【第二章 - 线性表之顺序表】- 数据结构(八千字详解)
目录
一、线性表的定义和特点
二、线性表的顺序表示和实现
2.1 - 线性表的顺序存储表示
2.2 - 顺序表中基本操作的实现
三、练习
3.1 - 移除元素
3.2 - 删除有序数组中的重复项
3.3 - BC100 有序序列合并
3.4 - 88.合并两个有序数组
四、顺序表的问题及思考
线性表、栈、队列、串和数组都属于线性结构。线性结构的基本特点是除了第一个元素无直接前驱,最后一个元素无直接后继之外,其他每个数据元素都有一个前驱和后继。线性表是最基本且最常用的一种线性结构,同时也是其他数据结构的基础,尤其单链表,是贯穿整个数据结构课程的基本技术。
一、线性表的定义和特点
由 n(n >= 0)个数据特性相同的元素构成的有限序列称为线性表(Linear List)。
线性表中元素的个数 n(n >= 0)定义为线性表的长度,n = 0 时称为空表。
对于非空的线性表或线性结构,其特点是:
-
存在唯一的一个被称作"第一个"的数据元素;
-
存在唯一的一个被称作"最后一个"的数据元素;
-
除第一个外,结构中的每个数据元素均只有一个前驱;
-
除最后一个外,结构中的每个数据元素均只有一个后继。
二、线性表的顺序表示和实现
2.1 - 线性表的顺序存储表示
线性表的顺序表示指的是用一组地址连续的存储单元依次存放线性表的数据元素,这种表示也称作线性表的顺序存储结构或顺序映像。
顺序存储结构的线性表又称为顺序表(Sequential List)。其特点是,逻辑上相邻的数据元素,其物理次序也是相邻的。
线性表的顺序存储结构是一种随机存取的存储结构,即只要确定了线性表的起始位置(基地址),线性表中任一数据元素都可以在 O(1) 时间内存取。
由于高级程序设计语言中的数组类型也有随机存取的特性,因此,可以用数组来描述数据结构中的顺序存储结构。
顺序表的静态存储:
#define MAXSIZE 100 // 静态顺序表可能达到的最大长度
typedef struct SeqList
{SLDataType elem[MAXSIZE];int count;
}SeqList;元素类型定义中的
SLDataType数据类型是为了描述统一而自定义的,在实际应用中,用户可根据实际需要具体定义表中数据元素的数据类型,例如typedef int SLDataType;。
count不仅能表示顺序表中当前数据元素的个数,还能表示第一个未存放数据元素的数组下标。
不过静态顺序表的缺点也是很明显的,其只适用于确定知道需要存储多少数据元素的场景,因为静态顺序表的定长数组如果开大了,可能导致浪费,但如果开小了,又可能不够用。所以现实中基本都是使用动态顺序表,根据需要动态分配空间大小。顺序表的动态存储:
typedef struct SeqList
{SLDataType* elem;int count;int capacity; // 动态顺序表的最大容量
}SeqList;2.2 - 顺序表中基本操作的实现
SeqList.h:
#pragma once// 动态顺序表
typedef int SLDataType;#define DEFAULT_CAPACITY 5 // 容量的默认大小typedef struct SeqList
{SLDataType* elem;int count;int capacity;
}SeqList;// 基本操作
typedef int Status;#define OK 1
#define ERROR 0void SeqListInit(SeqList* psl); // 初始化Status CheckCapacity(SeqList* psl); // 检查当前数据元素个数,考虑是否需要扩容void SeqListPushBack(SeqList* psl, SLDataType e); // 尾插void SeqListPopBack(SeqList* psl); // 尾删void SeqListPushFront(SeqList* psl, SLDataType e); // 头插void SeqListPopFront(SeqList* psl); // 头删void SeqListInsert(SeqList* psl, int pos, SLDataType e); // 在 pos 位置插入 evoid SeqListErase(SeqList* psl, int pos); // 删除 pos 位置的元素int SeqListFind(SeqList* psl, SLDataType e); // 查找void SeqListPrint(SeqList* psl); // 打印 void SeqListDestroy(SeqList* psl); // 销毁SeqList.c:
#define _CRT_SECURE_NO_WARNINGS 1#include "SeqList.h"
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>// 初始化
void SeqListInit(SeqList* psl)
{assert(psl);psl->elem = (SLDataType*)malloc(sizeof(SLDataType) * DEFAULT_CAPACITY);if (NULL == psl->elem){perror("malloc failed!");exit(1);}psl->count = 0;psl->capacity = DEFAULT_CAPACITY;
}// 检查当前数据元素个数,考虑是否需要扩容
Status CheckCapacity(SeqList* psl)
{assert(psl);if (psl->count == psl->capacity){SLDataType* tmp = (SLDataType*)realloc(psl->elem, sizeof(SLDataType) * 2 * psl->capacity);if (NULL == tmp){perror("realloc failed!");return ERROR;}psl->elem = tmp;psl->capacity *= 2;}return OK;
}// 尾插
void SeqListPushBack(SeqList* psl, SLDataType e)
{assert(psl);// 考虑是否需要扩容if (CheckCapacity(psl) == ERROR){return;}// 尾插psl->elem[psl->count++] = e;
}// 尾删
void SeqListPopBack(SeqList* psl)
{assert(psl);// 判断是否为空表if (psl->count == 0){return;}// 尾删--psl->count;
}// 头插
void SeqListPushFront(SeqList* psl, SLDataType e)
{assert(psl);// 考虑是否需要扩容if (CheckCapacity(psl) == ERROR) // 扩容失败{return;}// 头插for (int end = psl->count - 1; end >= 0; --end){psl->elem[end + 1] = psl->elem[end];}psl->elem[0] = e;++psl->count;
}// 头删
void SeqListPopFront(SeqList* psl)
{assert(psl);// 判断是否为空表if (psl->count == 0){return;}// 头删for (int begin = 1; begin < psl->count; ++begin){psl->elem[begin - 1] = psl->elem[begin];}--psl->count;
}// 在 pos 位置插入 e
void SeqListInsert(SeqList* psl, int pos, SLDataType e)
{assert(psl);// 当 pos == 0 时,即相当于头插;当 pos == psl->count,即相当于尾插if (pos < 0 || pos > psl->count){return;}// 考虑是否需要扩容if (CheckCapacity(psl) == ERROR) // 扩容失败{return;}// 插入for (int end = psl->count - 1; end >= pos; --end){psl->elem[end + 1] = psl->elem[end];}psl->elem[pos] = e;++psl->count;
}// 删除 pos 位置的元素
void SeqListErase(SeqList* psl, int pos)
{assert(psl);// 当 pos == 0 时,即相当于头删;当 pos == psl->count - 1 时,即相当于尾删if (pos < 0 || pos >= psl->count){return;}// 删除for (int begin = pos + 1; begin < psl->count; ++begin){psl->elem[begin - 1] = psl->elem[begin];}--psl->count;
}// 查找
int SeqListFind(SeqList* psl, SLDataType e)
{for (int i = 0; i < psl->count; ++i){if (psl->elem[i] == e){return i;}}return -1;
}// 打印(不通用)
void SeqListPrint(SeqList* psl)
{assert(psl);for (int i = 0; i < psl->count; ++i){printf("%d ", psl->elem[i]);}printf("\n");
}// 销毁
void SeqListDestroy(SeqList* psl)
{free(psl->elem);psl->elem = NULL;psl->count = 0;psl->capacity = DEFAULT_CAPACITY;
}断言(assert)是一种除错机制,用于验证代码是否符合编码人员的预期。编码人员在开发期间应该对函数的参数、代码中间执行结果合理地使用断言机制,确保程序地缺陷尽量在测试阶段被发现,即 assert 只在 debug 版本中有效,在 release 版本中无效。
在 SeqListInsert 函数中,当 pos == psl->count 时,该函数就相当于尾插,当 pos == 0 时,该函数就相当于头插,因此可以分别对 SeqListPushBack 和 SeqListPushFront 函数做如下修改:
void SeqListPushBack(SeqList* psl, SLDataType e)
{SeqListInsert(psl, psl->count, e);
}void SeqListPushFront(SeqList* psl, SLDataType e)
{SeqListInsert(psl, 0, e);
}在 SeqListErase 函数中,当 pos == psl->count - 1 时,该函数就相当于尾删,当 pos == 0 时,该函数就相当于头删,因此可以分别对 SeqListPopBack 和 SeqListPopFront 函数做如下修改:
void SeqListPopBack(SeqList* psl)
{SeqListErase(psl, psl->count - 1);
}void SeqListPopFront(SeqList* psl)
{SeqListErase(psl, 0);
}三、练习
3.1 - 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
-
0 <= nums.length <= 100 -
0 <= nums[i] <= 50 -
0 <= val <= 100
代码实现一(暴力求解):
int removeElement(int* nums, int numsSize, int val)
{for (int i = 0; i < numsSize; ++i){if (nums[i] == val){for (int j = i + 1; j < numsSize; ++j){nums[j - 1] = nums[j]; }--numsSize;--i;}}return numsSize;
}该算法最坏的时间复杂度为 O(n^2),空间复杂度为 O(1)。
代码实现二(快慢双指针):
int removeElement(int* nums, int numsSize, int val)
{int slow = 0; // slow 始终是第一个未存放数据元素的数组下标for (int fast = 0; fast < numsSize; ++fast){if (nums[fast] != val){nums[slow++] = nums[fast];}}return slow;
}该算法的时间复杂度是 O(n),空间复杂度是 O(1)。
3.2 - 删除有序数组中的重复项
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组 nums 的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
-
1 <= nums.length <= 3 * 10^4 -
-10^4 <= nums[i] <= 10^4 -
nums已按 升序 排列
代码实现(快慢双指针):
int removeDuplicates(int* nums, int numsSize)
{int slow = 0; // slow 始终是最后一个已存放数据元素的数组下标for (int fast = 1; fast < numsSize; ++fast){if (nums[fast] != nums[slow]){nums[++slow] = nums[fast];}}return slow + 1;
}该算法的时间复杂度是 O(n),空间复杂度是 O(1)。
3.3 - BC100 有序序列合并
描述:
输入两个升序排列的序列,将两个序列合并为一个有序序列并输出。
数据范围:1 <= n, m <= 1000,序列中的值满足 0 <= val <= 30000
输入描述:
输入包含三行,
第一行包含两个正整数 n, m,用空格分隔。n 表示第二行第一个升序序列中数字的个数,m 表示第三行第二个升序序列中数字的个数。
第二行包含 n 个整数,用空格分隔。
第三行包含 m 个整数,用空格分隔。
输出描述:
输出为一行,输出长度为 n + m 的升序序列,即长度为 n 的升序序列和长度为 m 的升序序列中的元素重新进行升序序列排列合并。
示例 1:
输入:
5 6
1 3 7 9 22
2 8 10 17 33 44
输出:
1 2 3 7 8 9 10 17 22 33 44
代码实现:
#include <stdio.h>
int main()
{int arr1[1000] = { 0 };int arr2[1000] = { 0 };int arr[2000] = { 0 };int n = 0, m = 0;// 一、输入scanf("%d %d", &n, &m);int i = 0;for (i = 0; i < n; ++i){scanf("%d", &arr1[i]);}for (i = 0; i < m; ++i){scanf("%d", &arr2[i]);}// 二、合并有序序列i = 0; // i 始终是 arr1 中未被合并的最小元素的下标int j = 0; // j 始终是 arr2 中未被合并的最小元素的下标int k = 0; // k 始终是 arr 中第一个未存放数据元素的下标while (i < n && j < m){if (arr1[i] <= arr2[j])arr[k++] = arr1[i++];elsearr[k++] = arr2[j++];}while (i < n){arr[k++] = arr1[i++];}while (j < m){arr[k++] = arr2[j++];}// 三、输出for (i = 0; i < n + m; ++i){printf("%d ", arr[i]);}printf("\n");return 0;
}3.4 - 88.合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6]。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。 合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。 合并结果是 [1] 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
提示:
-
nums1.length == m + n -
nums2.length == n -
0 <= m, n <= 200 -
1 <= m + n <= 200 -
-10^9 <= nums1[i], nums2[j] <= 10^9
代码实现(双指针):
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int end1 = m - 1; // end1 始终是 nums1 中未被合并的最大元素的下标int end2 = n - 1; // end2 始终是 nums2 中未被合并的最大元素的下标int end = m + n - 1; // end 始终是 nums1 中最后一个未存放数据元素的下标while (end1 >= 0 && end2 >= 0){if (nums1[end1] >= nums2[end2])nums1[end--] = nums1[end1--];elsenums1[end--] = nums2[end2--];}while (end2 >= 0){nums1[end--] = nums2[end2--];}// 当 nums2 中的元素都被合并到 nums1 中,nums1 数组就已经有序了
}该算法的时间复杂度是 O(m + n),空间复杂度是 O(1)。
四、顺序表的问题及思考
问题:
-
在中间/头部做插入或删除操作时,需要移动大量元素。
-
增容一般是呈 2 倍的增长,势必会有一定的空间浪费。
思考:
以上问题都可以通过线性表的另一种表示方法,即链式存储结构,来解决。
欲知后事如何,且听下回分解~
相关文章:
)
【第二章 - 线性表之顺序表】- 数据结构(八千字详解)
目录 一、线性表的定义和特点 二、线性表的顺序表示和实现 2.1 - 线性表的顺序存储表示 2.2 - 顺序表中基本操作的实现 三、练习 3.1 - 移除元素 3.2 - 删除有序数组中的重复项 3.3 - BC100 有序序列合并 3.4 - 88.合并两个有序数组 四、顺序表的问题及思考 线性表、…...

【史上最全面esp32教程】RGB彩灯篇
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录rgb彩灯的介绍使用方法连线库操作彩灯变换颜色实验彩灯呼吸灯效果总结提示:以下是本篇文章正文内容,下面案例可供参考 rgb彩灯的介绍 ESP32…...

大规模 IoT 边缘容器集群管理的几种架构-5-总结
前文回顾 大规模 IoT 边缘容器集群管理的几种架构-0-边缘容器及架构简介大规模 IoT 边缘容器集群管理的几种架构-1-RancherK3s大规模 IoT 边缘容器集群管理的几种架构-2-HashiCorp 解决方案 Nomad大规模 IoT 边缘容器集群管理的几种架构-3-Portainer大规模 IoT 边缘容器集群管…...

逆风翻盘拿下感知实习offer,机会总是留给有准备的人
个人背景211本,985硕,本科是计算机科学与技术专业,研究生是自学计算机视觉方向,本科主要做C和python程序设计开发,java安卓开发,研究生主要做目标检测,现在在入门目标跟踪和3d目标检测。无论文&…...
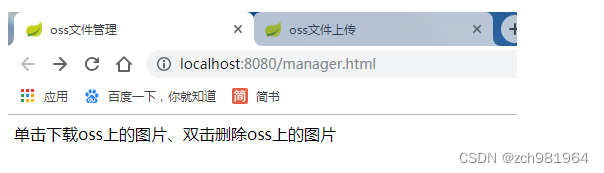
SpringBoot整合阿里云OSS文件上传、下载、查看、删除
SpringBoot整合阿里云OSS文件上传、下载、查看、删除1、开发准备1.1 前置知识1.2 环境参数1.3 你能学到什么2. 使用阿里云OSS2.1 创建Bucket2.2 管理文件2.3 阿里云OSS文档3. 项目初始化3.1 创建SpringBoot项目3.2 Maven依赖3.3 安装lombok插件4. 后端服务编写4.1 阿里云OSS配置…...

对话数字化经营新模式:第2届22客户节(22Day)年猪宴圆满结束!
2023年2月22日,由杭州电子商务研究院联合贰贰网络(集团)、TO B总监联盟等发起举办的“第二届客户节22Day”暨2022年度爱名奖 AM AWARDS颁奖及22年猪宴沙龙活动圆满结束。 (主持人:杜灵芝) 本次沙龙邀请到浙江工业大学管理学院程志…...
——双向循环链表)
数据结构——第二章 线性表(5)——双向循环链表
双向循环链表1.双向循环链表的定义2.双向循环链表的基本操作实现2.1 双向循环链表的初始化操作2.2.双向循环链表的插入操作2.3. 双向循环链表的删除操作1.双向循环链表的定义 单向链表便于查询后继结点,不便于查询前驱结点。为了方便两个方向的查询,可以…...
4面美团软件测试工程师,却忽略了这一点,直接让我前功尽弃
说一下我面试别人时候的思路 反过来理解,就是面试时候应该注意哪些东西;用加粗部分标注了 一般面试分为这么几个部分: 一、自我介绍 这部分一般人喜欢讲很多,其实没必要。大约5分钟内说清楚自己的职业经历,自己的核…...
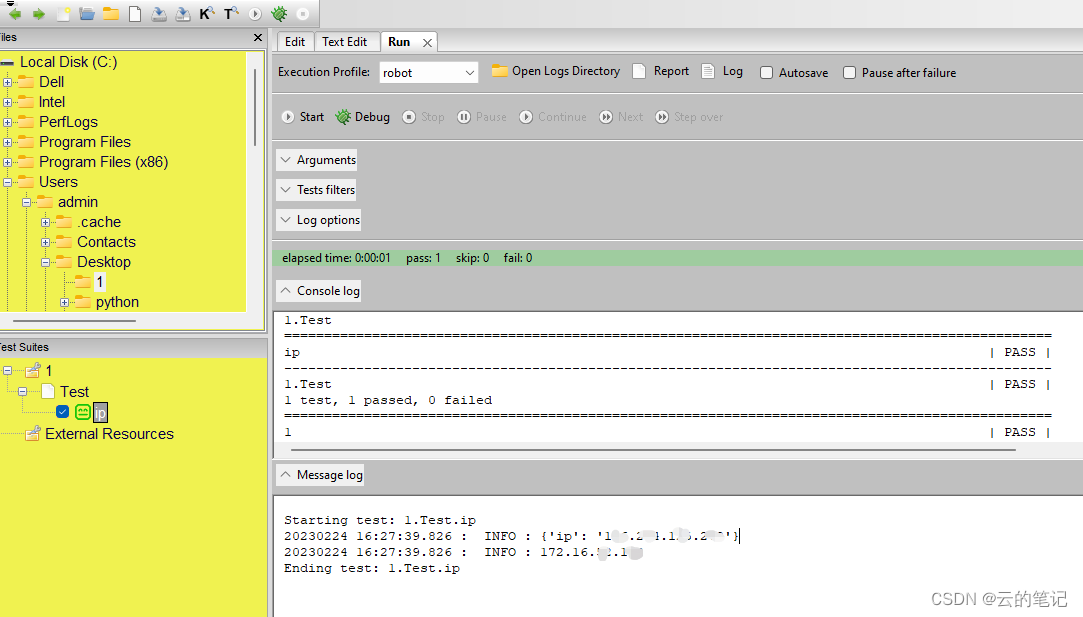
robot remote server用这个server去远程获取ip
server端配置: 1、安装python环境 2、下载robot remote server 下载地址:https://pypi.python.org/pypi/robotremoteserver/(不要用pip下载,把robotremoteserver.py文件下载下来) 3、首先创建一个目录E:\rfremote\ &a…...

【WSL】Windows 上安装并启动
一、什么是 WSL Windows Subsystem for Linux 适用于 Linux 的 Windows 子系统 可以帮助我们自然、方便地在 Windows 上使用 Linux 子系统 二、安装 我们要安装的是 WSL2 , 因为其功能相对来说更加完善 1. 简化安装 — 本人亲测不好用 简化安装:高…...
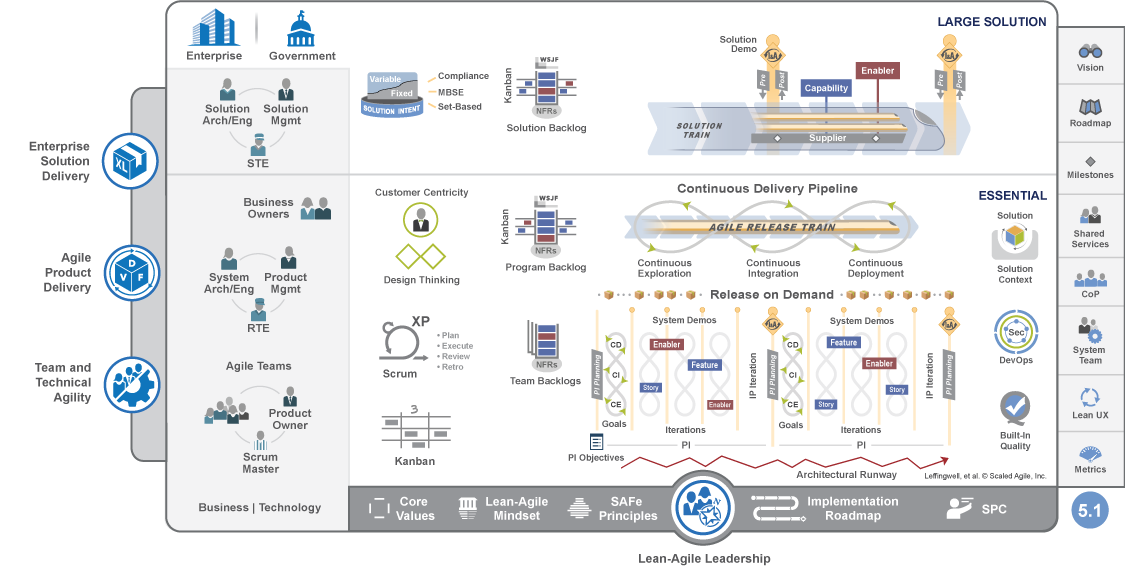
SAFe(Scaled Agile Framework)学习笔记
1.SAFe 概述 SAFe(Scaled Agile Framework)是一种面向大型企业的敏捷开发框架,旨在协调多个团队和部门的协同工作,以实现高效的软件开发和交付。下面是SAFe框架的简单介绍总结: SAFe框架包括以下四个层次:…...
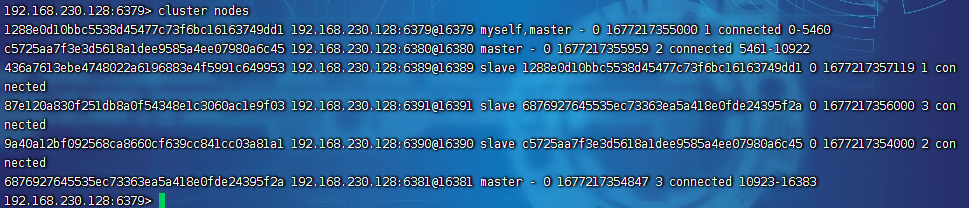
Redis 集群搭建
前缀参考文章1:Centos7 安装并启动 Redis-6.2.6 前缀参考文章2:Redis 主从复制-服务器搭建【薪火相传/哨兵模式】 管道符查看所有redis进程:ps -ef|grep redis 杀死所有redis进程:killall redis-server 1. 首先修改 redis.conf 配…...
【Unity VR开发】结合VRTK4.0:创建物理按钮
语录: 如今我努力奔跑,不过是为了追上那个曾经被寄予厚望的自己 前言: 使用线性关节驱动器和碰撞体从动器可以轻松创建基于物理的按钮,以使交互者能够在物理上按下按钮控件,然后挂钩到驱动器事件中以了解按钮何时被按…...
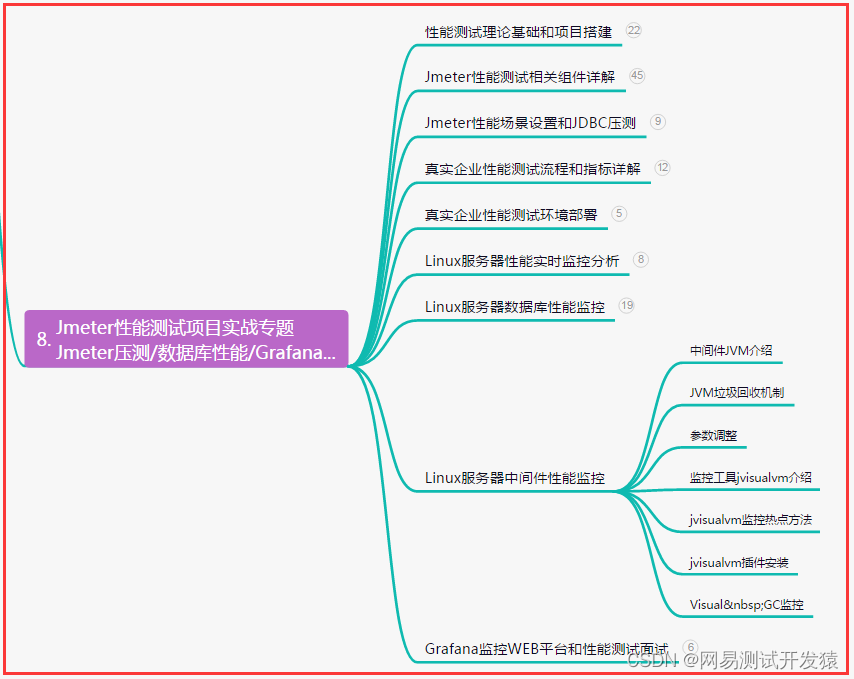
【软件测试】web自动化测试如何开展合适?自动化测试用例如何设计?资深测试的总结......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 首先,还…...
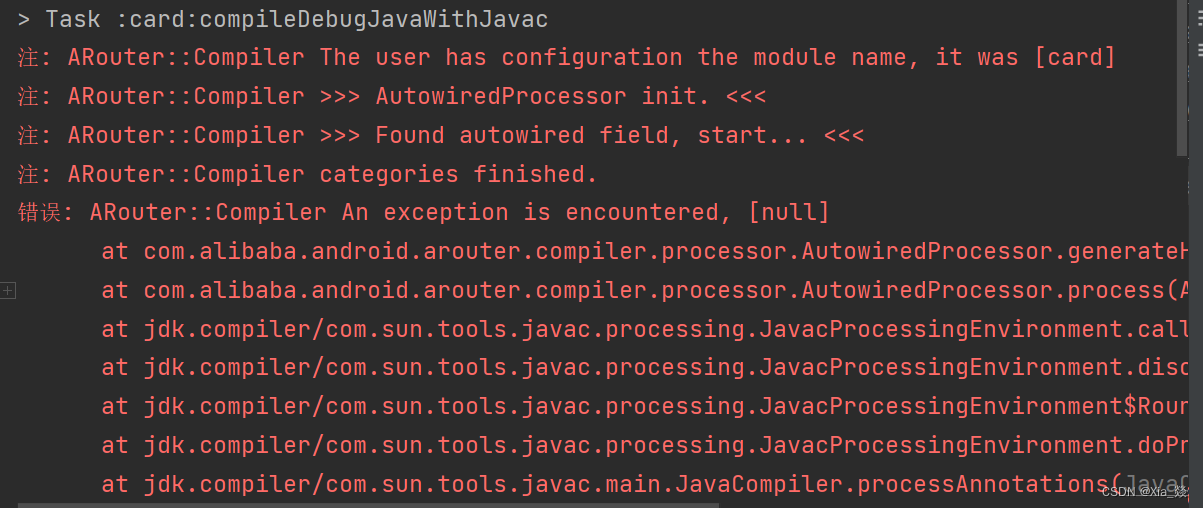
ARouter::Compiler The user has configuration the module name, it was
学习组件化使用的是阿里的ARouter,我是照着案例敲的,在编译的时候报了这么一个错。 我查了好多资料,大部分都是说build.gradle 配置出现了问题,比如没有配置 javaCompileOptions {annotationProcessorOptions {arguments [AROUTE…...

Jmeter(GUI模式)详细教程
Jmeter(GUI模式)详细教程 目录:导读 一、安装Jmeter 二、Jmeter工作原理 三、Jmeter操作步骤 Jmeter界面 1、测试计划 2、线程组 3、HTTP请求 4、监听器 四、压力测试 写在最后 前些天,领导让我做接口的压力测试。What…...
)
2023年CDGA考试-第14章-大数据和数据科学(含答案)
2023年CDGA考试-第14章-大数据和数据科学(含答案) 单选题 1.MapReduce模型有三个主要步骤 () A.剖析、关联、聚类 B.提取、转换、加载 C.映射、修正、转换 D.映射、洗牌、归并 答案 D 2.以下哪种技术已经成为面向数据科学的大数据集分析标准平台。 A.MPP技术。 B.Hado…...
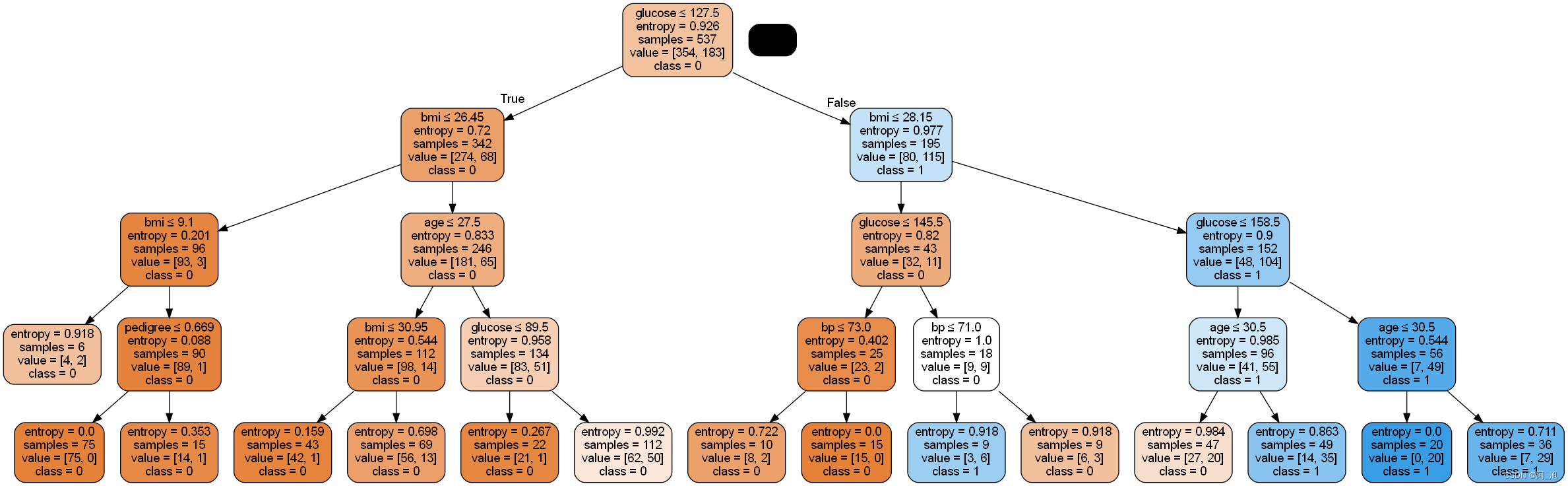
【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。 【阿旭机器学习实战】【36】糖尿病预测—决策树建模及其可视化 目录【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化1. 导入数据并…...
简易黑客初级教程:黑客技术,分享教学
第一节,伸展运动。这节操我们要准备道具,俗话说:“工欲善其事,必先利其器”(是这样吗?哎!文化低……)说得有道理,我们要学习黑客技术,一点必要的工具必不可少。 1,一台属于自己的可以上网的电…...

日本公派访问学者的具体申请流程
公派日本访问学者的具体申请流程,知识人网整理了相关的资料以供大家参考。第一、申请材料一般申请CSC日本访问学者,截止日是每年的1月15号左右,但是学院在1月10号之前就审查材料了。材料包括:CSC网页的报名表,教授邀请…...

Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具
Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款专为Nintendo Switch手柄设计的开源管理工具,为游戏玩…...

AI绘画如何听懂草图?文字+手绘混合生成原理与实战
1. 项目概述:当文字描述遇上手绘草图,AI绘画如何真正“听懂”你的想法? 你有没有过这样的经历:脑子里已经浮现出一幅画面——比如“一只戴圆框眼镜的柴犬坐在咖啡馆窗边,阳光斜射在它毛茸茸的耳朵上,背景是…...
3步搞定日语Galgame翻译的终极方案:TsubakiTranslator完全指南
3步搞定日语Galgame翻译的终极方案:TsubakiTranslator完全指南 【免费下载链接】TsubakiTranslator 一款Galgame文本翻译工具,支持Textractor/剪切板/OCR翻译 项目地址: https://gitcode.com/gh_mirrors/ts/TsubakiTranslator 还在为看不懂日语Ga…...

AI工程化落地的五大技术坐标:Agent、MoE、端云协同与可观测性
1. 这份AI周刊到底在讲什么?一个从业十年的观察者视角你点开这份标题叫《This AI newsletter is all you need #91》的邮件,第一反应可能是:又一份信息过载的AI速报?别急,先放下“刷完就忘”的惯性。作为一个从2014年就…...

【VMware虚拟机】Linux下ubuntu连接网络详细讲解!
原理讲解 window上网需要网络适配器,通过家用路由器下发WLAN,自分配ip地址,连接即用 linux同理:在VMware虚拟机上需要”虚拟路由器“。对应为虚拟网络编辑器 1.打开虚拟网络编辑器 2.点击NAT,NAT模式和DHCP必须选上…...

BurpShiroPassiveScan被动检测原理与实战调优指南
1. 这不是“加个插件就能挖到Shiro反序列化”的幻觉,而是你真正理解被动检测边界的开始很多人第一次在Burp Suite里装上 BurpShiroPassiveScan,点开一个Java老系统首页,看到插件弹出一条“疑似Shiro RememberMe Cookie”的告警,就…...
)
从炼丹炉到生产线:在Linux服务器上为Stable Diffusion部署配置PyTorch环境(驱动+CUDA+Anaconda实战)
从炼丹炉到生产线:Linux服务器部署PyTorch环境全流程指南 引言:为什么需要专业化的AI开发环境? 在AI模型开发领域,我们常常把训练模型比作"炼丹"——需要精准控制各种"火候"参数。而要让这个"炼丹炉&quo…...

嵌入式核心板选型实战:从AI加速到工业控制的设计权衡与趋势
1. 展会现场与行业风向初探上周,我作为飞凌嵌入式的一名老员工,亲身参与了2024上海国际嵌入式展。这不仅仅是一次公司产品的展示,更像是一场行业技术趋势的集中检阅。从人头攒动的展台到同行间热烈的技术交流,你能清晰地感受到&am…...

矩池云实战: 用Gemma 4 + Open WebUI打造你的私人OpenAI
在开源 AI 生态中,如何不依赖闭源 API,纯靠开源堆栈搭建出一套具备“深度思考(CoT)&原生多模态顶配开发环境? 答案是:Ollama Gemma-4-31B Open WebUI Ollama Gemma-4-31B Open WebUI 的真正核心价…...

告别手动启动:在Windows Server上把Gitblit配置成稳定可靠的后台服务
Windows Server生产环境Gitblit服务化部署全指南 在团队协作开发中,代码仓库的稳定性和可靠性直接影响着整个研发流程的效率。对于使用Windows Server作为基础架构的企业来说,将Gitblit从简单的命令行工具转变为系统服务,是实现7x24小时不间断…...