【使用 TensorFlow 2】03/3 创建自定义损失函数
一、说明
TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,我们将创建代价函数并在 TensorFlow 2 中使用它们。
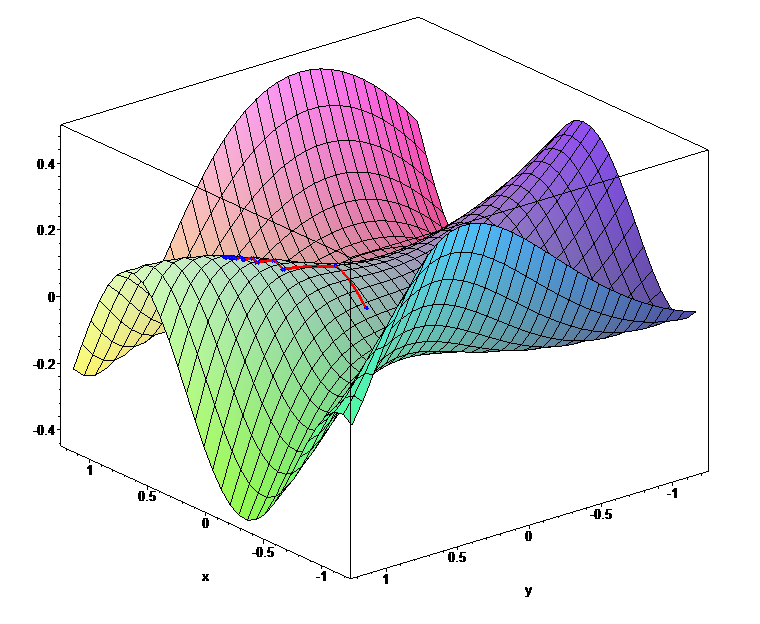
二、关于代价函数
神经网络学习将训练数据中的一组输入映射到一组输出。它通过使用某种形式的优化算法来实现这一点,例如梯度下降、随机梯度下降、AdaGrad、AdaDelta 或一些最近的算法,例如 Adam、Nadam 或 RMSProp。梯度下降中的“梯度”指的是误差梯度。每次迭代后,网络都会将其预测输出与实际输出进行比较,然后计算“误差”。通常,对于神经网络,我们寻求最小化错误。因此,用于最小化误差的目标函数通常称为成本函数或损失函数,并且由“损失函数”计算的值简称为“损失”。各种问题中使用的典型损失函数 –
A。均方误差
b. 均方对数误差
C。二元交叉熵
d. 分类交叉熵
e. 稀疏分类交叉熵
在Tensorflow中,这些损失函数已经包含在内,我们可以如下所示调用它们。
1 损失函数作为字符串
model.compile(损失='binary_crossentropy',优化器='adam',指标=['准确性'])
或者,
2. 损失函数作为对象
从tensorflow.keras.losses导入mean_squared_error
model.compile(损失=mean_squared_error,优化器='sgd')
将损失函数作为对象调用的优点是我们可以在损失函数旁边传递参数,例如阈值。
从tensorflow.keras.losses导入mean_squared_error
model.compile(损失=均方误差(参数=值),优化器='sgd')
三、使用函数创建自定义损失:
为了使用函数创建损失,我们需要首先命名损失函数,它将接受两个参数,y_true(真实标签/输出)和y_pred(预测标签/输出)。
def loss_function(y_true, y_pred):
***一些计算***
回波损耗
四、创建均方根误差损失 (RMSE):
损失函数名称 — my_rmse
目的是返回目标 (y_true) 和预测 (y_pred) 之间的均方根误差。
RMSE 公式:
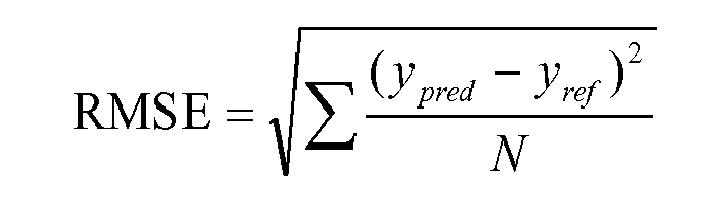
- 误差:真实标签和预测标签之间的差异。
- sqr_error:误差的平方。
- mean_sqr_error:误差平方的平均值
- sqrt_mean_sqr_error:误差平方均值的平方根(均方根误差)。
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import backend as K
#defining the loss function
def my_rmse(y_true, y_pred):#difference between true label and predicted labelerror = y_true-y_pred #square of the errorsqr_error = K.square(error)#mean of the square of the errormean_sqr_error = K.mean(sqr_error)#square root of the mean of the square of the errorsqrt_mean_sqr_error = K.sqrt(mean_sqr_error)#return the errorreturn sqrt_mean_sqr_error
#applying the loss function
model.compile (optimizer = 'sgd', loss = my_rmse)五、创建 Huber 损失

Huber损失的公式:
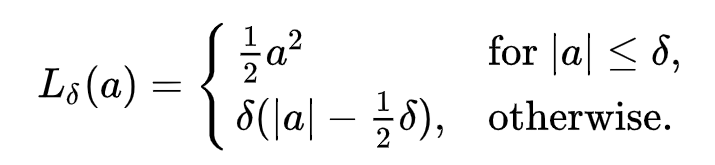
这里,
δ是阈值,
a是误差(我们将计算 a ,标签和预测之间的差异)
所以,当|a| ≤δ,损失= 1/2*(a)²
当|a|>δ 时,损失 = δ(|a| — (1/2)*δ)
代码:
# creating the Conv-Batch Norm blockdef conv_bn(x, filters, kernel_size, strides=1):x = Conv2D(filters=filters, kernel_size = kernel_size, strides=strides, padding = 'same', use_bias = False)(x)x = BatchNormalization()(x)
return x解释:
首先我们定义一个函数 - my huber loss,它接受 y_true 和 y_pred
接下来我们设置阈值 = 1。
接下来我们计算误差 a = y_true-y_pred
接下来我们检查误差的绝对值是否小于或等于阈值。is_small_error返回一个布尔值(True 或 False)。
我们知道,当|a| ≤δ,loss = 1/2*(a)²,因此我们将small_error_loss计算为误差的平方除以2 。
否则,当|a| >δ,则损失等于 δ(|a| — (1/2)*δ)。我们在big_error_loss中计算这一点。
最后,在return语句中,我们首先检查is_small_error是true还是false,如果是true,函数返回small_error_loss,否则返回big_error_loss。这是使用 tf.where 完成的。
然后我们可以使用下面的代码编译模型,
model.compile(optimizer='sgd', loss=my_huber_loss)在前面的代码中,我们始终使用阈值1。
但是,如果我们想要调整超参数(阈值)并在编译期间添加新的阈值,该怎么办?然后我们必须使用函数包装,即将损失函数包装在另一个外部函数周围。我们需要一个包装函数,因为默认情况下任何损失函数只能接受 y_true 和 y_pred 值,并且我们不能向原始损失函数添加任何其他参数。
5.1 使用包装函数的 Huber 损失
包装函数代码如下所示:
import tensorflow as tf
#wrapper function which accepts the threshold parameter
def my_huber_loss_with_threshold(threshold):def my_huber_loss(y_true, y_pred): error = y_true - y_pred is_small_error = tf.abs(error) <= threshold small_error_loss = tf.square(error) / 2 big_error_loss = threshold * (tf.abs(error) - (0.5 * threshold))return tf.where(is_small_error, small_error_loss, big_error_loss)return my_huber_loss在这种情况下,阈值不是硬编码的。相反,我们可以在模型编译期间通过阈值。
model.compile(optimizer='sgd', loss=my_huber_loss_with_threshold(threshold=1.5))5.2 使用类的 Huber 损失 (OOP)
import tensorflow as tf
from tensorflow.keras.losses import Lossclass MyHuberLoss(Loss): #inherit parent class#class attributethreshold = 1#initialize instance attributesdef __init__(self, threshold):super().__init__()self.threshold = threshold#compute lossdef call(self, y_true, y_pred):error = y_true - y_predis_small_error = tf.abs(error) <= self.thresholdsmall_error_loss = tf.square(error) / 2big_error_loss = self.threshold * (tf.abs(error) - (0.5 * self.threshold))return tf.where(is_small_error, small_error_loss, big_error_loss)MyHuberLoss是类名。在类名之后,我们从tensorflow.keras.losses继承父类'Loss'。所以MyHuberLoss继承为Loss。这允许我们使用 MyHuberLoss 作为损失函数。
__init__从类中初始化对象。
从类实例化对象时执行的调用函数
init 函数获取阈值,call 函数获取我们之前出售的 y_true 和 y_pred 参数。因此,我们将阈值声明为类变量,这允许我们给它一个初始值。
在 __init__ 函数中,我们将阈值设置为 self.threshold。
在调用函数中,所有阈值类变量将由 self.threshold 引用。
以下是我们如何在 model.compile 中使用这个损失函数。
model.compile(optimizer='sgd', loss=MyHuberLoss(threshold=1.9))六、创建对比损失(用于暹罗网络):
![]()
连体网络比较两个图像是否相似。对比损失是暹罗网络中使用的损失函数。
在上面的公式中,
Y_true 是图像相似度细节的张量。如果图像相似,它们就是 1,如果不相似,它们就是 0。
D 是图像对之间的欧几里德距离的张量。
边距是一个常量,我们可以用它来强制它们之间的最小距离,以便将它们视为相似或不同。
如果Y_true =1,则方程的第一部分变为 D²,第二部分变为零。因此,当 Y_true 接近 1 时,D² 项具有更大的权重。
如果Y_true = 0,则方程的第一部分变为零,第二部分产生一些结果。这为最大项赋予了更大的权重,而为 D 平方项赋予了更少的权重,因此最大项在损失的计算中占主导地位。
使用包装函数的对比损失
def contrastive_loss_with_margin(margin):def contrastive_loss(y_true, y_pred):square_pred = K.square(y_pred)margin_square = K.square(K.maximum(margin - y_pred, 0))return K.mean(y_true * square_pred + (1 - y_true) * margin_square)return contrastive_loss七、结论
Tensorflow 中不可用的任何损失函数都可以使用函数、包装函数或以类似的方式使用类来创建。阿琼·萨卡
相关文章:
【使用 TensorFlow 2】03/3 创建自定义损失函数
一、说明 TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,…...

Vue3中使用v-model高级用法参数绑定传值
Vue3中使用v-model高级用法参数绑定传值 单个输入框传值多个输入框传值,一个组件接受多个v-model值 单个输入框传值 App.vue <template><p>{{firstName}}</p><hello-world v-model"firstName"></hello-world> </template><…...

你的工作中,chatGPT可以帮你做什么?
如何在工作中使用 ChatGPT 的 10 种实用方法 现在您已经知道如何开始使用 ChatGPT 并了解其基本功能(提示 -> 响应),让我们探讨如何使用它来大幅提高工作效率。 1. 总结报告、会议记录等 ChatGPT可以快速分析大文本并识别关键点。例如&a…...

k8s简单部署nginx
文章目录 1. 前言2. 部署nginx2.1. **创建一个nginx的Deployment**2.2. **创建一个nginx的service** 3. 总结 1. 前言 前文提要: kubeadm简单搭建k8s集群第三方面板部署k8s 上篇文章我们简单部署了k8s的集群环境,相比一定迫不及待的想部署一个实际应用了…...
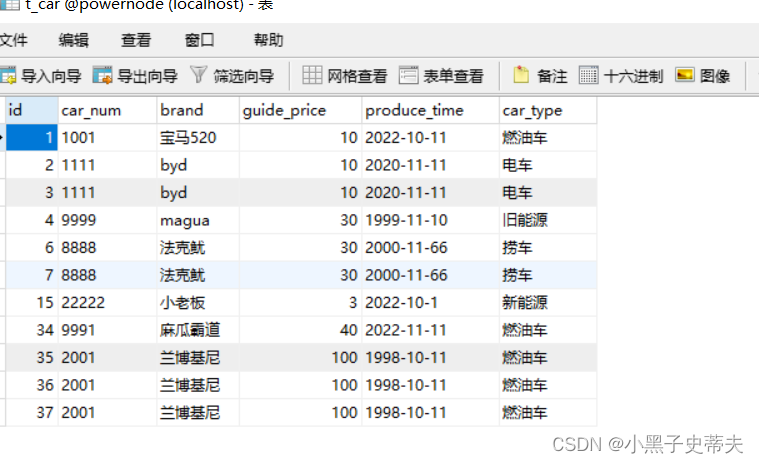
小黑子—MyBatis:第四章
MyBatis入门4.0 十 小黑子进行MyBatis参数处理10.1 单个简单类型参数10.1.1 单个参数Long类型10.1.2 单个参数Date类型 10.2 Map参数10.3 实体类参数(POJO参数)10.4 多参数10.5 Param注解(命名参数)10.6 Param注解源码分析 十一 小…...
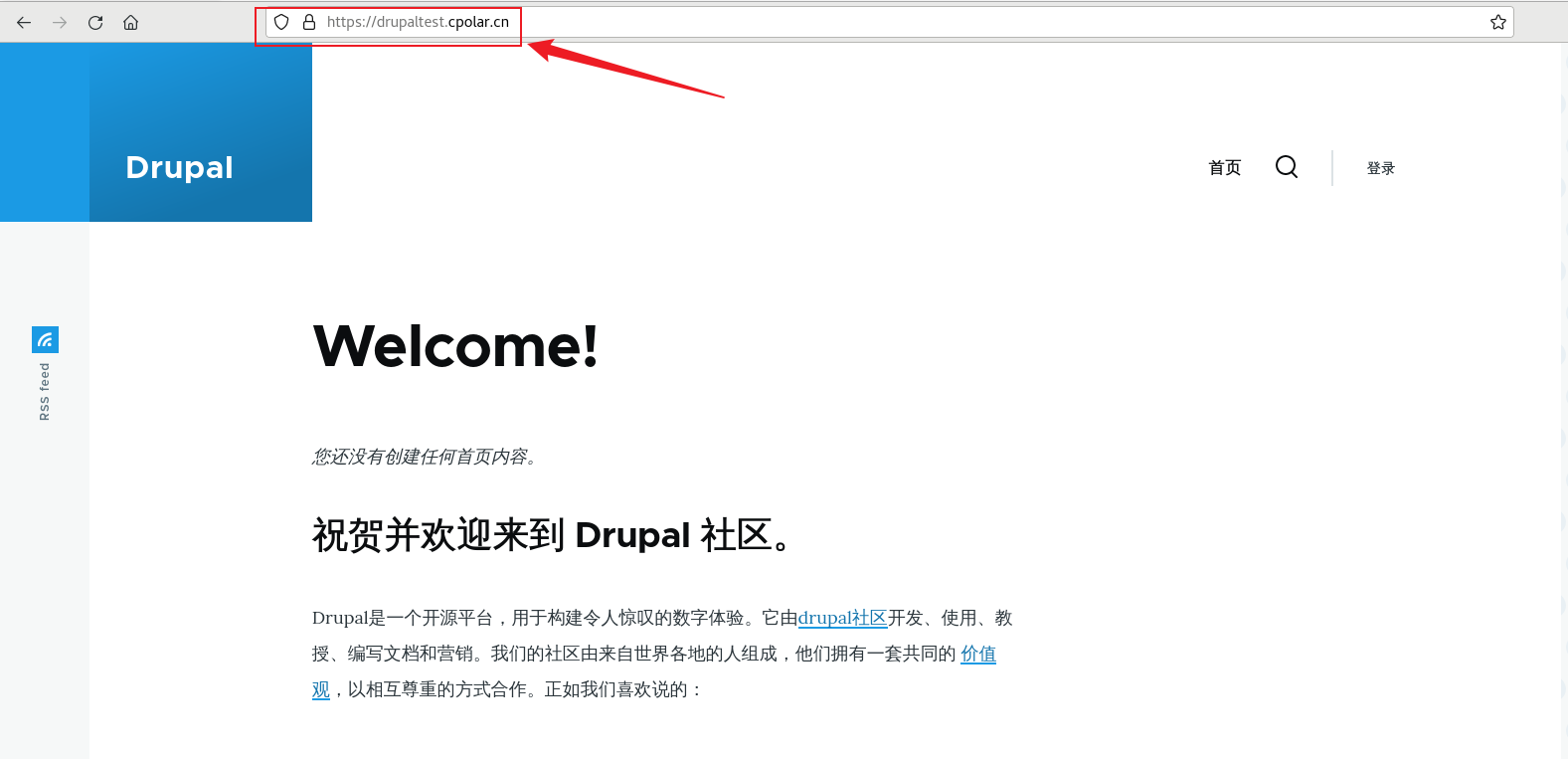
Docker快速上手:使用Docker部署Drupal并实现公网访问
文章目录 前言1. Docker安装Drupal2. 本地局域网访问3 . Linux 安装cpolar4. 配置Drupal公网访问地址5. 公网远程访问Drupal6. 固定Drupal 公网地址 前言 Dupal是一个强大的CMS,适用于各种不同的网站项目,从小型个人博客到大型企业级门户网站。它的学习…...
-每天10个小知识)
React知识点系列(1)-每天10个小知识
目录 1.什么是 React,以及它在前端开发中的优势是什么?2.你是如何组织和管理 React 组件的?3.你能解释一下 React 的生命周期方法吗?你通常在哪个生命周期方法中发起网络请求?4.什么是 React Hooks?你常用哪…...

substring 和 substr 的区别
1、结论 两个方法都用于截取字符串,其用法不同: 1)相同点: ① 都用于截取字符串; ② 第一个参数都是表示提取字符的开始索引位置; 2)不同点: ① 第一个参数的取值范围不同&…...

产品经理的工作职责是什么?
产品经理的工作职责主要包括以下几个方面: 1. 产品策划与定义:产品经理负责制定产品的整体策略和规划,包括产品定位、目标用户、市场需求分析等。他们需要与团队合作,定义产品的功能和特性,明确产品的核心竞争力和差异…...

智能井盖传感器:提升城市安全与便利的利器
在智能化城市建设的浪潮中,WITBEE万宾智能井盖传感器,正以其卓越的性能和创新的科技,吸引着越来越多的关注。本文小编将为大家详细介绍这款产品的独特优势和广阔应用前景。 在我们生活的城市中,井盖可能是一个最不起眼的存在。然而…...
给你一个项目,你将如何开展性能测试工作?
一、性能三连问 1、何时进行性能测试? 性能测试的工作是基于系统功能已经完备或者已经趋于完备之上的,在功能还不够完备的情况下没有多大的意义。因为后期功能完善上会对系统的性能有影响,过早进入性能测试会出现测试结果不准确、浪费测试资…...

点燃市场热情,让产品风靡全球——实用推广策略大揭秘!
文章目录 一、实用推广策略的重要性1. 提高产品知名度和认可度2. 拓展产品市场和用户群体3. 增强企业品牌形象和市场竞争力 二、实用推广策略的种类1. 社交媒体推广2. 定向推广3. 口碑营销4. 内容推广 三、实用推广策略的实施步骤1. 研究目标用户和市场需求,明确产品…...

Python操作Hive数据仓库
Python连接Hive 1、Python如何连接Hive?2、Python连接Hive数据仓库 1、Python如何连接Hive? Python连接Hive需要使用Impala查询引擎 由于Hadoop集群节点间使用RPC通信,所以需要配置Thrift依赖环境 Thrift是一个轻量级、跨语言的RPC框架&…...

客户收到报价后突然安静了,怎么办?
外贸人常常会有这样的经历:与意向度很高的客户数封邮件沟通报价之后,突然客户那边就沉静下来了,而不知所措,遇到这样的客户,应该怎么办呢? Vol.1 了解客户信息 首先自身要养成一个好习惯,针对…...
常见知识之 mysql 数据库备份)
O2OA(翱途)常见知识之 mysql 数据库备份
概述 系统运行一段时间后,可能发生各种情况导致数据丢失,如硬件故障、人为错误、软件错误、病毒攻击等。定期备份可以帮助您保护数据免受这些风险的影响,以便在需要时能够恢复数据。 O2OA应用本身可以通过dump配置每天自定备份数据ÿ…...

如何让你的程序支持lua脚本
最近做了一个控制机械臂的程序,使用C语言开发的,调试的时候总是需要修改代码来调整运动轨迹, 总是要编译,实在烦人 不过有个方法就是使用lua来调试运动逻辑 代码如下 static int lua_up(lua_State*l) {size_t stepluaL_checkinteger(l,1);//向上动作up(step);return 0; }st…...
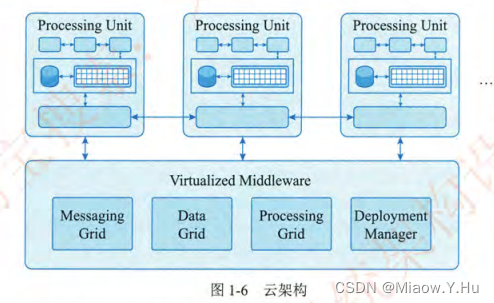
什么是系统架构师?什么是系统架构?
1. 什么是系统架构师? 系统架构设计师(System Architecture Designer)是项目开发活动中的关键角色之一。系统架构是系统的一种整体的高层次的结构表示,是系统的骨架和根基,其决定了系统的健壮性和生命周期的长短。 系统架构设计…...

大数据NoSQL数据库HBase集群部署
目录 1. 简介 2. 安装 1. HBase依赖Zookeeper、JDK、Hadoop(HDFS),请确保已经完成前面 2. 【node1执行】下载HBase安装包 3. 【node1执行】,修改配置文件,修改conf/hbase-env.sh文件 4. 【node1执行】…...

百乐钢笔维修(官方售后,全流程)
文章目录 1 背景2 方法3 结果 1 背景 在给钢笔上墨的途中,不小心总成掉地上了,把笔尖摔弯了(虽然还可以写字,但是非常的挂纸),笔身没有什么问题,就想着维修一下笔尖或者替换一下总成。 一般维…...

Redis 介绍安装
数据库 关系型数据库 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。 SQL 语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型…...

DyDiT++动态计算架构:优化扩散模型效率
1. 动态计算架构DyDiT的核心设计理念 在生成式AI领域,扩散模型因其出色的生成质量而备受关注,但其高昂的计算成本一直是实际应用的主要瓶颈。传统静态架构在处理不同复杂度任务时采用相同的计算资源配置,这造成了显著的资源浪费。DyDiT通过动…...

产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则
产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则 在互联网产品的世界里,每天都有无数场看不见的博弈正在上演——司机与乘客的匹配、商家与消费者的互动、创作者与平台的共生。这些看似复杂的商业行为背后,往往遵循着…...
)
Cadence Virtuoso新手避坑指南:手把手教你画反相器原理图(附3.3V工艺库设置)
Cadence Virtuoso新手避坑指南:3.3V工艺库反相器设计全流程解析 第一次打开Cadence Virtuoso时,那个充满专业术语的界面就像面对一架航天飞机的控制台——每个按钮都暗藏玄机,每次点击都可能引发未知错误。作为模拟IC设计的行业标准工具&…...

终极免费二维码修复方案:QRazyBox专业工具完全指南
终极免费二维码修复方案:QRazyBox专业工具完全指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox这款强大的QR二维码修…...

从Polycam扫描到自定义街道:用3D高斯泼溅碎片‘搭积木’创建虚拟场景的完整流程
从Polycam扫描到自定义街道:用3D高斯泼溅碎片‘搭积木’创建虚拟场景的完整流程 走在城市的街道上,你是否曾想过把那些有趣的街景元素——复古的路灯、造型独特的长椅、枝繁叶茂的行道树——全都数字化,然后像玩乐高一样重新组合成自己理想中…...

3步打造你的专属Minecraft领地世界:PlotSquared终极指南
3步打造你的专属Minecraft领地世界:PlotSquared终极指南 【免费下载链接】PlotSquared PlotSquared - Reinventing the plotworld 项目地址: https://gitcode.com/gh_mirrors/pl/PlotSquared 还在为Minecraft服务器管理混乱而烦恼吗?想要创建一个…...

基于ESP32的嵌入式AI语音交互系统:从硬件设计到软件实现全解析
1. 项目概述:从零打造一个会聊天的嵌入式AI伙伴几年前,当我第一次把“小爱同学”拆开,看到里面密密麻麻的芯片和电路时,一个念头就冒了出来:能不能自己动手,用一块开发板,从头搭建一个能听会说、…...

别焦虑,也别躺平:给年轻程序员的一封信
2026年了,程序员这个行业,和前几年的感觉已经完全不一样了。以前大家更多的是在想: 谁会的框架多谁加班狠谁能把CRUD写得飞快 现在很多东西,AI十几秒就能生成。不少年轻程序员开始焦虑: “以后是不是不需要程序员了&am…...
)
从Demo到实战:手把手教你用OpenMMLab的MMDetection训练自己的第一个目标检测模型(附数据集制作)
从零构建目标检测模型:OpenMMLab实战指南与数据集制作全流程 当你第一次成功运行OpenMMLab的Demo时,那种成就感可能很快会被新的困惑取代——如何让这套强大的工具识别你自己的数据?本文将带你跨越从"跑通示例"到"训练自定义模…...

信步SV3b-19016EP嵌入式主板深度解析:从选型到实战应用
1. 项目概述:为什么是SV3b-19016EP?在嵌入式系统开发这个行当里,选型永远是项目成败的第一步。最近几年,随着边缘计算、工业自动化、智能零售这些场景的爆发,大家对嵌入式主板的性能、接口丰富度和可靠性要求越来越高。…...