kafka消费者程序日志报错Offset commit failed问题研究
生产环境偶尔会遇到kafka消费者程序日志报错的问题
截取主要日志如下:
2023-10-02 19:35:28.554 {trace: d7f97f70dd693e3d} ERROR[Thread-49:137] ConsumerCoordinator$OffsetCommitResponseHandler.handle(812) - [Consumer clientId=consumer-1, groupId=cid_yingzi_fpf_group_device] Offset commit failed on partition topic_dvc_telemetery_bh_bh100-1 at offset 4313614: The request timed out.2023-10-02 19:35:28.554 {trace: d7f97f70dd693e3d} INFO [Thread-49:137] AbstractCoordinator.markCoordinatorUnknown(727) - [Consumer clientId=consumer-1, groupId=cid_yingzi_fpf_group_device] Group coordinator kafka02.yingzi.com:19292 (id: 2147483645 rack: null) is unavailable or invalid, will attempt rediscovery
kafka客户端版本为2.2.0
结合日志去阅读代码,只能大概定位到,是客户端程序向server发送commit offset请求的时候,server返回的错误信息是:The request timed out
看到 request timed out,第一时间很可能会误以为是客户端向server发送请求超时了。但是查看OffsetCommitResponseHandler.handle()的代码,发现server是成功返回信息了的。
server返回的数据是一个Map<TopicPartition, Errors>结构,每个partition都对应一个Errors结果,如果Errors为Errors.NONE,则表示offset提交成功。
如果Errors不为Errors.NONE,则打印错误日志,也就是上面的 Offset commit failed … The request timed out的日志,每个partition打印1条日志。
也就是说,问题发生在server内部处理的时候,可以排除掉是客户端和server的网络问题导致的超时
要继续深挖,需要了解下server的处理逻辑,server的入口代码在KafkaApis.handleOffsetCommitRequest()
查看代码逻辑,可以发现早期的offset是保存在zk中,新版本中改为存在kafka的topic中(往__consumer_offsets这个topic发消息,每个partition一条offset消息)
那么分析下来,大概率就是往__consumer_offsets topic发消息的时候,产生了超时
继续阅读client的代码,了解Offset commit的机制
在KafkaConsumer.poll()的代码中,每次拉取消息时,都会调用updateAssignmentMetadataIfNeeded()这个方法,这个方法最终会调用maybeAutoCommitOffsetsAsync()方法
maybeAutoCommitOffsetsAsync()方法根据autoCommitIntervalMs来判断,是否要提交offset
这里默认是5秒执行一次commit offset请求,每次会把订阅的所有topic和partition的信息都进行提交
每个topic每个partition对应1条消息,如果topic非常多的话,那往__consumer_offsets发送消息量也会很大
查看生产kafka的监控,__consumer_offsets每秒消息量大概为四五千
显然是不太合理的
于是通过命令去消费__consumer_offsets的数据进行查看,注意由于这里消息是序列化的,直接消费的话会显示乱码,要通过-formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter"去进行消息解码
测试环境消费命令如下:
/opt/software/kafka/kafka_2.11-2.0.0_test_yewu/bin/kafka-console-consumer.sh --topic __consumer_offsets --group yz.bigdata.tzy --bootstrap-server kafka-test01.yingzi.com:32295 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties
生产环境统计的消息量最多的group如下(消费25秒):
37485 cid_opf_scene_edgengine_offline_alarm
27216 idp_share_telemetery_scene
25776 idp_scene_lifecycle_offline_alarm
4892 cid_scene_dvc_tele_attr
1440 yingzi-scene-space-group
546 clickhouse-iotcenter-latest-rep
533 re-Main-consumer-b
533 clickhouse-iotcenter-rep
437 yingzi-bizcenter-dvc-telemetery-group
318 cid_yingzi_hwm_group
288 cid_yingzi_fpf_group_device
270 transport-b-node-tb-mqtt-transport-ca-b-8
258 transport-b-node-tb-mqtt-transport-ca-b-6
222 transport-b-node-tb-mqtt-transport-ca-b-5
208 tb-core-b-consumer
200 yz.bigdata.wns
排名前几的都是跟设备有关的,消费几百个topic
按照上面的分析,每个group每秒发送的消息量应该为:1 / auto-commit-interval * Sum(topic partirionNum)
但是实际计算下来,感觉不应该这么高才对
先针对cid_opf_scene_edgengine_offline_alarm这个group进行查看,这个group订阅的topic有250个,每个topic 6个partition
1/52506=300
但是实际37485/25 = 1500
差了5倍之多
于是找到对应的开发人员,查看kafka的配置,发现配置:spring.kafka.consumer.auto-commit-interval=1000
提交offset的间隔默认5秒,被人工修改为1秒,正好相差5倍
其他两个消息量很高的group,经分析也是一样的问题
沟通后建议还是把spring.kafka.consumer.auto-commit-interval配置改回默认值,后续再继续进行观察
当然问题的根本原因其实还是设计不合理,kafka的性能本身就是会随着topic的增多而降低的,设计上应该尽量避免产生很多个topic才对,这里就不再展开讨论了
相关文章:

kafka消费者程序日志报错Offset commit failed问题研究
生产环境偶尔会遇到kafka消费者程序日志报错的问题 截取主要日志如下: 2023-10-02 19:35:28.554 {trace: d7f97f70dd693e3d} ERROR[Thread-49:137] ConsumerCoordinator$OffsetCommitResponseHandler.handle(812) - [Consumer clientIdconsumer-1, groupIdcid_yin…...

SpringBoot+原生HTML+MySQL开发的电子病历系统源码
电子病历系统源码 电子病历编辑器源码 云端SaaS服务 电子病历系统,采用 “所见即所得、一体化方式”,协助医生和护士准确、标准、快捷实现病历书写、修改、审阅、打印、体温单浏览、医嘱管理等,是提供病历快速简洁化完成的一系列综合型医生病…...

软件测试/测试开发/人工智能丨聊聊AutoGPT那些事儿
点此获取更多相关资料 简介 在 ChatGPT 问世之后,大家很容易就发现其依然具备一些很难解决的问题,比如: Token 超出限制怎么办?(目前最新的 GPT4 支持最多8,192 tokens)。如何完全自动化?任务…...
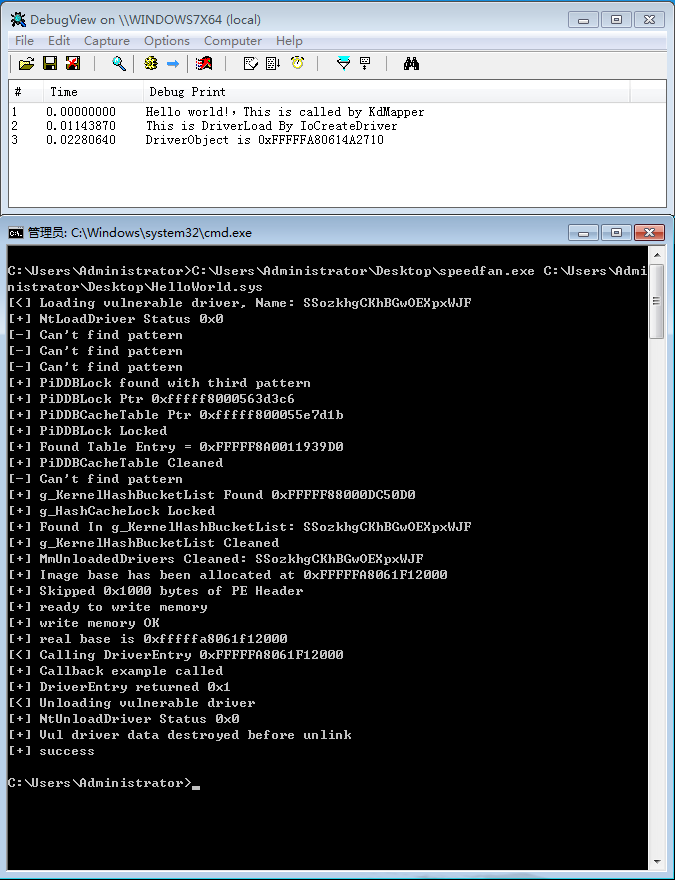
KdMapper扩展实现之SOKNO S.R.L(speedfan.sys)
1.背景 KdMapper是一个利用intel的驱动漏洞可以无痕的加载未经签名的驱动,本文是利用其它漏洞(参考《【转载】利用签名驱动漏洞加载未签名驱动》)做相应的修改以实现类似功能。需要大家对KdMapper的代码有一定了解。 2.驱动信息 驱动名称spee…...

MATLAB算法实战应用案例精讲-【图像处理】计算机视觉
目录 前言 几个高频面试题目 计算机视觉与图像处理、模式识别、机器学习学科之间的关系 计算机视觉和机器人视觉区别与联系...

docker应用的缓存 docker缓存机制
Docker镜像用作Docker执行程序中的主映像。它们是容器的蓝图,提供了有关如何生成容器的说明。在本文中,我将介绍一些经常被忽视的概念,这些概念将有助于优化Docker镜像开发和构建过程。 让我们从Docker构建过程的简短描述开始。这是通过使用…...

借助 ZooKeeper 生成唯一 UUID
ZooKeeper是一个分布式协调服务,它主要用于在分布式系统中管理和协调各种资源。它本身并不提供生成唯一UUID的功能,但你可以借助ZooKeeper来实现生成唯一UUID的机制。 下面是一种基于ZooKeeper的方法来生成唯一UUID的示例: 在ZooKeeper中创建…...

Redis哨兵机制原理
Redis哨兵机制可以保证Redis服务的高可用性。它通过启动一个或多个哨兵进程,监控Redis主服务器是否宕机,如果宕机,哨兵进程会自动将一个从服务器(Slave)升级为主服务器(Master),并通…...
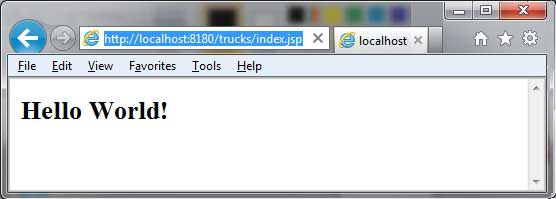
Maven Web应用
目录 创建 Web 应用 构建 Web 应用 部署 Web 应用 测试 Web 应用 本章节我们将学习如何使用版本控制系统 Maven 来管理一个基于 web 的项目,如何创建、构建、部署以及运行一个 web 应用。 创建 Web 应用 我们可以使用 maven-archetype-webapp 插件来创建一个简…...
)
考古:MFC界面的自适应缩放(代码示例)
MFC窗体的控件的自适应缩放早期VS开发环境是不支持的,后来VS开发环境提供了支持但也简单,或者固定的缩放比例不符合要求。我一向坚持一个理念:“不支持缩放的窗口不是好窗口”,所以需要有一个自定义的缩放处理。机制不复杂&#x…...
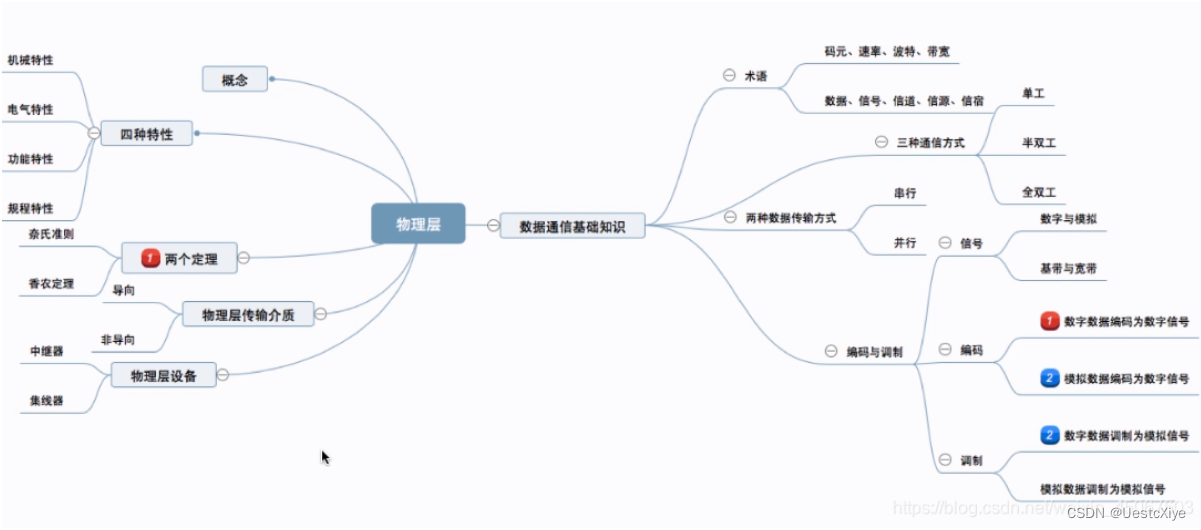
计算机网络 | 物理层
计算机网络 | 物理层 计算机网络 | 物理层基本概念数据通信基本知识(一)一个数据通信流程的例子数据通信相关术语三种通信方式数据传输方式串行传输和并行传输同步传输和异步传输 小结 数据通信基本知识(二)码元(Symbo…...

Centos下编译ffmpeg动态库
文章目录 一、下载ffmpeg安装包二、编译ffmpeg三、安装yasm 一、下载ffmpeg安装包 下载包 wget http://www.ffmpeg.org/releases/ffmpeg-4.4.tar.gz解压 tar -zxvf ffmpeg-4.4.tar.gz二、编译ffmpeg 进入解压的目录 cd ffmpeg-4.4编译动态库 ./configure --enable-shared…...

深度学习:UserWarning: The parameter ‘pretrained‘ is deprecated since 0.13..解决办法
深度学习:UserWarning: The parameter ‘pretrained’ is deprecated since 0.13 and may be removed in the future, please use ‘weights’ instead. 解决办法 1 报错警告: pytorch版本:0.14.1 在利用pytorch中的预训练模型时࿰…...

leetcode-279. 完全平方数
1. 题目链接 链接: 题目链接 2. 解答 #include <stdio.h> #include <stdlib.h> #include <stdbool.h>bool issquare(int n) {if (n 1 || n 4) return true;if (n 2 || n 3) return false;for (int i 3; i < n/2; i ) {if (n i*i) return true;}…...

MySQL常用指令
创建新的数据库 1、创建新的数据库 create database YOLO;显示本地创建的数据库 2、显示本地创建的数据库 show databases;进入新创建的数据库 3、进入新创建的数据库 use YOLO;在新创建的数据库内添加表(表内插入内容) 4、创建表并添加表内容 creat…...

Pulsar 之架构,客户端以及多区域容灾
Pulsar 之架构,客户端以及多区域容灾 架构BrokersClusters元数据存储配置存储区持久存储Apache BookKeeperLedgersLedgers读一致性托管Ledgers 日志存储 Pulsar 代理服务发现 Pulsar client(客户端)客户端设置阶段Reader interface 多区域容灾备份(GEO-REPLICATION)…...
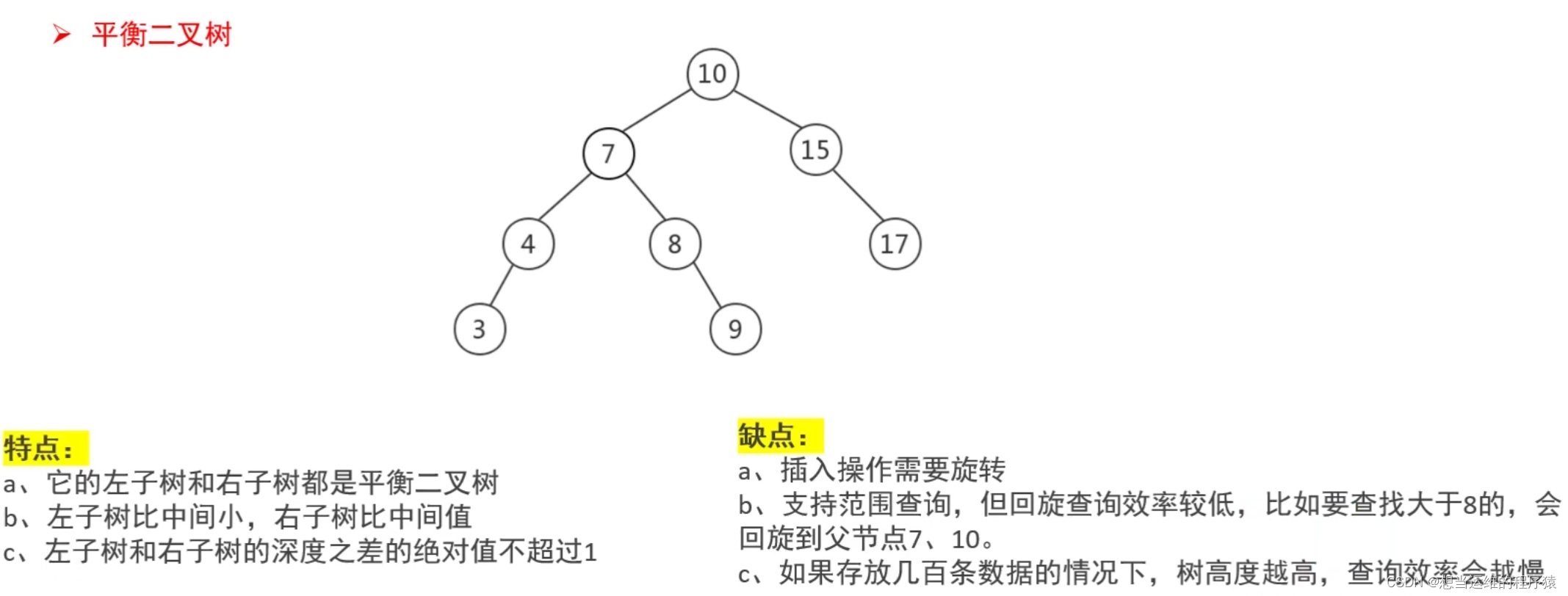
【SQL】MySQL中的索引,索引优化
索引是存储引擎用来快速查询记录的一种数据结构,按实现方式主要分为Hash索引和B树索引。 按功能划分,主要有以下几类 单列索引指的是对某一列单独建立索引,一张表中可以有多个单列索引 1. 单列索引 - 普通索引 创建索引(关键字i…...

uniapp 跳转到指定位置
this.$router.push({name: Demo,params: {id: 123} })这样就实现了页面的跳转,并且将参数id传递给了Demo组件。 如果需要跳转到当前页面的不同位置,我们可以使用锚点来实现。锚点是一个HTML元素的标识符,可以用于定位和跳转到该元素。例如&a…...
基于java的图书馆预约座位系统的设计与实现(部署+源码+LW)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java的图书馆预约座…...
golang 拉取 bitbucket.org 私有库
以 bitbucket.org 平台和mac电脑为例 前置条件私库需要给你账号权限,可拉取的权限,否则无法进行正常拉取 我们采用ssh方式,需要在本地生成对应的 rsa 的公钥和私钥,将公钥配置如下图: 在 .ssh/config 写入你的配置 H…...

别再死记硬背了!用NestJS + TypeORM实战‘用户-标签’系统,搞懂OneToMany和ManyToOne
NestJS TypeORM实战:构建高可维护的用户标签系统 在开发内容管理平台时,用户与标签的关联关系是典型的多对一建模场景。本文将带你从零实现一个基于NestJS和TypeORM的生产级用户标签系统,重点解析OneToMany和ManyToOne在实际项目中的最佳实践…...

WCHUsbSerTest:串口批量自动化测试工具的原理、配置与生产实践
1. 项目概述:为什么我们需要一个专用的串口批量测试工具?在嵌入式硬件开发、工业控制或者物联网设备的生产线上,USB转串口芯片和模块是连接PC与目标设备最常用、最基础的桥梁。无论是给单片机烧录程序,还是与PLC、传感器进行数据交…...

Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术
Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在手动解压、复制、配置空洞骑士模组吗?Sc…...

Tomcat 超精简总结
1. 定位轻量级 Java Web 服务器 / Servlet 容器只跑 Java 项目(jsp、servlet、springboot 内嵌)处理 动态请求,不擅长静态资源2. 核心作用解析 Servlet、JSP监听端口,接收浏览器请求调用 Java 代码执行业务返回页面 / 数据给客户端…...

宏裕塑胶代理新日铁住金日本工程塑料全系列产品服务详解
宏裕塑胶代理新日铁住金系列产品专注于为制造业企业提供高性价比、稳定可靠的通用工程塑料原料,依托源头直采及技术赋能,为塑胶制品厂、汽车零部件厂等客户降低采购成本并保障全流程供应。宏裕塑胶代理新日铁住金核心功能与服务模块覆盖多个维度…...

计算机视觉与VR融合:构建远程协助独居老人的智能生活守护系统
1. 当计算机视觉遇见VR:守护独居老人的科技新思路 早上8点,张阿姨家的智能摄像头捕捉到她起床时的一个踉跄,这个细微动作触发了系统的预警机制。200公里外的女儿立刻收到通知,戴上VR眼镜后,她仿佛瞬间"穿越"…...

【技术解读】xNIDS:如何为深度学习入侵检测系统“翻译”可执行的主动防御规则?
1. 深度学习入侵检测的"黑盒困境":为什么需要翻译器? 第一次接触深度学习入侵检测系统(DL-NIDS)时,我被它的检测准确率惊艳到了——某些场景下能达到99%以上的识别率。但当我试图把它部署到实际生产环境时&a…...

保姆级教程:Windows下VectorCAST License服务配置与常见启动失败排查
Windows平台VectorCAST License服务配置全指南与深度排错手册 引言 在嵌入式软件测试领域,VectorCAST作为行业领先的自动化测试工具链,其License服务的正确配置是保证团队高效协作的基础。然而,许多工程师在初次部署时,常因Window…...

终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案
终极指南:Original Prusa i3 MK3S 3D打印机的完整构建与定制方案 【免费下载链接】Original-Prusa-i3 Original Prusa i3 MK2 3D printer printed parts 项目地址: https://gitcode.com/gh_mirrors/or/Original-Prusa-i3 Original Prusa i3 MK3S是一款由PRUS…...

cstore_fdw迁移指南:从传统表到列式存储的无缝切换
cstore_fdw迁移指南:从传统表到列式存储的无缝切换 【免费下载链接】cstore_fdw Columnar storage extension for Postgres built as a foreign data wrapper. Check out https://github.com/citusdata/citus for a modernized columnar storage implementation bui…...