后的字段没索引,或有索引用不上(出现这种情况应该对排序的字段建立索引)
-
Using where
- 查询带了where 条件
-
Using temporary
- 使用了临时表
-
Using index
-
索引覆盖
- 仅用索引就能得到所有数据了,不用回表查真实数据(select 的字段都是 索引的字段 不用回表查询就满足条件)
- 要查询的字段正好是非聚蔟索引的键和聚蔟索引的键
-
-
Backward 反向索引
- 对索引字段进行 降序排列
-
Using index condition
-
索引下推:
- 在对联合索引(二级索引 || 非主键索引)遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数
- 列如对非聚蔟索引的二级索引字段进行排序时,就会使用到索引下推
- 注意: 索引下推是5.6之后的新特性
-
-
impossible where
- mysql判断出这个sql的where条件不可能满足
- 列如 where id =1 and id = 2 这个where条件不可能满足
-
using join buffer
- 关联的字段无索引,出现这个提示,应考虑给关联查询的字段添加索引
-
SQL优化
insert 插入优化 三个方面
批量插入时使用 insert into 表名 values ( ),( )不要多次顺序插入, 使用mybatis的动态sql
使用手动提交事务 ,不要每次插入一条数据后就自动提交事务,频繁的创建提交事务损耗性能
插入数据的主键有序,主键顺序插入的速度高于主键乱序插入的速度
主键优化
两种页现象
页分裂现象
当数据页一和数据页二的数据都是满的时候,此时乱序插入一个主键需要插在其中一页的中间,那么innodb将此页百分之五十的位置后的数据移动到新创建的一页数据上,然后再将乱序的主键插入其中,然后再将新创建的一页放到数据页一和数据页二中间,并用双向链表维护 其目的是为了维护叶子结点的有序性
页合并现象
innodb中删除索引数据的时候,叶子结点的数据将标记为被删除(具体可参考索引空洞问题),当被标记为已删除的数据占到此页数据的百分之五十时,innodb将判断是否可以将前后其中一页的数据合并 其目的是为了节省空间
主键优化三个方法
主键长度不宜过长,占用空间,产生更多页,导致多次IO
主键插入的时候,保持有序,避免产生页分裂
不要使用uuid或者其他自然主键如身份证
UUID随机,造成主键乱序,产生页分裂
UUID长度过长,占用空间
order by 优化
避免 Using filesort ,追求 Using index
对排序的字段建立索引
order by排序时,使用 sleect * 是大忌,只查询需要的字段
单路与双路排序
单路排序
是一次性取出满足条件行的所有字段,然后在 排序缓存 中进行排序
- 速度快,占用内存空间
双路排序
先根据相应的条件取出相应的排序字段和可以直接定位行 数据的行 ID,然后在 排序缓存 中进行排序,排序完后需要再次回表取回其它需要的记录;
- 速度慢,节省内存空间
group by 优化
分组的字段建立索引
limit 分页优化
通过 覆盖索引与子查询以及范围查询进行优化
例如 select * from t limit 1900000,10
方式一
select id from t order by id limit 1900000,10
- 首先查询要查询范围内的主键,使用覆盖索引
select t.* from t , ( select id from t order by id limit 1900000,10 ) t1 where t.id = t1.id
- 再通过子查询 进行主键 eq_ref查询
方式二
select id from t limit 1900000,1
- 首先进行 const 查询 获取范围内第一个 主键id
select * from t,(select id from t limit 1900000,1) t1 where t.id > t1.id LIMIT 0,10
- 通过 const,range 查询 最后分页
count 优化
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回总行数
InnoDB则需要把数据从引擎中读出来,一行一行统计,不为nulll则进行按行累计,返回累计数 或者一个新表 再执行insert时,使用redis 把值count值加一 delete时把值减一
count(主键)
InnoDB引擎会遍历整张,把主键取出,然后返回给服务层,服务层拿到主键后 ,按行进行累加
count(字段)
没有not null约束
- InnoDB引擎会遍历整张,把字段取出,然后返回给服务层,服务层拿到主键后,判断是否为null,不为null,则按行进行累加
有not null约束
- InnoDB引擎会遍历整张,把字段取出,然后返回给服务层,服务层拿到主键后 ,按行进行累加
count(数字)
InnoDB引擎会遍历整张,不取值,服务器对于每一行都放进去一个对应的数字,直接按行累计
count(*) InnoDB引擎会遍历整张,不取值,服务器进行了专门的优,直接按行累计
count(非索引且没有进行 not null约束字段) 的字段时,特别注意 是会判断是否为null 为null则不累积
update优化
update 表名 set 字段名 = 值 where 字段名(该字段一定要加索引) = 值
更新的条件字段名一定要加索引,否则行锁将升级为表锁
MySQL主从复制
主从复制原理
slave开启线程从master读取binlog日志(二进制日志),拷贝到Readlog日志(中继日志)中,SQL线程再读取Readlog日志的内容
复制的基本原理
每个slave只能有一个master
每个slave都只能有一个唯一的服务器ID
每个master可以有多个slave
主机配置
修改核心配置文件my.cnf 中配置
server-id=1
log-bin=mysql-bin
binlog-ignore-db=mysql
binlog-ignore-db=infomation_schema
binlog-do-db=mytestdb
binlog_format=STATEMENT
主从所有配置项都配置在[mysqld]节点下,且都是小写字母
binlog_format
STATEMENT(默认)
- 语句级
- binlog会记录每次一执行写操作的语句,相对于ROW模式节省空间,但会产生数据不一致问题
- 列如主机执行 update tt set create_date=now() 由于从机的执行时间不一致,造成数据不一致
- 优点: 节省空间
- 缺点: 有可能造成数据不一致。
ROW
- 行级
- binlog会记录每次操作后每行记录的变化
- 优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
- 缺点:占用较大空间。
MIXED
- statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
主机上建立帐户并授权slave
GRANT REPLICATION SLAVE ON . TO ‘slave’@‘%’ IDENTIFIED BY ‘123456’;
flush privileges;
grant all privileges on . to root@‘%’ identified by ‘root’; # 创建一个root 用户,并授权远程访问!
flush privileges 记下File和Position的值
查询master的状态: show master status
执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
从机配置
server-id=2
relay-log=mysql-relay
修改核心配置文件my.cnf 中配置
[必须]从服务器唯一ID:server-id=2
[可选]启用中继日志:relay-log=mysql-relay
MASTER_USER=‘X’,MASTER_PASSWORD=‘X’,
CHANGE MASTER TO MASTER_HOST=‘mall_mysql_master’,MASTER_PORT=3306,MASTER_USER=‘slave’,MASTER_PASSWORD=‘123456’,MASTER_LOG_FILE=‘mysql-bin.000001’,MASTER_LOG_POS=0;
MASTER_LOG_FILE=‘mysql-bin.具体数字’,MASTER_LOG_POS=具体值;
启动从服务器复制功能
start slave;
查看状态
show slave status\G;
Slave_IO_Running: Yes
lave_SQL_Running: Yes
主从机重启配置生效
systemctl restart mysqld
主从机都关闭防火墙
ystemctl stop firewalld
停止从服务复制功能,重新配置主从
在从机上执行。功能说明:停止I/O 线程和SQL线程的操作
mysql> stop slave;
在从机上执行。功能说明:用于删除SLAVE数据库的relaylog日志文件,并重新启用新的relaylog文件。
mysql> reset slave;
用于第一次进行搭建主从库时,进行主库binlog初始化工作;
mysql> reset master;
对于支持事务的表,这两种模式是一样的:如果发现某个值缺失或非法,MySQL将抛出错误,语句会停止运行并回滚。
主键索引一定是聚蔟索引,聚蔟索引不一定是主键索引,还可能是唯一索引以及行号索引
两者都可作为聚蔟索引,优先主键索引作为聚蔟索引
两者速度最快,因为不需要取值
排序分组优化
无过滤,不索引
没有使用where 的时候 可以试着加上 limit
顺序错,必排序
联合索引的字段顺序错了,一定走全表排序
方向反,必排序
联合索引排序的字段排序规则必须一致,要么全升序,要么全降序,否则一定走全表排序
相关文章:
MySQL 面试知识脑图 初高级知识点
脑图下载地址:https://mm.edrawsoft.cn/mobile-share/index.html?uuid18b10870122586-src&share_type1 sql_mode 基本语法及校验规则 ONLY_FULL_GROUP_BY 对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现ÿ…...
【数据结构】二叉树的链式结构及实现
目录 1. 前置说明 2. 二叉树的遍历 2.1 前序、中序以及后序遍历 2.2 层序遍历 3. 节点个数及高度等 4. 二叉树的创建和销毁 1. 前置说明 在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二叉树结构…...

OpenCV4(C++)—— 创建窗口滑动条来调参
文章目录 创建滑动条 —— createTrackbar 创建滑动条 —— createTrackbar createTrackbar是OpenCV中的一个函数,用于创建一个可调节的滑动条(Trackbar),以便在图像处理过程中实时调整参数 int cv::createTrackbar(const String…...
深度学习基础知识 学习率调度器的用法解析
深度学习基础知识 学习率调度器的用法解析 1、自定义学习率调度器**:**torch.optim.lr_scheduler.LambdaLR2、正儿八经的模型搭建流程以及学习率调度器的使用设置 1、自定义学习率调度器**:**torch.optim.lr_scheduler.LambdaLR 实验代码: i…...

【JUC系列-12】深入理解PriorityQueue的底层原理和基本使用
JUC系列整体栏目 内容链接地址【一】深入理解JMM内存模型的底层实现原理https://zhenghuisheng.blog.csdn.net/article/details/132400429【二】深入理解CAS底层原理和基本使用https://blog.csdn.net/zhenghuishengq/article/details/132478786【三】熟练掌握Atomic原子系列基本…...
Paddle安装
Paddle安装参考 docs/tutorials/INSTALL_cn.md PaddlePaddle/PaddleDetection - Gitee.comhttps://gitee.com/paddlepaddle/PaddleDetection/blob/release/2.6/docs/tutorials/INSTALL_cn.md # 不指定版本安装paddle-gpu python -m pip install paddlepaddle-gpu# 测试安装 …...
配置XP虚拟机和Win 10宿主机互相ping通
文章目录 一、关闭虚机和宿主机的防火墙1、关闭虚拟机的防火墙1.1方式一1.2方式二 2、关闭宿主机的防火墙 二、设置XP和宿主机VMnet8的IP地址、网关和DNS1、获取VMWare的虚拟网络配置信息2、设置XP的VMnet8的IP地址、网关和DNS3、设置宿主机VMnet8的IP地址、网关和DNS 三、获取…...
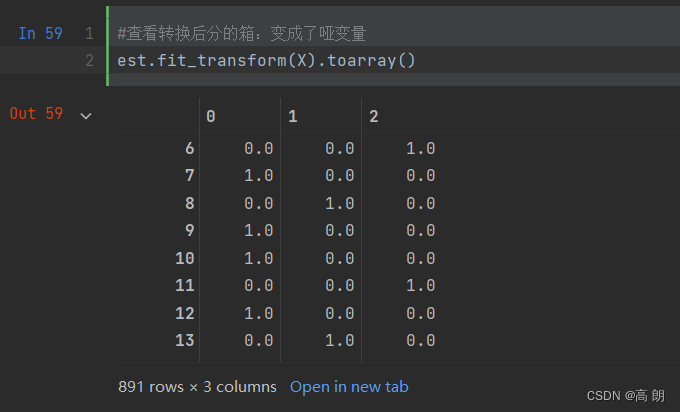
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤 数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据 通过pandas读取数据,通过head和info方法大致查…...

【智慧燃气】智慧燃气解决方案总体概述--终端层、网络层
关键词:智慧燃气、智慧燃气系统、智慧燃气平台、智慧燃气解决方案、智慧燃气应用、智能燃气 智慧燃气解决方案是基于物联网、大数据、云计算、移动互联网等先进技术,结合燃气行业特征,通过智能设备全面感知企业生产、环境、状态等信息的全方…...

Tomcat隔离web原理和热加载热部署
Tomcat 如何打破双亲委派机制 Tomcat 的自定义类加载器 WebAppClassLoader 打破了双亲委派机制,它首先自己尝试去加载某个类,如果找不到再代理给父类加载器,其目的是优先加载 Web 应用自己定义的类。具体实现就是重写 ClassLoader 的两个方法…...
使用ffmpeg和python脚本下载网络视频m3u8(全网最全面)
网上给娃找了些好看的电影和一些有趣的短视频,如何保存下来呢?从网上找各种工具?都不方便。于是想到何不编程搞定,搞个脚本。对程序员来说这都不是事儿。且我有华为云服务器,完全可以把地址记下,后台自动下…...
【考研408常用数据结构】C/C++实现代码汇总
文章目录 前言数组多维数组的原理、作用稀疏数组 链表单向链表的增删改查的具体实现思路约瑟夫环问题(可不学)双向链表 树二叉搜索树中序线索二叉树哈夫曼树的编码与译码红黑树B树B树 堆顺序与链式结构队列实现优先队列排序算法(重点…...

Flink学习笔记(二):Flink内存模型
文章目录 1、配置总内存2、JobManager 内存模型3、TaskManager 内存模型4、WebUI 展示内存5、Flink On YARN 模式下内存分配6、Flink On Yarn 集群消耗资源估算6.1、资源分配6.2、Flink 提交 Yarn 集群的相关命令6.3、Flink On Yarn 集群的资源计算公式 1、配置总内存 Flink J…...
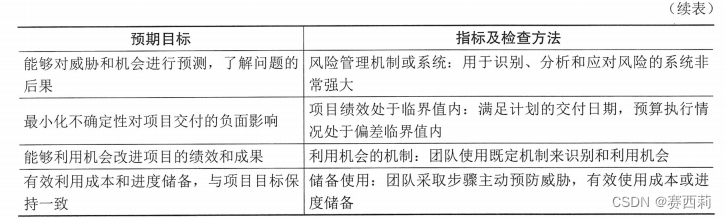
信息系统项目管理师第四版学习笔记——项目绩效域
干系人绩效域 干系人绩效域涉及与干系人相关的活动和职能。在项目整个生命周期过程中,有效执行本绩效域可以实现的预期目标主要包含:①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度…...

PyTorch 深度学习之加载数据集Dataset and DataLoader(七)
1. Revision: Manual data feed 全部Batch:计算速度,性能有问题 1 个 :跨越鞍点 mini-Batch:均衡速度与性能 2. Terminology: Epoch, Batch-Size, Iteration DataLoader: batch_size2, sheffleTrue 3. How to define your Dataset 两种处…...

小谈设计模式(26)—中介者模式
小谈设计模式(26)—中介者模式 专栏介绍专栏地址专栏介绍 中介者模式分析角色分析抽象中介者(Mediator)具体中介者(ConcreteMediator)抽象同事类(Colleague)具体同事类(C…...

7种设计模式
1. 工厂模式 优点:封装了对象的创建过程,降低了耦合性,提供了灵活性和可扩展性。 缺点:增加了代码的复杂性,需要创建工厂类。 适用场景:当需要根据不同条件创建不同对象时,或者需要隐藏对象创建…...
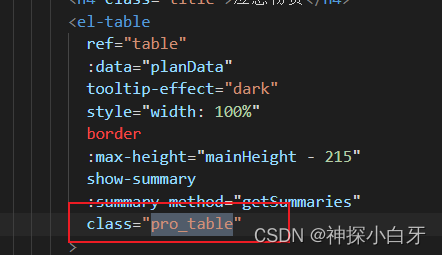
el-table合计行合并
效果如下 因为合计el-table的合并方法是不生效的,所以需要修改css下手 watch: {// 应急物资的合计合并planData: {immediate: true,handler() {setTimeout(() > {const tds document.querySelectorAll(".pro_table .el-table__footer-wrapper tr>td");tds[0]…...

新手如何快速上手HTTP爬虫IP?
对于刚接触HTTP爬虫IP的新手来说,可能会感到有些困惑。但是,实际上HTTP爬虫IP并不复杂,只要掌握了基本的操作步骤,就可以轻松使用。本文将为新手们提供一个快速上手HTTP爬虫IP的入门指南,帮助您迅速了解HTTP爬虫IP的基…...
(十五)VBA常用基础知识:正则表达式的使用
vba正则表达式的说明 项目说明Pattern在这里写正则表达式,例:[\d]{2,4}IgnoreCase大小写区分,默认false:区分;true:不区分Globaltrue:全体检索;false:最小匹配Test类似p…...

DownKyi终极指南:B站视频下载与管理的完整专业解决方案
DownKyi终极指南:B站视频下载与管理的完整专业解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性
ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一个开源的Windows内核模式…...

tars 环境安装及开发部署
参考:https://tarscloud.github.io/TarsDocs/installation/source-windows.html 安装环境 安装nodejs、vs(已安装了vs2022)、cmake(已安装,版本是3.30.0)、git(已安装,版本是2.45.2)、Mysql 下载并安装nodejs https://nodejs.org/en/ 版本是22.15.0 添加到环…...

为什么你需要一个完整的Unity历史版本下载库?开发者必备的版本管理解决方案
为什么你需要一个完整的Unity历史版本下载库?开发者必备的版本管理解决方案 【免费下载链接】download.unity.com Unity国际版下载,解决国内打不开网站和被重定向的问题 项目地址: https://gitcode.com/gh_mirrors/do/download.unity.com 在游戏开…...

3步解锁iOS应用自由:AltStore免越狱安装终极指南
3步解锁iOS应用自由:AltStore免越狱安装终极指南 【免费下载链接】AltStore AltStore is an alternative app store for non-jailbroken iOS devices. 项目地址: https://gitcode.com/gh_mirrors/al/AltStore 还在为iOS设备上无法自由安装应用而烦恼吗&#…...

CANN/asc-devkit asc_any函数
asc_any 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

uniCloud云函数实战:从‘Hello World’到连接数据库的完整数据流指南
uniCloud云函数实战:从‘Hello World’到连接数据库的完整数据流指南 在当今快速迭代的互联网开发领域,后端服务的轻量化与敏捷部署已成为开发者关注的焦点。uniCloud作为一款面向全栈开发的云服务平台,其云函数功能让前端开发者也能轻松处理…...

KING大咖直播|驯服时间洪流:电科金仓KES时序版“硬核”解码
设备互联、生产监控、交易行情……时序数据正以指数级速度狂奔,传统数据库频频掉队?电科金仓KES时序版,用“一库多模”破题:千万级并发写入稳如磐石、20倍压缩比瘦身立现、高密度写入与实时分析同框——这是国产时序数据库交出的一…...

半波整流电路:从原理到实践,掌握AC-DC转换基础
1. 项目概述:从交流到直流的第一步在电子电路的世界里,我们常常需要将交流电(AC)转换为直流电(DC),这个过程我们称之为“整流”。而半波整流电路,可以说是所有整流电路中最基础、最经…...

中间件简单题目教学
题目1:环境搭建与简单模式使用 Docker 启动 RabbitMQ 4.x 容器,用户 guest,密码 123456,映射管理端口 15672。编写 Java 原生生产者,向队列 test_queue 发送消息 "Hello Exam"。编写 Java 原生消费者&#x…...