用户行为数据案例
一、环境要求
Hadoop+Hive+Spark+HBase 开发环境。
二、数据描述
本数据集包含了2017-09-11至2017-12-03之间有行为的约5458位随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下具体字段说明如下:
| 列名称 | 列中文名称 | 说明 |
| user_id | 用户 ID | 整数类型,序列化后的用户 ID |
| item_id | 商品 ID | 整数类型,序列化后的商品 ID |
| category_id | 商品类目 ID | 整数类型,序列化后的商品所属类目 ID |
| behavior_type | 行为类型 | 字符串,枚举类型,包括 ('pv', 'buy', 'cart', 'fav') |
| time | 时间戳 | 行为发生的时间戳 |
用户行为类型共有四种,它们分别是:
| 行为类型 | 说明 |
| pv | 商品详情页 pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
三、功能要求
1.数据准备
(1)在 HDFS 中创建目录/data/userbehavior,并将 UserBehavior.csv 文件传到该目录。
[root@kb135 examdata]# hdfs dfs -mkdir -p /data/userbehavior
[root@kb135 examdata]# hdfs dfs -put ./UserBehavior.csv /data/userbehavior(2)通过 HDFS 命令查询出文档有多少行数据。
[root@kb135 examdata]# hdfs dfs -cat /data/userbehavior/UserBehavior.csv | wc -l2.数据清洗
(1)在 Hive 中创建数据库 exam
hive (default)> create database exam;
hive (default)> use exam;
(2)在 exam 数据库中创建外部表 userbehavior,并将 HDFS 数据映射到表中
create external table userbehavior(user_id int,item_id int,category_id int,behavior_type string,`time` bigint
)
row format delimited fields terminated by ","
stored as textfile location '/data/userbehavior';
(3)在 HBase 中创建命名空间 exam,并在命名空间 exam 创建 userbehavior 表,包
含一个列簇 info
hbase(main):002:0> create_namespace 'exam202010'
hbase(main):003:0> create 'exam202010:userbehavior','info'
(4)在 Hive 中创建外部表 userbehavior_hbase,并映射到 HBase 中,并将数
据加载到 HBase 中
create external table userbehavior_hbase(user_id int,item_id int,category_id int,behavior_type string,`time` bigint
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' withserdeproperties("hbase.columns.mapping"=":key,info:item_id,info:category_id,info:behavior_type,info:time")
tblproperties ("hbase.table.name"="exam202010:userbehavior");insert into userbehavior_hbase select * from userbehavior;
(5)在 exam 数据库中创建内部分区表 userbehavior_partitioned(按照日期进行分区),
并通过查询 userbehavior 表将时间戳格式化为”年-月-日时:分:秒”格式,将数据插入至 userbehavior_partitioned 表中,例如下图:
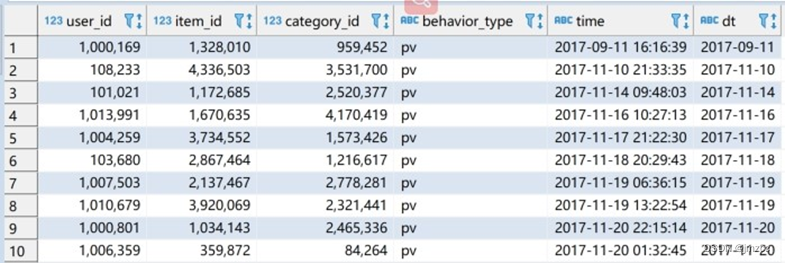
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table userbehavior_partition partition (dt)
select user_id,item_id,category_id,behavior_type,from_unixtime(`time`) as `time`,from_unixtime(`time`,'yyyy-MM-dd') dt
from userbehavior;3.用户行为分析
使用 Spark,加载 HDFS 文件系统 UserBehavior.csv 文件,并分别使用 RDD 完成以下分析。
加载文件:
scala> val fileRdd = sc.textFile("hdfs://kb135:9000/data/userbehavior")(1)统计 uv 值(一共有多少用户访问淘宝)
scala> fileRdd.map(x=>x.split(",")).filter(_.length==5).map(x=>x(0)).distinct().count
res1: Long = 5458scala> fileRdd.map(x=>x.split(",")).filter(_.length==5).groupBy(x=>x(0)).count
res2: Long = 5458
(2)分别统计浏览行为为点击,收藏,加入购物车,购买的总数量
scala> fileRdd.map(x=>x.split(",")).filter(_.length==5).map(x=>(x(3),1)).reduceByKey(_+_).collect.foreach(println)
(cart,30888)
(buy,11508)
(pv,503881)
(fav,15017)scala> fileRdd.map(x=>x.split(",")).filter(_.length==5).map(x=>(x(3),1)).groupByKey().map(x=>(x._1,x._2.toList.size)).collect.foreach(println)
(cart,30888)
(buy,11508)
(pv,503881)
(fav,15017)
4.找出有价值的用户
(1)使用 SparkSQL 统计用户最近购买时间。以 2017-12-03 为当前日期,计算时间范围为一个月,计算用户最近购买时间,时间的区间为 0-30 天,将其分为 5 档,0-6 天,7-12 天,13-18 天,19-24 天,25-30 天分别对应评分 4 到 0
with
tb as
(select user_id,datediff('2017-12-03',max(dt)) as diff,max(dt)
from userbehavior_partition
where dt>'2017-11-03' and behavior_type='buy'
group by user_id),
tb2 as
(select user_id,(case when diff between 0 and 6 then 4 when diff between 7 and 12 then 3 when diff between 13 and 18 then 2 when diff between 19 and 24 then 1 when diff between 25 and 30 then 0 else null end ) tag
from tb)
select * from tb2 where tag=3;
(2)使用 SparkSQL 统计用户的消费频率。以 2017-12-03 为当前日期,计算时间范围为一个月,计算用户的消费次数,用户中消费次数从低到高为 1-161 次,将其分为 5 档,1-32,33-64,65-96,97-128,129-161 分别对应评分 0 到 4
with
tb as
(select user_id,count(user_id) as num from userbehavior_partition
where dt between '2017-11-03' and '2017-12-03' and behavior_type='buy'
group by user_id)
select user_id,(case when num between 129 and 161 then 4 when num between 97 and 128 then 3 when num between 65 and 96 then 2 when num between 33 and 64 then 1 when num between 1 and 32 then 0 else null end) tag
from tb;相关文章:
用户行为数据案例
一、环境要求 HadoopHiveSparkHBase 开发环境。 二、数据描述 本数据集包含了2017-09-11至2017-12-03之间有行为的约5458位随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类…...

selenium教程 —— css定位
说明:本篇博客基于selenium 4.1.0 selenium-css定位 element_css driver.find_element(By.CSS_SELECTOR, css表达式) 复制代码 css定位说明 selenium中的css定位,实际是通过css选择器来定位到具体元素,css选择器来自于css语法 css定位优点…...
)
Leetcode 1834. Single-Threaded CPU (堆好题)
Single-Threaded CPU Medium You are given n tasks labeled from 0 to n - 1 represented by a 2D integer array tasks, where tasks[i] [enqueueTimei, processingTimei] means that the ith task will be available to process at enque…...
21-数据结构-内部排序-交换排序
简介:主要根据两个数据进行比较从而交换彼此位置,以此类推,交换完全部。主要有冒泡和快速排序两种。 目录 一、冒泡排序 1.1简介: 1.2代码: 二、快速排序 1.1简介: 1.2代码: 一、冒泡排序…...
5-k8s-探针介绍
文章目录 一、探针介绍二、探针类型三、探针定义方式四、探针实例五、启动探针测试六、存活探针测试七、就绪探针测试 一、探针介绍 概念 在 Kubernetes 中 Pod 是最小的计算单元,而一个 Pod 又由多个容器组成,相当于每个容器就是一个应用,应…...
【网络安全 --- MySQL数据库】网络安全MySQL数据库应该掌握的知识,还不收藏开始学习。
四,MySQL 4.1 mysql安装 #centos7默认安装的是MariaDB-5.5.68或者65, #查看版本的指令:[rootweb01 bbs]# rpm -qa| grep mariadb #安装mariadb的最新版,只是更新了软件版本,不会删除之前原有的数据。 #修改yum源的配…...

【MyBatis系列】- 什么是MyBatis
【MyBatis系列】- 什么是MyBatis 文章目录 【MyBatis系列】- 什么是MyBatis一、学习MyBatis知识必备1.1 学习环境准备1.2 学习前掌握知识二、什么是MyBatis三、持久层是什么3.1 为什么需要持久化服务3.2 持久层四、Mybatis的作用五、MyBatis的优点六、参考文档一、学习MyBatis知…...

【Linux】Ubuntu美化bash【教程】
【Linux】Ubuntu美化bash【教程】 文章目录 【Linux】Ubuntu美化bash【教程】1. 查看当前环境中是否有bash2. 安装Synth-Shell3. 配置Synth-Shell4. 取消greeterReference 1. 查看当前环境中是否有bash 查看当前使用的bash echo $SHELL如下所示 sjhsjhR9000X:~$ echo $SHELL…...

微信小程序仿苹果负一屏由弱到强的高斯模糊
进入下面小程序可以体验效果,然后进入更多。查看模糊效果 一、创建小程序组件 二、代码 wxml: <view class"topBar-15"></view> <view class"topBar-14"></view> <view class"topBar-13"></view&…...

js中的new方法
new方法的作用:创建一个实例对象,并继承原对象的属性和方法; new对象内部操作: 1,创建一个新对象,将新对象的proto属性指向原对象的prototype属性; 2,构造函数执行环境中的this指向…...

机器学习-无监督算法之降维
降维:将训练数据中的样本从高维空间转换到低维空间,降维是对原始数据线性变换实现的。为什么要降维?高维计算难,泛化能力差,防止维数灾难优点:减少冗余特征,方便数据可视化,减少内存…...
ubuntu20.04下Kafka安装部署及基础使用
Ubuntu安装kafka基础使用 kafka 安装环境基础安装下载kafka解压文件修改配置文件启动kafka创建主题查看主题发送消息接收消息 工具测试kafka Assistant 工具连接测试基础连接连接成功查看topic查看消息查看分区查看消费组 Idea 工具测试基础信息配置信息当前消费组发送消息消费…...

汉得欧洲x甄知科技 | 携手共拓全球化布局,助力出海中企数智化发展
HAND Europe 荣幸获得华为云颁发的 GrowCloud 合作伙伴奖项,进一步巩固了其在企业数字化领域的重要地位。于 2023 年 10 月 5 日,HAND Europe 参加了华为云荷比卢峰会,并因其在全球拓展方面的杰出贡献而荣获 GrowCloud 合作伙伴奖项的认可。 …...

【Javascript保姆级教程】显示类型转换和隐式类型转换
文章目录 前言一、显式类型转换1.1 字符串转换1.2 数字转换1.3 布尔值转换 二、隐式类型转换2.1 数字与字符串相加2.2 布尔值与数字相乘 总结 前言 JavaScript是一种灵活的动态类型语言,这意味着变量的数据类型可以在运行时自动转换,或者通过显式类型转…...

C++算法前缀和的应用:分割数组的最大值的原理、源码及测试用例
分割数组的最大值 相关知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例:付视频课程 二分 过些天整理基础知识 题目 给定一个非负整数数组 nums 和一个整数 m ,你需要将这个数组分成 m 个非空的连续子数组。 设计一个算法…...
gitlab自编译 源码下载
网上都是怎么用 gitlab,但是实际开发中有需要针对 gitlab 进行二次编译自定义实现功能的想法。 搜索了网上的资料以及在官网的查找,查到了如下 gitlab 使用 ruby 开发。 gitlab 下载包 gitlab/gitlab-ce - Packages packages.gitlab.com gitlab/gitl…...
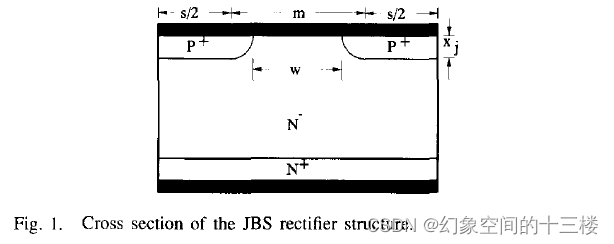
SBD(Schottky Barrier Diode)与JBS(Junction Barrier Schottky)
SBD和JBS二极管都是功率二极管,具有单向导电性,在电路中主要用于整流、箝位、续流等应用。两者的主要区别在于结构和性能。 结构 SBD是肖特基二极管的简称,其结构由一个金属和一个半导体形成的金属-半导体结构成。 JBS是结势垒肖特基二极…...
HANA:计算视图-图形化Aggregation组件-踩坑小记(注意事项)
今天遇到在做HANA视图开发的时候,遇到一个事,一直以为是个BUG,可把我气坏了,具体逻辑是这样的,是勇图形化处理的,ACDOCA innerjoin 一个时间维度表,就这么简单,完全按照ACDOCA的主键…...
【milkv】更新rndis驱动
问题 由于windows升级到了11,导致rndis驱动无法识别到。 解决 打开设备管理器,查看网络适配器,没有更新会显示黄色的图标。 右击选择更新驱动...

基于混沌博弈优化的BP神经网络(分类应用) - 附代码
基于混沌博弈优化的BP神经网络(分类应用) - 附代码 文章目录 基于混沌博弈优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.混沌博弈优化BP神经网络3.1 BP神经网络参数设置3.2 混沌博弈算法应用 4.测试结果…...

UE5 Nanite配置指南:开启D3D12与SM6渲染管线
1. 这个提示不是报错,而是UE5在“敲你门”问你准备好了吗?刚打开UE5项目,编辑器右上角突然弹出一个黄色感叹号提示:“Nanite requires project settings to be configured for SM6 and D3D12”——很多新手第一反应是慌࿱…...

AhMyth:跨平台Android远程管理工具的完整指南与实战教程
AhMyth:跨平台Android远程管理工具的完整指南与实战教程 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/A…...

《科技代替了我工作》的传播入口:技术焦虑如何落到听众
从内容传播角度看,《科技代替了我工作》有天然的现实入口,但写法必须克制。它不是技术教程,也不是政策评论,而是把技术变化落到一个普通人的饭碗、身份感和安全感上。这个标题容易被记住,因为它把宏大的技术词变成了第…...

chatgpt-web-midjourney-proxy的Tauri桌面应用:跨平台AI客户端构建终极指南
chatgpt-web-midjourney-proxy的Tauri桌面应用:跨平台AI客户端构建终极指南 想要在本地轻松体验ChatGPT、Midjourney和GPTs的强大功能吗?chatgpt-web-midjourney-proxy项目的Tauri桌面应用为你提供了完美的解决方案!这款跨平台AI客户端让AI助…...

ncmdumpGUI:免费解锁网易云音乐加密文件,3分钟实现跨设备播放自由
ncmdumpGUI:免费解锁网易云音乐加密文件,3分钟实现跨设备播放自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样…...

D1094UK,500MHz频段下20W高功率输出的单端式硅RF MOSFET射频晶体管
简介今天我要向大家介绍的是 TT Electronics / Semelab 的硅RF MOSFET晶体管——D1094UK。这是一款专为VHF/UHF通信频段设计的单端式射频功率场效应管,在28V工作电压、500MHz频率下可提供20W的输出功率。作为一款高性能射频器件,它具备极低的反向传输电容…...
)
RabbitMQ(七大模式+微服务+自用)
一、前置准备安装并启动 RabbitMQ(默认端口 5672)JDK 8、Maven、IDEA所有项目通用工具类 通用 pom,直接复制二、全局统一配置(所有项目必用)1. 公共连接工具类 ConnectionUtil.javajava运行package com.mq.util;impor…...

ComfyUI Manager终极指南:简单快速管理你的AI绘画插件生态系统
ComfyUI Manager终极指南:简单快速管理你的AI绘画插件生态系统 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vario…...

为OpenClaw智能体工作流配置Taotoken作为统一模型服务源
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为统一模型服务源 在构建基于智能体(Agent)的自动化工作流时&#x…...

通过Python快速调用Taotoken实现自动化文档生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Python快速调用Taotoken实现自动化文档生成 对于嵌入式或单片机开发者而言,为Keil5项目编写和维护技术文档是一项耗…...