2023_Spark_实验十六:编写LoggerLevel方法及getLocalSparkSession方法
一、搭建Spark项目结构

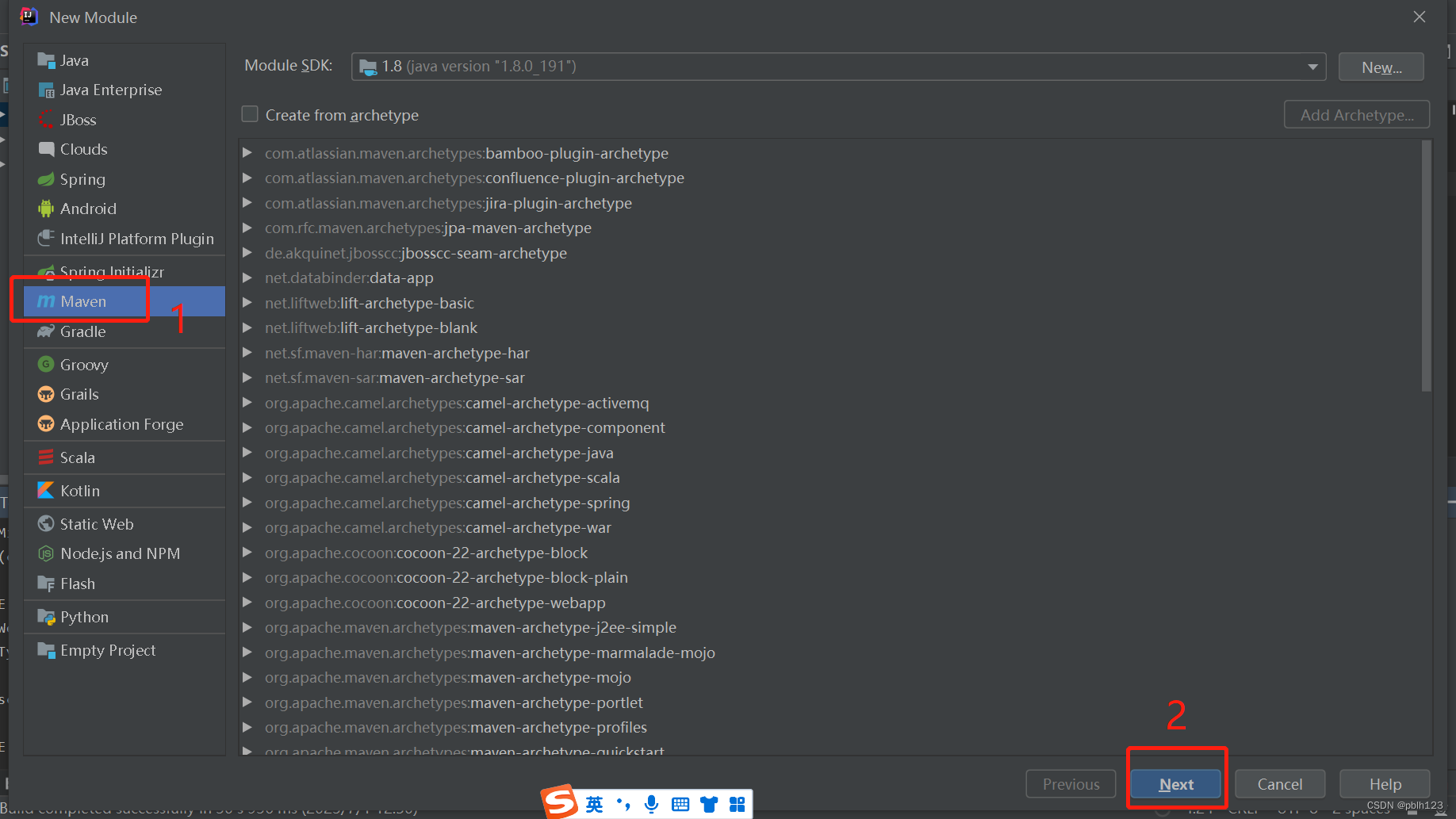

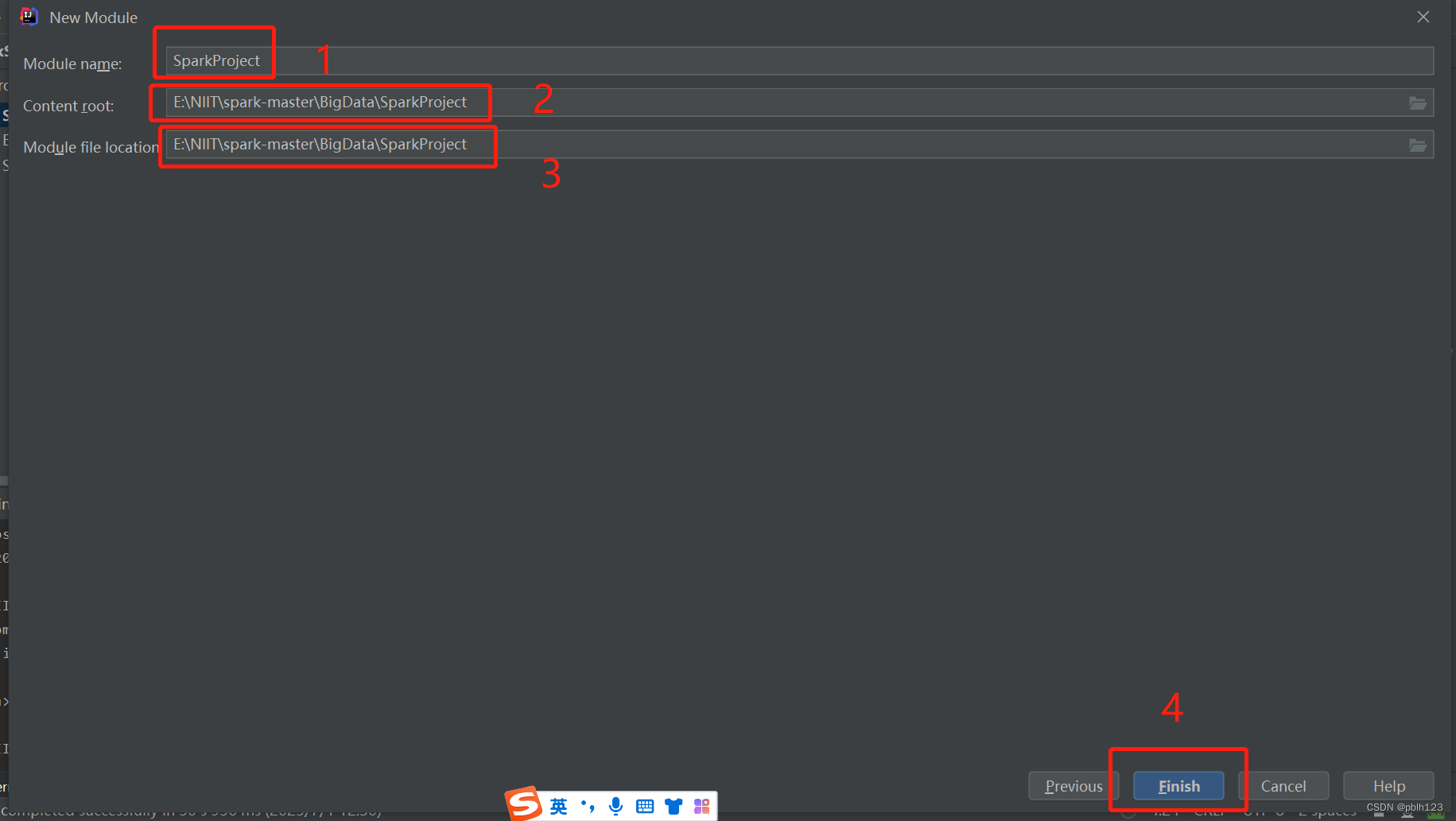

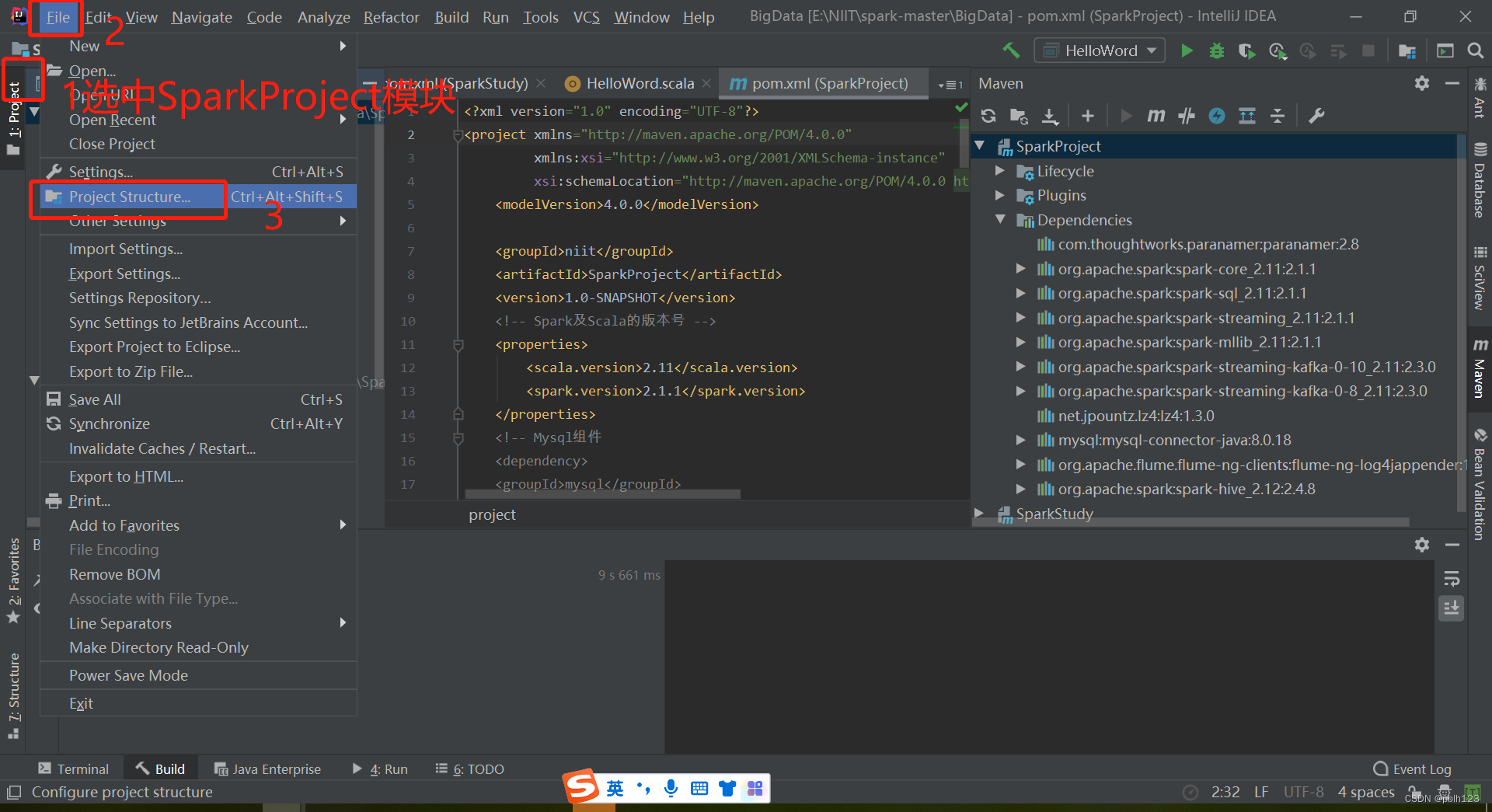
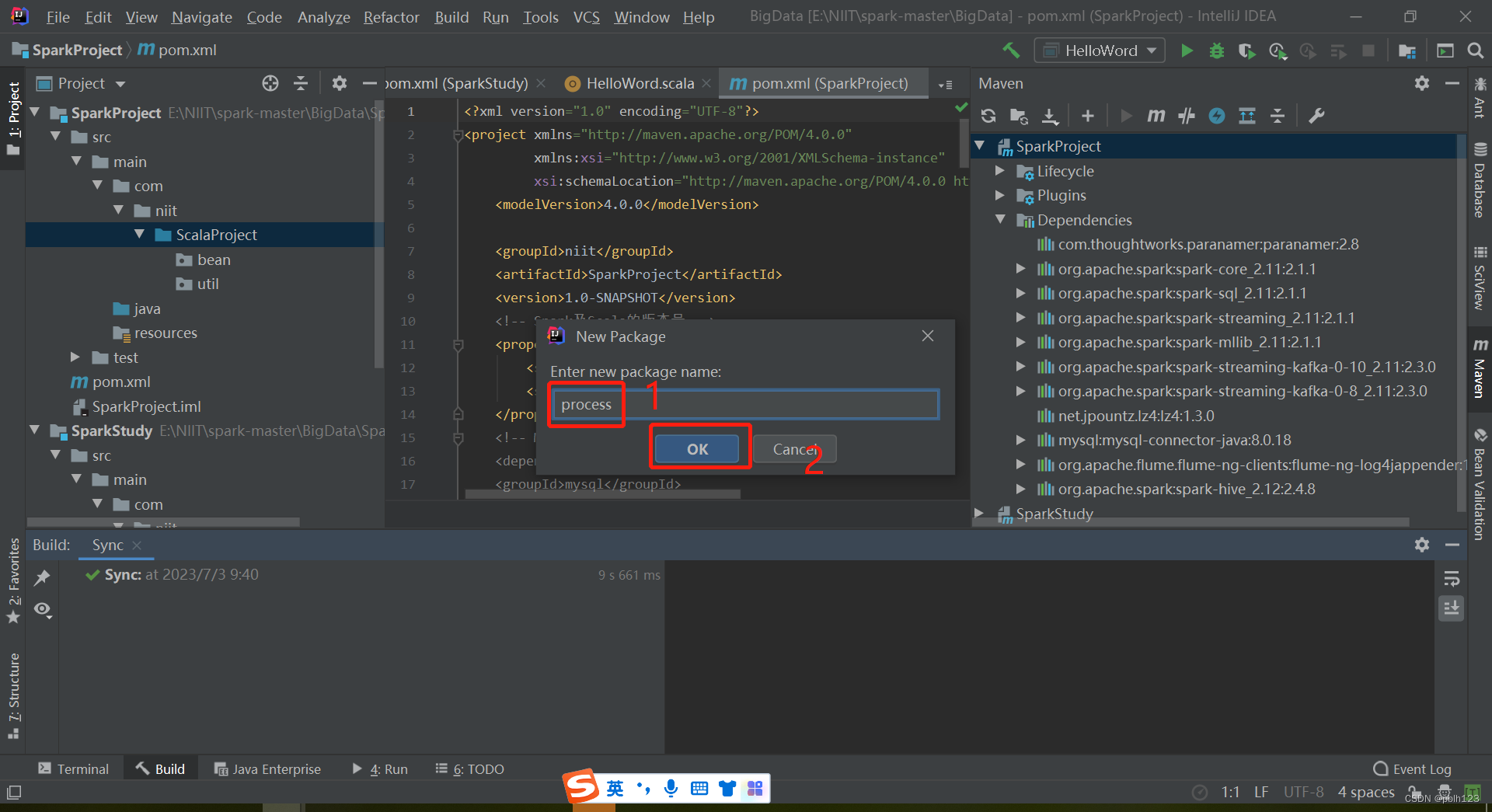
在SparkProject模块的pom.xml文件中增加一下依赖,并等待依赖包下载完毕,如上图。
<!-- Spark及Scala的版本号 --><properties><scala.version>2.11</scala.version><spark.version>2.1.1</spark.version></properties><!-- Mysql组件<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.7.22.1</version></dependency> 的依赖 --><!-- Spark各个组件的依赖 --><dependencies><!-- https://mvnrepository.com/artifact/com.thoughtworks.paranamer/paranamer --><dependency><groupId>com.thoughtworks.paranamer</groupId><artifactId>paranamer</artifactId><version>2.8</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.11</artifactId><version>2.1.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>2.3.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-8_${scala.version}</artifactId><version>2.3.0</version></dependency><dependency><groupId>net.jpountz.lz4</groupId><artifactId>lz4</artifactId><version>1.3.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.18</version></dependency><dependency><groupId>org.apache.flume.flume-ng-clients</groupId><artifactId>flume-ng-log4jappender</artifactId><version>1.7.0</version></dependency><!-- <dependency>--><!-- <groupId>org.apache.spark</groupId>--><!-- <artifactId>spark-streaming-flume-sink_2.10</artifactId>--><!-- <version>1.5.2</version>--><!-- </dependency>--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>2.4.8</version></dependency></dependencies><!-- 配置maven打包插件及打包类型 --><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin></plugins></build>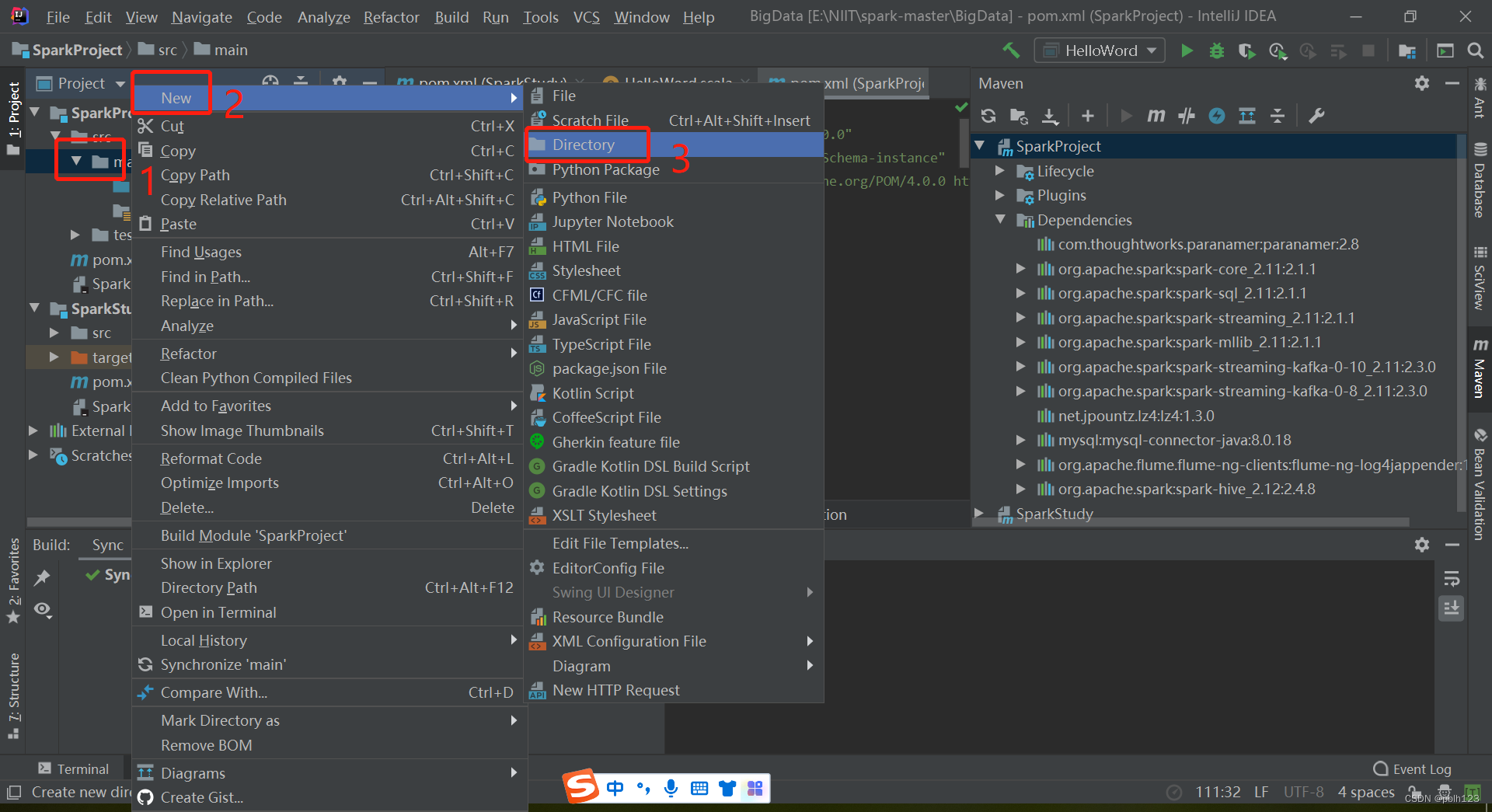
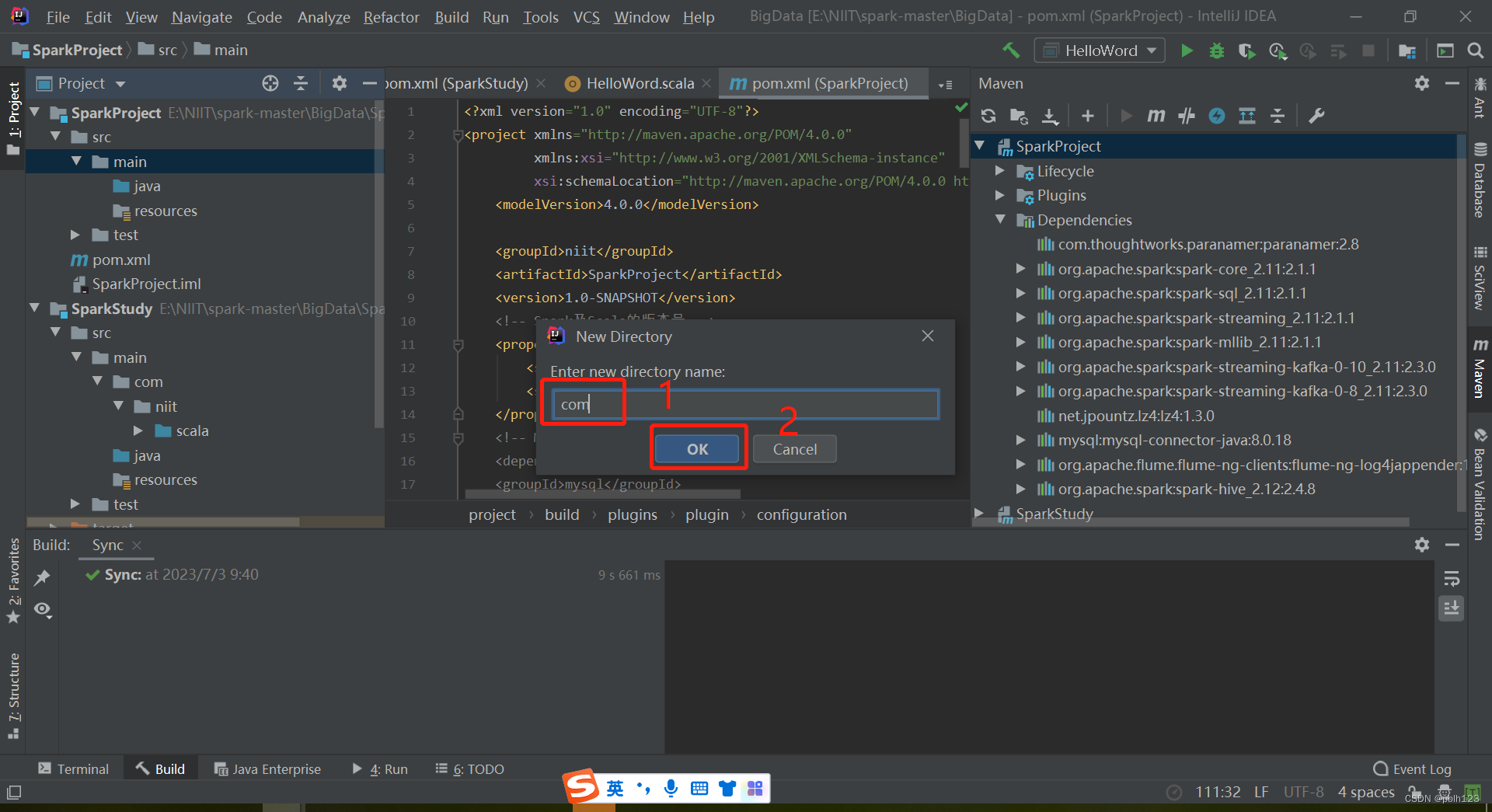

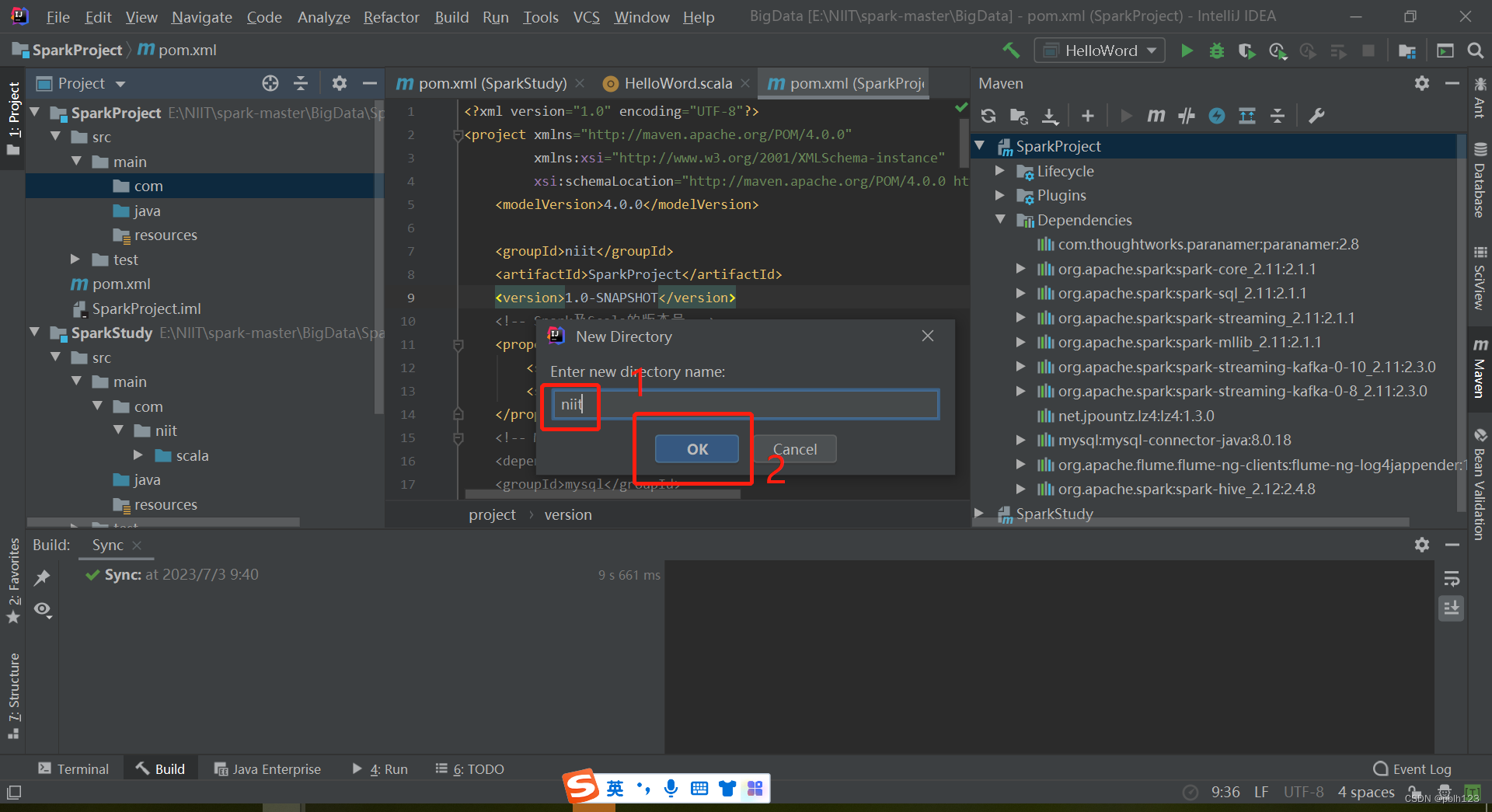
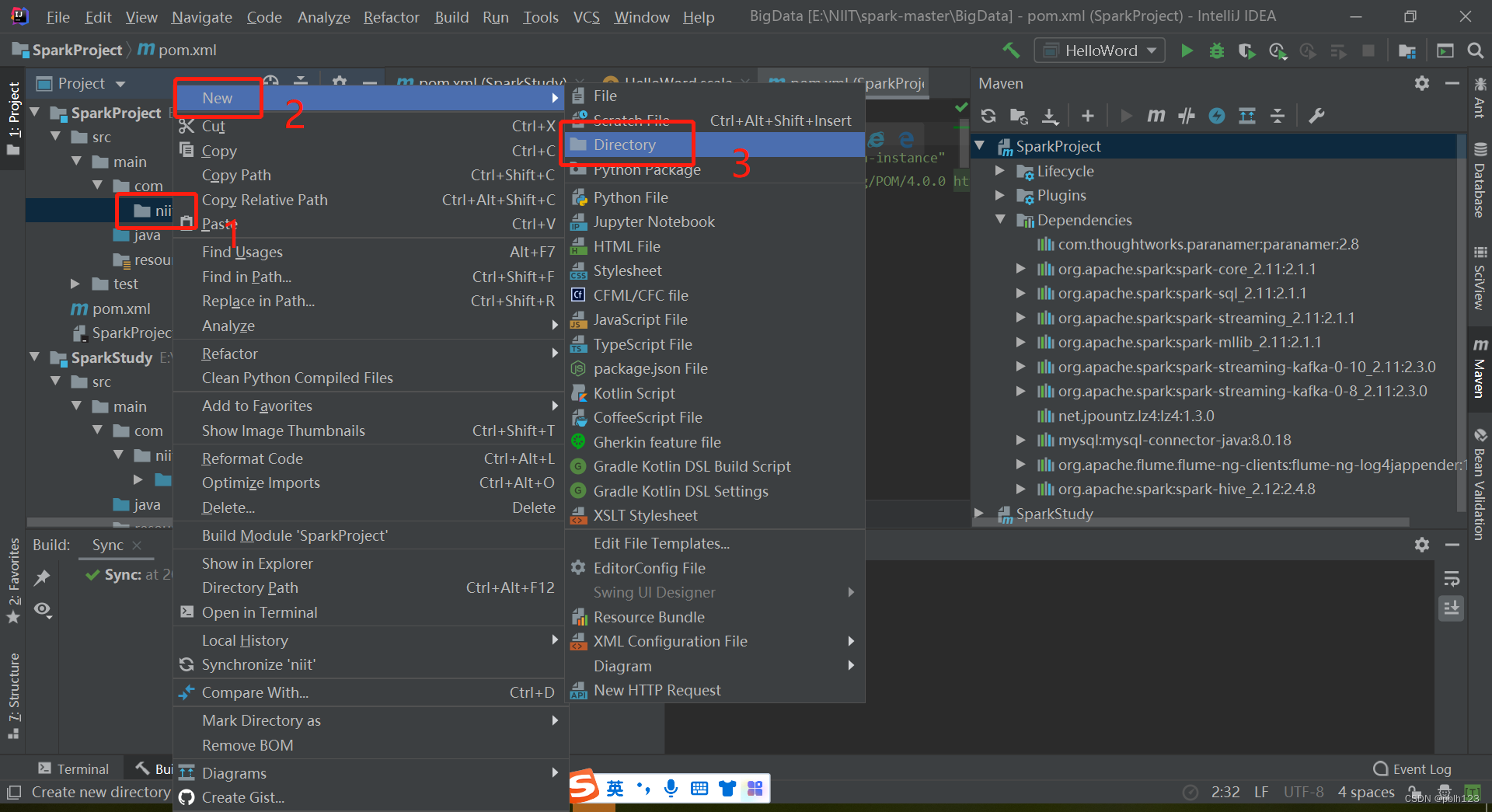

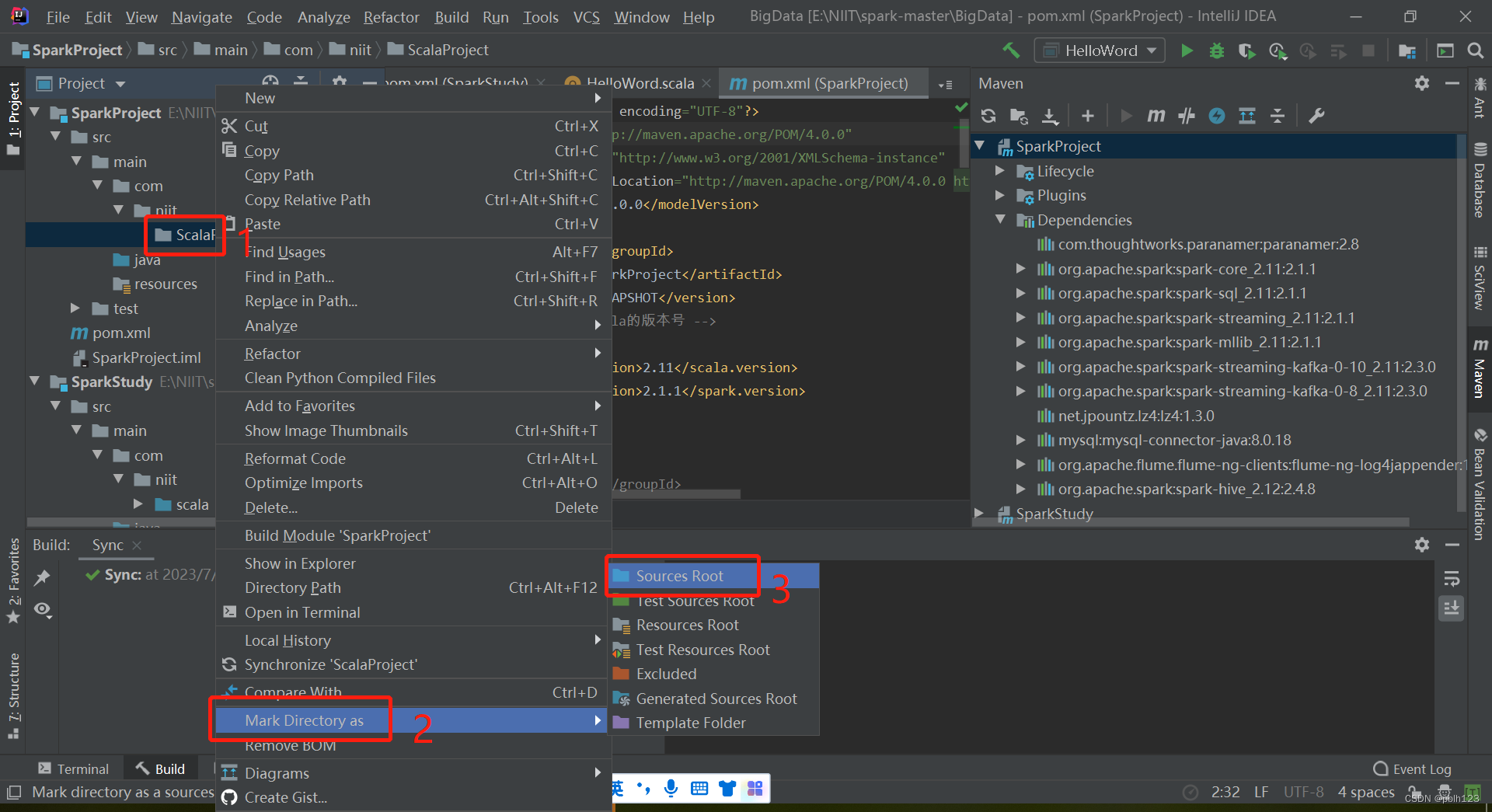
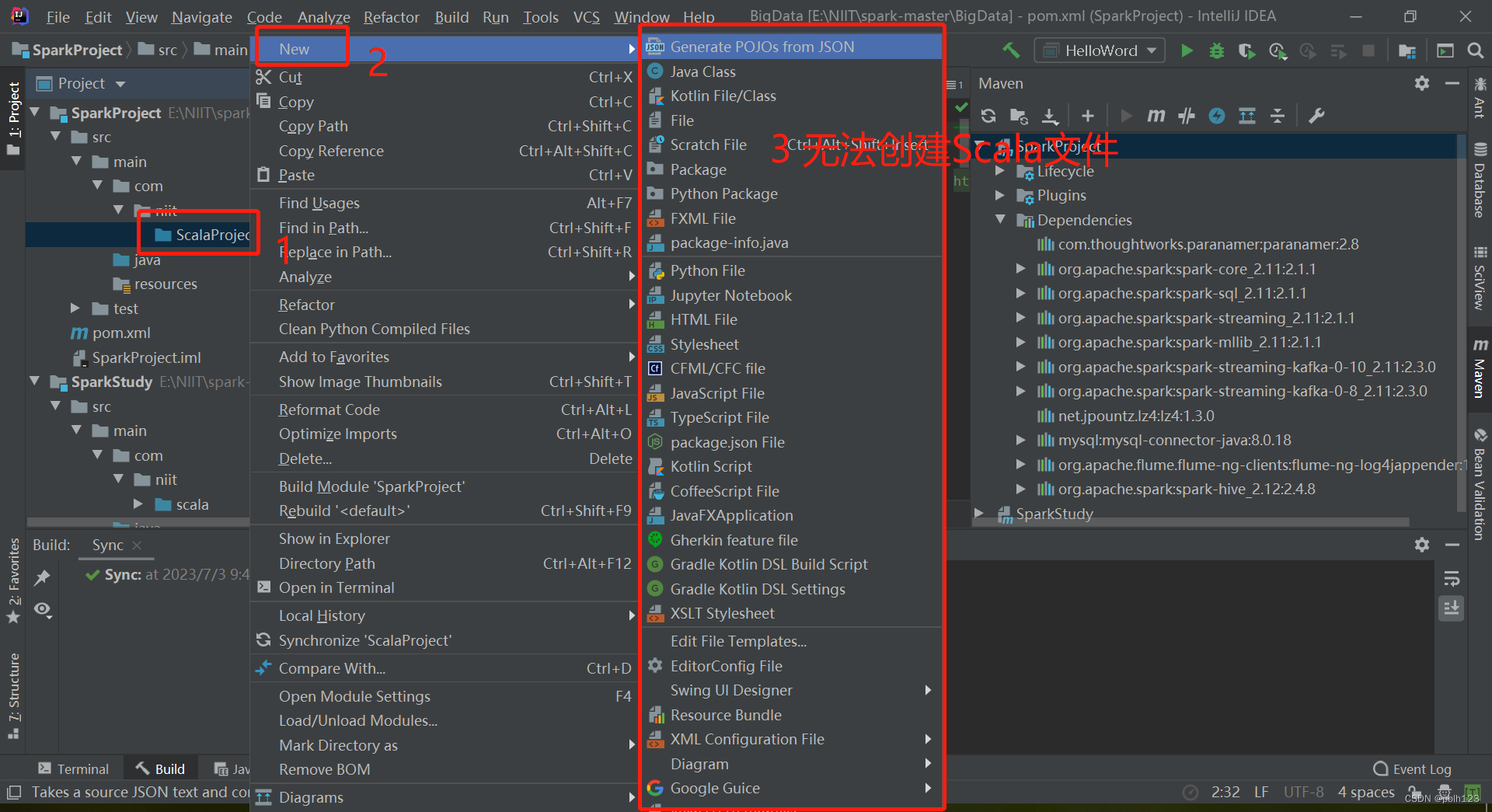
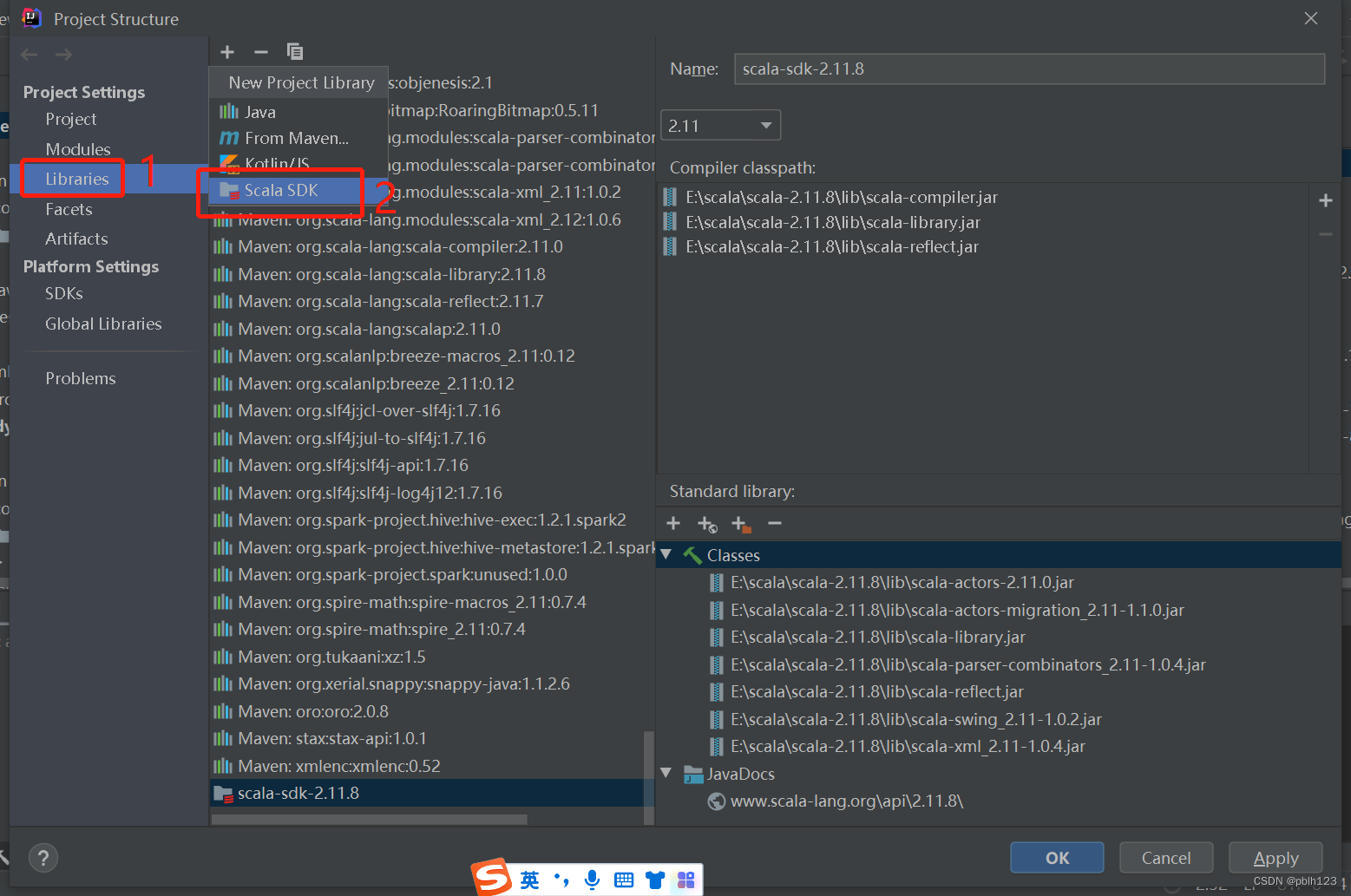
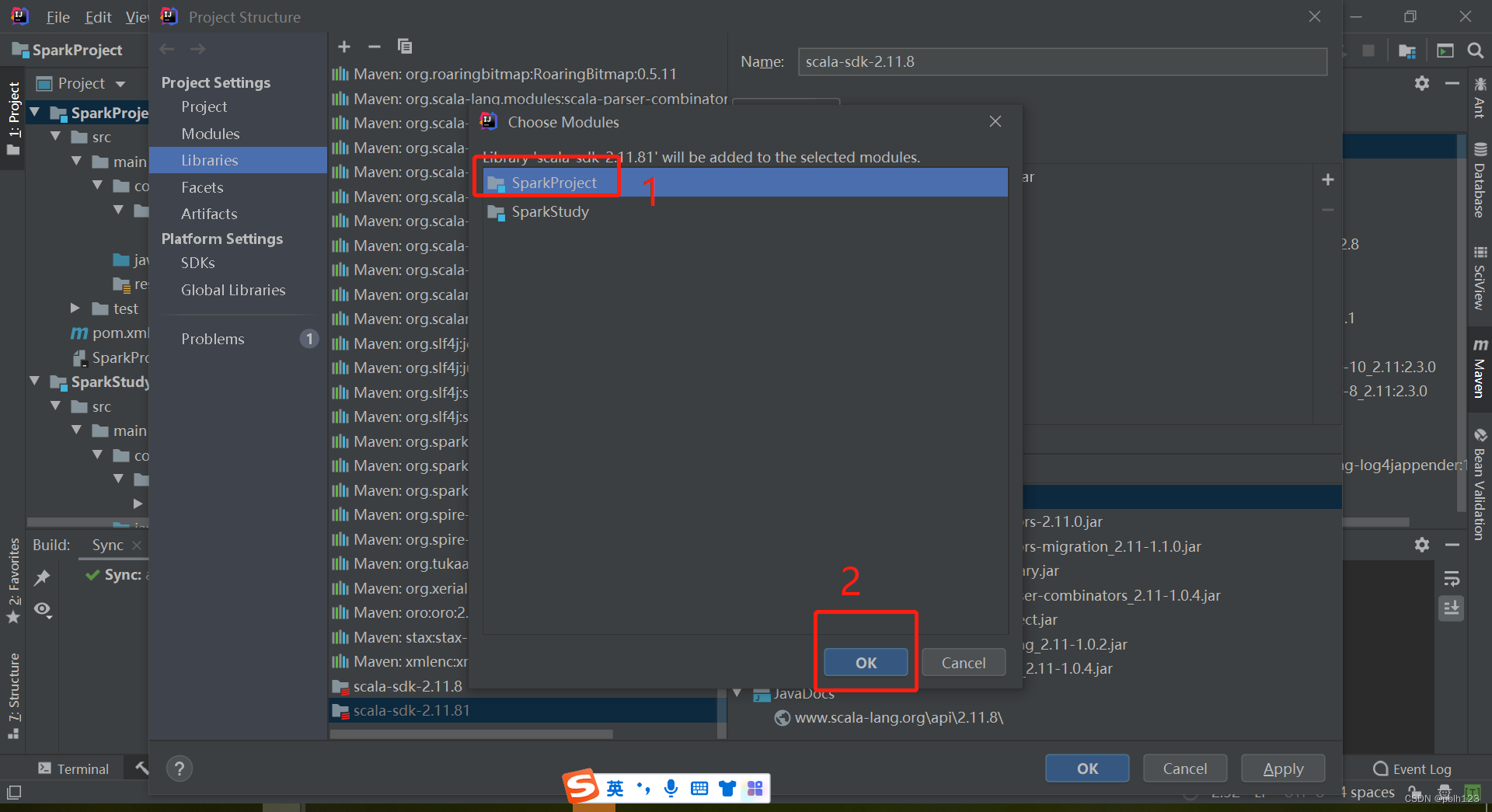
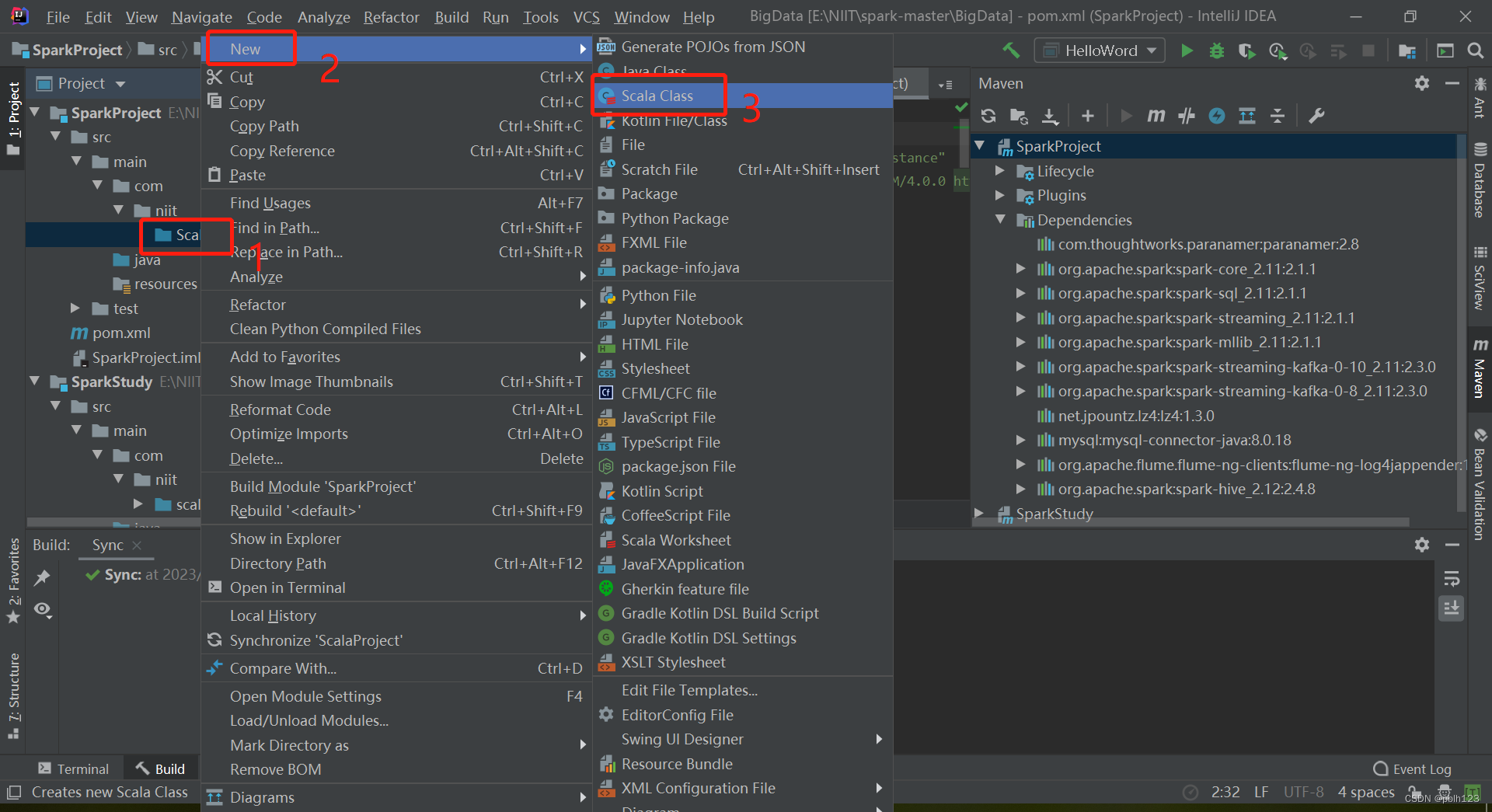
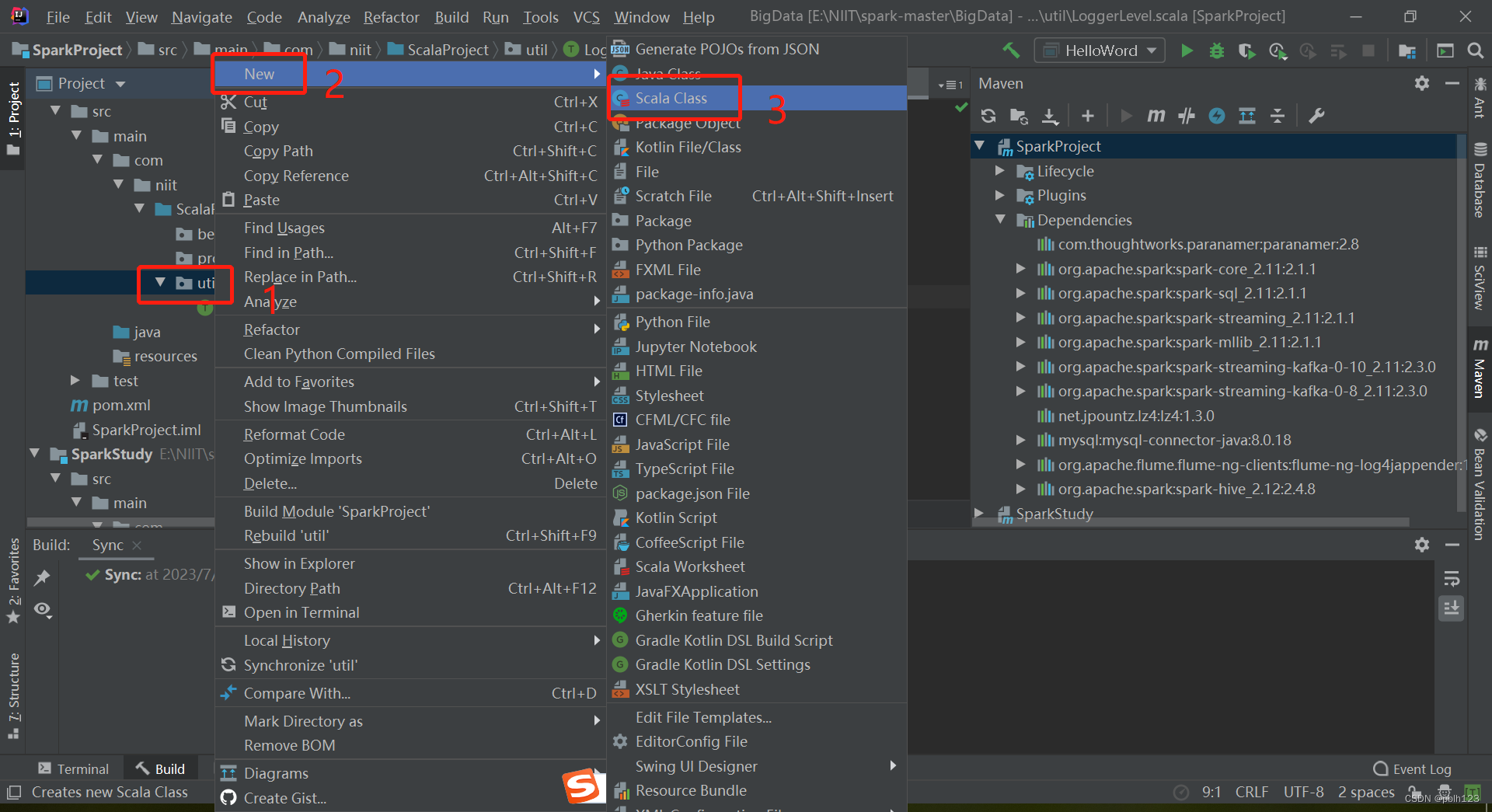
二、解决无法创建scala文件问题


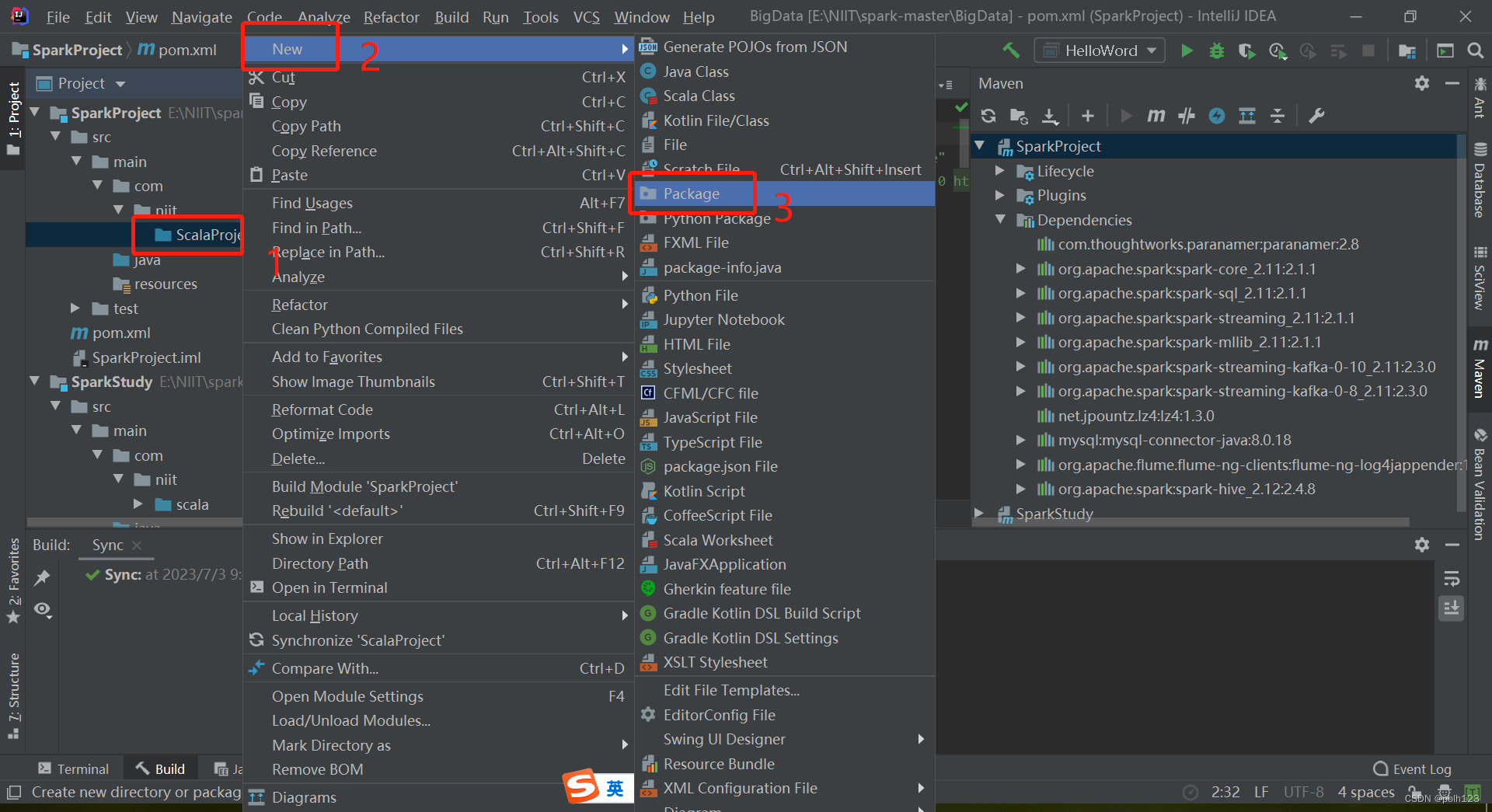
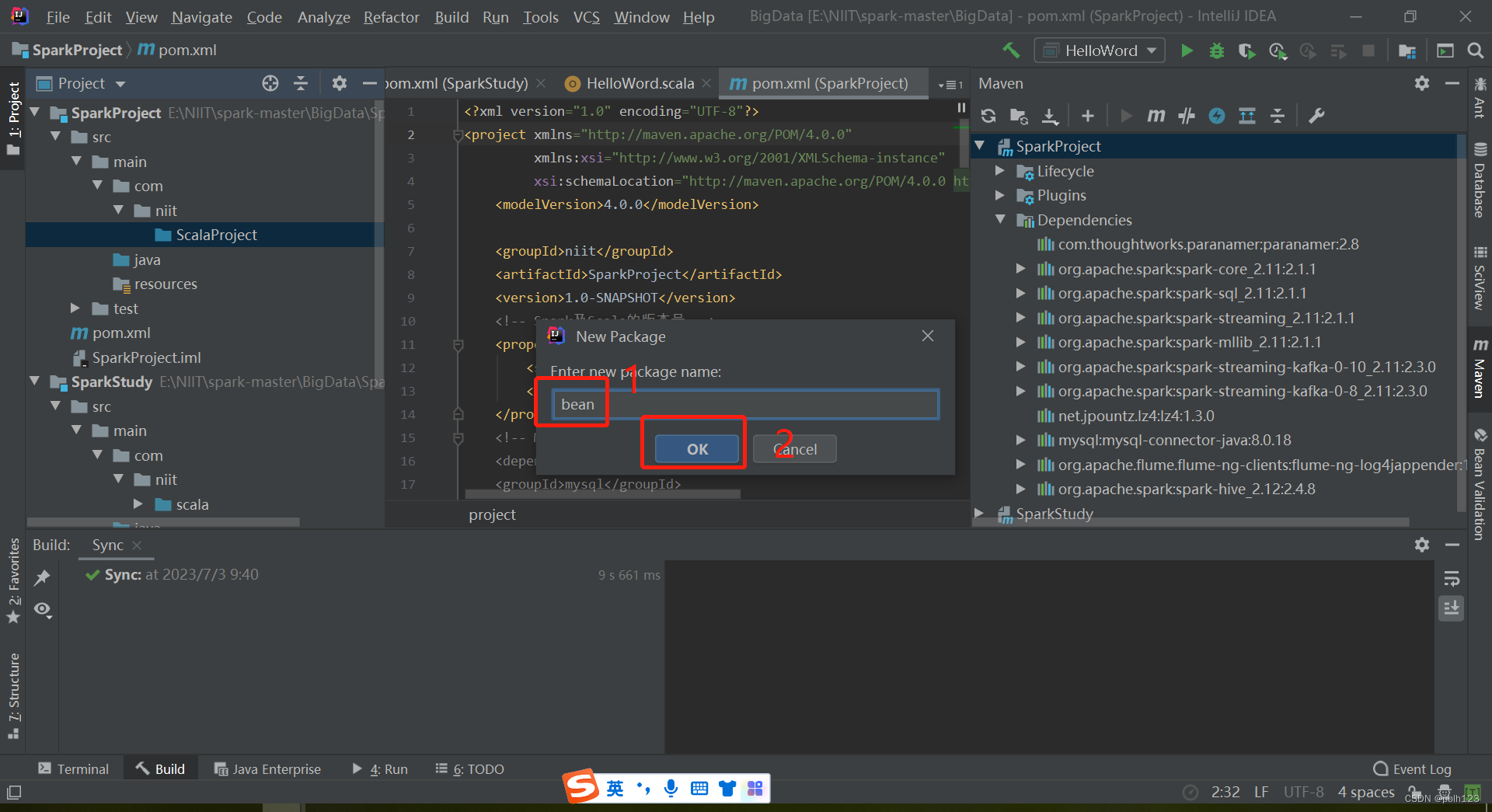
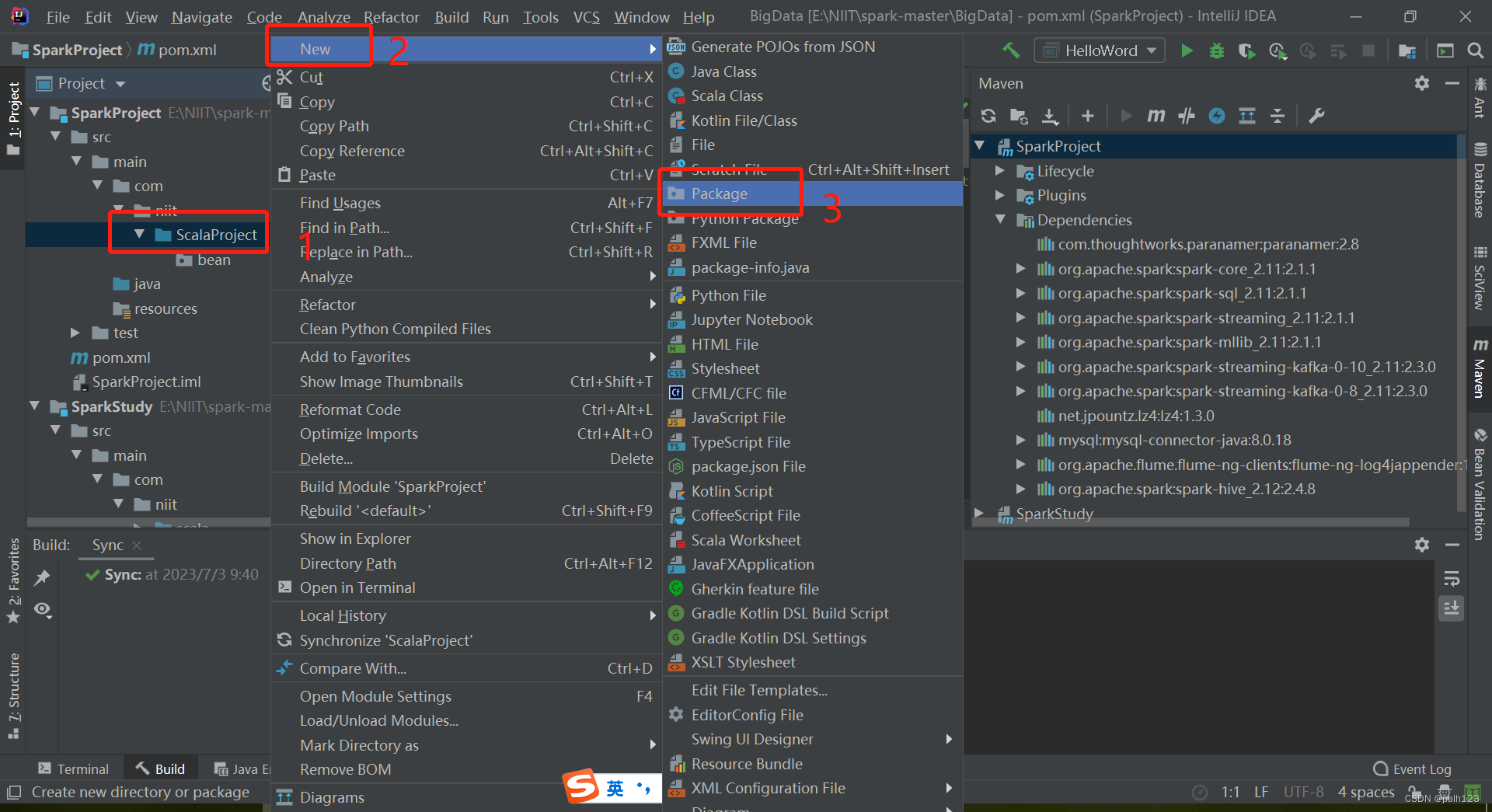
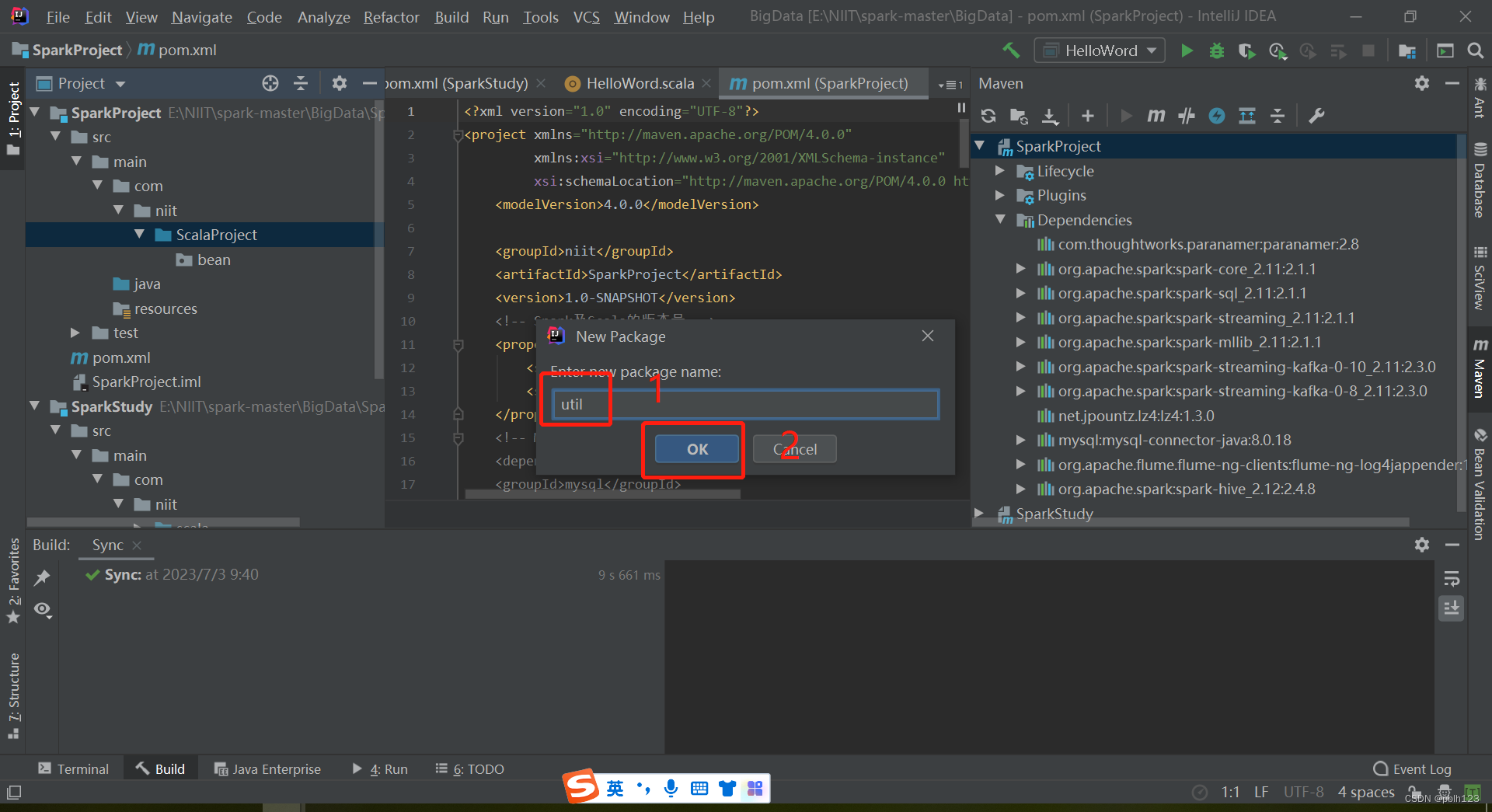


三、编写LoggerLevel特质


在特质 下增加如下代码
Logger.getLogger("org").setLevel(Level.ERROR)这个时候需要导包

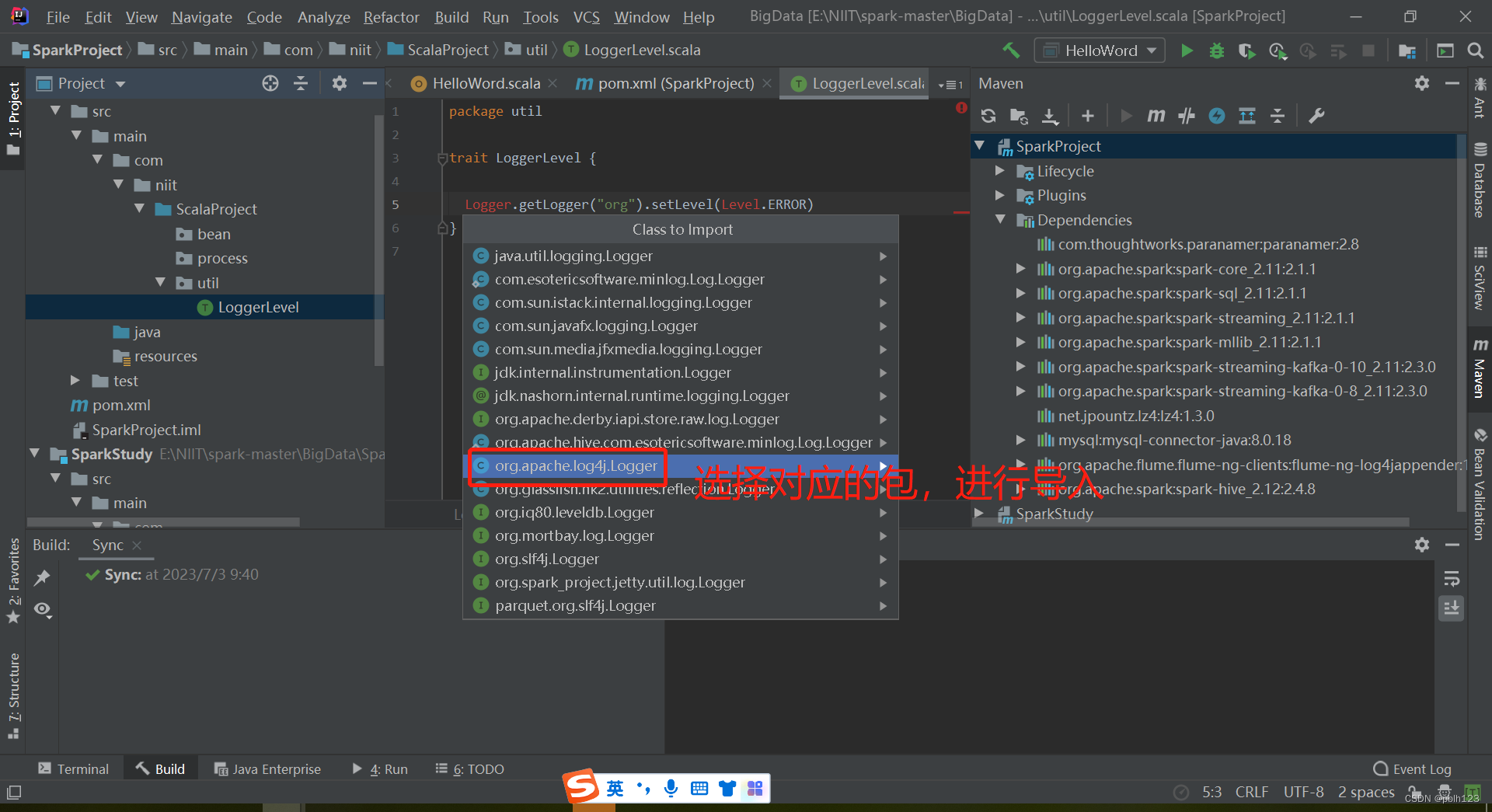


完整代码如下:
import org.apache.log4j.{Level, Logger}trait LoggerLevel {Logger.getLogger("org").setLevel(Level.ERROR)}四、编写getLocalSparkSession方法

以下是完整代码:
import org.apache.spark.sql.SparkSessionobject SparkUnit {/*** 一个class参数**/def getLocalSparkSession(appName: String): SparkSession = {SparkSession.builder().appName(appName).master("local[2]").getOrCreate()}def getLocalSparkSession(appName: String, support: Boolean): SparkSession = {if (support) SparkSession.builder().master("local[2]").appName(appName).enableHiveSupport().getOrCreate()else getLocalSparkSession(appName)}def getLocalSparkSession(appName: String, master: String): SparkSession = {SparkSession.builder().appName(appName).master(master).getOrCreate()}def getLocalSparkSession(appName: String, master: String, support: Boolean): SparkSession = {if (support) SparkSession.builder().appName(appName).master(master).enableHiveSupport().getOrCreate()else getLocalSparkSession(appName, master)}def stopSpark(ss: SparkSession) = {if (ss != null) {ss.stop()}}}相关文章:
2023_Spark_实验十六:编写LoggerLevel方法及getLocalSparkSession方法
一、搭建Spark项目结构 在SparkProject模块的pom.xml文件中增加一下依赖,并等待依赖包下载完毕,如上图。 <!-- Spark及Scala的版本号 --><properties><scala.version>2.11</scala.version><spark.version>2.1.1</sp…...

彻底搞懂:防止表单重复提交,前端限制还是后端限制?
欢迎大家来到小米的技术分享专栏!今天我将为大家带来一个热门话题:如何有效地防止表单重复提交。在开发中,我们常常会遇到这样的问题:用户频繁点击提交按钮,导致数据重复提交,给系统和用户体验带来不必要的…...
OCPP1.6协议
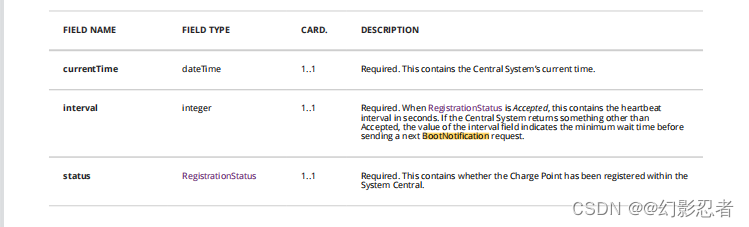
目录 导言 功能简介 本地授权列表 类型 IdToken IdTagInfo 授权状态 协议指令 1、授权 1.1 说明 1.2 Authorize.req 1.3 Authorize.conf 1.4 JSON格式 1.5 代码 2、启动通知 2.1 说明 2.2 BootNotification.req 2.3 BootNotification.conf 2.4 JSON格式 2…...

【数据存储:小端模式和大端模式】
一、引言 在计算机科学中,数据存储模式是指如何将数据存储在计算机内存中的方式。小端模式和大端模式是两种主要的字节序方式,它们决定了字节在内存中的排列顺序。这种字节顺序的选择对于跨平台编程和数据传输至关重要。在这篇博客中,我们将…...

【git】gitlab安装、备份
gitlab官网 官网:官网 中文官网:中文官网 作为一个英文不好的程序员,所以我都去中文网站去看了。下面也是带着大家去走走 安装gitlab 我不想写具体的安装方法,直接去逛网看下面是我的截图。步骤非常详细。 安装文档地址&…...
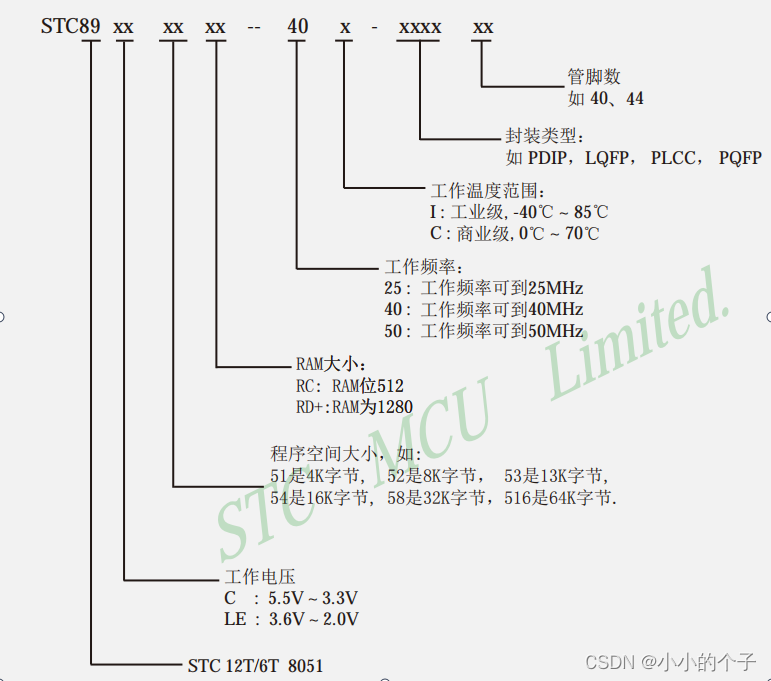
C51--基本认知
单片机基本认知: 1、什么是单片机 单片机是一种集成电路芯片。 把具有数据处理能力的中央处理器 CPU、随机存储器RAM、只读存储器ROM。 多种 I / O 口和中断系统、定时器/计数器等功能(可能还包括显示驱动电路、脉宽调制电路、模拟多路转换器、A/D转换器…...
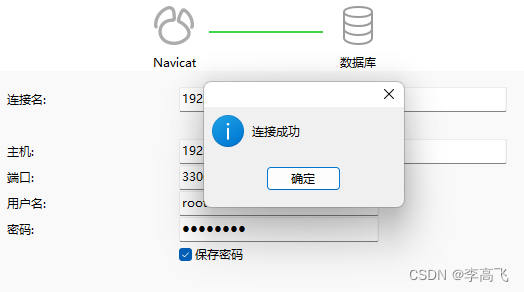
centos7 安装 mysql 8.0
文章目录 环境介绍一、安装前准备 1.卸载MariaDB 1.1 查看是否安装mariadb1.2 卸载1.3 检查是否卸载干净 2.检查依赖 2.1 查看是否安装libaio2.2 查看是否安装numactl 二、安装MySQL 1.下载资源包 1.1 官网下载1.2 wget下载 2.解压3.重命名4.创建存储数据文件5.设置用户组并赋…...
)
Vue15 计算属性VS监视属性(侦听属性)
计算属性VS监视属性(侦听属性) computed和watch之间的区别: 1.computed能完成的功能,watch都可以完成。 2.watch能完成的功能,computed不一定能完成,例如:watch可以进行异步操作。 两个重要的小…...

快速全面掌握数据库系统核心知识点
快速全面掌握数据库系统核心知识点 一、数据库系统二、三级模式-两层映射三、三级模式-视图四、数据库设计过程五、E-R模型六、关系代数七、规范化理论八、函数依赖九、规范化理论-键十、规范化理论-求候选键十一、规范化理论-范式十二、规范化理论-第一范式十三、规范化理论-第…...

学习笔记 | 音视频 | 推流项目框架及细节
推流项目: 跑起来项目,再调,创造问题,注意项目跑起来包括哪些步骤 前期准备:环境的配置 依赖库要交叉编译,编译还需注意依赖的库对应的头文件(注意是绝对路径还是相对路径) Rv1126_lib、arm_libx264、arm_libx265、arm_libsrt、arm32_ffmpeg_srt、arm_openssl Ubuntu搭…...
拓扑几何学
目录 一,欧拉定理 1,平面图论图 2,单连通多面体 3,一般多面体 一,欧拉定理 1,平面图论图 在一个联通无向图中,点数-边数面数 1 如: 7-126 1 如果把最外面的五边形外面也算…...

1.12.C++项目:仿muduo库实现并发服务器之LoopThreadPool模块的设计
文章目录 一、LoopThreadPool模块二、实现思想(一)功能(二)意义(三)功能设计 三、代码 一、LoopThreadPool模块 1.线程数量可配置(0或多个) 2. 对所有的线程进行管理,其…...

SpringBoot介绍
一、什么是SpringBoot 在使用传统的Spring去做Java EE(Java Enterprise Edition)开发中,大量的 XML 文件存在于项目之中,导致JavaEE项目变得慢慢笨重起来,繁琐的配置和整合第三方框架的配置,导致了开发和部…...

2022最新版-李宏毅机器学习深度学习课程-P17 卷积神经网络CNN
一、CNN 用于图像分类 需要图片大小统一 彩色图像分为R G B 三层,展平后首尾相接 值代表着颜色的强度 图像识别中不需要全连接的,参数太多了 观测1:通过判断多个小局部图像就能判断出图片标签 感受野的定义 简化1 感受野可以重叠ÿ…...

微博清理僵尸粉
1.选择chrome或者firefox浏览器 2.登陆微博账号 3.chrome右键点检查,选择console firefox右键点检查,选择控制台 4.粘贴下面代码到console或者控制台并且回车 let removeTargetFans false; /*是否删除符合条件的粉丝,默认关闭*/let dee…...

创建React Native的第一个hello world工程
创建React Native的第一个hello world工程 需要安装好node、npm环境 如果之前没有安装过react-native-cli脚手架的,可以按照下述步骤直接安装。如果已经安装过的,但是在使用这个脚手架初始化工程的时候遇到下述报错的话 cli.init(root, projectname);…...
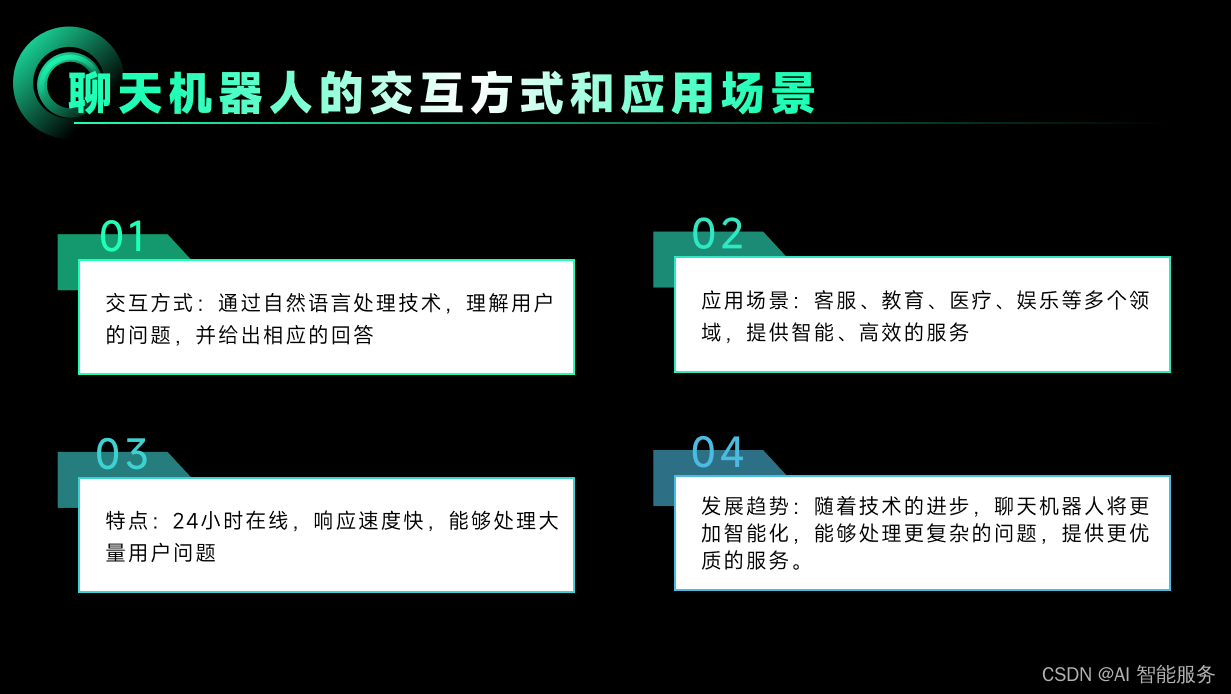
基础课3——自然语言处理的应用
自然语言处理是一种将人类语言转换为机器语言,以实现人机交互的技术。应用非常广泛,例如: 人机交互:自然语言处理技术可以应用于人机交互,让机器能够理解和运用人类语言,从而实现更加智能化的交互体验。 机…...
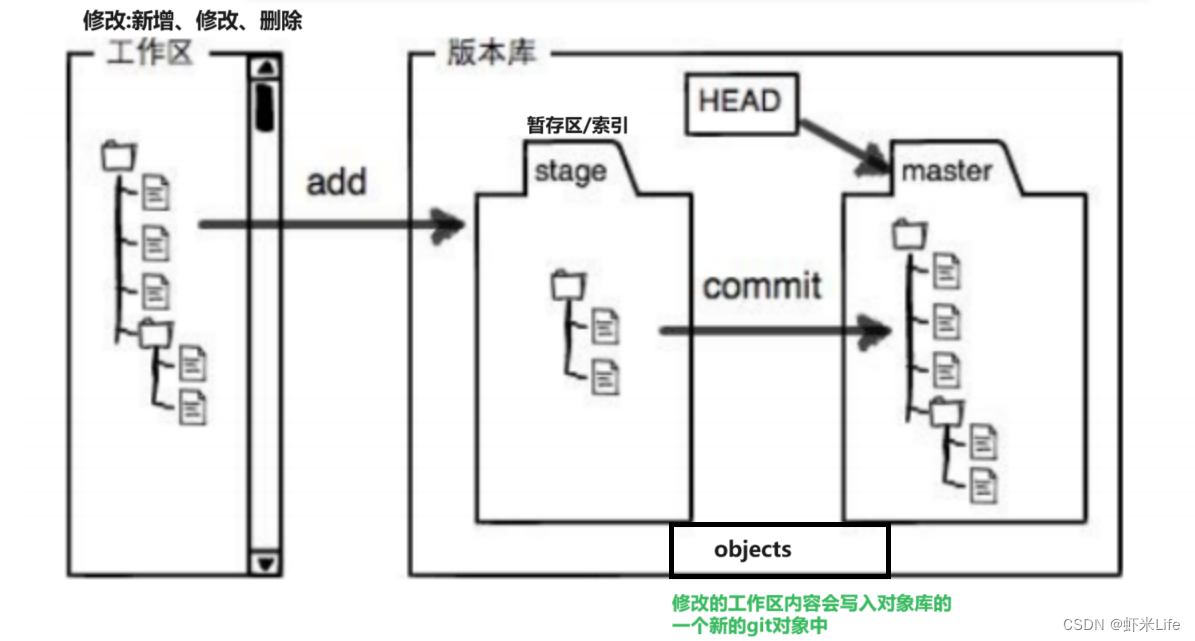
理解 Git 的三个工作区:工作区、暂存区和版本库
文章目录 创建 Git 本地仓库配置Git认识⼯作区、暂存区、版本库添加⽂件--场景查看 .git ⽂件添加⽂件--场景⼆ 创建 Git 本地仓库 要提前说的是,仓库是进⾏版本控制的⼀个⽂件⽬录。我们要想对⽂件进⾏版本控制,就必须先创建⼀个仓库出来。创建⼀个 Gi…...

web前端基础训练-----创建用户反馈表单
1,实验代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>用户反馈表单</title></head><body><form><fieldset><h1>用户反馈</h1><hr/><h4>亲爱的用…...

Scrum 敏捷管理流程图及敏捷管理工具
敏捷开发中的Scrum流程通常可以用一个简单的流程图来表示,以便更清晰地展示Scrum框架的各个阶段和活动。以下是一个常见的Scrum流程图示例: 转自:Leangoo.com 免费敏捷工具 这个流程图涵盖了Scrum框架的主要阶段和活动,其中包括…...
)
千问 LeetCode 2402.会议室 III public int mostBooked(int n, int[][] meetings)
这道题是经典的会议室 III,核心是双堆模拟,一个堆管空闲会议室(按编号排序),一个堆管正在使用的会议室(按结束时间排序)。解题思路1. 排序:按会议开始时间升序排列。 2. 双堆初始化&…...

基于SpringAI开发的通用RAG脚手框架,适配各种场景
RAG 业务落地开发指导 本文面向后续把这套 RAG 能力接入业务系统的开发者,重点回答三件事: 上游业务请求怎么进入 RAG。RAG 内部各组件怎么串起来。数据分别存到 MySQL、文件存储、向量库和搜索引擎的哪里。 1. 总体边界 独立工程保留的是一套完整 R…...

Postman+Newman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定
PostmanNewman自动化测试报告生成全攻略:让微信小程序接口回归测试5分钟搞定 在追求研发效能的今天,手工重复执行接口测试已成为效率瓶颈。想象一下:每次微信小程序迭代更新,测试工程师都需要在Postman中逐个点击上百个接口用例&a…...

朋升爱生活
我爱生活。...

GraphRAG 深度解析:把知识图谱接进检索链路,多跳推理准确率从 50% 提到 85%
很多同学搭完向量 RAG 之后,调了无数遍 Chunk 大小、换了好几个 Embedding 模型,多跳推理准确率就是卡在 50% 左右,怎么都上不去。比如「A 公司 CTO 和 B 公司 CEO 到底有什么合作关系」这类问题,答案散落在三个文档里,…...

ElevenLabs多角色对话生成性能压测报告:单实例并发超86路时语音错位率飙升至41.7%,我们找到了唯一稳定解
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs多角色对话生成性能压测报告:单实例并发超86路时语音错位率飙升至41.7%,我们找到了唯一稳定解 在真实业务场景中,ElevenLabs API 被广泛用于构建多角色交互…...

信号处理库mattbaconz/signal:实现优雅停机与进程通信的跨平台解决方案
1. 项目概述:一个信号处理与通信的瑞士军刀最近在GitHub上看到一个挺有意思的项目,mattbaconz/signal。光看名字,你可能会联想到那个知名的加密通讯应用,但点进去你会发现,这是一个完全不同的技术世界。这是一个由开发…...

tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南
tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南 【免费下载链接】tcpdive A TCP performance profiling tool. 项目地址: https://gitcode.com/gh_mirrors/tc/tcpdive tcpdive作为一款专业的TCP性能分析工具,在生产环境中的性能表现至关重要…...

Obsidian Importer:一站式笔记数据迁移终极指南
Obsidian Importer:一站式笔记数据迁移终极指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-importer …...
)
TensorRT量化实战:手把手教你用Entropy Calibration校准激活值(附代码避坑)
TensorRT熵校准实战:从理论到代码的完整避坑指南 引言 在深度学习模型部署领域,量化技术已经成为减小模型体积、提升推理速度的关键手段。而作为量化过程中的核心环节,激活值校准直接决定了最终模型的精度表现。TensorRT提供的Entropy Calibr…...