搭建 Hadoop 生态集群大数据监控告警平台
目录
一、部署 prometheus 环境
1.1 下载安装包
1.2 解压安装
1.3 修改配置文件
1.3.1 hadoop-env.sh
1.3.2 prometheus_config.yml
1.3.3 zkServer.sh
1.3.4 prometheus_zookeeper.yaml
1.3.5 alertmanager.yml
1.3.6 prometheus.yml
1.3.7 config.yml
1.3.8 template.tmpl
1.3.9 告警规则
1.3.10 /etc/profile
1.3.11 prometheus_spark.yml
1.3.12 spark-env.sh
1.3.13 hive
1.3.14 prometheus_metastore.yaml、prometheus_hs2.yaml
1.4 创建 systemd 服务
1.4.1 创建 prometheus 用户
1.4.2 alertmanager.service
1.4.3 prometheus.service
1.4.4 node_exporter.service
1.4.5 pushgateway.service
1.4.6 grafana.service
1.5 启动服务
二、补充
2.1 告警规则和 grafana 仪表盘文件下载
2.2 服务进程监控脚本
2.2.1 prometheus-webhook-dingtalk
2.2.2 hive
2.2.3 日志切割
2.3 常用命令
2.4 参考文档
2.5 内网环境
2.5.1 nginx(公网)
2.5.2 config
2.5.3 /etc/hosts
Hadoop 集群规模:Hadoop YARN HA 集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
Spark 集群规模:Spark-3.2.4 高可用集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
| IP | 主机名 | 运行角色 |
| 192.168.170.136 | hadoop01 | namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain spark hive |
| 192.168.170.137 | hadoop02 | namenode datanode resourcemanager nodemanager JournalNode DFSZKFailoverController QuorumPeerMain spark |
| 192.168.170.138 | hadoop03 | datanode nodemanage JournalNode QuorumPeerMain spark |
一、部署 prometheus 环境
1.1 下载安装包
-
prometheus、alertmanager、pushgateway、node_exporter:https://prometheus.io/download/
-
prometheus-webhook-dingtalk:https://github.com/timonwong/prometheus-webhook-dingtalk/tree/main
-
grafana:https://grafana.com/grafana/download
-
jmx_exporter:https://github.com/prometheus/jmx_exporter

1.2 解压安装
新建一个 /monitor 目录,把上面下载的 tar.gz 包都解压安装在 /monitor 目录下,并重命名如下名字:

1.3 修改配置文件
1.3.1 hadoop-env.sh
修改完后要把这个文件 scp 给各个 Hadoop 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
if ! grep -q <<<"$HDFS_NAMENODE_OPTS" jmx_prometheus_javaagent; then
HDFS_NAMENODE_OPTS="$HDFS_NAMENODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30002:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_DATANODE_OPTS" jmx_prometheus_javaagent; then
HDFS_DATANODE_OPTS="$HDFS_DATANODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30003:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_RESOURCEMANAGER_OPTS" jmx_prometheus_javaagent; then
YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30004:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_NODEMANAGER_OPTS" jmx_prometheus_javaagent; then
YARN_NODEMANAGER_OPTS="$YARN_NODEMANAGER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30005:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_JOURNALNODE_OPTS" jmx_prometheus_javaagent; then
HDFS_JOURNALNODE_OPTS="$HDFS_JOURNALNODE_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30006:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_ZKFC_OPTS" jmx_prometheus_javaagent; then
HDFS_ZKFC_OPTS="$HDFS_ZKFC_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30007:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$HDFS_HTTPFS_OPTS" jmx_prometheus_javaagent; then
HDFS_HTTPFS_OPTS="$HDFS_HTTPFS_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30008:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$YARN_PROXYSERVER_OPTS" jmx_prometheus_javaagent; then
YARN_PROXYSERVER_OPTS="$YARN_PROXYSERVER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30009:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi
if ! grep -q <<<"$MAPRED_HISTORYSERVER_OPTS" jmx_prometheus_javaagent; then
MAPRED_HISTORYSERVER_OPTS="$MAPRED_HISTORYSERVER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30010:/bigdata/hadoop/server/hadoop-3.2.4/prometheus_config.yml"
fi1.3.2 prometheus_config.yml
修改完后要把这个文件 scp 给各个 Hadoop 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4]# vim prometheus_config.yml
rules:
- pattern: ".*"1.3.3 zkServer.sh
修改完后要把这个文件 scp 给各个 zookeeper 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/zookeeper/zookeeper-3.7.1/bin/
[root@hadoop01 /bigdata/hadoop/zookeeper/zookeeper-3.7.1/bin]# vim zkServer.sh
if [ "x$JMXLOCALONLY" = "x" ]
thenJMXLOCALONLY=false
fiJMX_DIR="/monitor"
JVMFLAGS="$JVMFLAGS -javaagent:$JMX_DIR/jmx_prometheus_javaagent-0.19.0.jar=30011:/bigdata/hadoop/zookeeper/zookeeper-3.7.1/prometheus_zookeeper.yaml"1.3.4 prometheus_zookeeper.yaml
修改完后要把这个文件 scp 给各个 zookeeper 节点!
[root@hadoop01 ~]# cd /bigdata/hadoop/zookeeper/zookeeper-3.7.1/
[root@hadoop01 /bigdata/hadoop/zookeeper/zookeeper-3.7.1]# vim prometheus_zookeeper.yaml
rules:- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+)><>(\\w+)"name: "zookeeper_$2"type: GAUGE- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+)><>(\\w+)"name: "zookeeper_$3"type: GAUGElabels:replicaId: "$2"- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+)><>(Packets\\w+)"name: "zookeeper_$4"type: COUNTERlabels:replicaId: "$2"memberType: "$3"- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+)><>(\\w+)"name: "zookeeper_$4"type: GAUGElabels:replicaId: "$2"memberType: "$3"- pattern: "org.apache.ZooKeeperService<name0=ReplicatedServer_id(\\d+), name1=replica.(\\d+), name2=(\\w+), name3=(\\w+)><>(\\w+)"name: "zookeeper_$4_$5"type: GAUGElabels:replicaId: "$2"memberType: "$3"- pattern: "org.apache.ZooKeeperService<name0=StandaloneServer_port(\\d+)><>(\\w+)"type: GAUGEname: "zookeeper_$2"- pattern: "org.apache.ZooKeeperService<name0=StandaloneServer_port(\\d+), name1=InMemoryDataTree><>(\\w+)"type: GAUGEname: "zookeeper_$2"1.3.5 alertmanager.yml
[root@hadoop01 ~]# cd /monitor/alertmanager/
[root@hadoop01 /monitor/alertmanager]# ls
alertmanager alertmanager.yml amtool data LICENSE NOTICE
[root@hadoop01 /monitor/alertmanager]# vim alertmanager.yml
global:resolve_timeout: 5mtemplates:- '/monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/*.tmpl'route:group_by: ['job', 'severity']group_wait: 30sgroup_interval: 5mrepeat_interval: 3hreceiver: 'webhook1'receivers:- name: 'webhook1'webhook_configs:- url: 'http://192.168.170.136:8060/dingtalk/webhook1/send'send_resolved: true1.3.6 prometheus.yml
[root@hadoop01 ~]# cd /monitor/prometheus
[root@hadoop01 /monitor/prometheus]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool rule
[root@hadoop01 /monitor/prometheus]# vim prometheus.yml
# my global config
global:scrape_interval: 30s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 30s # Evaluate rules every 15 seconds. The default is every 1 minute.# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets: ['192.168.170.136:9093']# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:- "rule/*.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:- job_name: "prometheus"scrape_interval: 30sstatic_configs:- targets: ["hadoop01:9090"]# zookeeper 集群配置- job_name: "zookeeper"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30011', 'hadoop02:30011', 'hadoop03:30011']# node_exporter 配置- job_name: "pushgatewawy"scrape_interval: 30sstatic_configs:- targets: ["hadoop01:9091"]# node_exporter 配置- job_name: "node_exporter"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:9100', 'hadoop02:9100', 'hadoop03:9100']- job_name: " namenode "scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30002', 'hadoop02:30002']
# labels:
# instance: namenode 服务器- job_name: "datanode"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30003', 'hadoop02:30003', 'hadoop03:30003']- job_name: "resourcemanager"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30004', 'hadoop02:30004']- job_name: "nodemanager"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30005', 'hadoop02:30005', 'hadoop03:30005']- job_name: "journalnode"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30006', 'hadoop02:30006', 'hadoop03:30006']- job_name: "zkfc"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30007', 'hadoop02:30007']- job_name: "jobhistoryserver"scrape_interval: 30sstatic_configs:- targets: ["hadoop01:30010"]- job_name: "spark_master"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30012', 'hadoop02:30012']- job_name: "spark_worker"scrape_interval: 30sstatic_configs:- targets: ['hadoop01:30013', 'hadoop02:30013', 'hadoop03:30013'] - job_name: "hive_metastore"scrape_interval: 30sstatic_configs:- targets: ["hadoop01:30014"]- job_name: "hive_hs2"scrape_interval: 30sstatic_configs:- targets: ["hadoop01:30015"] 1.3.7 config.yml
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# ls
config.example.yml config.yml contrib LICENSE nohup.out prometheus-webhook-dingtalk
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# vim config.yml
## Request timeout
# timeout: 5s## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true## Customizable templates path
templates:- /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/template.tmpl## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'## Targets, previously was known as "profiles"
targets:webhook1:url: https://oapi.dingtalk.com/robot/send?access_token=0d6c5dc25fa3f79cf2f83c92705fe4594dcxxx# secret for signaturesecret: SECecdbfff858ab8f3195dc34b7e225fee9341bc9xxxmessage:title: '{{ template "ops.title" . }}'text: '{{ template "ops.content" . }}'1.3.8 template.tmpl
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk/contrib/templates/legacy]# vim template.tmpl
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}{{ define "__alert_list" }}{{ range . }}
---**告警类型**: {{ .Labels.alertname }}**告警级别**: {{ .Labels.severity }}**故障主机**: {{ .Labels.instance }}**告警信息**: {{ .Annotations.description }}**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}{{ define "__resolved_list" }}{{ range . }}
---**告警类型**: {{ .Labels.alertname }}**告警级别**: {{ .Labels.severity }}**故障主机**: {{ .Labels.instance }}**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}{{ define "ops.title" }}
{{ template "__subject" . }}
{{ end }}{{ define "ops.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}{{ define "ops.link.title" }}{{ template "ops.title" . }}{{ end }}
{{ define "ops.link.content" }}{{ template "ops.content" . }}{{ end }}
{{ template "ops.title" . }}
{{ template "ops.content" . }}1.3.9 告警规则
在第二点下面的文件里下载即可。
1.3.10 /etc/profile
修改完后要把这个文件 scp 给各个 Hadoop 节点!
# JDK 1.8
JAVA_HOME=/usr/java/jdk1.8.0_381
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib
export JAVA_HOME PATH CLASSPATH# hadoop
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin# spark
export SPARK_HOME=/bigdata/spark-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PYSPARK_PYTHON=/usr/local/anaconda3/envs/pyspark/bin/python3.10
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native1.3.11 prometheus_spark.yml
修改完后要把这个文件 scp 给各个 spark 节点!
(base) [root@hadoop01 ~]# cd /bigdata/spark-3.2.4/
(base) [root@hadoop01 /bigdata/spark-3.2.4]# vim prometheus_spark.yml
rules:# These come from the master# Example: master.aliveWorkers- pattern: "metrics<name=master\\.(.*), type=counters><>Value"name: spark_master_$1# These come from the worker# Example: worker.coresFree- pattern: "metrics<name=worker\\.(.*), type=counters><>Value"name: spark_worker_$1# These come from the application driver# Example: app-20160809000059-0000.driver.DAGScheduler.stage.failedStages- pattern: "metrics<name=(.*)\\.driver\\.(DAGScheduler|BlockManager|jvm)\\.(.*), type=gauges><>Value"name: spark_driver_$2_$3type: GAUGElabels:app_id: "$1"# These come from the application driver# Emulate timers for DAGScheduler like messagePRocessingTime- pattern: "metrics<name=(.*)\\.driver\\.DAGScheduler\\.(.*), type=counters><>Count"name: spark_driver_DAGScheduler_$2_totaltype: COUNTERlabels:app_id: "$1"- pattern: "metrics<name=(.*)\\.driver\\.HiveExternalCatalog\\.(.*), type=counters><>Count"name: spark_driver_HiveExternalCatalog_$2_totaltype: COUNTERlabels:app_id: "$1"# These come from the application driver# Emulate histograms for CodeGenerator- pattern: "metrics<name=(.*)\\.driver\\.CodeGenerator\\.(.*), type=counters><>Count"name: spark_driver_CodeGenerator_$2_totaltype: COUNTERlabels:app_id: "$1"# These come from the application driver# Emulate timer (keep only count attribute) plus counters for LiveListenerBus- pattern: "metrics<name=(.*)\\.driver\\.LiveListenerBus\\.(.*), type=counters><>Count"name: spark_driver_LiveListenerBus_$2_totaltype: COUNTERlabels:app_id: "$1"# Get Gauge type metrics for LiveListenerBus- pattern: "metrics<name=(.*)\\.driver\\.LiveListenerBus\\.(.*), type=gauges><>Value"name: spark_driver_LiveListenerBus_$2type: GAUGElabels:app_id: "$1"# These come from the application driver if it's a streaming application# Example: app-20160809000059-0000.driver.com.example.ClassName.StreamingMetrics.streaming.lastCompletedBatch_schedulingDelay- pattern: "metrics<name=(.*)\\.driver\\.(.*)\\.StreamingMetrics\\.streaming\\.(.*), type=gauges><>Value"name: spark_driver_streaming_$3labels:app_id: "$1"app_name: "$2"# These come from the application driver if it's a structured streaming application# Example: app-20160809000059-0000.driver.spark.streaming.QueryName.inputRate-total- pattern: "metrics<name=(.*)\\.driver\\.spark\\.streaming\\.(.*)\\.(.*), type=gauges><>Value"name: spark_driver_structured_streaming_$3labels:app_id: "$1"query_name: "$2"# These come from the application executors# Examples:# app-20160809000059-0000.0.executor.threadpool.activeTasks (value)# app-20160809000059-0000.0.executor.JvmGCtime (counter)# filesystem metrics are declared as gauge metrics, but are actually counters- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.filesystem\\.(.*), type=gauges><>Value"name: spark_executor_filesystem_$3_totaltype: COUNTERlabels:app_id: "$1"executor_id: "$2"- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.(.*), type=gauges><>Value"name: spark_executor_$3type: GAUGElabels:app_id: "$1"executor_id: "$2"- pattern: "metrics<name=(.*)\\.(.*)\\.executor\\.(.*), type=counters><>Count"name: spark_executor_$3_totaltype: COUNTERlabels:app_id: "$1"executor_id: "$2"- pattern: "metrics<name=(.*)\\.(.*)\\.ExecutorMetrics\\.(.*), type=gauges><>Value"name: spark_executor_$3type: GAUGElabels:app_id: "$1"executor_id: "$2"# These come from the application executors# Example: app-20160809000059-0000.0.jvm.threadpool.activeTasks- pattern: "metrics<name=(.*)\\.([0-9]+)\\.(jvm|NettyBlockTransfer)\\.(.*), type=gauges><>Value"name: spark_executor_$3_$4type: GAUGElabels:app_id: "$1"executor_id: "$2"- pattern: "metrics<name=(.*)\\.([0-9]+)\\.HiveExternalCatalog\\.(.*), type=counters><>Count"name: spark_executor_HiveExternalCatalog_$3_totaltype: COUNTERlabels:app_id: "$1"executor_id: "$2"# These come from the application driver# Emulate histograms for CodeGenerator- pattern: "metrics<name=(.*)\\.([0-9]+)\\.CodeGenerator\\.(.*), type=counters><>Count"name: spark_executor_CodeGenerator_$3_totaltype: COUNTERlabels:app_id: "$1"executor_id: "$2"1.3.12 spark-env.sh
修改完后要把这个文件 scp 给各个 spark 节点!
(base) [root@hadoop01 ~]# cd /bigdata/spark-3.2.4/conf/
(base) [root@hadoop01 /bigdata/spark-3.2.4/conf]# vim spark-env.sh
export SPARK_MASTER_OPTS="$SPARK_MASTER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30012:/bigdata/spark-3.2.4/prometheus_spark.yml"
export SPARK_WORKER_OPTS="$SPARK_WORKER_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30013:/bigdata/spark-3.2.4/prometheus_spark.yml"1.3.13 hive
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim bin/hive
···
if [[ "$SERVICE" =~ ^(help|version|orcfiledump|rcfilecat|schemaTool|cleardanglingscratchdir|metastore|beeline|llapstatus|llap)$ ]] ; thenexport HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30014:/bigdata/apache-hive-3.1.2/prometheus_metastore.yaml"SKIP_HBASECP=true
fi
···
if [[ "$SERVICE" =~ ^(hiveserver2|beeline|cli)$ ]] ; thenexport HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -javaagent:/monitor/jmx_prometheus_javaagent-0.19.0.jar=30015:/bigdata/apache-hive-3.1.2/prometheus_hs2.yaml"# If process is backgrounded, don't change terminal settingsif [[ ( ! $(ps -o stat= -p $$) =~ "+" ) && ! ( -p /dev/stdin ) && ( ! $(ps -o tty= -p $$) =~ "?" ) ]]; thenexport HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Djline.terminal=jline.UnsupportedTerminal"fi
fi
···1.3.14 prometheus_metastore.yaml、prometheus_hs2.yaml
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim prometheus_metastore.yaml
---
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern: ".*"(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim prometheus_hs2.yaml
---
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
rules:
- pattern: ".*"1.4 创建 systemd 服务
1.4.1 创建 prometheus 用户
各个节点都需要创建!!!(也可以不创建 prometheus 用户,把后面 service 文件的 prometheus 改为 root 即可!)
useradd -M -s /usr/sbin/nologin prometheus
chown -R prometheus:prometheus /monitor1.4.2 alertmanager.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
Documentation=https://prometheus.io/docs/alerting/alertmanager/
After=network-online.target
Wants=network-online.target[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/alertmanager/alertmanager \--config.file=/monitor/alertmanager/alertmanager.yml \--storage.path=/monitor/alertmanager/data \--web.listen-address=0.0.0.0:9093
ExecReload=/bin/kill -HUP $MAINPID
Restart=always[Install]
WantedBy=multi-user.target1.4.3 prometheus.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network-online.target[Service]
Type=simple
User=prometheus
Group=prometheus
WorkingDirectory=/monitor/prometheus
ExecStart=/monitor/prometheus/prometheus \--web.listen-address=0.0.0.0:9090 \--storage.tsdb.path=/monitor/prometheus/data \--storage.tsdb.retention.time=30d \--config.file=prometheus.yml \--web.enable-lifecycle
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Restart=on-failure[Install]
WantedBy=multi-user.target1.4.4 node_exporter.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
Documentation=https://github.com/prometheus/node_exporter
After=network-online.target
Wants=network-online.target[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/node_exporter/node_exporter[Install]
WantedBy=multi-user.target1.4.5 pushgateway.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/pushgateway.service
[Unit]
Description=Pushgateway Server
Documentation=https://github.com/prometheus/pushgateway
After=network-online.target
Wants=network-online.target[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/monitor/pushgateway/pushgateway \--web.listen-address=:9091 \--web.telemetry-path=/metrics
Restart=always[Install]
WantedBy=multi-user.target1.4.6 grafana.service
[root@hadoop01 ~]# vim /usr/lib/systemd/system/grafana.service
[Unit]
Description=Grafana Server
Documentation=http://docs.grafana.org
After=network-online.target
Wants=network-online.target[Service]
Type=simple
User=prometheus
Group=prometheus
ExecStart=/monitor/grafana/bin/grafana-server \--config=/monitor/grafana/conf/defaults.ini \--homepath=/monitor/grafana
Restart=on-failure
RestartSec=10
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=grafana
Environment=GRAFANA_HOME=/monitor/grafana \GRAFANA_USER=prometheus \GRAFANA_GROUP=prometheus[Install]
WantedBy=multi-user.target1.5 启动服务
把上述服务启动即可!
注意:prometheus-webhook-dingtalk 服务需要用下面方式启动:
cd /monitor/prometheus-webhook-dingtalk/
nohup ./prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --config.file="/monitor/prometheus-webhook-dingtalk/config.yml" &二、补充
2.1 告警规则和 grafana 仪表盘文件下载
[root@hadoop01 ~]# cd /monitor/prometheus/
[root@hadoop01 /monitor/prometheus]# ls
console_libraries consoles data LICENSE NOTICE prometheus prometheus.yml promtool rule
[root@hadoop01 /monitor/prometheus]# ls rule/
HDFS.yml node.yml spark_master.yml spark_worker.yml yarn.yml zookeeper.yml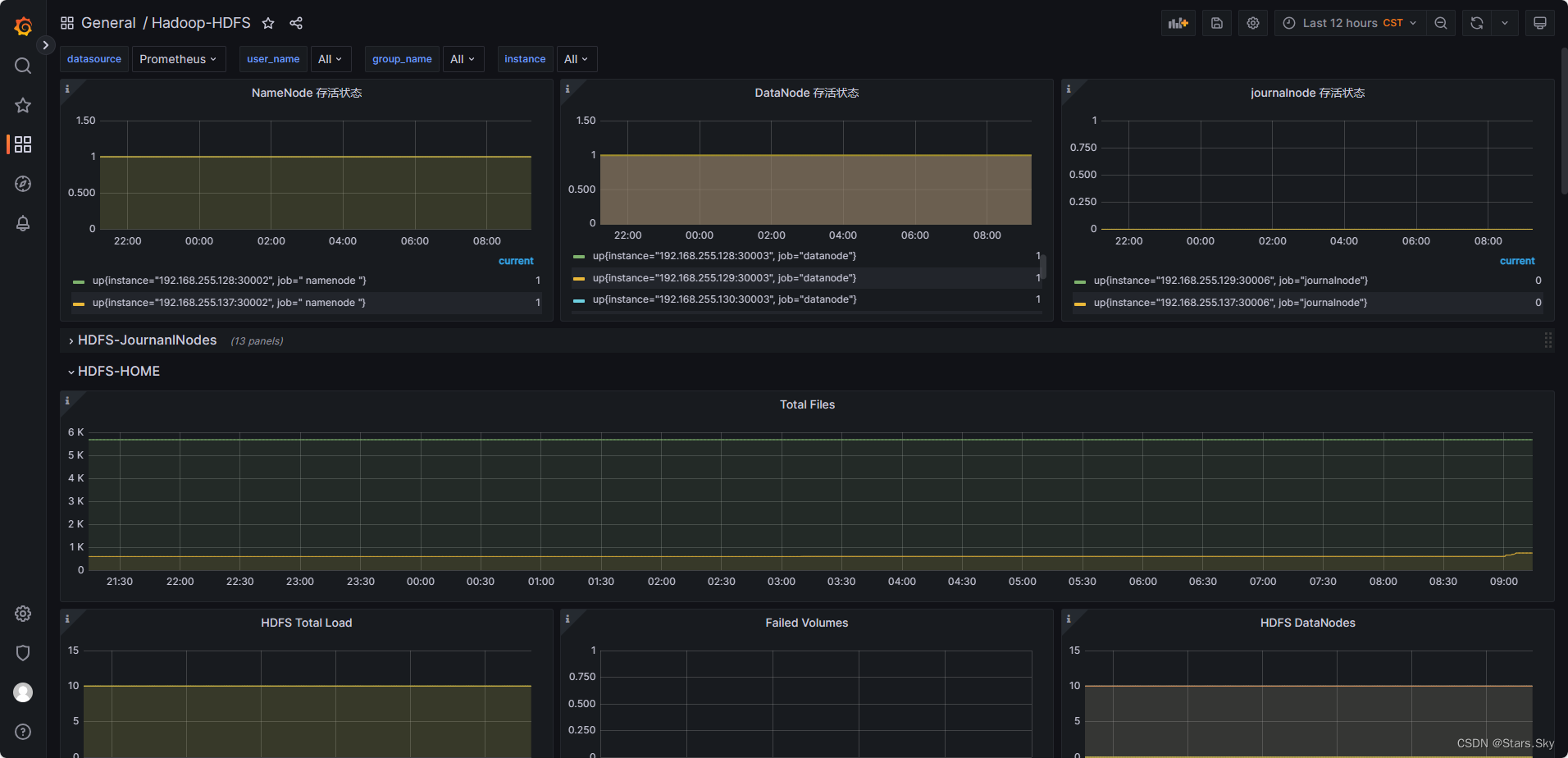
文件下载链接:【免费】prometheus告警规则文件和grafana仪表盘文件资源-CSDN文库
2.2 服务进程监控脚本
2.2.1 prometheus-webhook-dingtalk
[root@hadoop01 ~]# cd /monitor/prometheus-webhook-dingtalk/
[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# vim monitor_prometheus_webhook_dingtalk.sh
#!/bin/bash# 获取当前系统时间
current_time=$(date "+%Y-%m-%d %H:%M:%S")# 定义日志文件路径
log_file="/monitor/prometheus-webhook-dingtalk/monitor.log"echo "[$current_time] Checking if prometheus-webhook-dingtalk process is running..." >> $log_file# 检查进程是否在运行
if ! /usr/bin/pgrep -fx "/monitor/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --web.listen-address=0.0.0.0:8060 --config.file=/monitor/prometheus-webhook-dingtalk/config.yml" >> $log_file; thenecho "[$current_time] prometheus-webhook-dingtalk process is not running. Starting it now..." >> $log_file# 使用绝对路径和 nohup 在后台启动进程/usr/bin/nohup /monitor/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --web.listen-address="0.0.0.0:8060" --config.file="/monitor/prometheus-webhook-dingtalk/config.yml" >> /monitor/prometheus-webhook-dingtalk/output.log 2>&1 &elseecho "[$current_time] prometheus-webhook-dingtalk process is running." >> $log_file
fi[root@hadoop01 /monitor/prometheus-webhook-dingtalk]# chmod 777 monitor_prometheus_webhook_dingtalk.sh [root@hadoop01 /monitor/prometheus-webhook-dingtalk]# crontab -e
* * * * * /usr/bin/bash /monitor/prometheus-webhook-dingtalk/monitor_prometheus_webhook_dingtalk.sh2.2.2 hive
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim monitor_hive.sh
#!/bin/bash# 获取当前系统时间
current_time=$(date "+%Y-%m-%d %H:%M:%S")# 定义日志文件路径
log_file_metastore="/bigdata/apache-hive-3.1.2/monitor_metastore.log"
log_file_hs2="/bigdata/apache-hive-3.1.2/monitor_hs2.log"echo "[$current_time] Checking if hive metastore and hs2 processes are running..." # 检查 Hive Metastore 是否在运行
echo "[$current_time] Checking if hive metastore process is running..." >> $log_file_metastore
if ! /usr/bin/pgrep -f "hive-metastore-3.1.2.jar" >> $log_file_metastore; thenecho "[$current_time] hive metastore process is not running. Starting it now..." >> $log_file_metastore# 使用绝对路径和 nohup 在后台启动进程/usr/bin/nohup /bigdata/apache-hive-3.1.2/bin/hive --service metastore >> /bigdata/apache-hive-3.1.2/metastore_output.log 2>&1 &# 等待一点时间以确保 metastore 完全启动sleep 30
elseecho "[$current_time] hive metastore process is running." >> $log_file_metastore
fi# 检查 HiveServer2 是否在运行
echo "[$current_time] Checking if hive hs2 process is running..." >> $log_file_hs2
if ! /usr/bin/pgrep -f "HiveServer2" >> $log_file_hs2; thenecho "[$current_time] hive hs2 process is not running. Starting it now..." >> $log_file_hs2# 使用绝对路径和 nohup 在后台启动进程/usr/bin/nohup /bigdata/apache-hive-3.1.2/bin/hive --service hiveserver2 >> /bigdata/apache-hive-3.1.2/hs2_output.log 2>&1 &
elseecho "[$current_time] hive hs2 process is running." >> $log_file_hs2
fi(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# chmod 777 montior_metastore.sh (base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# crontab -e
* * * * * /usr/bin/bash /bigdata/apache-hive-3.1.2/monitor_hive.sh2.2.3 日志切割
[root@hadoop01 ~]# vim /etc/logrotate.d/prometheus-webhook-dingtalk
/monitor/prometheus-webhook-dingtalk/monitor.log \
/bigdata/apache-hive-3.1.2/monitor_metastore.log \
/bigdata/apache-hive-3.1.2/monitor_hs2.log {dailyrotate 7size 150Mcompressmaxage 30missingoknotifemptycreate 0644 root rootcopytruncate
}# 测试调式 logrotate 配置
[root@hadoop01 ~]# logrotate -d /etc/logrotate.d/prometheus-webhook-dingtalk
# 手动执行日志轮换
logrotate -f /etc/logrotate.d/prometheus-webhook-dingtalk2.3 常用命令
# 检查 prometheus 配置文件,包括告警规则文件
[root@hadoop01 ~]# cd /monitor/prometheus
./promtool check config prometheus.yml# 重启 prometheus 配置
curl -X POST http://localhost:9090/-/reload# 测试发送信息到机器人
curl 'https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx' \-H 'Content-Type: application/json' \-d '{"msgtype": "text","text": {"content":"我就是我, 是不一样的烟火"}}'2.4 参考文档
-
Hadoop 官方监控指标:https://hadoop.apache.org/docs/r3.2.4/hadoop-project-dist/hadoop-common/Metrics.html
-
阿里云监控指标:https://help.aliyun.com/zh/emr/emr-on-ecs/user-guide/hdfs-metrics?spm=a2c4g.11186623.0.0.11ba6daalnmBWn
-
阿里云 grafana 仪表盘:https://help.aliyun.com/document_detail/2326798.html?spm=a2c4g.462292.0.0.4c4c5d35uXCP6k#section-1bn-bzq-fw3
-
jmx_exporter 配置文件参考:https://github.com/prometheus/jmx_exporter/tree/main/example_configs
-
钉钉机器人文档:https://open.dingtalk.com/document/robots/custom-robot-access
2.5 内网环境
2.5.1 nginx(公网)
需要一台可以访问公网的 nginx 服务器来代理钉钉 api:
[root@idc-master-02 ~]# cat /etc/nginx/conf.d/uat-prometheus-webhook-dingtalk.conf
server {listen 30080;location /robot/send {proxy_pass https://oapi.dingtalk.com;proxy_set_header Host oapi.dingtalk.com;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme;}
}2.5.2 config
[root@localhost-13 ~]# cat /opt/prometheus-webhook-dingtalk/config.yml targets:webhook1:url: http://10.0.4.11:30080/robot/send?access_token=0d6c5dc25fa3f79cf2f83c92705fe4594dcc5b3xxxsecret: SECecdbfff858ab8f3195dc34b7e225fee93xxxmessage:title: '{{ template "ops.title" . }}'text: '{{ template "ops.content" . }}'2.5.3 /etc/hosts
[root@localhost-13 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.4.11 oapi.dingtalk.com相关文章:
搭建 Hadoop 生态集群大数据监控告警平台
目录 一、部署 prometheus 环境 1.1 下载安装包 1.2 解压安装 1.3 修改配置文件 1.3.1 hadoop-env.sh 1.3.2 prometheus_config.yml 1.3.3 zkServer.sh 1.3.4 prometheus_zookeeper.yaml 1.3.5 alertmanager.yml 1.3.6 prometheus.yml 1.3.7 config.yml 1.3.8 t…...
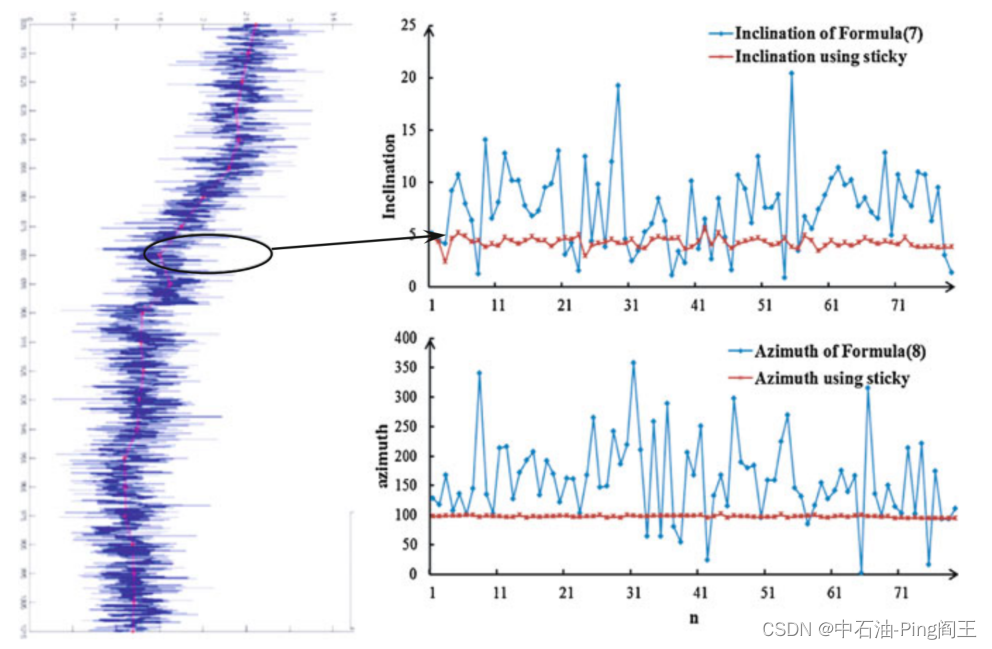
课题学习(七)----粘滑运动的动态算法
一、 粘滑运动的动态算法 在实际钻井过程中,钻柱会出现扭振和粘滑现象(粘滑运动–B站视频连接),但并不总是呈现均匀旋转。如下图所示,提取一段地下数据时,转盘转速保持在100 r/min,钻头转速在0-…...

python二次开发CATIA:测量曲线长度
以下代码是使用Python语言通过win32com库来控制CATIA应用程序的一个示例。主要步骤包括创建一个新的Part文件,然后在其中创建一个新的几何图形集,并在这个集合中创建一个样条线。这个样条线是通过一组给定的坐标点来创建的,这些点被添加到集合…...
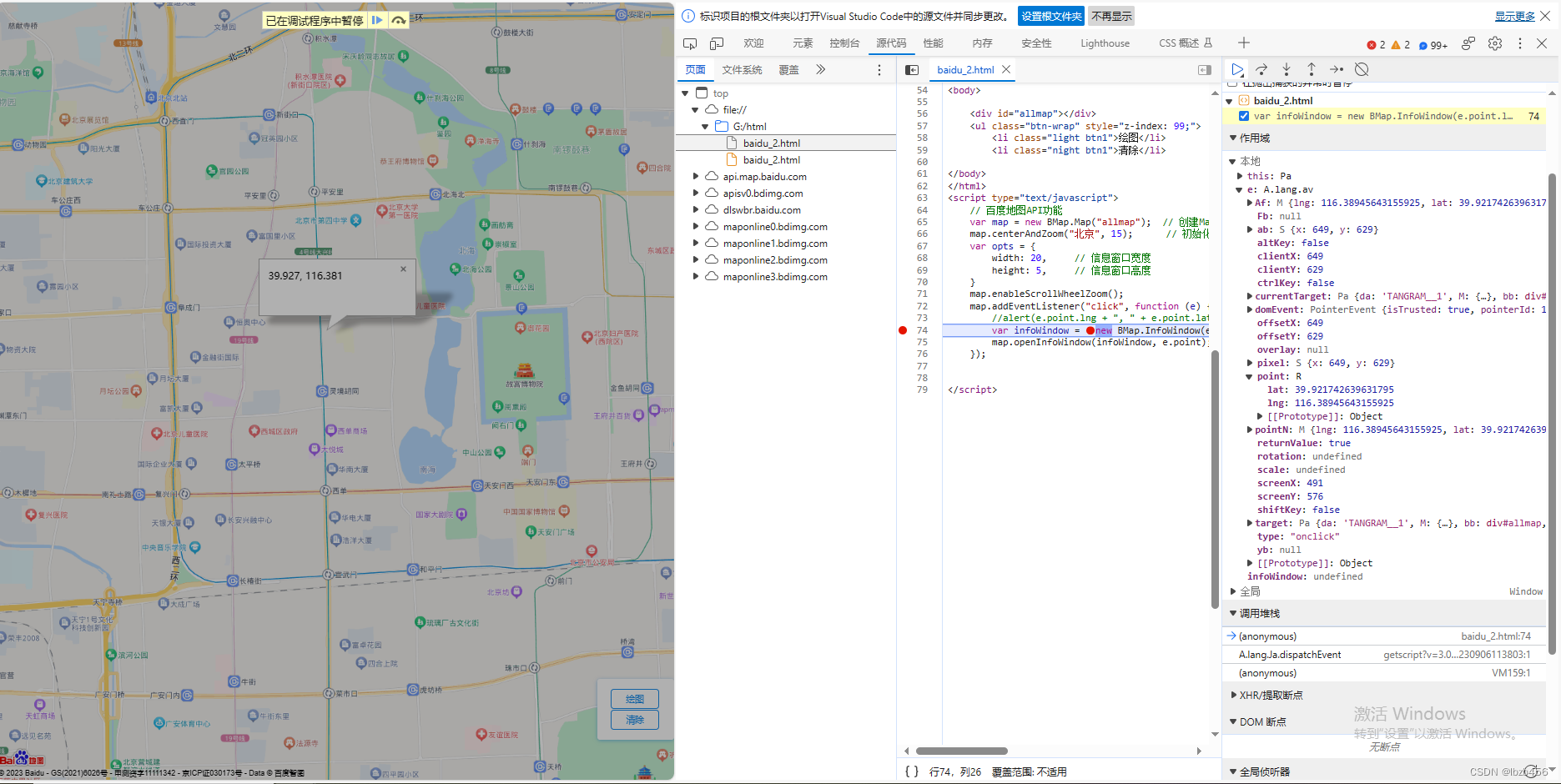
从零开始学习调用百度地图网页API:二、初始化地图,鼠标交互创建信息窗口
目录 代码结构headbodyscript 调试 代码 <!DOCTYPE html> <html> <head><meta http-equiv"Content-Type" content"text/html; charsetutf-8" /><meta name"viewport" content"initial-scale1.0, user-scalable…...

Yarn基础入门
文章目录 一、Yarn资源调度器1、架构2、Yarn工作机制3、HDFS、YARN、MR关系4、作业提交之HDFS&MapReduce 二、Yarn调度器和调度算法1、先进先出调度器(FIFO)2、容量调度器(Capacity Scheduler)3、公平调度器(Fair …...

element picker 时间控件,指定区间和指定月份置灰
直接上代码 <el-date-pickerv-model"fillingList.declareDate"type"month":disabled"isDisplayName"placeholder"选择填报时间"value-format"yyyy-MM":picker-options"pickerOptions"change"declareDate…...

thinkphp6
unexpected , expecting case (T_CASE) or default (T_DEFAULT) or } 在模板中应用{switch}{/switch}标签,报错,其实是switch的问题,模板解析后,switch:和第一个case:之间不能有有输出的,一个空格也不行,所以第一个要紧跟着 Thi…...

Android 13.0 USB鼠标右键改成返回键的功能实现
1.概述 在13.0设备定制化开发中,产品有好几个usb口,用来可以连接外设,所以USB鼠标通过usb口来控制设备也是常见的问题,在window系统中,鼠标右键是返回键的功能,可是android原生的系统 鼠标右键不是返回键根据产品开发需要鼠标修改成右键就需要跟代码, 2.USB鼠标右键改…...

超低延时 TCP/UDP IP核
实现以太网协议集当中的ARP、ICMP、UDP以及TCP协议 一、概述 TCP_IP核是公司自主开发的使用FPGA逻辑搭建的用于10G以太网通信IP。该IP能够实现以太网协议集当中的ARP、ICMP、UDP以及TCP协议。支持连接10G/25G以太网PHY,组成高速网络通信系统。该IP上传、下传数据B…...

Python与数据库存储
Python与数据库存储的最佳实践包括以下几个方面的内容: 连接数据库:使用合适的数据库连接库,如sqlite3、psycopg2、pymysql等来连接数据库。创建连接对象并通过该对象获取游标。 import sqlite3# 连接SQLite数据库 conn sqlite3.connect(sam…...
及其使用)
RN操作SQLite数据库的包(sqlite-helper.js)及其使用
先安装 yarn add react-native-sqlite-storagesqlite-helper.js工具包的具体代码 "use strict";var _interopRequireDefaultrequire("babel/runtime/helpers/interopRequireDefault");Object.defineProperty(exports,"__esModule",{value:true…...
软件测试学习(四)自动测试和测试工具、缺陷轰炸、外包测试、计划测试工作、编写和跟踪测试用例
目录 自动测试和测试工具 工具和自动化的好处 测试工具 查看器和监视器 驱动程序 桩 压力和负载工具 干扰注入器和噪声发生器 分析工具 软件测试自动化 宏录制和回放 可编程的宏 完全可编程的自动测试工具 随机测试:猴子和大猩猩 使用测试工具和自动…...

【Rust日报】2023-10-12 论文:利用公共信息评估 Rust 代码库
论文 - 利用公共信息评估 Rust 代码库 作者 Emil Eriksson 是 Lund University 的硕士学生,今年春天发布了其硕士论文 Evaluation of Rust Codebases Using Public Information ,并获得了 electrical engineering 学位。 在论文撰写过程中,Em…...
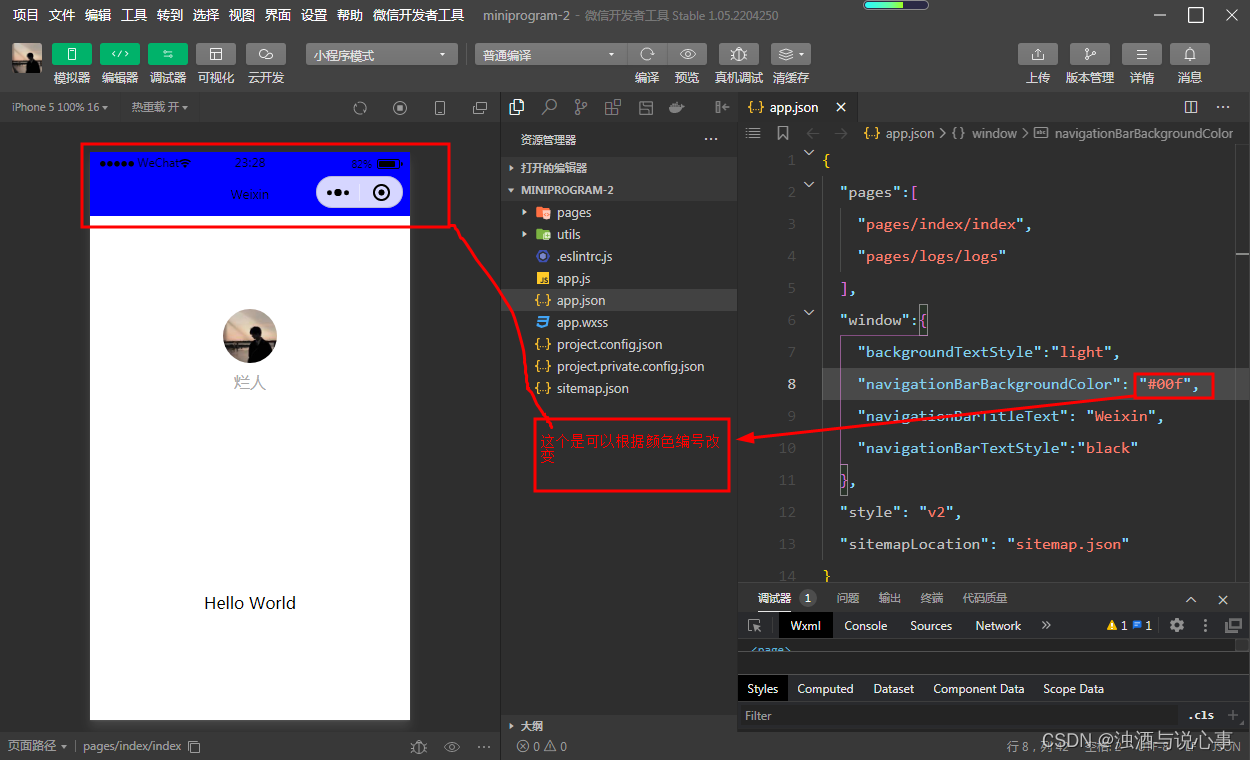
微信小程序入门
微信小程序介绍 微信小程序是一种轻量级应用程序,可以在微信中直接使用,无需下载和安装。它们基于微信的开发标准和API构建,并且可以实现许多不同的功能,例如娱乐、社交、购物、生活服务等。微信小程序用户仅需点击微信聊天窗口中…...
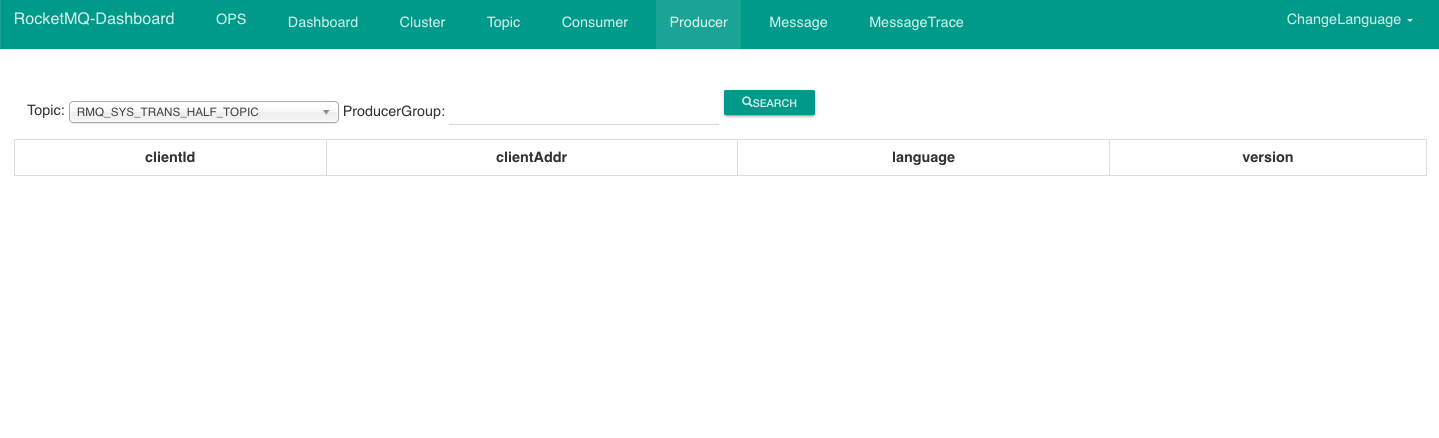
【RocketMQ系列二】通过docker部署单机RocketMQ
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...

中缀表达式转后缀表达式
58同城1012笔试第二题 示例1 输入 “exp1 & (exp2|exp3)/!exp4” 输出 “exp1 exp2 exp3| & exp4 !” 思路与代码 这个代码的核心思想是通过栈来处理不同操作符的优先级和括号的嵌套,将中缀表达式转换为后缀表达式,以便更容易进行计算。 …...

Zabbix 使用同一ODBC监控不同版本MySQL
一、ODBC介绍 ODBC是Open Database Connect 即开发数据库互连的简称,它是一个用于访问数据库的统一界面标准。ODBC引入一个公共接口以解决不同数据库潜在的不一致性,从而很好的保证了基于数据库系统的应用程序的相对独立性。ODBC 概念由 Microsoft 开发&…...
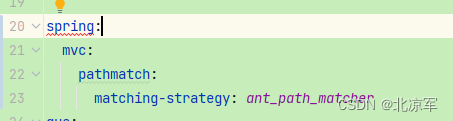
Swagger3.0 与spring boot2.7x 整合避免swagger2.0与boot2.7冲突
注释掉2.0引入的俩包 直接引入3.0 <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version></dependency> swagger配置文件粘贴即用哦 import org.springfram…...

【HTML+REACT+ANTD 表格操作】处理(改变)数据,改变DOM
博主:_LJaXi 专栏: React | 前端框架 主要是一些表格DOM操作,数据更换 个人向 HTML <!DOCTYPE html> <html lang"en"> <link> <meta charset"UTF-8" /> <meta name"viewport" con…...

【面试经典150 | 哈希表】最长连续序列
文章目录 写在前面Tag题目来源题目解读解题思路方法一:哈希表 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主,并附带一些对于本题涉及到的数据结构等内…...

《算法竞赛从入门到国奖》算法基础:动态规划-最长子序列
💡Yupureki:个人主页 ✨个人专栏:《C》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》 《个人在线OJ平台》 🌸Yupureki🌸的简介: 目录 1. 最长上升子序列 算法原理 代码示例 2. 合唱队形 算法原理 代码示例 3. 最长公共…...

利用快马平台快速构建403 forbidden错误演示原型,直观理解HTTP权限状态
今天在调试一个前端项目时,遇到了403 forbidden错误,突然想到可以做个简单的演示原型来帮助团队新人理解这个常见的HTTP状态码。正好最近在用InsCode(快马)平台做各种小demo,发现它特别适合快速搭建这类教学演示项目。 理解403状态码的核心场…...

企业AI定制开发:以工业场景为核心,赋能全行业数智化转型
在人工智能与实体经济深度融合的趋势下,标准化AI产品难以适配企业差异化业务流程,定制化AI开发成为企业数智化转型的关键路径。山东向量空间人工智能科技有限公司依托JBoltAI企业级Java AI应用开发框架,聚焦工业领域AI改造,同时为…...

Linux安装中文+MySQL的详细过程
中文安装1. 清理环境变量打开终端执行:sed -i /fcitx/d ~/.bashrcsed -i /GTK_IM_MODULE/d ~/.bashrcsed -i /QT_IM_MODULE/d ~/.bashrcsed -i /XMODIFIERS/d ~/.bashrc2. 重新配置 ibus 环境变量echo export GTK_IM_MODULEibus >> ~/.bashrcecho export QT_I…...

VBA数据库解决方案第二十九讲 如何批量修改数据库中的数据
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

LCC-HVDC系统中交流滤波器的选型实战:从理论到工程落地
LCC-HVDC系统中交流滤波器的选型实战:从理论到工程落地 在特高压直流输电工程中,交流滤波器如同电力系统的"净化器",其选型直接关系到电网谐波抑制效果与系统运行经济性。某800kV换流站曾因滤波器选型不当导致年度损耗增加1200万元…...

文墨共鸣大模型处理Java八股文与面试题:智能学习与模拟面试
文墨共鸣大模型处理Java八股文与面试题:智能学习与模拟面试 准备Java技术面试,大概是每个开发者都绕不开的一道坎。面对海量的“八股文”知识点和层出不穷的面试题,你是不是也经历过这样的场景:翻开厚厚的面试宝典,感…...

Krita AI Diffusion图像引导适配器功能异常的深度解决方案
Krita AI Diffusion图像引导适配器功能异常的深度解决方案 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.com/gh…...

3步突破Navicat试用期限制:让数据库管理工具持续为你服务
3步突破Navicat试用期限制:让数据库管理工具持续为你服务 【免费下载链接】navicat_reset_mac navicat16 mac版无限重置试用期脚本 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 作为数据库开发者的日常伴侣,Navicat以其直观的…...

3 月 21 日G-Star Gathering Day 武汉站活动精彩回顾
3 月 21 日,G-Star Gathering Day 武汉站在鄂港澳青创园顺利举办。来自 AI 与开源领域的开发者、创业者齐聚一堂,围绕 AI Agent、代码智能体、个人创业形态与真实落地场景展开分享与交流。这不仅是一场技术沙龙,更是一场关于 “AI 如何真正改…...