【深度学习实验】循环神经网络(四):基于 LSTM 的语言模型训练
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. RNN与梯度裁剪
2. LSTM模型
3. 训练函数
a. train_epoch
b. train
4. 文本预测
5. GPU判断函数
6. 训练与测试
7. 代码整合
经验是智慧之父,记忆是智慧之母。
——谚语
一、实验介绍
基于 LSTM 的语言模型训练
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入必要的工具包
import torch
from torch import nn
from d2l import torch as d2l1. RNN与梯度裁剪
【深度学习实验】循环神经网络(一):循环神经网络(RNN)模型的实现与梯度裁剪_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133742433?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133742433?spm=1001.2014.3001.5501
2. LSTM模型
【深度学习实验】循环神经网络(三):门控制——自定义循环神经网络LSTM(长短期记忆网络)模型-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133864731?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133864731?spm=1001.2014.3001.5501
3. 训练函数
a. train_epoch
def train_epoch(net, train_iter, loss, updater, device, use_random_iter):state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * d2l.size(y), d2l.size(y))return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()-
参数:
net:神经网络模型train_iter:训练数据迭代器loss:损失函数updater:更新模型参数的方法(如优化器)device:计算设备(如CPU或GPU)use_random_iter:是否使用随机抽样
-
函数内部定义了一些辅助变量:
state:模型的隐藏状态变量timer:计时器,用于记录训练时间metric:累加器,用于计算训练损失之和和词元数量
-
函数通过迭代
train_iter中的数据进行训练。每次迭代中,执行以下步骤:- 如果是第一次迭代或者使用随机抽样,则初始化隐藏状态
state - 如果
net是nn.Module的实例并且state不是元组类型,则将state的梯度信息清零(detach_()函数用于断开与计算图的连接,并清除梯度信息) - 对于其他类型的模型(如
nn.LSTM或自定义模型),遍历state中的每个元素,将其梯度信息清零 - 将输入数据
X和标签Y转移到指定的计算设备上 - 使用神经网络模型
net和当前的隐藏状态state进行前向传播,得到预测值y_hat和更新后的隐藏状态state - 计算损失函数
loss对于预测值y_hat和标签y的损失,并取均值 - 如果
updater是torch.optim.Optimizer的实例,则执行优化器的相关操作(梯度清零、梯度裁剪、参数更新) - 否则,仅执行梯度裁剪和模型参数的更新(适用于自定义的更新方法)
- 将当前的损失值乘以当前批次样本的词元数量,累加到
metric中
- 如果是第一次迭代或者使用随机抽样,则初始化隐藏状态
-
训练完成后,函数返回以下结果:
- 对数似然损失的指数平均值(通过计算
math.exp(metric[0] / metric[1])得到) - 平均每秒处理的词元数量(通过计算
metric[1] / timer.stop()得到)
- 对数似然损失的指数平均值(通过计算
b. train
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)for epoch in range(num_epochs):ppl, speed = train_epoch(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, [ppl])print('Train Done!')torch.save(net.state_dict(), 'chapter6.pth')print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
- 参数
net(神经网络模型)train_iter(训练数据迭代器)vocab(词汇表)lr(学习率)num_epochs(训练的轮数)device(计算设备)use_random_iter(是否使用随机抽样)。
- 在函数内部,它使用交叉熵损失函数(
nn.CrossEntropyLoss())计算损失,创建了一个动画器(d2l.Animator)用于可视化训练过程中的困惑度(perplexity)指标。 - 根据
net的类型选择相应的更新器(updater)- 如果
net是nn.Module的实例,则使用torch.optim.SGD作为更新器; - 否则,使用自定义的更新器(
d2l.sgd)。
- 如果
- 通过迭代训练数据迭代器
train_iter来进行训练。在每个训练周期(epoch)中- 调用
train_epoch函数来执行训练,并得到每个周期的困惑度和处理速度。 - 每隔10个周期,将困惑度添加到动画器中进行可视化。
- 调用
- 训练完成后,打印出训练完成的提示信息,并将训练好的模型参数保存到文件中('chapter6.pth')。
- 打印出困惑度和处理速度的信息。
4. 文本预测
定义了给定前缀序列,生成后续序列的predict函数。
def predict(prefix, num_preds, net, vocab, device):state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.reshape(torch.tensor([outputs[-1]], device=device), (1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])- 使用指定的
device和批大小为1调用net.begin_state(),初始化state变量。 - 使用
vocab[prefix[0]]将第一个标记在prefix中对应的索引添加到outputs列表中。 - 定义了一个
get_input函数,该函数返回最后一个输出标记经过reshape后的张量,作为神经网络的输入。 - 对于
prefix中除第一个标记外的每个标记,通过调用net(get_input(), state)进行前向传播。忽略输出的预测结果,并将对应的标记索引添加到outputs列表中。
5. GPU判断函数
def try_gpu(i=0):"""如果存在,则返回gpu(i),否则返回cpu()"""if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')6. 训练与测试
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_epochs, lr= 28, 256, 200, 1
device = try_gpu()
lstm_layer = nn.LSTM(vocab_size, num_hiddens)
model_lstm = RNNModel(lstm_layer, vocab_size)
train(model_lstm, train_iter, vocab, lr, num_epochs, device)-
训练中每个小批次(batch)的大小和每个序列的时间步数(time step)的值分别为32,25
-
加载的训练数据迭代器和词汇表
-
vocab_size是词汇表的大小,num_hiddens是 LSTM 隐藏层中的隐藏单元数量,num_epochs是训练的迭代次数,lr是学习率。 -
选择可用的 GPU 设备进行训练,如果没有可用的 GPU,则会使用 CPU。
-
训练模型
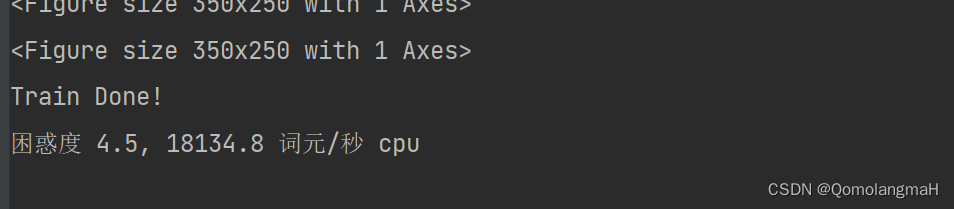
7. 代码整合
# 导入必要的库
import torch
from torch import nn
import torch.nn.functional as F
from d2l import torch as d2l
import mathclass LSTM(nn.Module):def __init__(self, input_size, hidden_size):super(LSTM, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_size# 初始化模型,即各个门的计算参数self.W_i = nn.Parameter(torch.randn(input_size, hidden_size))self.W_f = nn.Parameter(torch.randn(input_size, hidden_size))self.W_o = nn.Parameter(torch.randn(input_size, hidden_size))self.W_a = nn.Parameter(torch.randn(input_size, hidden_size))self.U_i = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_f = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_o = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_a = nn.Parameter(torch.randn(hidden_size, hidden_size))self.b_i = nn.Parameter(torch.randn(1, hidden_size))self.b_f = nn.Parameter(torch.randn(1, hidden_size))self.b_o = nn.Parameter(torch.randn(1, hidden_size))self.b_a = nn.Parameter(torch.randn(1, hidden_size))self.W_h = nn.Parameter(torch.randn(hidden_size, hidden_size))self.b_h = nn.Parameter(torch.randn(1, hidden_size))# 初始化隐藏状态def init_state(self, batch_size):hidden_state = torch.zeros(batch_size, self.hidden_size)cell_state = torch.zeros(batch_size, self.hidden_size)return hidden_state, cell_statedef forward(self, inputs, states=None):batch_size, seq_len, input_size = inputs.shapeif states is None:states = self.init_state(batch_size)hidden_state, cell_state = statesoutputs = []for step in range(seq_len):inputs_step = inputs[:, step, :]i_gate = torch.sigmoid(torch.mm(inputs_step, self.W_i) + torch.mm(hidden_state, self.U_i) + self.b_i)f_gate = torch.sigmoid(torch.mm(inputs_step, self.W_f) + torch.mm(hidden_state, self.U_f) + self.b_f)o_gate = torch.sigmoid(torch.mm(inputs_step, self.W_o) + torch.mm(hidden_state, self.U_o) + self.b_o)c_tilde = torch.tanh(torch.mm(inputs_step, self.W_a) + torch.mm(hidden_state, self.U_a) + self.b_a)cell_state = f_gate * cell_state + i_gate * c_tildehidden_state = o_gate * torch.tanh(cell_state)y = torch.mm(hidden_state, self.W_h) + self.b_houtputs.append(y)return torch.cat(outputs, dim=0), (hidden_state, cell_state)class RNNModel(nn.Module):def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_sizeself.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, state# 在第一个时间步,需要初始化一个隐藏状态,由此函数实现def begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)for epoch in range(num_epochs):ppl, speed = train_epoch(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, [ppl])print('Train Done!')torch.save(net.state_dict(), 'chapter6.pth')print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')def train_epoch(net, train_iter, loss, updater, device, use_random_iter):state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * d2l.size(y), d2l.size(y))return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()def predict(prefix, num_preds, net, vocab, device):state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.reshape(torch.tensor([outputs[-1]], device=device), (1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])def grad_clipping(net, theta):if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / normdef try_gpu(i=0):"""如果存在,则返回gpu(i),否则返回cpu()"""# if torch.cuda.device_count() >= i + 1:# return torch.device(f'cuda:{i}')return torch.device('cpu')batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_epochs, lr= 28, 256, 200, 1
device = try_gpu()
lstm_layer = nn.LSTM(vocab_size, num_hiddens)
model_lstm = RNNModel(lstm_layer, vocab_size)
train(model_lstm, train_iter, vocab, lr, num_epochs, device)相关文章:
【深度学习实验】循环神经网络(四):基于 LSTM 的语言模型训练
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. RNN与梯度裁剪 2. LSTM模型 3. 训练函数 a. train_epoch b. train 4. 文本预测 5. GPU判断函数 6. 训练与测试 7. 代码整合 经验是智慧之父,记忆…...

IOS课程笔记[1-3] 第一个IOS应用
安装开发环境 安装Xcode软件 历史版本查找 https://developer.apple.com/download/all/?qdebug 创建Object-C项目 启动过程 步骤 1.加载Main中定义的storyBoard 2.加载Main控制器 3.加载控制器下的View组件显示 获取控件的两种方式 定义属性连线:property (…...

Flink的基于两阶段提交协议的事务数据汇实现
背景 在flink中可以通过使用事务性数据汇实现精准一次的保证,本文基于Kakfa的事务处理来看一下在Flink 内部如何实现基于两阶段提交协议的事务性数据汇. flink kafka事务性数据汇的实现 1。首先在开始进行快照的时候也就是收到checkpoint通知的时候,在…...
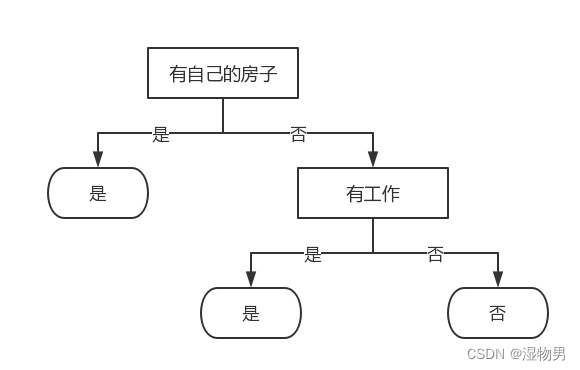
树模型(三)决策树
决策树是什么?决策树(decision tree)是一种基本的分类与回归方法。 长方形代表判断模块 (decision block),椭圆形成代表终止模块(terminating block),表示已经得出结论,可以终止运行。从判断模块引出的左右箭头称作为分支(branch)…...

vueday01——使用属性绑定+ref属性定位获取id
1.属性绑定(Attribute 绑定) 第一种写法 <div v-bind:id"refValue"> content </div> 第二种写法(省略掉v-bind) <div :id"refValue"> content </div> 2.代码展示 <template…...

LeetCode 260. 只出现一次的数字 III:异或
【LetMeFly】260.只出现一次的数字 III 力扣题目链接:https://leetcode.cn/problems/single-number-iii/ 给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返…...

使用PyTorch解决多分类问题:构建、训练和评估深度学习模型
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
基于nodejs+vue网课学习平台
各功能简要描述如下: 1个人信息管理:包括对学生用户、老师和管理员的信息进行录入、修改,以及老师信息的审核等 2在库课程查询:用于学生用户查询相关课程的功能 3在库老师查询:用于学生用户查询相关老师教学的所有课程的功能。 4在库学校查询:用于学生用户查询相关学…...
、条款14(基类有虚析构))
读书笔记:Effective C++ 2.0 版,条款13(初始化顺序==声明顺序)、条款14(基类有虚析构)
条款13: 初始化列表中成员列出的顺序和它们在类中声明的顺序相同 类成员是按照它们在类里被声明的顺序进行初始化的,和它们在成员初始化列表中列出的顺序没一点关系。 根本原因可能是考虑到内存的分布,按照定义顺序进行排列。 另外,初始化列表…...

flutter开发实战-下拉刷新与上拉加载更多实现
flutter开发实战-下拉刷新与上拉加载更多实现 在开发中经常遇到列表需要下拉刷新与上拉加载更多,这里使用EasyRefresh,版本是3.3.21 一、什么是EasyRefresh EasyRefresh可以在Flutter应用程序上轻松实现下拉刷新和上拉加载。它几乎支持所有Flutter Sc…...
旧手机热点机改造成服务器方案
如果你也跟我一样有这种想法, 那真的太酷了!!! ok,前提是得有root,不然体验大打折扣 目录 目录 1.做一个能爬墙能走百度直连的热点机(做热点机用) 2.做emby视频服务器 3.做文件服务, 存取文件 4.装青龙面板,跑一些定时任务 5.做远程摄像头监控 6.做web服务器 7.内网穿…...
网工实验笔记:策略路由PBR的应用场景
一、概述 PBR(Policy-Based Routing,策略路由):PBR使得网络设备不仅能够基于报文的目的IP地址进行数据转发,更能基于其他元素进行数据转发,例如源IP地址、源MAC地址、目的MAC地址、源端口号、目的端口号、…...

webrtc快速入门——使用 WebRTC 拍摄静止的照片
文章目录 使用 getUserMedia() 拍摄静态照片HTML 标记JavaScript 代码初始化startup() 函数获取元素引用获取流媒体 监听视频开始播放处理按钮上的点击包装 startup() 方法 清理照片框从流中捕获帧 例子代码HTML代码CSS代码JavaScript代码 过滤器使用特定设备 使用 getUserMedi…...

预约按摩app软件开发定制足浴SPA上们服务小程序
同城按摩小程序是一种基于地理位置服务的小程序,它可以帮助用户快速找到附近的按摩师,并提供在线预约、评价、支付等功能。用户可以通过手机或者其他移动设备访问同城按摩小程序,实现足不出户就能预约到专业的按摩服务。 一、同城按摩小程序的…...
jenkins出错与恢复
如果你的jenkins出现了如下图所示问题(比如不能下载插件,无法保存任务等),这个时候就需要重新安装了。 一、卸载干净jenknis 要彻底卸载 Jenkins,您可以按照以下步骤进行操作: 1、停止 Jenkins 服务&…...

ssh免密登录的原理RSA非对称加密的理解
RSA非对称加密,是采用公钥加密私钥解密的原则。 举个例子SSH的免密登录 SSH免密登录是通过使用公钥加密技术实现的。以下是SSH免密登录的原理: 1. 生成密钥对:首先,在客户端上生成一对密钥,包括一个私钥和一个公钥。私…...
【监督学习】基于合取子句进化算法(CCEA)和析取范式进化算法(DNFEA)解决分类问题(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

力扣每日一题41:缺失的第一个正数
题目描述: 给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3示例 2: 输…...

OpenCV与mediapipe实践
1. 安装前准备 开发环境:vscode venv 设置vscode, 建立项目,如: t1/src, 用vscode打开,新建终端Terminal,这时可能会有错误产生,解决办法: 运行命令:Set-ExecutionPolicy -ExecutionPolicy …...
【css拾遗】粘性布局实现有滚动条的情况下,按钮固定在页面底部展示
效果: 滚动条滚动过程中,按钮的位置位于手机的底部 滚动条滚到底部时,按钮的位置正常 这个position:sticky真的好用,我原先的想法是利用滚动条滚动事件去控制,没想到css就可以解决 <template><view class…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...