pytorch中的归一化函数
在 PyTorch 的 nn 模块中,有一些常见的归一化函数,用于在深度学习模型中进行数据的标准化和归一化。以下是一些常见的归一化函数:
-
nn.BatchNorm1d,nn.BatchNorm2d,nn.BatchNorm3d:
这些函数用于批量归一化 (Batch Normalization) 操作。它们可以应用于一维、二维和三维数据,通常用于卷积神经网络中。批量归一化有助于加速训练过程,提高模型的稳定性。 -
nn.LayerNorm:
Layer Normalization 是一种归一化方法,通常用于自然语言处理任务中。它对每个样本的每个特征进行归一化,而不是对整个批次进行归一化。nn.LayerNorm可用于一维数据。 -
nn.InstanceNorm1d,nn.InstanceNorm2d,nn.InstanceNorm3d:
Instance Normalization 也是一种归一化方法,通常用于图像处理任务中。它对每个样本的每个通道进行归一化,而不是对整个批次进行归一化。这些函数分别适用于一维、二维和三维数据。 -
nn.GroupNorm:
Group Normalization 是一种介于批量归一化和 Instance Normalization 之间的方法。它将通道分成多个组,然后对每个组进行归一化。这个函数可以用于一维、二维和三维数据。 -
nn.SyncBatchNorm:
SyncBatchNorm 是一种用于分布式训练的归一化方法,它扩展了 Batch Normalization 并支持多 GPU 训练。
这些归一化函数可以根据具体的任务和模型选择使用,以帮助模型更快地收敛,提高训练稳定性,并改善模型的泛化性能。选择哪种归一化方法通常取决于数据的特点和任务的需求。在使用时,可以在 PyTorch 的模型定义中包含这些归一化层,以将它们集成到模型中。
本文主要包括以下内容:
- 1.归一化函数的函数构成
- (1)nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
- (2)nn.LayerNorm
- (3)nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d
- (4) nn.GroupNorm
- (5)nn.SyncBatchNorm
- 2.归一化函数的用法
- (1)nn.BatchNorm1d`, `nn.BatchNorm2d`, `nn.BatchNorm3d
- (2)nn.LayerNorm
- (3)nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d
- (4)nn.GroupNorm
- (5)nn.SyncBatchNorm
- 3.归一化函数在神经网络中的应用示例
- (1)Batch Normalization (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d)
- (2) Layer Normalization (nn.LayerNorm)
- (3)Instance Normalization (nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d)
1.归一化函数的函数构成
PyTorch中的归一化函数都是通过nn模块中的不同类来实现的。这些类都是继承自PyTorch的nn.Module类,它们具有共同的构造函数和一些通用的方法,同时也包括了归一化特定的计算。以下是这些归一化函数的一般函数构成:
(1)nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
构造函数:
nn.BatchNorm*d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
*:1,2,3num_features:输入数据的通道数或特征数。eps:防止除以零的小值。momentum:用于计算运行时统计信息的动量。affine:一个布尔值,表示是否应用仿射变换。track_running_stats:一个布尔值,表示是否跟踪运行时的统计信息。
(2)nn.LayerNorm
构造函数:
nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
normalized_shape:输入数据的形状,通常是一个整数或元组。eps:防止除以零的小值。elementwise_affine:一个布尔值,表示是否应用元素级别的仿射变换。
(3)nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d
构造函数:
nn.InstanceNorm*d(num_features, eps=1e-05, affine=False, track_running_stats=False)
*:1,2,3num_features:输入数据的通道数或特征数。eps:防止除以零的小值。affine:一个布尔值,表示是否应用仿射变换。track_running_stats:一个布尔值,表示是否跟踪运行时的统计信息。
(4) nn.GroupNorm
构造函数:
nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
num_groups:将通道分成的组数。num_channels:输入数据的通道数。eps:防止除以零的小值。affine:一个布尔值,表示是否应用仿射变换。
(5)nn.SyncBatchNorm
- 这个归一化函数通常在分布式训练中使用,它与
nn.BatchNorm*d具有相似的构造函数,但还支持分布式计算。
这些归一化函数的构造函数参数可能会有所不同,但它们都提供了一种方便的方式来创建不同类型的归一化层,以用于深度学习模型中。一旦创建了这些层,您可以将它们添加到模型中,然后通过前向传播计算归一化的输出。
2.归一化函数的用法
这些函数都是 PyTorch 中用于规范化(Normalization)的函数,它们用于在深度学习中处理输入数据以提高训练稳定性和模型性能。
(1)nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
这是批标准化(Batch Normalization)的函数,用于规范化输入数据。它在训练深度神经网络时有助于加速收敛,提高稳定性。
import torch
import torch.nn as nn# 以二维输入为例(2D图像数据)
input_data = torch.randn(4, 3, 32, 32) # 假设有4个样本,每个样本是3通道的32x32图像# 创建 Batch Normalization 层
batch_norm = nn.BatchNorm2d(3)# 对输入数据进行规范化
output = batch_norm(input_data)
(2)nn.LayerNorm
层标准化(Layer Normalization)通常用于自然语言处理(NLP)中,用于规范化神经网络中的层级数据。
import torch
import torch.nn as nn# 以二维输入为例
input_data = torch.randn(4, 3) # 假设有4个样本,每个样本有3个特征# 创建 Layer Normalization 层
layer_norm = nn.LayerNorm(3)# 对输入数据进行规范化
output = layer_norm(input_data)
(3)nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d
实例标准化(Instance Normalization)通常用于风格迁移等任务,逐样本规范化数据。
import torch
import torch.nn as nn# 以二维输入为例
input_data = torch.randn(4, 3, 32, 32) # 假设有4个样本,每个样本是3通道的32x32图像# 创建 Instance Normalization 层
instance_norm = nn.InstanceNorm2d(3)# 对输入数据进行规范化
output = instance_norm(input_data)
(4)nn.GroupNorm
分组标准化(Group Normalization)是一种替代 Batch Normalization 的规范化方法,它将通道分成多个组,并在每个组内进行规范化。
import torch
import torch.nn as nn# 以二维输入为例
input_data = torch.randn(4, 6, 32, 32) # 假设有4个样本,每个样本有6个通道的32x32图像# 创建 Group Normalization 层
group_norm = nn.GroupNorm(3, 6)# 对输入数据进行规范化
output = group_norm(input_data)
(5)nn.SyncBatchNorm
同步批标准化(SyncBatchNorm)是一种多 GPU 训练时用于保持 Batch Normalization 的统计一致性的方法。
import torch
import torch.nn as nn# 以二维输入为例
input_data = torch.randn(4, 3, 32, 32) # 假设有4个样本,每个样本是3通道的32x32图像# 创建 SyncBatchNorm 层
sync_batch_norm = nn.SyncBatchNorm(3)# 对输入数据进行规范化
output = sync_batch_norm(input_data)
这些规范化方法可以在神经网络中用于处理不同类型的数据和任务,以提高训练和收敛的稳定性。我们可以根据具体任务和模型需求选择合适的规范化方法。
3.归一化函数在神经网络中的应用示例
当使用 PyTorch 中的不同归一化函数时,您通常会首先创建一个归一化层实例,然后将其添加到您的神经网络模型中。以下是一些不同类型的归一化函数的示例用法:
(1)Batch Normalization (nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d)
Batch Normalization 用于对输入数据进行批量归一化。以下是一个示例,演示如何在一个卷积神经网络中使用 Batch Normalization:
import torch
import torch.nn as nn# 定义一个简单的卷积神经网络
class CNNWithBatchNorm(nn.Module):def __init__(self):super(CNNWithBatchNorm, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.fc = nn.Linear(64 * 16 * 16, 10)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 64 * 16 * 16)x = self.fc(x)return x# 创建模型实例
model = CNNWithBatchNorm()# 将模型添加到优化器等代码中进行训练
(2) Layer Normalization (nn.LayerNorm)
Layer Normalization 通常用于自然语言处理任务。以下是一个示例,演示如何在一个循环神经网络中使用 Layer Normalization:
import torch
import torch.nn as nn# 定义一个简单的循环神经网络
class RNNWithLayerNorm(nn.Module):def __init__(self, input_size, hidden_size):super(RNNWithLayerNorm, self).__init__()self.rnn = nn.LSTM(input_size, hidden_size, num_layers=2)self.ln = nn.LayerNorm(hidden_size)self.fc = nn.Linear(hidden_size, 10)def forward(self, x):x, _ = self.rnn(x)x = self.ln(x)x = self.fc(x[-1]) # 取最后一个时间步的输出return x# 创建模型实例
model = RNNWithLayerNorm(input_size=100, hidden_size=128)# 将模型添加到优化器等代码中进行训练
(3)Instance Normalization (nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d)
Instance Normalization 通常用于图像处理任务。以下是一个示例,演示如何在一个卷积神经网络中使用 Instance Normalization:
import torch
import torch.nn as nn# 定义一个简单的卷积神经网络
class CNNWithInstanceNorm(nn.Module):def __init__(self):super(CNNWithInstanceNorm, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)self.in1 = nn.InstanceNorm2d(64)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.fc = nn.Linear(64 * 16 * 16, 10)def forward(self, x):x = self.conv1(x)x = self.in1(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 64 * 16 * 16)x = self.fc(x)return x# 创建模型实例
model = CNNWithInstanceNorm()# 将模型添加到优化器等代码中进行训练
nn.SyncBatchNorm。nn.SyncBatchNorm是在多GPU分布式训练环境中使用的同步批标准化方法,用于确保不同GPU上的批标准化参数保持同步,不再举例。
这些示例演示了如何在不同类型的神经网络中使用不同的归一化函数,具体用法可以根据任务和模型的需求进行调整。不同的归一化函数适用于不同的场景,可帮助加速训练过程,提高模型的稳定性,并改善模型的泛化性能。
相关文章:

pytorch中的归一化函数
在 PyTorch 的 nn 模块中,有一些常见的归一化函数,用于在深度学习模型中进行数据的标准化和归一化。以下是一些常见的归一化函数: nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d: 这些函数用于批量归一化 (Batch Normalization…...

【管理运筹学】第 10 章 | 排队论(1,排队论的基本概念)
文章目录 引言一、基本概念1.1 排队过程1.2 排队系统的组成和特征1.3 排队模型的分类1.4 系统指标1.5 系统状态 引言 开一点排队论的内容吧,方便做题。 排队论(Queuing Theory)也称随机服务系统理论,是为解决一系列排队问题&…...

【Express】服务端渲染(模板引擎 EJS)
EJS(Embedded JavaScript)是一款流行的模板引擎,可以用于在Express中创建动态的HTML页面。它允许在HTML模板中嵌入JavaScript代码,并且能够生成基于数据的动态内容。 下面是一个详细的讲解和示例,演示如何在Express中…...

Linux CentOS8安装gitlab_ce步骤
1 下载安装包 wget --content-disposition https://packages.gitlab.com/gitlab/gitlab-ce/packages/el/8/gitlab-ce-15.0.2-ce.0.el8.x86_64.rpm/download.rpm2 安装gitlab yum install policycoreutils-python-utilsrpm -Uvh gitlab-ce-15.0.2-ce.0.el8.x86_64.rpm3 更新配…...
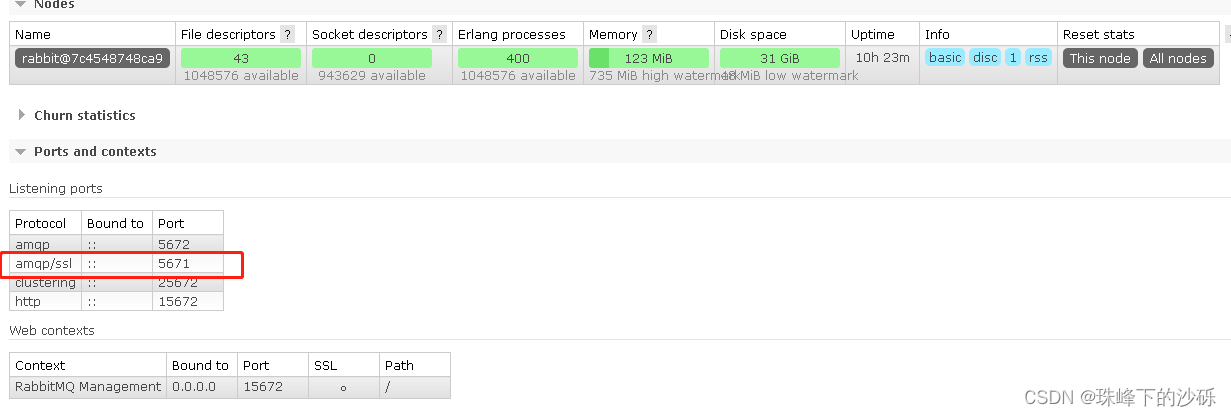
RabbitMq启用TLS
Windows环境 查看配置文件的位置 选择使用的节点 查看当前节点配置文件的配置 配置TLS 将证书放到同配置相同目录中 编辑配置文件添加TLS相关配置 [{ssl, [{versions, [tlsv1.2]}]},{rabbit, [{ssl_listeners, [5671]},{ssl_options, [{cacertfile,"C:/Users/17126…...
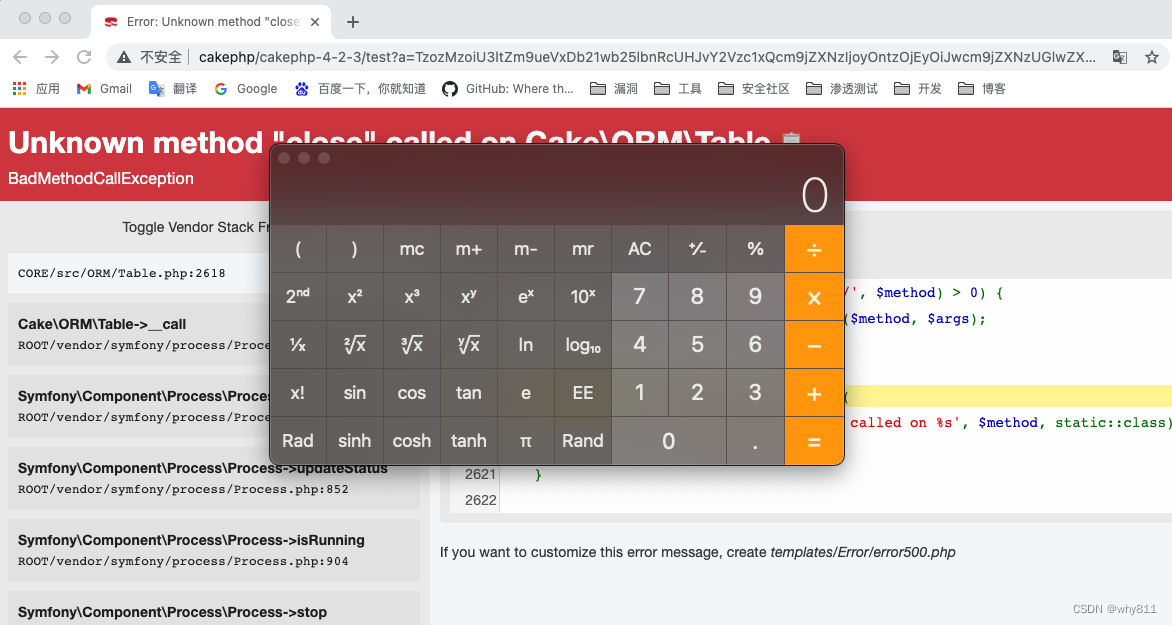
CakePHP 3.x/4.x反序列化RCE链
最近网上公开了cakephp一些反序列化链的细节,但是没有公开poc,并且网上关于cakephp的反序列化链比较少,于是自己跟一下 ,构造pop链。 CakePHP简介 CakePHP是一个运用了诸如ActiveRecord、Association Data Mapping、Front Contr…...

练习之C++[3]
文章目录 1.模板类2.模板声明3.string类 1.模板类 模板可以具有非类型参数,用于指定大小,可以根据指定的大小创建动态结构所以可用来创建动态增长和减小的数据结构模板运行时不检查数据类型,也不保证类型安全,相当于类型的宏替换…...

[MT8766][Android12] 修改WIFI热点默认名称、密码、IP地址以及默认开启热点
文章目录 开发平台基本信息问题描述解决方法 开发平台基本信息 芯片: MTK8766 版本: Android 12 kernel: msm-4.19 问题描述 最近做了一款没有屏幕显示的智能盒子,要想操控这款设备就只能通过adb投屏,如果默认不允许有线连接,那么要怎么实…...
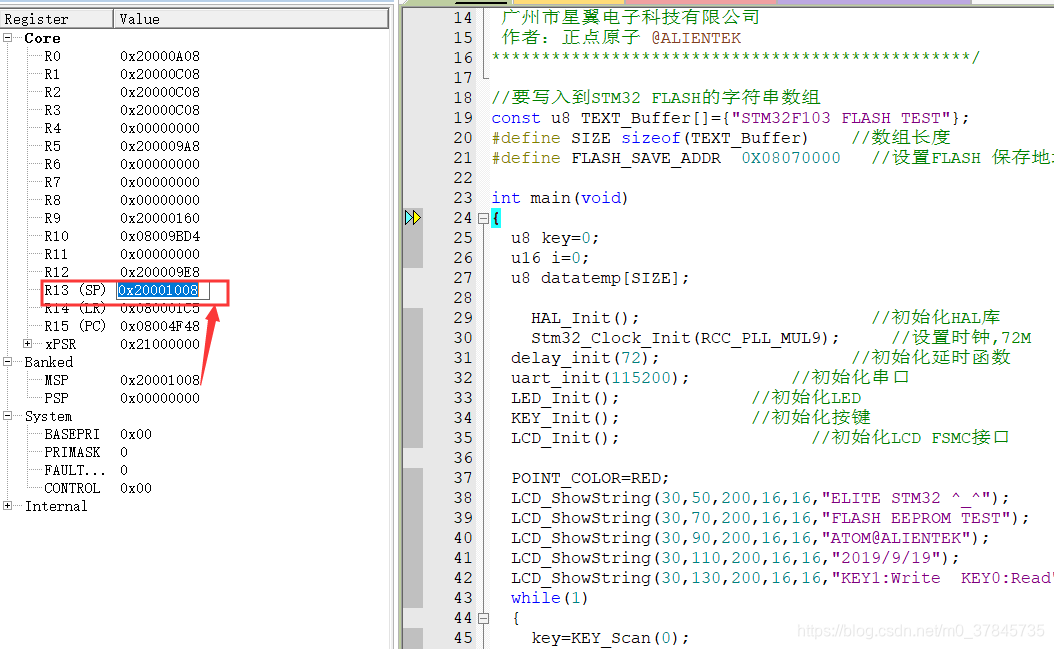
【嵌入式】堆栈与单片机内存
堆栈 在片内RAM中,常常要指定一个专门的区域来存放某些特别的数据 它遵循顺序存取和后进先出(LIFO/FILO)的原则,这个RAM区叫堆栈。 其实堆栈就是单片机中的一些存储单元,这些存储单元被指定保存一些特殊信息,比如地址࿰…...

十大排序算法Java实现及时间复杂度
文章目录 十大排序算法选择排序冒泡排序插入排序希尔排序快速排序归并排序堆排序计数排序基数排序桶排序时间复杂度 参考资料 十大排序算法 选择排序 原理 从待排序的数据元素中找出最小或最大的一个元素,存放在序列的起始位置, 然后再从剩余的未排序元…...

[Go]配置国内镜像源
配置 Windows 选一个 go env -w GOPROXYhttps://goproxy.cn,direct go env -w GOPROXYhttps://mirrors.aliyun.com/goproxy,direct查看环境配置 go env...

Java知识点补充
静态方法 vs 实例方法: 静态方法(使用 static 关键字声明):属于类,不依赖于对象实例,可以通过类名直接调用。 实例方法(不使用 static 关键字声明):属于类的实例…...
Webpack和JShaman相比有什么不同?
Webpack和JShaman相比有什么不同? Webpack的功能是打包,可以将多个JS文件打包成一个JS文件。 JShaman专门用于对JS代码混淆加密,目的是让JavaScript代码变的不可读、混淆功能逻辑、加密代码中的隐秘数据或字符,是用于代码保护的…...
WEB应用程序编程接口API
使用Web API Web API是网站的一部分,用于与使用具体URL请求特定信息的程序交互。这种请求称为API调用。请求的数据格式以易于处理的格式(JSON,CSV)返回。 Git和GitHub Git是一个分布式版本控制系统,帮助人们管理为项目所做的工作…...

进阶JAVA篇- BigDecimal 类的常用API(四)
目录 API 1.0 BigDecimal 类说明 1.1 为什么浮点数会计算不精确呢? 1.2 如何创建 BigDecimal 类型的对象 1.2.1具体来介绍三种方式来创建: 1.2.2 结合三种创建方法,一起来分析一下。 1.3 BigDecimal 类中的 valueOf(Strin…...
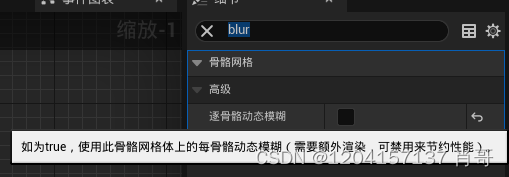
UE4 顶点网格动画播放后渲染模糊问题
问题描述:ABC格式的顶点网格动画播放结束后,改模型看起来显得很模糊有抖动的样子 解决办法:关闭逐骨骼动态模糊...

centos 磁盘挂载与解挂
磁盘挂载 查看已挂载的磁盘 df -TH查看磁盘分区,对比第一步,看哪些磁盘没有挂载,例如发现/dev/sdb的磁盘没有在第一步中显示 fdisk -l磁盘分区(/dev/sdb为上一步骤中没有挂载的磁盘) fdisk /dev/sdb执行上一命令后…...

C语言 位操作
定义 位操作提高程序运行效率,减少除法和取模的运算。在计算机程序中,数据的位是可以操作的最小数据单位,理论上可以用“位运算”来完成所有的运算和操作。 左移 后空缺自动补0 右移 分为逻辑右移和算数右移 逻辑右移 不管什么类型&am…...

Go语言中入门Hello World以及IDE介绍
您可以阅读Golang教程第1部分:Go语言介绍与安装 来了解什么是golang以及如何安装golang。 Go语言已经安装好了,当你开始学习Go语言时,编写一个"Hello, World!"程序是一个很好的入门点。 下面将会提供了一些有关IDE和在线编辑器的…...
)
Java面试题-Java核心基础-第二天(基本语法)
目录 一、注释有几种形式 二、标识符与关键字的区别 三、自增自减运算符 四、移位运算符 五、continue、break、return的区别 一、注释有几种形式 注释除了有其他编程语言有的单行注释和多行注释之外,还有其Java特有的文档注释 文档注释能够使用javadoc命令就…...
)
200块搞定AI视觉项目:手把手教你用Canmv K210训练识别模型(附完整代码)
200元打造AI视觉神器:Canmv K210从模型训练到落地实战指南 在AI技术快速普及的今天,动辄数千元的开发套件让许多创客和学生望而却步。Canmv K210开发板的出现彻底改变了这一局面——仅需200元预算,就能搭建完整的AI视觉识别系统。本文将带你从…...

编写程序统计职场上下级沟通频率,工作执行效果数据,搭建高效沟通模式,减少指令传达偏差工作失误。
构建一个职场上下级沟通频率与工作执行效果分析的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在任何组织中,上下级沟通质量直接决定执行效率:- 上级布置任务 → 下级理解并执行 → 反馈结…...

百度文心大模型如何通过Taotoken实现稳定API调用与成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心大模型如何通过Taotoken实现稳定API调用与成本控制 对于希望集成百度文心大模型进行内容生成的企业开发者而言,…...

终极指南:如何使用FlicFlac快速完成Windows音频格式转换
终极指南:如何使用FlicFlac快速完成Windows音频格式转换 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在Windows平台上处理音频文件时&…...

如何在5分钟内掌握Illustrator智能填充神器Fillinger
如何在5分钟内掌握Illustrator智能填充神器Fillinger 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为复杂的图案填充耗费数小时吗?今天我要为你介绍一款能彻底改变…...

【AI Agent软件直控革命】:20年架构师亲授5大落地陷阱与3步安全接入法
更多请点击: https://intelliparadigm.com 第一章:AI Agent软件直控革命:从概念到产业拐点 AI Agent 已不再停留于对话式助手或任务调度器的初级形态,正加速演进为具备环境感知、自主决策与系统级直控能力的“数字执行体”。其核…...
)
深入电机FOC内核:为什么`id=0`控制是能效与性能的黄金法则?(从方程到代码实现)
深入电机FOC内核:为什么id0控制是能效与性能的黄金法则? 在永磁同步电机(PMSM)的矢量控制领域,id0控制策略如同一位低调的幕后英雄。它不像那些复杂的算法那样引人注目,却在无数工业应用中默默发挥着关键作…...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...