四、多线程服务器
1.进程的缺陷和线程的优点
1.进程的缺陷
创建进程(复制)的工作本身会给操作系统带来相当沉重的负担。
而且,每个进程具有独立的内存空间,所以进程间通信的实现难度也会随之提高。
同时,上下文切换(Context Switching)过程是创建进程的最大开销。
系统同时运行多个进程,系统将CPU时间分成多个微小的块后分配给了多个进程。为了分时使用CPU,需要上下文切换过程。下面了解一下“上下文切换”的概念。
如果运行进程A后需要紧接着运行进程B,就应该将进程A相关信息移出内存,并读入进程B相关信息。这就是上下文切换。但此时进程A的数据将被移动到硬盘,所以上下文切换需要很长时间。即使通过优化加快速度,也会存在一定的局限。
2.线程的优点
为了保持多进程的优点,同时在一定程度上克服其缺点,人们引人了线程(Thread )。这是为了将进程的各种劣势降至最低限度(不是直接消除)而设计的一种“轻量级进程”。线程相比于进程具有如下优点。
1.线程的创建和上下文切换比进程的创建和上下文切换更快。
2.线程间交换数据时无需特殊技术。
2.线程和进程的差异
进程空间:
每个进程的内存空间都由保存全局变量的“数据区”、向malloc等函数的动态分配提供空间的堆(Heap)、函数运行时使用的栈(Stack)构成。每个进程都拥有这种独立空间,如下:
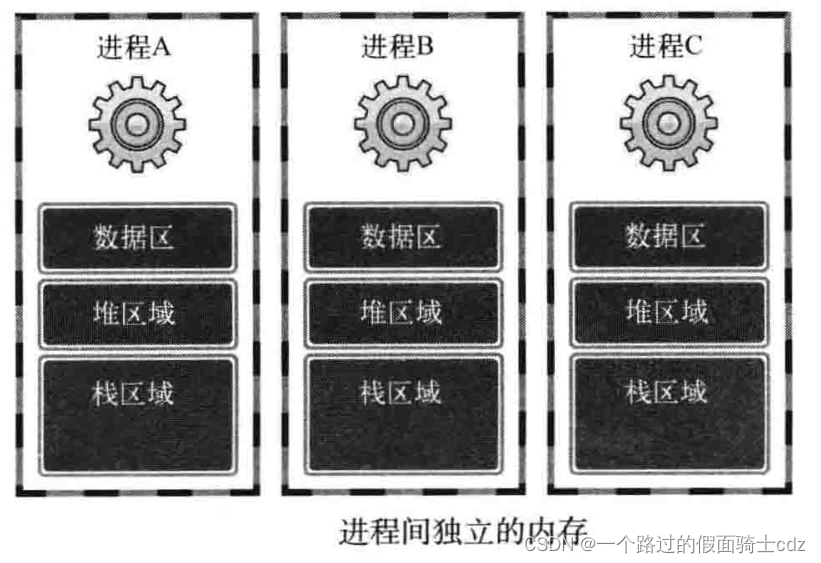
如果以获得多个代码执行流为主要目的,则不应像上面一样完全分离内存结构,而只需要分离栈区域。因此,可以通过这种办法获取下面的优势:
1.上下文切换时,不需要切换数据区和堆
2.可以利用数据区和堆交换数据
线程为了保持多条代码执行流而隔开了栈区域,因此拥有下面的内存结构:
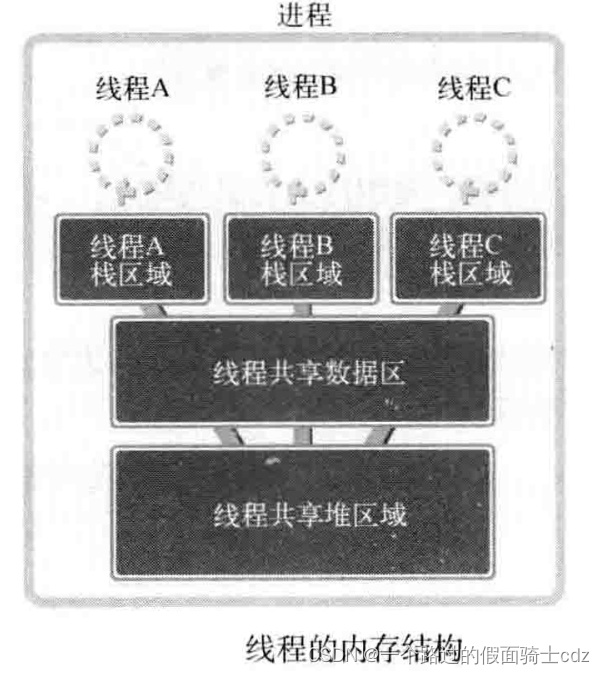
多个线程将共享数据区和堆。为了保持这种结构,线程将在进程内创建并运 线程将在进程内创建并运行。也就是说,进程和线程可以定义为如下形式。
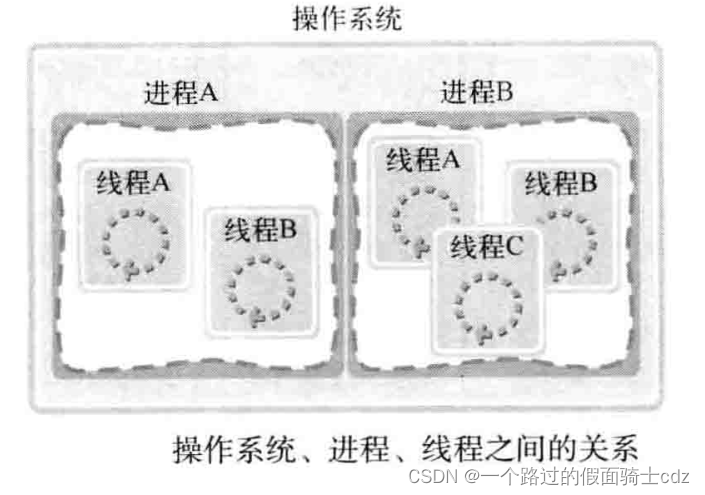
进程:在操作系统构成单独执行流的单位。
线程:在进程构成单独执行流的单位。
3.线程创建及运行
POSIX是Portable Operating System Interface for Computer Environment(适用于计算机环境的可移植操作系统接口)的简写,是为了提高UNIX系列操作系统间的移植性而制定的API规范。下面要介绍的线程创建方法也是以POSIX标准为依据的。因此,它不仅适用于Linux,也适用于大部分UNIX系列的操作系统。
1.线程的创建和执行流程
下面是我在百度找到的关于restrict关键字的描述:
restrict,C语言中的一种类型限定符(Type Qualifiers),用于告诉编译器,对象已经被指针所引用,不能通过除该指针外所有其他直接或间接的方式修改该对象的内容。
1.pthread_create函数
int pthread_create(pthread_t *restrict thread,const pthread_attr_t *restrict attr,void* (* start_routine)(void*),void *restrict arg);
//成功时返回0,失败时返回其他值(1)thread
保存新创建线程ID的变量地址值。线程与进程相同,也需要用于区分不同线程的ID。
(2)attr
用于传递线程属性的参数,传递NULL时,创建默认属性的线程
(3)start_routine
相当于线程main函数的、在单独执行流中执行的函数地址值(函数指针)
(4)arg
通过第三个参数传递调用函数所包含传递参数信息的变量地址值
代码示例:
#include<stdio.h>
#include<pthread.h>void* thread_main(void *arg)
{int cnt=*((int*)arg);int i;for(i=0;i<cnt;i++){sleep(1);puts("running thread");}return NULL;
}int main(int argc,char *argv[])
{pthread_t trdId;int threadParam=5;if(pthread_create(&trdId,NULL,thread_main,(void*)&threadParam)!=0){puts("pthread_create() error");return -1;}sleep(10);puts("end of main");return 0;
}线程相关代码在编译时需要添加-lpthread选项声明需要连接线程库,只有这样才能调用pthread.h中声明的函数。
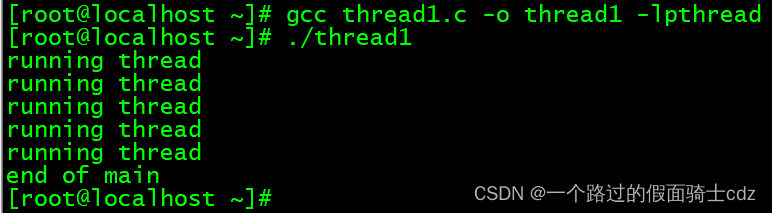
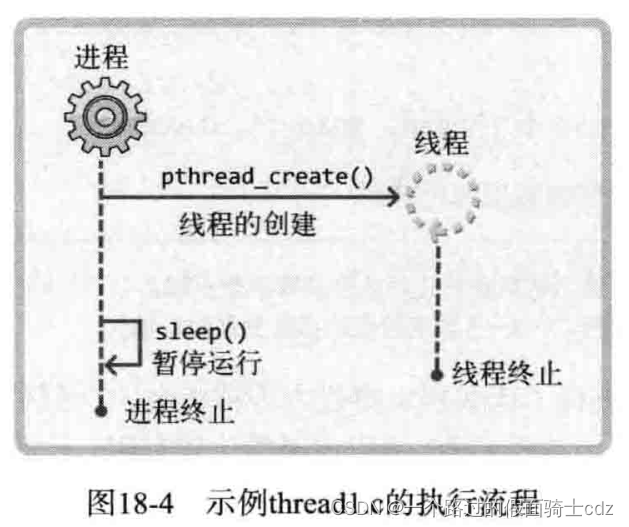
虚线代表执行流程,向下的箭头指的是执行流,横向箭头是函数调用。

如果将sleep(10)改成sleep(2),不会像代码中写的那样输出5次“running thread”字符串,如上。因为main函数返回后整个进程将被销毁。如下:
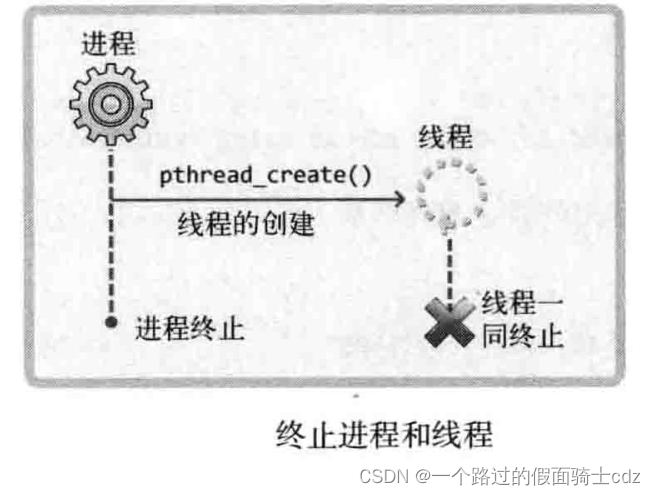
那是否就只要合理使用sleep函数,就能很好的控制线程的执行了呢?
通过调用sleep函数控制线程的执行相当于预测程序的执行流程,但实际上这是不可能完成的。
而且稍有不慎,很可能干扰程序的正常执行流。
因此,为了控制线程的执行流,通常利用下面的函数:
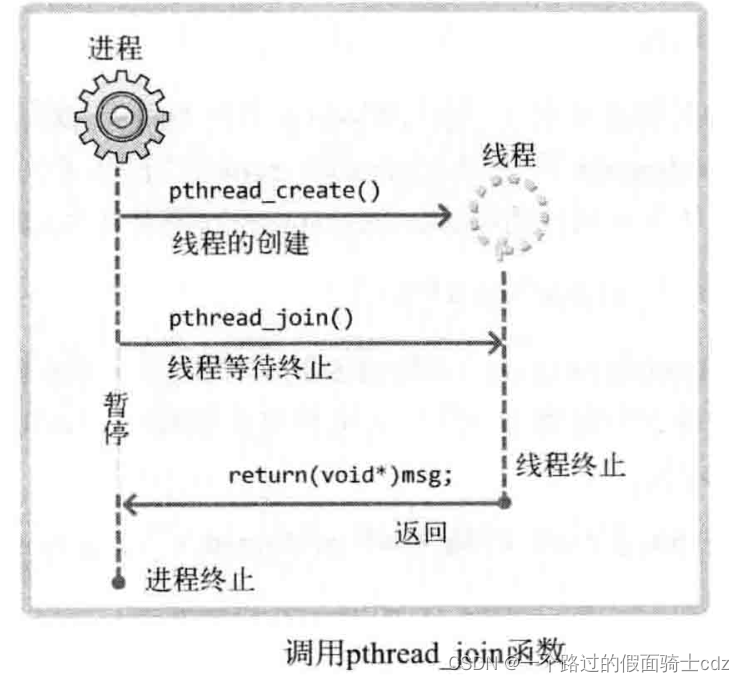
2.pthread_join函数
int pthread_join(pthread_t thread,void** status);
//成功返回0,失败时返回其他值(1)thread
该参数值ID的线程终止后才会从该函数返回
(2)status
保存线程的main函数返回值的指针变量地址值
也就是说,调用该函数的进程或者线程将进入等待状态,直到ID为第一个参数的线程终止为止。
而且可以得到线程的main函数返回值。代码示例:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<pthread.h>
void *thread_main(void *arg)
{int cnt=*((int*)arg);char *msg=(char*)malloc(sizeof(char)*50);strcpy(msg,"Hello, I am thread.\n");int i;for(i=0;i<cnt;i++){sleep(1);puts("running thread");}return (void*)msg;
}int main(int argc,char *argv[])
{pthread_t trd_id;int thread_param=5;if(pthread_create(&trd_id,NULL,thread_main,(void*)&thread_param)!=0){puts("pthread_create() error");return -1;}void* pthread_rtn;if(pthread_join(trd_id,&pthread_rtn)!=0){puts("pthread_join() error");return -1;}printf("Thread return message: %s\n",(char*)pthread_rtn);free(pthread_rtn);return 0;
}
其执行流程图如下:
2.临界区
关于线程的运行需要考虑多个线程同时调用函数时可能产生问题。
这类函数内部存在临界区(Critical Section),也就是说多个线程同时执行这部分代码,可能引发问题。
临界区指的是一个访问共用资源的程序片段,而这些共用资源又无法同时被多个线程访问的特性。
当有线程进入临界区段时,其他线程或是进程必须等待,有一些同步的机制必须在临界区段的进入点与离开点实现,以确保这些共用资源是被互斥获得使用。
因此根据临界区是否引起问题,函数可分为以下2类:
1.线程安全函数(Thread-safe function)
2.非线程安全函数(Thread-unsafe function)
线程安全函数被多个线程同时调用时也不会引发问题。反之,非线程安全函数被同时调用时会引发问题。
但这并非关于有无临界区的讨论,线程安全的函数中同样可能存在临界区。只是在线程安全函数中,同时被多个线程调用时可通过一些措施避免问题。
大多数标准函数都是线程安全的函数。而且不需要自己区分线程安全的函数和非线程安全的函数(在Windows程序中同样如此)。因为这些平台在定义非线程安全函数的同时,提供了具有相同功能的线程安全的函数。如:

提供线程安全的同一函数是:

线程安全函数的名称后缀通常为_r(这与Windows平台不同)。但这种方法会给程序员带来沉重的负担。可以通过声明头文件前定义_REENTRANT宏。自动将gethostbyname函数调用改为gethostbyname_r的函数调用。
gethostbyname函数和gethostbyname_r函数的函数名和参数声明都不同。因此,这种宏声明方式很有用。另外,无需为了上述宏定义特意添加#define语句,可以在编译时通过添加-D REENTRANT选项定义宏。另外,无需为了上述宏定义特意添加#定义语句,可以在编译时通过添加-D_REENTRANT可重入的选项定义宏。如下:

下面编译线程相关代码时均默认添加-D_REENTRANT选项。
3.工作(Worker)线程模型
下面给出创建多个线程的示例:
计算1到10的和,但并不是在main函数中进行累加运算,而是创建2个线程,其中一个线程计算1到5的和,另一个线程计算6到10的和,main函数只负责输出运算结果。
这种方式的编程模型称为工作线程(Worker thread)模型。计算1到5之和的线程与计算6到10之和的线程将成为main线程管理的工作(Worker )(这里是不是应该这样断句,main 线程管理,求大佬告知)。最后,给出示例代码前先给出程序执行流程图:
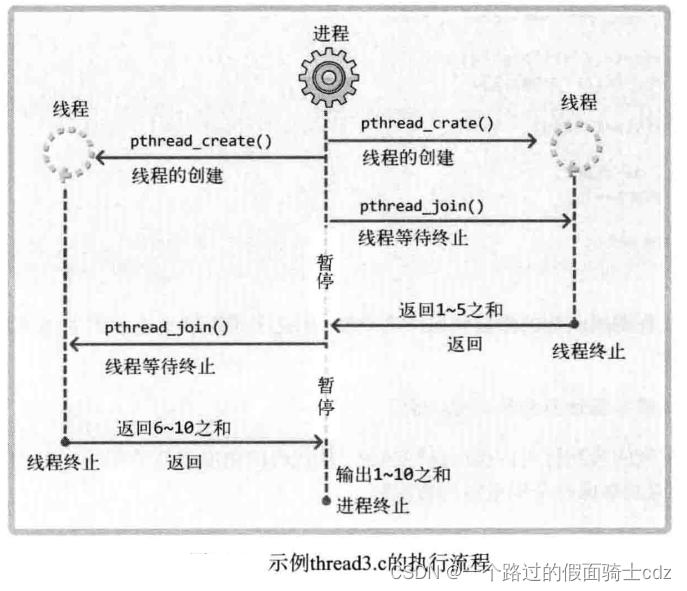
代码示例:
#include<stdio.h>
#include<pthread.h>int sum=0;
void *thread_summation(void *arg)
{int start=((int*)arg)[0];int end=((int*)arg)[1];while(start<=end){sum+=start;++start;}return NULL;
}int main(int argc,char *argv[])
{int range1[]={1,5};int range2[]={6,10};pthread_t trd_id1,trd_id2;pthread_create(&trd_id1,NULL,thread_summation,(void*)range1);pthread_create(&trd_id2,NULL,thread_summation,(void*)range2);void *trd_rtn1,*trd_rtn2;pthread_join(trd_id1,&trd_rtn1);pthread_join(trd_id2,&trd_rtn2);printf("sum=%d\n",sum);return 0;
}结果:

虽然结果正确,但2个线程直接访问了全局变量sum。因此存在着问题,下面举相似的例子证明:
#include<stdlib.h>
#include<unistd.h>#define NUM_THREAD 100long long num=0;void *thread_inc(void *arg)
{int i;for(i=0;i<50000000;i++)num++;return NULL;
}
void *thread_des(void *arg)
{int i;for(i=0;i<50000000;i++)num--;return NULL;
}int main(int argc,char *argv[])
{pthread_t thread_id[NUM_THREAD];printf("sizeof long long: %d\n",sizeof(long long));int i;for(i=0;i<NUM_THREAD;i++){if(i%2)pthread_create(thread_id+i,NULL,thread_inc,NULL);elsepthread_create(thread_id+i,NULL,thread_des,NULL);}for(i=0;i<NUM_THREAD;i++)pthread_join(thread_id[i],NULL);printf("sum=%lld\n",num);return 0;
}在程序中,我们两个线程main函数分别加减50000000,但最后的结果却不是0。

下面分析错误的原因。
上面的问题出在2个线程正在同时访问全局变量num。此处的访问指的是值的更改。
被访问的是全局变量,但这并非是全局变量引发的问题。实际上任何内存空间,只要被同时访问都可能发生问题。线程虽然是分时使用CPU,但同时访问可能和我们所想的不一样。
最理想的情况:
如下,2个线程要执行将变量值逐次加1的工作
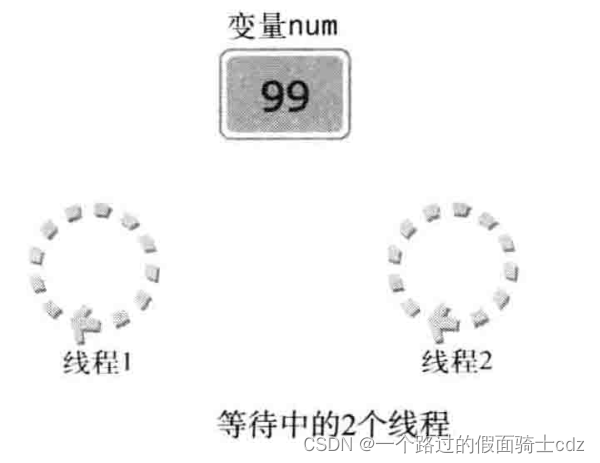
线程1将变量的值增加到100,线程2再访问num时,变量num中将按照我们预想保存101。
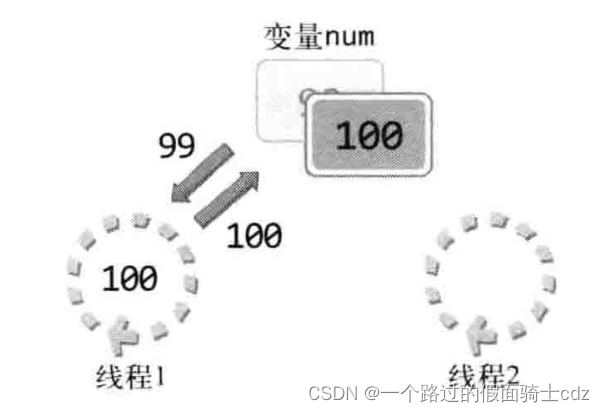
注意值的增加方式,值的增加需要CPU运算完成,变量中的值不会自动增加。
线程1首先读该变量的值并将其传递到CPU,获得加1之后的结果为100,最后把结果写回变量num,这样num中就保存100。接下来给出线程2的执行过程:
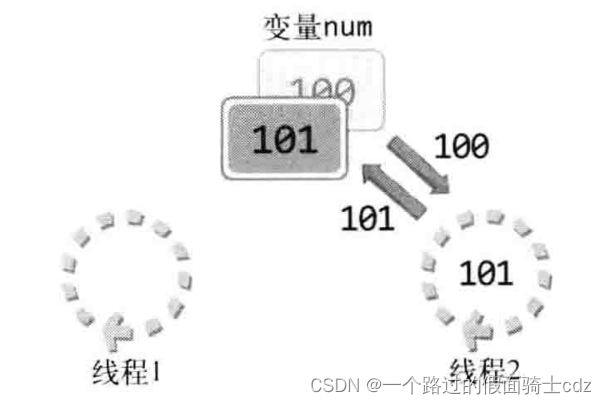
变量中将保存101,但这是最理想的情况。线程1完全增加num值之前,线程2完全有可能通过切换得到CPU资源。
可能的情况:
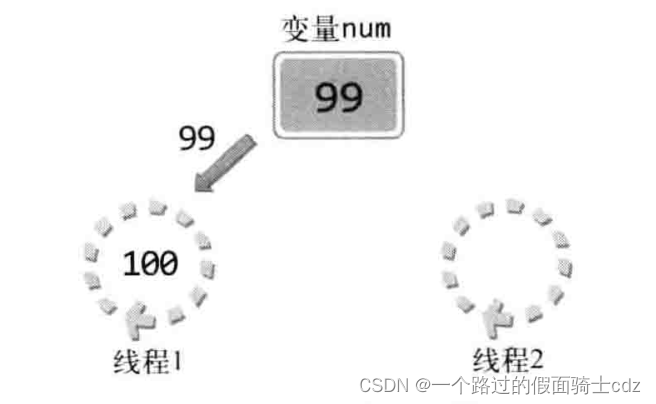
线程1读取变量num的值并完成加1运算,但这时加1后的结果尚未写入到变量num。
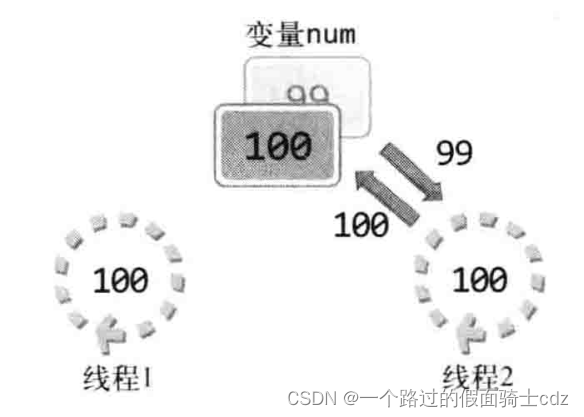
在将要把100保存到变量中,但执行该操作前,执行流程转到了线程2。
线程2获取此时num的值仍未99,因为线程1还没有把num加一后的值保存到num,所以线程2重复了线程1的工作,线程2完成后才为100。不控制其他线程访问,实际的情况可能更复杂。
因此,线程访问变量num时应阻止其他线程访问,直到线程1结束。这就是同步(Synchronization)。
因此,为了保证同步,需要划分临界区。

临界区并非num的定义部分,而是访问num的2条语句。这2条语句可能由多个线程同时使用,也是引起问题的直接原因。产生的问题可以整理为3中情况:
1.2个线程同时执行thread_inc函数
2.2个线程同时执行thread_des函数
3.2个线程分别执行thread_inc函数和thread_des函数
4.线程同步
线程同步可以从下面俩方面考虑:
1.同时访问同一内存空间时发生的情况
2.需要指定访问同一内存空间的线程执行顺序的情况
上面已讨论过第一种情况,因此下面重点讨论第二种。这是控制线程执行顺序的相关内容。
假设有A、B两个线程,线程A负责向指定内存空间写人数据,线程B负责取走该数据。这种情况下,线程A首先应该访问约定的内存空间并保存数据。万一线程B先访问并取走数据,将导致错误结果。像这种需要控制执行顺序的情况也需要使用同步技术。
下面将会介绍互斥量(Mutex)和信号量(Semaphore)这两种同步技术。
1.互斥量
下面举一个例子:
假如有个电话亭,我们想要使用,则必须保证里面现在没有人在使用。因此,电话亭这个公共的资源不能被多个人占用。则电话亭使用规则如下:
1.为了保护个人隐私,电话亭在有人进来使用时会自动锁上门。
2.如果此时有人在使用电话亭,则需要等待。
3.里面的人使用后,电话亭从里面打开,且电话亭的锁将会打开,直到下一个人的使用。
因此,互斥量的作用就是电话亭的门锁。
1.pthread_mutex_init函数
int pthread_mutex_init(pthread_mutex_t *mutex,const pthread_mutexattr_t *attr);
//成功返回0,失败返回其他值(1)mutex
创建互斥量时传递保存互斥量的变量地址值
(2)attr
传递即将创建的互斥量属性,没有特别需要指定的属性时传递NULL。
attr可能的值有:
1.PTHREAD_MUTEX_TIMED_NP,这是缺省值,也就是普通锁。当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。
2.PTHREAD_MUTEX_RECURSIVE_NP,嵌套锁,允许同一个线程对同一个锁成功获得多次,并通过多次unlock解锁。如果是不同线程请求,则在加锁线程解锁时重新竞争。
3.PTHREAD_MUTEX_ERRORCHECK_NP,检错锁,如果同一个线程请求同一个锁,则返回EDEADLK,否则与PTHREAD_MUTEX_TIMED_NP类型动作相同。这样保证当不允许多次加锁时不出现最简单情况下的死锁。
4.PTHREAD_MUTEX_ADAPTIVE_NP,适应锁,动作最简单的锁类型,仅等待解锁后重新竞争。
2.pthread_mutex_destory函数
int pthread_mutex_destory(pthread_mutex_t *mutex);
//成功返回0,失败返回其他值(1)mutex
需要销毁的互斥量地址值
为了创建相当于锁系统的互斥量,需要声明如下pthread_mutex_t变量:

该变量的地址将传递给pthread_mutex_init函数,用来保存操作系统创建的互斥量(锁系统)。
调用pthread_mutex_destory函数时同样需要该信息。如果不需要配置特殊的互斥量属性,则向第二个参数传递NULL时,可以利用PTHREAD_MUTEX_INITIALIZER宏进行如下初始化:

但通过宏进行初始化很难发现发生的错误,因此上面的做法不推荐,最好用pthread_init函数初始化。
3.pthread_mutex_lock函数
int pthread_mutex_lock(pthread_mutex_t *mutex);
//成功返回0,失败时返回其他值4.pthread_mutex_unlock函数
int pthread_mutex_unlock(pthread_mutex_t *mutex);
//成功返回0,失败时返回其他值函数的名字很容易理解。进入临界区前调用的函数就是pthread_mutex_lock函数。相当于进入锁门的过程。因为如果里面有人,则我们将不能进入使用电话亭。所以,调用该函数时,如果发现其他线程已进入临界区,则pthread_mutex_lock函数不会返回,直到里面的线程调用pthread_mutex_unlock退出临界区为止。也就是,其他线程让出临界区之前,当前线程将一直处于阻塞状态。创建好互斥量的前提下,可以通过如下结构保护临界区:

退出临界区时,如果线程忘了调用pthread_mutex_unlock函数,那么其他为了进入临界区而调用pthread_mutex_lock函数的线程就无法摆脱阻塞状态。这种情况称为死锁(Dead-lock)。
#include<stdio.h>
#include<pthread.h>
#include<stdlib.h>
#include<unistd.h>#define NUM_THREAD 100long long num=0;
pthread_mutex_t mutex;void *thread_inc(void *arg)
{int i;pthread_mutex_lock(&mutex);for(i=0;i<50000000;i++)num++;pthread_mutex_unlock(&mutex);return NULL;
}
void *thread_des(void *arg)
{int i;pthread_mutex_lock(&mutex);for(i=0;i<50000000;i++)num--;pthread_mutex_unlock(&mutex);return NULL;
}
int main(int argc,char *argv[])
{pthread_t thread_id[NUM_THREAD];printf("sizeof long long: %d\n",sizeof(long long));pthread_mutex_init(&mutex,NULL);int i;for(i=0;i<NUM_THREAD;i++){if(i%2)pthread_create(thread_id+i,NULL,thread_inc,NULL);elsepthread_create(thread_id+i,NULL,thread_des,NULL);}for(i=0;i<NUM_THREAD;i++)pthread_join(thread_id[i],NULL);printf("sum=%lld\n",num);pthread_mutex_destroy(&mutex);return 0;
}结果:

2.信号量
此处只涉及二进制信号量完成控制线程顺序为中心的同步方法。
1.sem_init函数
int sem_init(sem_t *sem,int pshared,unsigned int value);
//成功返回0,失败返回其他值(1)sem
创建信号量时传递信号量的变量地址值
(2)pshared
传递其他值时,创建可由多个进程共享的信号量;传递0时,创建只允许1个进程内部使用的信号量。我们需要完成同一进程内的线程同步,故传递0。
(3)value
指定新创建的信号量初始值
2.sem_destroy函数
int sem_destroy(sem_t *sem);
//成功时返回0,失败时返回其他值(1)sem
传递需要销毁的信号量的变量地址值
3.sem_post函数
int sem_post(sem_t *sem);
//成功返回0,失败返回其他值(1)sem
传递保存信号量读取值的变量地址值,传递给sem_post时信号量增1。
4.sem_wait函数
int sem_wait(sem_t *sem);
//成功时返回0,失败返回其他值(1)sem
传递保存信号量读取值的变量地址值,传递给sem_wait时信号量减1。
调用sem_init函数时,操作系统将创建信号量对象,此对象中记录着“信号量值”(Semaphore Value)整数。
该值在调用sem_post函数时增1,调用sem_wait函数时减1。但信号量的值不能小于0,因此,在信号量为0的情况下调用sem_wait函数时,调用函数的线程将进入阻塞状态(因为函数未返回)。当然,此时如果有其他线程调用sem_post函数,信号量的值将变为1,而原本阻塞的线程可以将该信号量重新减为0并跳出阻塞状态。实际上就是通过这种特性完成临界区的同步操作,可以通过如下形式同步临界区(假设信号量的初始值为1)。

调用sem_wait函数进入临界区的线程在调用sem_post函数前不允许其他线程进入临界区。
信号量的值在0和1之间跳转,因此,具有这种特性的机制称为二进制信号量。
下面给出一个示例:
线程A从用户输入得到值后存入全局变量num,此时线程B将取走该值并累加。
该过程共进行5次,完成后输出总和并退出程序。
#include<stdio.h>
#include<pthread.h>
#include<semaphore.h>static sem_t sem_one;
static sem_t sem_two;
static int num;void* read(void *arg)
{int i;for(i=0;i<5;i++){fputs("Input num: ",stdout);sem_wait(&sem_two);scanf("%d",&num);sem_post(&sem_one);}return NULL;
}void* accu(void *arg)
{int sum=0;int i;for(i=0;i<5;i++){sem_wait(&sem_one);sum+=num;sem_post(&sem_two);}printf("Result: %d \n",sum);return NULL;
}int main(int argc,char *argv[])
{sem_init(&sem_one,0,0);sem_init(&sem_two,0,1);pthread_t id_t1,id_t2;pthread_create(&id_t1,NULL,read,NULL);pthread_create(&id_t2,NULL,accu,NULL);pthread_join(id_t1,NULL);pthread_join(id_t2,NULL);sem_destroy(&sem_one);sem_destroy(&sem_two);return 0;
}结果: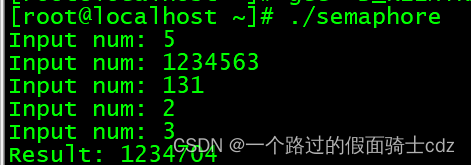
4.线程的销毁
销毁线程有以下的三种方法(书上似乎只说了两种方法,第一种不知道算不算,大家帮看看):
1.Linux线程并不是在首次调用的线程main函数返回时自动销毁。
2.pthread_join函数
3.pthread_detach函数
pthread_join函数很好理解,就是等待线程终止,还会引导线程销毁。
1.pthread_detach函数
int pthread_detach(pthread_t pthread);
//成功返回0,失败时返回其他值(1)thread
终止的同时需要销毁的进程ID
调用该函数不会引起线程终止或进入阻塞状态,可以通过该函数引导销毁线程创建的内存空间。
另外,调用该函数后,不能再针对相应线程调用pthread_join函数。
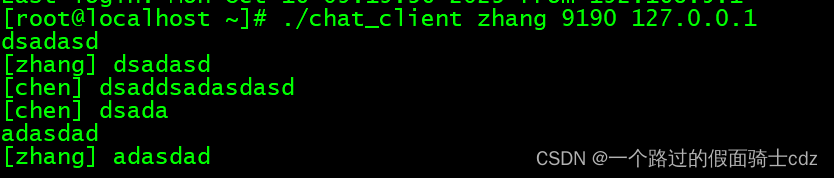
一个简单的聊天小程序示例:
服务器接收用户发送的信息,然后将其发送给参与聊天的全部用户。客户端发送信息,接收服务端发送的信息。类似一个qq群的作用。
服务器端:
#include<stdio.h>
#include<pthread.h>
#include<unistd.h>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<stdlib.h>
#include<string.h>#define BUF_SIZE 100
#define MAX_CLNT 256int clientCnt=0;
int clientSocks[MAX_CLNT];
pthread_mutex_t mutx;//send to all
void send_msg(char *msg,int len)
{ int i;pthread_mutex_lock(&mutx);for(i=0;i<clientCnt;i++)write(clientSocks[i],msg,len);pthread_mutex_unlock(&mutx);
}void *handle_clnt(void *arg)
{ int clientSock=*((int*)arg);int readLen=0;char msg[BUF_SIZE];int i;while((readLen=read(clientSock,msg,sizeof(msg)))!=0)send_msg(msg,readLen);pthread_mutex_lock(&mutx);//remove disconnected clientfor(i=0;i<clientCnt;i++){ if(clientCnt==clientSocks[i]){while(i++<clientCnt-1){clientSocks[i]=clientSocks[i+1];}break;}}clientCnt--;pthread_mutex_unlock(&mutx);close(clientSock);return NULL;
}void printMess(char *mess)
{fputs(mess,stderr);fputc('\n',stderr);exit(1);
}int main(int argc,char *argv[])
{if(argc!=3)printMess("argc error");pthread_mutex_init(&mutx,NULL);int serverSock=socket(PF_INET,SOCK_STREAM,IPPROTO_TCP);struct sockaddr_in serverAddr;memset(&serverAddr,0,sizeof(serverAddr));serverAddr.sin_family=AF_INET;serverAddr.sin_port=htons(atoi(argv[1]));serverAddr.sin_addr.s_addr=inet_addr(argv[2]);if(bind(serverSock,(struct sockaddr*)&serverAddr,sizeof(serverAddr))==-1)printMess("bind() error!");if(listen(serverSock,5)==-1)printMess("listen() error!");struct sockaddr_in clientAddr;pthread_t id1;socklen_t clientAddrLen=sizeof(clientAddr);while(1){int clientSock=accept(serverSock,(struct sockaddr*)&clientAddr,&clientAddrLen);pthread_mutex_lock(&mutx);clientSocks[clientCnt++]=clientSock;pthread_mutex_unlock(&mutx);pthread_create(&id1,NULL,handle_clnt,(void*)&clientSock);pthread_detach(id1);printf("Connected client IP: %s \n",inet_ntoa(clientAddr.sin_addr));}close(serverSock);return 0;
}
客户端1:
#include<stdio.h>
#include<pthread.h>
#include<stdlib.h>
#include<string.h>
#include<sys/socket.h>
#include<arpa/inet.h>#define BUF_SIZE 100
#define NAME_SIZE 20char name[NAME_SIZE]="[DEFAULT]";
char msg[BUF_SIZE];void *send_msg(void *arg)
{int sock=*((int*)arg);char name_msg[NAME_SIZE+BUF_SIZE];while(1){fgets(msg,BUF_SIZE,stdin);if(!strcmp(msg,"q\n")||!strcmp(msg,"Q\n")){close(sock);exit(0);}sprintf(name_msg,"%s %s",name,msg);write(sock,name_msg,strlen(name_msg));}return NULL;
}void *recv_msg(void* arg)
{int sock=*((int*)arg);char name_msg[NAME_SIZE+BUF_SIZE];int readLen=0;int error_rtn=-1;while(1){readLen=read(sock,name_msg,NAME_SIZE+BUF_SIZE-1);if(readLen==-1)return (void*)(-1);name_msg[readLen]=0;fputs(name_msg,stdout);}return NULL;
}void printMess(char *mess)
{fputs(mess,stderr);fputc('\n',stderr);exit(1);
}int main(int argc,char *argv[])
{if(argc!=4)printMess("argc error!");sprintf(name,"[%s]",argv[1]);int clientSock=socket(PF_INET,SOCK_STREAM,IPPROTO_TCP);struct sockaddr_in serverAddr;memset(&serverAddr,0,sizeof(serverAddr));serverAddr.sin_family=AF_INET;serverAddr.sin_port=htons(atoi(argv[2]));serverAddr.sin_addr.s_addr=inet_addr(argv[3]);if(connect(clientSock,(struct sockaddr*)&serverAddr,sizeof(serverAddr))==-1)printMess("connect() error!");pthread_t snd_thread,rcv_thread;pthread_create(&snd_thread,NULL,send_msg,(void*)&clientSock);pthread_create(&rcv_thread,NULL,recv_msg,(void*)&clientSock);pthread_join(snd_thread,NULL);pthread_join(rcv_thread,NULL);close(clientSock);return 0;
}
客户端2:
相关文章:
四、多线程服务器
1.进程的缺陷和线程的优点 1.进程的缺陷 创建进程(复制)的工作本身会给操作系统带来相当沉重的负担。 而且,每个进程具有独立的内存空间,所以进程间通信的实现难度也会随之提高。 同时,上下文切换(Cont…...

基于vue实现滑块动画效果
主要实现:通过鼠标移移动、触摸元素、鼠标释放、离开元素事件来进行触发 创建了一个滑动盒子,其中包含一个滑块图片。通过鼠标按下或触摸开始事件,开始跟踪滑块的位置和鼠标/触摸位置之间的偏移量。然后,通过计算偏移量和起始时的…...

探寻蓝牙的未来:从蓝牙1.0到蓝牙5.4,如何引领无线连接革命?
►►►蓝牙名字的来源 这要源于一个小故事,公元940-985年,哈洛德布美塔特(Harald Blatand),后人称Harald Bluetooth,统一了整个丹麦。他的名字“Blatand”可能取自两个古老的丹麦词语。“bla”意思是黑皮肤的,而“tan…...
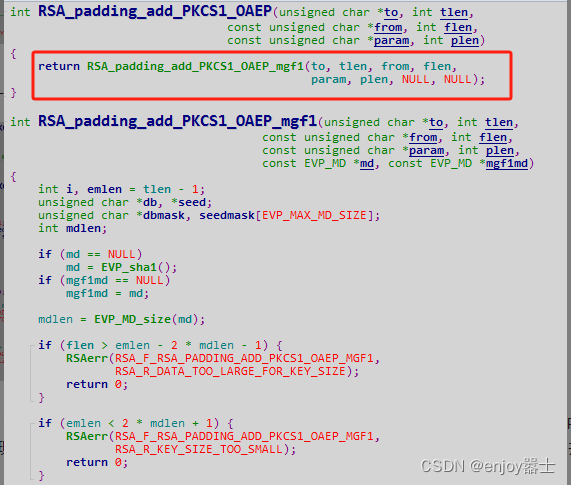
openssl 之 RSA加密数据设置OAEP SHA256填充方式
背景 如题 环境 openssl 1.1.1l c centos7.9 代码 /** 思路:填充方式自己写,不需要使用库提供的,然后加密时选择不填充的方式加密 关键代码 */ int padding_result RSA_padding_add_PKCS1_OAEP_mgf1(buf, padding_len, (unsigned char*…...

js将带标签的内容转为纯文本
背景:现需要将富文本的所有 html 标签全部删除得到纯文本 思路:创建临时DOM元素并获取其中的文本 创建一个临时 DOM 并给他赋值,然后我们使用 DOM 对象方法提取文本。 代码如下: convertToPlain( html){//新创建一个 divvar di…...
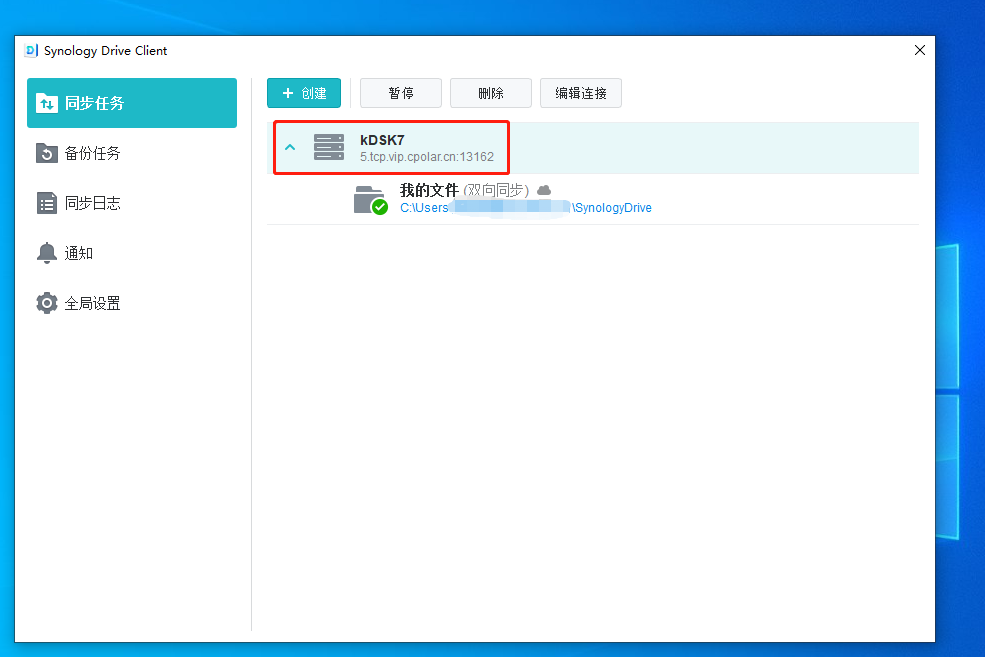
如何通过内网穿透实现远程连接NAS群晖drive并挂载电脑硬盘?
文章目录 前言1.群晖Synology Drive套件的安装1.1 安装Synology Drive套件1.2 设置Synology Drive套件1.3 局域网内电脑测试和使用 2.使用cpolar远程访问内网Synology Drive2.1 Cpolar云端设置2.2 Cpolar本地设置2.3 测试和使用 3. 结语 前言 群晖作为专业的数据存储中心&…...

4.2 抽象类
1. 抽象类概念 定义一个类时,常常需要定义一些成员方法用于描述类的行为特征,但有时这些方法的实现方式是无法确定的。例如,Animal类中的shout()方法用于描述动物的叫声,但是不同的动物,叫声也不相同,因此…...
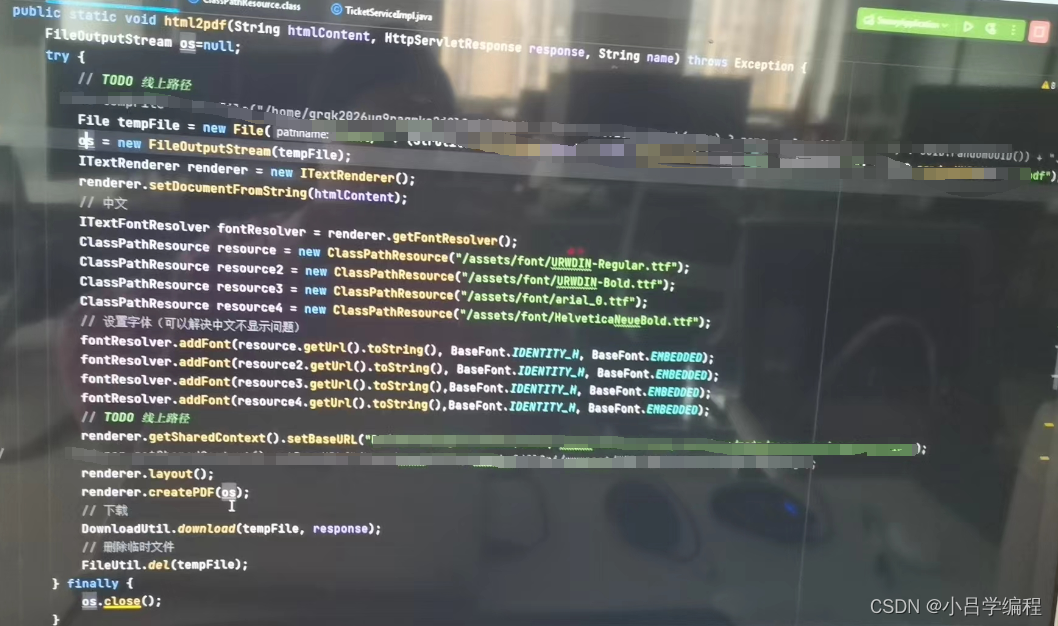
ITextRenderer将PDF转换为HTML详细教程
引入依赖 <dependency><groupId>org.xhtmlrenderer</groupId><artifactId>flying-saucer-pdf-itext5</artifactId><version>9.1.18</version></dependency> 问题一:输出中文字体 下载字体simsun.ttc 下载链接&am…...
c#设计模式-行为型模式 之 备忘录模式
🚀简介 备忘录模式(Memento Pattern)是一种行为型设计模式,它保存一个对象的某个状态,以便在适当的时候恢复对象。所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象…...
ffmpeg+安卓+yolo+RK3399部署
一次满足多项需求. 首先, 思路是, 使用ffmpeg解码本地mp4文件, 在无需任何其他改动的情况下, 就可以直接播放rtsp流, 这个是使用ffmpeg的好处. ffmpeg本身是c语言的, 所以需要编译成jni的库, https://note.youdao.com/s/6XeYftc 具体过程在这里, 用windows/macOS, Ubuntu应该都…...

发电机教程:小白必学的柴油发电机技巧
柴油发电机监控是关键的能源管理和维护工具,它用于确保持续的电力供应,提高能源效率,并延长发电机的寿命。 随着科技的不断发展,监控系统变得更加智能和高效,使用户能够远程监测和管理柴油发电机的运行状态。 客户案例…...

基础课1——人工智能的分类和层次
1.人工智能的分类 人工智能(AI)的分类主要有以下几种: 弱人工智能(Artificial Narrow Intelligence,ANI):弱人工智能是擅长于单个方面的人工智能,例如战胜象棋世界冠军的人工智能阿…...

C语言复杂表达式与指针高级
一、指针数组与数组指针 1.指针数组VS数组指针 (1)指针数组:实质是一个数组,因为这个数组中传参的内容全部是指针变量。 (2)数组指针:实质是一个指针,这个指针指向一个数组 2.分析指…...
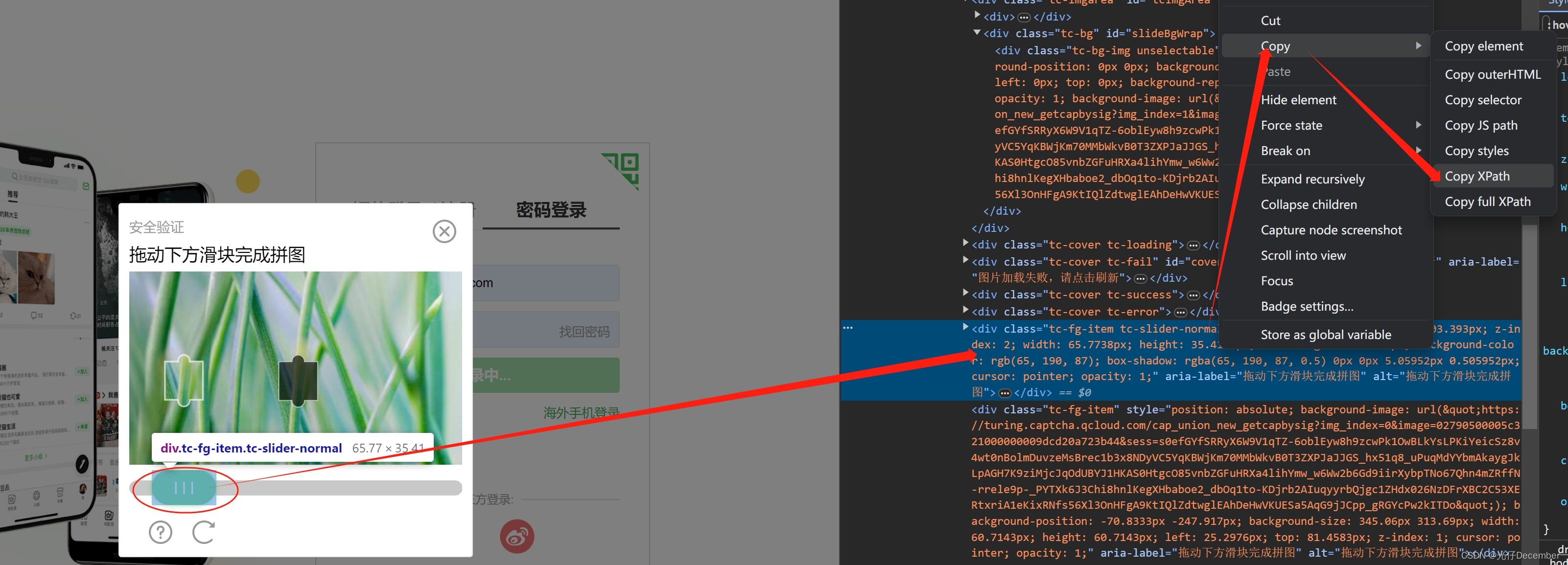
【Python从入门到进阶】39、使用Selenium自动验证滑块登录
接上篇《38、selenium关于Chrome handless的基本使用》 上一篇我们介绍了selenium中有关Chrome的无头版浏览器Chrome Handless的使用。本篇我们使用selenium做一些常见的复杂验证功能,首先我们来讲解如何进行滑块自动验证的操作。 一、测试用例介绍 我们要通过sel…...
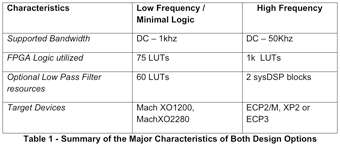
利用FPGA和CPLD数字逻辑实现模数转换器
数字系统的嵌入式工程师熟悉如何通过使用FPGA和CPLD在其印刷电路板上将各种处理器,存储器和标准功能组件粘合在一起来实现其数字设计的“剩余”。除了这些数字功能之外,FPGA和CPLD还可以使用LVDS输入,简单的电阻电容器(RC…...
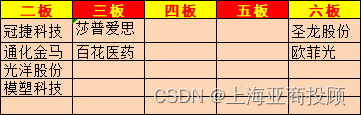
上海亚商投顾:沪指震荡调整跌 减肥药、华为概念股持续活跃
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 沪指上个交易日低开后震荡调整,深成指、创业板指盘中跌超1%,宁德时代一度跌超3%ÿ…...

间歇性微服务问题...
在Kubernetes环境中,最近由于特定配置导致Pod调度失败。哪种 Kubernetes 资源类型(通常与节点约束相关)可能导致此故障,尤其是在未正确定义的情况下? 节点选择器资源配额优先级污点Pod 中断预算 已有 201 人回答了该…...
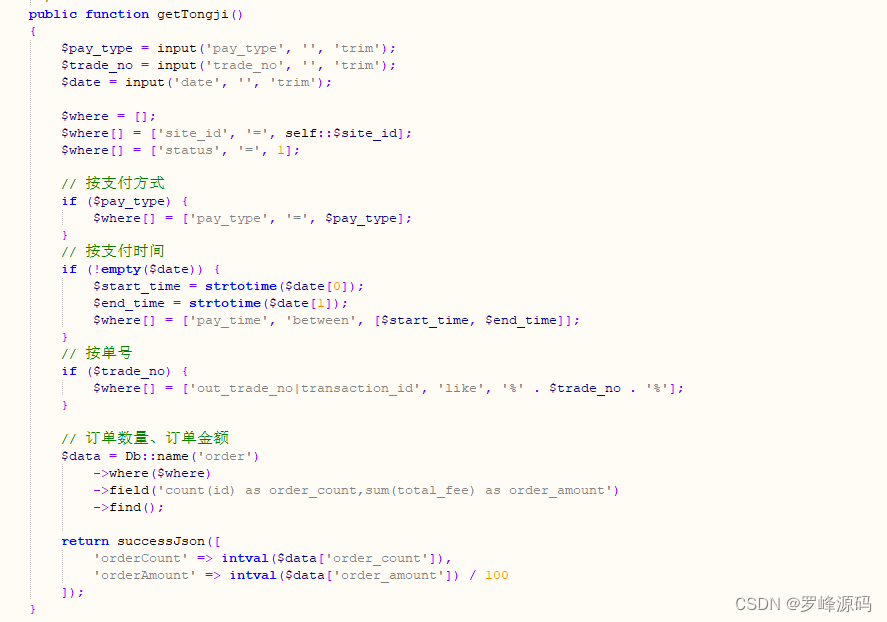
小程序开发平台源码系统+ 带前后端完整搭建教程
大家好,给大家分享一个小程序开发平台源码系统。这款小程序开发平台中有很多功能,今天主要来给大家介绍一下洗车行业小程序制作的功能。以下是部分核心代码图: 系统特色功能: LBS定位:小程序能够自动显示附近的共享洗…...
外部统一设置了::-webkit-scrollbar { display: none; }如何单独给特定元素开启滚动条设置样式-web页面滚动条样式设置
如果你在外部统一设置了::-webkit-scrollbar { display: none; }来隐藏滚动条,但是想要在.lever元素中单独开启滚动条的样式,你可以使用CSS的级联选择器来覆盖外部样式。 以下是一个示例,展示如何给.lever单独开启…...

【计算机网络】网络原理
目录 1.网络的发展 2.协议 3.OSI七层网络模型 4.TCP/IP五层网络模型及作用 5.经典面试题 6.封装和分用 发送方(封装) 接收方(分用) 1.网络的发展 路由器:路由指的是最佳路径的选择。一般家用的是5个网口,1个WAN口4个LAN口(口:端口)。可…...

下载视频不如用Via,一分都不花
找了很长时间,没想到竟然这么简单,为啥早没发现呢! 工具的名称叫Via浏览器是个App,没错在安卓手机或平板运行的工具。 缺点:pc下用不了,有些视频下不了,如爱奇艺等。苹果手机是否能用不知道,自己试吧。 优点:操作方便、简单,即使你是小白也能熟练操作。免费,一分…...

Go语言装饰器模式:功能扩展
Go语言装饰器模式:功能扩展 1. 装饰器实现 type Component interface {Operation() string }type ConcreteComponent struct{}func (c *ConcreteComponent) Operation() string {return "ConcreteComponent" }type Decorator struct {component Component…...

Acton性能调优终极指南:10个提升TON智能合约开发效率的技巧 [特殊字符]
Acton性能调优终极指南:10个提升TON智能合约开发效率的技巧 🚀 【免费下载链接】acton Toolchain for TON smart contract development and beyond 项目地址: https://gitcode.com/GitHub_Trending/acto/acton Acton是TON区块链上强大的智能合约开…...

你的桌面布局管家:PersistentWindows如何让窗口位置记忆永不丢失
你的桌面布局管家:PersistentWindows如何让窗口位置记忆永不丢失 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows 你是否…...

开源AI应用构建平台Casibase:从架构设计到生产部署全解析
1. 项目概述:一个开源的AI应用构建平台最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:想法很多,但落地太难。从模型选型、API对接、到前端交互、数据管理,每一个环节都够喝一壶。特别是当你想把多个模型、多种…...
)
别再乱用`define了!SV宏定义实战避坑指南(从`ifdef到字符串拼接)
别再乱用define了!SV宏定义实战避坑指南(从ifdef到字符串拼接) 在SystemVerilog开发中,宏定义(define)是提高代码复用性和灵活性的利器,但同时也是隐藏最深的"代码地雷"之一。许多开发…...
)
从Processing到Arduino IDE:一个让硬件编程变简单的GUI故事(附STM32兼容板配置避坑)
从Processing到Arduino IDE:硬件编程的平民化革命与STM32实战指南 2005年,当Massimo Banzi在意大利伊夫雷亚交互设计学院第一次向学生们展示那块蓝色电路板时,他可能没想到这个简单的教学工具会彻底改变嵌入式开发的世界。Arduino IDE的诞生并…...

Squirrel-RIFE实战指南:7步掌握AI视频补帧核心技术
Squirrel-RIFE实战指南:7步掌握AI视频补帧核心技术 【免费下载链接】Squirrel-RIFE 效果更好的补帧软件,显存占用更小,是DAIN速度的10-25倍,包含抽帧处理,去除动漫卡顿感 项目地址: https://gitcode.com/gh_mirrors/…...

从化学结构到生物大分子:Ketcher的模块化绘图技术深度解析
从化学结构到生物大分子:Ketcher的模块化绘图技术深度解析 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher Ketcher作为一款专业的Web分子编辑器,不仅支持基础化学结构绘制ÿ…...

第15章:C++ 日志监控告警
第15章:C++ 日志监控告警 本章定位:第四卷《实战卷》第五篇"生产环境"第 16 章。 一个 C++ 服务上线后能不能"看见"它,能不能"听见"它喊救命,决定了你深夜会不会被叫起来还能在 30 分钟内修好。 目录 01.可观测性三件套 1.1 logs / metrics …...