【TensorFlow2 之012】TF2.0 中的 TF 迁移学习
#012 TensorFlow 2.0 中的 TF 迁移学习

一、说明
在这篇文章中,我们将展示如何在不从头开始构建计算机视觉模型的情况下构建它。迁移学习背后的想法是,在大型数据集上训练的神经网络可以将其知识应用于以前从未见过的数据集。也就是说,为什么它被称为迁移学习;我们将现有模型的学习转移到新的数据集中。
教程概述:
- 介绍
- 使用内置的 TensorFlow 模型进行迁移学习
- 使用 TensorFlow Hub 进行迁移学习
二、为什么迁移学习简介
之 我们已经探讨了如何使用数据增强来提高模型性能。现在的问题是,“如果我们没有足够的数据来从头开始训练我们的网络怎么办?
对 此的解决方案是使用迁移学习方法。一篇更具理论意义的帖子已经发布在我们的博客上。如果需要,请查看它以刷新一些想法。我们可以使用迁移学习将知识从一些预先训练好的开源网络转移到我们自己的简历问题中。
计 算机视觉研究社区在互联网上发布了许多数据集,如Imagenet或MS Coco或Pascal数据集。许多计算机视觉研究人员已经在这些数据集上训练了他们的算法。有时,此培训需要数周时间,并且可能需要许多 GPU。事实上,其他人已经完成了这项任务并经历了痛苦的高性能研究过程,这意味着我们经常可以下载开源权重。
有 很多网络已经过训练。例如,Imagenet 数据集,它由 1000 个不同的类和超过 14 万张图像组成。因此,网络可能有一个 softmax 单元,它输出一千个可能的类之一。我们可以做的是摆脱softmax层并创建我们自己的输出单元来表示例如猫或狗。
由于我们使用下载的权重,我们将只训练与我们的输出层关联的参数,在我们的例子中,这将是一个 sigmoid 输出层。
三、使用内置的 TensorFlow 模型进行迁移学习
让我们首先为训练准备数据集。我们将使用 wget.download 命令下载数据集。之后,我们需要解压缩它并合并训练和测试部分的路径。
import os
import wget
import zipfile
wget.download("https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip")with zipfile.ZipFile("cats_and_dogs_filtered.zip","r") as zip_ref:zip_ref.extractall()base_dir = 'cats_and_dogs_filtered'train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
现在,让我们导入所有必需的库并构建模型。我们将使用一个名为MobileNetV2的预训练网络,该网络在ImageNet数据集上进行训练。在这里,我们希望使用除顶部分类图层之外的所有图层,因此我们不会将它们包含在我们的网络中。
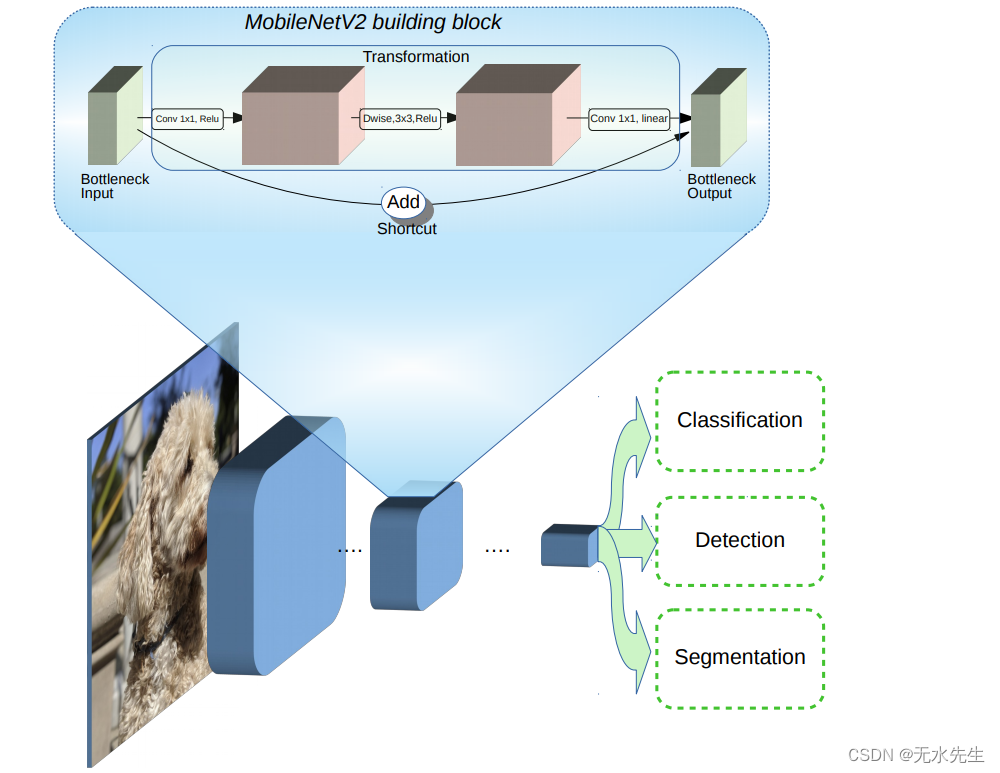
obileNetV2 体系结构概述:https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html
这 个模型和其他预训练模型已经在TensorFlow中可用。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as mpimgfrom tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.preprocessing.image import ImageDataGeneratorbase_model = MobileNetV2(input_shape=(224, 224, 3),include_top=False,weights='imagenet')base_model.summary()如
输出:
Model: "mobilenetv2_1.00_224"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
Conv1_pad (ZeroPadding2D) (None, 225, 225, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
Conv1 (Conv2D) (None, 112, 112, 32) 864 Conv1_pad[0][0]
__________________________________________________________________________________________________
bn_Conv1 (BatchNormalization) (None, 112, 112, 32) 128 Conv1[0][0]
__________________________________________________________________________________________________
Conv1_relu (ReLU) (None, 112, 112, 32) 0 bn_Conv1[0][0]
__________________________________________________________________________________________________
expanded_conv_depthwise (Depthw (None, 112, 112, 32) 288 Conv1_relu[0][0] 果最后一层输出不同数量的类,那么我们需要有自己的输出单元来输出以下类:猫或狗。有几种方法可以做到这一点:
- 取最后几层的权重,将它们用作初始化并进行梯度下降。这样,我们将重新训练网络的一部分。
- 删除最后几层的权重,使用我们自己的新隐藏单元和我们自己的最终 sigmoid(或 softmax)输出。通过这种方式,我们可以更改输出的数量。
因此,这两种方法中的任何一种都值得尝试。
现在让我们冻结预训练层并添加一个新层,称为 GlobalAveragePooling2D,之后是具有 sigmoid 激活函数的 Dense 层。
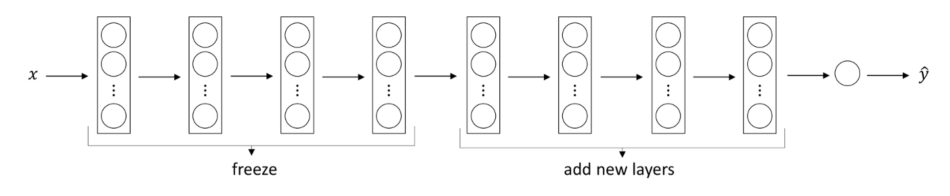
现
base_model.trainable = Falsemodel = Sequential([base_model,GlobalAveragePooling2D(),Dense(1, activation='sigmoid')])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
mobilenetv2_1.00_224 (Model) (None, 7, 7, 1280) 2257984
_________________________________________________________________
global_average_pooling2d (Gl (None, 1280) 0
_________________________________________________________________
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________现在是训练步骤的时候了。我们将使用图像数据生成器来迭代图像。现在没有必要为大量时期训练网络,因为我们已经预先训练了一部分网络。
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])train_datagen = ImageDataGenerator(rescale=1./255)
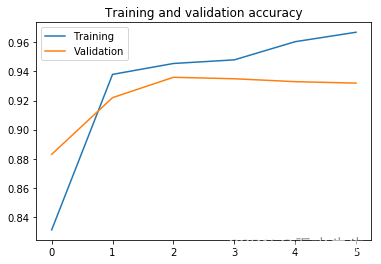
val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(224, 224),batch_size=32,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(224, 224),batch_size=32,class_mode='binary')history = model.fit(train_generator,epochs=6,validation_data=validation_generator,verbose=2)让 我们看看结果。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy, label="Training")
plt.plot(epochs, val_accuracy, label="Validation")
plt.legend()
plt.title('Training and validation accuracy')
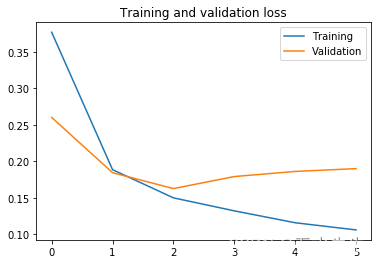
plt.figure()plt.plot(epochs, loss, label="Training")
plt.plot(epochs, val_loss, label="Validation")
plt.legend()
plt.title('Training and validation loss')3.Text(0.5, 1.0, 'Training and validation loss')
四、 使用 TensorFlow Hub 进行迁移学习
访问预训练模型的另一种方法是TensorFlow Hub。TensorFlow Hub是一个库,用于发布,发现和使用机器学习模型的可重用部分。您可以在此处找到更多预训练模型。
我们将冻结图层并添加一个用于分类的新图层。全连接网络的输入称为瓶颈要素。它们表示网络中最后一个卷积层的激活图。
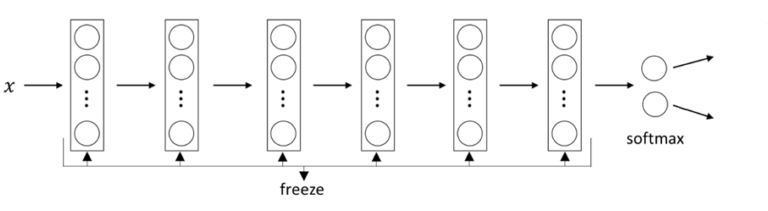
让
在这里,我们也可以使用 TensorBoard,但这次让我们保持简单。
最后,让我们可视化一些预测。在此数据集中,猫标记为 0,狗标记为 1。我们将用蓝色显示正确的预测,用红色显示假。

五、总结
正如我们在上面看到的,使用迁移学习可以帮助我们在短时间内取得非常好的结果。使用数据增强,可以进一步增强结果。
在下一篇文章中,我们将展示如何创建网络并将其转换以在移动设备上使用。
相关文章:
【TensorFlow2 之012】TF2.0 中的 TF 迁移学习
#012 TensorFlow 2.0 中的 TF 迁移学习 一、说明 在这篇文章中,我们将展示如何在不从头开始构建计算机视觉模型的情况下构建它。迁移学习背后的想法是,在大型数据集上训练的神经网络可以将其知识应用于以前从未见过的数据集。也就是说,为什么…...

mysql面试题46:MySQL中datetime和timestamp的区别
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:MySQL中DATETIME和TIMESTAMP的区别 在MySQL中,DATETIME和TIMESTAMP是两种用于存储日期和时间的数据类型。虽然它们都可以用于存储日期和时间信息…...

【Spring Boot】RabbitMQ消息队列 — RabbitMQ入门
💠一名热衷于分享知识的程序员 💠乐于在CSDN上与广大开发者交流学习。 💠希望通过每一次学习,让更多读者了解我 💠也希望能结识更多志同道合的朋友。 💠将继续努力,不断提升自己的专业技能,创造更多价值。🌿欢迎来到@"衍生星球"的CSDN博文🌿 🍁本…...
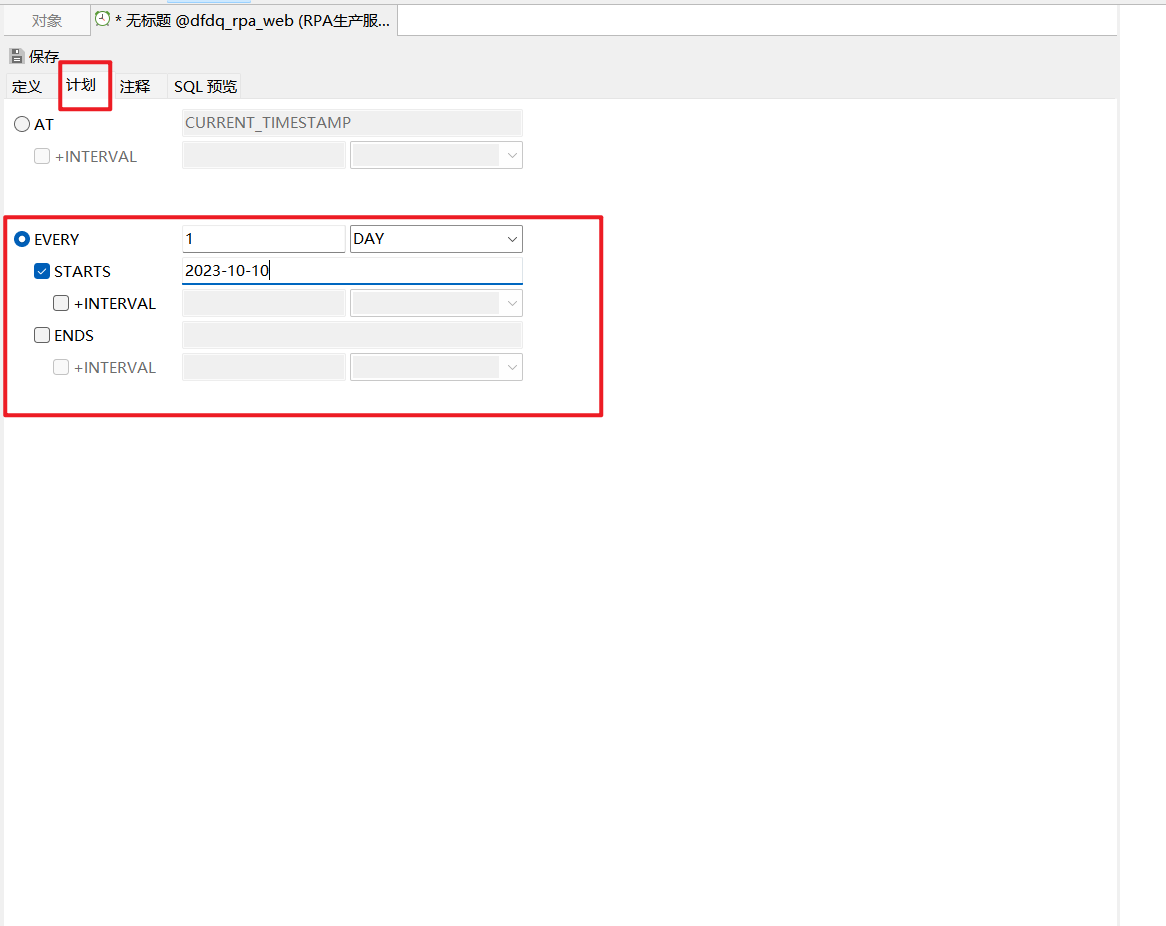
Navicat定时任务
Navicat定时任务 1、启动Navicat for MySQL工具,连接数据库。 2、查询定时任务选项是否开启 查询命令:SHOW VARIABLES LIKE ‘%event_scheduler%’; ON表示打开,OFF表示关闭。 打开定时任务命令 SET GLOBAL event_scheduler 0; 或者 SET G…...
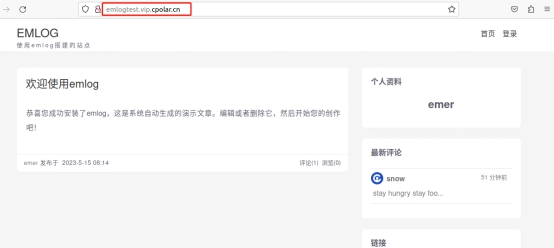
小白必备:简单几步, 使用Cpolar+Emlog在Ubuntu上搭建个人博客网站
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

封装 Token
什么是token? 作为计算机术语,是“令牌”的意思 。 Token 是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请…...
——点云添加均匀分布的随机噪声)
CloudCompare 二次开发(17)——点云添加均匀分布的随机噪声
目录 一、概述二、代码集成三、结果展示一、概述 不依赖任何第三方点云相关库,使用CloudCompare编程实现点云添加随机噪声。添加随机噪声的算法原理见:PCL 点云添加均匀分布的随机噪声。 二、代码集成 1、mainwindow.h文件public中添加: void doActionAddRandomNoise(); …...

研发必会-异步编程利器之CompletableFuture(含源码 中)
近期热推文章: 1、springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表; 2、SpringBoot用线程池ThreadPoolTaskExecutor异步处理百万级数据; 3、基于Redis的Geo实现附近商铺搜索(含源码) 4、基于Redis实现关注、取关、共同关注及消息推送(含源码) 5…...
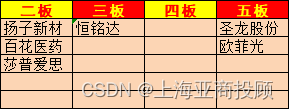
上海亚商投顾:沪指高开高走 锂电等新能源赛道大反攻
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日高开后强势震荡,创业板指盘中一度翻绿,随后探底回升再度走高。碳酸锂期货合约…...
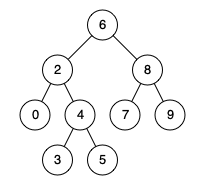
力扣第235题 二又搜索树的最近公共祖先 c++
题目 235. 二叉搜索树的最近公共祖先 中等 (简单) 相关标签 树 深度优先搜索 二叉搜索树 二叉树 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q&…...

时代风口中的Web3.0基建平台,重新定义Web3.0!
近年来,Web3.0概念的广泛兴起,给加密行业带来了崭新的叙事方式,同时也为加密行业提供了更加具有想象力的应用场景与商业空间,并让越来越多的行业从业者们意识到只有更大众化的市场共性需求才能推动加密市场的持续繁荣。当前围绕这…...
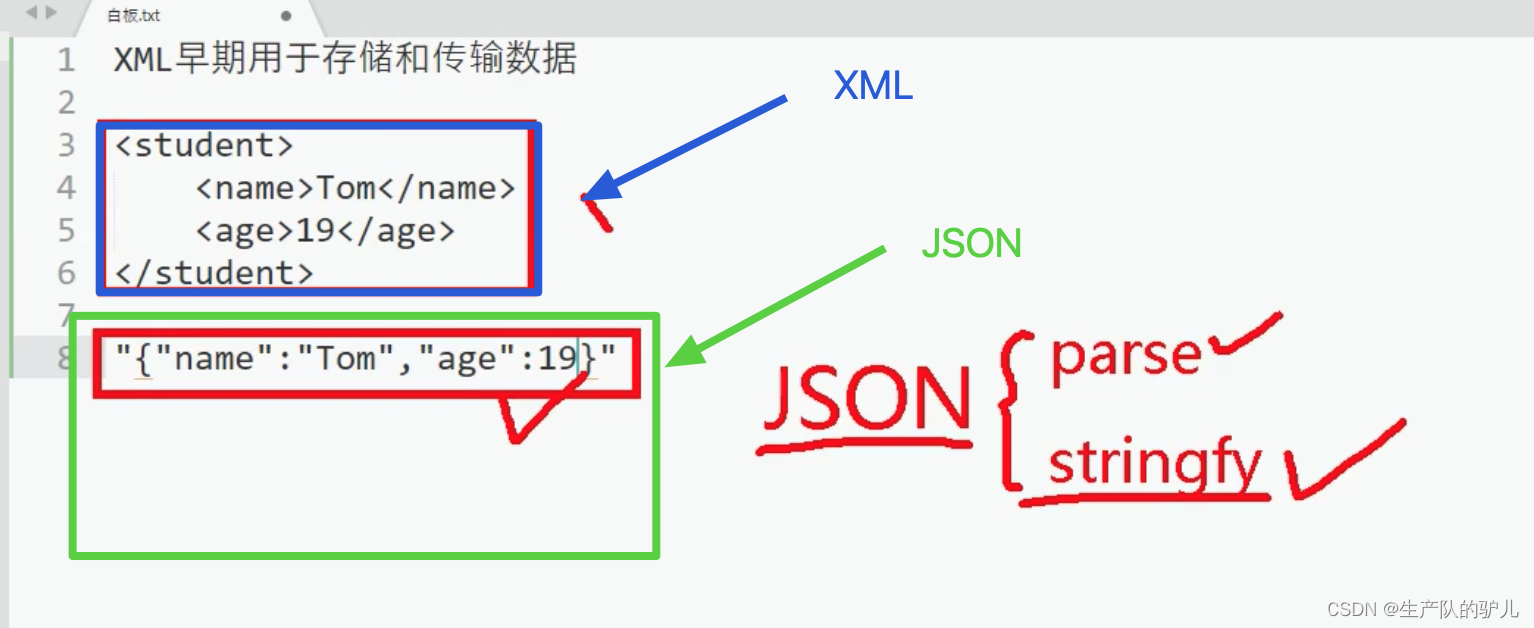
React学习笔记 001
什么是React 1.发送请求获取数据 处理数据(过滤、整理格式等) 3.操作DOM呈现页面 react 主要是负责第三部 操作dom 处理页面 数据渲染为HTML视图的开源js库。 好处 避免dom繁琐 组件化 提升复用率 特点 声明式编程: 简单 组件化编程…...
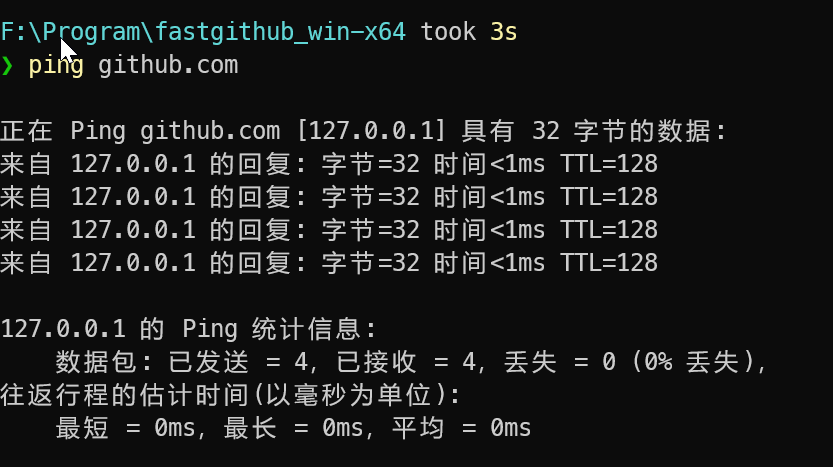
2023 | github无法访问或速度慢的问题解决方案
github无法访问或速度慢的问题解决方案 前言: 最近经常遇到github无法访问, 或者访问特别慢的问题, 在搜索了一圈解决方案后, 有些不再有效了, 但是其中有几个还特别好用, 总结一下. 首选方案 直接在github.com的域名上加一个fast > githubfast.com, 访问的是与github完全相…...
unity各种插件集合(自用)
2D Animation——2D序列帧/骨骼动画相关 2D PSD Importer——psb骨骼动画(unity官方建议使用psb而非psd) (Advanced —show preview package 勾选)出现 2D IK——反向动力学IK Universal RP——升级项目到Urp(通用渲…...
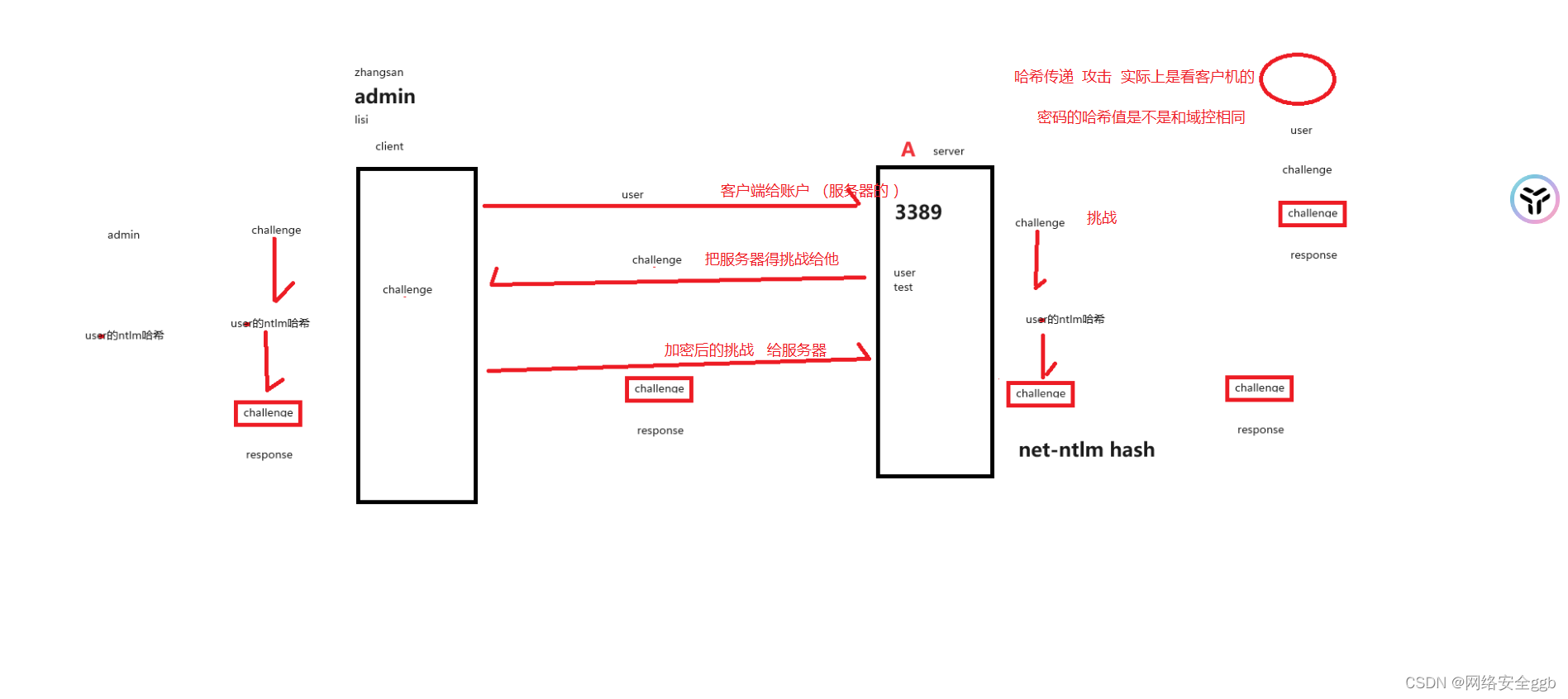
内网收集哈希传递
1.内网收集的前提 获得一个主机权限 补丁提权 可以使用 systeminfo 然后使用python脚本找到缺少的补丁 下载下来 让后使用exp提权 收集信息 路由信息 补丁接口 dns域看一看是不是域控 扫描别的端口 看看有没有内在的web网站 哈希传递 哈希是啥 哈希…...

前端目录笔记
HTML HTML 笔记:初识 HTML(HTML文本标签、文本列表、嵌入图片、背景色、网页链接)-CSDN博客html 笔记:CSS_UQI-LIUWJ的博客-CSDN博客HTML 笔记 表格_UQI-LIUWJ的博客-CSDN博客 javascript JavaScript 笔记 初识JavaScript&…...

Sui主网升级至V1.11.2版本
Sui主网现已升级至V1.11.2版本,同时Sui协议升级至27版本。其他升级要点如下: 对于一些更高级别的交易,更改了一些gas费设置,使其gas费消耗的更快。这些更改不影响以前在网络上运行的任何交易,只是为了确保在开始大量使…...

Mysql-数据库和数据表的基本操作
Mysql数据库和数据表的基本操作 一.数据库 1.创建数据库 创建数据库就是在数据库系统中划分一块空间存储数据 (1)语法 create database 数据库名称;(2)查看数据库 show create database 数据库名;(3)…...
拓扑排序求最长路
P1807 最长路 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目要求我们求出第1号到第n号节点之间最长的距离。 我们想到使用拓扑排序来求最长路。 正常来讲,我们应该把1号节点入队列,再出队列,把一号节点能到达的所有的点的入度减一&a…...

sqli-lab靶场通关
文章目录 less-1less-2less-3less-4less-5less-6less-7less-8less-9less-10 less-1 1、提示输入参数id,且值为数字; 2、判断是否存在注入点 id1报错,说明存在 SQL注入漏洞。 3、判断字符型还是数字型 id1 and 11 --id1 and 12 --id1&quo…...
)
手把手教你用STM32F103C8T6驱动NRF24L01模块(附完整代码与避坑指南)
STM32F103C8T6与NRF24L01无线通信实战:从硬件对接到代码调试全解析 在物联网和智能硬件快速发展的今天,无线通信技术已成为嵌入式系统设计中不可或缺的一环。NRF24L01作为一款性价比极高的2.4GHz无线收发模块,配合STM32F103C8T6这类主流微控制…...

蓝桥杯嵌入式LCD显示避坑指南:sprintf函数格式化变量显示的正确姿势
蓝桥杯嵌入式LCD显示避坑指南:sprintf函数格式化变量显示的正确姿势 在蓝桥杯嵌入式竞赛中,LCD显示是基础但至关重要的环节。许多参赛选手在实现变量动态显示时,常常因为对sprintf函数的使用不当而陷入各种"坑"中——数据显示不全、…...

车规级LGA封装RK3588开发板:硬件设计与车规应用实战解析
1. 项目概述:当“车规级”遇上“LGA封装”的RK3588 最近在嵌入式圈子里,一个消息引起了不小的讨论:深圳市九鼎创展科技推出了一款搭载LGA封装核心板的RK3588开发板,并且主打车规级应用。对于长期在工业控制和边缘计算领域摸爬滚打…...

VT2516A板卡进阶玩法:模拟汽车线束开路/短路故障,做更真实的ECU诊断测试
VT2516A板卡实战:构建汽车线束故障注入测试系统 在汽车电子控制系统开发中,ECU对电气故障的检测和处理能力直接关系到整车安全性和可靠性。传统测试方法往往局限于理想工况下的信号模拟,难以覆盖真实车辆可能遭遇的线束开路、短路等异常场景…...

这几家有机膨润土厂家口碑稳定,你选对了吗?
在工业与新材料领域,有机膨润土作为一种关键的功能性添加剂,正从“幕后”走向“台前”。无论是涂料、油墨的流变控制,还是钻井液、润滑脂的耐温需求,又或是农药、兽药的载体优化,它的身影无处不在。然而,面…...
4种颠覆性组合:重构Pixelle-Video的模块化潜能
4种颠覆性组合:重构Pixelle-Video的模块化潜能 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 想象一下:输入&qu…...

OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查!
更多请点击: https://kaifayun.com 第一章:OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查! 当你调用 DeepSeek 的 OAuth 2.0 接口(如 /v1/auth/token)时&am…...
:数据通路与控制器的“双人舞“)
从沙子到车辙(3.3):数据通路与控制器的“双人舞“
3.3 数据通路与控制器的"双人舞" 📚 本文内容摘自本人的开源书《从沙子到车辙 - 一个工程师的理解》 🔗 在线阅读/下载:from-sand-to-ruts git clone https://github.com/Lularible/from-sand-to-ruts⭐ 如果对您有帮助…...

Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿
Bilibili视频转文字完整指南:一键将B站视频转为可编辑文字稿 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为观看Bilibili视频时需要做…...

测试TVS:SP0503BAHTG
简 介: 本文测试了SP0503BAHTG三通道TVS二极管阵列的特性。通过设计测试电路板,测量了该器件对1kHz正弦波的限幅效果,测得反向导通电压约-0.8V,顶部饱和电压6.3V。在1MHz高频测试中观察到快速响应特性,通过矩形波上升沿…...