【MySQL】聚合查询与分组查询
我们先重建一个test库,在test库里新建一个people表(包含序列号,姓名,工资),再往表该表里新增六条数据:
mysql> drop database if exists test; Query OK, 1 row affected (0.07 sec)mysql> create database test; Query OK, 1 row affected (0.00 sec)mysql> use test; Database changed mysql> create table people(-> id int primary key auto_increment,-> name varchar(20),-> careen varchar(20),-> salary int-> ); Query OK, 0 rows affected (0.05 sec)mysql> insert into people value(null,"张三","老师",3000); Query OK, 1 row affected (0.01 sec)mysql> insert into people value(null,"李四","老师",4000); Query OK, 1 row affected (0.01 sec)mysql> insert into people value(null,"王五","老师",5000); Query OK, 1 row affected (0.01 sec)mysql> insert into people value(null,"赵六","医生",60000); Query OK, 1 row affected (0.00 sec)mysql> insert into people value(null,"小七","医生",70000); Query OK, 1 row affected (0.00 sec)mysql> insert into people value(null,null,null,null); Query OK, 1 row affected (0.00 sec)mysql> select * from people; +----+--------+--------+--------+ | id | name | careen | salary | +----+--------+--------+--------+ | 1 | 张三 | 老师 | 3000 | | 2 | 李四 | 老师 | 4000 | | 3 | 王五 | 老师 | 5000 | | 4 | 赵六 | 医生 | 60000 | | 5 | 小七 | 医生 | 70000 | | 6 | NULL | NULL | NULL | +----+--------+--------+--------+ 6 rows in set (0.00 sec)接下来我们就针对该表进行聚合查询操作~
♫聚合查询
前面我们所用的基础的查询操作只能对每行进行独立的查询操作,而要是想要查询的结果是该列所有数据的平均值,最大或最小值,则需要使用聚合查询才能做到。聚合查询需要用到聚合函数,因此,要学会聚合查询,首先得先了解下MySQL中的聚合函数。
♪聚合函数
常见的聚合函数有以下几种:
函数 描述 COUNT([DISTINCT] expr) AVG([DISTINCT] expr) SUM([DISTINCT] expr) MAX([DISTINCT] expr) MIN([DISTINCT] expr) 知道了聚合函数,接下来就可以使用这些聚合函数进行聚合查询操作了。
♪查询表的行数
查询表的行数需要用到聚合函数count():
语法:select count(*) from 表名;
mysql> select count(*) from people; +----------+ | count(*) | +----------+ | 6 | +----------+ 1 row in set (0.00 sec)此外count(常量)也能查询表的行数:
语法:select count(常量) from 表名;
mysql> select count(1) from people; +----------+ | count(1) | +----------+ | 6 | +----------+ 1 row in set (0.00 sec)注:
①.count(1)和count(*)的实现方式略有不同,count(1)是对表中的每一行都执行一次计数操作,而count(*)则是对整个表执行计数操作
②.查询表的行数包括全为NULL的行
♪查询表某一列的行数
单独查询表某一列有几行也是需要用到count():
语法:select count(列名/表达式) from 表名;
mysql> select count(name) from people; +----------------+ | count(name) | +----------------+ | 5 | +----------------+ 1 row in set, 5 warnings (0.00 sec)注:查询某一列的行数不会包含NULL数据
♪查询表某一列数据的和
要想查询结果是某一列的数据和就需要用到聚合函数sum():
语法:select sum(列名/表达式) from 表名;
mysql> select sum(salary) from people; +-------------+ | sum(salary) | +-------------+ | 142000 | +-------------+ 1 row in set (0.00 sec)注:只能查询数字列的和,不能求字符串/日期的和
♪查询表某一列数据的平均值
要查询某一列数据的平均值就需要用到聚合函数avg():
语法:select avg(列名/表达式) from 表名;
mysql> select avg(salary) from people; +-------------+ | avg(salary) | +-------------+ | 28400.0000 | +-------------+ 1 row in set (0.00 sec)注:只能查询数字列的平均值
♪查询表某一列数据的最大值
要查询某一列数据的最大值就需要用到聚合函数max():
语法:select max(列名/表达式) from 表名;
mysql> select max(salary) from people; +-------------+ | max(salary) | +-------------+ | 70000 | +-------------+ 1 row in set (0.00 sec)注:只能查询数字列的最大值
♪查询表某一列数据的最小值
要查询某一列数据的最小值就需要用到聚合函数min():
语法:select min(列名/表达式) from 表名;
mysql> select min(salary) from people; +-------------+ | min(salary) | +-------------+ | 3000 | +-------------+ 1 row in set (0.00 sec)注:只能查询数字列的最小值
上面聚合查询的对象是所有人,要想查询的对象为同一职业的人,可以通过group by子句来实现。
♫分组查询
♪group by子句
select中使用 group by 子句可以对指定列进行分组查询。需要满足:使用group by 进行分组查询时,select 指定的字段必须是 “ 分组依据字段 ” ,其他字段若想出现在 select 中则必须包含在聚合函数中。语法:select 列名,聚合函数,... from 表名 group by 列名;
-- 查询每种职业的最高薪资 mysql> select careen,max(salary) from people group by careen; +--------+-------------+ | careen | max(salary) | +--------+-------------+ | NULL | NULL | | 医生 | 70000 | | 老师 | 5000 | +--------+-------------+ 3 rows in set (0.01 sec)如果是不带聚合函数的分组查询,查询结果为每个分组的第一条记录:
mysql> select * from people group by careen; +----+--------+--------+--------+ | id | name | careen | salary | +----+--------+--------+--------+ | 6 | NULL | NULL | NULL | | 4 | 赵六 | 医生 | 60000 | | 1 | 张三 | 老师 | 3000 | +----+--------+--------+--------+ 3 rows in set (0.01 sec)分组查询还可以对分组前指定条件或对分组后指定条件:
♪分组前指定条件
对筛选出来的数据进行分组查询:
语法:select 列名,聚合函数,... from 表名 group by 列名 where 指定条件;
-- 取所有工资大于3000的人,对这类人按照对应职业进行分组查询 mysql> select careen,avg(salary) from people where salary>3000 group by careen; +--------+-------------+ | careen | avg(salary) | +--------+-------------+ | 医生 | 65000.0000 | | 老师 | 4500.0000 | +--------+-------------+ 2 rows in set (0.02 sec)♪分组后指定条件
对分组查询后的数据进行筛选:
语法:select 列名,聚合函数,... from 表名 group by 列名 having 指定条件;
-- -- 按照职业进行分组查询,取查询结果中平均工资大于5000的职业 mysql> select careen,avg(salary) from people group by careen having avg(salary)>5000; +--------+-------------+ | careen | avg(salary) | +--------+-------------+ | 医生 | 65000.0000 | +--------+-------------+ 1 row in set (0.00 sec)
相关文章:

【MySQL】聚合查询与分组查询
我们先重建一个test库,在test库里新建一个people表(包含序列号,姓名,工资),再往表该表里新增六条数据: mysql> drop database if exists test; Query OK, 1 row affected (0.07 sec)mysql>…...
RFID技术在锂电池生产线自动化应用
随着电动汽车和能源储存系统市场的不断扩大,锂离子电池作为其核心部件,以其高能量密度、长寿命等优点成为了主流选择。而对于锂电池智能化、高效化生产有着更高的要求,RFID技术的使用,将大幅度提高锂电池的生产产能,从…...

钢筋智能测径仪 光圆与带肋钢筋均可检测!
在一个大规模、高效、连续的工业生产中,制造业正朝着自动化方向快速优化发展,这种自动化的生产需要快速、准确地分析控制生产工艺中的参数,超差及时提示,为操作工对工厂的运行和自我调节做出快速反应,人工操作越来越不…...

docker--在Anaconda jupyter 容器中使用oracle数据源时,Oracle客户端安装配置及使用示例
配置oracle 11.2 客户端 将instantclient-basic-linux.x64-11.2.0.4.0.zip解压至/home/jupyter/oracle/将instantclient-sqlplus-linux.x64-11.2.0.4.0.zip解压/home/jupyter/oracle/【可选,提供sqlplus命令】复制【操作系统一般都有安装libaio.so】 cp /usr/lib64…...

can的波特率/比特率
can控制器只需要进行少量的设置就可以进行通信,就像RS232那样。其中较难设置的部分就是通信波特率的计算。can总线能够在一定范围内容忍总线上can节点的通信波特率的偏差,这种技能使得can总线有很强的容错性,同时也降低了对每个节点的振荡器精…...

项目经理涨薪秘籍!技巧都在这里了
好奇前辈们是如何带好团队、做出成功项目,从而升职加薪,成为高级项目经理或项目管理主管的?这是绝大多数新手PM最关注的事情。今天小编给大家揭秘! 一、刚入门如何进阶 从入门的项目管理者发展到中级的项目管理者,重…...
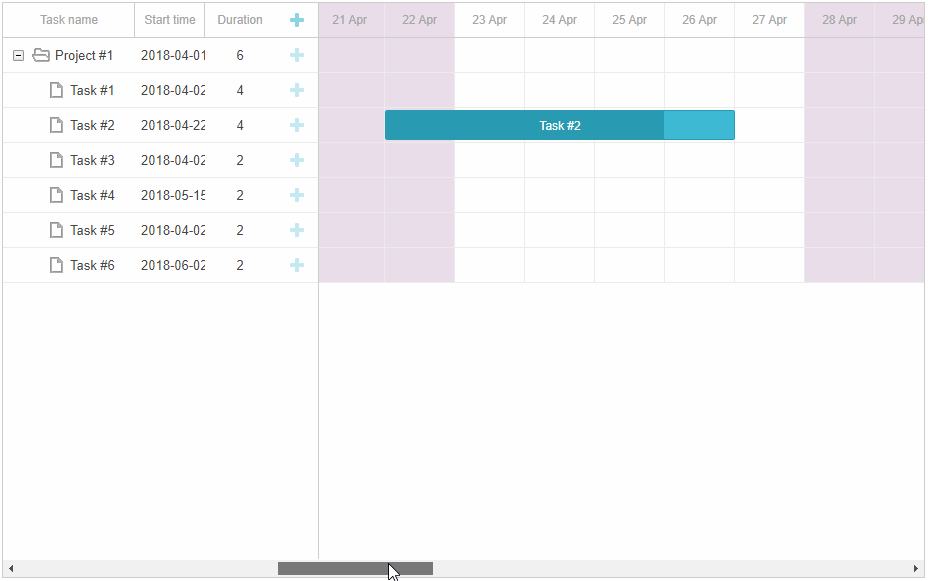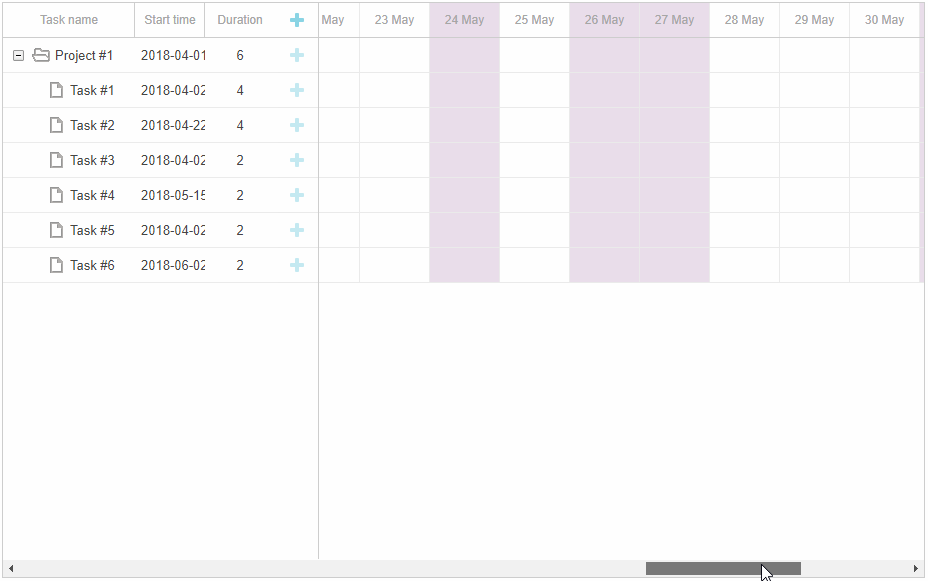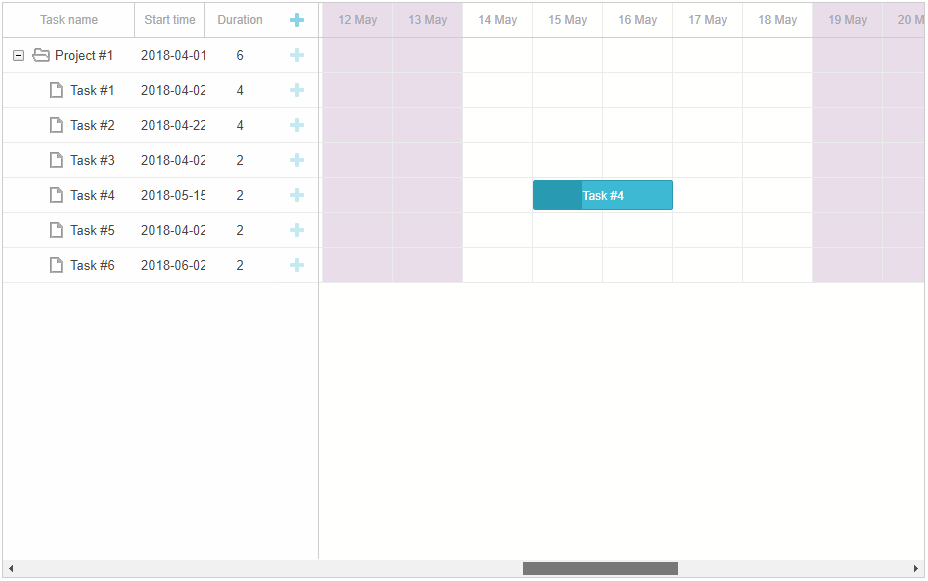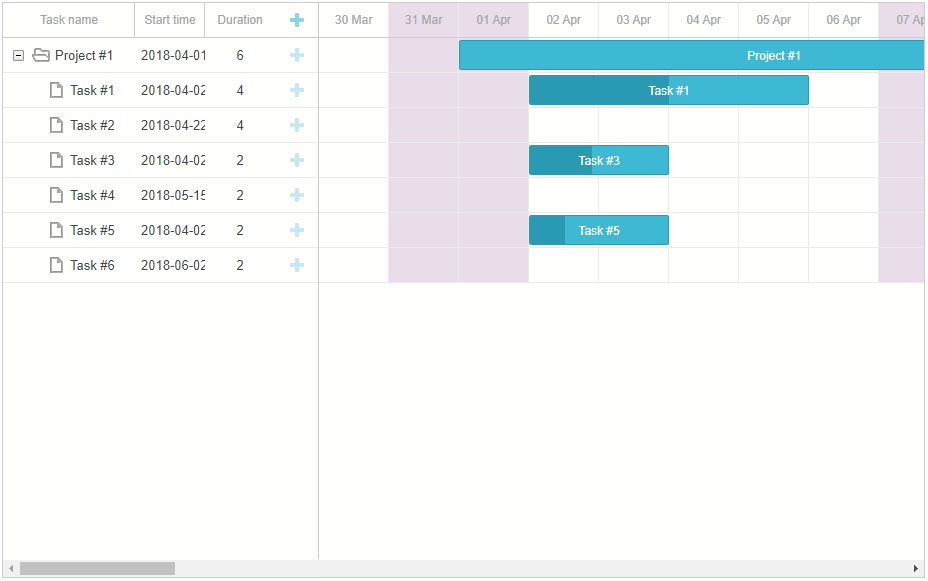
甘特图组件DHTMLX Gantt示例 - 如何有效管理团队工作时间?(一)
如果没有有效的时间管理工具,如工作时间日历,很难想象一个项目如何成功运转。这就是为什么我们的开发团队非常重视项目管理,并提供了多种选择来安排DHTMLX Gantt的工作时间。使用DHTMLX Gantt这个JavaScript库,您可以创建一个强大…...

健效达海豚妈妈儿保项目推介会盛大启幕,聚焦互联网+精准医疗
2023年10月12日,由上海健启星科技发展有限公司和北京安智因生物技术有限公司联合主办的“2023互联网精准医学平台助力基层医疗|海豚妈妈儿保项目推介会”在中国苏州盛大启幕。 本次项目推介会得到国内行业专家、权威学者、国内知名三甲名医教授、头部企业、学术大咖…...

使用XLua在Unity中获取lua全局变量和函数
1、Lua脚本 入口脚本 print("OK") --也会执行重定向 require("Test") 测试脚本 print("TestScript") testNum 1 testBool true testFloat 1.2 testStr "123"function testFun()print("无参无返回") endfunction te…...

springboot项目集成kafka,并创建kafka生成消息线程池
效果图: 步骤1:添加依赖 <!-- kafka依赖 --><dependency><groupId>org.apache.kafka</groupId><<...
PreScan与MATLAB联合仿真报错
一、 问题: Error:Matlab ||和&&运算符的操作数必须能够转换为逻辑标量值 二、解决办法 必须安装VS2013(我装的VS2017不行的),然后重启prescan和MATLAB,编译通过,界面如下: 三、VS…...

ros学习笔记(1)Mac本地安装虚拟机,安装Ros2环境
Ros与Linux的关系 Ros环境基于Linux系统内核 我们平时用的是Linux发行版,centos,ubuntu等等,机器人就用了ubunut 有时候我们经常会听到ubunue的版本,众多版本中,有一些是长期维护版TLS,有一些是短期维护…...
史上最强,Jmeter性能测试-性能场景设计实例(详全)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、性能测试需求 …...

【vim 学习系列文章 7-- vim vnormap nnoremap nmap map inoremap 区别】
文章目录 1.1 vim 递归映射和非递归映射1.1.1 vim 可视模式 1.2 map nmap vnormap nnoremap inoremap 区别 1.1 vim 递归映射和非递归映射 递归映射和非递归映射是 Vim 中两种不同的键盘映射方式。 递归映射(recursive map)是指在定义键盘映射时&#x…...

[ERROR] COLLATION ‘utf8_unicode_ci‘ is not valid for CHARACTER SET ‘latin1‘
[ERROR] COLLATION utf8_unicode_ci is not valid for CHARACTER SET latin1错误来源是: 跟着b站的谷粒商城项目做,前面的视频中设置了数据库的字符集编码,但是后面自己发现了MySQL容器重启报错,不停的在重启 查看log信息可以使用…...

基于rancher安装部署k8s
基础配置 systemctl stop firewalld && systemctl disable firewalld setenforce 0 sed -i s/SELINUXenforcing/SELINUXdisabled/ /etc/selinux/configvi /etc/hosts ip1 node1 ip2 node2 ip3 node3#免密登录 ssh-keygenssh-copy-id -i ~/.ssh/id_rsa.pub 普通用户ip1…...
保姆级微服务部署教程
大家好,我是鱼皮。 项目上线是每位学编程同学必须掌握的基本技能。之前我已经给大家分享过很多种上线单体项目的方法了,今天再出一期微服务项目的部署教程,用一种最简单的方法,带大家轻松部署微服务项目。 开始之前,…...

springboot 定时任务
springboot 定时任务 在Spring Boot中,你可以使用Spring的Scheduled注解来创建定时任务。以下是一个简单的示例: 首先,你需要在Spring Boot的主类上添加EnableScheduling注解以启用定时任务功能。 import org.springframework.boot.Spring…...
【大数据】HBase入门指南
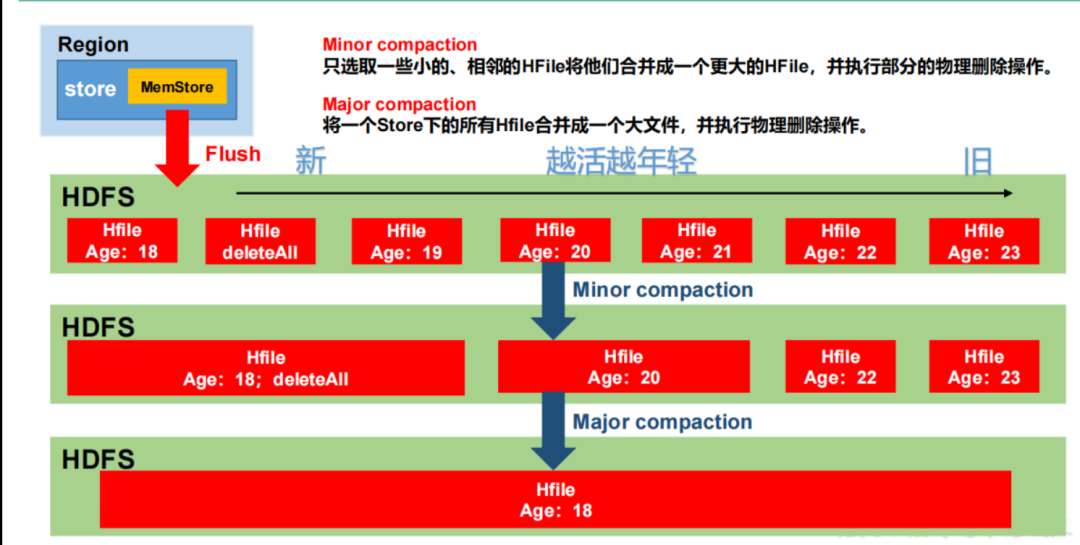
原创不易,注重版权。转载请注明原作者和原文链接 文章目录 HBase特性Hadoop的限制基本概念NameSpaceTableRowKeyColumnTimeStampCell 存储结构HBase 数据访问形式架构体系HBase组件HBase读写流程读流程写流程 MemStore Flush参数说明 StoreFile Compaction参数说明触…...
零售数据分析模板鉴赏-品类销售结构报表
不管是服装零售,还是连锁超市或者其他,只要是零售行业就绕不过商品数据分析,那么商品数据分析该怎么做?奥威BI的零售数据分析方案早早就预设好相关报表模板,点击应用后,一键替换数据源,立得新报…...

耕耘皆有回响,蓄力终会绽放
在日常的学习和生活当中,我们常常会听到这样一句话:耕耘皆有回响,蓄力终会绽放。简简单单一句话,没有华丽的辞藻,却说出了最实在的道理。不管是孩子读书求学,还是我们普通人做人做事,都离不开踏…...

云深处冲刺科创板:年营收3.4亿,净利2868万 拟募资25亿 又一杭州6小龙拟IPO
雷递网 雷建平 5月19日杭州云深处科技股份有限公司(简称:“云深处”)日前递交招股书,准备在科创板上市。云深处计划募资25亿元,其中,11.7亿元用于具身算法及模型研发项目,5.54亿用于机器人本体与…...

AI英语智能体的开发
构建一个专门用于英语学习的AI智能体(AI Agent),核心在于如何将大语言模型(LLM)的通用能力,转化为符合二语习得(SLA)理论的教学逻辑。这类智能体不仅需要“懂英语”,更需…...

告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFO+DMA实现高效CAN FD数据接收
告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFODMA实现高效CAN FD数据接收 在汽车电子和工业控制领域,CAN FD总线的高负载场景对MCU的实时性提出了严苛挑战。当波特率飙升至5Mbps、单帧数据扩展到64字节时,传统的中断接收模式会让CPU陷入…...

告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据
告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据 在雷达信号处理领域,数据采集的稳定性和效率直接影响后续算法开发的效果。传统图形界面工具mmWaveStudio虽然功能全面,但在长时间连续采集时容易出现卡顿、崩溃等…...

PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧
PolyHook 2.0导入导出表钩子:IatHook和EatHook的10个核心技巧 【免费下载链接】PolyHook_2_0 C20, x86/x64 Hooking Libary v2.0 项目地址: https://gitcode.com/gh_mirrors/po/PolyHook_2_0 PolyHook 2.0是一个功能强大的C20 x86/x64钩子库,提供…...

异步分布式k-mer计数算法DAKC解析与优化
1. 异步分布式k-mer计数算法解析 k-mer计数是基因组分析中的基础操作,它统计DNA序列中所有长度为k的子串出现频率。这项技术在基因组组装、宏基因组分析等场景中扮演着关键角色。传统方法在处理大规模数据时面临性能瓶颈,而分布式异步算法DAKC通过创新设…...

金融公共服务机构钓鱼邮件威胁治理研究 —— 以 NSI 安全事件为例
摘要 英国国家储蓄与投资机构 NS&I 近三年拦截各类恶意邮件 132,126 封,其中垃圾邮件 97,777 封,钓鱼攻击从 1,043 起激增至 4,414 起,呈现总量下降但精准化、AI 化、高危害性显著上升的趋势。作为管理海量公众资金与敏感数据的金融公共服…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...

大模型应用开发:从需求分析到上线的全流程指南
一、需求分析:锚定测试视角下的开发方向对于软件测试从业者而言,大模型应用开发的需求分析阶段,核心是跳出传统功能测试的思维局限,从“验证功能正确性”转向“定义AI能力边界”。首先要明确业务场景的核心诉求,比如开…...