44.ES
一、ES。
(1)es概念。
(1.1)什么是es。
(1.2)es的发展。
es是基于lucene写的。

(1.3)总结。
es是基于lucene写的。
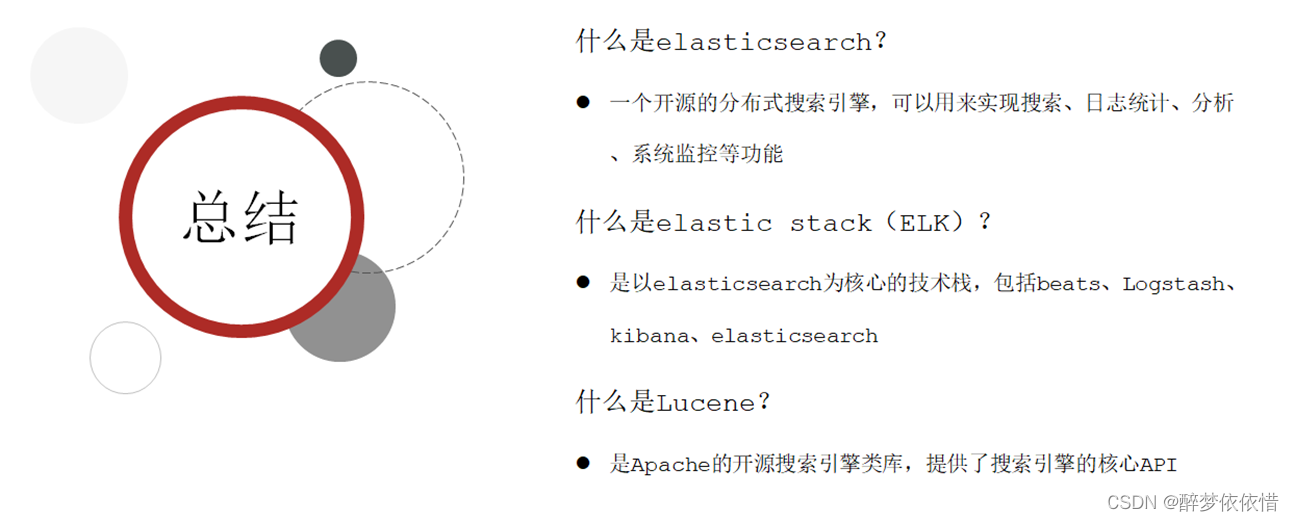
(2)倒排索引。
(3)es与mysql的概念对比。
索引:对应数据表。
文档:对应数据表记录。
词条:一条数据表记录有若干词条。

(4)部署es、kibana、IK分词器。
(4.1)部署单点es。
(4.1.1)创建网络。
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
(4.1.2)加载镜像。
这里我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。
大家将其上传到虚拟机中,然后运行命令加载即可:
docker load -i es.tar
同理还有kibana的tar包也需要这样做。
(4.1.3)运行es容器。
运行docker命令,部署单点es:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
数据卷挂载提示:docker run -v <宿主机路径>:<容器路径> <镜像名称>
命令解释:
--e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net :加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
在浏览器中输入:
http://192.168.150.101:9200
即可看到elasticsearch的响应结果。
(4.2)部署bibana。
(4.2.1)运行docker命令,部署kibana。
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
命令解释:
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
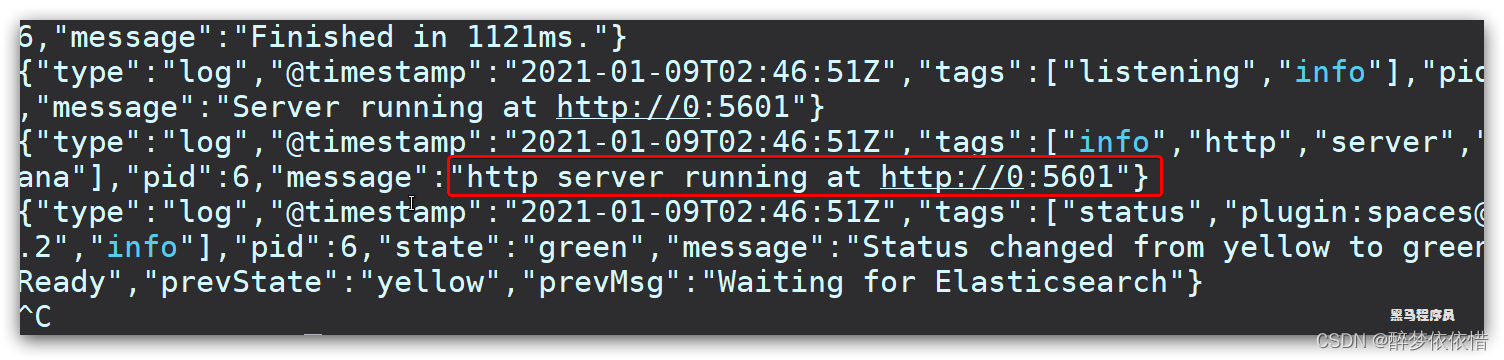
此时,在浏览器输入地址访问(注意该IP地址):
http://192.168.150.101:5601
即可看到结果
(4.2.2)DevTools。
点击Dev tools

kibana中提供了一个DevTools界面:
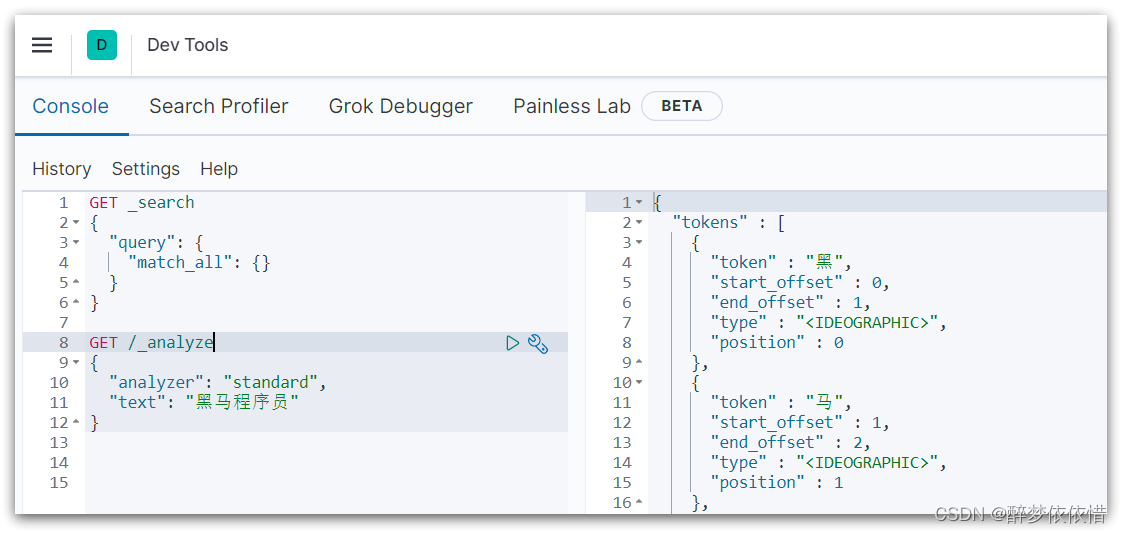
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
(4.3)安装IK分词器。

(4.3.1)在线安装ik插件(较慢)。
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
(4.3.2)离线安装ik插件(推荐)。
(4.3.2.1)查看数据卷目录。
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
提示:只要将ik分词器放到挂载到容器的主机挂载目录下就行,当时运行容器的时候挂载了:
-v es-plugins:/usr/share/elasticsearch/plugins
显示结果:
[{"CreatedAt": "2022-05-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
(4.3.2.2)解压缩分词器安装包。
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
(4.3.2.3)上传到es容器的插件数据卷中。
也就是/var/lib/docker/volumes/es-plugins/_data :

(4.3.2.4)重启容器。
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es(4.3.2.5)测试。
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
GET /_analyze
{"analyzer": "ik_max_word","text": "黑马程序员学习java太棒了"
}
结果:
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "程序","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 2},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "CN_CHAR","position" : 3},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 5},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 6},{"token" : "太棒","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 7},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 8}]
}(4.3.3.6)扩展词词典。
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“传智播客” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
奥力给
4)重启elasticsearch
docker restart es# 查看 日志
docker logs -f elasticsearch
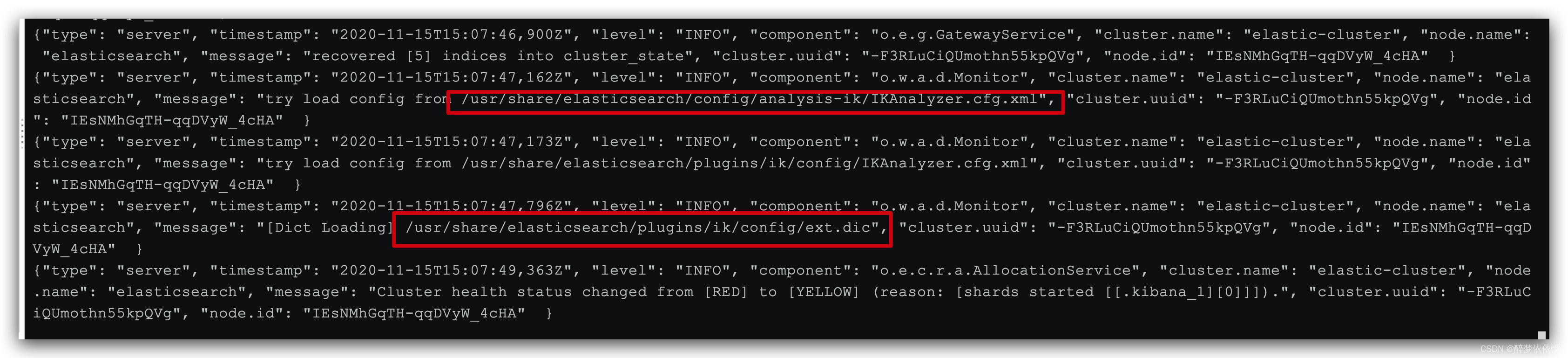
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "传智播客Java就业超过90%,奥力给!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
(4.3.3.7)停用词词典。
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
3)在 stopword.dic 添加停用词
黑马
4)重启elasticsearch
# 重启服务
docker restart elasticsearch
docker restart kibana# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "传智播客Java就业率超过95%,奥力给!"
}
注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
(5)索引库操作(即表操作)。
(5.1)mapping映射属性。

(5.2)索引库的CRUD。
(5.2.1)创建索引库。
分词器只对text类型的数据分词。(不分词代表整个内容就是一个词条,分词就是整个内容可能超过一个词条)。
index约束如果为真,则参与倒排索引,否则不参与倒排索引(即不成为词条)。
PUT /itheima
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}
(5.2.2)查看、删除索引库。
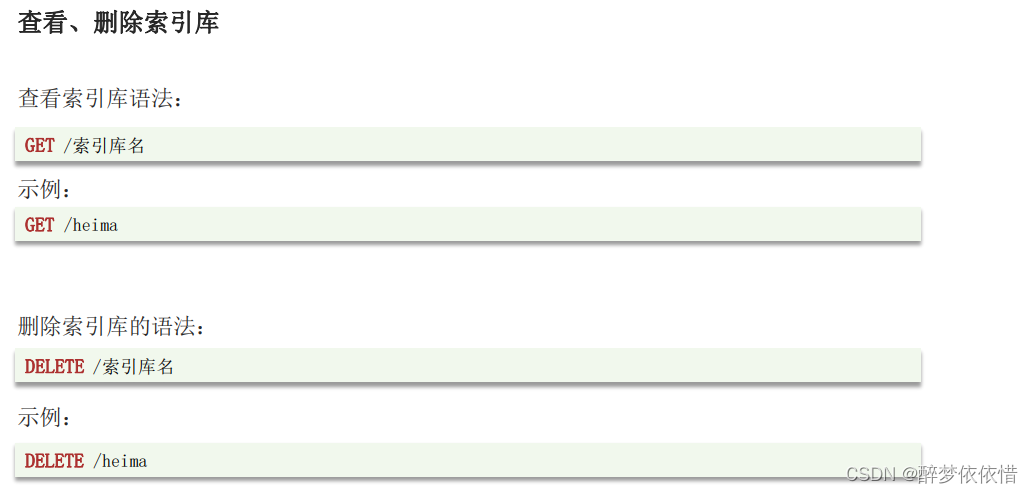
(5.2.3)修改索引库。

(5.2.4)索引库操作有哪些?

(6)文档操作。
(6.1)新增文档。

(6.2)查询、删除文档。

(6.3)修改文档。
注意:测试了一下,这也是全量修改。
POST /itheima/_doc/1
{"info": "1黑马程序员java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
(6.4)文档操作总结。

(7)RestClient操作索引库。

(7.1)初始化JavaRestClient、创建索引库。
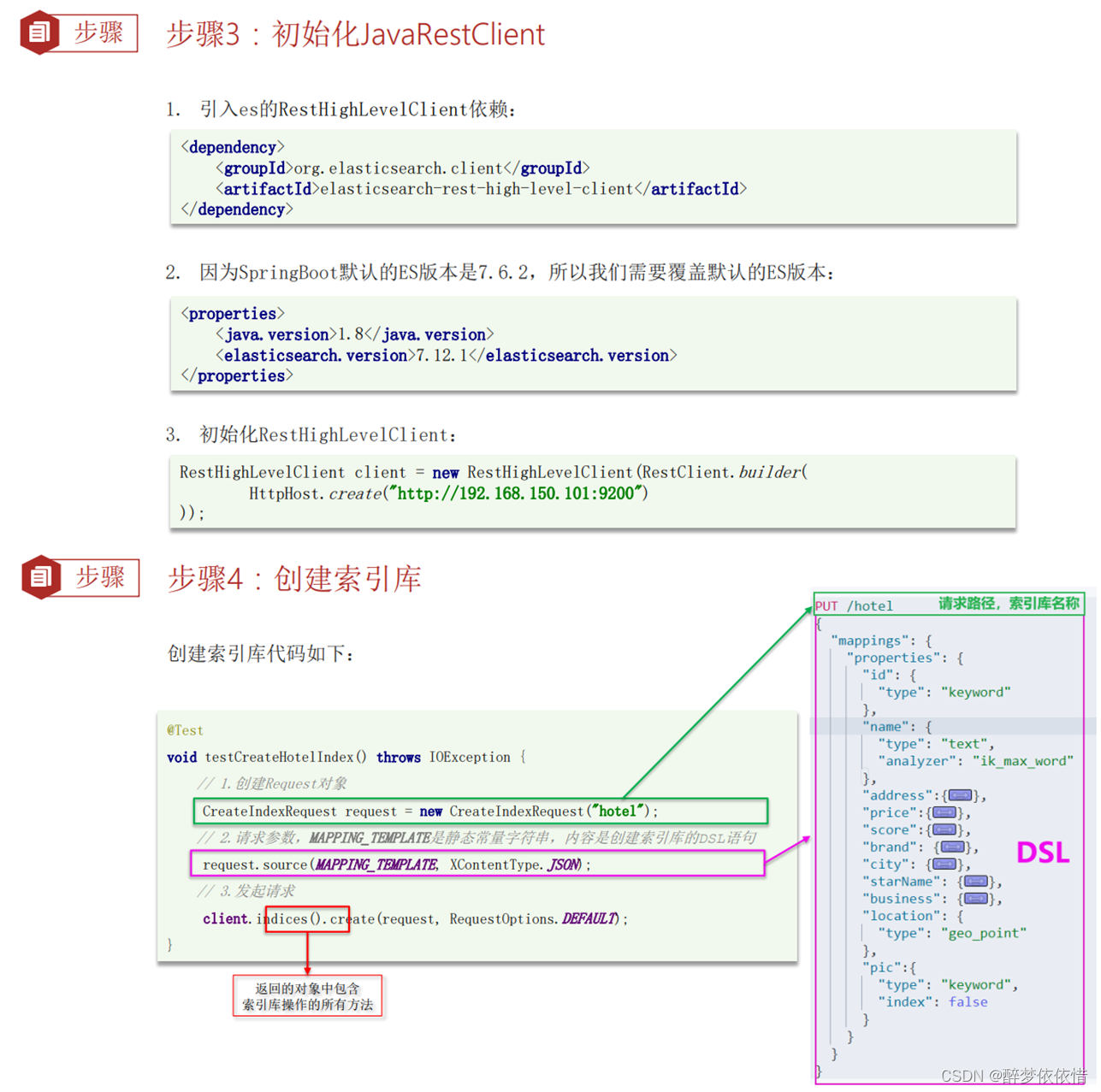
(7.2)删除索引库、判断索引库是否存在。

(7.3)总结。

(8)RestClient操作文档。
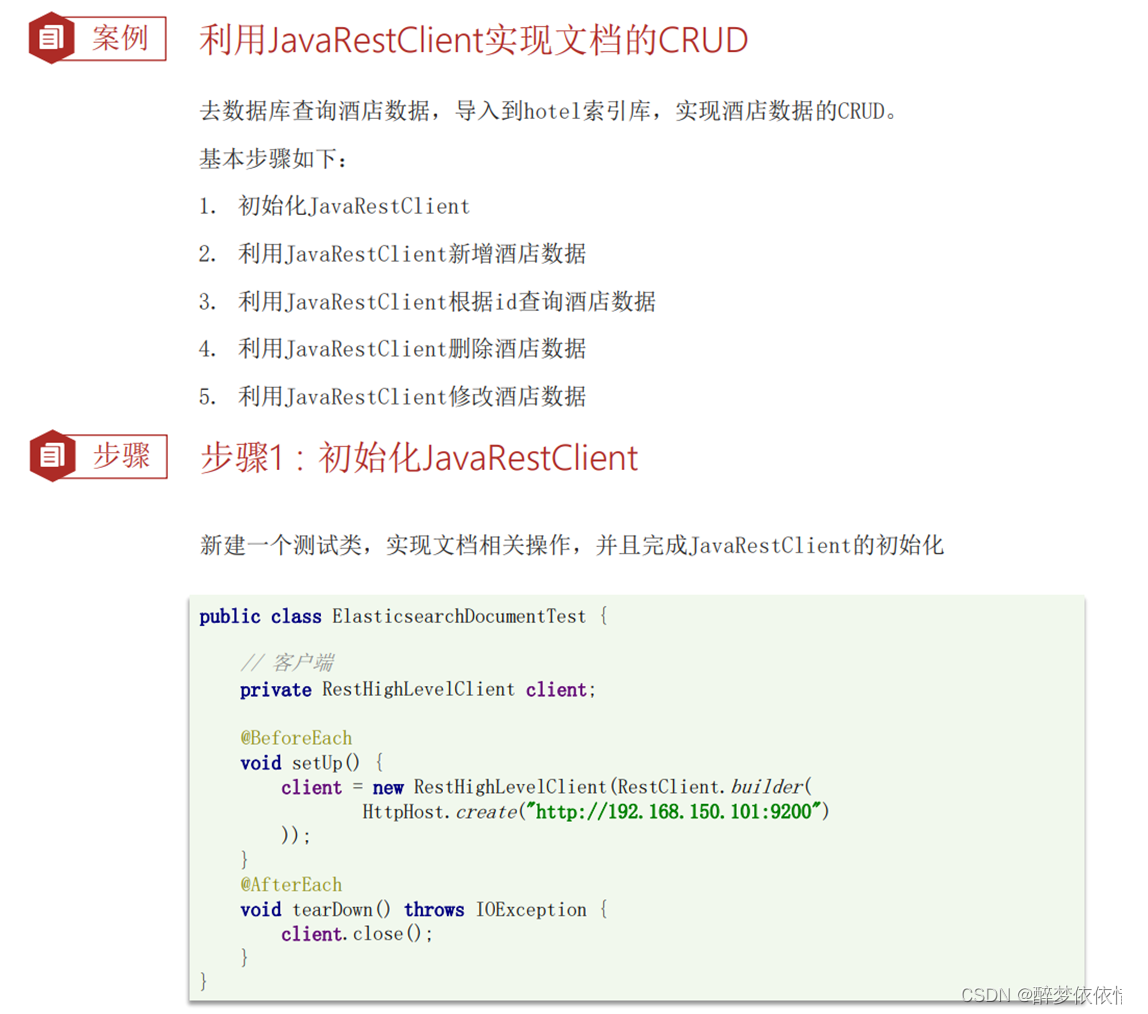
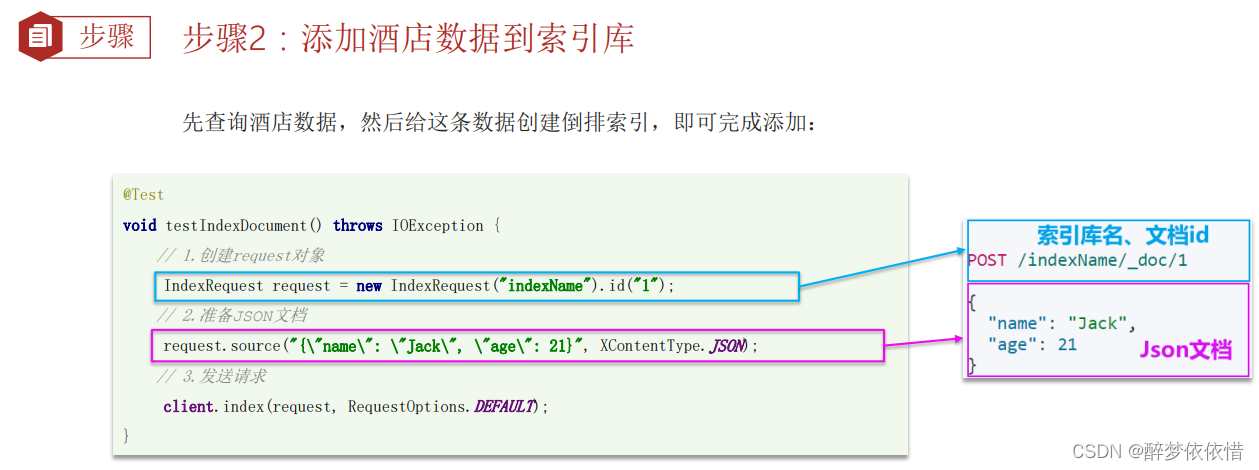
(8.1)新增文档。
案例的mapping:
# 酒店的mapping
PUT /hotel
{"mappings": {"properties": {"id": {"type": "keyword"},"name": {"type": "text","analyzer": "ik_max_word"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"business": {"type": "keyword"},"location": {"type": "geo_point"},"pic": {"type": "binary","index": false}}}
}
(8.2)查询文档。

(8.3)修改文档。

(8.4)删除文档。
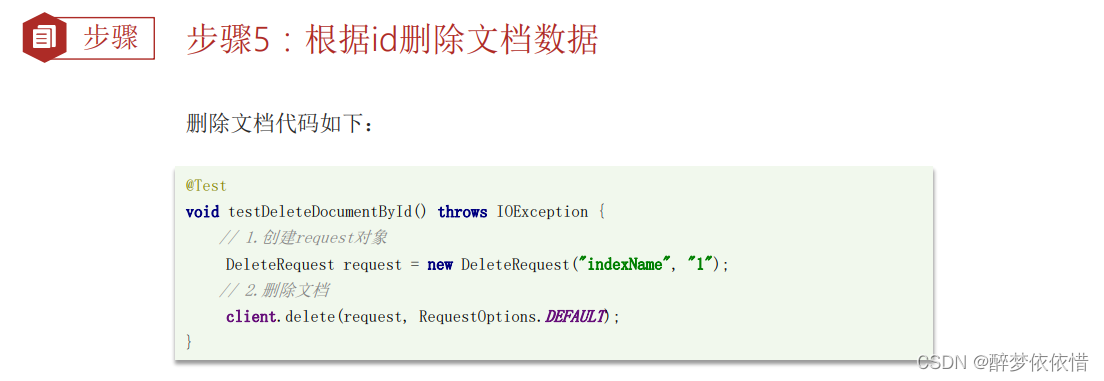
(8.5)批量导入文档。

(8.6)总结。

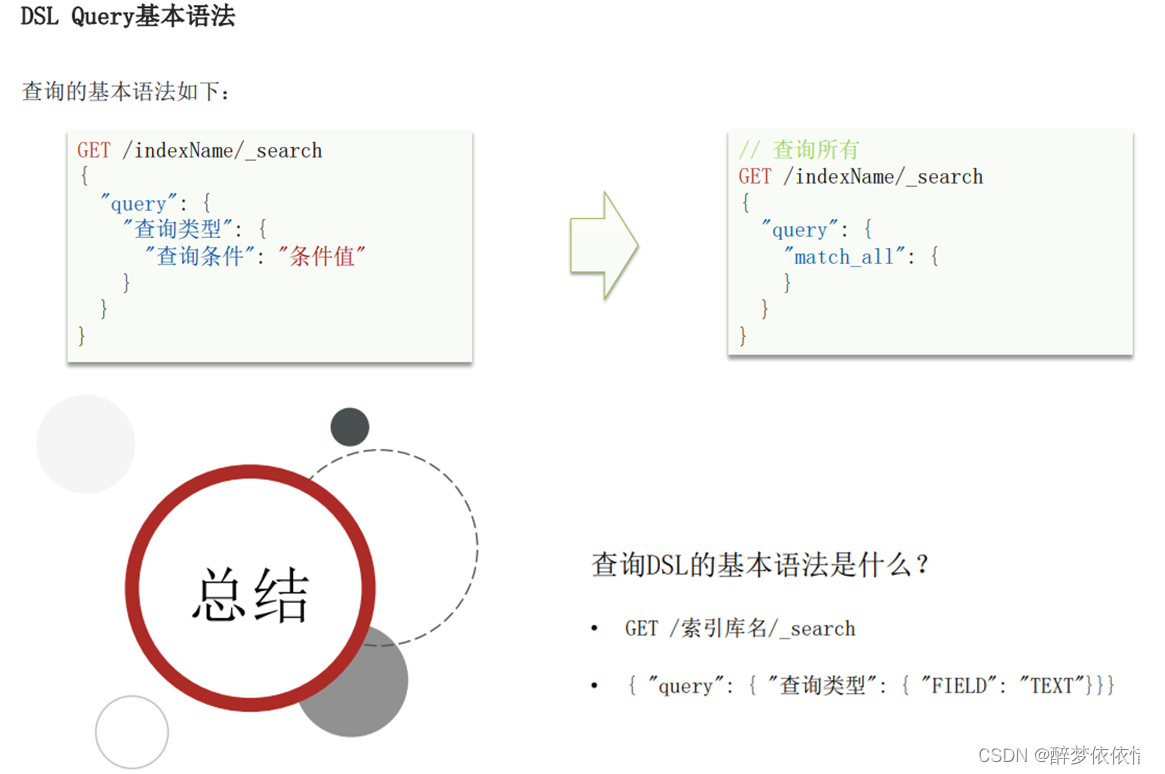
(9)DSL查询文档。
(9.1)DSL查询分类。

(9.2)查询所有。
GET /hotel/_search
{"query": {"match_all": {}}
}
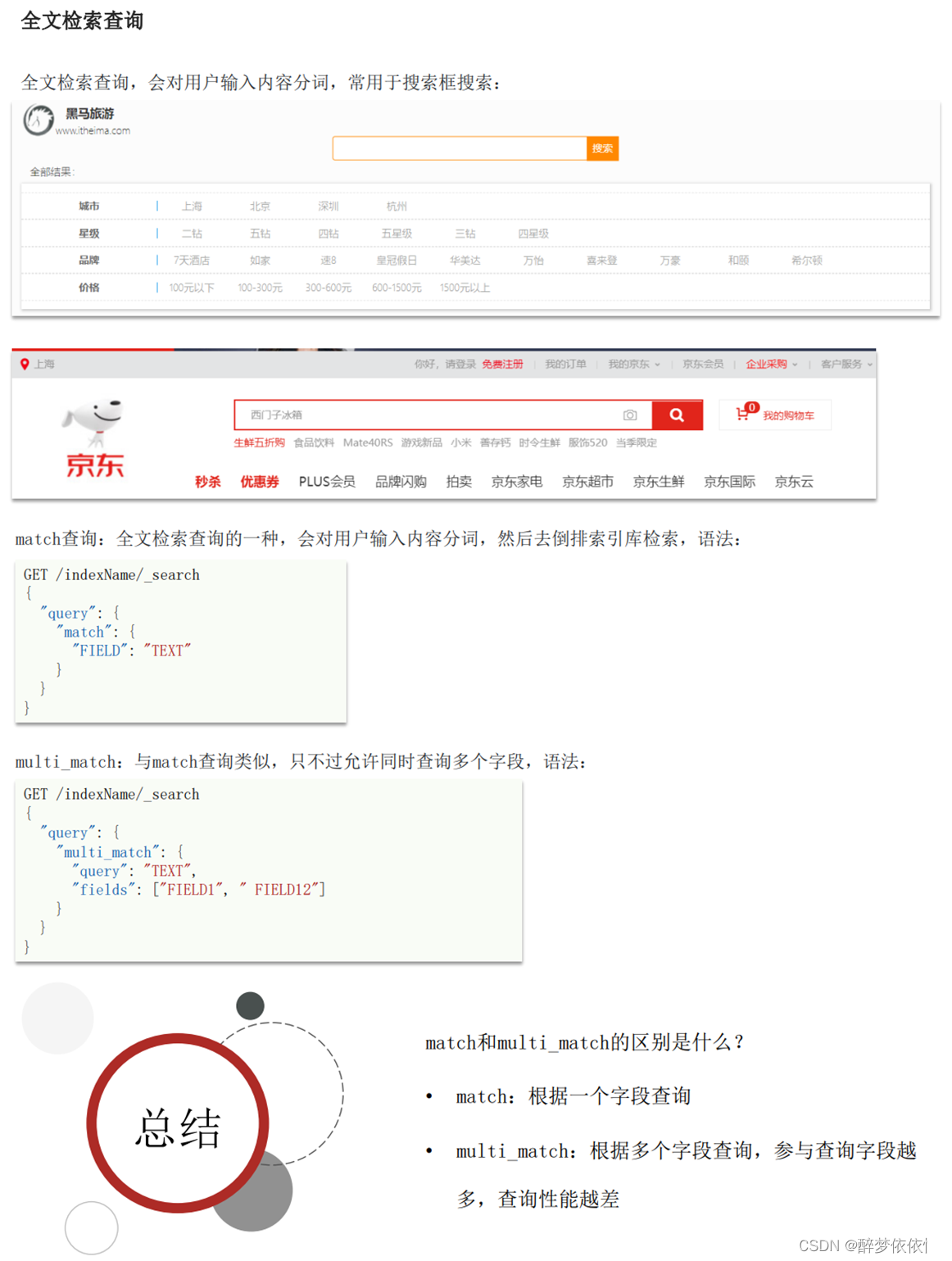
(9.3)全文检索查询。
GET /hotel/_search
{"query": {"match": {"business": "交大/闵行经济开发区"}}
}GET /hotel/_search
{"query": {"multi_match": {"query": "上海滩","fields": ["name","city","brand"]}}
}
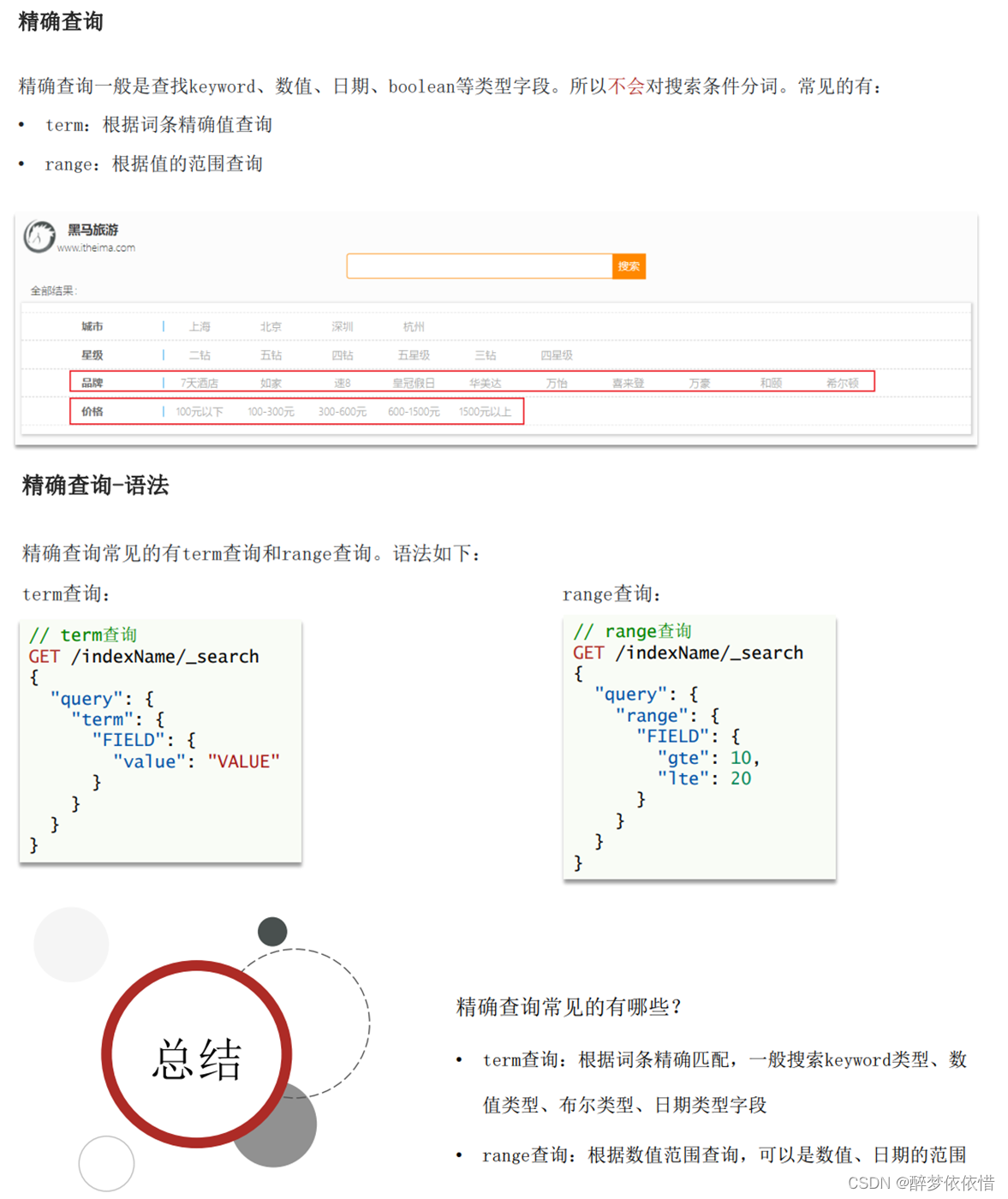
(9.4)精准查询。
# term查询
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}# range查询
GET /hotel/_search
{"query": {"range": {"price": {"gte": 100,"lte": 2000}}}
}
(9.5)地理坐标查询。
# 地理查询
GET /hotel/_search
{"query": {"geo_distance": {"distance": "150km","location": "31.21,122.6"}}
}
(9.6)组合查询。
相关文章:
44.ES
一、ES。 (1)es概念。 (1.1)什么是es。 (1.2)es的发展。 es是基于lucene写的。 (1.3)总结。 es是基于lucene写的。 (2)倒排索引。 (3…...

分权分域有啥内容?
目前的系统有什么问题? 现在我们的系统越来越庞大,可是每一个人进来的查看到的内容完全一样,没有办法灵活的根据不同用户展示不同的数据 例如我们有一个系统,期望不同权限的用户可以看到不同类型的页面,同一个页面不…...
6.Docker搭建RabbitMQ
1、端口开放 如果在云服务上部署需在安全组开通一下端口:15672、5672、25672、61613、1883。 15672(UI页面通信口)、5672(client端通信口)、25672(server间内部通信口)、61613(stomp 消息传输)、1883(MQTT消息队列遥测传输)。 2、安装镜像 docker pull rabbitmq 3、…...
用 docker 创建 jmeter 容器, 实现性能测试,该如何下手?
用 docker 创建 jmeter 容器, 实现性能测试 我们都知道,jmeter可以做接口测试,也可以用于性能测试,现在企业中性能测试也大多使用jmeter。docker是最近这些年流行起来的容器部署工具,可以创建一个容器,然后把项目放到…...

4年软件测试,突破不了20K,太卷了。。。
先说一个插曲:上个月我有同学在深圳被裁员了,和我一样都是软件测试,不过他是平安外包,所以整个组都撤了,他工资和我差不多都是14K。 现在IT互联网已经比较寒冬,特别是软件测试,裁员先裁测试&am…...
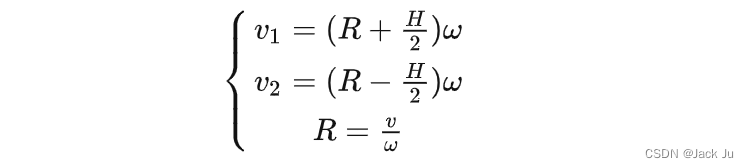
机器人控制算法——两轮差速驱动运动模型
1.Introduction 本文主要介绍针对于两轮差速模型的逆运动学数学推导。因为在机器人控制领域,决策规划控制层给执行器输出的控制指令v(车辆前进速度)和w(角速度),因此,我们比较关心,当底层两个驱动电机接收到此信息,如何…...

Queue简介
概念: 队列(Queue)是一种常见的线性数据结构,在Java中用于存储和操作元素序列。它基于先进先出(First-In-First-Out, FIFO)原则,即最早入队的元素首先出队。只能在队尾添加元素,在队…...

被面试官问到分布式ID,别再傻乎乎只会答雪花算法了...
文章目录 1. 分布式ID2. 数据库主键自增3. 数据库号段模式4. Redis自增5. UUID6. Snowflake (雪花算法)7. Leaf (美团分布式ID生成系统)7.1 Leaf-segment 号段方案7.1.2 双buffer优化 7.2 Leaf-snowflake方案7.3 Leaf-snowflake Demo 1. 分布式ID 在分布式系统中,通…...

使用Boto3访问AWS S3服务
安装Boto3,执行如下命令: python -m venv .venv . .venv/bin/activate python -m pip install boto3创建配置文件,执行如下命令: mkdir -p ~/.aws touch ~/.aws/credentials touch ~/.aws/config编辑 ~/.aws/credentials&#x…...

ODrive移植keil(五)—— 开环控制和电流变换
目录 一、开环控制1.1、控制原理1.2、硬件接线1.3、代码说明1.4、程序演示1.5、程序架构的体现 二、电流变换2.1、理论说明2.2、代码说明 ODrive、VESC和SimpleFOC 教程链接汇总:请点击 一、开环控制 在SimpleFOC系列中有开环控制的教程,SimpleFOC移植S…...

【Java学习之道】日期与时间处理类
引言 在前面的章节中,我们介绍了Java语言的基础知识和核心技能,现在我们将进一步探讨Java中的常用类库和工具。这些工具和类库将帮助我们更高效地进行Java程序开发。在本节中,我们将一起学习日期与时间处理类的使用。 一、为什么需要日期和…...
信息系统项目管理师第四版学习笔记——高级项目管理
项目集管理 项目集管理角色和职责 在项目集管理中涉及的相关角色主要包括:项目集发起人、项目集指导委员会、项目集经理、其他影响项目集的干系人。 项目集发起人和收益人是负责承诺将组织的资源应用于项目集,并致力于使项目集取得成功的人。 项目集…...

MySQL建表操作和用户权限
1.创建数据库school,字符集为utf8 mysql> create database school character set utf8; 2.在school数据库中创建Student和Score表 mysql> create table school.student( -> Id int(10) primary key, -> Stu_id int(10) not null, -> C_n…...

TCP/IP(十一)TCP的连接管理(八)socket网络编程
一 socket网络编程 socket 基本操作函数 bind、listen、connect、accept、recv、send、select、close 说明: 本文需要C语言、syscall系统调用、OS 操作系统基础理论,如果不了解可以暂时跳过目标: 知道对应库函数的更底层机制思考: socket函数与FIN、A…...
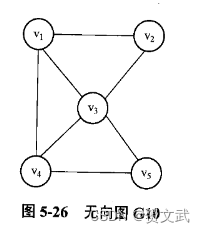
第五章 图
第五章 图 图的基本概念图的应用背景图的定义和术语 图的存储结构邻接矩阵邻接表 图的遍历连通图的深度优先搜索连通图的广度优先搜索 图的应用最小生成树拓扑排序 小试牛刀 图的基本概念 图结构中,任意两个结点之间都可能相关;而在树中,结点…...

深度学习实战:用Keras搭建深度学习网络做手写数字识别
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

算法解析:LeetCode——机器人碰撞和最低票价
摘要:本文由葡萄城技术团队原创并首发。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 机器人碰撞 问题: 现有 n 个机器人,编号从 1 开始,每个…...
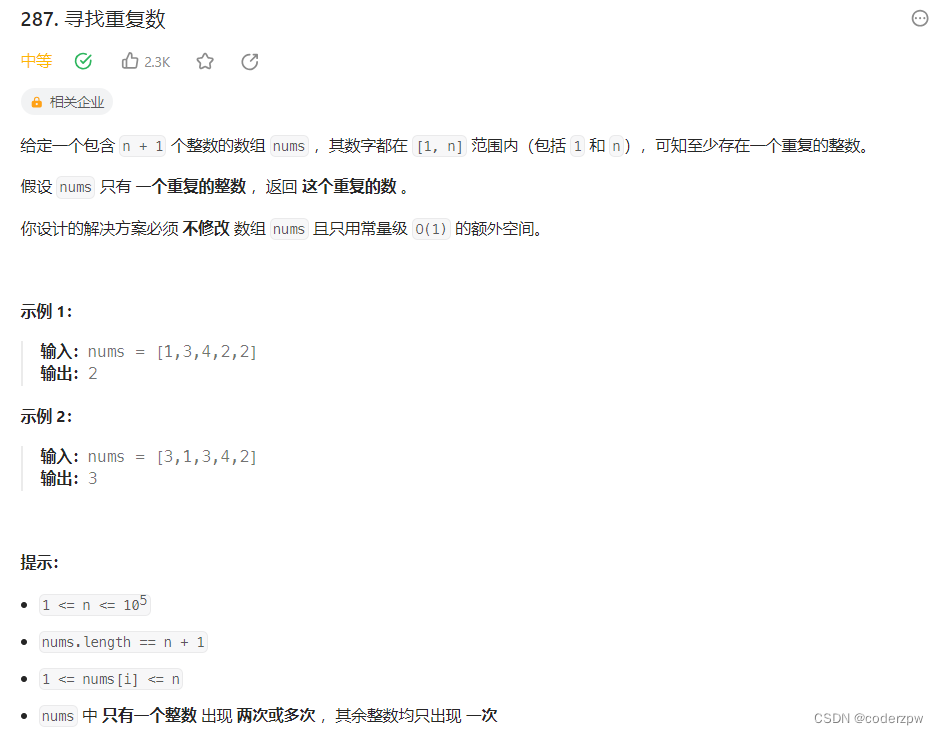
LeetCode刷题总结 - LeetCode 热题 100 - 持续更新
LeetCode 热题 100 其他系列哈希1. 两数之和49. 字母异位词分组128. 最长连续序列 双指针27. 移除元素283. 移动零11. 盛最多水的容器剑指 Offer II 007. 数组中和为 0 的三个数42. 接雨水 滑动窗口438. 找到字符串中所有字母异位词3. 无重复字符的最长子串 字串560. 和为 K 的…...
Spring是什么?为什么要使用Spring?
目录 前言 一、Spring是什么? 1.1 轻量级 1.2 JavaEE的解决方案 二、为什么要使用Spring 2.1 传统方式完成业务逻辑 2.2 使用Spring模式完成业务逻辑 三、为什么使用Spring? 前言 本文主要介绍Spring是什么,并且解释为何要去使用Spring&…...

自我监督学习日志
学习日志 10.12 一天学不了一分钟,不知道为什么也就是了 今天一定要学一个小时! 机器学习就是机器帮我们找一个函数 语音辨识,语音,声音讯号 转化为文字 帮我们找一个人类写不出来的复杂函数 类神经网络 输入 一张图片用一个矩…...

Redis Sentinel:主从架构的自动保镖详解
Redis 哨兵(Sentinel):主从架构的「自动保镖」 在 Redis 主从复制经典架构当中,主节点(Master)全权负责集群读写核心请求处理,从节点(Slave)仅专注于实时同步主节点数据&…...

CircuitFusion:多模态AI在集成电路设计中的革命性应用
1. 集成电路设计的多模态革命:CircuitFusion技术解析在AI芯片设计领域,一个令人头疼的现实是:随着芯片复杂度呈指数级增长,传统设计流程已难以应对。以7nm工艺节点为例,单个芯片可能包含数十亿个晶体管,设计…...

基于SpringBoot+Vue的旅游景点攻略与门票预订系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的旅游景点攻略与门票预订系统以解决传统旅游信息管理中存在的数据孤岛现象服务响应滞后问题以及用户体验单一化等核…...

对比直接使用官方API体验Taotoken在用量可视化方面的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API体验Taotoken在用量可视化方面的优势 效果展示类,分享开发者在同时使用官方渠道与Taotoken聚合服务…...

选择智能体框架:LangChain、AutoGen、CrewAI、Dify对比
去年秋天,我们团队准备上一个新项目,一个可以为客户自动生成月度运营分析报告的智能体。需求不复杂,就是每周从数据库里拉点数据,跑一下趋势分析,最后产出一个带图表和结论的PDF。 我那时候刚花了三个月时间把LangCha…...

大语言模型在模块化布局优化中的应用与实战
1. 项目概述:当大语言模型遇见模块化布局优化在芯片设计和建筑规划领域,模块布局优化一直是个令人头疼的NP难问题。想象一下,你面前有16个形状各异的乐高积木(模块),需要将它们严丝合缝地拼成一个矩形底板&…...

ncmdump技术解析:网易云音乐NCM加密格式的逆向工程与转换实现原理
ncmdump技术解析:网易云音乐NCM加密格式的逆向工程与转换实现原理 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 项目技术定位与核心价值 ncmdump是一款专注于网易云音乐NCM加密格式逆向解析的开源工具,通过…...

地下水数值模拟中稳态与瞬态模型的构建机理及参数率定方法指南
概述在地下水流数值模拟(如基于有限差分法的 MODFLOW 平台)中,稳态(Steady-State)与瞬态(Transient)模拟是揭示地下水流场特征、评估水资源量以及预测流场演变的核心阶段。然而,在实…...

从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析
从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr…...

【使用高斯原理推导缆绳-拖曳伞系统的动态模型】使用拖缆系统进行微型空中飞行器的空中回收研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...