Hadoop3教程(十四):MapReduce中的排序
文章目录
- (99)WritableComparable排序
- 什么是排序
- 什么时候需要排序
- 排序有哪些分类
- 如何实现自定义排序
- (100)全排序案例
- 案例需求
- 思路分析
- 实际代码
- (101)二次排序案例
- (102) 区内排序案例
- 参考文献
(99)WritableComparable排序
什么是排序
排序是MR中最重要的操作之一,也是面试中可能被问到的重点。
MapTask和ReduceTask中都会对数据按照KEY来排序,主要是为了效率,排完序之后,相同key值的数据会被放在一起,更方便下一步(如Reducer())的汇总处理。
默认排序是按照字典顺序(字母由小到大,或者是数字由小到大)排序,且实现该排序的方法是快速排序。
什么时候需要排序
MR的过程中,什么时候用到了排序呢?
Map阶段:
- 环形缓冲区溢写到磁盘之前,会将每个分区内数据分别进行一个快排,这个排序是在内存中完成的;(对key的索引,按照字典顺序排列)
- 环形缓冲区多轮溢写完毕后,会形成一堆文件,这时候会对这些文件做merge归并排序,我理解是单个MapTask最终会汇总形成一个文件;
Reduce阶段:
- ReduceTask会主动拉取MapTask们的输出文件,理论上是会优先保存到内存里,但是往往内存里放不下,所以多数情况下会直接溢写到磁盘,于是我们会得到多个文件。当文件数量超过阈值,之后需要做归并排序,合并成一个大文件。如果是内存中的数据超过阈值,则会进行一次合并后将数据溢写到磁盘。当所有数据拷贝完后,ReduceTask会统一对内存和磁盘上的所有数据进行一次归并排序。
- 文件合并后其实还可以进行一个分组排序,过于复杂,这里就不介绍了。
排序有哪些分类
MR里的排序还有部分排序、全排序、辅助排序、二次排序的不同说法,注意,它们之间不是像那种传统的排序算法之间的区别,只是当排序在不同场景的时候,分别起了个名字。
MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部是有序的,这就是部分排序。
最终输出结果只有一个文件,且文件内部有序。这就是全排序。
全排序的实现方式是只设置一个ReduceTask。但是这种方式在处理大型文件时效率很低很低,因为一台机器处理全部数据,完全没有利用MR所提供的并行架构的优势,生产环境上完全不适用。
所以生产环境里,常用的还是部分排序。
辅助排序,就是GroupingComparator分组。
这个似乎是可选的,是在Reduce阶段,Reducer在从Map阶段主动拉取完数据后,会对所有文件做一次归并排序。做完归并排序之后,理论上就可以进行辅助排序。
辅助排序有啥用呢,就是当接收到的Key是个bean对象时,辅助排序可以让一个或者几个字段相同的key(全部字段不相同)进入同一个Reduce(),所以也起名叫做分组排序。
二次排序比较简单,在自定义排序过程中,如果compareTo中的判断条件为两个,那它就是二次排序。
如何实现自定义排序
说到这里,那 如何实现自定义排序 呢?
如果是bean对象作为key传输,那需要实现WritableComparable接口,重写compareTo方法,就可以实现自定义排序。
@Override
public int compareTo(FlowBean bean) {int result;// 按照总流量大小,倒序排列if (this.sumFlow > bean.getSumFlow()) {result = -1;}else if (this.sumFlow < bean.getSumFlow()) {result = 1;}else {result = 0;}return result;
}
(100)全排序案例
案例需求
之前我们做过一个案例,输入文件有一个,里面放的是每个手机号的上行流量和下行流量,输出同样是一个文件,里面放的除了手机号的上行流量和下行流量之外,还多了一行总流量。
这时候我们提一个新需求,就是我不止要这个输出文件,我还要这个文件里的内容,按照总流量降序排列。
思路分析
MapReduce里,只能对Key进行排序。在先前的需求里,我们是用手机号作为key,上行流量、下行流量和总流量组成一个bean,作为value,这样的安排显然不适合新需求。
因此我们需要改变一下,将上行流量、下行流量和总流量组成的bean作为key,而将手机号作为value,如此来排序。
所以第一步,我们需要对我们自定义的FlowBean对象声明WritableComparable接口,并重写CompareTo方法,这一步的目的是使得FlowBean可进行算数比较,从而允许排序:
@Override
public int CompareTo(FlowBean o){// 按照总流量,降序排列return this.sumFlow > o.getSumFlow()?-1:1;
}
注意这里,因为Hadoop里默认的字典排序是从小到大排序,如果想实现案例里由大到小的排序,那么当大于的时候,就要返回-1,从而将大的值排在前面。
其次,Mapper类里:
context.write(bean, 手机号)
bean成了key,手机号成了value。
最后,Reduce类里,需要循环输出,避免出现总流量相同的情况。
for (Text text: values){context.write(text, key); // 注意顺序,原先的key放在value位置
}
2023-7-19 11:16:04 这里没懂。。。
哦哦明白了,什么样的数据会进一个Reducer呢,当然是key 值相同的会进同一个,又因为我们之前compareTo的时候用的是总流量,所以最后是总流量相同的记录会送进同一个Reducer,然后汇总成一条记录做输出,毕竟reducer就是用来做汇总的。
但"汇总成一条记录"这并不是我们想要的,我们需要的是把这些数据原模原样输出来。这就是为什么我们在Reducer的reduce()里面,要加上循环输出的原因。
实际代码
贴一下教程里的代码实现:
首先是FlowBean对象,需要声明WritableComparable接口,并重写CompareTo()
package com.atguigu.mapreduce.writablecompable;import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements WritableComparable<FlowBean> {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//提供无参构造public FlowBean() {}//生成三个属性的getter和setter方法public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}//实现序列化和反序列化方法,注意顺序一定要一致@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(this.upFlow);out.writeLong(this.downFlow);out.writeLong(this.sumFlow);}@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readLong();this.downFlow = in.readLong();this.sumFlow = in.readLong();}//重写ToString,最后要输出FlowBean@Overridepublic String toString() {return upFlow + "\t" + downFlow + "\t" + sumFlow;}@Overridepublic int compareTo(FlowBean o) {//按照总流量比较,倒序排列if(this.sumFlow > o.sumFlow){return -1;}else if(this.sumFlow < o.sumFlow){return 1;}else {return 0;}}
}
然后编写Mapper类:
package com.atguigu.mapreduce.writablecompable;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {private FlowBean outK = new FlowBean();private Text outV = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1 获取一行数据String line = value.toString();//2 按照"\t",切割数据String[] split = line.split("\t");//3 封装outK outVoutK.setUpFlow(Long.parseLong(split[1]));outK.setDownFlow(Long.parseLong(split[2]));outK.setSumFlow();outV.set(split[0]);//4 写出outK outVcontext.write(outK,outV);}
}
然后编写Reducer类:
package com.atguigu.mapreduce.writablecompable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean> {@Overrideprotected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {//遍历values集合,循环写出,避免总流量相同的情况for (Text value : values) {//调换KV位置,反向写出context.write(value,key);}}
}
最后编写驱动类:
package com.atguigu.mapreduce.writablecompable;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);//2 关联本Driver类job.setJarByClass(FlowDriver.class);//3 关联Mapper和Reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4 设置Map端输出数据的KV类型job.setMapOutputKeyClass(FlowBean.class);job.setMapOutputValueClass(Text.class);//5 设置程序最终输出的KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6 设置输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\inputflow2"));FileOutputFormat.setOutputPath(job, new Path("D:\\comparout"));//7 提交Jobboolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}
完成,仅做了解即可。
(101)二次排序案例
二次排序的概念很简单,其实之前提过了,就是在自定义排序的时候,判断条件有两个。
比如说,原先我对一堆人排序,是按照身高从高到低排,但是身高一样的就没法排序了,这时候我可以再加入一个判断条件,比如说如果身高一样的话,就按体重排序。
具体就是修改FlowBean的CompareTo方法,在第一条件相等的时候,添加第二判定条件。
public int compareTo(FlowBean o) {//按照总流量比较,倒序排列if(this.sumFlow > o.sumFlow){return -1;}else if(this.sumFlow < o.sumFlow){return 1;}else {if (this.upFlow > o.upFlow){return 1;} else if (this.upFlow < o.upFlow){return -1;}else {return 0;}}
}
如果有需要的话,还可以继续加第三判定条件。
(102) 区内排序案例
还是之前的手机号案例,之前我们想要的是,只有一个文件,然后文件内所有数据按照总流量降序排列。
现在我们提出一个新要求,按照前3位来分区输出,比如说136的在一个文件里,137的在一个文件里,以此类推。而且每个文件内部,还需要按照总流量降序排列。
本质上就是之前说的分区 + 排序,这两部分的结合。需要额外定义好Partitioner类。
贴一下教程里的代码示例,其实只需要在上一小节的基础上补充自定义分区类即可:
首先自定义好分区类:
package com.atguigu.mapreduce.partitionercompable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner2 extends Partitioner<FlowBean, Text> {@Overridepublic int getPartition(FlowBean flowBean, Text text, int numPartitions) {//获取手机号前三位String phone = text.toString();String prePhone = phone.substring(0, 3);//定义一个分区号变量partition,根据prePhone设置分区号int partition;if("136".equals(prePhone)){partition = 0;}else if("137".equals(prePhone)){partition = 1;}else if("138".equals(prePhone)){partition = 2;}else if("139".equals(prePhone)){partition = 3;}else {partition = 4;}//最后返回分区号partitionreturn partition;}
}
然后在驱动类里注册好分区器:
// 设置自定义分区器
job.setPartitionerClass(ProvincePartitioner2.class);// 设置对应的ReduceTask的个数
job.setNumReduceTasks(5);
其他跟上一小节保持一致即可。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce中的排序)
Hadoop3教程(十四):MapReduce中的排序
文章目录 (99)WritableComparable排序什么是排序什么时候需要排序排序有哪些分类如何实现自定义排序 (100)全排序案例案例需求思路分析实际代码 (101)二次排序案例(102) 区内排序案例…...
测试需要写测试用例吗?
如何理解软件的质量 我们都知道,一个软件从无到有要经过需求设计、编码实现、测试验证、部署发布这四个主要环节。 需求来源于用户反馈、市场调研或者商业判断。意指在市场行为中,部分人群存在某些诉求或痛点,只要想办法满足这些人群的诉求…...

Qt 视口和窗口的区别
视口和窗口 绘图设备的物理坐标是基本的坐标系,通过QPainter的平移、旋转等变换可以得到更容易操作的逻辑坐标 为了实现更方便的坐标,QPainter还提供了视口(Viewport)和窗口(Window)坐标系,通过QPainter内部的坐标变换矩阵自动转换为绘图设…...

使用Git将GitHub仓库下载到本地
前记: git svn sourcetree gitee github gitlab gitblit gitbucket gitolite gogs 版本控制 | 仓库管理 ---- 系列工程笔记. Platform:Windows 10 Git version:git version 2.32.0.windows.1 Function:使用Git将GitHub仓库下载…...
前端需要了解的浏览器缓存知识
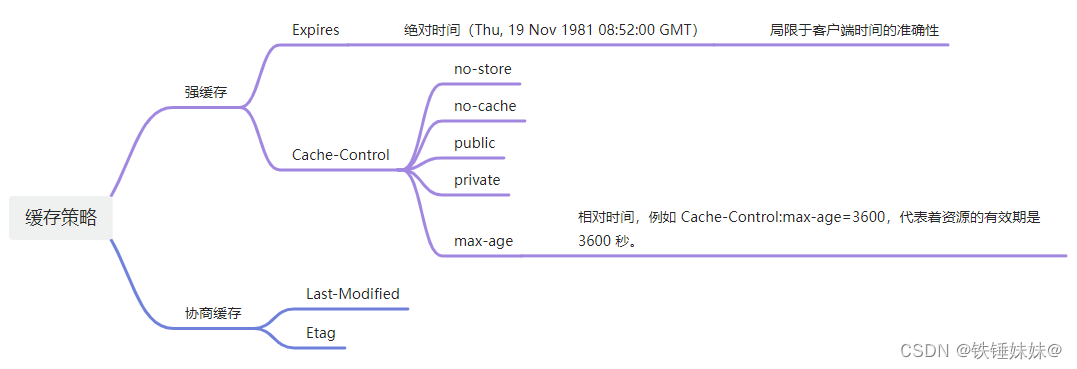
文章目录 前言为什么需要缓存?DNS缓存缓存读写顺序缓存位置memory cache(浏览器本地缓存)disk cache(硬盘缓存)重点!!! 缓存策略 - 强缓存和协商缓存1)强缓存ExpiresCach…...

自动驾驶:控制算法概述
自动驾驶:控制算法概述 常见控制算法PID算法LQR算法MPC算法 自动驾驶控制算法横向控制纵向控制 参考文献 常见控制算法 PID算法 PID(Proportional-Integral-Derivative)控制是一种经典的反馈控制算法,通常用于稳定性和响应速度要…...
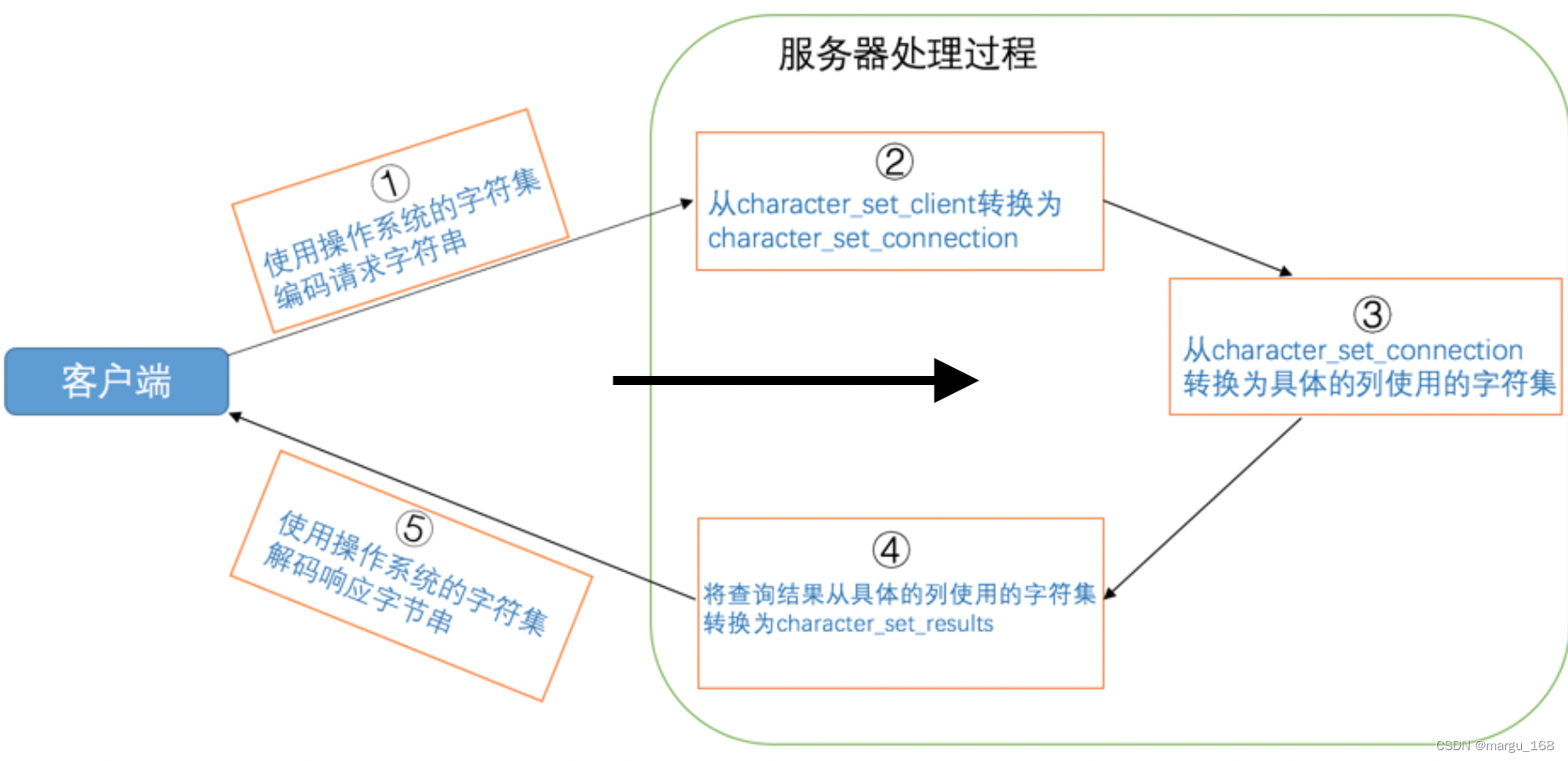
【Mysql】Mysql的字符集和比较规则(三)
字符集和比较规则简介 字符集简介 我们知道在计算机中只能以二进制的方式对数据进行存储,那么他们之间是怎样对应并进行转换的?我们需要了解两个概念: 字符范围:我们可以将哪些字符转换成二进制数据,也就是规定好字…...
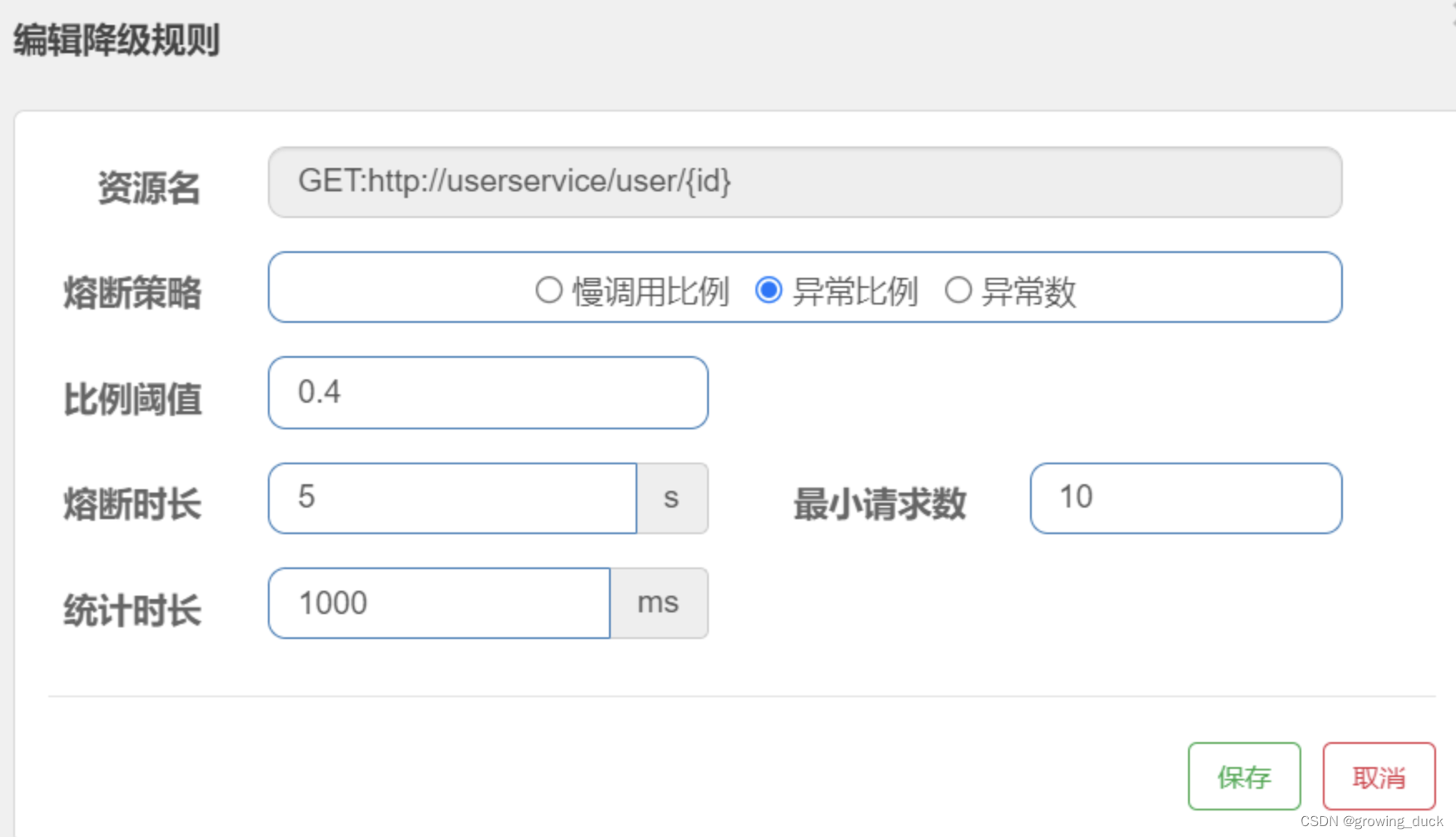
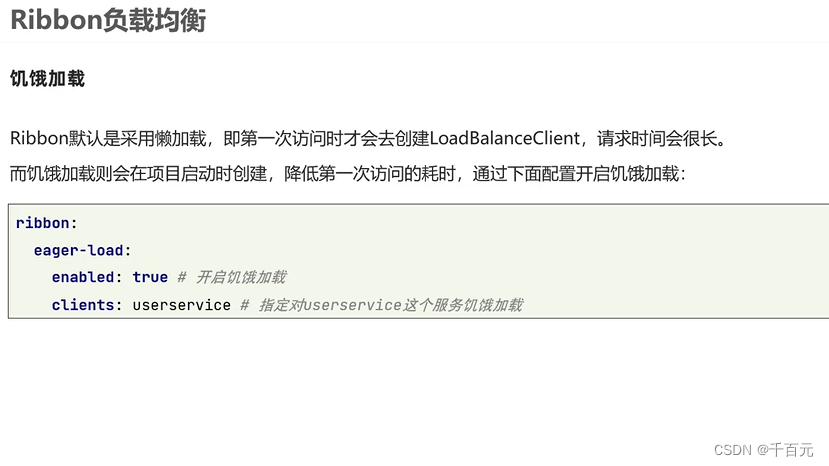
【SpringCloud-11】SCA-sentinel
sentinel是一个流量控制、熔断降级的组件,可以替换第一代中的hystrix。 hystrix用起来没有那么方便: 1、要在调用方引入hystrix,没有ui界面进行配置,需要在代码中进行配置,侵入了业务代码。 2、还要自己搭建监控平台…...
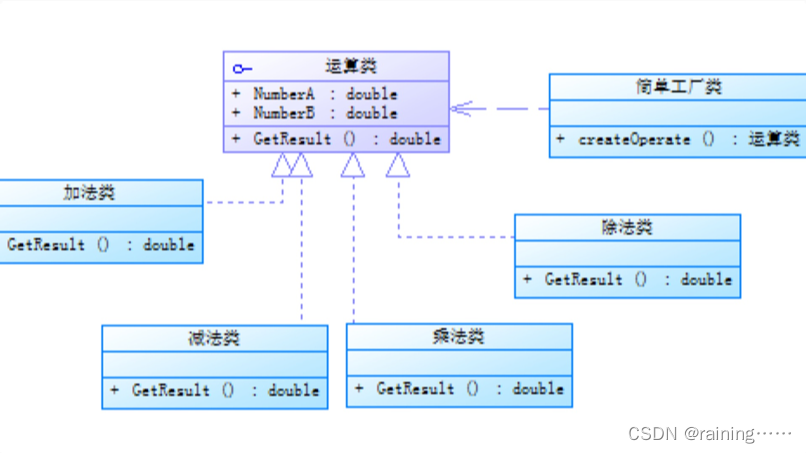
设计模式:简单工厂模式(C#、JAVA、JavaScript、C++、Python、Go、PHP):
简介: 简单工厂模式,它提供了一个用于创建对象的接口,但具体创建的对象类型可以在运行时决定。这种模式通常用于创建具有共同接口的对象,并且可以根据客户端代码中的参数或配置来选择要创建的具体对象类型。 在简单工厂模式中&am…...
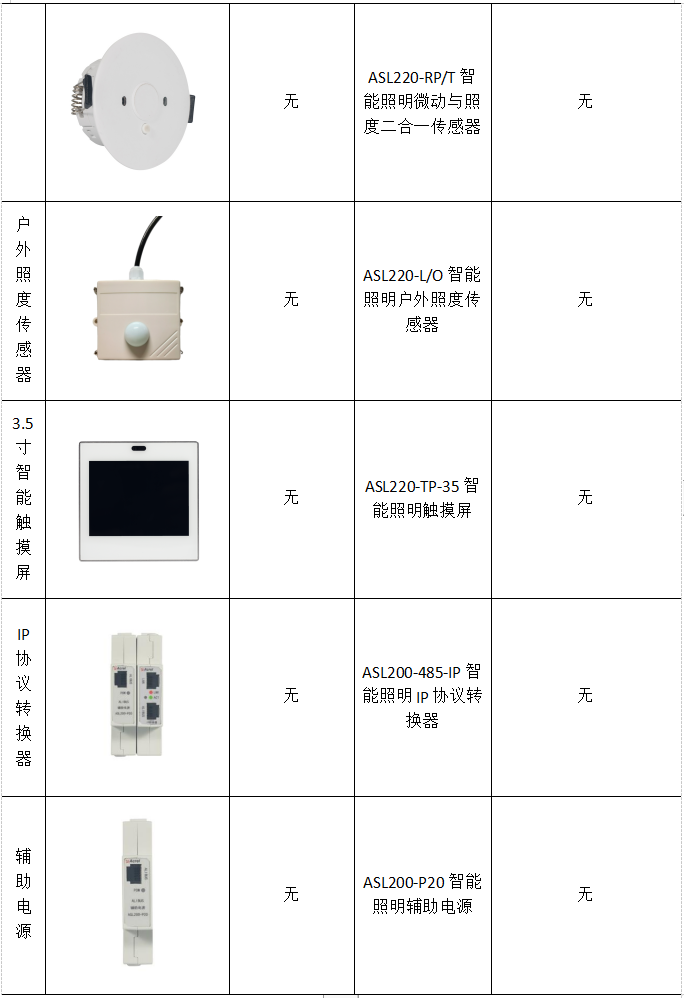
浅谈智能照明控制系统在智慧建筑中的应用
贾丽丽 安科瑞电气股份有限公司 上海嘉定 201801 摘要:新时期,建筑行业发展迅速,在信息化背景下,建筑功能逐渐拓展,呈现了智能化的发展态势。智能建筑更加安全、节能、环保,也符合绿色建筑理念。在建筑智…...
以及upper_bound())
lower_bound()以及upper_bound()
lower_bound(): lower_bound()的返回值是第一个大于等于 target 的值的地址,用这个地址减去first,得到的就是第一个大于等于target的值的下标。 在数组中: int poslower_bound(a,an,target)-a;\\n为数组…...
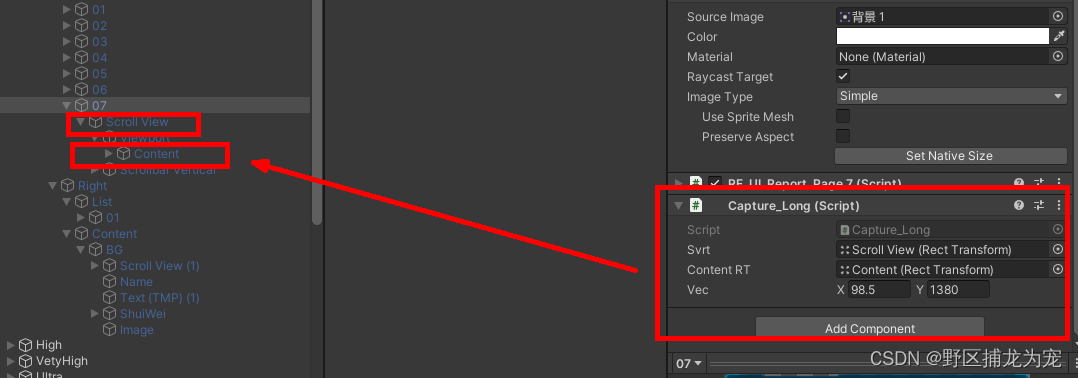
unity(WebGL) 截图拼接并保存本地,下载PDF
截图参考:Unity3D 局部截图、全屏截图、带UI截图三种方法_unity 截图_野区捕龙为宠的博客-CSDN博客 文档下载: Unity WebGL 生成doc保存到本地电脑_unity webgl 保存文件_野区捕龙为宠的博客-CSDN博客 中文输入:Unity WebGL中文输入 支持输…...

加速企业云计算部署:应对新时代的挑战
随着科技的飞速发展,企业面临着诸多挑战。在这个高度互联的世界中,企业的成功与否常常取决于其能否快速、有效地响应市场的变化。云计算作为一种新兴的技术趋势,为企业提供了实现这一目标的可能。通过加速企业云计算部署,企业可以…...

ubuntu 18.04 LTS交叉编译opencv 3.4.16并编译工程[全记录]
一、下载并解压opencv 3.4.16源码 https://opencv.org/releases/ 放到home路径下的Exe文件夹(专门放用户安装的软件)中,其中build是后期自建的 为了版本控制,保留了3.4.16,并增加了-gcc-arm 二、安装cmake和cmake-g…...
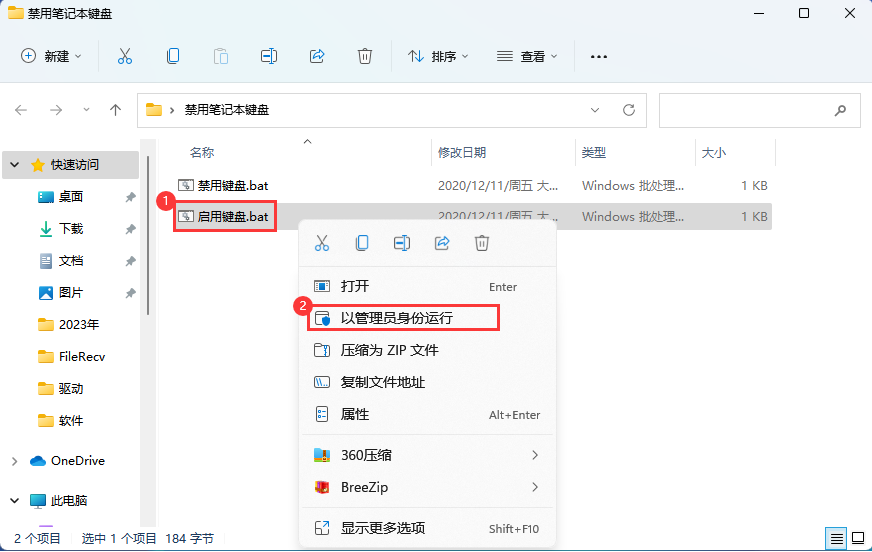
禁用和开启笔记本电脑的键盘功能,最快的方式
笔记本键盘通常较小,按键很不方便,当我们外接了键盘时就不需要再使用自带的键盘了,而且午睡的时候,总是担心碰到笔记本的键盘,可能会删掉我们的代码什么的,所以就想着怎么禁用掉,下面是操作步骤…...
【单片机基础】使用51单片机制作函数信号发生器(DAC0832使用仿真)
文章目录 (1)DA转换(2)DAC0832简介(3)电路设计(4)参考例程(5)参考文献 (1)DA转换 单片机作为一个数字电路系统,当需要采集…...
springcloud组件
https://www.bilibili.com/video/BV1QX4y1t7v5?p32&vd_source297c866c71fa77b161812ad631ea2c25 eureka : 主要是收集服务的注册信息。 如果有了eureka启动了。内部之前的调用其实就可以用服务名了, 本来是要是用ip端口来访问的,只要eureka启来了…...

手机爬虫用Appium详细教程:利用Python控制移动App进行自动化抓取数据
Appium是一个强大的跨平台工具,它可以让你使用Python来控制移动App进行自动化操作,从而实现数据的抓取和处理。今天,我将与大家分享一份关于使用Appium进行手机爬虫的详细教程,让我们一起来探索Appium的功能和操作,为手…...

deb包构建详解
deb包构建详解 一、deb包构建流程二、deb包构建描述文件详解2.1 control文件2.2 postinst 文件 (post-installation script)2.3 postrm 文件 (post-removal script)2.4 prerm 文件 (pre-removal script)2.5 preinst 文件 (pre-installation script)2.6 rules 文件2.7 changelog…...

【Spring Cloud】网关Gateway的请求过滤工厂RequestRateLimiterGatewayFilterFactory
概念 关于微服务网关Gateway中有几十种过滤工厂,这一篇博文记录的是关于请求限流过滤工厂,也就是标题中的RequestRateLimiterGatewayFilterFactory。这个路由过滤工厂是用来判断当前请求是否应该被处理,如果不会被处理就会返回HTTP状态码为42…...

Open-Meteo:高性能开源天气API架构深度解析与技术实践
Open-Meteo:高性能开源天气API架构深度解析与技术实践 【免费下载链接】open-meteo Free Weather Forecast API for non-commercial use 项目地址: https://gitcode.com/GitHub_Trending/op/open-meteo 技术痛点与解决方案定位 传统天气数据服务面临三大技术…...

NoFences:三分钟让你的Windows桌面从混乱到有序的免费开源方案
NoFences:三分钟让你的Windows桌面从混乱到有序的免费开源方案 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否也曾面对满屏杂乱无章的图标感到无从下手&am…...
)
告别在线安装卡顿:手把手教你离线部署Vitis 2021.2到Ubuntu 20.04(含77G包处理技巧)
高效离线部署Vitis 2021.2:Ubuntu 20.04全流程实战指南 对于从事FPGA开发的工程师而言,稳定可靠的开发环境搭建是项目成功的第一步。当网络条件受限或需要批量部署时,离线安装方式往往成为刚需。本文将深入解析如何在Ubuntu 20.04系统上完成V…...

DeepStream-Yolo GPU加速原理深度解析:从ONNX到TensorRT的完整流程
DeepStream-Yolo GPU加速原理深度解析:从ONNX到TensorRT的完整流程 【免费下载链接】DeepStream-Yolo NVIDIA DeepStream SDK 8.0 / 7.1 / 7.0 / 6.4 / 6.3 / 6.2 / 6.1.1 / 6.1 / 6.0.1 / 6.0 / 5.1 implementation for YOLO models 项目地址: https://gitcode.c…...

掌握这四大趋势,让你的AI Agent真正“能干活”!CSDN收藏必备指南
本文深入探讨了企业级AI Agent的四大核心趋势:MCP协议实现可扩展集成、GraphRAG提升回答一致性、AgentDevOps确保行为质量与推理链路稳定性、RaaS模式实现结果计费。文章指出,这些趋势共同推动AI Agent从“可用”到“好用”的跨越,并提供了实…...

Ubuntu 26.04 完美安装和设置
设置 root 用户密码 sudo passwd root Linux安装微软命令行文本编辑器-Microsoft Edit # 安装 Zstandard apt install zstd # 下载软件包 wget https://github.com/microsoft/edit/releases/download/v1.2.0/edit-1.2.0-x86_64-linux-gnu.tar.zst # 解压缩到用户的当前目录…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...

CM201-1-CH刷机避坑指南:S905L3B+UWE5621DS芯片组合刷机时,为什么必须取消‘擦除flash’?
CM201-1-CH刷机避坑指南:S905L3BUWE5621DS芯片组合的特殊性解析 每次刷机操作都像一场精密手术,而CM201-1-CH这款搭载S905L3B主控与UWE5621DS无线芯片组合的机顶盒,则像一位"特殊体质"的患者——常规操作可能导致不可逆的"医疗…...

2026 最新 6 款漏洞扫描工具!一篇全覆盖
渗透测试收集信息完成后,就要根据所收集的信息,扫描目标站点可能存在的漏洞了,包括我们之前提到过的如:SQL注入漏洞、跨站脚本漏洞、文件上传漏洞、文件包含漏洞及命令执行漏洞等,通过这些已知的漏洞,来寻找…...

重磅!国家首部NAD⁺抗衰共识发布,这11条建议必读!
2026年4月,国内首个《NAD⁺在衰老相关疾病中的作用及临床应用中国专家共识(2026版)》正式发布!这份由中华医学会老年医学分会牵头、汇聚全国衰老医学、代谢病、心血管病及神经病学等领域权威专家共同制定的国家级共识,…...