Hadoop3教程(四):HDFS的读写流程及节点距离计算
文章目录
- (55)HDFS 写数据流程
- (56) 节点距离计算
- (57)机架感知(副本存储节点选择)
- (58)HDFS 读数据流程
- 参考文献
(55)HDFS 写数据流程
数据文件ss.avi是如何从客户端写到HDFS的?
完整流程见下图,接下来我们会按顺序详细捋一下
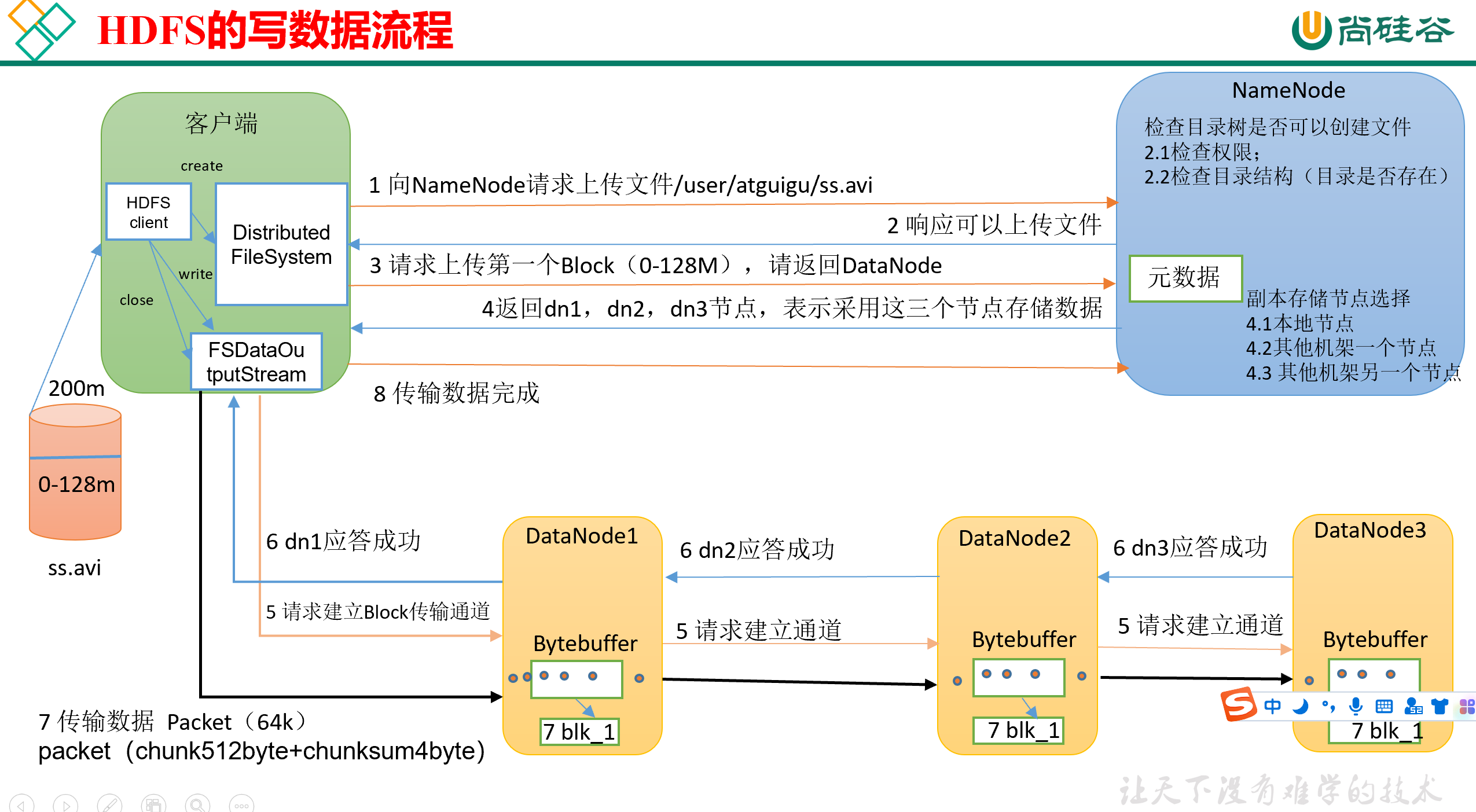
0)首先,客户端里需要有一个HDFS Client,这个HDFS客户端在创建的时候需要限制是Distributed FileSystem。(因为HDFS Client有很多种类型,默认是Local的)。
1)其次,向NameNode发送请求,请求将文件ss.avi发送到NameNode的指定目录下,这里假定是/user/atguigu/。
2)NameNode接收请求,并针对本次请求进行检查:
- 检查该客户端是否有权限在指定目录下写文件;
- 检查指定的目录树是否存在
然后,NameNode检查完之后,发回响应,通知Client可以上传文件。
3)再然后,Client接收到响应,请求上传第一个Block(0M~128M),要求NameNode返回存储用的DataNode位置。(即请求NameNode告知我应该往哪儿存)
4)接着,NameNode接收到请求,开始寻找合适的DataNode,并将其返回。默认情况下,HDFS是保留3个副本,因此会返回3个DataNode。
这里需要注意,NameNode挑选DataNode的时候,是有一个基本策略的,在3.x中,优先级从高到低是:
- 本地节点
- 其它机架的一个节点
- 其它机架(跟第二个相同)的另一个节点
而在2.x版本中,是按照:
- 本地节点
- 本地机架的另一个节点
- 其它机架的一个节点
这个之后会详细说明。
同时,DataNode的挑选也遵守负载均衡,某个节点存放的数据也不能过多。
5)再其次,Client接收到NameNode返回的DataNode名单之后,就会创建FSDataOutputStream,向名单里的DataNode写数据。
那Client具体是怎么往DataNode里写的呢?
Client只跟DataNode1建立Block传输通道,然后DataNode1跟DataNode2建立传输通道,DataNode2跟DataNode3建立传输通道,整个过程是一个串联的。
传输通道中,每次发送的数据量是一个Packet(64K),一个Packet包含若干个chunk(512B)+chunksum(4B的校验位)的组合,当一个Packet的大小达到了64K之后(chunk组合的数量够了),就可以发送了。
Client发送一个Packet之后,还会维护一个ACK缓冲队列,在里面备份刚才发送的Packet。
每次发送了一个packet之后,各个DataNode要按顺序返回应答。待到Client接收到最后的应答之后,就认为这个packet传输完成了,就会从ACK缓冲队列中删掉这个packet的备份。如果传输失败,则从ack队列中缓冲读取,继续发送。
为了加快传输速度,DataNode内部是边读边传边写,一边从管道里读一个Packet,一边往磁盘里写一个Packet,一边把内存中的Packet直接传给下面的DataNode。
6)当一个block传输完成后,客户端会再次请求NameNode上传第二个block,即从第3步开始重复执行,直到最后数据传输完成。
(56) 节点距离计算
在选择副本存储节点的时候,主要考虑节点的距离(越近越好) + 负载均衡(单个节点总负载不能太高)
如何计算两个服务器之间的节点距离呢?
所谓的节点距离就是,两个节点到达最近的公共祖先的距离之和。
计算距离的时候有些基本准则,跟树有些类似,整个架构的子孙关系是:
互联网 -> 集群(类似机房)-> 机架 -> 节点服务器
简单的说就是节点的直接祖先是机架,机架的直接祖先是集群。
每个节点服务器到自己机架的距离是1,到自己所在集群的距离是2,到整个互联网的距离是3。
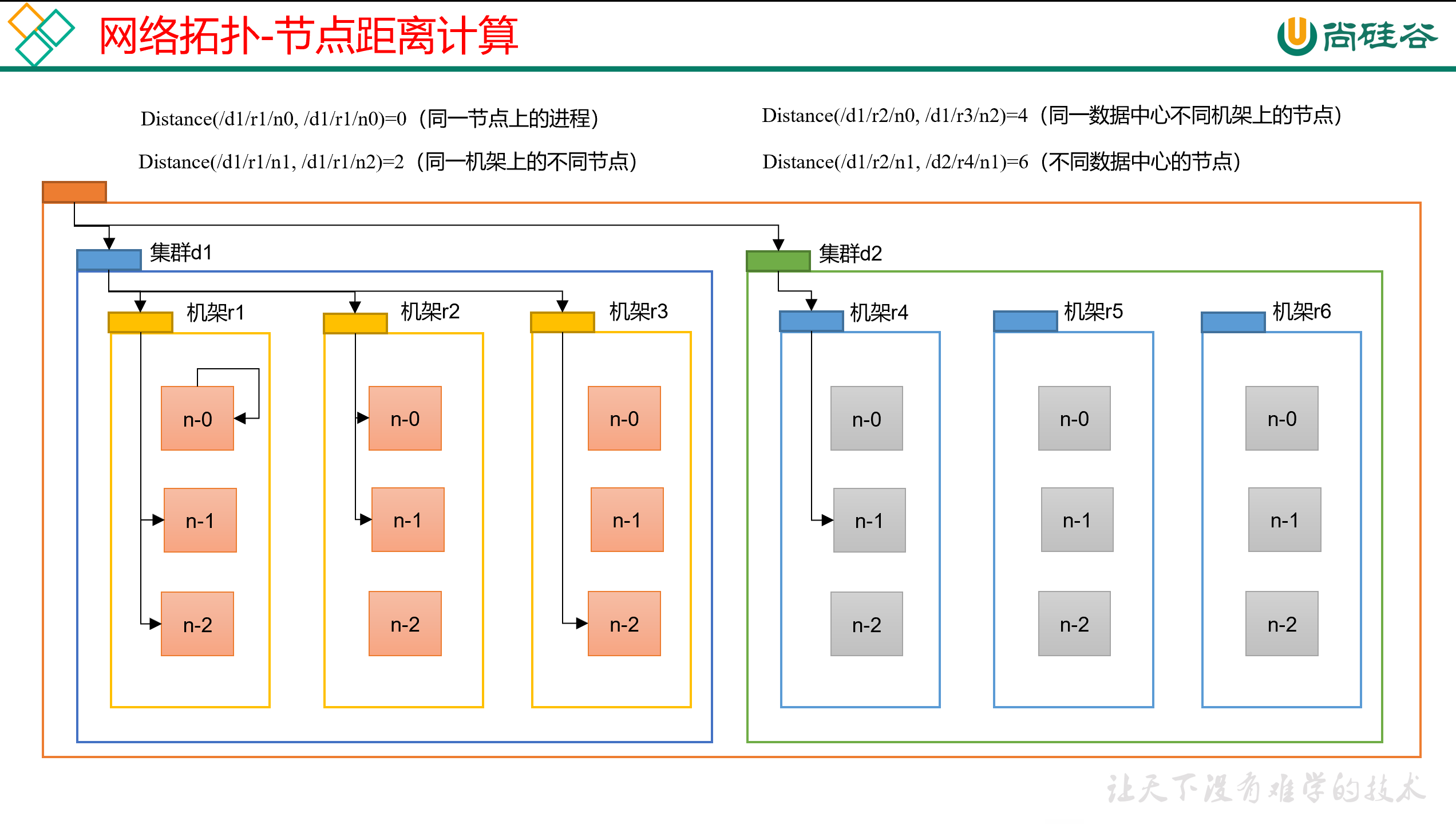
所以,结合图可见,节点间的距离其实是固定的:
- 同一节点的距离是0
- 同一机架上的两个节点,距离是2(共同祖先是机架,即节点1 -> 共同机架 -> 节点2);
- 同一集群,不同机架上的两个节点,距离是4(共同祖先是集群,即节点1 -> 机架1 -> 共同集群 -> 机架2 -> 节点2);
- 不同集群上的两个节点,距离是6(共同祖先是互联网,链路就不演示了);
(57)机架感知(副本存储节点选择)
即副本存储节点的选择策略
3.x的基本策略:
- 本地节点
- 其他机架上的一个节点(随机)
- 第二个副本所在机架上的另一个节点(随机)
所谓的本地节点,是指client的位置而言的,即client所在的节点视为是本地节点。
如果Client是在集群外,那就随便选一个节点作为本地节点。
这里其实有一个权衡,为了更加安全,所以第二个副本选择为另一个机架,防止前两个副本都在一个机架上,机架坏了,副本就没了。
但是如果是基于这种考虑,那第三个副本应该放在第3个机架上更安全啊,为什么要放在第2个机架上呢?
主要是考虑到效率问题,同机架内节点做数据传输更快,而且两个机架都出问题的情况比较少,所以就没必要那么谨慎的备份3个机架了。
(58)HDFS 读数据流程
我们有一个NameNode,和3个DataNode,现在想从DataNode下载一个ss.avi文件,完整流程见下图:
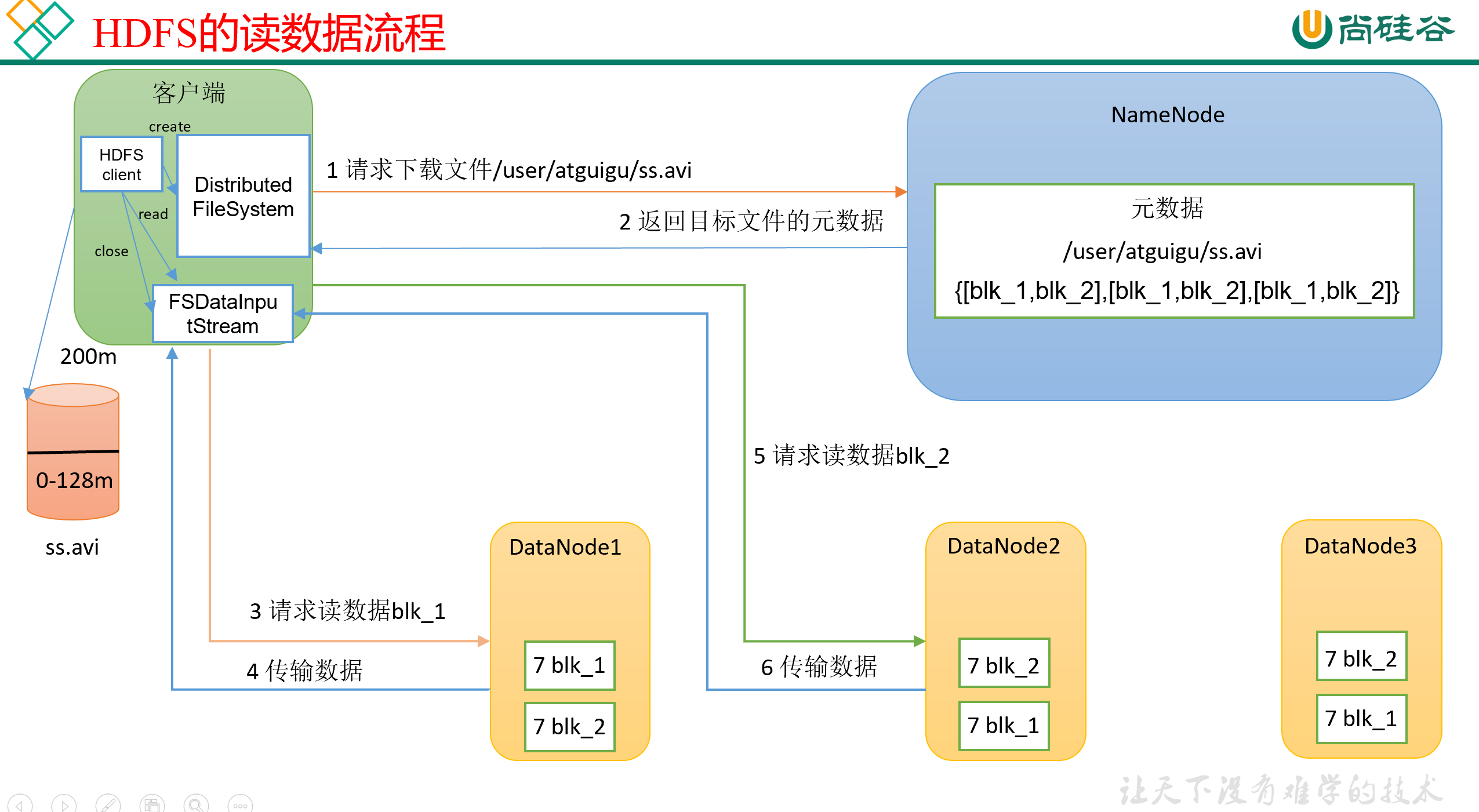
0)首先,客户端Client会生成一个Distributed FileSystem对象,来由它代表自己,对外做交互。
1)然后,Client会向NameNode发送文件的下载请求,比如说告诉它,我想下/user/atguigu/ss.avi这个文件;
2)NameNode接收到客户端的请求,然后就开始检查,自己目录里有没有这个文件、这个文件是不是这个客户端有权限下载的。如果这些检查都通过了,那么NameNode会把目标文件的元信息发送回Client。
3)Client接收到反馈,开始生成一个FSDataInputStream对象,来由它代表自己,对外建立数据传输。
注意,NameNode在反馈的时候,会把目前文件的所有副本地址都返回给Client,那 Client应该选择哪个或者哪些副本去读取呢? 这里是有两个基本原则的:
- 一般是选择节点距离最近的那个副本节点。
- 负载均衡。每个节点可接受的线程数是有上限的,如果最近的节点当前的任务已经超过负载的话,那就可以换到别的副本去读,加快速度。
然后,NameNode会向指定的副本节点发送读请求。
注意:Client在读的时候是串行读,第一块读完了之后再读第二块,不是咔咔咔开多个线程,好几块一起读。
为什么不并行读呢?大概是因为并行读没法保证拼接的顺序吧。
4)客户端以Packet为单位接收,先在本地缓存,最后再写入目标文件。
参考文献
- Hadoop2.x与Hadoop3.x副本选择机制
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(四):HDFS的读写流程及节点距离计算
文章目录 (55)HDFS 写数据流程(56) 节点距离计算(57)机架感知(副本存储节点选择)(58)HDFS 读数据流程参考文献 (55)HDFS 写数据流程 …...
[0xGameCTF 2023] web题解
文章目录 [Week 1]signinbaby_phphello_httprepo_leakping [Week 2]ez_sqli方法一(十六进制绕过)方法二(字符串拼接) ez_upload [Week 1] signin 打开题目,查看下js代码 在main.js里找到flag baby_php <?php /…...

Qt之submodule编译
工作中会遇到这样一种情况:qt应用程序在运行时提示找不到某个qt的动态库。我遇到的是缺少libQt5Websocket.so,因为应用程序是在x86平台银河麒麟v10上开发,能够正常编译运行,然后移植到rk3588(aarch64架构)上…...

Python实现带图形界面的计算器
Python实现带图形界面的计算器 在本文中,我们将使用Python编写一个带有图形用户界面的计算器程序。这个程序将允许用户通过点击按钮或键盘输入数字和操作符,并在显示屏上显示计算结果。 开发环境准备 要运行这个计算器程序,您需要安装Pyth…...
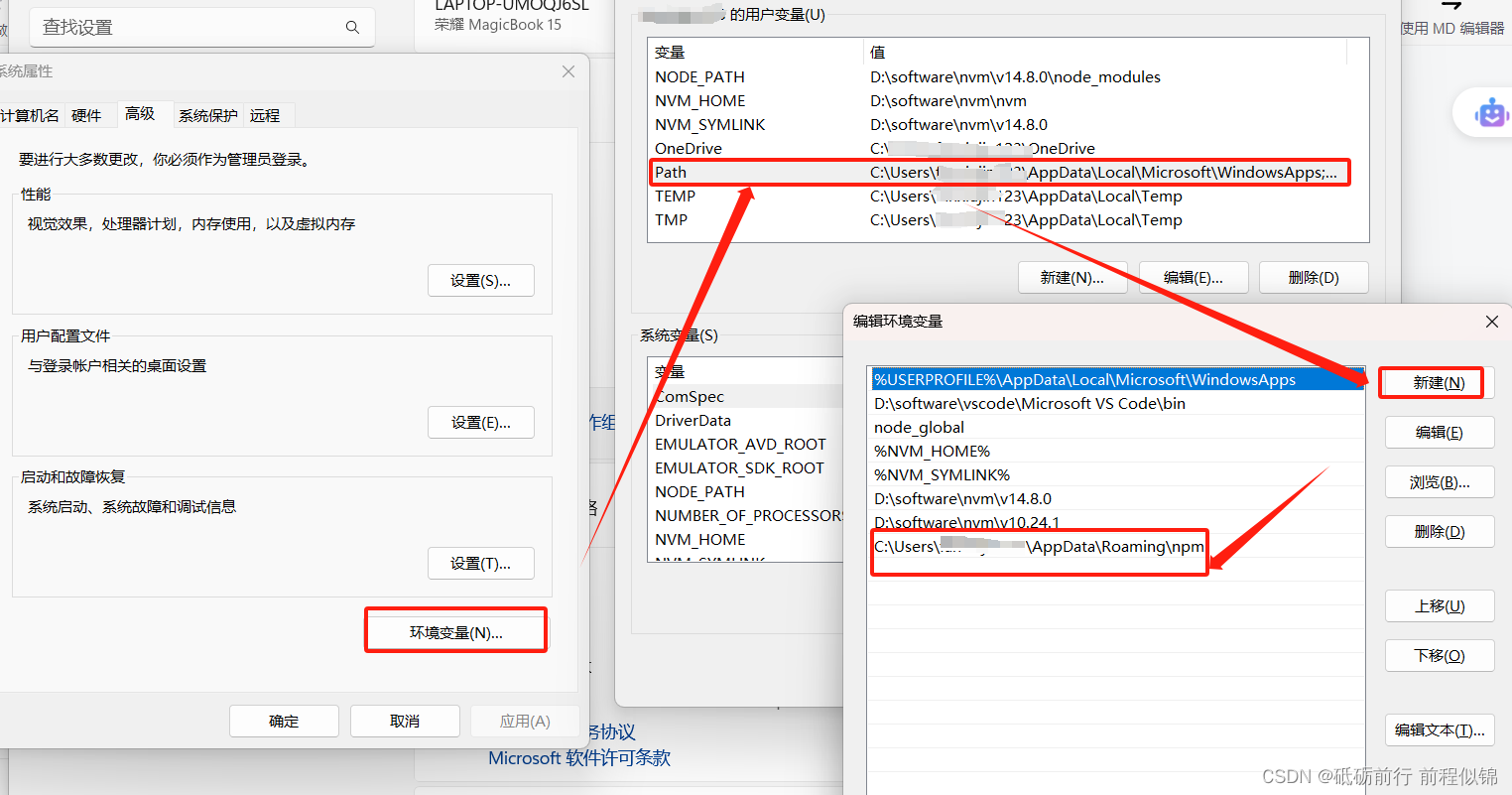
$ vue -Vbash: vue: command not found
$ vue -V bash: vue: command not found报这个错,我们需要找到vue安装路径,添加在环境变量的用户变量中: 1、vue安装路径 2、编辑环境变量 然后重新打开命令框,就可以了...

专业音视频领域中,Pro AV的崛起之路
编者按:在技术进步的加持下,AV行业发展得如何了?本文采访了两位深耕于广播电视行业的技术人,为我们介绍了专业音视频的进展:一位冉冉升起的新星:Pro AV以及FPGA在其中发挥的作用。 美国,拉斯维加…...
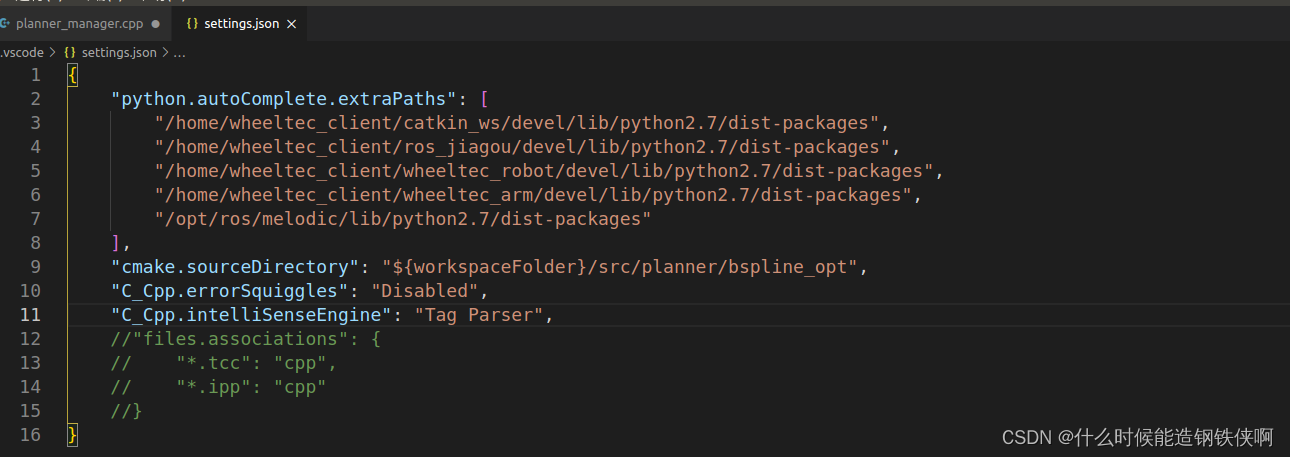
vscode 右侧滚动条标记不提示,问题解决纪录
问题描述 用vscode看代码时,我希望在右侧提示一个变量在文件下都在那里使用,在那里赋值,之前该功能是存在的,当我打开一个新的文件夹时这个功能消失了。 解决办法 在setting.json文件下输入 "C_Cpp.intelliSenseEngine&…...

【Java 进阶篇】JavaScript特殊语法详解
JavaScript是一门非常灵活的编程语言,允许开发人员使用多种不同的语法和技巧来解决各种问题。本篇博客将深入探讨JavaScript中的一些特殊语法,这些语法可能不是常规的JavaScript编程知识,但它们对于理解语言的强大之处以及在某些情况下解决问…...

PCL点云处理之配准中的匹配对连线可视化显示 Correspondences(二百一十九)
PCL点云处理之配准中的匹配对连线可视化显示 Correspondences(二百一十九) 一、算法介绍二、算法实现1.可视化代码2.完整代码(特征匹配+可视化)最终效果一、算法介绍 关于点云配准中的匹配对,如果能够可视化将极大提高实验的准确性,还好PCL提供了这样的可视化工具,做法…...

Vue el-table全表搜索,模糊匹配-前端静态查询
后端返回的数据是全部的数据,没有分页,前端需要做的是分页全表模糊查询 代码: //根据关键字对表全局搜索 globalSearch() {//为了拿到对象的列名let filterList Object.keys(this.tableData[0]);if (this.searchWord) {this.tableFilterDat…...

基于html5开发的Win12网页版,抢先体验
据 MSPoweruser 报道,Windows 11虽然刚刚开始步入正轨,但最新爆料称微软已经在开启下一个计划,Windows 12 的开发将在 去年3 月份开始。德国科技网站 Deskmodder.de 称,根据内部消息,微软将在 2022年3 月开始开发 Wind…...
Studio One6.5中文版本下载安装步骤
在唱歌效果调试当中,我们经常给客户安装的几款音频工作站。第一,Studio One 6是PreSonus公司开发的一款功能强大的音频工作平台,具有丰富的音频处理功能和灵活的工作流程。以下是Studio One6的一些主要特点: 1.多轨录音和编辑&…...

Java架构师缓存架构设计解决方案
目录 1 缓存常见的三大问题1.1 缓存雪崩1.2 缓存穿透1.3 缓存击穿2 缓存key的生成策略3 热点数据集中失效的问题4 如何提高缓存的命中率5 缓存和数据库双写不一致的问题6 如何对缓存数据进行分片想学习架构师构建流程请跳转:Java架构师系统架构设计 1 缓存常见的三大问题 缓…...

【玩转Redhat Linux 8.0系列 | 实验—使用Bash shell执行命令】
今天继续分享一些Redhat Linux 8.0的知识,记得关注,会一直更新~ 访问命令行 任务执行清单 在本实验中,您将使用Bash shell来执行命令。 成果 使用Bash shell命令行成功运行简单的程序。 执行用于识别文件类型并显示文本文件部分内容的命…...

Linux系统编程详解
Linux 多线程编程 什么是线程? 与线程类似,线程是允许应用程序并发执行多个任务的一种机制 线程是轻量级的进程(LWP:Light Weight Process),在 Linux 环境下线程的本 质仍是进程。 一个进程可以包含多个线…...

ios设备管理软件iMazing 2.17.11官方中文版新增功能介绍
iMazing 2.17.11官方中文版(ios设备管理软件)是一款管理苹果设备的软件, Windows 平台上的一款帮助用户管理 IOS 手机的应用程序,软件功能非常强大,界面简洁明晰、操作方便快捷,设计得非常人性化。iMazing官方版与苹果设备连接后&…...
算法通关村第18关【青铜】| 回溯
回溯算法是一种解决组合优化问题和搜索问题的算法。它通过尝试各种可能的选择来找到问题的解决方案。回溯算法通常用于问题的解空间非常大,而传统的穷举法会导致计算时间爆炸的情况。回溯算法可以帮助限制搜索空间,以提高效率。 回溯算法的核心思想是在…...

【环境搭建】linux docker-compose安装seata1.6.1,使用nacos注册、db模式
新建目录,挂载用 mkdir -p /data/docker/seata/resources mkdir -p /data/docker/seata/logs 给权限 chmod -R 777 /data/docker/seata 先在/data/docker/seata目录编写一个使用file启动的docker-compose.yml文件(seata包目录的script文件夹有&#…...

20231008-20231013 读书笔记
计算机硬件 基本硬件系统:运算器、控制器、存储器、输入设备和输出设备中央处理单元(CPU):运算器、控制器、寄存器组和内部总线等部件组成 功能:程序控制、操作控制、时间控制、数据处理运算器:ALU、AC、DR、PSW控制器…...

YOLOv8 windows下的离线安装 offline install 指南 -- 以 带有CUDA版本的pytorch 为例
文章大纲 简介基础环境与安装包的准备windows 下 lap 包的离线安装conda 打包基础环境使用 pip 下载 whl 包特别的注意:pytorch cuda 版本的下载迁移与部署流程基础python 的conda 环境迁移与准备必备包: 安装cuda 版本 的torch,torchvision,ultralytics参考文献与学习路径…...

10分钟掌握Unity口型动画神器:LipSync完全使用指南
10分钟掌握Unity口型动画神器:LipSync完全使用指南 【免费下载链接】LipSync LipSync for Unity3D 根据语音生成口型动画 支持fmod 项目地址: https://gitcode.com/gh_mirrors/lip/LipSync 还在为角色口型动画制作而烦恼吗?LipSync for Unity3D 是…...
)
ISE 14.7 最后的倔强:手把手教你给CPLD烧录程序(附JTAG连接避坑指南)
ISE 14.7 最后的倔强:手把手教你给CPLD烧录程序(附JTAG连接避坑指南) 在Vivado大行其道的今天,ISE 14.7这个"老古董"依然活跃在某些工程师的工作站上。这不是技术怀旧,而是实实在在的工程需求——当你面对一…...
期刊论文功能全拆解)
书匠策AI(http://www.shujiangce.com)期刊论文功能全拆解
哈喽,我是那个专门帮你把论文写作这件事"翻译成人话"的博主。 今天不画饼,不喊口号,就干一件事——把书匠策AI( 官网直达:www.shujiangce.com微信搜一搜"书匠策AI"直达)里的期刊论文功…...
算法揭秘)
【LeetCode刷题日记】222.极速计算完全二叉树节点数:O(log²n)算法揭秘
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

3分钟掌握音乐文件解密:NCM加密格式终极转换指南
3分钟掌握音乐文件解密:NCM加密格式终极转换指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾在网易云音乐下载了心爱的歌曲,却发现只能在官方App中播放?那些神秘的NCM格式文件就像被锁…...

AI智能体编排框架实战:构建具备记忆与协作能力的智能系统
1. 项目概述:当AI智能体需要“记忆”与“协作”在AI智能体开发领域,我们常常面临一个核心挑战:如何让智能体不仅能在单次对话中表现出色,还能记住历史、规划未来,并与其他智能体协同工作?这就像组建一支足球…...

Piccolo-FIM:DRAM细粒度访问优化技术解析
1. 现代DRAM架构的细粒度访问挑战在传统DRAM架构中,数据访问的最小单位通常是一个完整的行(Row),这种粗粒度的访问机制在处理图计算等不规则访问模式时暴露出了明显的效率问题。当需要随机访问内存中的离散数据时,系统…...

微博图片智能采集器:一键构建你的专属视觉素材库
微博图片智能采集器:一键构建你的专属视觉素材库 【免费下载链接】weibo-image-spider 微博图片爬虫,极速下载、高清原图、多种命令、简单实用。 项目地址: https://gitcode.com/gh_mirrors/we/weibo-image-spider 还在为手动保存微博图片而烦恼吗…...

豆包大模型免费API调用实战:逆向工程原理、集成方案与风险规避
1. 项目概述与核心价值最近在折腾大模型应用开发的朋友,估计都绕不开一个核心问题:API调用成本。无论是做个人项目练手,还是小团队内部测试,动辄按token计费的商业API,账单看着都让人心疼。特别是当你需要频繁调用、进…...

当计算机视觉模型开始“打架”:对抗性攻击与鲁棒性研究
摘要随着计算机视觉模型在安全敏感场景(如自动驾驶、人脸识别、安防监控)中的广泛应用,模型的脆弱性问题日益凸显。“打架”在这里并非字面意义的冲突,而是指对抗性攻击(Adversarial Attacks)与防御机制&am…...