《动手学深度学习 Pytorch版》 8.3 语言模型和数据集
8.3.1 学习语言模型
依靠在 8.1 节中对序列模型的分析,可以在单词级别对文本数据进行词元化。基本概率规则如下:
P ( x 1 , x 2 , … , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , … , x t − 1 ) P(x_1,x_2,\dots,x_T)=\prod^T_{t=1}P(x_t|x_1,\dots,x_{t-1}) P(x1,x2,…,xT)=t=1∏TP(xt∣x1,…,xt−1)
例如,包含了四个单词的一个文本序列的概率是:
P ( d e e p , l e a r n i n g , i s , f u n ) = P ( d e e p ) P ( l e a r n i n g ∣ d e e p ) P ( i s ∣ d e e p , l e a r n i n g ) P ( f u n ∣ d e e p , l e a r n i n g , i s ) P(deep,learning,is,fun)=P(deep)P(learning|deep)P(is|deep,learning)P(fun|deep,learning,is) P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is)
语言模型就是要计算单词的概率,以及给定前面几个单词后出现某个单词的条件概率。这些概率本质上就是语言模型的参数。
假设训练数据集是一个大型的文本语料库。训练数据集中词的概率可以根据给定词的相对词频来计算。对于频繁出现的单词可以统计单词“deep”在数据集中的出现次数,然后将其除以整个语料库中的单词总数。接下来尝试估计
P ^ ( l e a r n i n g ∣ d e e p ) = n ( d e e p , l e a r n i n g ) n ( d e e p ) \hat{P}(learning|deep)=\frac{n(deep,learning)}{n(deep)} P^(learning∣deep)=n(deep)n(deep,learning)
其中 n ( x ) n(x) n(x) 和 n ( x , x ′ ) n(x,x') n(x,x′) 分别是单个单词和连续单词对的出现次数。
对于一些不常见的单词组合,要想找到足够的出现次数来获得准确的估计可能都不容易。如果数据集很小,或者单词非常罕见,那么这类单词出现一次的机会可能都找不到。这里一种常见的策略是执行某种形式的拉普拉斯平滑(Laplace smoothing),具体方法是在所有计数中添加一个小常量。用 n n n 表示训练集中的单词总数,用 m m m 表示唯一单词的数量。例如通过:
P ^ ( x ) = n ( x ) + ϵ 1 / m n + ϵ 1 P ^ ( x ′ ∣ x ) = n ( x , x ′ ) + ϵ 2 P ^ ( x ′ ) n ( x ) + ϵ 2 P ^ ( x " ∣ x , x ′ ) = n ( x , x ′ , x " ) + ϵ 3 P ^ ( x " ) n ( x , x ′ ) + ϵ 3 \begin{align} \hat{P}(x)&=\frac{n(x)+\epsilon_1/m}{n+\epsilon_1}\\ \hat{P}(x'|x)&=\frac{n(x,x')+\epsilon_2\hat{P}(x')}{n(x)+\epsilon_2}\\ \hat{P}(x"|x,x')&=\frac{n(x,x',x")+\epsilon_3\hat{P}(x")}{n(x,x')+\epsilon_3} \end{align} P^(x)P^(x′∣x)P^(x"∣x,x′)=n+ϵ1n(x)+ϵ1/m=n(x)+ϵ2n(x,x′)+ϵ2P^(x′)=n(x,x′)+ϵ3n(x,x′,x")+ϵ3P^(x")
其中 ϵ 1 \epsilon_1 ϵ1, ϵ 2 \epsilon_2 ϵ2 和 ϵ 3 \epsilon_3 ϵ3 是超参数。例如当 ϵ 1 = 0 \epsilon_1=0 ϵ1=0 时,不应用平滑;当 ϵ 1 \epsilon_1 ϵ1 接近无穷大时, P ^ ( x ) \hat{P}(x) P^(x) 基金均匀概率分布 1 / m 1/m 1/m。
上述方案也存在问题,模型很容易变得无效,原因如下:
-
需要存储所有的计数;
-
完全忽略了单词的意思。例如,“猫”(cat)和“猫科动物”(feline)可能出现在相关的上下文中,但是想根据上下文调整这类模型其实是相当困难的。
-
长单词序列大部分是没出现过的,因此一个模型如果只是简单地统计先前“看到”的单词序列频率,那么模型面对这种问题肯定是表现不佳的。
8.3.2 马尔可夫模型与 n 元语法
如果 P ( x t + 1 ∣ x t , … , x 1 ) = P ( x t + 1 ∣ x t ) P(x_{t+1}|x_t,\dots,x_1)=P(x_{t+1}|x_t) P(xt+1∣xt,…,x1)=P(xt+1∣xt),则序列上的分布满足一阶马尔可夫性质。阶数越高则对应的依赖关系就越长。这种性质可以推导出许多可以应用于序列建模的近似公式:
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 2 ) P ( x 4 ∣ x 3 ) P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 4 ∣ x 2 , x 3 ) \begin{align} P(x_1,x_2,x_3,x_4)&=P(x_1)P(x_2)P(x_3)P(x_4)\\ P(x_1,x_2,x_3,x_4)&=P(x_1)P(x_2|x_1)P(x_3|x_2)P(x_4|x_3)\\ P(x_1,x_2,x_3,x_4)&=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)P(x_4|x_2,x_3) \end{align} P(x1,x2,x3,x4)P(x1,x2,x3,x4)P(x1,x2,x3,x4)=P(x1)P(x2)P(x3)P(x4)=P(x1)P(x2∣x1)P(x3∣x2)P(x4∣x3)=P(x1)P(x2∣x1)P(x3∣x1,x2)P(x4∣x2,x3)
通常,涉及一个、两个和三个变量的概率公式分别被称为一元语法(unigram)、二元语法(bigram)和三元语法(trigram)模型。
以下将对模型进行更好的设计。
8.3.3 自然语言统计
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
corpus = [token for line in tokens for token in line] # 将文本行拼接到一起
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10] # 打印前10个频率最高的单词
[('the', 2261),('i', 1267),('and', 1245),('of', 1155),('a', 816),('to', 695),('was', 552),('in', 541),('that', 443),('my', 440)]
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')

频率最高的词都是停用词(stop words),可以被过滤掉。但它们本身仍然是有意义的,我们仍然会在模型中使用它们。
此外,还有个明显的问题是词频衰减的速度相当地快。从词频图看到,词频衰减大致遵循双对数坐标图上的一条直线。这意味着单词的频率满足齐普夫定律(Zipf’s law),即第 i i i 个最常用单词的频率 n i n_i ni 为:
n i ∝ 1 i α n_i\propto\frac{1}{i^\alpha} ni∝iα1
可以等价为
log n i = − α log i + c \log{n_i}=-\alpha\log{i}+c logni=−αlogi+c
其中 α \alpha α 是刻画分布的指数, c c c 是常数。
所以,上面通过计数统计和平滑来建模单词是不可行的,因为这样建模的结果会大大高估尾部(也就是所谓的不常用单词)的频率。
下面尝试一下二元语法的频率是否与一元语法的频率表现出相同的行为方式。
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])] # 优雅 实在优雅
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
[(('of', 'the'), 309),(('in', 'the'), 169),(('i', 'had'), 130),(('i', 'was'), 112),(('and', 'the'), 109),(('the', 'time'), 102),(('it', 'was'), 99),(('to', 'the'), 85),(('as', 'i'), 78),(('of', 'a'), 73)]
可以看到二元语法大部分也是两个停用词组成的。下面的三元语法就好些。
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
[(('the', 'time', 'traveller'), 59),(('the', 'time', 'machine'), 30),(('the', 'medical', 'man'), 24),(('it', 'seemed', 'to'), 16),(('it', 'was', 'a'), 15),(('here', 'and', 'there'), 15),(('seemed', 'to', 'me'), 14),(('i', 'did', 'not'), 14),(('i', 'saw', 'the'), 13),(('i', 'began', 'to'), 13)]
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',ylabel='frequency: n(x)', xscale='log', yscale='log',legend=['unigram', 'bigram', 'trigram'])

从这张一元语法、二元语法和三元语法的直观对比图可以看到:
-
除了一元语法词,单词序列似乎也遵循齐普夫定律,指数的大小受序列长度的影响。
-
词表中 n 元组的数量并没有那么大,这说明语言中存在相当多的结构,这些结构给了我们应用模型的希望;
-
很多 n 元组很少出现,这使得拉普拉斯平滑非常不适合语言建模。作为代替,我们将使用基于深度学习的模型。
8.3.4 读取长序列数据
长序列不能被模型一次性全部处理时,依然采用第一节的拆分序列方法。不同的是,步长不选择固定的而是从随机偏移量开始划分序列,以同时获得覆盖性(coverage)和随机性(randomness)。
随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻。
def seq_data_iter_random(corpus, batch_size, num_steps): #@save"""使用随机抽样生成一个小批量子序列"""corpus = corpus[random.randint(0, num_steps - 1):] # 从头随机截一下,保证第一个序列的随机性num_subseqs = (len(corpus) - 1) // num_steps # 计算序列数initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 获取各序列起始下标random.shuffle(initial_indices) # 进行打乱def data(pos):# 返回从pos位置开始的长度为num_steps的序列return corpus[pos: pos + num_steps]num_batches = num_subseqs // batch_size # 计算组数for i in range(0, batch_size * num_batches, batch_size):# 在这里,initial_indices包含子序列的随机起始索引initial_indices_per_batch = initial_indices[i: i + batch_size] # 截取当前组各序列的启示下标X = [data(j) for j in initial_indices_per_batch] # 获取序列作为数据Y = [data(j + 1) for j in initial_indices_per_batch] # 获取下一个序列作为标签yield torch.tensor(X), torch.tensor(Y)
my_seq = list(range(35)) # 生成一个从0到34的序列
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
X: tensor([[18, 19, 20, 21, 22],[13, 14, 15, 16, 17]])
Y: tensor([[19, 20, 21, 22, 23],[14, 15, 16, 17, 18]])
X: tensor([[ 8, 9, 10, 11, 12],[ 3, 4, 5, 6, 7]])
Y: tensor([[ 9, 10, 11, 12, 13],[ 4, 5, 6, 7, 8]])
X: tensor([[23, 24, 25, 26, 27],[28, 29, 30, 31, 32]])
Y: tensor([[24, 25, 26, 27, 28],[29, 30, 31, 32, 33]])
顺序分区
在小批量的迭代过程中保留了拆分的子序列的顺序,可以保证两个相邻的小批量中的子序列在原始序列上也是相邻的。
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save"""使用顺序分区生成一个小批量子序列"""offset = random.randint(0, num_steps) # 随机首序列的起始下标num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size # 计算总词源数Xs = torch.tensor(corpus[offset: offset + num_tokens]) # 获取词元起始下标Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens]) # 获取对应的下一个词元的起始下标Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1) # 利用矩阵操作分组num_batches = Xs.shape[1] // num_steps # 计算组数for i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps] # 顺序获取各组作为数据Y = Ys[:, i: i + num_steps] # 获取下一个序列作为标签yield X, Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):print('X: ', X, '\nY:', Y)
X: tensor([[ 5, 6, 7, 8, 9],[19, 20, 21, 22, 23]])
Y: tensor([[ 6, 7, 8, 9, 10],[20, 21, 22, 23, 24]])
X: tensor([[10, 11, 12, 13, 14],[24, 25, 26, 27, 28]])
Y: tensor([[11, 12, 13, 14, 15],[25, 26, 27, 28, 29]])
将上述两个采样函数包装到一个类中,再定义一个返回数据迭代器和词表的 load 函数。
class SeqDataLoader: #@save"""加载序列数据的迭代器"""def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentialself.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, #@saveuse_random_iter=False, max_tokens=10000):"""返回时光机器数据集的迭代器和词表"""data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)return data_iter, data_iter.vocab
练习
(1)假设训练数据集中有 10 万个单词。一个四元语法需要存储多少个词频和相邻多词频率?
这应该不好说吧。
(2)我们如何对一系列对话建模?
不会,略。
(3)一元语法、二元语法和三元语法的齐普夫定律的指数是不一样的,能设法估计么?
不会,略。
(4)想一想读取长序列数据的其他方法?
固定最大长度,截取多余的部分
(5)考虑一下我们用于读取长序列的随机偏移量。
a. 为什么随机偏移量是个好主意?
b. 它真的会在文档的序列上实现完美的均匀分布吗?
c. 要怎么做才能使分布更均匀?
总比从头到尾顺着读好。
(6)如果我们希望一个序列样本是一个完整的句子,那么这在小批量抽样中会带来怎样的问题?如何解决?
不会,略。
相关文章:
《动手学深度学习 Pytorch版》 8.3 语言模型和数据集
8.3.1 学习语言模型 依靠在 8.1 节中对序列模型的分析,可以在单词级别对文本数据进行词元化。基本概率规则如下: P ( x 1 , x 2 , … , x T ) ∏ t 1 T P ( x t ∣ x 1 , … , x t − 1 ) P(x_1,x_2,\dots,x_T)\prod^T_{t1}P(x_t|x_1,\dots,x_{t-1}) …...
Linux桌面环境(桌面系统)
早期的 Linux 系统都是不带界面的,只能通过命令来管理,比如运行程序、编辑文档、删除文件等。所以,要想熟练使用 Linux,就必须记忆很多命令。 后来随着 Windows 的普及,计算机界面变得越来越漂亮,点点鼠标…...
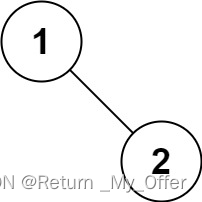
【LeetCode刷题(数据结构)】:二叉树的前序遍历
给你二叉树的根节点root 返回它节点值的前序遍历 示例1: 输入:root [1,null,2,3] 输出:[1,2,3] 示例 2: 输入:root [] 输出:[] 示例 3: 输入:root [1] 输出:[1] 示例…...

自定义Flink kafka连接器Decoding和Serialization格式
前言 使用kafka连接器时: 1.作为source端时,接受的消息报文的格式并不是kafka支持的格式,这时则需要自定义Decoding格式。 2.作为sink端时,期望发送的消息报文格式并非kafka支持的格式,这时则需要自定义Serializati…...

推荐八个大学搜题软件和学习工具哪个好用且免费,一起对比看看
以下分享的软件提供了各种实用的功能,如数学公式计算、语文阅读辅助等,让大学生们在学习过程中更加高效和便利。 1.九超查题 这是一个老公众号了,我身边的很多朋友都在用,支持超新星、学习强国、知到、智慧树和各类专业网课题目…...

SpringBoot面试题1:什么是SpringBoot?为什么要用SpringBoot?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:什么是SpringBoot? Spring Boot 是一个用于快速开发独立的、基于 Spring 框架的应用程序的开源框架。它简化了 Spring 应用的配置和部署过程,使…...

Django Test
Django--Laboratory drug management and early warning system-CSDN博客 创建项目doinglms django-admin startproject doinglms python manage.py runserver 运行开发服务器(Development Server) 创建一个自定义 App,名称为 lms: python manage.py startapp lms...

Linux- 自定义一个ARP请求
自定义一个ARP请求或响应,并使用AF_PACKET套接字发送,需要手动创建整个以太网帧。 下面是一个简单的C代码示例,用于发送一个ARP请求,查询给定IP地址的MAC地址: #include <stdio.h> #include <stdlib.h> …...

C++下载器程序:如何使用cpprestsdk库下载www.ebay.com图片
本文介绍了如何使用C语言和cpprestsdk库编写一个下载器程序,该程序可以从www.ebay.com网站上下载图片,并保存到本地文件夹中。为了避免被网站屏蔽,我们使用了亿牛云爬虫代理服务提供的代理IP地址,以及多线程技术提高下载效率。 首…...
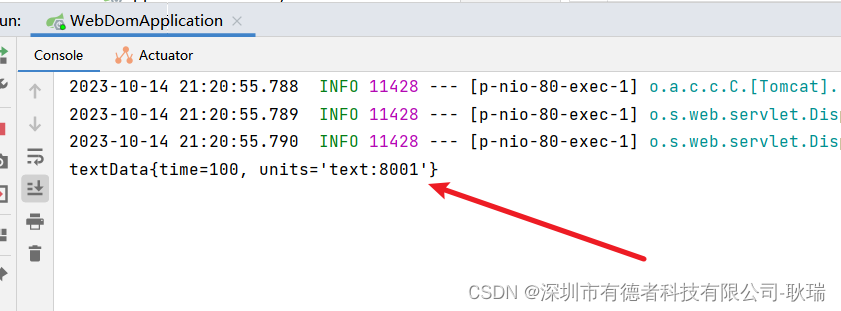
java springboot通过EnableConfigurationProperties全局声明bean并处理装配
Spring Boot中 我们想条件装配一个类 首先 我们要声明他的bean 而 EnableConfigurationProperties 可以直接将 要全局声明的类绑定在 属性类中 例如 我们随便创建一个类 就叫 textData 吧 参考代码如下 package com.example.webdom.domain;import org.springframework.boot.co…...
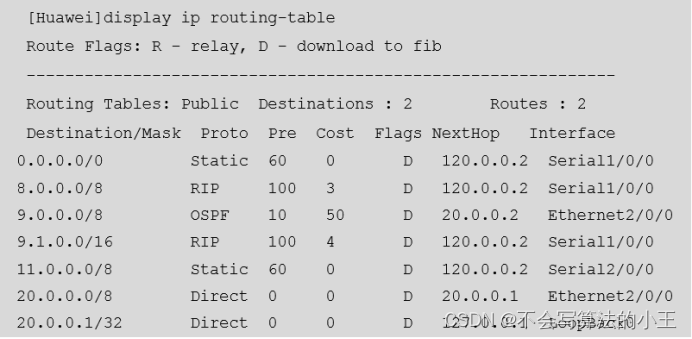
网络工程师知识点2
21、VLAN 有什么作用? ①广播控制;②安全性;③增加带宽利用率;④减少延迟。 22、实际的项目中如何划分vlan的? 采用静态VLAN的划分方式,可以按照楼层划分,可以按安装科室划分 23、vlan 的链路…...
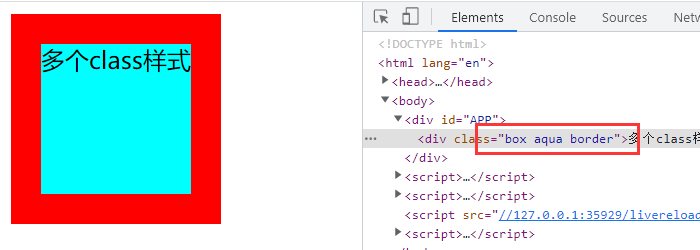
Vue 绑定style和class
在应用界面中,某些元素的样式是动态的。class 与 style 绑定就是专门用来实现动态样式效果的技术。 如果需要动态绑定 class 或 style 样式,可以使用 v-bind 绑定。 绑定 class 样式【字符串写法】 适用于:类名不确定,需要动态指…...

【Electron+Vue】Error: error:0308010C:digital envelope routines::unsupported
问题描述 使用 electron-builder 构建 vue 项目,运行 npm run electron:build ,构建过程报错。 / Bundling main process...ERROR Failed to compile with 1 errors …...

第7章 验证你的 Micro SaaS 应用程序构想
虽然可以使用一些软性验证技术,但要完全验证你的 Micro SaaS 创意,其实只有一种方法:为你的应用程序打造一个最基本的 MVP(最小化可行产品)版本,把它放出去,看看人们是否愿意为它买单。 不过,在开始构建 MVP 之前,您也可以利用一些软性验证检查,然后再继续编写应用程…...

【微服务部署】七、使用Docker安装Nginx并配置免费的SSL证书步骤详解
SSL(Secure Socket Layer,安全套接字层)证书是一种数字证书,用于加密网站与访问者之间的数据传输。SSL证书是网站安全和可靠性的重要保证,是建立信任和保护用户隐私的重要手段。其作用可以总结为以下几点: …...

【Java 进阶篇】JavaScript 中的全局对象和变量
JavaScript 是一门非常强大的编程语言,它提供了许多全局对象和变量,以便于在整个应用程序中共享数据和功能。本文将详细介绍 JavaScript 中的全局对象和变量,包括全局对象、全局变量、全局函数以及它们的用途和示例。 全局对象 JavaScript …...
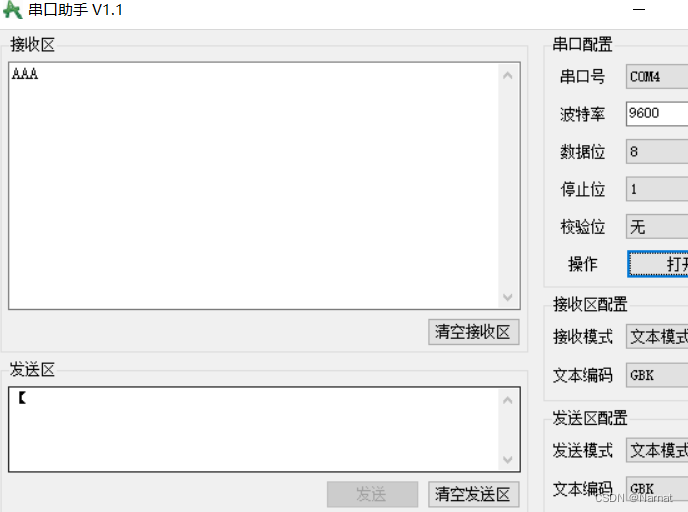
Stm32_标准库_12_串口_发送数据
波特率:约定的传输速率,1000bps,1s发1000位 引脚 结构 数据帧的传输特点 代码: #include "stm32f10x.h" // Device header #include "Delay.h" #include "OLED.h"GPIO_InitTypeDef GPIO_InitStruct; USART…...

“之江创客”跨境电商赛区决赛暨浙南新电商发展论坛圆满落幕
9月26日,由商务部中国国际电子商务中心指导,浙江省商务厅等十个部门主办,浙江省电子商务促进中心、温州市商务局、苍南县人民政府承办的“之江创客”2023全球电子商务创业创新大赛跨境电商赛区决赛暨浙南新电商发展论坛在苍南圆满落幕。浙江省…...
使用antd-pro脚手架搭建react ts项目
Pro 中使用 TypeScript 来作为默认的开发语言,TypeScript 的好处已经无须赘述,无论是开发成本还是维护成本都能大大减少,是中后台开发的必选。 初始化 提供了 pro-cli 来快速的初始化脚手架。 # 使用 npm npm i ant-design/pro-cli -g pro…...

推荐几款简单易用的协作化项目管理工具
您是否正在寻找一种有效且简单的项目管理工具来帮助您与团队成员协作?项目管理工具在当今的商业世界中已经变得必不可少,因为它们帮助团队保持组织和生产力。找到合适的工具是困难的,因为有太多的选择。有些工具是为特定类型的项目设计的,而…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

手机号归属地查询系统:3步构建可视化定位工具
手机号归属地查询系统:3步构建可视化定位工具 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors/lo/l…...

Apex Legends进阶指南:结构化训练框架与技能模块化拆解
1. 项目概述:一个面向Apex Legends玩家的成长型技能库如果你是一位《Apex Legends》的玩家,并且对提升自己的游戏水平有持续的热情,那么你很可能和我一样,经历过一个漫长的摸索期。从最初落地成盒,到逐渐熟悉地图、枪械…...

VT.ai:开发者AI工具集实战指南,提升编码效率与调试体验
1. 项目概述:一个面向开发者的AI工具集最近在GitHub上看到一个挺有意思的项目,叫“vinhnx/VT.ai”。乍一看这个标题,可能有点摸不着头脑,但点进去研究一番,你会发现这其实是一个开发者为自己、也为社区打造的一个AI工具…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...