CSwin Transformer 学习笔记
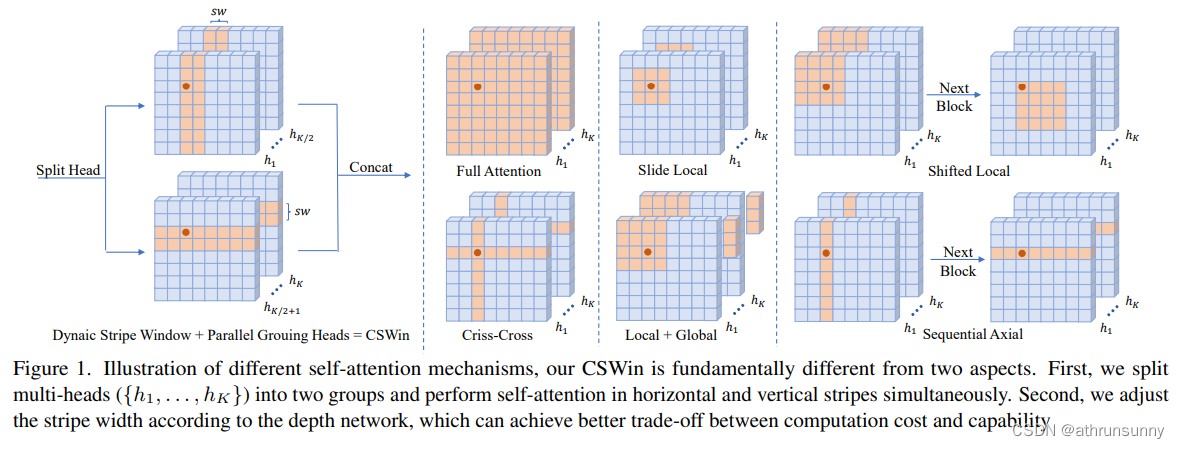
Cswin提出了上图中使用交叉形状局部attention,为了解决VIT模型中局部自注意力感受野进一步增长受限的问题,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA(当时的SOTA,已经被SG Former超越,感兴趣的可以看看SG Former)。
论文地址:https://arxiv.org/abs/2107.00652
代码地址:https://github.com/microsoft/CSWin-Transformer
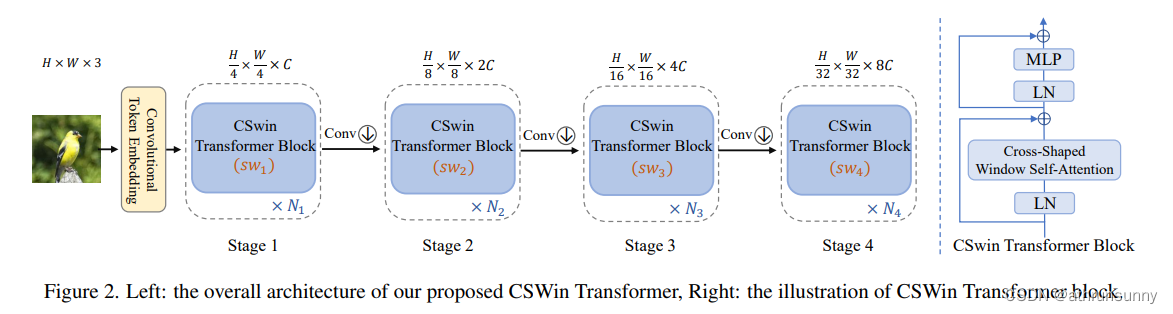
模型整体结构如上所示,由token embeeding layer和4个stageblock所堆叠而成,每个stage block后面都会接入一个conv层,用来对featuremap进行下采样。和典型的R50设计类似,每次下采样后,会增加dim的数量,一是为了提升感受野,二是为了增加特征性。
研究动机:
- 基于global attention的transformer效果虽然好但是计算复杂度与特征图大小平方(H==W的情况)成正比。
- 基于local attention的transformer的会限制每个token的感受野的交互,减缓感受野的增长,需要堆叠大量的block来实现全局自注意力。
解决办法:
- 提出了Cross-Shaped Window self-attention机制,对注意力头进行分组,并行计算水平和竖直方向的self-attention,可以在更小的计算量条件下获得更好的效果。
- 提出了Locally-enhanced Positional Encoding(LePE), 可以更好的处理局部位置信息,并且支持任意形状的输入。
1.1 Convolutional Token Embedding
用convolution来做embedding,为了减少计算量,本文直接采用了7x7的卷积核,stride为4的卷积来直接对输入进行embedding,之后再对最后一维进行layernorm。
self.stage1_conv_embed = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 7, 4, 2),Rearrange('b c h w -> b (h w) c', h=img_size // 4, w=img_size // 4),nn.LayerNorm(embed_dim)
)1.2 Cross-Shaped Window Self-Attention
具体来讲,假设原始的Feature Map为,为了计算它在横向上的自注意力,它首先被拆分成
个横条的数据(实际代码先进行竖列处理),其中
是横条的宽度。在这4个不同的Stage中取不同的值,实验结果表明[1,2,7,7]这组值在速度和精度上取得了比较好的均衡。
对于每个条状特征,使用Transformer可以得到它的特征
,最后将这
个特征拼接到一起便得到了这个head的输入。假设它属于第
个head,那么横向自注意力
的计算方式为:
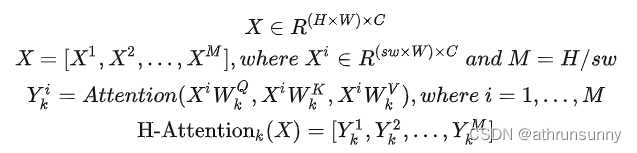
纵向自注意力V-Attention 和H-Attention的计算方式类似,不同的是它是取的宽度为的竖条。
最终,这个block的输出表示为:
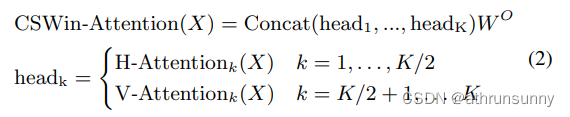
CSWin self-attention计算复杂度分析:

对于高分辨率输入,H,W早期大于C,后期小于C,因此早期sw小,后期大。即,调整sw可以有效地扩大后期每个token的attention区域。为了使224×224输入的中间特征图大小可被sw整除,默认将4个阶段的sw设置为1、2、7、7。
def img2windows(img, H_sp, W_sp):"""img: B C H W"""B, C, H, W = img.shapeimg_reshape = img.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp) # [N 32 1 56 56 1] [N 32 56 1 1 56] / [N 64 1 28 14 2] [N 64 14 2 1 28] / [N 128 1 14 2 7] [N 128 2 7 1 14] / [N 512 1 7 1 7]img_perm = img_reshape.permute(0, 2, 4, 3, 5, 1).contiguous().reshape(-1, H_sp* W_sp, C) # [N*56*1 56 32] [N*56*1 56 32] / [N*14*1 56 64] [N*14*1 56 64] / [N*2*1 98 128] [N*2*1 98 128] / [N*1*1 49 512]return img_permdef windows2img(img_splits_hw, H_sp, W_sp, H, W):"""img_splits_hw: B' H W C"""B = int(img_splits_hw.shape[0] / (H * W / H_sp / W_sp))img = img_splits_hw.view(B, H // H_sp, W // W_sp, H_sp, W_sp, -1) # [N*56*1 56 32]->[N 1 56 56 1 32] [N*56*1 56 32]->[N 56 1 1 56 32] / [N*14*1 56 64]->[N 1 14 28 2 64] [N*14*1 56 64]->[N 14 1 2 28 64] / [N*2*1 98 128]->[N 1 2 14 7 128] [N*2*1 98 128]->[N 2 1 7 14 128] / [N*1*1 49 512]->[N 1 1 7 7 512]img = img.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1) # [N 56 56 32] [N 28 28 64] [N 14 14 128] [N 7 7 512]return imgclass LePEAttention(nn.Module):def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0.,qk_scale=None):super().__init__()self.dim = dimself.dim_out = dim_out or dimself.resolution = resolutionself.split_size = split_sizeself.num_heads = num_headshead_dim = dim // num_heads# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weightsself.scale = qk_scale or head_dim ** -0.5if idx == -1:H_sp, W_sp = self.resolution, self.resolutionelif idx == 0:H_sp, W_sp = self.resolution, self.split_sizeelif idx == 1:W_sp, H_sp = self.resolution, self.split_sizeelse:print("ERROR MODE", idx)exit(0)self.H_sp = H_spself.W_sp = W_spstride = 1self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, groups=dim)self.attn_drop = nn.Dropout(attn_drop)def im2cswin(self, x):B, N, C = x.shapeH = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W) # [B, N, C] -> [B, C, N] -> [B, C, H, W]x = img2windows(x, self.H_sp, self.W_sp) # [N*56*1 56 32] [N*14*1 56 64] [N*2*1 98 128] [N*1*1 49 512]x = x.reshape(-1, self.H_sp * self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1,3).contiguous() # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]return xdef get_lepe(self, x, func):B, N, C = x.shape # [N 3136 32] [N 784 64] [N 196 128] [N 49 512]H = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W) # [N 32 56 56] [N 64 28 28] [N 128 14 14] [N 512 7 7]H_sp, W_sp = self.H_sp, self.W_spx = x.view(B, C, H // H_sp, H_sp, W // W_sp,W_sp) # [N 32 1 56 56 1] [N 32 56 1 1 56] / [N 64 1 28 14 2] [N 64 14 2 1 28] / [N 128 1 14 2 7] [N 128 2 7 1 14] / [N 512 1 7 1 7]x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp,W_sp) ### B', C, H', W' # [N*56*1 32 56 1][N*56*1 32 1 56] / [N*14*1 64 28 2][N*14*1 64 2 28] / [N*2*1 128 14 7][N*2*1 128 7 14] / [N*1*1 512 7 7]lepe = func(x) ### B', C, H', W' # [N*56*1 32 56 1] [N*56*1 32 1 56] / [N*14*1 64 28 2][N*14*1 64 2 28] / [N*2*1 128 14 7][N*2*1 128 7 14] / [N*1*1 512 7 7]lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3,2).contiguous() # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp * self.W_sp).permute(0, 1, 3,2).contiguous() # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]return x, lepedef forward(self, qkv):"""x: B L C"""q, k, v = qkv[0], qkv[1], qkv[2] # [N 3136 32] [N 784 64] [N 196 128] [N 49 512]### Img2WindowH = W = self.resolution # 56 28 14 7B, L, C = q.shape # [N 3136 32] [N 784 64] [N 196 128] [N 49 512]assert L == H * W, "flatten img_tokens has wrong size"q = self.im2cswin(q) # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]k = self.im2cswin(k) # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]v, lepe = self.get_lepe(v, self.get_v)q = q * self.scaleattn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N Nattn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)attn = self.attn_drop(attn)x = (attn @ v) + lepex = x.transpose(1, 2).reshape(-1, self.H_sp * self.W_sp,C) # B head N N @ B head N C # [N*56*1 56 32] [N*14*1 56 64] [N*2*1 98 128] [N*1*1 49 512]### Window2Imgx = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C) # B H' W' Creturn x # [N 3136 32] [N 784 64] [N 196 128] [N 49 512]代码部分其实和Swin类似,如果理解了swin的分窗机制,再加上head分组,基本上就能很快理解论文中思想。
1.3 Locally-Enhanced Positional Encoding(LePE)

因为Transformer是输入顺序无关的,因此需要向其中加入位置编码。上图左边为ViT模型的PE,使用的绝对位置编码或者是条件位置编码,只在embedding的时候与token一起进入transformer,中间的是Swin,CrossFormer等模型的PE,使用相对位置编码偏差,通过引入token图的权重来和attention一起计算,灵活度更好,相对APE效果更好。
本文所提出的LePE,相比于RPE更加直接,将位置信息施加到线性投影中,同时注意到RPE以head方式引入偏差,而LepE是per-channel bias,这可能显示出更强大的潜力来充当位置嵌入。也就是直接将位置编码添加加到了Value向量上,假设位置编码为,它的添加方式是通过将位置编码
和
相乘完成的。然后通过一个short-cut将添加了位置编码的
和通过自注意力加权的
单位加到一起,公式如下:

这里作者基于一个假设:对于一个输入元素,他附近的元素提供最重要的位置信息。所以对V做一个深度卷积,加到softmax之后的结果上。公式为:
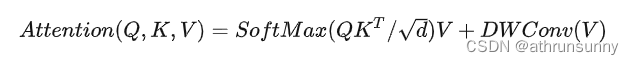
这样,LePE可以友好地应用于将任意输入分辨率作为输入的下游任务。
def get_lepe(self, x, func):# func -> self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1,groups=dim)B, N, C = x.shape # [N 3136 32] [N 784 64] [N 196 128] [N 49 512]H = W = int(np.sqrt(N))x = x.transpose(-2, -1).contiguous().view(B, C, H, W) # [N 32 56 56] [N 64 28 28] [N 128 14 14] [N 512 7 7]H_sp, W_sp = self.H_sp, self.W_spx = x.view(B, C, H // H_sp, H_sp, W // W_sp,W_sp) # [N 32 1 56 56 1] [N 32 56 1 1 56] / [N 64 1 28 14 2] [N 64 14 2 1 28] / [N 128 1 14 2 7] [N 128 2 7 1 14] / [N 512 1 7 1 7]x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp,W_sp) ### B', C, H', W' # [N*56*1 32 56 1][N*56*1 32 1 56] / [N*14*1 64 28 2][N*14*1 64 2 28] / [N*2*1 128 14 7][N*2*1 128 7 14] / [N*1*1 512 7 7]lepe = func(x) ### B', C, H', W' # [N*56*1 32 56 1] [N*56*1 32 1 56] / [N*14*1 64 28 2][N*14*1 64 2 28] / [N*2*1 128 14 7][N*2*1 128 7 14] / [N*1*1 512 7 7]lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3,2).contiguous() # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp * self.W_sp).permute(0, 1, 3,2).contiguous() # [N*56*1 1 56 32] [N*14*1 2 56 32] [N*2*1 4 98 32] [N*1*1 16 49 32]return x, lepe1.4 CSWin Transformer Block
CSWin Transformer Block的结构如图所示,它最显著的特点是添加了两个shortcut,并使用LN对特征做归一化.
网络结构配置:
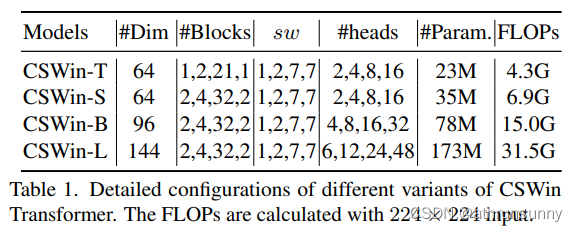

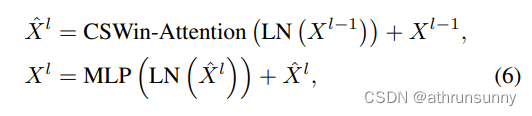
其中为第
个Transformer block的输出或各stage的卷积层。
CSwin的block有两个部分,一个是做LayerNorm和Cross-shaped window self-attention并接一个shortcut,另一个则是做LayerNorm和MLP,相比于Swin和Twins来说,block的计算量大大的降低了(swin,twins则是有两个attention+两个MLP堆叠一个block)。
class CSWinBlock(nn.Module):def __init__(self, dim, reso, num_heads,split_size=7, mlp_ratio=4., qkv_bias=False, qk_scale=None,drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm,last_stage=False):super().__init__()self.dim = dimself.num_heads = num_headsself.patches_resolution = resoself.split_size = split_sizeself.mlp_ratio = mlp_ratioself.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.norm1 = norm_layer(dim)if self.patches_resolution == split_size:last_stage = Trueif last_stage:self.branch_num = 1else:self.branch_num = 2self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(drop)if last_stage:self.attns = nn.ModuleList([LePEAttention(dim, resolution=self.patches_resolution, idx = -1,split_size=split_size, num_heads=num_heads, dim_out=dim,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)for i in range(self.branch_num)])else:self.attns = nn.ModuleList([LePEAttention(dim//2, resolution=self.patches_resolution, idx = i,split_size=split_size, num_heads=num_heads//2, dim_out=dim//2,qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)for i in range(self.branch_num)])mlp_hidden_dim = int(dim * mlp_ratio)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer, drop=drop)self.norm2 = norm_layer(dim)def forward(self, x):"""x: B, H*W, C"""H = W = self.patches_resolution # 56B, L, C = x.shape # [N 3136 64] [N 784 128] [N 196 256] [N 49 512]assert L == H * W, "flatten img_tokens has wrong size"img = self.norm1(x)qkv = self.qkv(img).reshape(B, -1, 3, C).permute(2, 0, 1, 3) # [3 N 3136 64] [3 N 784 128] [3 N 196 256] [3 N 49 512]if self.branch_num == 2:x1 = self.attns[0](qkv[:,:,:,:C//2]) # qkv[3 N 3136 32]->x1[N 3136 32] qkv[3 N 784 128]->x1[N 784 64] qkv[3 N 196 256]->x1[N 196 128]x2 = self.attns[1](qkv[:,:,:,C//2:]) # qkv[3 N 3136 32]->x2[N 3136 32] qkv[3 N 784 128]->x1[N 784 64] qkv[3 N 196 256]->x1[N 196 128]attened_x = torch.cat([x1,x2], dim=2)else:attened_x = self.attns[0](qkv) # [3 N 49 512]->[N 49 512]attened_x = self.proj(attened_x)x = x + self.drop_path(attened_x)x = x + self.drop_path(self.mlp(self.norm2(x)))return x # [N 3136 64] [N 784 128] [N 196 256] [N 49 512]在相似网络参数和计算量的模型中,cswin在分类任务和各类下游任务中都做到了SOTA
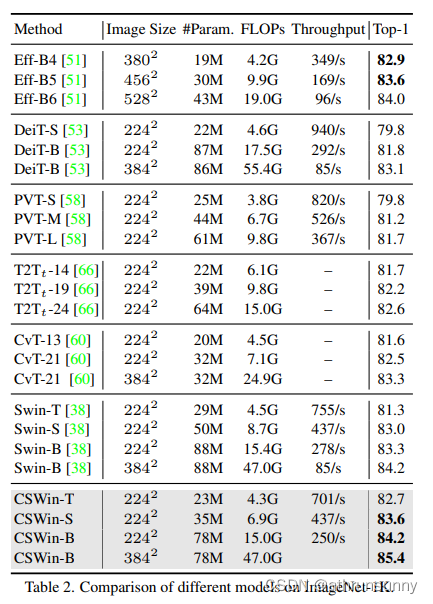
检测:
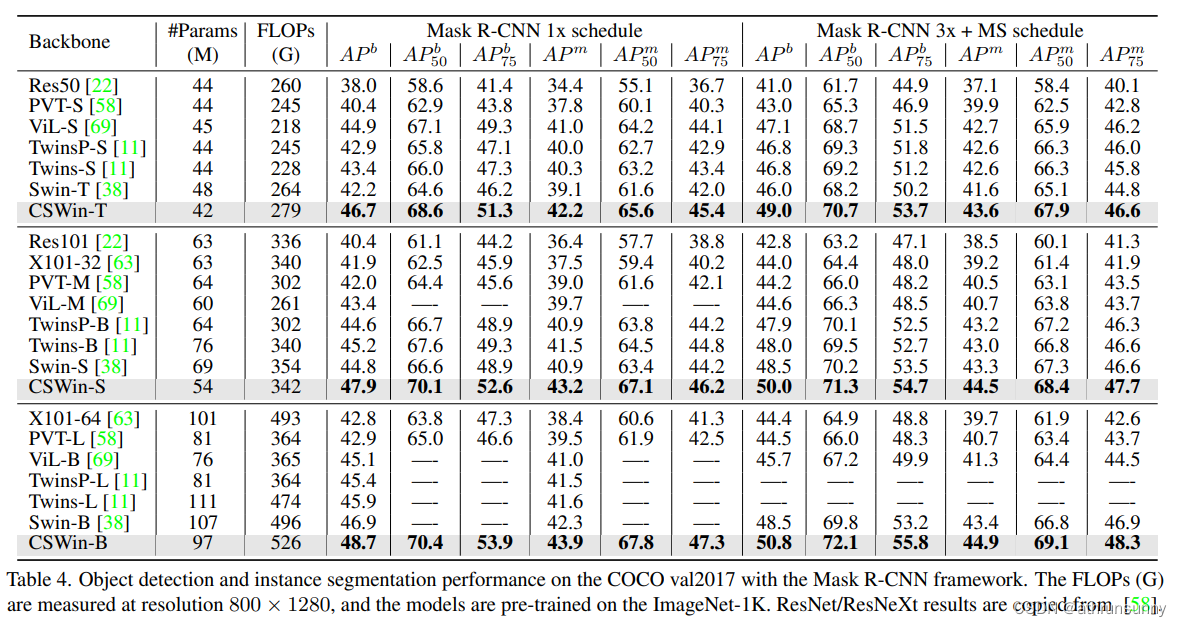
分割:
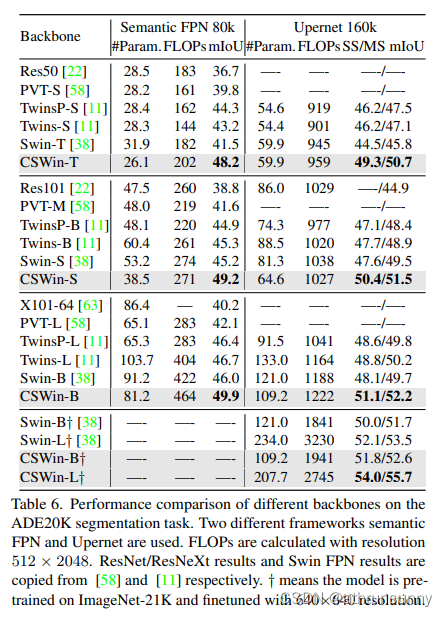
相关文章:
CSwin Transformer 学习笔记
Cswin提出了上图中使用交叉形状局部attention,为了解决VIT模型中局部自注意力感受野进一步增长受限的问题,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA(当时的SOTA,已经被SG Fo…...
Linux上通过mysqldump命令实现自动备份
Linux上通过mysqldump命令实现自动备份 直接上代码 #!/bin/bash mysql_user"root" mysql_host"localhost" mysql_port"3306" mysql_charset"utf8mb4"backup_location/home/mysql/mysql_back/sql # 是否开始自动删除过期文件,过期时间…...

v-model与.sync的区别
我们在日常开发的过程中,v-model指令可谓是随处可见,一般来说 v-model 指令在表单及元素上创建双向数据绑定,但 v-model 本质是语法糖。但提到语法糖,这里就不得不提另一个与v-model有相似功能的双向绑定语法糖了,这就是 .sync修饰符。在这里就两者的使用进行一下比较和总结: …...

Linux---进程(1)
操作系统 传统的计算机系统资源分为硬件资源和软件资源。硬件资源包括中央处理器,存储器,输入设备,输出设备等物理设备;软件资源是以文件形式保存在存储器上的成熟和数据等信息。 操作系统就是计算机系统资源的管理者。 如果你的计…...
C# U2Net Portrait 跨界肖像画
效果 项目 下载 可执行文件exe下载 源码下载...
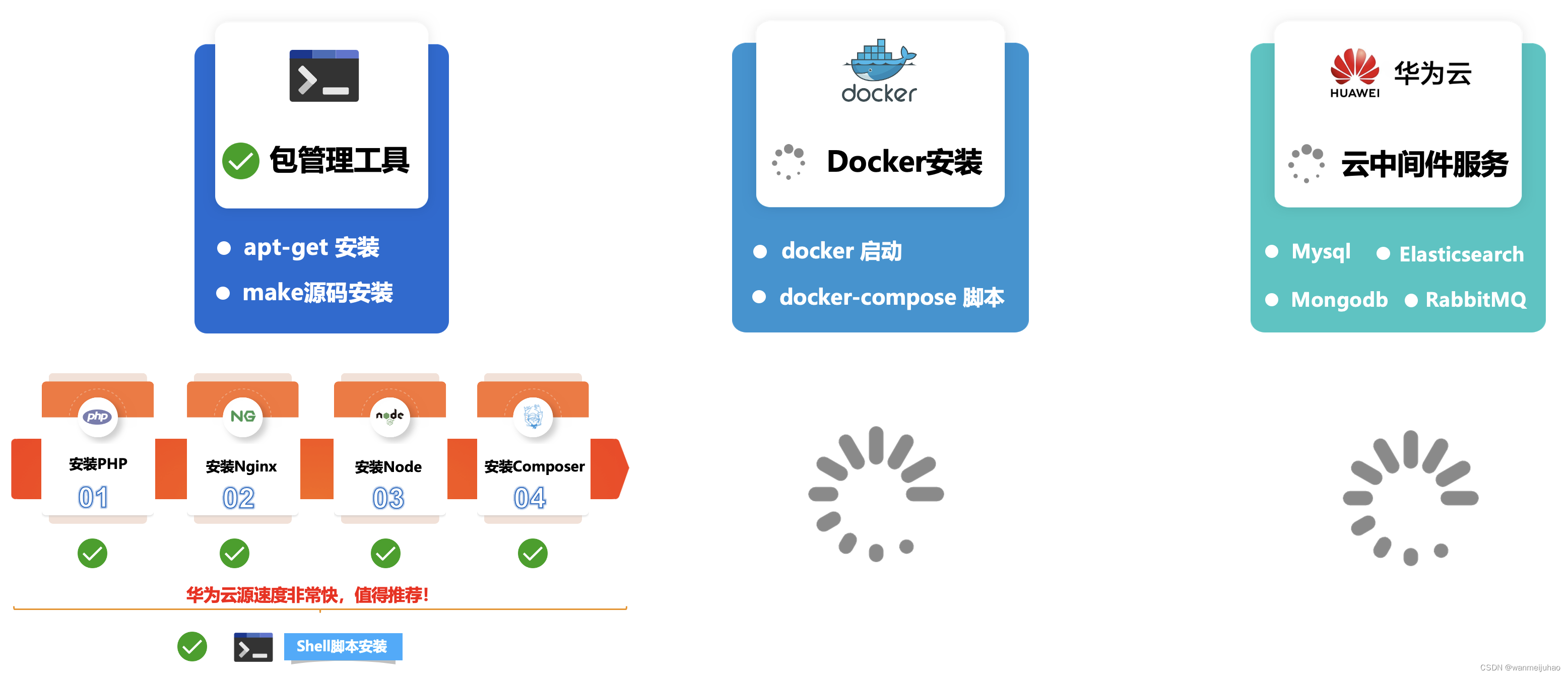
华为云云耀云服务器L实例评测|华为云耀云服务器L实例评测包管理工具安装软件(六)
七、华为云耀云服务器L实例评测包管理工具安装软件: 根据企业级项目架构图所示,本章主要是安装公司企业项目的基本环境LNMP,相关的包管理器Composer、Node、Npm、Yarn安装,评测一下包管理工具安装软件是否存在问题,如果…...

在PYTHON中用zlib模块对文本进行压缩,写入图片的EXIF中,后在C#中读取EXIF并用SharpZipLib进行解压获取压缩前文本
在PYTHON中用zlib模块对文本进行压缩长度,写入图片的EXIF中,并在C#中读取EXIF后用SharpZipLib进行解压缩获取压缩前文本。 PS:当压缩后的字节数组长度为单数时,无法写入EXIF的XPComment中,需要在后面增加一个以utf-8编码的空格&a…...
centos / oracle Linux 常用运维命令讲解
目录 1.shell linux常用目录: 2.命令格式 3.man 帮助 4.提示符 5.echo输出字符串或变量值 6.date显示及设置系统的时间或日期 7.重启系统 8.关闭系统 9.登录注销 10.wget 下载文件 11.ps 查看系统的进程 12.top动态监视进程信息和系统负载等信息 13.l…...
EMNLP 2023 录用论文公布,速看NLP各领域最新SOTA方案
EMNLP 2023 近日公布了录用论文。 开始前以防有同学不了解这个会议,先简单介绍介绍:EMNLP 是NLP 四大顶会之一,ACL大家应该都很熟吧,EMNLP就是由 ACL 下属的SIGDAT小组主办的NLP领域顶级国际会议,一年举办一次。相较于…...

互联网Java工程师面试题·Java 并发编程篇·第三弹
目录 26、什么是线程组,为什么在 Java 中不推荐使用? 27、为什么使用 Executor 框架比使用应用创建和管理线程好? 27.1 为什么要使用 Executor 线程池框架 27.2 使用 Executor 线程池框架的优点 28、java 中有几种方法可以实现一个线程…...

mac jdk的环境变量路径,到底在哪里?
在mac 电脑中,直接执行 java -version 显示Jdk的版本为1.8 然后打印Java环境变量 在终端中执行 echo $JAVA_HOME 1、情况一:发现环境变量是空的 我草,没配置环境变量怎么能使用Java ,和查看jdk版本 2、情况二:环…...
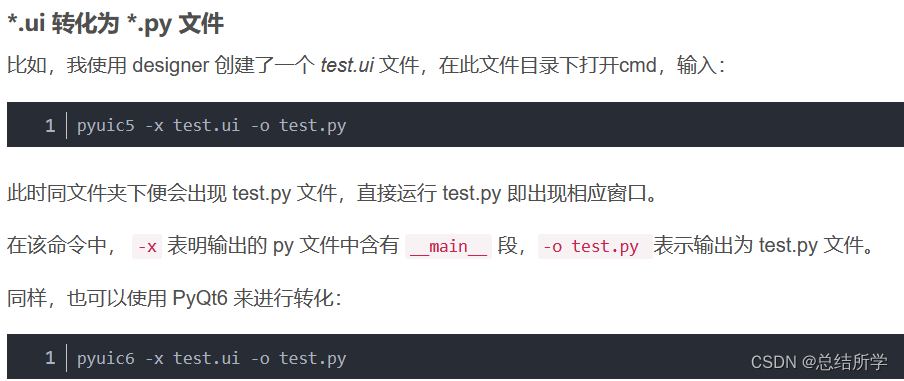
PyQt5 PyQt6 Designer 的安装
pip国内的一些镜像 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣(douban) http://pypi.douban.com/simple/ 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.…...
)
数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有…...
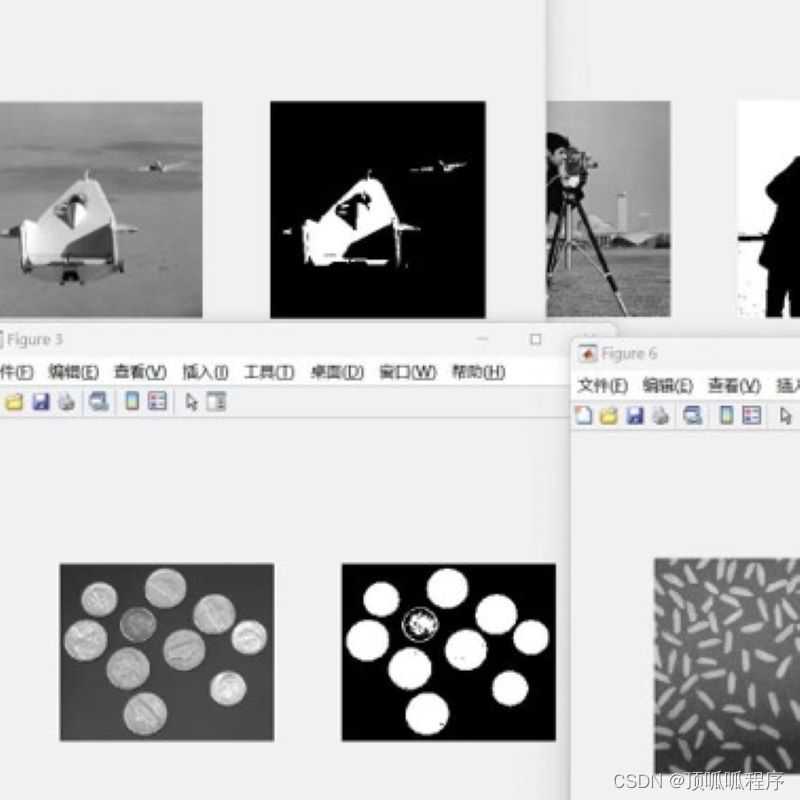
16基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。
基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。 16matlab图像处理图像分割 (xiaohongshu.com)...

2、使用阿里云镜像加速器提升Docker的资源下载速度
1、注册阿里云账号并登录 https://www.aliyun.com/ 2、进入个人控制台,找到“容器镜像服务” 3、在“容器镜像服务”中找到“镜像加速器” 4、在右侧列表中会显示你的加速器地址,复制地址 5、进入/etc/docker目录,编辑daemon.json࿰…...
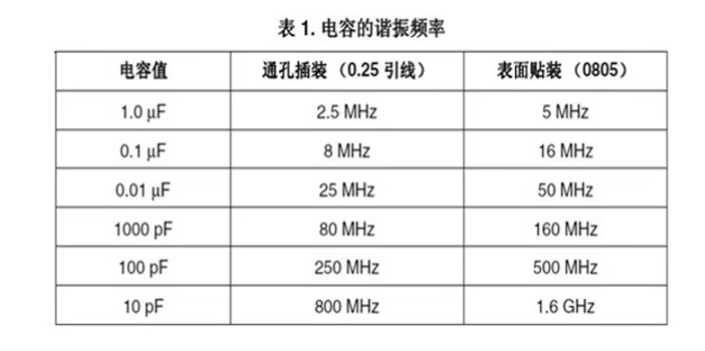
贴片电容材质的区别与电容的主要作用
一、贴片电容材质NPO、COG、X7R、X5R、Y5V、Z5U区别 主要是介质材料不同,不同介质种类由于它的主要极化类型不一样,其对电场变化的响应速度和极化率也不一样。在相同的体积下的容量就不同,随之带来的电容器介质的损耗、容量的稳定性也就不同…...
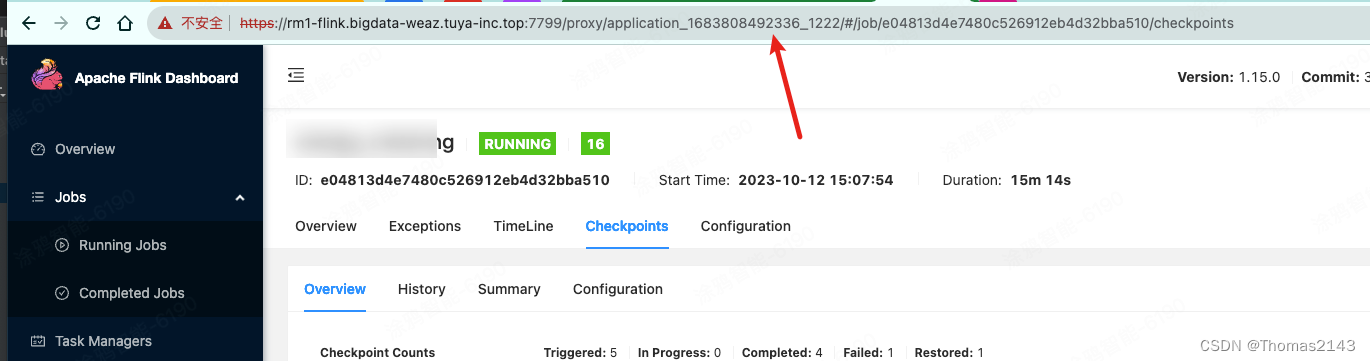
flink1.15 savepoint 超时报错 java.util.concurrent.TimeoutException
savepoint命令 flink savepoint e04813d4e7480c526912eb4d32bba510 hdfs://flink/flink/migration/savepoint56650 -Dyarn.application.id=application_1683808492336_1222报错内容 org.apache.flink.util.FlinkException: Triggering a savepoint for the job e04813d4e7480…...

并发编程——1.java内存图及相关内容
这篇文章,我们来讲一下java的内存图及并发编程的预备内容。 首先,我们来看一下下面的这两段代码: 下面,我们给出上面这两段代码在运行时的内存结构图,如下图所示: 下面,我们来具体的讲解一下。…...
Android studio安装详细教程
Android studio安装详细教程 文章目录 Android studio安装详细教程一、下载Android studio二、安装Android Studio三、启动Android Studio 一、下载Android studio Android studio安装的前提是必须保证安装了jdk1.8版本以上 1、打开android studio的官网:Download…...

Jetson Orin NX 开发指南(7): EGO-Swarm 的编译与运行
一、前言 EGO-Planner 浙江大学 FAST-LAB 实验室的开源轨迹规划算法是,受到 IEEE Spectrum 等知名科技媒体的报道,其理论技术较为前沿,是一种不依赖于ESDF,基于B样条的规划算法,并且规划成功率、算法消耗时间、代价数…...

第7周学习总结:多工具Agent、RAG基础与环境搭建
多工具Agent、RAG基础与环境搭建 本周的学习重点围绕两个方向展开:一是完成了第七周的多工具协同与规划任务,并进入了第八周的流式思考链优化;二是正式启动了RAG(检索增强生成)的系统学习,搭建了知识库和环…...

通过用量看板与账单追溯实现团队 AI 成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与账单追溯实现团队 AI 成本精细化管理 对于技术团队而言,将大模型能力集成到产品与研发流程中已成为常态…...

开源阅读鸿蒙版:打造您的个性化无广告数字图书馆
开源阅读鸿蒙版:打造您的个性化无广告数字图书馆 【免费下载链接】legado-Harmony 开源阅读鸿蒙版仓库 项目地址: https://gitcode.com/gh_mirrors/le/legado-Harmony legado-Harmony是一款专为鸿蒙系统设计的开源电子书阅读器,它为您提供纯净的阅…...

phpenv故障排除终极指南:解决PHP版本管理中的10大常见问题
phpenv故障排除终极指南:解决PHP版本管理中的10大常见问题 【免费下载链接】phpenv Simple PHP version management 项目地址: https://gitcode.com/gh_mirrors/ph/phpenv phpenv是一款简单而强大的PHP版本管理工具,专为PHP开发者设计,…...

【亲测免费】 基于深度学习的计算机视觉PPT
基于深度学习的计算机视觉PPT 【下载地址】基于深度学习的计算机视觉PPT 本仓库提供了一份名为“基于深度学习的计算机视觉PPT”的资源文件,该文件详细介绍了计算机视觉的基本概念、理论基础以及深度学习在计算机视觉中的应用。计算机视觉是一门研究如何使机器“看”…...

零基础玩转Linux:CentOS安装、Xshell连接与文件权限全攻略
零基础玩转Linux:CentOS安装、Xshell连接与文件权限全攻略 目录 1、Linux系统简介 2、安装Linux 3、Linux相关配制 3.1 配制静态IP 3.2 安装Linux终端 3.3 安装ftp 3.4、Linux目录结构 4、Linux基本命令 4.1、关机与重启 4.2、文件与目录 4.3、日期与日历 4.4、帮助指令 4.5、…...

vibe coding效率高:一个新mcp server已经试运行尚可
下面是文档: judicial-doc-quality-mcp v0.1.0 司法裁判文书质量评估 MCP 服务器 — 桥接架构,零 LLM 调用 English | 中文 概述 judicial-doc-quality-mcp 是一个基于 Model Context Protocol (MCP) 的裁判文书质量评估服务器,采用**桥接…...
)
TVA智能体范式的工业视觉革命(8)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

为什么越来越多人放弃了传统日记本?因为他们发现了雷小兔写期刊
在这个信息爆炸的时代,我们每个人的心中都装满了故事、想法和情感。但往往,这些珍贵的内容在日常的忙碌中逐渐褪色,最终消散在时间的长河里。你是否也曾有过这样的遗憾——明明想记录下某个瞬间,却苦于没有合适的方式去表达&#…...

终极ncmdump使用指南:3步解锁网易云NCM加密音乐,实现跨平台自由播放
终极ncmdump使用指南:3步解锁网易云NCM加密音乐,实现跨平台自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐下载的NCM格式文件无法在其他设备播放而烦恼?ncmdump作为…...