【动手学深度学习-Pytorch版】BERT预测系列——BERTModel
本小节主要实现了以下几部分内容:
- 从一个句子中提取BERT输入序列以及相对的segments段落索引(因为BERT支持输入两个句子)
- BERT使用的是Transformer的Encoder部分,所以需要需要使用Encoder进行前向传播:输出的特征等于词嵌入+位置编码+Encoder块
- 用于BERT预训练时预测的掩蔽语言模型任务中的掩蔽标记
< mask > - 用于预训练任务的下一个句子的预测——在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
- 通过
BERTModel整合代码
"""可学习的位置编码也需要进行初始化"""
import torch
import d2l.torch
from torch import nn
import transformers
"""将一个句子或者两个句子作为输入,然后返回BERT输入序列及其相应的序列对的片段索引segments"""
def get_tokens_segments(tokens_a,tokens_b=None):"""获取输入序列的词元及其片段索引"""tokens = ['<cls>'] + tokens_a + ['<sep>']# 利用0和1分别标记片段A和片段Bsegments = [0] * (len(tokens_a)+2) #加上<cls>和sepif tokens_b is not None:# 如果是句子对tokens += tokens_b+['<sep>']segments += [1]*(len(tokens_b)+1) # 加上<sep>return tokens,segments"""在原始的Transformer架构中,编码器的位置嵌入信息是直接加到了输入序列的每个位置,但是BERT使用的是可学习的位置嵌入"""
"""bert-input = tokens_embedding + position_embedding + segment_embedding"""
class BERTEncoder(nn.Module):"""BERT编码器"""def __init__(self,vocab_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout,max_len=1000,key_size=768,query_size=768,value_size=768,use_bias=True):super(BERTEncoder, self).__init__()self.token_embedding = nn.Embedding(vocab_size,num_hiddens)self.segment_embedding = nn.Embedding(2,num_hiddens)# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入的参数self.pos_embedding = nn.Parameter(torch.randn(size=(1,max_len,num_hiddens)))# print('self.pos_embedding:',self.pos_embedding)"""self.pos_embedding.data : [1,1000,768]在下面与X相加时利用的是广播机制"""self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module(f'{i}',d2l.torch.EncoderBlock(key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,use_bias))def forward(self,tokens,segments,valid_lens):# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)X = self.token_embedding(tokens)+self.segment_embedding(segments)print('X.shape:',X.shape) # [2,8,768]X += self.pos_embedding.data[:,:X.shape[1],:] #[2,8,768]for blk in self.blks:X = blk(X,valid_lens)return X
"""演示BERTEncoder的前向传播--->词表大小:10000"""
vocab_size,num_hiddens,ffn_num_input,ffn_num_hiddens,num_heads,num_layers = 1000,768,768,1024,4,2
norm_shape,dropout = [768],0.2
encoder = BERTEncoder(vocab_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout)
"""将tokens定义为长度为8的2个输入序列"""
tokens = torch.randint(0,vocab_size,(2,8))
print('tokens:',tokens)
print('tokens_shape:',tokens.shape)
"""其中每个词元由向量表示,其长度由超参数num_hiddens定义,此超参数通常称为Transformer编码器的隐藏大小(隐藏单元数)"""
segments = torch.tensor([[0,0,0,0,1,1,1,1],[0,0,0,1,1,1,1,1]])
print('segments:',segments)
enc_outputs = encoder(tokens,segments,None)
print('enc_outputs.shape',enc_outputs.shape)# 预训练任务---》双向编码上下文:掩蔽语言模型
"""预测BERT预训练的掩蔽语言模型任务中的掩蔽标记"""
#@save
class MaskLM(nn.Module):"""BERT的掩蔽语言模型任务"""def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):super(MaskLM, self).__init__(**kwargs)# 两层的MLP,同时使用激活函数ReLU 和 层归一化self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),nn.ReLU(),nn.LayerNorm(num_hiddens),nn.Linear(num_hiddens, vocab_size))# 前向传播时的输入信息包括:# 1 BERTEncoder编码结果# 2 用于预测词元的位置def forward(self, X, pred_positions):num_pred_positions = pred_positions.shape[1]# 将预测的位置压缩成一维向量空间pred_positions = pred_positions.reshape(-1)# BERTEncoder的输出特征形状:[batch_size,...]batch_size = X.shape[0]batch_idx = torch.arange(0, batch_size)# 假设batch_size=2,num_pred_positions=3# 那么batch_idx是np.array([0,0,0,1,1,1])# torch.repeat_interleave用于重复张量元素batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)print('输入的X形状:',X.shape)# batch_idx# pred_positions# 都是两个list其中batch_idx选择的是屏蔽的行# pred_positions选择的是屏蔽的列masked_X = X[batch_idx, pred_positions]print('masked后X的内容:',masked_X)# 最后把所有要屏蔽的数据拉成一个一维的向量masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))mlm_Y_hat = self.mlp(masked_X)# 最后返回的是利用MLP预测这些位置的结果return mlm_Y_hat"""将mlm_positions定义为在encoded_X的任一输如系列中预测3个值"""
"""而且对于每一个预测的结果都等于词表的大小"""
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(enc_outputs, mlm_positions)
mlm_Y_hat_shape = mlm_Y_hat.shape
print('mlm_Y_hat_shape:',mlm_Y_hat_shape)# 通过掩码下的预测词元mlm_Y的真实标签mlm_Y_hat,我们可以计算在BERT预训练中的遮蔽语言模型任务的交叉熵损失
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l_shape = mlm_l.shape
print('mlm_l_shape:',mlm_l_shape)# 预训练任务---》下一个句子的预测
"""在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
"""
#@save
class NextSentencePred(nn.Module):"""BERT的下一句预测任务"""def __init__(self, num_inputs, **kwargs):super(NextSentencePred, self).__init__(**kwargs)self.output = nn.Linear(num_inputs, 2)def forward(self, X):# X的形状:(batchsize,num_hiddens)return self.output(X)
"""NextSentencePred实例的前向推断返回每个BERT输入序列的二分类预测"""
enc_outputs = torch.flatten(enc_outputs, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(enc_outputs.shape[-1])
nsp_Y_hat = nsp(enc_outputs)
print('nsp_Y_hat.shape',nsp_Y_hat.shape)
# 计算两个二元分类的交叉熵损失
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l_shape = nsp_l.shape
print('nsp_l_shape:',nsp_l_shape)#@save
class BERTModel(nn.Module):"""BERT模型"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,hid_in_features=768, mlm_in_features=768,nsp_in_features=768):super(BERTModel, self).__init__()self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, num_layers,dropout, max_len=max_len, key_size=key_size,query_size=query_size, value_size=value_size)self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),nn.Tanh())self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self.nsp = NextSentencePred(nsp_in_features)def forward(self, tokens, segments, valid_lens=None,pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat相关文章:

【动手学深度学习-Pytorch版】BERT预测系列——BERTModel
本小节主要实现了以下几部分内容: 从一个句子中提取BERT输入序列以及相对的segments段落索引(因为BERT支持输入两个句子)BERT使用的是Transformer的Encoder部分,所以需要需要使用Encoder进行前向传播:输出的特征等于词…...

Python之元组、字典和集合练习
1、餐厅下午茶 (列表与元组 crr66) 某餐厅推出了优惠下午茶套餐活动。顾客可以以优惠的价格从给定的糕点和给定的饮 料中各选一款组成套餐。已知,指定的糕点包括松饼(Muffins)、提拉米苏(Tiramisu)、芝士蛋 糕(Cheese Cake)和三明治(Sandwic…...
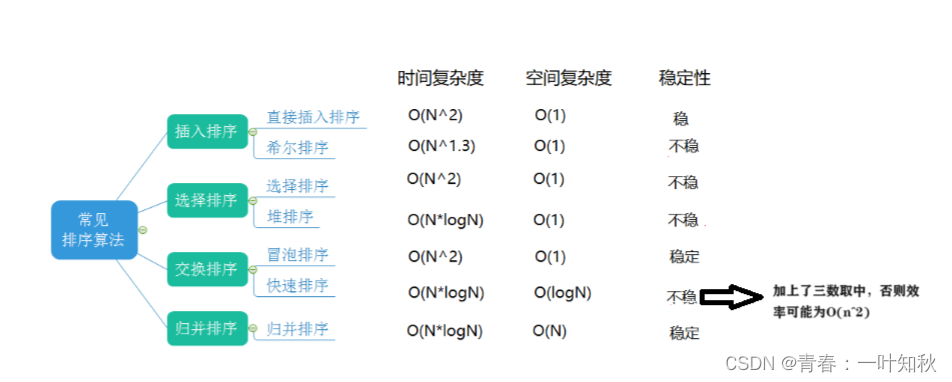
【数据结构】归并排序和计数排序(排序的总结)
目录 一,归并排序的递归 二,归并排序的非递归 三,计数排序 四,排序算法的综合分析 一,归并排序的递归 基本思想: 归并采用的是分治思想,是分治法的一个经典的运用。该算法先将原数据进行拆…...

某医疗机构:建立S-SDLC安全开发流程,保障医疗前沿科技应用高质量发展
某医疗机构是头部资本集团旗下专注大健康领域战略性投资与运营的实业公司,市场规模超300亿。该医疗机构已完成数字赋能,形成了标准化、专业化、数字化的疾病和健康管理体系,将进一步规划战略方向,为人工智能纳米技术、高温超导、生…...

验证二叉搜索树的后序遍历序列
LCR 152. 验证二叉搜索树的后序遍历序列 class VerifyTreeOrder:"""LCR 152. 验证二叉搜索树的后序遍历序列https://leetcode.cn/problems/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof/description/"""def solution(self, postorder: Lis…...
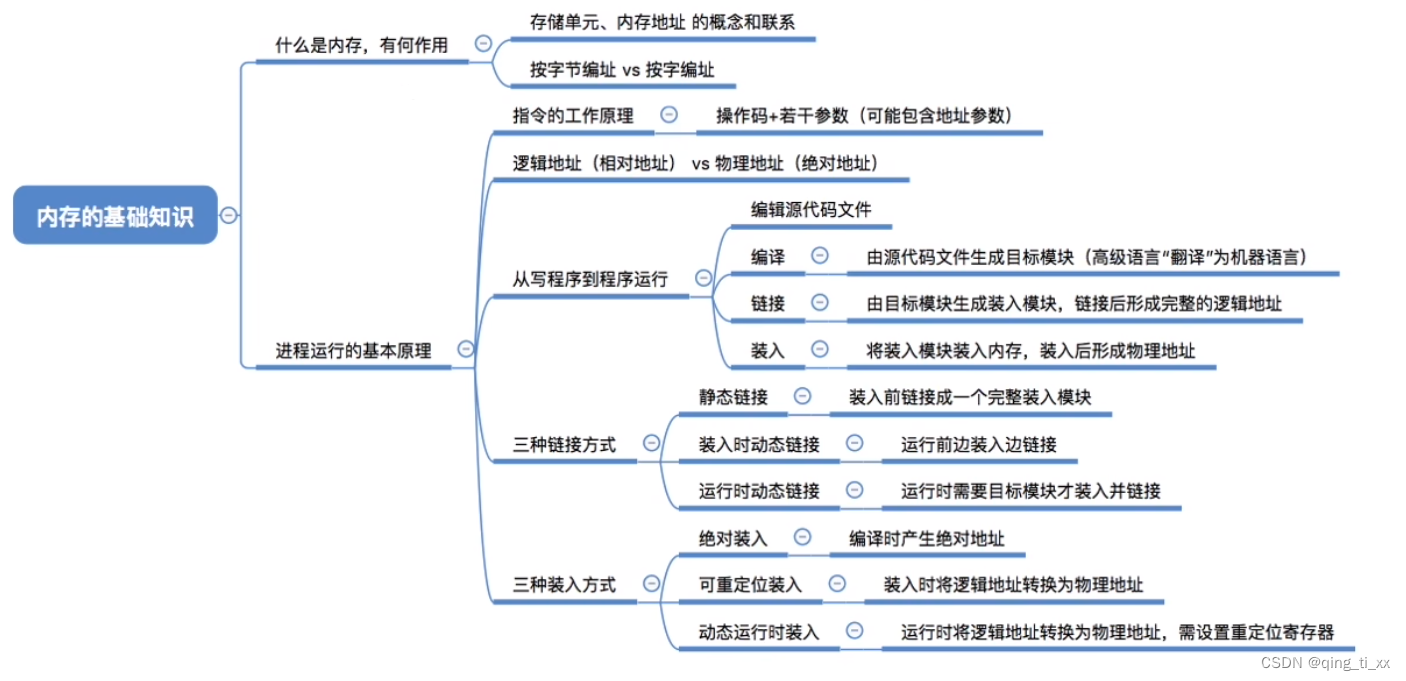
第三章 内存管理 一、内存的基础知识
目录 一、什么是内存 二、有何作用 三、常用数量单位 四、指令的工作原理 五、装入方式 1、绝对装入 2、可重定位装入(静态重定位) 3、动态运行时装入(动态重定位) 六、从写程序到程序运行 七、链接的三种方式 1、静态…...

【Java学习之道】Java常用集合框架
引言 在Java中,集合框架是一个非常重要的概念。它提供了一种方式,让你可以方便地存储和操作数据。Java中的集合框架包括各种集合类和接口,这些类和接口提供了不同的功能和特性。通过学习和掌握Java的集合框架,你可以更好地管理和…...
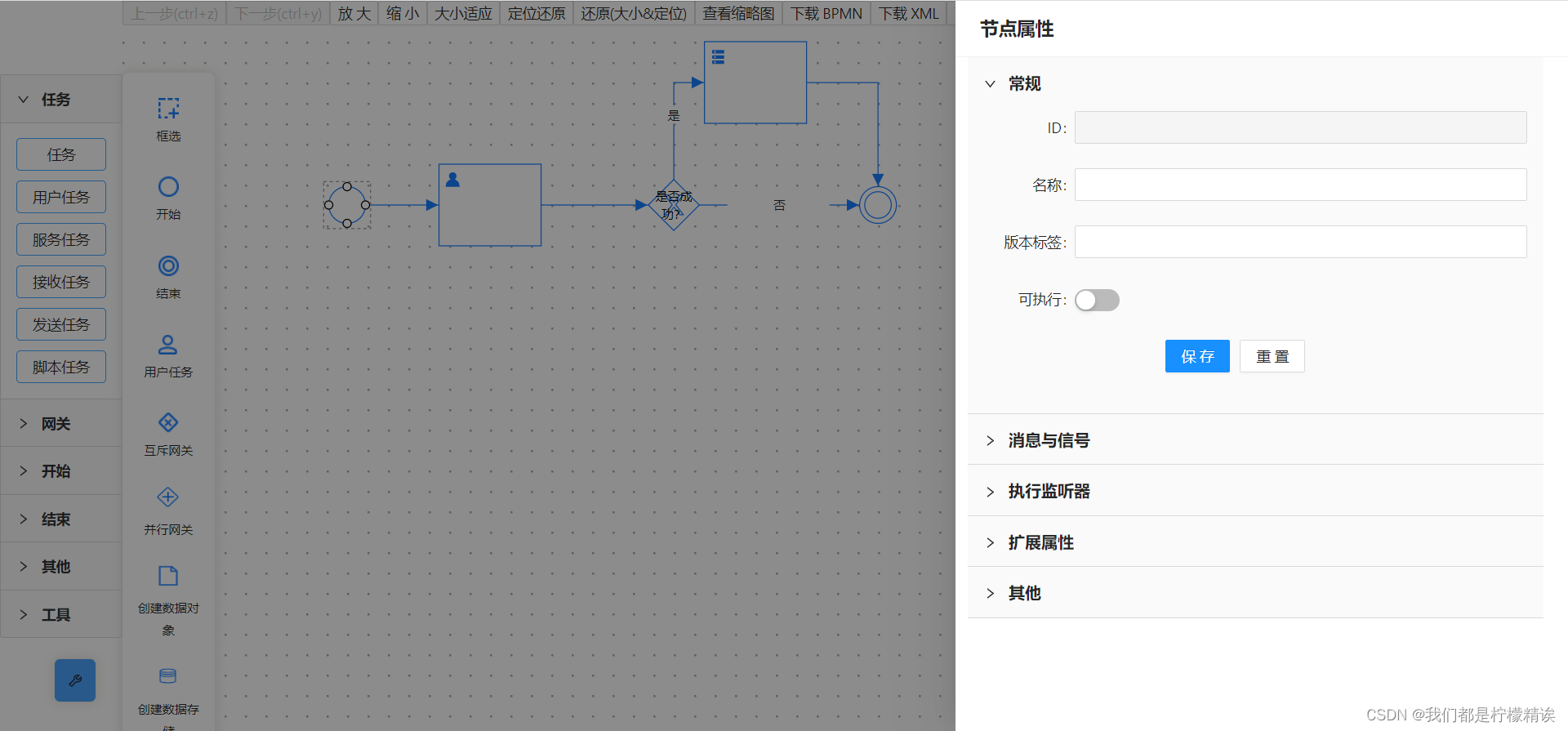
logicFlow 流程图编辑工具使用及开源地址
一、工具介绍 LogicFlow 是一款流程图编辑框架,提供了一系列流程图交互、编辑所必需的功能和灵活的节点自定义、插件等拓展机制。LogicFlow 支持前端研发自定义开发各种逻辑编排场景,如流程图、ER 图、BPMN 流程等。在工作审批配置、机器人逻辑编排、无…...
/OPTEE之动态代码分析汇总)
ATF(TF-A)/OPTEE之动态代码分析汇总
安全之安全(security)博客目录导读 1、ASAN(AddressSanitizer)地址消毒动态代码分析 2、ATF(TF-A)之UBSAN动态代码分析 3、OPTEE之KASAN地址消毒动态代码分析...

10-11 周三 shell xargs tr curl 做大事情
最近发现,shell的小工具非常的强大,简单记录下 tr命令 -d 删除字符串1中所有输入字符。-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串 -d 用于删除查询到的字符串中的空格。 [test3NH-DC-NM1…...

1.1 向量与线性组合
一、向量的基础知识 两个独立的数字 v 1 v_1 v1 和 v 2 v_2 v2,将它们配对可以产生一个二维向量 v \boldsymbol{v} v: 列向量 v v [ v 1 v 2 ] v 1 v 的第一个分量 v 2 v 的第二个分量 \textbf{列向量}\,\boldsymbol v\kern 10pt\boldsymbol …...

django: You may need to add ‘localhost‘ to ALLOWED_HOSTS
参考:https://blog.csdn.net/qq_21744873/article/details/87857279 python manage.py runserver后页面访问失败,提示: DisallowedHost at /admin/ Invalid HTTP_HOST header: ‘localhost:8000’. You may need to add ‘localhost’ to ALLOWED_HOSTS…...

网络安全(黑客技术)—自学手册
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
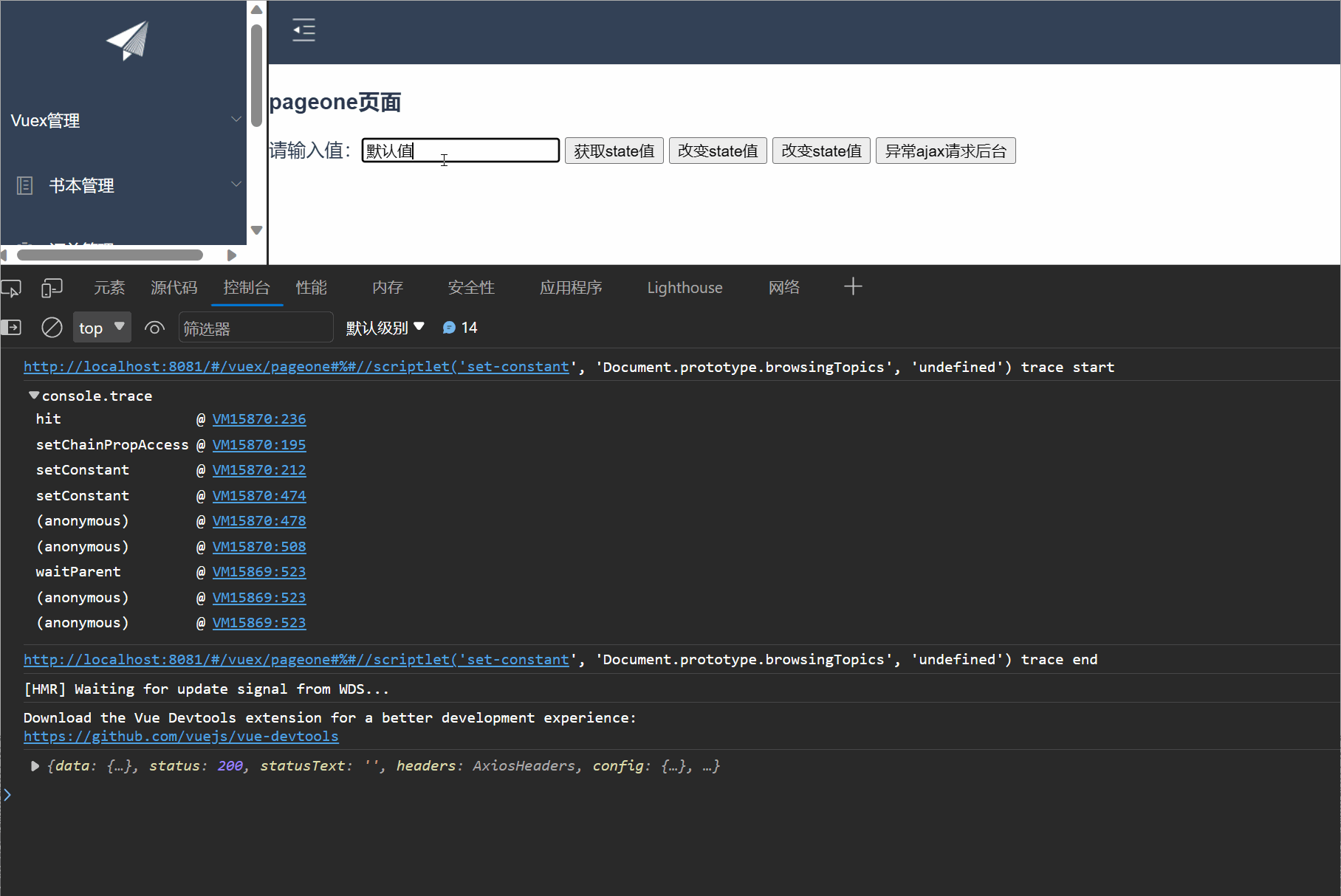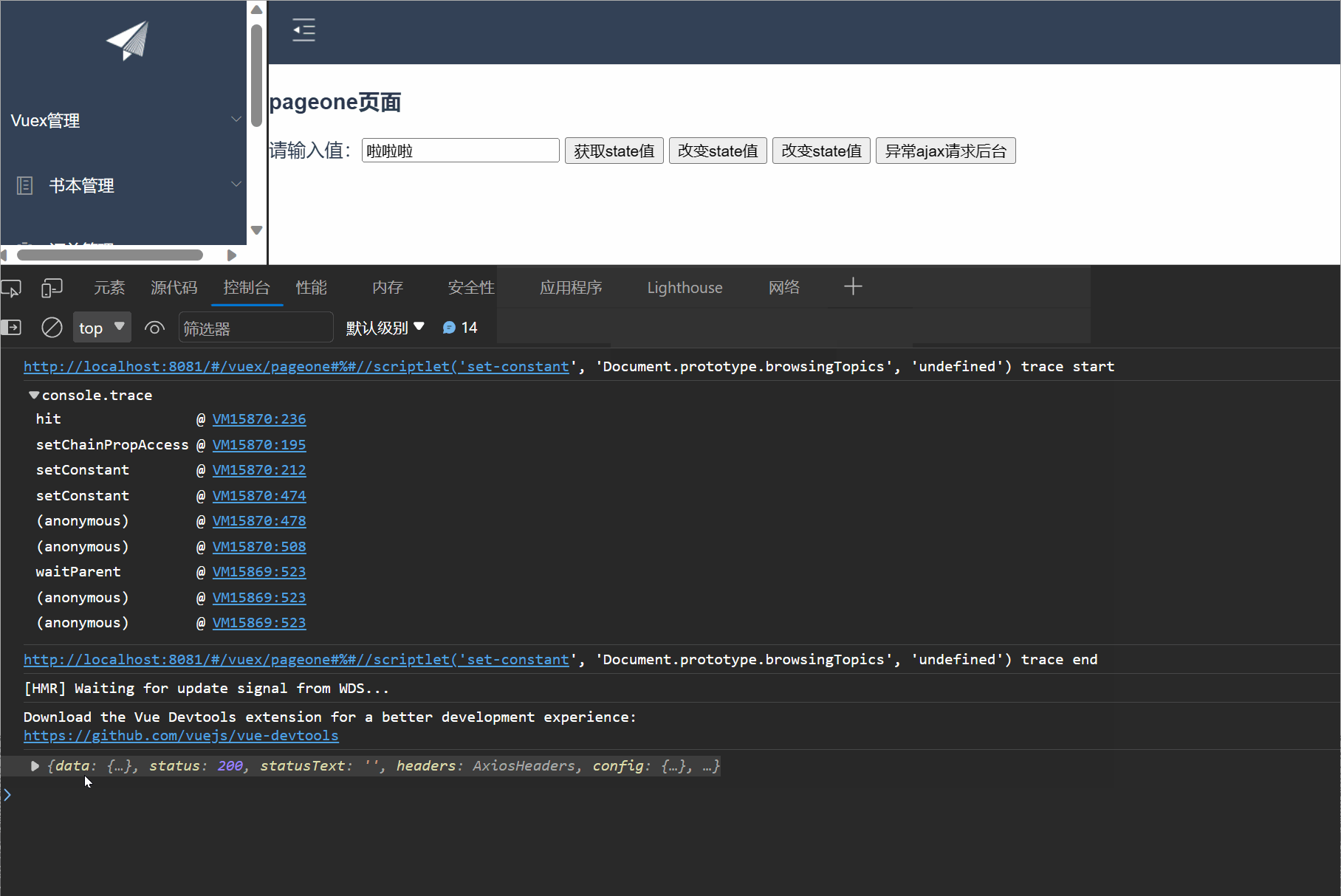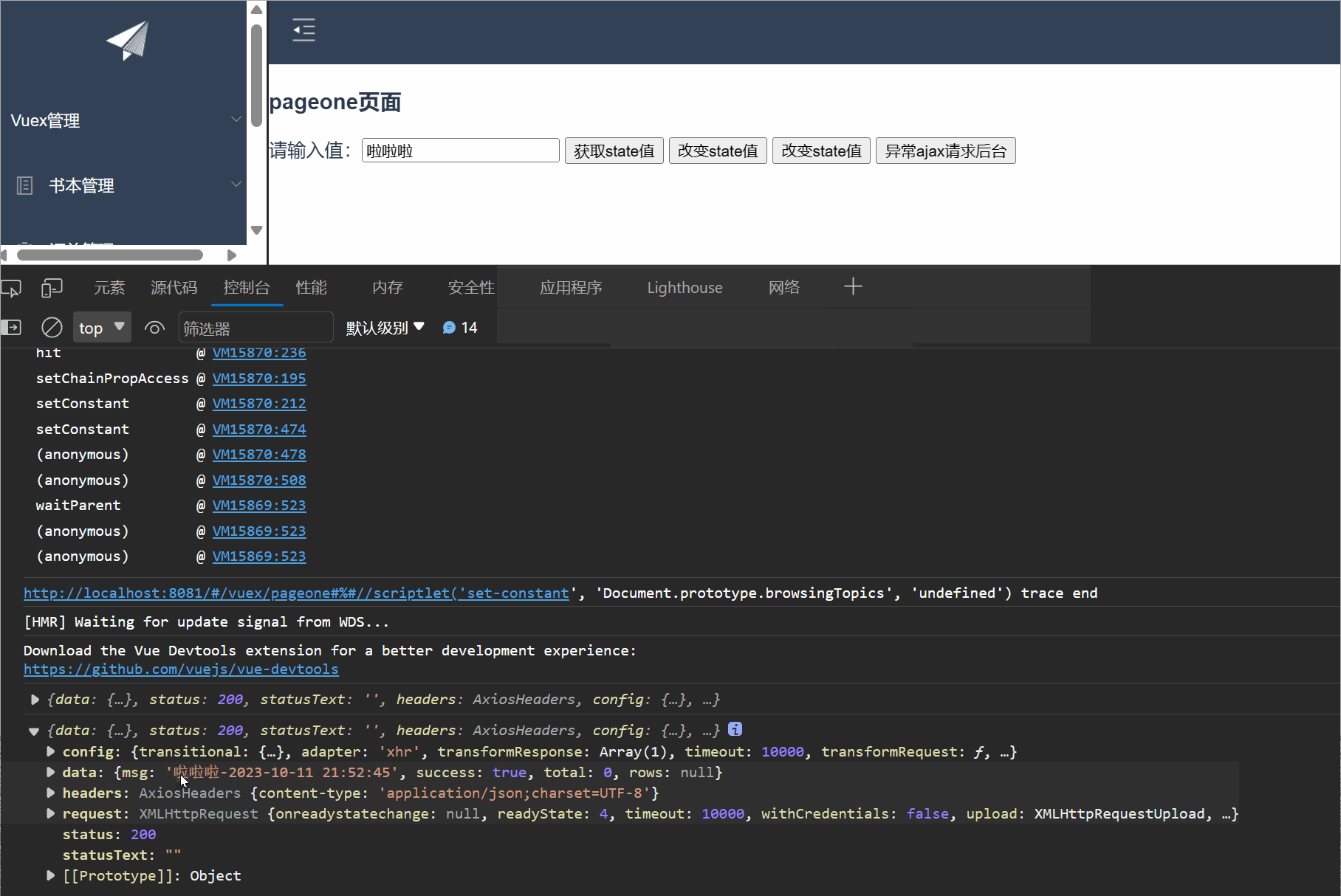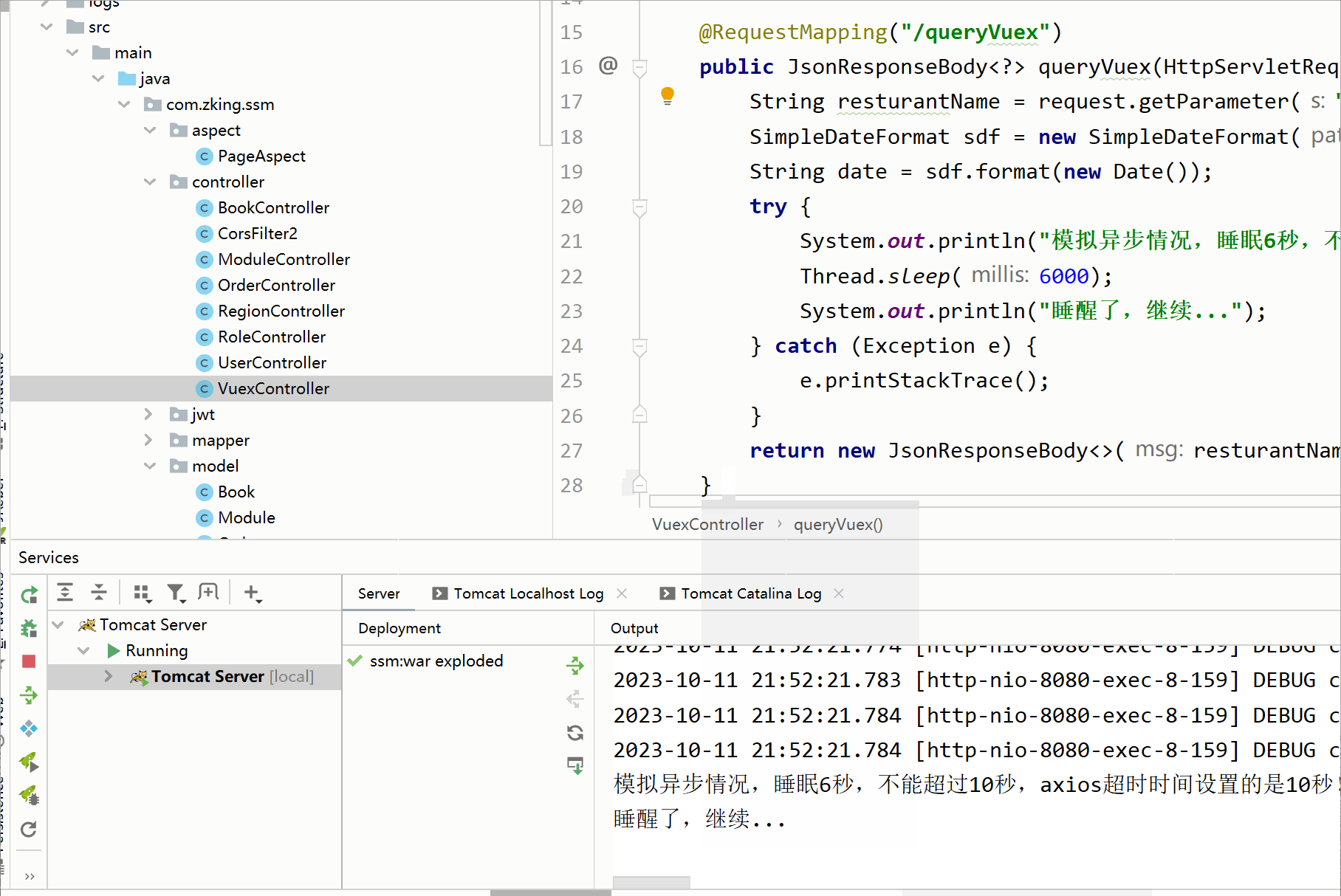
【Vue】之Vuex的入门使用,取值,修改值,同异步请求处理---保姆级别教学
一,Vuex入门 1.1 什么是Vuex Vuex是一个专门为Vue.js应用程序开发的状态管理库。它用于管理应用程序中的共享状态,它采用集中式存储管理应用的所有组件的状态,使得状态的管理变得简单和可预测 官方解释:Vuex 是一个专为 Vue.js 应…...
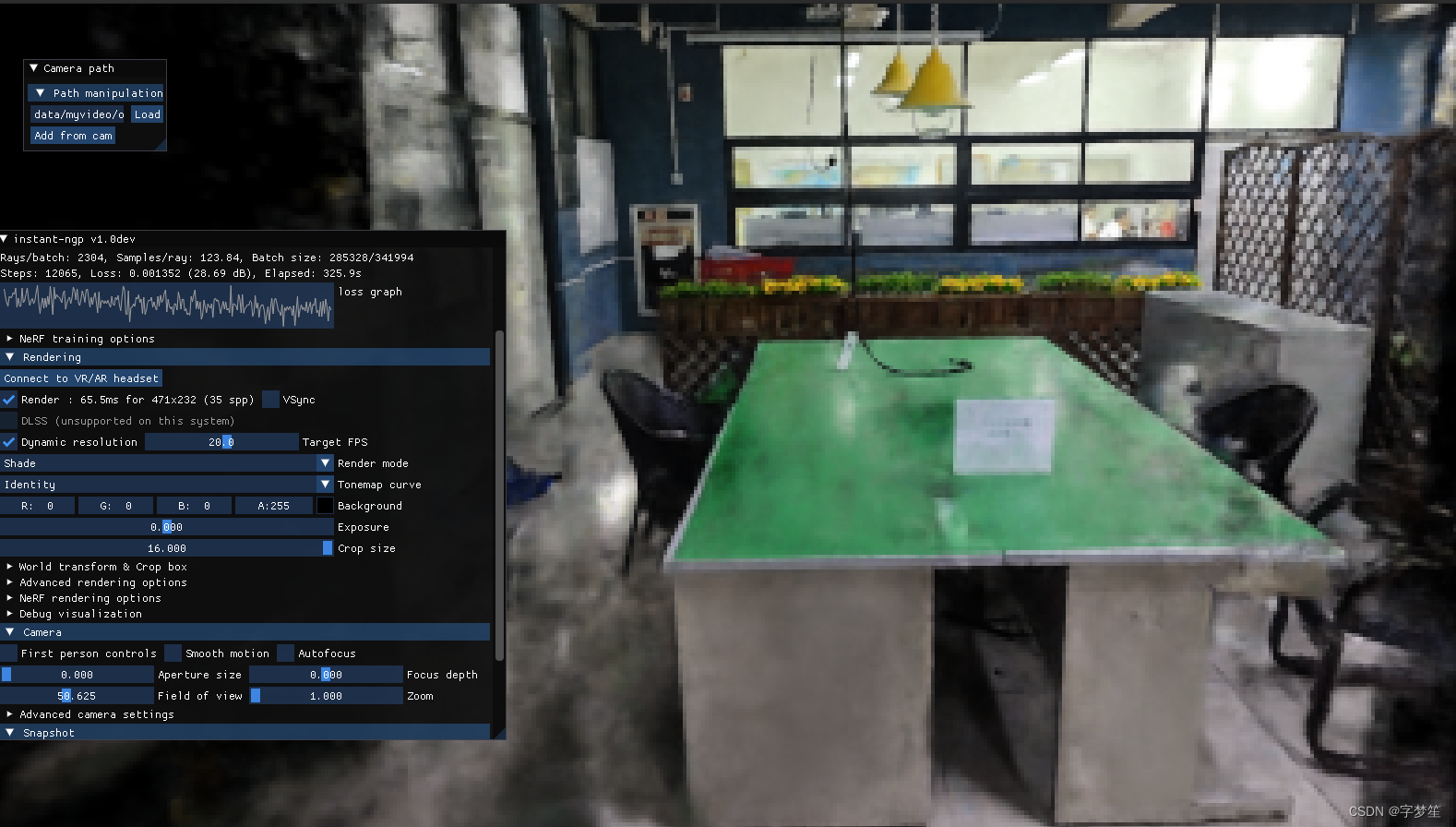
ubuntu20.04 nerf Instant-ngp (下) 复现,自建数据集,导出mesh
参考链接 Ubuntu20.04复现instant-ngp,自建数据集,导出mesh_XINYU W的博客-CSDN博客 GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more youtube上的一个博主自建数据集 https://www.youtube.com/watch…...
【常见错误】SVN提交项目时,出现了这样的提示:“XXX“ is scheduled for addition, but is missing。
SVN提交项目时,出现了这样的提示:“XXX“ is scheduled for addition, but is missing。 原因是:之前用SVN提交过的文件/文件夹,被标记为"addition"状态,等待被加入到仓库。虽然你把这个文件删除了…...
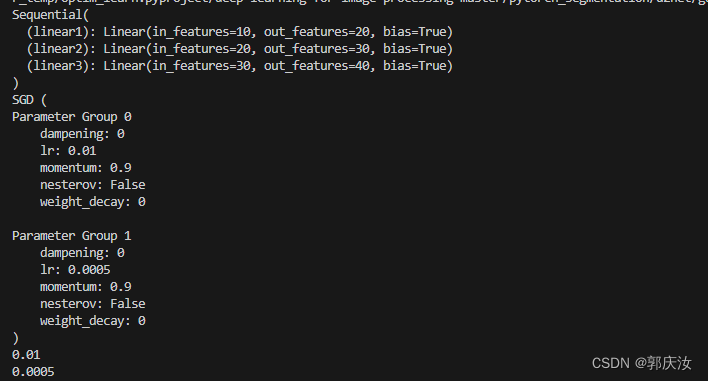
深度学习基础知识 给模型的不同层 设置不同学习率
深度学习基础知识 给模型的不同层 设置不同学习率 1、使用预训练模型时,可能需要将2、学习率设置方式: 1、使用预训练模型时,可能需要将 (1)预训练好的 backbone 的 参数学习率设置为较小值, (2…...

【Python 零基础入门】 Numpy
【Python 零基础入门】第六课 Numpy 概述什么是 Numpy?Numpy 与 Python 数组的区别并发 vs 并行单线程 vs 多线程GILNumpy 在数据科学中的重要性 Numpy 安装Anaconda导包 ndarraynp.array 创建数组属性np.zeros 创建np.ones 创建 数组的切片和索引基本索引切片操作数组运算 常…...

1600*C. Circle of Monsters(贪心)
Problem - 1334C - Codeforces 解析: 对于某个怪兽,他的耗费为两种情况,要么直接用子弹打,要么被前面的怪兽炸,显然第二种情况耗费更少。 统计出所有怪兽的 max(0,a[ i ] - b[ i - 1 ]ÿ…...

国外互联网巨头常用的项目管理工具揭秘
大型互联网公司有涉及多个团队和利益相关者的复杂项目。为了保持项目的组织性和效率,他们中的许多人依赖于项目管理工具。这些工具有助于跟踪任务,与团队成员沟通,并监控进度。让我们来看看一些大型互联网公司正在使用的项目管理工具。 1、Zo…...

阿里企业邮箱代理:阿里企业邮箱与钉钉协同办公技术实践
前言在国内企业数字化办公趋势下,单一邮件通讯早已无法满足企业日常管理需求,邮箱与内部办公软件深度融合成为主流趋势。阿里企业邮箱与钉钉生态无缝打通,实现账号互通、消息联动、日程同步、办公审批联动等多项实用功能,极大提升…...

别只仿真了!手把手教你将Proteus里的AT89C52温控风扇代码烧录进实物单片机
从Proteus仿真到实物落地:AT89C52温控风扇全流程实战指南 当你成功在Proteus中完成了AT89C52温控风扇的仿真,看到虚拟环境中风扇随着温度变化自动启停时,那种成就感不言而喻。但仿真终究只是第一步,真正的挑战在于如何将这个系统…...
)
从开发到上线:UniApp小程序跳转全流程配置指南(含环境区分与版本管理)
UniApp跨小程序跳转工程化实践:多环境配置与版本管理全解析 在移动互联网生态中,小程序间的相互跳转已成为提升用户体验的关键链路。作为技术负责人,我曾亲历过因环境配置错误导致的线上事故——某次紧急更新中,由于跳转参数未区分…...

告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号
告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号 在汽车电子开发中,硬件在环(HIL)测试往往面临一个典型困境:当物理ECU或CAN卡尚未就绪时,如何提前开展总线信号验证?传…...

从‘果冻屏’到‘瀑布屏’:OCA全贴合工艺如何悄悄改变了你的视觉体验?
从‘果冻屏’到‘瀑布屏’:OCA全贴合工艺如何悄悄改变了你的视觉体验? 还记得十年前那些让人抓狂的“果冻屏”吗?阳光下泛着彩虹纹,触控时总感觉隔着一层毛玻璃,甚至能清晰看到屏幕边缘积攒的灰尘。如今拿起任何一款旗…...

智能车底盘DIY避坑指南:直流电机、减速器、编码器怎么选?TB6612FNG够用吗?
智能车底盘DIY避坑指南:直流电机、减速器、编码器怎么选?TB6612FNG够用吗? 当你第一次尝试组装智能车底盘时,站在琳琅满目的电机、减速器和驱动器面前,很容易陷入选择困难。本文将带你避开新手常踩的坑,从实…...

PIC16F驱动WS2812:8位MCU实现无限随机动态灯光算法
1. 项目概述与核心思路 几年前,我在捣鼓一个节日南瓜灯项目时,遇到了一个经典难题:手头只有一片资源极其有限的PIC16F1847微控制器,却想驱动一串WS2812(也就是大家常说的NeoPixel)LED,做出那种看…...

手把手教你写JS逆向通用模板:一键提取加密参数
在JS逆向实战中,你一定遇到过这种情况:同一个网站,换个接口就要重新扣代码、调环境、处理依赖;换个网站,又要从头再来一遍,重复劳动浪费大量时间。 其实90%的JS逆向场景,都可以用一套通用模板搞定。不管是MD5/SHA1签名、AES/RSA加密、还是混淆后的动态加密函数,这套模…...

SQL注入技术详解:从联合查询到盲注实战
前言: 继续开始我们的SQL注入吧!本文详细讲解SQL注入的各类技术,包括联合查询、报错注入、布尔盲注、时间盲注、UA注入、Referer注入等,涵盖漏洞判断、利用方法和实战步骤。内容基于MySQL 5.0以上环境,围绕information…...

生成式AI项目实战:从PyTorch到Hugging Face的完整开发指南
1. 项目概述:从GitHub仓库名到生成式AI项目的实战蓝图看到HeyNina101/generative_ai_project这个仓库名,很多开发者会心一笑。这太典型了——一个以个人ID命名的GitHub仓库,里面很可能是一个关于生成式人工智能(Generative AI&…...