【LeetCode刷题(数据结构与算法)】:用队列实现栈

请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶
int pop() 移除并返回栈顶元素
int top() 返回栈顶元素
boolean empty() 如果栈是空的,返回 true ;否则,返回 false
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty 这些操作
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可
示例:
输入:
[“MyStack”, “push”, “push”, “top”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
提示:
1 <= x <= 9
最多调用100 次 push、pop、top 和 empty
每次调用 pop 和 top 都保证栈不为空
这里有一个动图我一会儿上传到评论区大家可以看一下加深理解
为了满足栈的特性,即最后入栈的元素最先出栈,在使用队列实现栈时,应满足队列前端的元素是最后入栈的元素。可以使用两个队列实现栈的操作,其中 queue1
用于存储栈内的元素,queue2
作为入栈操作的辅助队列
入栈操作时,首先将元素入队到 queue2
然后将 queue1
的全部元素依次出队并入队到 queue2
此时queue2
的前端的元素即为新入栈的元素,再将 queue1
和queue2
互换,则queue1
的元素即为栈内的元素,queue1
的前端和后端分别对应栈顶和栈底
由于每次入栈操作都确保 queue1
的前端元素为栈顶元素,因此出栈操作和获得栈顶元素操作都可以简单实现。出栈操作只需要移除 queue1
的前端元素并返回即可,获得栈顶元素操作只需要获得 queue1
的前端元素并返回即可(不移除元素)
由于 queue1
用于存储栈内的元素,判断栈是否为空时,只需要判断 queue1
是否为空即可
动图链接
动图链接
#include<stdlib.h>
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>typedef int QueueDataType;typedef struct QNode
{struct QNode* next;QueueDataType data;
}QueueNode;typedef struct Queue
{QueueNode* head;QueueNode* tail;QueueDataType size;
}Que;
void QueueInit(Que* pq);void QueuePush(Que* pq, QueueDataType x);void QueuePop(Que* pq);void QueueDestroy(Que* pq);QueueDataType QueueFront(Que* pq);QueueDataType QueueBack(Que* pq);bool QueueEmpty(Que* pq);QueueDataType QueueSize(Que* pq);//#include"Queue.h"void QueueInit(Que* pq)
{assert(pq);pq->head = pq->tail = NULL;pq->size =0;
}void QueuePush(Que* pq, QueueDataType x)
{assert(pq);QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));if (newnode == NULL){perror("malloc fail\n");exit(-1);}newnode->data = x;newnode->next = NULL;if (pq->head == NULL && pq->tail == NULL){pq->head = pq->tail = newnode;}else{pq->tail->next = newnode;//tail指针指向下一个结构体---//--存放地址pq->tail = newnode;//尾节点}pq->size++;
}void QueuePop(Que* pq)
{assert(pq);//assert(!QueueEmpty(Que * pq));//写法错误 不允许使用类命名assert(!QueueEmpty(pq));if (pq->head->next == NULL){free(pq->head);pq->head = pq->tail = NULL;}else{QueueNode* next = pq->head->next;free(pq->head);pq->head = next;}pq->size--;
}QueueDataType QueueFront(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->head->data;
}QueueDataType QueueBack(Que* pq)
{assert(pq);assert(!QueueEmpty(pq));return pq->tail->data;
}bool QueueEmpty(Que* pq)
{assert(pq);return pq->head == NULL;
}QueueDataType QueueSize(Que* pq)
{assert(pq);return pq->size;
}void QueueDestroy(Que* pq)
{assert(pq);//assert(!QueueEmpty(pq));QueueNode* current = pq->head;while (current){QueueNode* next = current->next;free(current);current = next;}pq->head = pq->tail = NULL;pq->size = 0;
}typedef struct {Que q1;Que q2;
}MyStack;MyStack* myStackCreate() {//动态内存开辟函数malloc在堆区 无free不会主动销毁MyStack*pst=(MyStack*)malloc(sizeof(MyStack)*2);QueueInit(&pst->q1);QueueInit(&pst->q2);return pst;//避免野指针NULL
}void myStackPush(MyStack* obj, int x) {if(!QueueEmpty(&obj->q1)){QueuePush(&obj->q1,x);}else{QueuePush(&obj->q2,x);}
}int myStackPop(MyStack* obj) {Que*Empty=&obj->q1;Que*NonEmpty=&obj->q2;if(!QueueEmpty(&obj->q1)){NonEmpty=&obj->q1;Empty=&obj->q2;}while(QueueSize(NonEmpty)>1){QueuePush(Empty,QueueFront(NonEmpty));QueuePop(NonEmpty);}//题目要求移除并返回栈顶元素topint top=QueueFront(NonEmpty);QueuePop(NonEmpty);return top;
}int myStackTop(MyStack* obj) {if(!QueueEmpty(&obj->q1)){return QueueBack(&obj->q1);}else {return QueueBack(&obj->q2);}
}bool myStackEmpty(MyStack* obj) {return QueueEmpty(&obj->q1)&&QueueEmpty(&obj->q2);
}void myStackFree(MyStack* obj) {QueueDestroy(&obj->q1);QueueDestroy(&obj->q2);free(obj);obj=NULL;
}/*** Your MyStack struct will be instantiated and called as such:* MyStack* obj = myStackCreate();* myStackPush(obj, x);* int param_2 = myStackPop(obj);* int param_3 = myStackTop(obj);* bool param_4 = myStackEmpty(obj);* myStackFree(obj);
*/
相关文章:
【LeetCode刷题(数据结构与算法)】:用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty) 实现 MyStack 类: void push(int x) 将元素 x 压入栈顶 int pop() 移除并返回栈顶元素 int top() 返…...

“客户端到服务器的数据传递”和“服务器上的数据传递”这两种数据传递的方式的区别
“客户端到服务器的数据传递”和“服务器上的数据传递”这两种数据传递方式的主要区别如下: 数据的流动方向: 在“客户端到服务器的数据传递”中,数据是从客户端(如浏览器)流向服务器。在“服务器上的数据传递”中&…...

LCR 181 字符串中的单词反转
题目来源: leetcode题目,网址:LCR 181. 字符串中的单词反转 - 力扣(LeetCode) 解题思路: 倒叙遍历,获得每个单词的起始位置与终止位置,然后将每次遇到的单词插入结果中。 解题…...

百度OCR识别图片文本字符串——物联网上位机软件
一、开发背景 根据项目需求,我们需要完成LED显示屏实时显示歌词的效果。最优的方法是调用歌曲播放器的API获取歌词,但是由于这个开发资格不是很好申请,因此我们采用其他方案,即通过OCR识别获取歌词,并投射到LED显示屏上…...

JAVA学习(6)-全网最详细~
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

睿趣科技:未来抖音开网店还有前景吗
随着科技的快速发展,电商平台已经成为了人们生活中不可或缺的一部分。在中国,抖音作为一个短视频平台,近年来迅速崛起,吸引了大量的用户和商家。那么,在未来,抖音是否还能为商家提供一个有效的电商平台呢?…...

第六章 应用层 | 计算机网络(谢希仁 第八版)
文章目录 第六章 应用层6.1 域名系统DNS6.1.1 域名系统概述6.1.2 互联网的域名结构6.1.3 域名服务器 6.2 文件传送协议6.2.1 FTP概述6.2.2 FTP的基本工作原理6.2.3 简单文件传送协议TFTP 6.3 远程终端协议TELNET6.4 万维网www6.4.1 万维网概述6.4.2 统一资源定位符URL6.4.3 超文…...

c++ lambda 表达式
1. 简介 lambda(匿名函数)是C11引入的一种函数对象,它允许我们在需要函数的地方创建一个临时的、匿名的函数。lambda表达式表示一个可以执行的代码单元,可以理解为一个未命名的内联函数。Lambda函数可以用于简化代码、提高可读性…...

Go语言入门心法(七): 并发与通道
Go语言入门心法(一): 基础语法 Go语言入门心法(二): 结构体 Go语言入门心法(三): 接口 Go语言入门心法(四): 异常体系 Go语言入门心法(五): 函数 一: go语言并发与通道...

前端组件封装:构建模块化、可维护和可重用的前端应用
前端组件封装:构建模块化、可维护和可重用的前端应用 前端开发领域的快速演进已经将前端应用的规模和复杂性提升到了一个新的水平。在这个背景下,前端组件封装成为了一项关键实践,旨在构建模块化、可维护和可重用的前端应用。在本文中&#…...
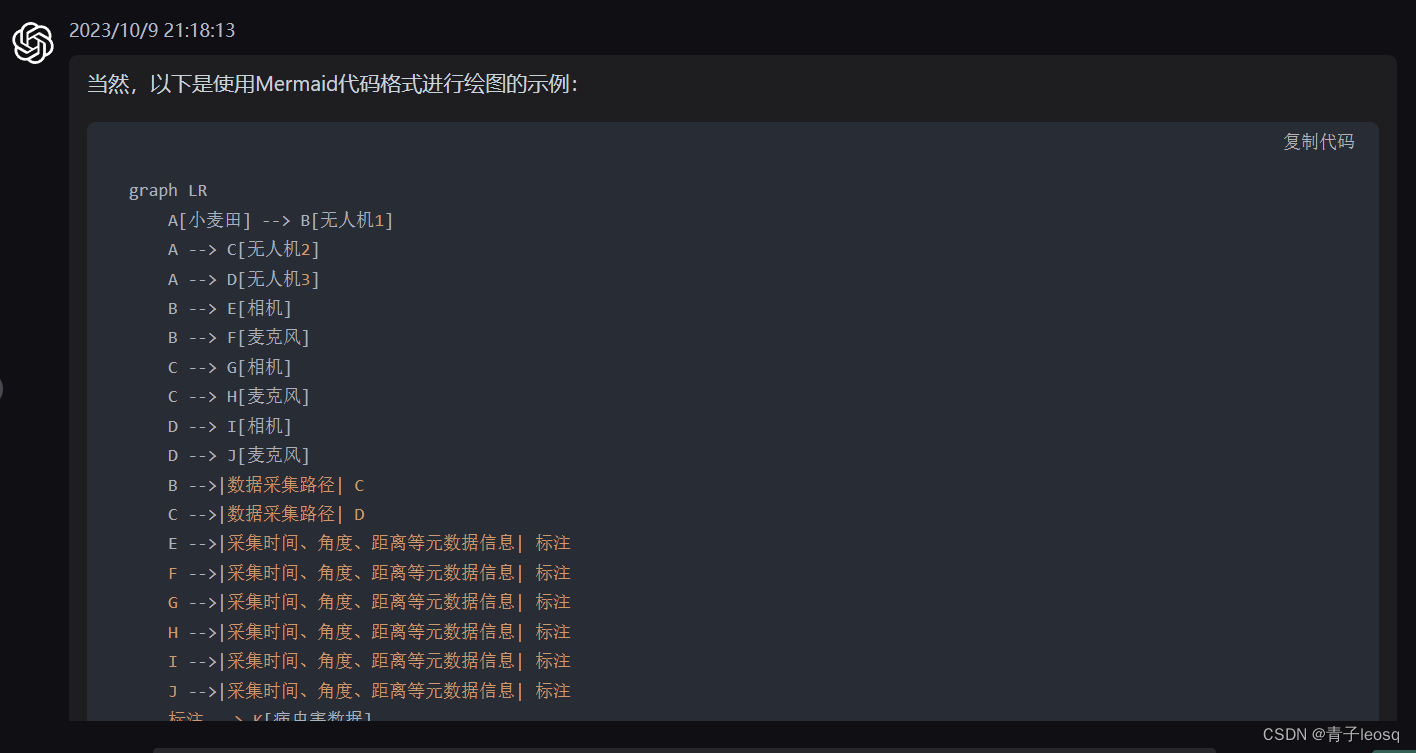
GPT绘制流程图咒语
【咒语】下面是我的一篇论文选取部分,为了让读者更好理解,我准备画一张图,请你阅读后为我设计一下这个图应该怎么画,更有说服力,更容易理解 论文片段: 多模态数据融合研究的基础在于有效的数据采集。首先&a…...

【扩散模型从原理到实战】Chapter1 扩散模型简介
文章目录 1.1 扩散模型的原理生成模型扩散过程DDPM的扩散过程前向过程反向过程优化目标 1.2 扩散模型的发展开始扩散:DDPM加速生成:采样器刷新记录:基于CLIP的多模态图像生成引爆网络:基于CLIP的多模态图像生成再次“出圈”&#…...
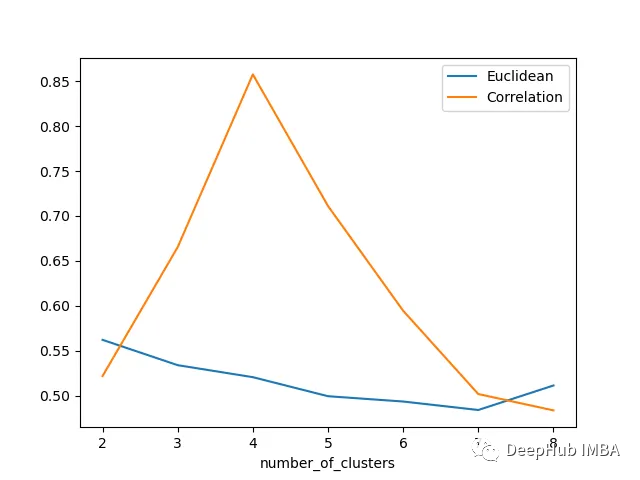
使用轮廓分数提升时间序列聚类的表现
我们将使用轮廓分数和一些距离指标来执行时间序列聚类实验,并且进行可视化 让我们看看下面的时间序列: 如果沿着y轴移动序列添加随机噪声,并随机化这些序列,那么它们几乎无法分辨,如下图所示-现在很难将时间序列列分组为簇: 上面…...
蔬菜水果生鲜配送团购商城小程序的作用是什么
蔬菜水果是人们生活所需品,从业者众多,无论小摊贩还是超市商场都有不少人每天光临,当然这些只是自然流量,在实际经营中,蔬菜水果商家还是面临着一些难题。 对蔬菜水果商家而言,线下门店是重要的࿰…...

金融用户实践|分布式存储支持数据仓库业务系统性能验证
作者:深耕行业的 SmartX 金融团队 闫海涛 估值是指对资产或负债的价值进行评估的过程,这对于投资决策具有重要意义。每个金融公司资管业务人员都期望能够实现实时的业务估值,快速获取最新的数据和指标,从而做出更明智的投资决策。…...

代码随想录二刷 Day41
509. 斐波那契数 这个题简单入门,注意下N小于等于1的情况就可以 class Solution { public:int fib(int n) {if (n < 1) return n; //这句不写的话test能过但是另外的过不了vector<int> result(n 1); //定义存放dp结果的数组,还要定义大小r…...

C++项目实战——基于多设计模式下的同步异步日志系统-⑪-日志器管理类与全局建造者类设计(单例模式)
文章目录 专栏导读日志器建造者类完善单例日志器管理类设计思想单例日志器管理类设计全局建造者类设计日志器类、建造者类整理日志器管理类测试 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计…...
:MapReduce中的排序)
Hadoop3教程(十四):MapReduce中的排序
文章目录 (99)WritableComparable排序什么是排序什么时候需要排序排序有哪些分类如何实现自定义排序 (100)全排序案例案例需求思路分析实际代码 (101)二次排序案例(102) 区内排序案例…...
测试需要写测试用例吗?
如何理解软件的质量 我们都知道,一个软件从无到有要经过需求设计、编码实现、测试验证、部署发布这四个主要环节。 需求来源于用户反馈、市场调研或者商业判断。意指在市场行为中,部分人群存在某些诉求或痛点,只要想办法满足这些人群的诉求…...

Qt 视口和窗口的区别
视口和窗口 绘图设备的物理坐标是基本的坐标系,通过QPainter的平移、旋转等变换可以得到更容易操作的逻辑坐标 为了实现更方便的坐标,QPainter还提供了视口(Viewport)和窗口(Window)坐标系,通过QPainter内部的坐标变换矩阵自动转换为绘图设…...

自动驾驶系统商业化策略:硬件与软件协同设计解析
1. 自动驾驶系统的商业策略框架解析自动驾驶系统(Autonomous Driving System, ADS)作为智能交通领域的核心技术,其商业化落地需要硬件(SSH)与软件策略的协同设计。从技术架构来看,ADS由感知层、决策层和执行…...

小白程序员看过来!TS同学半年逆袭AI大模型产品经理,收藏这份转行避坑指南!
TS同学从景观设计转行AI大模型产品经理的经历分享。他经历了离职、脱产学习、国企子公司项目被裁等波折,最终以20%薪资涨幅加入AI公司。文章重点介绍了他的心态调整、求职策略变化以及对“稳定”的新理解,同时探讨了AI时代教育孩子的思考。 本期嘉宾TS同…...

Flink 流处理核心算子深度剖析
一、ProcessFunction 与 MapFunction 区别 1、功能和区别 MapFunction:纯数据转换,一条进一条出,无状态、无时间、无侧输出,只能做简单映射。 ProcessFunction:全能处理,一条进可以 0/1/N 条出,支持状态、定时器、侧输出、访问时间,能实现复杂业务逻辑。 简单说:Map …...

SOCD Cleaner终极指南:告别游戏输入冲突,开启精准操作新时代
SOCD Cleaner终极指南:告别游戏输入冲突,开启精准操作新时代 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在《街头霸王6》中因为同时按下左右方向键而错失连招机会࿱…...

Windows驱动管理专业解决方案:Driver Store Explorer完全指南
Windows驱动管理专业解决方案:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称Rapr)是一款…...
)
完美解决VS Code/Cursor远程连接报错:远程主机不满足运行 VS Code 服务器的先决条件(附AI编程最佳实践)
完美解决VS Code/Cursor远程连接报错:远程主机不满足运行 VS Code 服务器的先决条件(附AI编程最佳实践) 💡 背景与痛点 最近在接手维护一个老项目,服务器是腾讯云的轻量应用服务器,装了宝塔面板。在经历了一…...

基于Adafruit Trinket的光控互动玩具:嵌入式系统入门实战
1. 项目概述:给毛绒玩具注入灵魂几年前,我女儿的一个旧毛绒玩具被冷落在角落,除了偶尔被当作抱枕,几乎失去了“玩具”的活力。这让我萌生了一个想法:能不能用一些简单的电子元件,让这些静态的玩偶重新“活”…...

Linly中文大模型本地部署指南:从选型到实战优化
1. 项目概述:一个面向中文场景的“小而美”语言模型最近在折腾本地部署大语言模型的朋友,可能都绕不开一个名字:Linly。这个由深圳大学计算机视觉研究所(CVI-SZU)开源的项目,在中文社区里热度一直不低。它不…...

基于CircuitPython与蓝牙BLE的交互式电子糖果心制作指南
1. 项目概述:一个可交互的蓝牙电子糖果心 情人节期间,那些印着“BE MINE”、“HUG ME”等短句的糖果心(Conversation Hearts)总是能传递简单而直接的情感。你有没有想过,如果能亲手制作一个可以随时改变文字和颜色的电…...

对比直接使用原厂 API 体验 Taotoken 在模型选型上的便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂 API 体验 Taotoken 在模型选型上的便捷性 当开发者需要评估不同大模型的能力以适配具体项目时,通常会…...