kafka简述
前言
在大数据高并发场景下,当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消息队列,作为抽象层,弥合双方的差异。一般选型是Kafka、RocketMQ,这源于这些中间件的高吞吐、可扩展以及可靠性。
另外企业中离线业务场景实时业务场景都需要使用到kafka,Kafka具备数据的计算能力和存储能力,但是两个能力相对(MR/SPARK,HDFS)较弱,Kafka角色的角色与hbase比较像,层级关系比较多。
消息队列
是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保信息的可靠专递,消息发布者只管把消息发布到MQ中而不管谁来取,消息使用者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
消息队列的应用场景
消息队列在实际应用中包括如下四个场景:
应用耦合:多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败;
异步处理:多应用对消息队列中同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间;
限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉的情况;
消息驱动的系统:系统分为消息队列、消息生产者、消息消费者,生产者负责产生消息,消费者(可能有多个)负责对消息进行处理;
消息队列的两种模式
1)点对点模式
点对点模式下包括三个角色: 消息发送者 (生产者)、 接收者(消费者)
消息发送者生产消息发送到queue中,然后消息接收者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息接收者不可能消费到已经被消费的消息。
特点:
每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);
• 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;
• 接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
2)发布/订阅模式
发布/订阅模式下包括三个角色: 角色主题(Topic)、 发布者(Publisher)、订阅者(Subscriber)
发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
特点:
• 每个消息可以有多个订阅者;
• 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
• 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行;
介绍
**kafka是一个分布式,分区的,多副本的,多订阅者的消息发布订阅系统(分布式MQ系统)。基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎,web/nginx日志、搜索日志、监控日志、访问日志,消息服务等等。**用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
kafka适合离线和在线消息消费。kafka构建在zookeeper同步服务之上。它与apache和spark非常好的集成,应用于实时流式数据分析。
好处
1、可靠性:分布式的,分区,复制和容错。
2、可扩展性:kafka消息传递系统轻松缩放,无需停机。
3、耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快速的保存在磁盘上,因此它是持久的。
4、性能:kafka对于发布和定于消息都具有高吞吐量。即使存储了许多TB的消息,他也爆出稳定的性能。 kafka非常快:保证零停机和零数据丢失。
使用场景
**1)日志收集:**一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
**2)消息系统:**解耦和生产者和消费者、缓存消息等。
**3)用户活动跟踪:**Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
**4)运营指标:**Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
**5)流式框架:**从主题中读取数据,对其进行处理,并将处理后的数据写入新的主题,供用户和应用程序使用,kafka的强耐久性在流处理的上下文中也非常的有用。
基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。
从宏观层面上看,Producer通过网络发送消息到Kafka集群,然后Consumer来进行消费。服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
基本使用(原生API)
1、创建主题
【1】创建一个名字为“test”的Topic,这个topic只有一个partition,并且备份因子也设置为1:
bin/kafka-topics.sh --create --zookeeper 192.168.65.60:2181 --replication-factor 1 --partitions 1 --topic test
【2】通过以下命令来查看kafka中目前存在的topic
bin/kafka-topics.sh --list --zookeeper 192.168.65.60:2181
【3】除了通过手工的方式创建Topic,当producer发布一个消息到某个指定的Topic,如果Topic不存在,就自动创建。所以如果发送错了Topic,那么就需要创建对应的消费者来消费掉发送错误的消息。
【4】删除主题
bin/kafka-topics.sh --delete --topic test --zookeeper 192.168.65.60:2181
2、发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。
示例:运行发布消息的脚本,然后在命令中输入要发送的消息的内容:
//指定往哪个broker(也就是服务器)上发消息
bin/kafka-console-producer.sh --broker-list 192.168.65.60:9092 --topic test
>this is a msg
>this is a another msg
3、消费消息
【1】对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输出,默认是消费最新的消息:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --topic test
【2】想要消费之前的消息可以通过–from-beginning参数指定,如下命令:
//这里便凸显了与传统消息中间件的不同,消费完,消息依旧保留(默认保留在磁盘一周)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --from-beginning --topic test
【3】通过不同的终端窗口来运行以上的命令,你将会看到在producer终端输入的内容,很快就会在consumer的终端窗口上显示出来。
【4】所有的命令都有一些附加的选项;当我们不携带任何参数运行命令的时候,将会显示出这个命令的详细用法
执行bin/kafka-console-consumer.sh 命令显示所有的可选参数
4、消费消息类型分析
1)单播消费
单播消费是一条消息只能被一个消费组内的某一个消费者消费。
2)多播消费
多播消费是一条消息可以被不同组内的某一个消费者消费。
设计原理分析
Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
1)当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
2)当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
3)当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
Controller选举机制
【1】在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点,zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller。
【2】当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点。
【3】具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
**1)监听broker相关的变化。**为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
**2)监听topic相关的变化。**为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
**3)从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。**对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
4)更新集群的元数据信息,同步到其他普通的broker节点中。
Partition副本选举Leader机制
controller感知到分区leader所在的broker挂了(controller监听了很多zk节点可以感知到broker存活),controller会从ISR列表(参数unclean.leader.election.enable=false的前提下)里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本)【这种会阻塞直到ISR列表有数据】,
如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。【其实就是知道/broker/ids/下面的数据没了】
副本进入ISR列表有两个条件:
1)副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
2)副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由 replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
消费者消费消息的offset记录机制
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据。【相当于记录了这个消费组在这个topic的某分区上消费到了哪】
由于consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
选出consumer消费的offset要提交到consumer_offsets的哪个分区公式:hash(consumerGroupId) % consumer_offsets主题的分区数
消费者Rebalance机制(再平衡机制)
**rebalance就是指如果消费组里的消费者数量有变化或消费的分区数有变化,kafka会重新分配消费者消费分区的关系。**比如consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他。
注意:
1)rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定了分区,kafka不会进行rebanlance。
**2)rebalance过程中,消费者无法从kafka消费消息。**这对kafka的TPS会有影响,如果kafka集群内节点较多,比如数百个,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的重平衡发生。
如下情况可能会触发消费者rebalance
1.消费组里的consumer增加或减少了
2.动态给topic增加了分区
3.消费组订阅了更多的topic
消费者Rebalance分区分配策略:
rebalance的策略:range、round-robin、sticky。
Kafka 提供了消费者客户端参数partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况为range分配策略。
假设一个主题有10个分区(0-9),现在有三个consumer消费:
1)range策略就是按照分区序号排序,比如分区03给一个consumer,分区46给一个consumer,分区7~9给一个consumer。
假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。
2)round-robin策略就是轮询分配,比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、8给一个consumer。
3)sticky策略初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则。1)分区的分配要尽可能均匀 。2)分区的分配尽可能与上次分配的保持相同。
Rebalance过程
当有消费者加入消费组时,消费者、消费组及组协调器之间会经历以下几个阶段。
1)选择组协调器
consumer group中的每个consumer启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
组协调器GroupCoordinator:每个consumer group都会选择一个broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者rebalance。
2)加入消费组JOIN GROUP
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。
GroupCoordinator 从一个consumer group中选择第一个加入group的consumer作为leader(消费组协调器),把consumer group情况发送给这个leader,接着这个leader会负责制定分区方案。
3)( SYNC GROUP)
consumer leader通过给GroupCoordinator发送SyncGroupRequest,接着GroupCoordinator就把分区方案下发给各个consumer【心跳的时候】,他们会根据指定分区的leader broker进行网络连接以及消息消费。
producer发布消息机制剖析
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。存储分区会根据分区算法选择将其存储到哪一个 partition。
路由机制为:
1)指定了 patition,则直接使用;
2)未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition
3)patition 和 key 都未指定,使用轮询选出一个 patition。
写入流程
1)producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
2)producer 将消息发送给该 leader
3)leader 将消息写入本地 log
4)followers 从 leader pull 消息,写入本地 log 后 向leader 发送 ACK
5)leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
集群消费
partitions分布在kafka集群中不同的broker上,kafka集群支持配置partition备份的数量。针对每个partition,都有一个broker起到“leader”的作用,其他的broker作为“follwers”的作用。
leader来负责处理所有关于这个partition的读写请求,而followers被动复制leader的结果,不提供读写(主要是为了保证多副本数据与消费的一致性)。如果这个leader失效了,其中的一个follower通过选举成为新的leader。
Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡,也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
Consumers
传统的消息传递模式有2种:队列( queue) 和(publish-subscribe)。Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者( logical subscriber )。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。
其他
消息回溯消费的机制是怎么实现的?
因为kafka的消息存储在log文件里面,而且对应的还会有index与timeindex(可以加快对于消息的检索),根据设置给予的offset可以快速定位到是哪个log文件,因为文件名就是offset偏移值。快速拿出数据就可以进行消费了。此外根据时间回溯也是一样不过量会更大一点。
如果新的消费组订阅已存在的topic,那么是重新开始消费么?
**默认是将当前topoc的最后offset传给消费组,作为其已消费的记录。**所以若是需要从头消费,则要设置为props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, “earliest”)。这个消费组如果是已经存在的,那么这个参数其实不会变动已有的offset。默认处理大数据量的应该采用latest,业务场景则用earliest。
日志分段存储
**Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,每个段的消息都存储在不一样的log文件里。**这种特性方便old segment file快速被删除,kafka规定了一个段位的 log 文件最大为 1G,做这个限制目的是为了方便把 log 文件加载到内存去操作。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
总结
后续再次补充…
相关文章:

kafka简述
前言 在大数据高并发场景下,当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消息队列,作为抽象层,弥合双方的差异。一般选型是Kafka、RocketMQ,这源于这些中间件的高吞吐、可扩展以及可靠…...
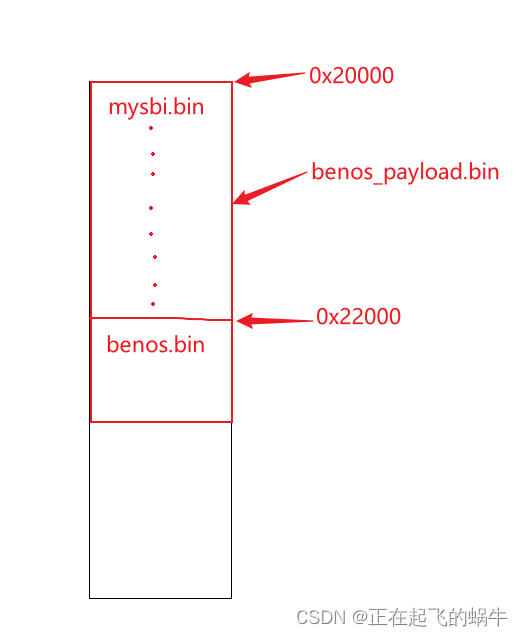
《RISC-V体系结构编程与实践》的benos_payload程序——mysbi跳转到benos分析
1、benos_payload.bin结构分析 韦东山老师提供的开发文档里已经对程序的结构做了分析,这里不再赘述,下面是讨论mysbi跳转到benos的问题; 2、mysbi跳转到benos的代码 3、跳转产生的疑问 我认为mysbi.bin最后跳转到0x22000地址处执行࿰…...
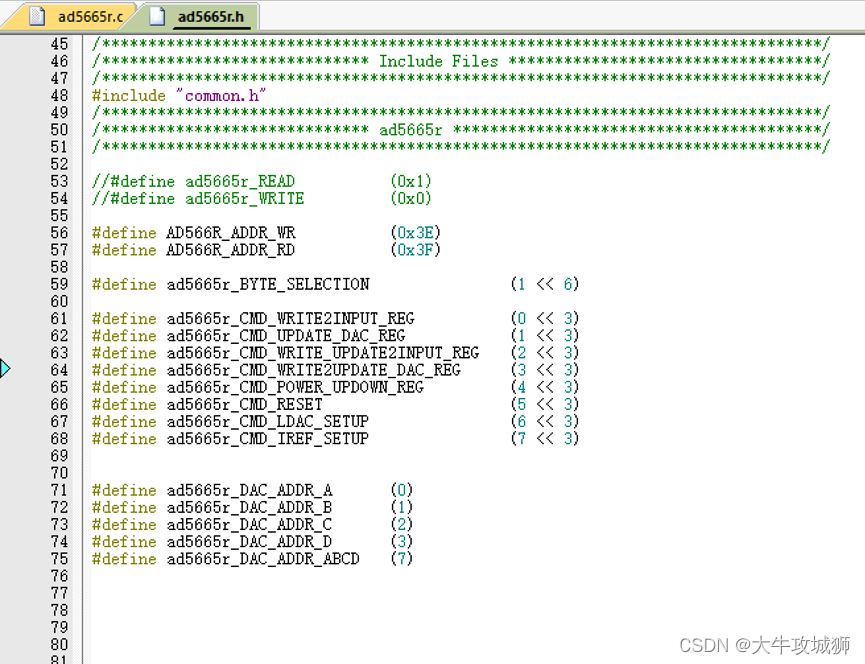
ad5665r STM32 GD32 IIC驱动设计
本文涉及文档工程代码,下载地址如下 ad5665rSTM32GD32IIC驱动设计,驱动程序在AD公司提供例程上修改得到,IO模拟的方式进行IIC通信资源-CSDN文库 硬件设计 MCU采用STM32或者GD32,GD32基本上和STM32一样,针对ad566r的IIC时序操作是完全相同的. 原理图设计如下 与MC…...
TensorFlow入门(十六、识别模糊手写图片)
TensorFlow在图像识别方面,提供了多个开源的训练数据集,比如CIFAR-10数据集、FASHION MNIST数据集、MNIST数据集。 CIFAR-10数据集有10个种类,由6万个32x32像素的彩色图像组成,每个类有6千个图像。6万个图像包含5万个训练图像和1万个测试图像。 FASHION MNIST数据集由衣服、鞋子…...
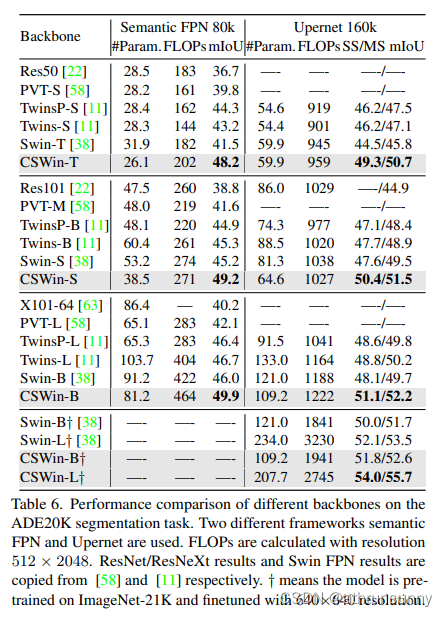
CSwin Transformer 学习笔记
Cswin提出了上图中使用交叉形状局部attention,为了解决VIT模型中局部自注意力感受野进一步增长受限的问题,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA(当时的SOTA,已经被SG Fo…...
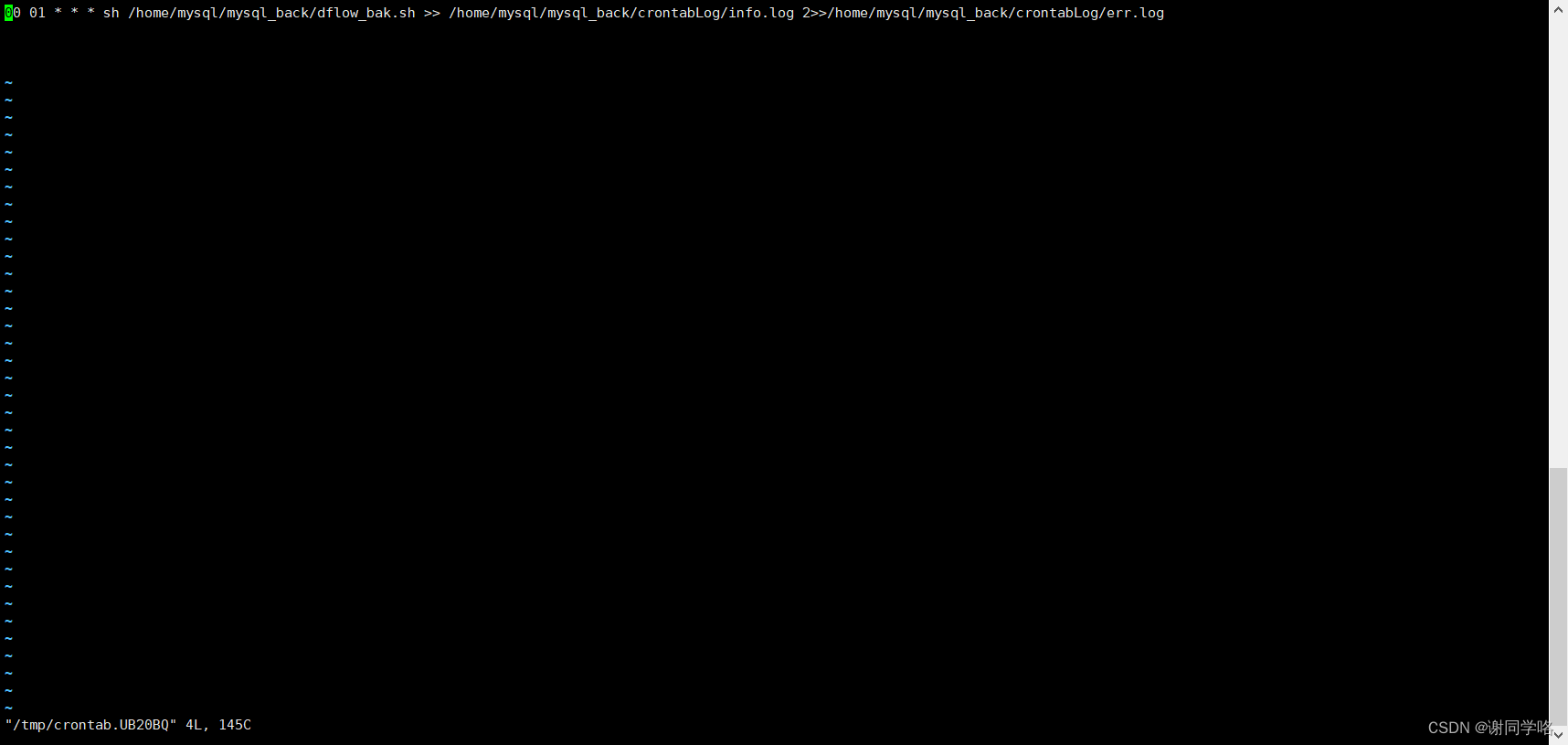
Linux上通过mysqldump命令实现自动备份
Linux上通过mysqldump命令实现自动备份 直接上代码 #!/bin/bash mysql_user"root" mysql_host"localhost" mysql_port"3306" mysql_charset"utf8mb4"backup_location/home/mysql/mysql_back/sql # 是否开始自动删除过期文件,过期时间…...

v-model与.sync的区别
我们在日常开发的过程中,v-model指令可谓是随处可见,一般来说 v-model 指令在表单及元素上创建双向数据绑定,但 v-model 本质是语法糖。但提到语法糖,这里就不得不提另一个与v-model有相似功能的双向绑定语法糖了,这就是 .sync修饰符。在这里就两者的使用进行一下比较和总结: …...

Linux---进程(1)
操作系统 传统的计算机系统资源分为硬件资源和软件资源。硬件资源包括中央处理器,存储器,输入设备,输出设备等物理设备;软件资源是以文件形式保存在存储器上的成熟和数据等信息。 操作系统就是计算机系统资源的管理者。 如果你的计…...
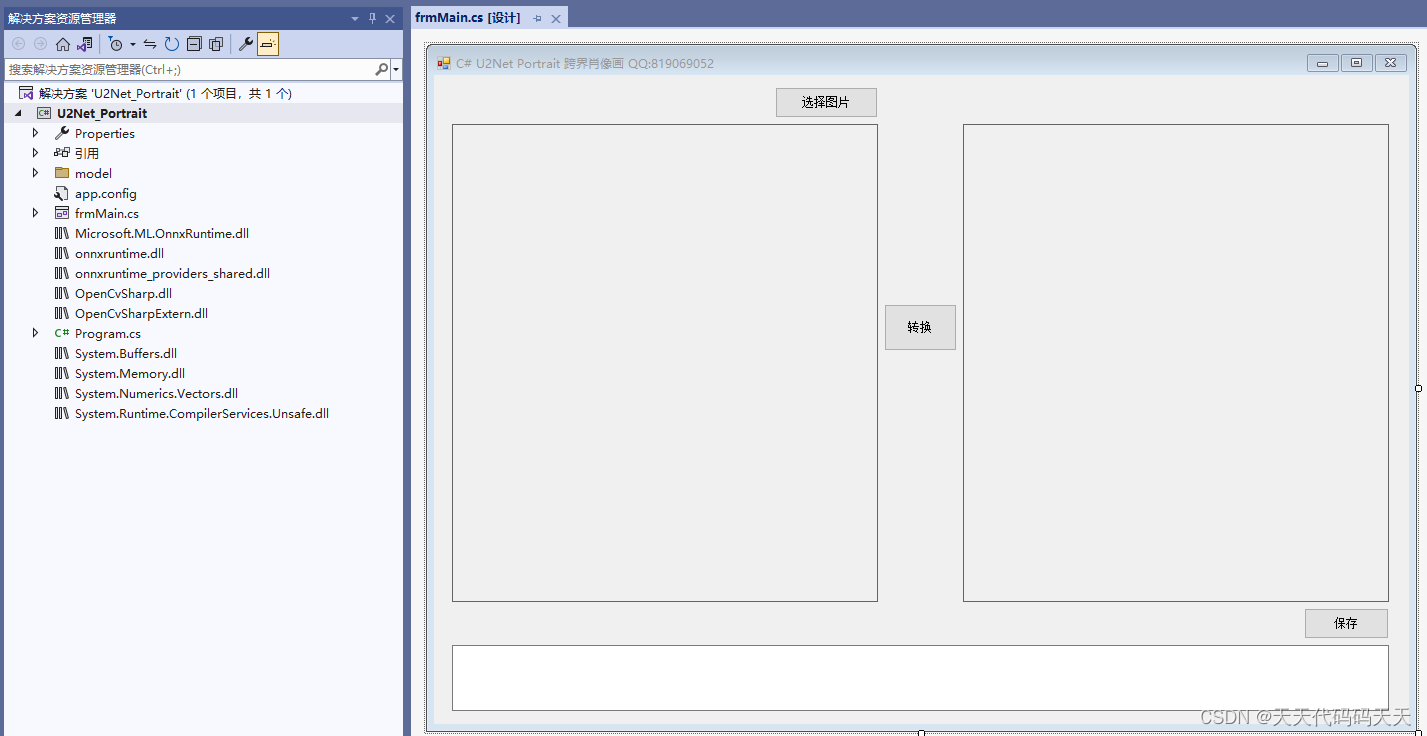
C# U2Net Portrait 跨界肖像画
效果 项目 下载 可执行文件exe下载 源码下载...
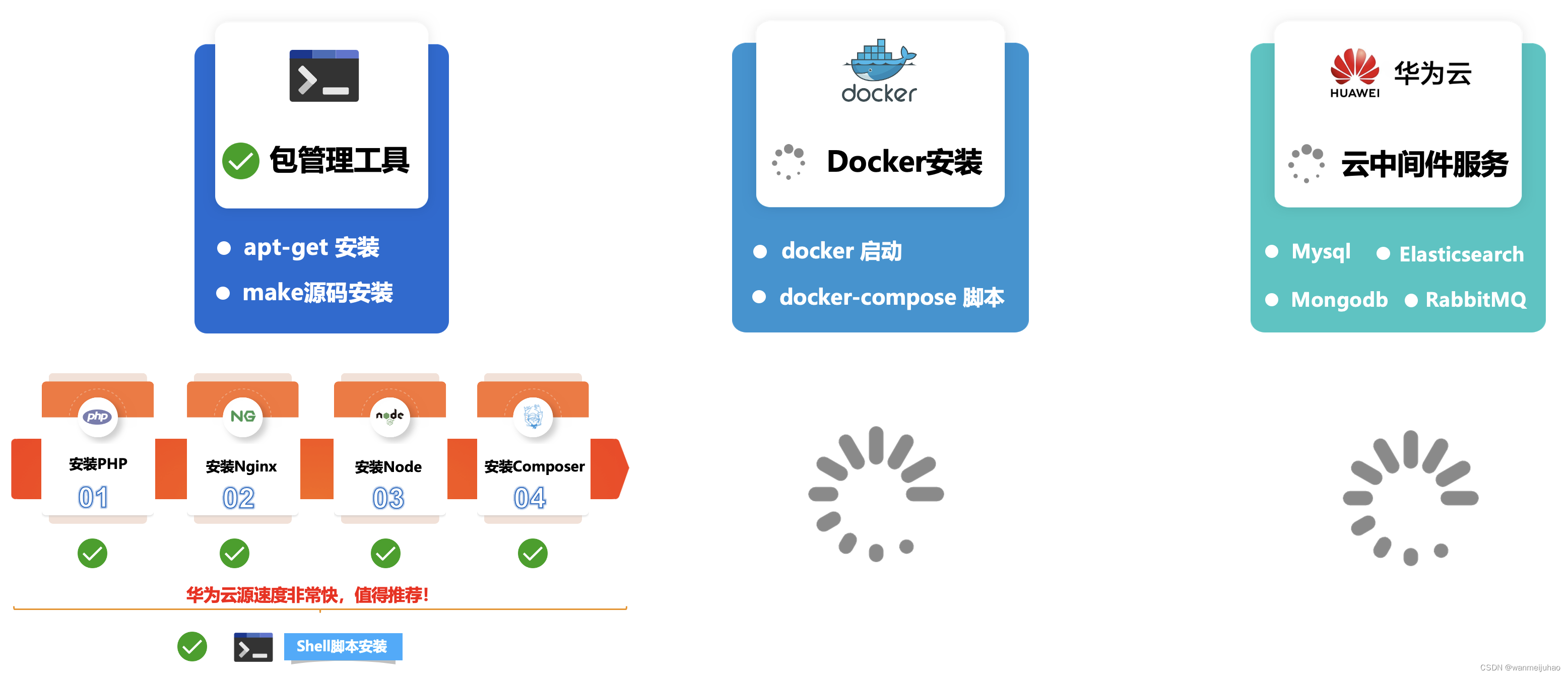
华为云云耀云服务器L实例评测|华为云耀云服务器L实例评测包管理工具安装软件(六)
七、华为云耀云服务器L实例评测包管理工具安装软件: 根据企业级项目架构图所示,本章主要是安装公司企业项目的基本环境LNMP,相关的包管理器Composer、Node、Npm、Yarn安装,评测一下包管理工具安装软件是否存在问题,如果…...

在PYTHON中用zlib模块对文本进行压缩,写入图片的EXIF中,后在C#中读取EXIF并用SharpZipLib进行解压获取压缩前文本
在PYTHON中用zlib模块对文本进行压缩长度,写入图片的EXIF中,并在C#中读取EXIF后用SharpZipLib进行解压缩获取压缩前文本。 PS:当压缩后的字节数组长度为单数时,无法写入EXIF的XPComment中,需要在后面增加一个以utf-8编码的空格&a…...
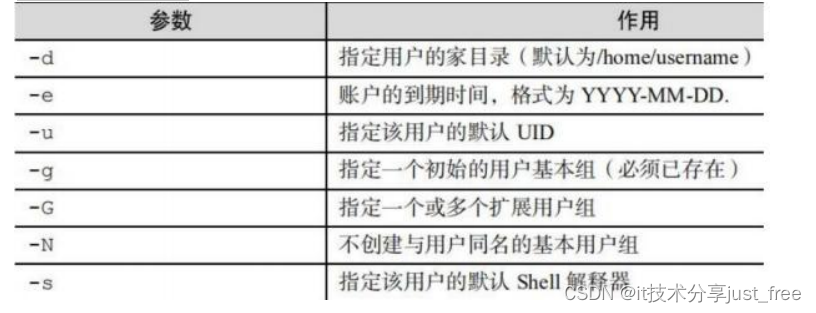
centos / oracle Linux 常用运维命令讲解
目录 1.shell linux常用目录: 2.命令格式 3.man 帮助 4.提示符 5.echo输出字符串或变量值 6.date显示及设置系统的时间或日期 7.重启系统 8.关闭系统 9.登录注销 10.wget 下载文件 11.ps 查看系统的进程 12.top动态监视进程信息和系统负载等信息 13.l…...
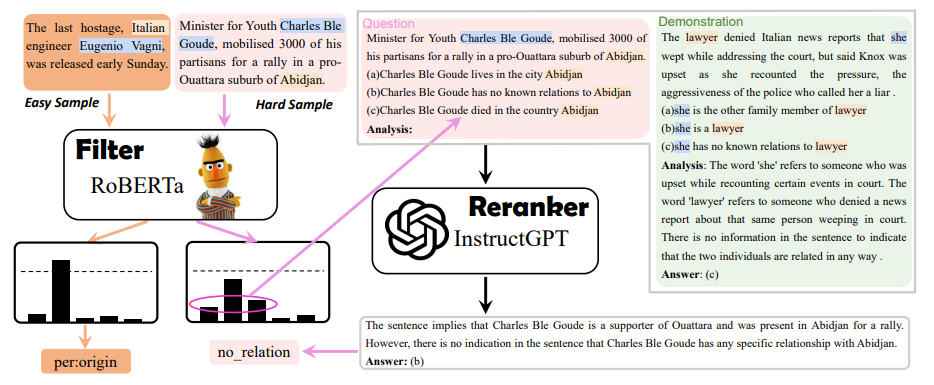
EMNLP 2023 录用论文公布,速看NLP各领域最新SOTA方案
EMNLP 2023 近日公布了录用论文。 开始前以防有同学不了解这个会议,先简单介绍介绍:EMNLP 是NLP 四大顶会之一,ACL大家应该都很熟吧,EMNLP就是由 ACL 下属的SIGDAT小组主办的NLP领域顶级国际会议,一年举办一次。相较于…...

互联网Java工程师面试题·Java 并发编程篇·第三弹
目录 26、什么是线程组,为什么在 Java 中不推荐使用? 27、为什么使用 Executor 框架比使用应用创建和管理线程好? 27.1 为什么要使用 Executor 线程池框架 27.2 使用 Executor 线程池框架的优点 28、java 中有几种方法可以实现一个线程…...

mac jdk的环境变量路径,到底在哪里?
在mac 电脑中,直接执行 java -version 显示Jdk的版本为1.8 然后打印Java环境变量 在终端中执行 echo $JAVA_HOME 1、情况一:发现环境变量是空的 我草,没配置环境变量怎么能使用Java ,和查看jdk版本 2、情况二:环…...
PyQt5 PyQt6 Designer 的安装
pip国内的一些镜像 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣(douban) http://pypi.douban.com/simple/ 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.…...
)
数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有…...
16基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。
基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。 16matlab图像处理图像分割 (xiaohongshu.com)...

2、使用阿里云镜像加速器提升Docker的资源下载速度
1、注册阿里云账号并登录 https://www.aliyun.com/ 2、进入个人控制台,找到“容器镜像服务” 3、在“容器镜像服务”中找到“镜像加速器” 4、在右侧列表中会显示你的加速器地址,复制地址 5、进入/etc/docker目录,编辑daemon.json࿰…...
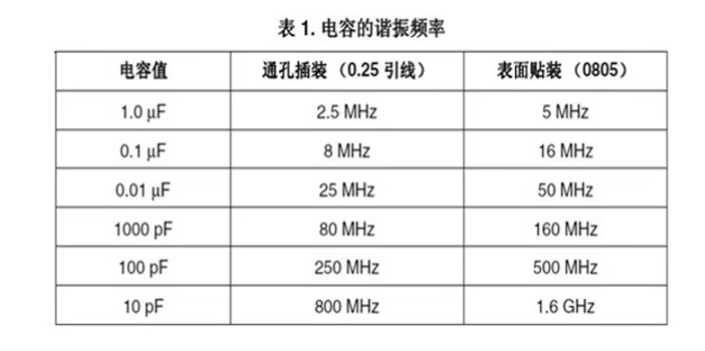
贴片电容材质的区别与电容的主要作用
一、贴片电容材质NPO、COG、X7R、X5R、Y5V、Z5U区别 主要是介质材料不同,不同介质种类由于它的主要极化类型不一样,其对电场变化的响应速度和极化率也不一样。在相同的体积下的容量就不同,随之带来的电容器介质的损耗、容量的稳定性也就不同…...

XXMI-Launcher:多游戏Mod管理平台的终极指南
XXMI-Launcher:多游戏Mod管理平台的终极指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI-Launcher是一款专为热门游戏设计的Mod管理平台,支持《原…...

CSPM 信息与文档管理:从混沌到数智化,企业转型的核心命门
在 2026 年 CSPM 最新考纲中,信息与文档管理从边缘考点升级为战略级核心模块,直指企业数字化转型的最大盲区 ——文档混沌、信息孤岛、数据资产流失。本文以犀利视角拆解传统文档管理的致命弊端,结合 AI 大模型、区块链存证、BIM 数字孪生、知…...

G-Helper深度解析:华硕笔记本的终极轻量级控制方案
G-Helper深度解析:华硕笔记本的终极轻量级控制方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

B站视频转文字终极指南:5分钟掌握高效知识管理神器
B站视频转文字终极指南:5分钟掌握高效知识管理神器 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容࿰…...

用Python lifetimes库实战:手把手教你用BG/NBD+Gamma-Gamma模型预测电商用户未来3个月价值
用Python lifetimes库实战:电商用户价值预测的极简指南 电商行业的核心挑战之一是如何精准识别高价值用户。想象一下,你手头有一份过去12个月的交易数据,老板要求你在下周的预算会议前,预测未来三个月哪些用户最值得投入营销资源。…...

SteamVR Unity插件实战:解决VR开发中的三大核心挑战
SteamVR Unity插件实战:解决VR开发中的三大核心挑战 【免费下载链接】steamvr_unity_plugin SteamVR Unity Plugin - Documentation at: https://valvesoftware.github.io/steamvr_unity_plugin/ 项目地址: https://gitcode.com/gh_mirrors/st/steamvr_unity_plug…...
)
手把手教你用ADS 2023设计433MHz低噪放大器(从DC分析到S参数,保姆级避坑指南)
从零开始用ADS 2023打造433MHz低噪声放大器:原理剖析与实战避坑指南 在物联网和无线通信设备爆发式增长的今天,433MHz频段因其良好的穿透性和适中的传输距离,成为智能家居、远程控制等场景的首选。而作为接收机前端的关键部件,低噪…...

金融涉外业务赋能,守护跨境金融安全
随着跨境金融业务的快速发展,银行、保险等金融机构的涉外业务日益增多,外籍客户开户、跨境转账、保险投保等业务,都需要进行严格的证件核验与身份确认。传统的人工核验模式,不仅效率低下,还难以应对复杂的证件伪造手段…...

SaaS ERP和传统ERP,到底差在哪?
这几年,ERP这个词越来越火。但有意思的是,很多企业老板、管理层,甚至已经在用ERP的人,其实都没真正分清:“SaaS ERP”和“传统ERP”,到底差在哪。很多人会觉得:“不都是ERP吗?不就是…...

观察使用TaotokenTokenPlan后项目月度AI成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken TokenPlan后项目月度AI成本的变化趋势 对于许多采用按量计费模式的中小型项目而言,大模型API的月度支…...