数据仓库DW-理论知识储备
数据仓库DW
数据仓库具备 采集数据、分析数据、存储数据的功能,最后得出一些有用的数据,一些目标数据来使用。
采集来自不同源的数据,然后对这些数据进行分析和计算得出一些有用的指标,提供数据决策支持。
数据的来源有:系统的业务数据、用户的行为数据、爬虫数据等。
数据仓库包含:实时数据仓库、离线数据仓库。
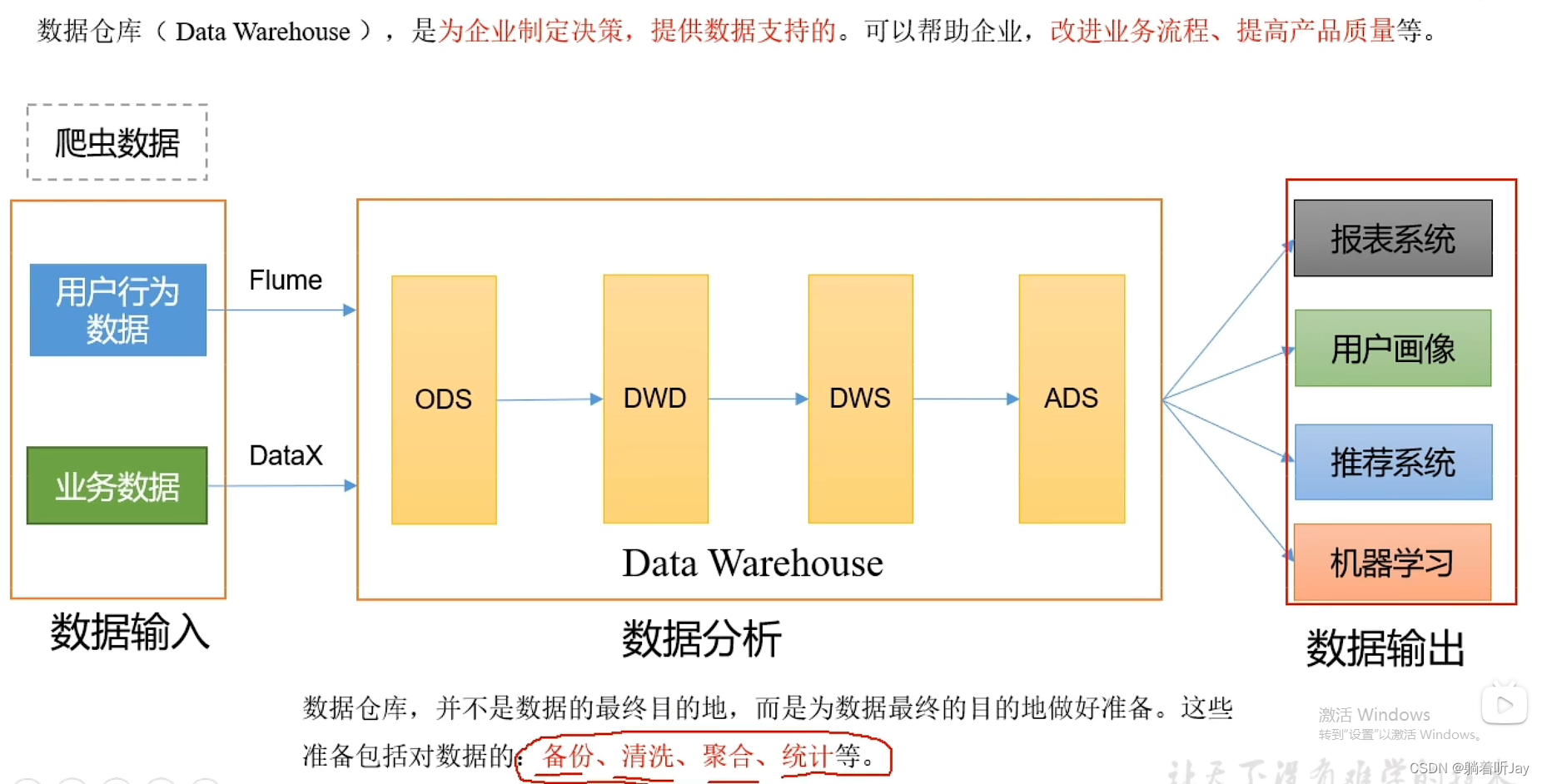
数仓分层
数据仓库中的数据一般经过一下几层处理:参考来自
1.ODS
ODS主要完成:
(1)保持数据原貌不做任何修改,保留历史数据,储存起到备份数据作用,采集过来是什么数据就存储什么数据;
(2)数据一般采用lzo、Snappy、parquet等压缩格式;
(3)创建分区表,防止后续的全表扫描,减少集群资源访问数仓的压力,一般按天存储在数仓中。
2.DWD
DWD主要完成:
1. 数据清洗
(1)去除空值、脏数据、超过极限范围的数据。
(2)过滤核心字段无意义的数据,比如订单表中订单 id 为 null,支付表中支付 id 为空
(3)将用户行为宽表和业务表进行数据一致性处理
清洗的手段包括Sql、mr、rdd、kettle、Python等等。清洗掉数据不能太多也不能很少。合理范围:1 万条数据清洗掉 1 条。
2. 脱敏
对手机号(181****7089)、身份证号等敏感数据脱敏
3. 维度退化
对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月日)
4. 压缩
LZO,列式存储 parquet
3.DWS
以DWD为基础,进行轻度的汇总。预聚合。
DWS层就是关于各个主题的加工和使用,这层是宽表聚合值,是各个事实表的聚合值。这里做轻度的汇总会让以后的计算更加的高效,如:统计各个主题对象计算7天、30天、90天的行为, 应对特殊需求(例如,购买行为,统计商品复购率)会快很多不必走ODS层反复拿数据做加工。
这层会把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。
涉及的主题包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等
4.DWT
这层涉及的主题和DWS层一样包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等。只不过DWS层的粒度是对当日用户汇总信息,而DWT层是对截止到当日、或者近7日、近30日等的汇总信息。
以用户主题这个来举列:
*DWS层:用户主题层是记录某一个用户在某一天的汇总行为。
*DWT层:用户主题层是记录某一个用户截止在当日的汇总行为。
5.ADS
统计指标。
ADS层数据是专门给业务使用的数据层,这层是面向业务定制的应用数据层。
ADS主要完成:
(1)提供为数据产品使用的结果数据、指标等。
(2)提供给数据产品和数据分析使用的数据,一般会存放在 ES、MySQL等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。如报表数据,或者说那种大宽表。
这个项目中ADS层也是包含有多个主题:设备主题、会员主题、商品主题、营销主题、地区主题、访客主题、用户主题、订单主题、优惠券主题、活动主题等等。每个主题都包含多个指标的计算。
离线数仓
通常是批处理数据,一般一天处理一次,所以是批处理数据量大,处理时间长
离线数仓架构参考图
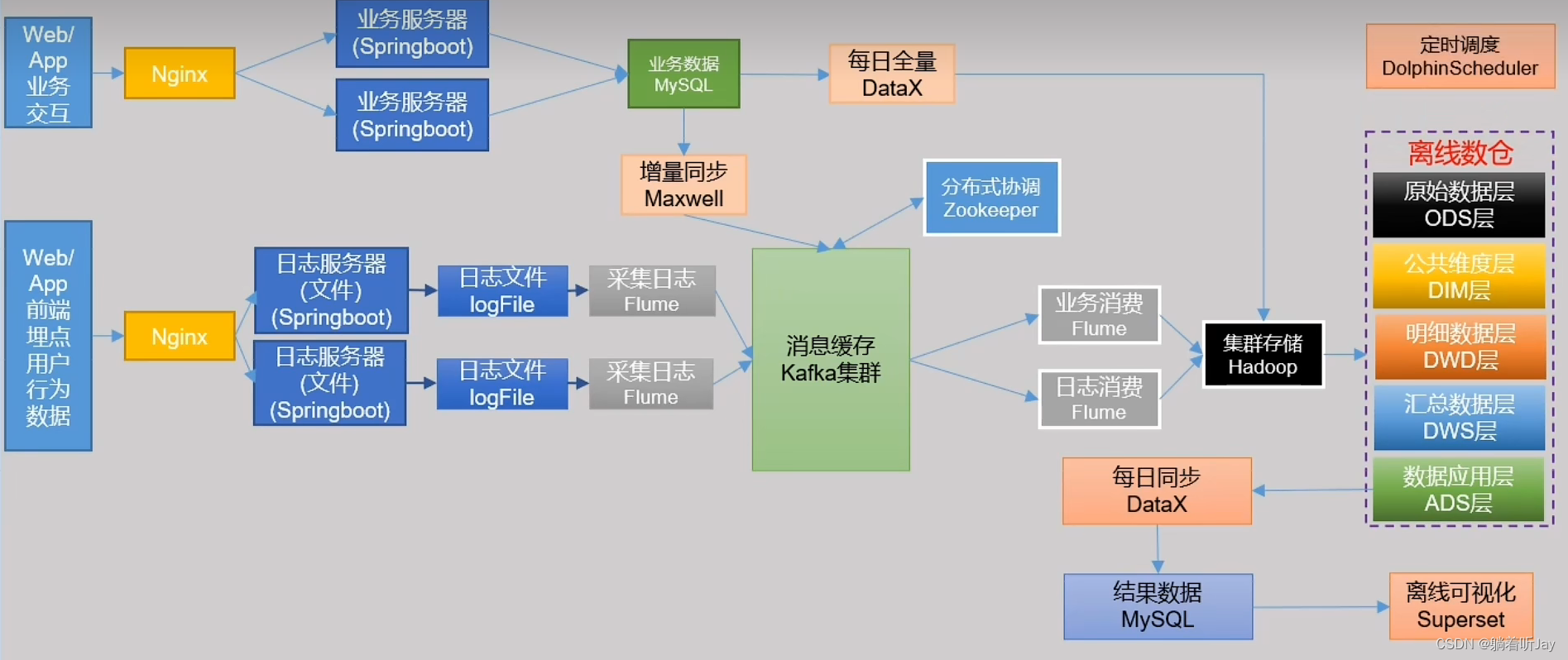
业务数据存储在MySQL,用户行为数据存储在日志文件中。这两个数据源都要先采集进来然后进行分析计算等,因为数据量会比较大,所以采用Hadoop的HDFS存储。
业务数据在MySQL中,由于是离线数仓,所以每天进行全量同步一次数据到HDFS中即可,这边我也不知道为啥还要进行增量同步到kafka中,然后由消费者发送给HDFS存储。
日志文件由flume监控采集,又因为日志文件比较大,如果flume采集完就直接发送给HDFS效率不好,所以flume采集完先发送给kafka的主题中,接着flume消费者订阅这个主题,消费日志文件发送给HDFS存储,kafka消息队列在这起消峰的作用。
经过上面的步骤后,数据就全部来到了HDFS中供使用。数据经过ODS、DWD、DWS、ADS层层处理产生想要的结果后,数据处理经过这些层,这些层总要有先后,定时任务调度的作用就是:如果数据在ODS处理好了,就可以自动进入到下一层DWD继续处理。层层处理后的想要结果由DataX将结果每日同步到MySQL中方便进行后续的使用,比如Superset可视化展示。
实时数仓
数据源源不断的来,流式处理数据,处理时间较短。
实时数仓用来处理那些实时性高的数据。
实时数仓架构参考图
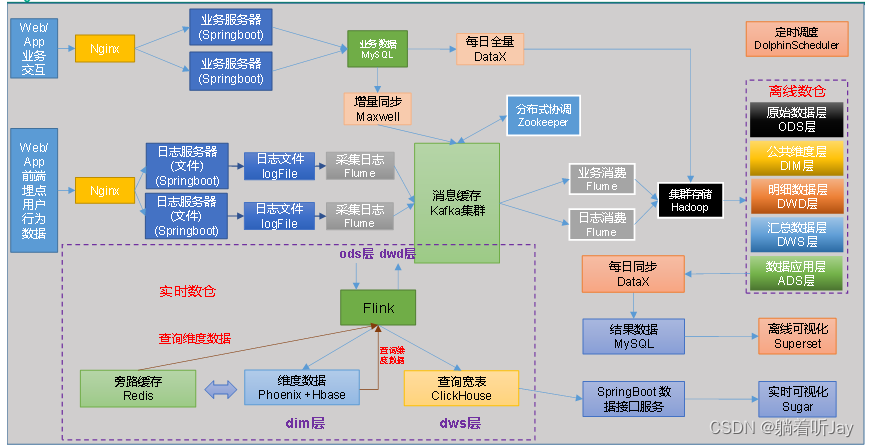
实时的话,创建flink消费者从kafka中取出数据,那我就理解了为啥业务数据也要增量同步发给kafka了,因为实时处理需要,所以kafka就是ods层,flink进行简单处理后发送给DWD层。
flume采集文件案例
以下的架构就是一个实时数仓的简单架构,flume一直监控数据文件,只要一有文件来,就会被flume采集然后发给kafka主题,接着就会被flink消费。
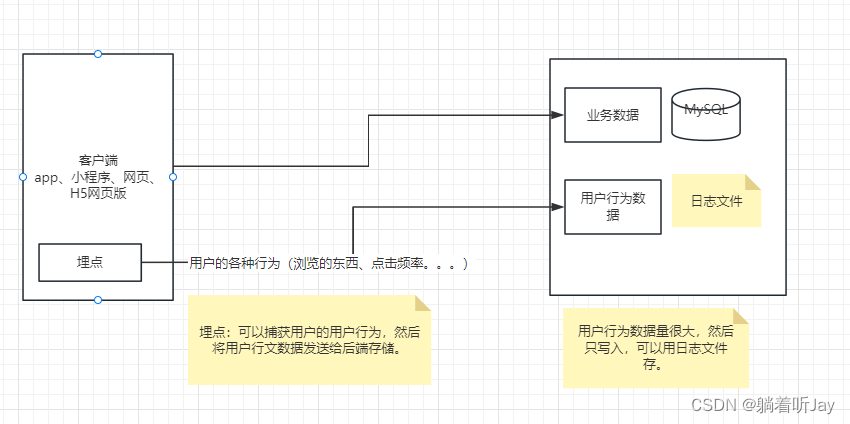
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。由于用户的行为数据比较多,所以用户行为数据通常存储在日志文件中。
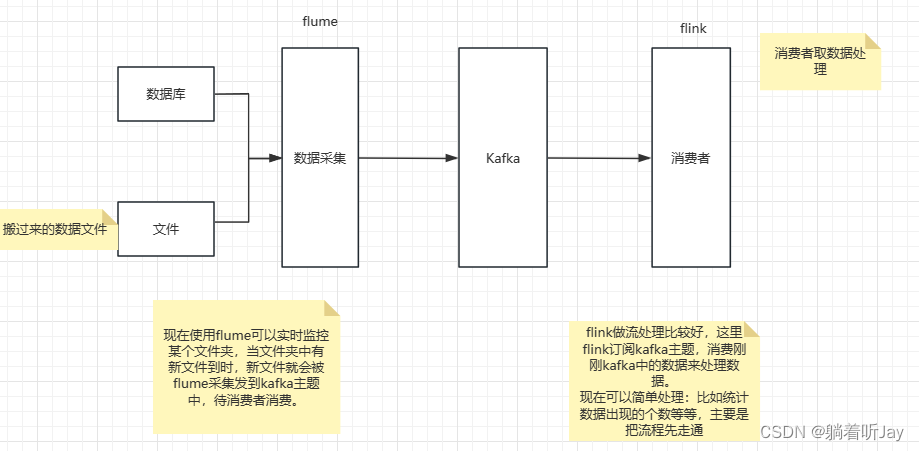 在flume的家目录中,采集一个job文件夹存放flume的配置文件,file_to_kafka.conf:
在flume的家目录中,采集一个job文件夹存放flume的配置文件,file_to_kafka.conf:
a1.sources = r1
a1.channels = c1#配置source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /mydata/spoolingDir#配置channel org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = 192.168.10.128:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false#组装
a1.sources.r1.channels = c1
启动:
bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
bin/flume-ng:这是启动 Flume 的可执行文件。agent:指定要运行的 Flume 组件类型,这里是代理(agent)。-n a1:指定代理的名称,这里是 "a1"。-c conf/:指定配置文件的目录,Flume 会在该目录下查找配置文件。-f job/file_to_kafka.conf:指定要使用的配置文件的路径,这是 Flume 的配置文件,它描述了数据传输的配置。-Dflume.root.logger=info,console:设置 Flume 的日志级别和输出方式。在此设置中,日志级别为 "info",并将日志输出到控制台。
数仓技术选型
数据采集:如果数据是以文件形式存在可以使用flume监控采集,MySQL中的数据可以使用DataX采集
数据存储:数据量比较小可以用MySQL存储,数据量大用HDFS
数据计算:实时性要求高用flink流式处理
相关文章:

数据仓库DW-理论知识储备
数据仓库DW 数据仓库具备 采集数据、分析数据、存储数据的功能,最后得出一些有用的数据,一些目标数据来使用。 采集来自不同源的数据,然后对这些数据进行分析和计算得出一些有用的指标,提供数据决策支持。 数据的来源有ÿ…...

SpringBoot 如何优雅的停机
这里写目录标题 1 介绍2 使用2.1 开启 hook2.2 禁用 hook 3 手动指定 hook 1 介绍 SpringBoot 如果需要使用hook则需要开启spring.main.register-shutdown-hooktrue(默认为true) 如果使用kill -9则不会出发JVM的hook,kill可以正常触发hook server:port: 8080shutd…...
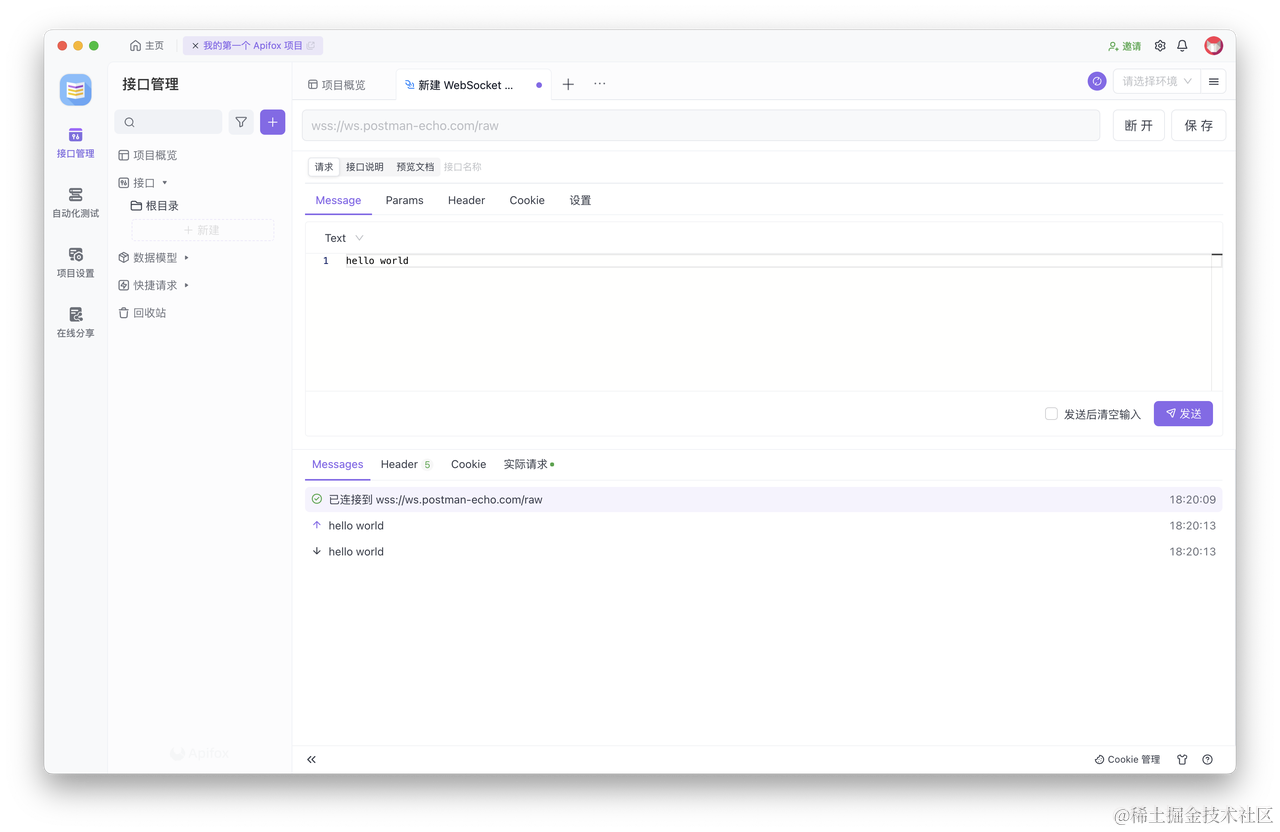
详细教程:Postman 怎么调试 WebSocket
WebSocket 是一个支持双向通信的网络协议,它在实时性和效率方面具有很大的优势。Postman 是一个流行的 API 开发工具,它提供了许多功能来测试和调试 RESTful API 接口,最新的版本也支持 WebSocket 接口的调试。想要学习更多关于 Postman 的知…...

互联网Java工程师面试题·Java 并发编程篇·第五弹
目录 52、什么是线程池? 为什么要使用它? 53、怎么检测一个线程是否拥有锁? 54、你如何在 Java 中获取线程堆栈? 55、JVM 中哪个参数是用来控制线程的栈堆栈小的? 56、Thread 类中的 yield 方法有什么作用? 57、…...

mysql与oracle分页的有什么区别
Java面试:mysql与oracle分页的有什么区别 相信许多人在日常工作中都会用到分页,比如日常查询数据量太大,而我们只需要其中的几条即可,所以这时就会去使用分页去查询,今天主要就mysql与oracle的分页进行分析。 MySQL 分…...
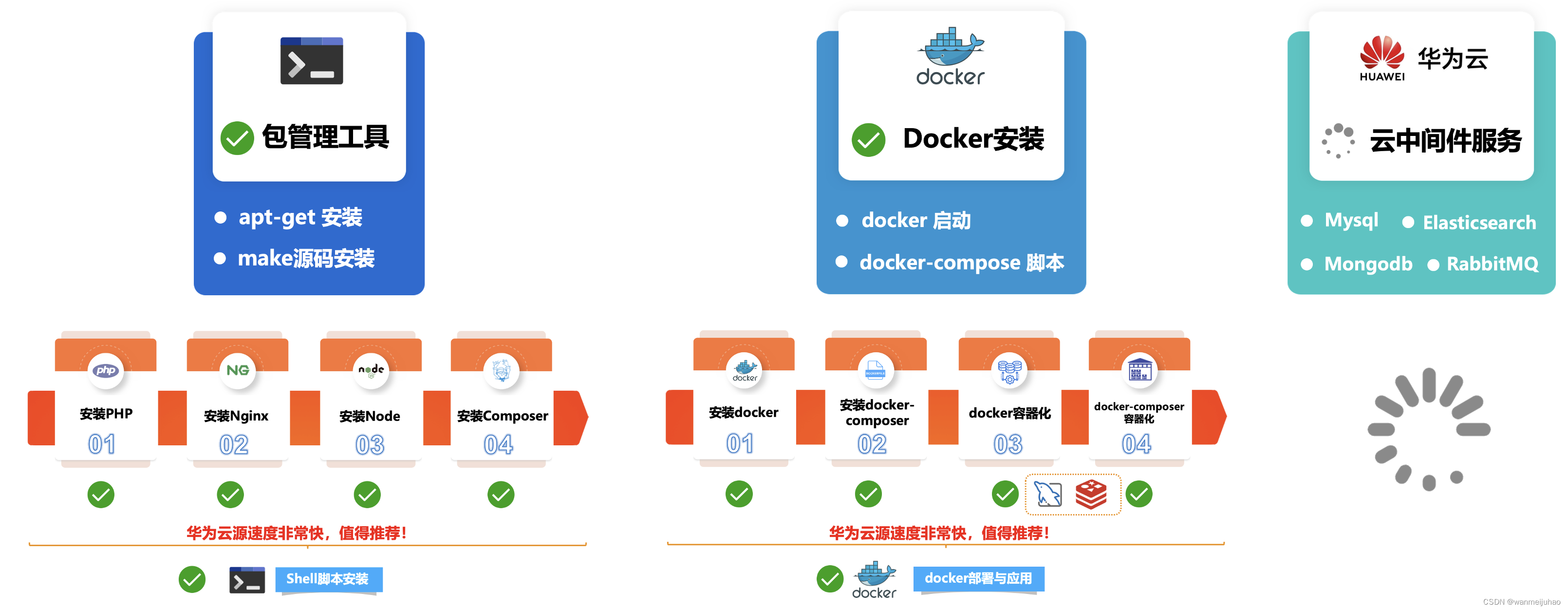
华为云云耀云服务器L实例评测|华为云耀云服务器L实例docker部署及应用(七)
八、华为云耀云服务器L实例docker、docker-compose安装及部署MySQL、Redis应用: 随着云原生、容器化、微服务、K8S等技术的发展,容器 docker 也逐渐在企业团队实践中大量的使用。它可以提供了一套标准化的解决方案,极大地提升了部署、发布、运…...
实体解析实施的复杂性
实体的艺术表现斯特凡伯克纳 一、说明 实体解析是确定数据集中的两条或多条记录是否引用同一现实世界实体(通常是个人或公司)的过程。乍一看,实体分辨率可能看起来像一个相对简单的任务:例如,给定一张人物的两张照片&a…...

MAKEFLAGS += -rR --include-dir=$(CURDIR)的含义
一、目的 在看uboot顶层Makefile文件时遇到这个代码不甚明白,故查找了一下资料以供大家学习 二、介绍 MAKEFLAGS -rR 表示禁止使用内置的隐含规则和变量定义;这个选项用于启用recursive make,使得Makefile目标可以调用其他Makefile目标&…...

maven问题与解决方案、部署
问题一、was cached in the local repository, resolution will not be reattempted until the update interval of idea中 Maven中Lifecycle时,能正常clean 和 install,但在idea的Terminal中mvn install出现: was cached in the local repo…...
【大数据】Hadoop MapReduce与Hadoop YARN(学习笔记)
一、Hadoop MapReduce介绍 1、设计构思 1)如何对付大数据处理场景 对相互间不具有计算依赖关系的大数据计算任务,实现并行最自然的办法就是采取MapReduce分而治之的策略。 不可拆分的计算任务或相互间有依赖关系的数据无法进行并行计算! …...
接口测试文档
接口测试的总结文档 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什么要做? 第二部分:主要介绍为什…...

Ubuntu中不能使用ifconfig命令
问题 打开终端使用如下命令不能运行: ifconfig显示如下错误: 解决方法 在VMware中的虚拟机下面打开“编辑虚拟机设置”,或者在已经打开的虚拟机面板上面打开“虚拟机—设置” 选择网络适配器,选择“NAT模式”,没开机的就…...

BAT020:将文本文档中多行文本拼接为;分隔的单行文本
引言:编写批处理程序,实现将文本文档中多行文本拼接为;分隔的单行文本。 一、新建Windows批处理文件 参考博客: CSDNhttps://mp.csdn.net/mp_blog/creation/editor/132137544 二、写入批处理代码 1.右键新建的批处理文件,点击【…...

安防初识命令【学习笔记】
1、美杜莎爆破 medusa -M ssh -h 192.168.42.135 -u guest -P top1000.txt -t 8 2、passwd文件与shadow文件 root:x:0:0:root:/root:/usr/bin/zsh 用户名:密码:uid:gid:描述性信息:主目录:默认…...
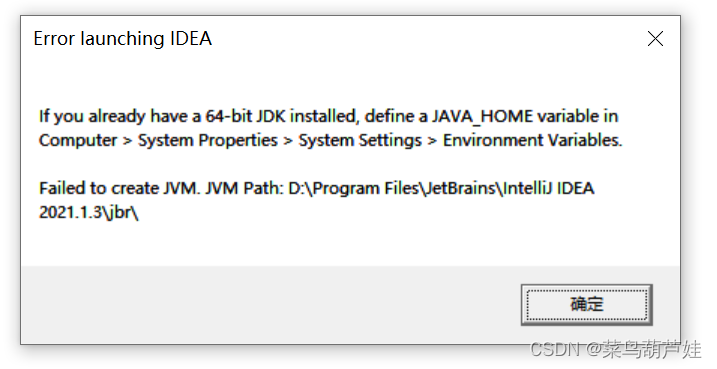
idea 启动出现 Failed to create JVM JVM Path
错误 idea 启动出现如下图情况 Error launching IDEA If you already a 64-bit JDK installed, define a JAVA_HOME variable in Computer > System Properties> System Settings > Environment Vanables. Failed to create JVM. JVM Path: D:\Program Files\JetB…...

凉鞋的 Unity 笔记 108. 第二个通识:增删改查
在这一篇,我们来学习此教程的第二个通识,即:增删改查。 增删改查我们不只是一次接触到了。 在最先接触的场景层次窗口中,我们是对 GameObject 进行增删改查。 在 Project 文件窗口中,我们是对文件&文件夹进行增删…...

angular项目指定端口,实现局域网内ip访问
直接修改package.json文件 "dev": "ng serve --host 0.0.0.0 --port 8080"终端运行npm run dev启动项目。 这里就指定了使用8080端口运行项目,同时局域网内的其他电脑可以通过访问运行项目主机的ip来访问项目 例如项目运行在ip地址为192.168.2…...
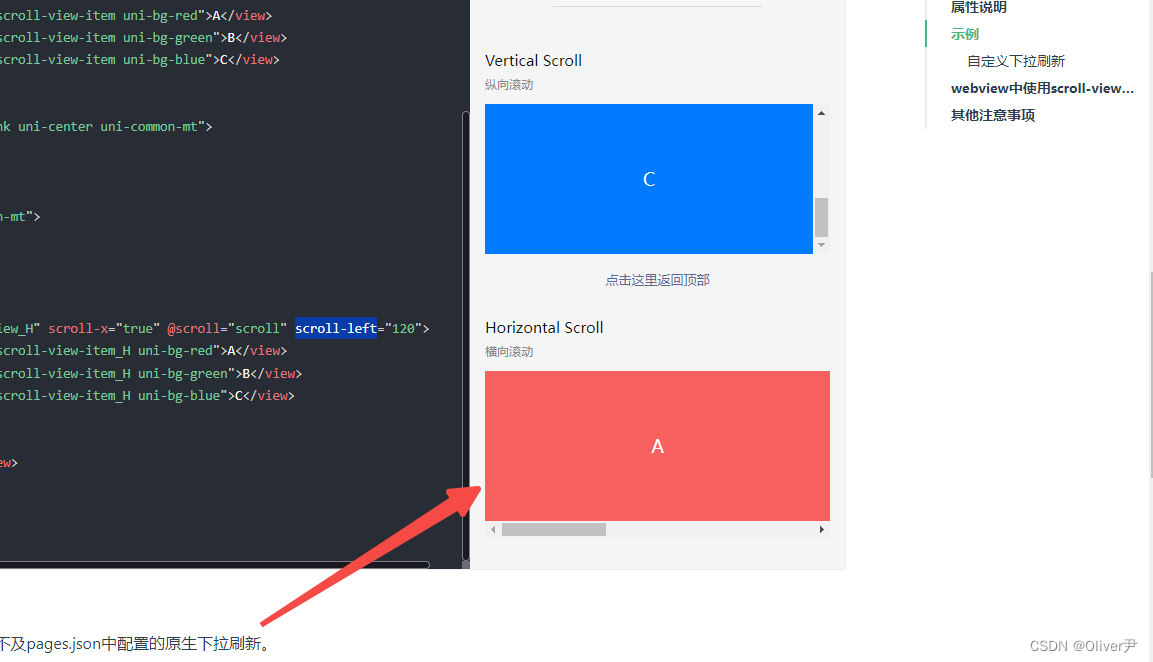
解决uniapp里scroll-view横向滚动的问题
一、前言 本以为是一件很简单的事,结果浪费了整整一个上午,并且问题并没有全部解决....后来没办法,用了touchmove模拟的滑动,如果有好的解决方法麻烦告诉我...非常感谢~ 一、问题 其实我想要实现的功能很简单,就是一…...
)
LeetCode——动态规划(五)
刷题顺序及思路来源于代码随想录,网站地址:https://programmercarl.com 目录 121. 买卖股票的最佳时机 - 力扣(LeetCode) 122. 买卖股票的最佳时机 II - 力扣(LeetCode) 123. 买卖股票的最佳时机 III …...

与HTTP相关的各种概念
网络世界 网络世界中最重要的一个名词就是互联网(Internet),它以TCP/IP协议族为基础,构建成了一望无际的信息传输网络。而我们通常所说的“上网”,主要就是访问互联网的一个子集——万维网(World Wide Web)…...

GenAI云服务事故特征与高效缓解策略解析
1. GenAI云服务事故特征与挑战 在云服务运维领域,GenAI服务因其独特的架构特性呈现出明显区别于传统云服务的事故特征。根据微软云系统的大规模实证研究数据,GenAI事故的平均缓解时间(TTM)达到1.12个时间单位,比非GenA…...

STM32篇-12.指针函数和函数指针
指针函数是什么指针函数是指返回值类型为指针的函数 比如:int* open(void) { return (an addr); }该函数返回的地址或者变量;函数指针是什么函数指针其实类似变量的指针; 比如下面:#include <stdio.h>void open(void) {prin…...

AI工作流编排框架aiflows:构建模块化、可维护的多智能体系统
1. 项目概述:当AI工作流成为团队协作的“操作系统”如果你和我一样,在过去几年里尝试过将多个大语言模型(LLM)串联起来,构建一个能处理复杂任务的智能体(Agent)或工作流,那你一定经历…...

告别‘数据孤岛’的幻想:深入拆解联邦学习Non-IID问题的根源与EMD度量
告别“数据孤岛”的幻想:联邦学习Non-IID问题的本质与实战应对 当企业兴奋地部署联邦学习系统时,常会遭遇这样的尴尬:模型在各方本地数据上表现优异,聚合后却性能骤降。这背后隐藏着一个被低估的真相——数据天然独立同分布&#…...

蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析
蓝桥杯单片机备赛:AT24C02 EEPROM存储整型数据的完整流程与常见错误分析 在蓝桥杯单片机竞赛中,AT24C02 EEPROM模块是必考内容之一。许多选手已经掌握了基本字符型数据的读写操作,但当面对整型数据时,往往会遇到各种问题。本文将深…...

【技术解析】VadCLIP:如何让视觉语言模型“看懂”视频异常?
1. VadCLIP是什么?为什么视频异常检测需要它? 想象一下你正在监控室盯着几十块屏幕,突然有个画面闪过一个可疑行为——可能是打架、偷窃或者交通事故。传统监控系统要么依赖人工盯屏(容易疲劳漏检),要么使用…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

SoC与SoM技术解析:嵌入式开发的双刃剑与选型实战
1. 项目概述:当“系统”成为商品最近几年,无论是消费电子、工业控制还是物联网设备,一个明显的趋势是:越来越多的产品不再从零开始设计核心计算单元。取而代之的,是直接采用一颗高度集成的“片上系统”,或者…...
动态加载)
PyQt5开发避坑:别再手动编译.ui文件了,试试uic.loadUi()动态加载
PyQt5高效开发:uic.loadUi()动态加载技术深度解析 在快速迭代的GUI开发过程中,PyQt5开发者常陷入一个效率陷阱——每次修改界面后都需要手动执行pyuic编译命令。这种重复性操作不仅打断开发流状态,还会在频繁调整阶段浪费大量时间。本文将揭示…...

终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁
终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS激活锁绕过是许多iPhone用户在设备所有权验证遇到困难时的迫切需求。AppleRa1n…...