【TensorFlow2 之014】在 TF 2.0 中实现 LeNet-5

一、说明
在这篇文章中,我们将展示如何在 TensorFlow 中实现像 \(LeNet-5\) 这样的基础卷积神经网络。LeNet-5 架构由 Yann LeCun 于 1998 年发明,是第一个卷积神经网络。
1.1 教程概述:
- 理论重述
- 在 TensorFlow 中的实现
1. 理论重述
\(LeNet-5 \) 的目标是识别手写数字。因此,它作为输入 \(32\times32\times1 \) 图像。它是灰度图像,因此通道数为 \(1 \)。下面我们可以看到该网络的架构。

LeNet-5架构
I. 最初的 MNIST 现在被认为太简单了。在过去的二十年里,许多研究人员针对原始 MNIST 提出了成功的解决方案。您可以在此处查看直接比较结果。
由于该网络主要是为 MNIST 数据集设计的,因此它的性能明显更好。通过微小的改变,它就可以在 Fashion MNIST 数据集上达到这种准确性。然而,在这篇文章中,我们将坚持网络的原始架构。
关于 LeNet-5 架构,您可以在此处阅读详细的理论文章。
让我们总结一下 LeNet-5 架构的各层。
| 图层类型 | 特征图 | 尺寸 | 内核大小 | 跨步 | 激活 |
|---|---|---|---|---|---|
| 图像 | 1 | 32×32 | – | – | – |
| 卷积 | 6 | 28×28 | 5×5 | 1 | 正值 |
| 平均池化 | 6 | 14×14 | 2×2 | 2 | – |
| 卷积 | 16 | 10×10 | 5×5 | 1 | 正值 |
| 平均池化 | 16 | 5×5 | 2×2 | 2 | – |
| 完全连接 | – | 120 | – | – | 正值 |
| 完全连接 | – | 84 | – | – | 正值 |
| 完全连接 | – | 10 | – | – | 软最大 |
二、TensorFlow中的实现
交互式 Colab 笔记本可在以下链接找到
在 Google Colab 中运行
为了练习,您可以尝试通过将Fashion_mnist替换为mnist、cifar10或其他来更改数据集。
让我们从导入所有必需的库开始。导入后,我们可以使用导入的模块来加载数据。load_data () 函数将自动下载数据并将其拆分为训练集和测试集。
import datetime
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as pltfrom tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.layers import Dense, Flatten, Conv2D, AveragePooling2Dfrom tensorflow.keras import datasets
from tensorflow.keras.utils import to_categorical#from __future__ import absolute_import, division, print_function, unicode_literals# The data, split between train and test sets:
(x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 2us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 7s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 1s 0us/step我们可以检查新数据的形状,发现我们的图像是 28×28 像素,因此我们需要添加一个新轴,它将代表多个通道。此外,对标签进行 one-hot 编码和对输入图像进行归一化也很重要。
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_train[0].shape, 'image shape')x_train shape: (60000, 28, 28)
60000 train samples
10000 test samples
(28, 28) image shape
# Add a new axis
x_train = x_train[:, :, :, np.newaxis]
x_test = x_test[:, :, :, np.newaxis]print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print(x_train[0].shape, 'image shape')x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples (28, 28, 1) image shape
# Convert class vectors to binary class matrices.num_classes = 10
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)# Data normalization
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
现在,是时候开始使用 TensorFlow 2.0 来构建我们的卷积神经网络了。最简单的方法是使用 Sequential API。我们将其包装在一个名为LeNet的类中。输入是图像,输出是类概率向量。
在 tf.keras 中,顺序模型表示层的线性堆栈,在本例中它遵循网络架构。
# LeNet-5 model
class LeNet(Sequential):def __init__(self, input_shape, nb_classes):super().__init__()self.add(Conv2D(6, kernel_size=(5, 5), strides=(1, 1), activation='tanh', input_shape=input_shape, padding="same"))self.add(AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))self.add(Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))self.add(AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))self.add(Flatten())self.add(Dense(120, activation='tanh'))self.add(Dense(84, activation='tanh'))self.add(Dense(nb_classes, activation='softmax'))self.compile(optimizer='adam',loss=categorical_crossentropy,metrics=['accuracy'])model = LeNet(x_train[0].shape, num_classes)
model.summary()Model: "le_net" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 6) 156 _________________________________________________________________ average_pooling2d (AveragePo (None, 14, 14, 6) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 10, 10, 16) 2416 _________________________________________________________________ average_pooling2d_1 (Average (None, 5, 5, 16) 0 _________________________________________________________________ flatten (Flatten) (None, 400) 0 _________________________________________________________________ dense (Dense) (None, 120) 48120 _________________________________________________________________ dense_1 (Dense) (None, 84) 10164 _________________________________________________________________ dense_2 (Dense) (None, 10) 850 ================================================================= Total params: 61,706 Trainable params: 61,706 Non-trainable params: 0
创建模型后,我们需要训练它的参数以使其强大。让我们训练给定数量的 epoch 模型。我们可以在TensorBoard中看到训练的进度。
# Place the logs in a timestamped subdirectory
# This allows to easy select different training runs
# In order not to overwrite some data, it is useful to have a name with a timestamp
log_dir="logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
# Specify the callback object
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)# tf.keras.callback.TensorBoard ensures that logs are created and stored
# We need to pass callback object to the fit method
# The way to do this is by passing the list of callback objects, which is in our case just onemodel.fit(x_train, y=y_train, epochs=20, validation_data=(x_test, y_test), callbacks=[tensorboard_callback],verbose=0)%tensorboard --logdir logs/fit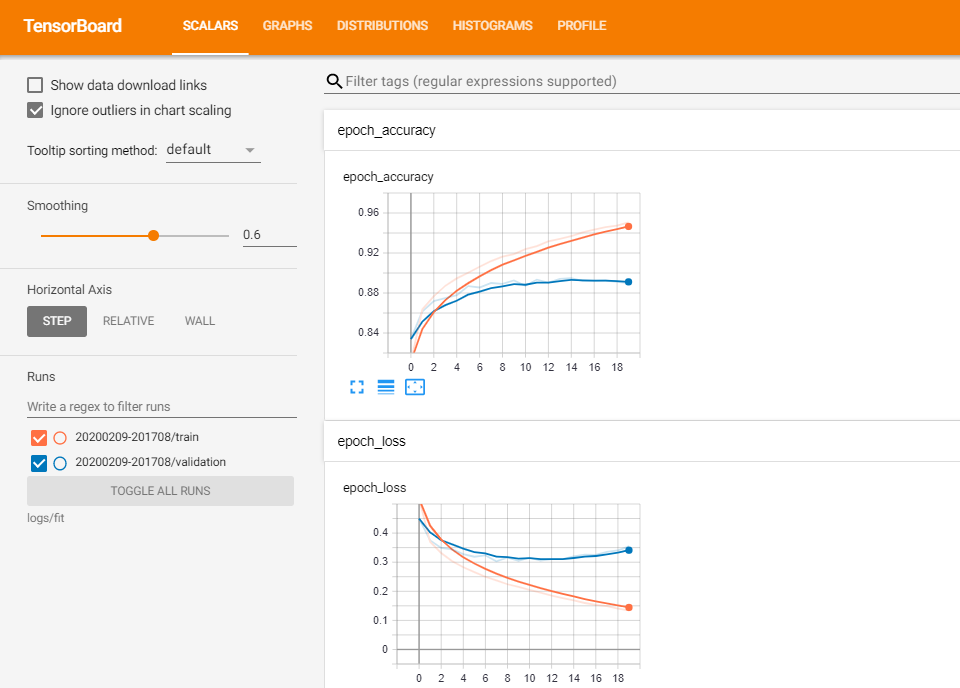
仅 20 个 epoch 就已经不错了。
之后,我们可以做出一些预测并将其可视化。使用predict_classes()函数,我们可以从网络中获取准确的类别而不是概率值。它与使用numpy.argmax()相同。我们将用红色显示错误的预测,用蓝色表示正确的预测。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']prediction_values = model.predict_classes(x_test)# set up the figure
fig = plt.figure(figsize=(15, 7))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)# plot the images: each image is 28x28 pixels
for i in range(50):ax = fig.add_subplot(5, 10, i + 1, xticks=[], yticks=[])ax.imshow(x_test[i,:].reshape((28,28)),cmap=plt.cm.gray_r, interpolation='nearest')if prediction_values[i] == np.argmax(y_test[i]):# label the image with the blue textax.text(0, 7, class_names[prediction_values[i]], color='blue')else:# label the image with the red textax.text(0, 7, class_names[prediction_values[i]], color='red')
三、总结
所以,在这里我们学习了如何在 Tensorflow 2.0 中开发和训练 LeNet-5。在下 一篇文章中 ,我们将继续实现流行的卷积神经网络,并学习如何在 TensorFlow 2.0 中实现AlexNet 。
相关文章:
【TensorFlow2 之014】在 TF 2.0 中实现 LeNet-5
一、说明 在这篇文章中,我们将展示如何在 TensorFlow 中实现像 \(LeNet-5\) 这样的基础卷积神经网络。LeNet-5 架构由 Yann LeCun 于 1998 年发明,是第一个卷积神经网络。 数据黑客变种rs 深度学习 机器学习 TensorFlow 2020 年 2 月 29 日 | 0 …...

【2023】redis-stream配合spring的data-redis详细使用(包括广播和组接收)
目录 一、简介1、介绍2、对比 二、整合spring的data-redis实现1、使用依赖2、配置类2.1、配置RedisTemplate bean2.2、异常类 3、实体类3.1、User3.2、Book 4、发送消息4.1、RedisStreamUtil工具类4.2、通过延时队列线程池模拟发送消息4.3、通过http主动发送消息 5、dz…...
飞书应用机器人文件上传
背景: 接上一篇 flask_apscheduler实现定时推送飞书消息,当检查出的异常结果比较多的时候,群里会有很多推送消息,一条条检查工作量会比较大,且容易出现遗漏。 现在需要将定时任务执行的结果记录到文件,…...

高版本Mac系统如何打开低版本的Xcode
这里写目录标题 前言解决方案 前言 大家偶尔也碰见过更新Mac系统后经常发现低版本的Xcode用不了的情况吧.基本每年大版本更新之后都可以在各个开发群里碰见问这个问题的. 解决方案 打开访达->应用程序->选中打不开的那个版本的Xcode并且右键显示包内容->Contents-…...

测试H5需要注意的交互测试用例点
H5(HTML5)是一种用于构建网页的标准,可以实现丰富的交互和功能。测试H5交互通常涉及到验证网页在各种情况下的行为,包括用户输入、按钮点击、页面加载等等。以下是一些可能的H5交互测试用例: 页面加载: 验…...

1014蓝桥算法双周赛,学习算法技巧,助力蓝桥杯
家人们,我来免费给大家送福利了!!! 【1014蓝桥算法双周赛 】 背景 蓝桥杯全国软件和信息技术专业人才大赛是由工业和信息化部人才交流中心举办的全国性IT学科赛事。参赛高校超过1200余所,累计参赛人数超过40万人。该…...
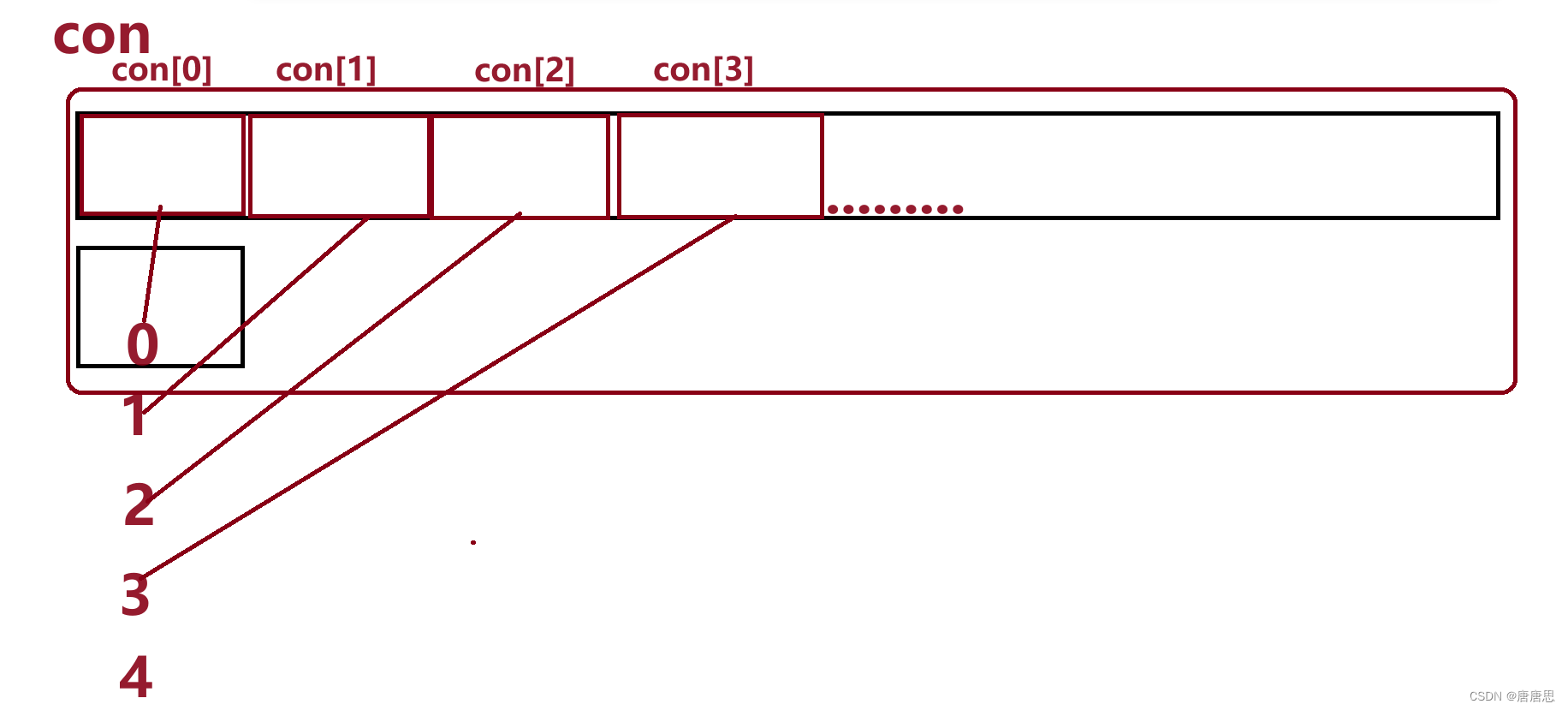
C语言之通讯录的实现篇
目录 test.c 主菜单menu 创建通讯录con 初始化通讯录InitContact 增加个人信息AddContact 展示个人信息ShowContact 删除个人信息DelContact 查找个人信息SearchContact 修改个人信息ModifyContact test.c总代码 contact.h 头文件包含 PeoInfo_个人信息的设置声…...
如何降低海康、大华等网络摄像头调用的高延迟问题(二)
目录 1.RTSP介绍 2.解决办法1 3.解决办法2 1.RTSP介绍 RTSP(Real-time Streaming Protocol)是一种用于实时流媒体传输的网络协议。它被设计用于在服务器和客户端之间传输音频、视频以及其他流媒体数据。 RTSP协议允许客户端通过与服务器建立RTSP会话…...

centos清理日志和缓存
今天使用redmine修改密码,修改报错,再去试试创建用户,创建用户的页面直接报错显示不出来。然后看了一下服务器,发现服务器磁盘空间全部占满了。 CentOS系统也会在使用很长一段时间后出现硬盘空间开始不够的情况,而这并…...

排序算法的稳定性
什么是排序算法的稳定性? 排序算法的稳定性: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i] r[j],且 r[i…...

kafka属性说明
kafka中关于一些字段说明 groupId :标识消费者分组id,如果多个消费者id相同,就表示这几个消费者是一组,当一组多个消费者消费同一个topic时,一组中只会有一个成功消费 代码如下 这时只会有一条消息被消费...

STM32F4使用ucosii时操作浮点数卡死的问题
STM32F4使用ucosii时操作浮点数卡死的问题_stm32 fpu float 程序跑不起来_shou撕代码的博客-CSDN博客...

python练习:赋值运算 => 输入身高,体重,求BMI = 体重(kg)/身高(m)的平方。
赋值运算 > 输入身高,体重,求BMI 体重(kg)/身高(m)的平方。 代码: height float(input(‘请输入您的身高(m):’)) weight float(input(‘请输入您的体重(kg):’))…...
)
PCL ICP精配准(点到点)
文章目录 一、简介二、实现过程三、实现效果参考资料一、简介 迭代最近点(ICP)算法作为是目前最常用的刚性点集配准方法,它有着简单、计算复杂度低等优点,该算法的具体计算过程如下: (1)在目标点云P中取点集 p i ∈ P p_i∈P p...
)
Redis数据缓存(Redis的缓存击穿和穿透的区别)
Redis是一个高性能的内存中数据存储系统,可以使用它作为数据缓存。使用Redis作为数据缓存可以提高应用程序的性能和可伸缩性,因为Redis运行在内存中,读写速度非常快。 Redis支持许多数据结构,如字符串、哈希表、列表、集合和有序…...

八大排序算法(含时间复杂度、空间复杂度、算法稳定性)
文章目录 八大排序算法(含时间复杂度、空间复杂度、算法稳定性)1、(直接)插入排序1.1、算法思想1.2、排序过程图解1.3、排序代码 2、希尔排序3、冒泡排序3.1、算法思想3.2、排序过程图解3.3、排序代码 4、(简单)选择排序4.1、算法…...
【C++】:引用的概念/引用的特性/常引用/引用的使用场景/传值与传引用的效率比较/引用和指针的区别/内联函数的概念/内联函数的特性
引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风&…...
点云地面点提取——基于格网算法)
Python点云处理(十七)点云地面点提取——基于格网算法
目录 0 简述1 算法流程2 优缺点3 实现4 效果5 结语0 简述 提取地面点是点云数据分析和处理中的重要任务,而点云格网法是一种常用的地面点提取方法。点云格网法(Grid-based Method),通过将点云数据划分为网格单元,根据高程值分析来实现地面点的提取。 1 算法流程 步骤1:…...

Flink 中kafka broker缩容导致Task一直重启
背景 Flink版本 1.12.2 Kafka 客户端 2.4.1 在公司的Flink平台运行了一个读Kafka计算DAU的流程序,由于公司Kafka的缩容,直接导致了该程序一直在重启,重启了一个小时都还没恢复(具体的所容操作是下掉了四台kafka broker࿰…...

纯前端js中使用sheetjs导出excel,并且合并标题
先定义变量----用的是Vue2 ,以下在vue的data:{}中定义--------------//空格占位符 headerTopTitle: [患者信息, , , , , , , , , 入出院信息, , , , , , , 病案首页中的出院主要诊断, ,出院其他诊断(病案首页中原始信息), , , , ,…...

突破百度网盘限速难题:非会员高速下载的技术实现与实战指南
突破百度网盘限速难题:非会员高速下载的技术实现与实战指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当你急需下载一份600MB的项目资料,却发现百…...

如何用OpenRGB终结RGB灯光控制混乱:终极跨平台解决方案
如何用OpenRGB终结RGB灯光控制混乱:终极跨平台解决方案 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. Relea…...

STM32环境监测系统在烟花爆竹仓库的应用
1. 项目概述与背景烟花爆竹作为一种特殊商品,其存储环境的安全管理一直是行业痛点。传统的人工巡检方式存在明显的滞后性——我曾亲眼见过一家小型烟花仓库因为夜间温湿度骤变而引发自燃,等值班人员发现时火势已难以控制。这个基于STM32的环境监测系统正…...
)
GESP三级语法知识(六、string 入门与基础操作)
🌟 第一课:《string 入门与基础操作》🏰 第一章:string 是什么?(升级版小火车)1、🎯 故事以前我们用的是:👉 char数组 小火车 🚂(要自…...

深入解析dlopen:动态库加载的机制与实践
1. 动态库加载的两种方式 在C/C开发中,动态库(Dynamic Library)的使用是提升代码复用性和灵活性的重要手段。动态库加载主要分为隐式链接和显式链接两种方式,它们各有特点,适用于不同场景。 隐式链接是最常见的方式&am…...

ESP32Cam与YOLOv3构建边缘图像识别系统
1. 项目概述:ESP32CamYOLOv3图像识别系统这个项目构建了一个完整的嵌入式图像识别系统,核心由ESP32Cam模块和YOLOv3算法组成。作为一名长期从事嵌入式视觉开发的工程师,我认为这种组合是目前性价比最高的边缘计算视觉方案之一。ESP32Cam模块集…...
)
Libero SoC v2021.1离线安装全攻略:从下载到IP核配置(附避坑指南)
Libero SoC v2021.1离线安装全攻略:从下载到IP核配置(附避坑指南) 在企业内网开发环境中,离线安装EDA工具往往面临诸多挑战。本文将手把手指导您完成Libero SoC v2021.1的完整离线部署流程,涵盖从安装包获取到IP核配置…...

2026年,江北高档 KTV 哪个好玩?这份实测推荐别错过!
2026 年,想在江北找个高档又好玩的 KTV 可不容易。其实,深海公馆娱乐会所就凭借多年行业经验,成了很多人的心头好。接下来,我就给大家分享一些 KTV 选择的干货。说实话,很多人去 KTV 都踩过不少坑。比如有些 KTV 装修看…...

【LangGraph】 官方demo调整为本地大模型实现
官网文档链接: https://docs.langchain.com/oss/python/langgraph/quickstart#full-code-example 样例代码: # 第一步:定义工具与大模型 # 导入LangChain工具装饰器,用于将普通函数封装为Agent可调用的工具 from langchain.tool…...

Blender3mfFormat插件:3MF文件处理全攻略
Blender3mfFormat插件:3MF文件处理全攻略 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 一、项目核心价值解析 Blender3mfFormat作为Blender的专业级3MF文件…...