机器学习 Q-Learning
对马尔可夫奖励的理解
看的这个教程
- 公式:V(s) = R(s) + γ * V(s’)
V(s) 代表当前状态 s 的价值。
R(s) 代表从状态 s 到下一个状态 s’ 执行某个动作后所获得的即时奖励。
γ 是折扣因子,它表示未来奖励的重要性,通常取值在 0 到 1 之间。
V(s’) 代表下一个状态 s’ 的价值。 - 理解

- 如果折扣因子γ为1,那么从现在开始,一直到结束,所有的即时奖励加在一起就是当前状态的价值。所以,现在的价值是以后的所有即时奖励决定的。但是,实际中,γ是0到1的一个小数。就是说,相同的动作,离现在越远,带来的收益越小。还有,我发现,终点是没有价值的,或者他的价值对于算法没有帮助,只是终点前一步到终点这个动作,或者状态转移产生了一个大的奖励。不知道对不对。请大家提出意见。
- 假设我们把所有的状态价值放在一个shape为(16,4)的表格里,我们把它称为Q表。16代表16个格子,4代表每一个动作。(数字是16,4是因为图片有16个格子,每个格子都能执行四个动作,这里只是举个简单的例子,你有多少种状态和有几个动作都没有关系,可以随便改,只要合理)。初始值都为0。就是说当前所有位置的所有动作的价值都为0。
- 在这个格子里,我们的目的是走到终点。规则是,每次任意方向走一步,走到终点胜利,走到陷阱,就失败。胜利与失败就结束游戏。胜利,这次游戏的一分,失败则是得-100分。每走一步扣一分。
- 要知道,Q表的所有格子初始值为0,是不符合现实的,那么,怎么把值逐步更改为现实中对应的值呢?
- 假设,我们走对了一次,倒数第二个格子,在向终点方向的那个动作就有了价值(不是0了,而且大于0)。
- 假设,我们走错了一次,那么走错的倒数第二个格子,向陷阱走的那个动作就有了价值,(不是0,并且小于0)。这样打完一局游戏,不论走对还是走错,都会产生1个有价值的格子。如果这个格子不是起点,那就肯定还有倒数第三个格子,根据公式,倒数第三个格子的那个方向价值也能算出来。如果倒数第三个格子不是起点…就这样,一点一点的“辐射”。所有的,走过的格子都有了价值。
- 假如走到了一个格子,我们只要查Q表,就能知道,往哪里走比较安全,能通向终点,往哪里走比较危险,会掉进陷阱。所以Q表会指引我们,走向正确的道路,避开危险的道路。
- 算法成立的前提是,有过走成功的经历,这样才会把最终的那个奖励,“扩散”到起点。
- 实际上,我们不是直接从终点扩散的,而是直接采样足够多的样本,一点点更新Q表。比如,我们采样到一步数据,拿Q表查询当前状态的当前动作的价值(V(s) )计作A,还有查询下一个状态的价值(V(s’))计作B。再拿到这一步的奖励R(s)计作R,假设折扣是0.9,那么A = R+0.9*B 。看到没有,是未来的价值决定现在的价值。如果Q表是正确的,这个等式就成立,但是我们会发现有误差,所以,我们得计算出误差(等式右边减去左边),误差 = (R+0.9*B - A)0.1,0.1是学习率,再拿这个误差更新A,就是Q表中,当前的状态这个动作的价值。这样,Q表就会距离理想中的绝对正确的Q表更进一步了。至于为什么有学习率,我的理解是,R+0.9*B这个东西也是估算出来的,不是真正的值,(但是按道理他是和奖励R决定A的),所以只取用他的影响*,不取用他真正的值。**(大家可以谈谈自己的看法,本人能力尚浅)**什么是影响,我也不清楚,可能在这个领域有他的名字,只是我不知道,或者没有察觉出是哪个概念。
关于陷阱的作用

- 加入把打叉的都变成陷阱,那么,我们就会更快的到达终点,因为走进陷阱后,Q表就不会让他再次掉进陷阱。所以说,陷阱在某种程度上,帮助我们接近终点。有不同意见,可以提出来,让大家讨论。
代码,上面的链接里有完整版。还有视频,我也是从B站找到的
- 这个代码在2023-10-11 跑成功过
- gym== 0.26.2
- python == 3.9
- ipython == 8.16.1
- ipython-genutils == 0.2.0 (不确定有没有用到)
- 用的conda(这个倒是无所谓)
import randomimport gym
import numpy as np
from IPython import displayclass NasWrapper(gym.Wrapper):def __init__(self):env = gym.make('FrozenLake-v1',render_mode='rgb_array',is_slippery=False)super(NasWrapper, self).__init__(env)self.env = envdef reset(self):state, _ = self.env.reset()return statedef step(self, action):state, reward, terminated, truncated, info = self.env.step(action)over = terminated or truncatedif not over:reward = -1# elif reward == 1:# reward = 100if over and reward == 0:reward = -100return state, reward, overdef show(self):from matplotlib import pyplot as pltplt.figure(figsize=(3, 3))plt.imshow(self.env.render())plt.show()nw = NasWrapper()
Q = np.zeros((16, 4))def play(isShow=False):data = []reword_sum = 0state = nw.reset()over = Falsewhile not over:action = Q[state].argmax()if random.random() < 0.1:action = nw.action_space.sample()next_state, reward, over = nw.step(action)reword_sum += rewarddata.append((state, action, reward, next_state, over))state = next_stateif isShow:display.clear_output(wait=True)nw.show()return data, reword_sumclass Pool():def __init__(self):self.pool = []def __len__(self):return len(self.pool)def __getitem__(self, item):return self.pool[item]def update(self):old_len = len(pool)while len(pool) - old_len < 200:self.pool.extend(play()[0])self.pool = self.pool[-10000:]# 获取一批数据样本def sample(self):return random.choice(self.pool)pool = Pool()# pool.update()def train():for epoch in range(100):pool.update()for i in range(100):state, action, reward, next_state, over = pool.sample()value = Q[state, action]target = Q[next_state].max() * 0.9 + rewardupdate = (target - value) * 0.1Q[state, action] += updateif epoch % 100 == 0:print(epoch, len(pool), play()[-1])train()
print("train ok")
print(Q)
play(isShow=True)
# nw.reset()
# while True:
# inputNumber = input()
# print("---")
# nw.step(int(inputNumber))
# nw.show()相关文章:
机器学习 Q-Learning
对马尔可夫奖励的理解 看的这个教程 公式:V(s) R(s) γ * V(s’) V(s) 代表当前状态 s 的价值。 R(s) 代表从状态 s 到下一个状态 s’ 执行某个动作后所获得的即时奖励。 γ 是折扣因子,它表示未来奖励的重要性,通常取值在 0 到 1 之间。…...

产品设计心得体会 优漫动游
产品设计需要综合考虑用户需求、市场需求和技术可行性,从而设计出能够满足用户需求并具有市场竞争力的产品。以下是我在产品设计方面的心得体会: 产品设计心得体会 1.深入了解用户需求:在产品设计之前,需要进行充分的用户调研…...

前端--CSS
文章目录 CSS的介绍 引入方式 代码风格 选择器 复合选择器 (选学) 常用元素属性 背景属性 圆角矩形 Chrome 调试工具 -- 查看 CSS 属性 元素的显示模式 盒模型 弹性布局 一、CSS的介绍 层叠样式表 (Cascading Style Sheets). CSS 能够对网页中元素位置的排版进行像素级精…...
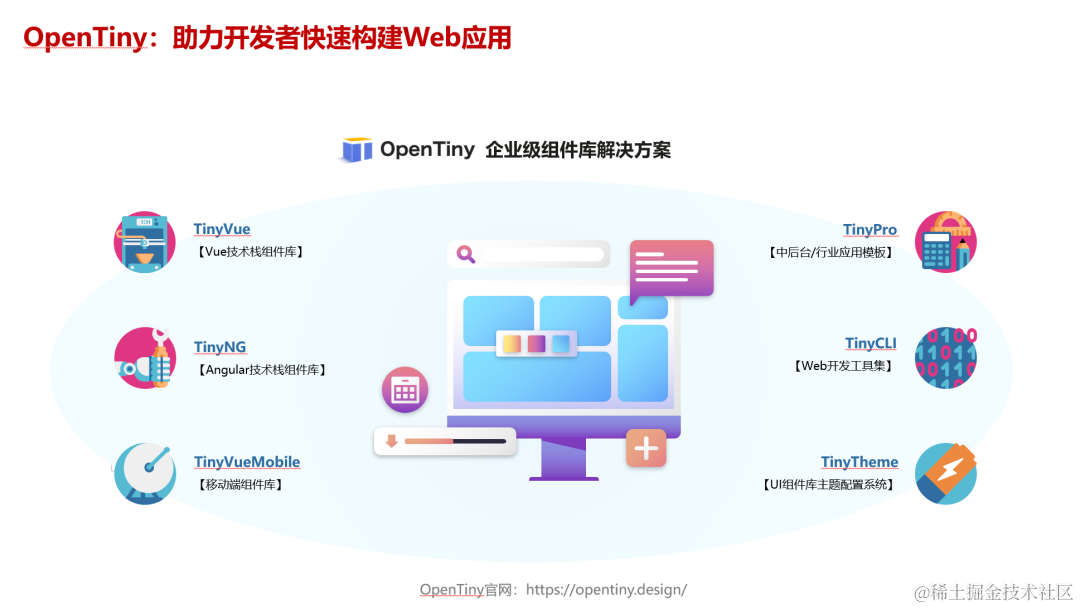
实操指南|如何用 OpenTiny Vue 组件库从 Vue 2 升级到 Vue 3
前言 根据 Vue 官网文档的说明,Vue2 的终止支持时间是 2023 年 12 月 31 日,这意味着从明年开始: Vue2 将不再更新和升级新版本,不再增加新特性,不再修复缺陷 虽然 Vue3 正式版本已经发布快3年了,但据我了…...

系统架构设计:15 论软件架构的生命周期
目录 一 软件架构的生命周期 1 需求分析阶段 2 设计阶段 3 实现阶段 4 构件组装阶段...

金山wps golang面试题总结
简单自我介绍如果多个协程并发写map 会导致什么问题如何解决(sync.map,互斥锁,信号量)chan 什么时候会发生阻塞如果 chan 缓冲区满了是阻塞还是丢弃还是panicchan 什么时候会 panic描述一下 goroutine 的调度机制goroutine 什么时…...

计算机视觉实战--直方图均衡化和自适应直方图均衡化
计算机视觉 文章目录 计算机视觉前言一、直方图均衡化1.得到灰度图2. 直方图统计3. 绘制直方图4. 直方图均衡化 二、自适应直方图均衡化1.自适应直方图均衡化(AHE)2.限制对比度自适应直方图均衡化(CRHE)3.读取图片4.自适应直方图均…...

501. 二叉搜索树中的众数
501. 二叉搜索树中的众数 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def findMode(self, root: Option…...

【Linux】常用命令
目录 文件解压缩服务器文件互传scprsync 进程资源网络curl发送简单get请求发送 POST 请求发送 JSON 数据保存响应到文件 文件 ls,打印当前目录下所有文件和目录; ls -l,打印每个文件的基本信息 pwd,查看当前目录的路径 查看文件 catless:可以左右滚动阅读more :翻…...
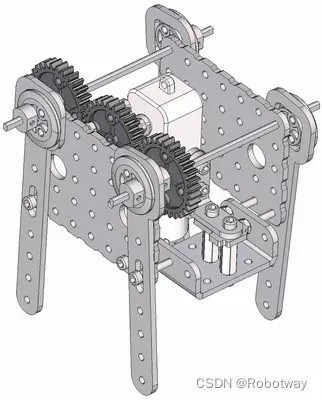
机器人制作开源方案 | 齿轮传动轴偏心轮摇杆简易四足
1. 功能描述 齿轮传动轴偏心轮摇杆简易四足机器人是一种基于齿轮传动和偏心轮摇杆原理的简易四足机器人。它的设计原理通常如下: ① 齿轮传动:通过不同大小的齿轮传动,实现机器人四条腿的运动。通常采用轮式齿轮传动或者行星齿轮传动…...
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理 第一步: 在已经安装好的tomcat的bin目录下: 输入cmd,进入命令窗口 安装服务: 输入如下命令,最后是你的服务名,避免中文和特殊字符 service.…...
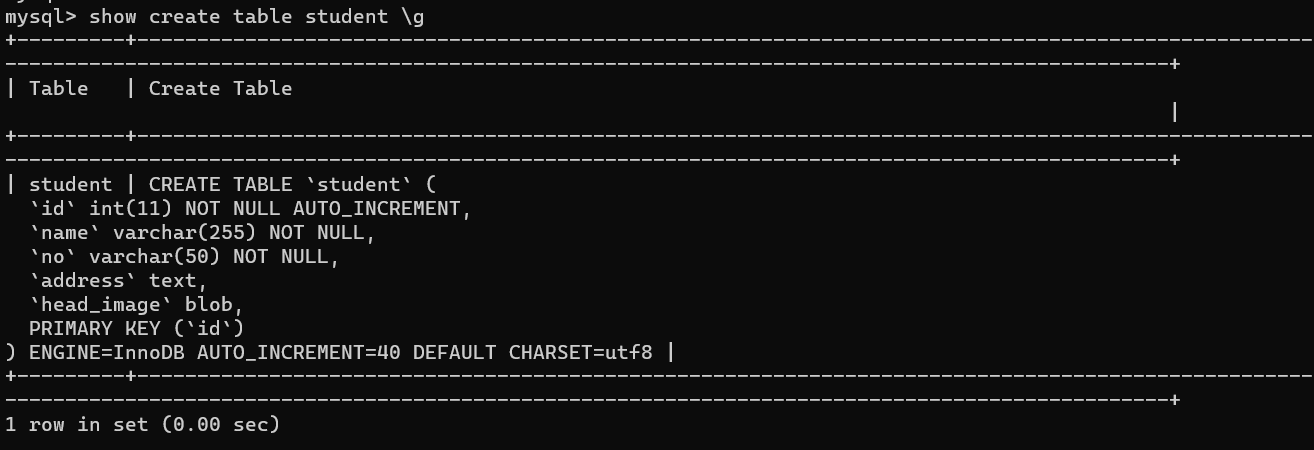
解决ERROR: No query specified的错误以及\G 和 \g 的区别
文章目录 1. 复现错误2. 分析错误3. 解决问题4. \G和\g的区别 1. 复现错误 今天使用powershell连接数据库后,执行如下SQL语句: mysql> select * from student where id 39 \G;虽然成功查询除了数据,但报出如下错误的信息: my…...

mysql中SUBSTRING_INDEX函数用法详解
MySQL中的SUBSTRING_INDEX函数用于从字符串中提取子字符串,其用法如下: SUBSTRING_INDEX(str, delim, count)参数说明: str:要提取子字符串的原始字符串。delim:分隔符,用于确定子字符串的位置。count&am…...

AndroidStudio报错:android.support.v4.app.Fragment
解决办法一 android.support.v4.app.Fragment替换为android.app.Fragment 解决办法二 有时太多,先类型过去再说。 找到gradle.properties,修改: android.useAndroidXfalse android.enableJetifierfalse...
今年这情况,还能不能选计算机了?
在知乎上看到一个有意思的问题,是劝退计算机的。 主要观点: 计算机从业人员众多加班,甚至需要99635岁危机秃头 综上所属,计算机不仅卷,而且还是一个高危职业呀,可别来干了。 关于卷 近两年确实能明显感觉…...

Elastic Cloud v.s. Zilliz Cloud:性能大比拼
Elastic Cloud v.s. Zilliz Cloud:性能大比拼 Zilliz 经常会收到来自开发者和架构师的提问:“Zilliz Cloud 和 Elastic Cloud 比起来,谁进行向量处理能力比较强?” 诸如此类的问题很多,究其根本,大都是开发者/架构师在为语义相似性检索系统进行数据库选型时缺少决策依据有…...
设计模式03———包装器模式 c#
首先我们打开一个项目 在这个初始界面我们需要做一些准备工作 创建基础通用包 创建一个Plane 重置后 缩放100倍 加一个颜色 (个人喜好)调节渐变色 可更改同种颜色的色调 (个人喜好) 调节天空盒 准备工作做完后 接下我们做【…...

《动手学深度学习 Pytorch版》 8.3 语言模型和数据集
8.3.1 学习语言模型 依靠在 8.1 节中对序列模型的分析,可以在单词级别对文本数据进行词元化。基本概率规则如下: P ( x 1 , x 2 , … , x T ) ∏ t 1 T P ( x t ∣ x 1 , … , x t − 1 ) P(x_1,x_2,\dots,x_T)\prod^T_{t1}P(x_t|x_1,\dots,x_{t-1}) …...
Linux桌面环境(桌面系统)
早期的 Linux 系统都是不带界面的,只能通过命令来管理,比如运行程序、编辑文档、删除文件等。所以,要想熟练使用 Linux,就必须记忆很多命令。 后来随着 Windows 的普及,计算机界面变得越来越漂亮,点点鼠标…...
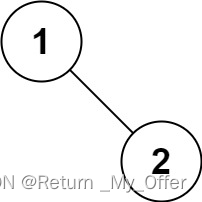
【LeetCode刷题(数据结构)】:二叉树的前序遍历
给你二叉树的根节点root 返回它节点值的前序遍历 示例1: 输入:root [1,null,2,3] 输出:[1,2,3] 示例 2: 输入:root [] 输出:[] 示例 3: 输入:root [1] 输出:[1] 示例…...

编程学习时怎么更好归纳自己的笔记
学了一个月,回头翻笔记,发现根本看不懂自己写了什么。 记了满满一本,真要查某个知识点时,翻来翻去找不到。 明明记过,用的时候大脑一片空白。这是不是你?笔记不是记过就算,而是要用得上。本文从…...

书匠策AI到底怎么帮你“生“出毕业论文?一个论文博主的拆解笔记
各位深夜还在跟Word较劲的同学们,我是那个天天教别人写论文、自己也被论文折磨过的教育博主。 今天不讲写作技巧,讲一个我自己反复用、觉得真能帮到人的工具——书匠策AI。 官网直达 官网直达:www.shujiangce.com微信搜一搜"书匠策AI…...
实战剖析:从原理到攻防演进)
模型逆向攻击(MIA)实战剖析:从原理到攻防演进
1. 模型逆向攻击(MIA)的本质与核心原理 第一次听说模型逆向攻击(Model Inversion Attack)时,我脑海中浮现的是黑客电影里那种对着键盘一通乱敲就能破解系统的场景。但真正深入研究后才发现,MIA更像是一种&q…...

如何永久保存微信聊天记录?WeChatMsg终极解决方案完全指南
如何永久保存微信聊天记录?WeChatMsg终极解决方案完全指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

告别卡顿!用这款神器轻松下载M3U8格式视频流
告别卡顿!用这款神器轻松下载M3U8格式视频流 【免费下载链接】m3u8-downloader 一个M3U8 视频下载(M3U8 downloader)工具。跨平台: 提供windows、linux、mac三大平台可执行文件,方便直接使用。 项目地址: https://gitcode.com/gh_mirrors/m3u8d/m3u8-downloader …...

MAX3421E USB主机控制器实战:为微控制器扩展USB外设连接能力
1. 项目概述:为你的微控制器打开USB主机世界的大门如果你玩过Arduino、ESP32或者树莓派Pico这类微控制器,肯定对它们的USB设备功能不陌生——插上电脑就能被识别成一个串口、一个键盘或者一个U盘。但你想过反过来吗?让你的微控制器项目变成“…...

每日大赛间歇期通过Taotoken模型广场探索新模型特性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 每日大赛间歇期通过Taotoken模型广场探索新模型特性 对于每日参与各类AI应用开发或创意大赛的选手而言,比赛间歇期并非…...

避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析
避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析 在无感FOC驱动开发中,观测器的调试往往是整个项目中最具挑战性的环节。当电机出现抖动、观测角度不准或启动失败时,如何快速定位问题并优化参数,成为工程师们必须…...
Flutter Shimmer高级用法:创建复杂的多方向闪烁效果
Flutter Shimmer高级用法:创建复杂的多方向闪烁效果 【免费下载链接】flutter_shimmer A package provides an easy way to add shimmer effect in Flutter project 项目地址: https://gitcode.com/gh_mirrors/fl/flutter_shimmer Flutter Shimmer是一款强大…...
)
保姆级教程:从NCBI下载序列到MEGA7构建进化树(附拟南芥SPL15基因实战)
生物信息学实战:从基因检索到进化树构建的全流程解析 在分子生物学研究中,系统进化分析是理解基因家族演化关系的重要工具。对于刚接触生物信息学的学生来说,从零开始完成一个完整的进化树分析项目往往面临诸多挑战——如何获取目标基因序列…...