Flink之源算子Data Source
源算子Data Source
- 概述
- 内置Data Source
- 基于集合构建
- 基于文件构建
- 基于Socket构建
- 自定义Data Source
- SourceFunction
- RichSourceFunction
- 常见连接器
- 第三方系统连接器
- File Source连接器
- DataGen Source连接器
- Kafka Source连接器
- RabbitMQ Source连接器
- MongoDB Source连接器
概述
Flink中的Data Source(数据源、源算子)用于定义数据输入的来源。数据源是Flink作业的起点,它可以从各种数据来源获取数据,例如文件系统、消息队列、数据库等。
将数据源添加到Flink执行环境中,从而创建一个数据流。然后可以对该数据流应用一系列转换和操作,例如过滤、转换、聚合、计算等。最后将结果写入其他系统,例如文件系统、数据库、消息队列等。
数据源是Flink作业中非常重要的组件,它确定了数据的来源和初始输入,是构建流处理和批处理作业的基础。
内置Data Source
Flink Data Source用于定义Flink程序的数据来源,Flink官方提供了多种数据获取方法,用于帮助开发者简单快速地构建输入流
基于集合构建
可以将数据临时存储到内存中,形成特殊的数据结构后,作为数据源使用,比如采用集合类型。一般用来进行本地调试或者验证。
fromCollection(Collection):基于集合构建,集合中的所有元素必须是同一类型fromElements(T ...): 基于元素构建,所有元素必须是同一类型generateSequence(from, to):基于给定的序列区间进行构建fromCollection(Iterator, Class):基于迭代器进行构建。第一个参数用于定义迭代器,第二个参数用于定义输出元素的类型
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 基于元素构建DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3, 4);// 基于集合构建DataStreamSource<Integer> source2 = env.fromCollection(Arrays.asList(1, 2, 3, 4));// 基于给定的序列区间进行构建env.generateSequence(0,100);// 基于迭代器进行构建env.fromCollection(new CustomIterator(), BasicTypeInfo.INT_TYPE_INFO).print();source1.print();env.execute();}
自定义的迭代器CustomIterator,产生 1 到 100 区间内的数据
注意: 自定义迭代器要实现Iterator接口外,还必须要实现序列化接口Serializable ,否则会抛出序列化失败的异常
import java.io.Serializable;
import java.util.Iterator;public class CustomIterator implements Iterator<Integer>, Serializable {private Integer i = 0;@Overridepublic boolean hasNext() {return i < 100;}@Overridepublic Integer next() {i++;return i;}
}
基于文件构建
在本地环境进行测试时可以方便地从本地文件读取数据
readTextFile(path):按照TextInputFormat 格式读取文本文件,并将其内容以字符串的形式返回。示例如下:readFile(fileInputFormat, path) :按照指定格式读取文件。readFile(inputFormat, filePath, watchType, interval, typeInformation):按照指定格式周期性的读取文件。
各个参数含义:
inputFormat:数据流的输入格式filePath:文件路径,可以是本地文件系统上的路径,也可以是HDFS上的文件路径watchType:读取方式,两个可选值: 1.FileProcessingMode.PROCESS_ONCE: 表示对指定路径上的数据只读取一次,然后退出2.FileProcessingMode.PROCESS_CONTINUOUSLY: 表示对路径进行定期地扫描和读取。注意:当文件被修改时,其所有的内容 (包含原有的内容和新增的内容) 都将被重新处理,因此这会打破Flink的exactly-once语义interval:定期扫描的时间间隔typeInformation:输入流中元素的类型
public static void main(String[] args) throws Exception {String filePath = "data/test.text";// 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env// 读取文本文件,并将其内容以字符串的形式返回.readTextFile(filePath).print();env.readFile(new TextInputFormat(new Path(filePath)), filePath, FileProcessingMode.PROCESS_ONCE, 1, BasicTypeInfo.STRING_TYPE_INFO).print();env.execute();}
基于Socket构建
通过监听Socket端口,可以在本地很方便地模拟一个实时计算环境。
Flink提供了socketTextStream方法可以通过host和port从一个Socket中以文本的方式读取数据,以此构建基于Socket的数据流
socketTextStream方法有以下四个主要参数:
hostname:主机名port:端口号,设置为 0 时,表示端口号自动分配delimiter:用于分隔每条记录的分隔符maxRetry:当Socket临时关闭时,程序的最大重试间隔,单位为秒。设置为0时表示不进行重试;设置为负值则表示一直重试
示例如下:
env.socketTextStream("IP", 8888, "\n", 3).print();
读取socket文本流,是流处理场景,这种方式由于吞吐量小、稳定性较差,一般也是用于测试
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);// 读取socket文本流
DataStreamSource<String> socketDS = env.socketTextStream("IP", 8888);
注意:基于Socket构建数据源,一般需要搭配Netcat使用。
Netcat(又称为NC)是一个计算机网络工具,它可以在两台计算机之间建立 TCP/IP 或 UDP 连接。它被广泛用于测试网络中的端口,发送文件等操作。使用 Netcat 可以轻松地进行网络调试和探测,也可以进行加密连接和远程管理等高级网络操作。因为其功能强大而又简单易用,所以在计算机安全领域也有着广泛的应用。
安装nc命令
yum install -y nc
启动socket端口
[root@master ~]# nc -l 8080
abc bcd cde
bcd cde fgh
cde fgh hij
注意:
测试时,先启动端口,后启动程序,会报超时连接异常,最后发送测试数据即可。
自定义Data Source
可以通过实现Flink的SourceFunction、ParallelSourceFunction、RichSourceFunction、RichParallelSourceFunction等类并重写其方法以此实现自定义Data Source
ParallelSourceFunction、RichParallelSourceFunction分别与SourceFunction、RichSourceFunctio功能类似,只不过它们通过SourceContext发送的数据会自动分发到并行任务中去,也就是说具有并行度的功能。
SourceFunction
它是Flink 提供的基础接口之一,用于定义数据源的行为。它包含一个 run 方法,该方法用于启动数据源,并使用SourceContext来发送数据元素。它中的方法是生命周期很简单的基础方法。
操作步骤:
实现SourceFunction接口:创建一个实现SourceFunction接口的类,该接口定义读取数据并发出数据流的方法。这个接口中的核心方法是run()和cancel(),其中run()方法用于读取数据并发出一系列事件,cancel()方法用于取消数据源的运行实现run()方法:可以定义从数据源读取数据的逻辑。这可以是从文件、数据库、消息队列等读取数据的逻辑。在适当的时候,使用collect()方法将读取的数据发出到数据流中实现cancel()方法:可以编写停止或清理数据源的逻辑。例如,如果数据源使用了外部资源,在这里释放这些资源注册数据源:将数据源注册到Flink的执行环境中,以便可以在作业中使用。通过执行环境的addSource()方法,向执行环境添加数据源
public class MySource implements SourceFunction<String> {private boolean isRunning = true;/*** run() 方法是核心方法,它会不断地读取、产生数据并将数据发送到下游* */@Overridepublic void run(SourceContext ctx) throws Exception {while (isRunning) {// 产生一些数据String data = UUID.randomUUID().toString();// 将数据发送到下游ctx.collect(data);// 每秒产生一条数据Thread.sleep(1000);}}/*** cancel() 方法用于在取消任务时清理资源*/@Overridepublic void cancel() {isRunning = false;}
}
将自定义的数据源传递给 env.addSource() 方法,并通过 .print() 将数据打印到控制台中。最后调用 env.execute() 方法来启动Flink程序。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 将自定义的数据源添加到 Flink 程序中DataStreamSource<String> streamSource = env.addSource(new MySource());streamSource.print();env.execute("MyApp");}
RichSourceFunction
如果需要更高级的功能和更丰富的生命周期控制,可以使用RichSourceFunction 类。RichSourceFunction是
SourceFunction接口的子类,它提供了额外的方法和功能,例如初始化、配置和资源管理。
操作步骤:
扩展RichSourceFunction 类:创建一个类,扩展 RichSourceFunction<T> 类,并将 T 替换为要发出的数据类型实现open() 方法:进行初始化操作,例如建立与外部系统的连接或加载资源等。这个方法是在数据源的生命周期开始时被调用的实现run() 方法:实现读取数据并发出数据流的逻辑。这个方法在启动数据源时会被调用实现cancel() 方法:添加取消数据源的逻辑。这个方法将在停止数据源时调用实现close() 方法:进行一些资源清理操作。这个方法是在数据源生命周期结束时调用的
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;public class CustomRichDataSource extends RichSourceFunction<String> {private volatile boolean isRunning = true;@Overridepublic void open(Configuration parameters) throws Exception {// 初始化操作,例如建立与外部系统的连接或加载资源等}@Overridepublic void run(SourceContext<String> ctx) throws Exception {while (isRunning) {// 读取数据的逻辑// 发出数据到数据流ctx.collect("Hello, World!");// 控制发送数据的速度Thread.sleep(1000);}}@Overridepublic void cancel() {isRunning = false;}@Overridepublic void close() throws Exception {// 资源清理操作}
}
常见连接器
第三方系统连接器
Flink内置了多种连接器,用于满足大多数的数据收集场景。连接器可以和多种多样的第三方系统进行交互。
Flink官方目前支持以下第三方系统连接器
Apache Kafka (source/sink)
Apache Cassandra (sink)
Amazon DynamoDB (sink)
Amazon Kinesis Data Streams (source/sink)
Amazon Kinesis Data Firehose (sink)
DataGen (source)
Elasticsearch (sink)
Opensearch (sink)
FileSystem (sink)
RabbitMQ (source/sink)
Google PubSub (source/sink)
Hybrid Source (source)
Apache Pulsar (source)
JDBC (sink)
MongoDB (source/sink)
除Flink官方之外,还有一些其他第三方系统与Flink的连接器,通过Apache Bahir发布:
Apache ActiveMQ (source/sink)
Apache Flume (sink)
Redis (sink)
Akka (sink)
Netty (source)
File Source连接器
从文件读取数据是一种常见方式,比如读取日志文件,这是批处理中最常见的读取方式
flink-connector-files是Apache Flink的一个连接器,用于将本地文件系统或远程文件系统中的文件作为数据源或数据接收器使用。
它提供了一种简单的方法来处理文本文件或其他格式的文件,例如CSV、JSON、Avro等,并将其转换为Flink数据流。在使用时,可以指定文件的路径、编码方式和分隔符等参数,并使用适当的转换函数将文件内容解析为Flink的数据类型,然后进行数据处理和分析。
它支持对输出流的写入操作,将Flink数据流中的结果写入到指定的文件中。可以通过配置文件路径、编码方式和文件格式等参数来控制输出文件的格式和内容
添加文件连接器依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>1.17.0</version><scope>provided</scope></dependency>
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);/*** 从文件流中逐条记录读取** 文件路径参数可以是目录,具体文件、以及从HDFS目录下读取* 路径可以是相对路径,也可以是绝对路径;* 相对路径是从系统属性`user.dir`获取路径:idea下是`project的根目录`,standalone模式下是`集群节点根目录`*/FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("data/word.txt")).build();/*** source ——用户定义的来源* sourceName – 数据源的名称*/env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "file-source").print();env.execute();}
DataGen Source连接器
Flink提供了一个内置的DataGen连接器,主要用于生成一些随机数,进行流任务的测试以及性能测试
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-datagen</artifactId><version>1.17.0</version>
</dependency>
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 如果有n个并行度, 最大值设为a// 将数值 均分成 n份, a/n ,比如,最大100,并行度2,每个并行度生成50个// 其中一个是 0-49,另一个50-99/*** DataGeneratorSource中,单个并行度生成数据个数与 与 生成的数据个数 相关* 公式: 生成的数据个数 / 并行度 = 每个并行度生成个数* 例子: 并行度设置为2,生成数据个数100,则每个并行度生成个数=100/2. 一个并行度:0-49 另一个并行度:50-99*/env.setParallelism(2);/*** 数据生成器Source* GeneratorFunction<Long, OUT> generatorFunction : GeneratorFunction接口函数需要实现, 重写map方法, 输入类型固定是Long* long count : 生成的数据个数。自动生成的数字序列,从0自增。当数字数序列最大值达到或小于这个值就停止* RateLimiterStrategy rateLimiterStrategy :限速策略,如每秒生成几条数据* TypeInformation<OUT> typeInfo : 返回的数据类型**/DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:" + value;}},100,RateLimiterStrategy.perSecond(1),Types.STRING);env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator").print();env.execute();}
1> Number:0
2> Number:50
2> Number:51
1> Number:1
2> Number:52
1> Number:2
2> Number:53
Kafka Source连接器
Flink-connector-kafka就是Flink的一个连接器,它提供了一个简单的方法来将Kafka作为Flink应用程序的数据源或数据接收器使用。
flink-connector-kafka可以帮助Flink应用程序从Kafka主题中读取数据,也可以将Flink的数据流写入到Kafka主题中。在使用时,可以指定Kafka集群的地址、主题名称、消费者组名称等参数,并使用适当的序列化和反序列化工具将数据转换为Flink的数据类型。
Topic、Partition订阅
Kafka Source提供了3 种Topic、Partition的订阅方式:
1.Topic 列表,订阅 Topic 列表中所有Partition的消息:
KafkaSource.builder().setTopics("topic-a", "topic-b");
2.正则表达式匹配,订阅与正则表达式所匹配的Topic下的所有Partition:
KafkaSource.builder().setTopicPattern("topic.*");
3.Partition列表,订阅指定的 Partition:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic-a", 0), // 主题为 "topic-a"的0号分区new TopicPartition("topic-b", 5))); // 主题为 "topic-b"的5号分区
KafkaSource.builder().setPartitions(partitionSet);
起始消费位点
Kafka source 能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费 。
如果内置的初始化器不能满足需求,也可以实现自定义的位点初始化器OffsetsInitializer
如果未指定位点初始化器,将默认使用 OffsetsInitializer.earliest()
内置的位点初始化器包括:
KafkaSource.builder()// 从消费组提交的位点开始消费,不指定位点重置策略.setStartingOffsets(OffsetsInitializer.committedOffsets())// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))// 从最早位点开始消费.setStartingOffsets(OffsetsInitializer.earliest())// 从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest());
动态分区检查
为了在不重启Flink作业的情况下处理Topic扩容或新建Topic等场景,可以将KafkaSource配置为在提供的Topic/Partition订阅模式下定期检查新分区。分区检查功能默认不开启。
KafkaSource.builder().setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
事件时间和水印
默认情况下,Kafka Source使用Kafka消息中的时间戳作为事件时间。可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");
示例
引入Kafka连接器依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.0</version></dependency>
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);KafkaSource<String> kafkaSource = KafkaSource.<String>builder()// 指定kafka节点的地址和端口.setBootstrapServers("node01:9092,node02:9092,node03:9092")// 指定消费者组的id.setGroupId("flink_group")// 指定消费的 Topic.setTopics("flink_topic")// 指定反序列化器,反序列化value.setValueOnlyDeserializer(new SimpleStringSchema())// flink消费kafka的策略.setStartingOffsets(OffsetsInitializer.latest()).build();// 不使用 watermark 的策略,意味着数据流不会根据事件时间进行处理DataStreamSource<String> stream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_source");stream.print("Kafka");// 定义事件时间watermark策略,处理数据流中的无序事件,并设置最大延迟时间为3秒。DataStreamSink<String> kafka_source = env.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafka_source").print("Kafka");env.execute();}
RabbitMQ Source连接器
添加对RabbitMQ连接器的依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-rabbitmq</artifactId><version>3.0.1-1.17</version>
</dependency>
1.服务质量 (QoS)
服务质量是一种用于控制数据源连接器如何消费消息的策略。在Flink中,服务质量定义了消费者和消息代理之间的消息传输保证级别。通过合适的服务质量设置,可以实现以下不同的语义保证:
Exactly-once:确保消息仅被正确处理一次At-least-once:确保消息至少被正确处理一次None(最多一次):不提供消息处理保证,可能会出现重复处理或丢失消息的情况
1.精确一次:
保证精确一次需要以下条件
开启checkpointing: 开启之后,消息在checkpoints完成之后才会被确认,然后从RabbitMQ队列中删除使用关联标识Correlationids: 关联标识是RabbitMQ的一个特性,消息写入RabbitMQ时在消息属性中设置。从checkpoint恢复时有些消息可能会被重复处理,source可以利用关联标识对消息进行去重。非并发source: 为了保证精确一次的数据投递,source必须是非并发的(并行度设置为1)。这主要是由于RabbitMQ分发数据时是从单队列向多个消费者投递消息的。
2.至少一次:
在checkpointing开启的条件下,如果没有使用关联标识或者source是并发的,那么source就只能提供至少一次的保证。
3.无任何保证:
如果没有开启checkpointing,source就不能提供任何的数据投递保证。使用这种设置时,source一旦接收到并处理消息,消息就会被自动确认。
2.消费者预取Consumer Prefetch
注意:
默认情况下是不设置prefetch count的,这意味着RabbitMQ服务器将会无限制地向source发送消息。因此在生产环境中,最好要设置它。
prefetch count是对单个channel设置的,并且由于每个并发的source都持有一个connection/channel,因此这个值实际上会乘以 source 的并行度,来表示同一时间可以向这个job总共发送多少条未确认的消息。
使用
setPrefetchCount()方法用于设置消费者预取值,这里将其设置为 10。这意味着每个消费者在处理完 10 条消息之前不会从 RabbitMQ 队列中获取更多的消息。
RMQConnectionConfig connectionConfig = new RMQConnectionConfig.Builder().setPrefetchCount(10) //设置消费者预取值为 10....build();
以下是保证exactly-once的RabbitMQ source示例
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 启用检查点(checkpointing)以实现精确一次或至少一次的一致性保证env.enableCheckpointing(5000); // 每 5000 毫秒执行一次检查点final RMQConnectionConfig connectionConfig = new RMQConnectionConfig.Builder().setHost("localhost") // RabbitMQ 主机名.setPort(5672) // RabbitMQ 端口号.setUserName("guest") // RabbitMQ 用户名.setPassword("guest") // RabbitMQ 密码.setVirtualHost("/") // RabbitMQ 虚拟主机.setPrefetchCount(10) // 设置消费者预取值为 10.build();final DataStream<String> stream = env.addSource(new RMQSource<String>(connectionConfig, // RabbitMQ 连接配置"queueName", // 需要消费的 RabbitMQ 队列名true, // 是否使用关联 ID;如果仅需要至少一次的保证,可以设置为 falsenew SimpleStringSchema())) // 反序列化方案,将消息转换为 Java 对象.setParallelism(1); // 非并行的源,仅在需要精确一次性保证时才需要设置stream.print();env.execute("RabbitMQ Source Example");}
MongoDB Source连接器
Flink 提供了MongoDB 连接器使用至少一次(At-least-once)的语义在 MongoDB collection中读取和写入数据。
要使用此连接器,先添加依赖到项目中:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-mongodb</artifactId><version>1.0.1-1.17</version>
</dependency>
public static void main(String[] args) throws Exception {MongoSource<String> source = MongoSource.<String>builder()// MongoDB 连接 URI.setUri("mongodb://user:password@127.0.0.1:27017")// 数据库名.setDatabase("my_db")// 集合名.setCollection("my_coll")// 投影的字段.setProjectedFields("_id", "f0", "f1")// 默认值: 2048 设置每次循环读取时应该从游标中获取的行数.setFetchSize(2048)// 默认值:-1 限制每个reader最多读取文档的数量。如果设置了读取并行度大于1,那么最多读取的文档数量等于 并行度 * 限制数量。.setLimit(10000)// 默认值: true 不使用游标超时 防止cursor因为读取时间过长或者背压导致的空闲而关闭.setNoCursorTimeout(true)/*** 使用分区可以利用并行读取来加速整体的读取效率。** 设置分区策略,可选的分区策略有 SINGLE,SAMPLE,SPLIT_VECTOR,SHARDED 和 DEFAULT** SINGLE:将整个集合作为一个分区。* SAMPLE:通过随机采样的方式来生成分区,快速但可能不均匀。* SPLIT_VECTOR:通过 MongoDB 计算分片的 splitVector 命令来生成分区,快速且均匀。 仅适用于未分片集合,需要 splitVector 权限。* SHARDED:从 config.chunks 集合中直接读取分片集合的分片边界作为分区,不需要额外计算,快速且均匀。 仅适用于已经分片的集合,需要 config 数据库的读取权限。* DEFAULT:对分片集合使用 SHARDED 策略,对未分片集合使用 SPLIT_VECTOR 策略。*/.setPartitionStrategy(PartitionStrategy.SAMPLE) // 设置每个分区的内存大小,默认值:64mb 通过指定的分区大小,将 MongoDB 的一个集合切分成多个分区。 可以设置并行度,并行地读取这些分区,以提升整体的读取速度。.setPartitionSize(MemorySize.ofMebiBytes(64))// 默认值:10 仅用于 SAMPLE 抽样分区策略,设置每个分区的样本数量。抽样分区器根据分区键对集合进行随机采样的方式计算分区边界。 总的样本数量 = 每个分区的样本数量 * (文档总数 / 每个分区的文档数量).setSamplesPerPartition(10)// 设置 MongoDeserializationSchema 用于解析 MongoDB BSON 类型的文档.setDeserializationSchema(new MongoDeserializationSchema<String>() {@Overridepublic String deserialize(BsonDocument document) {return document.toJson();}@Overridepublic TypeInformation<String> getProducedType() {return BasicTypeInfo.STRING_TYPE_INFO;}}) // 自定义的反序列化方案.build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.fromSource(source, WatermarkStrategy.noWatermarks(), "MongoDB-Source").setParallelism(2) // 设置并行度为 2.print().setParallelism(1); // 设置并行度为 1env.execute("MongoDB Source Example");}
相关文章:

Flink之源算子Data Source
源算子Data Source 概述内置Data Source基于集合构建基于文件构建基于Socket构建 自定义Data SourceSourceFunctionRichSourceFunction 常见连接器第三方系统连接器File Source连接器DataGen Source连接器Kafka Source连接器RabbitMQ Source连接器MongoDB Source连接器 概述 Fl…...
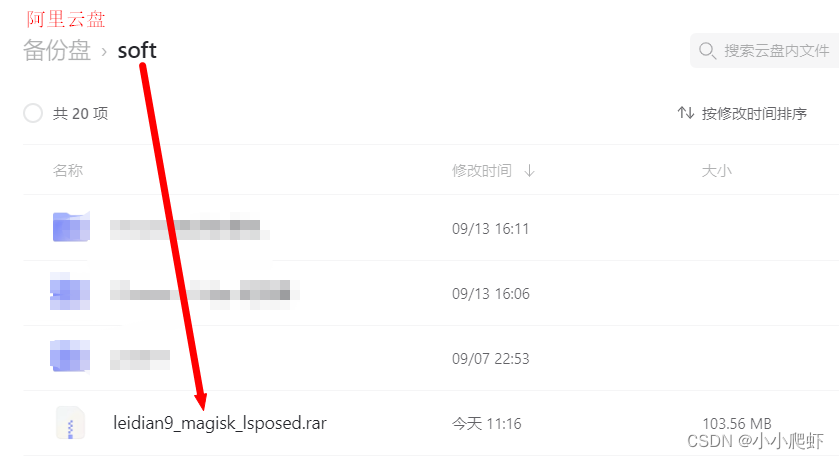
在雷电模拟器9上安装magisk并安装LSPosed模块以及其Manager管理器(一)
环境:win10 64,雷电模拟器9.0.60(9),Android 9。 之前我都是用雷电模拟器版本4.0.78,Android版本7.1.2,为什么本篇要使用9了呢?先解答下这个问题。原因如下:经过我的测试,LSPosed不支…...
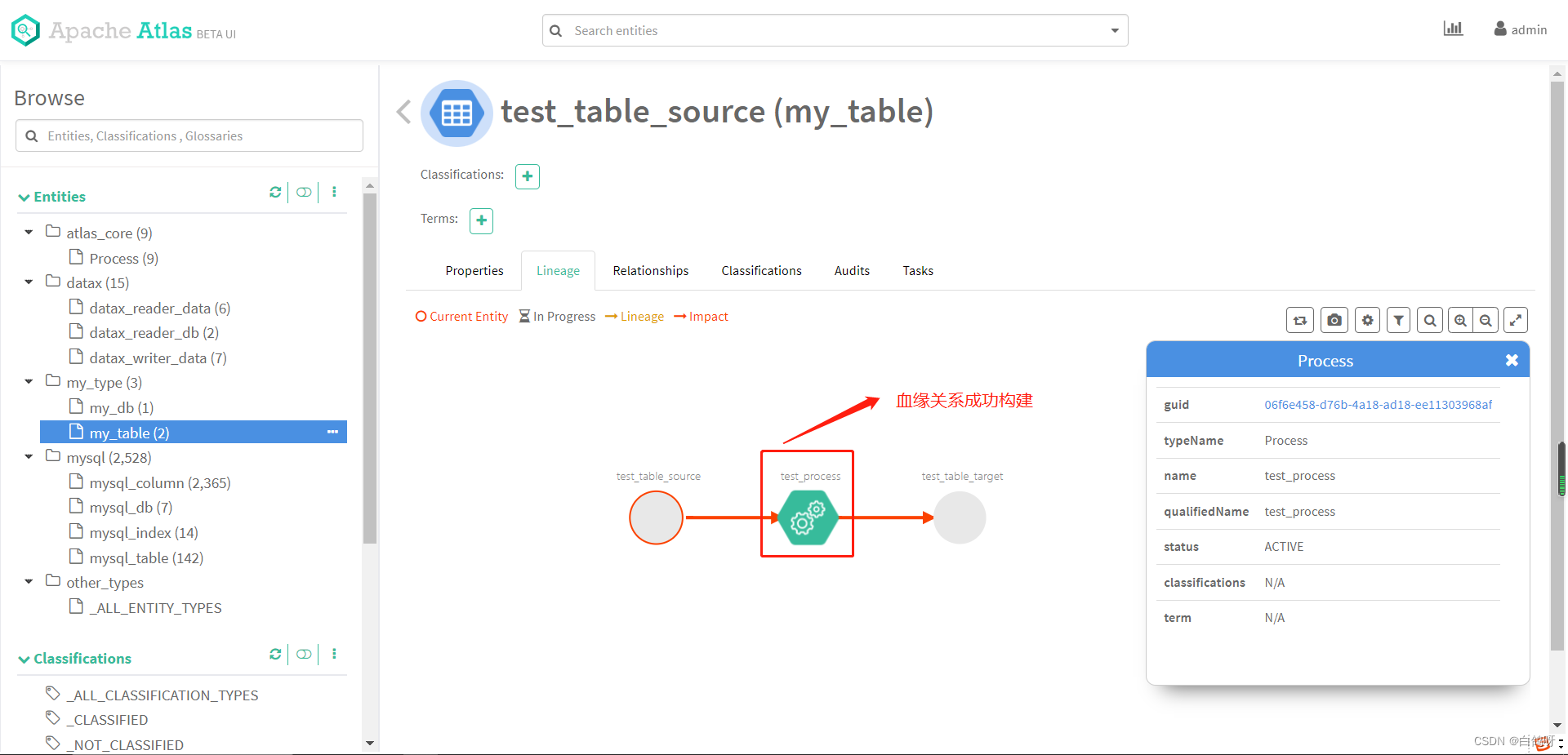
Apache atlas 元数据管理治理平台使用和架构
1、前言 Apache Atlas 是托管于 Apache 旗下的一款元数据管理和治理的产品,目前在大数据领域应用颇为广泛,可以很好的帮助企业管理数据资产,并对这些资产进行分类和治理,为数据分析,数据治理提供高质量的元数据信息。…...

MFF论文笔记
论文名称:Improving Pixel-based MIM by Reducing Wasted Modeling Capability_发表时间:ICCV2023 作者及组织:上海人工智能实验室,西门菲沙大学,香港中文大学 问题与贡献 MIM(Model Maksed Model)方法可以分为两部分…...

Leetcode 02.07 链表相交(链表)
Leetcode 02.07 链表相交(链表) 解法1 尾部对齐解法2:太厉害了,数学归纳推导的方法 很巧妙,这就是将链表的尾端对齐后再一起遍历,这样能满足题目的要求。因为相交之后两个链表到结束的所有节点都一样了&…...

Bootstrap的媒体对象组件(图文展示组件),挺有用的一个组件。
Bootstrap的.media类是用于创建媒体对象的,媒体对象通常用于展示图像(图片)和文本内容的组合,这种布局在展示新闻文章、博客帖子等方面非常常见。.media类使得创建这样的媒体对象非常简单,通常包含一个图像和相关的文本…...
Day2力扣打卡
打卡记录 无限数组的最短子数组(滑动窗口) 链接 思路:先求单个数组的总和,再对两个重复数组所组成的新数组上使用 不定长的滑动窗口 来求得满足目标的最小长度。 class Solution { public:int minSizeSubarray(vector<int>…...
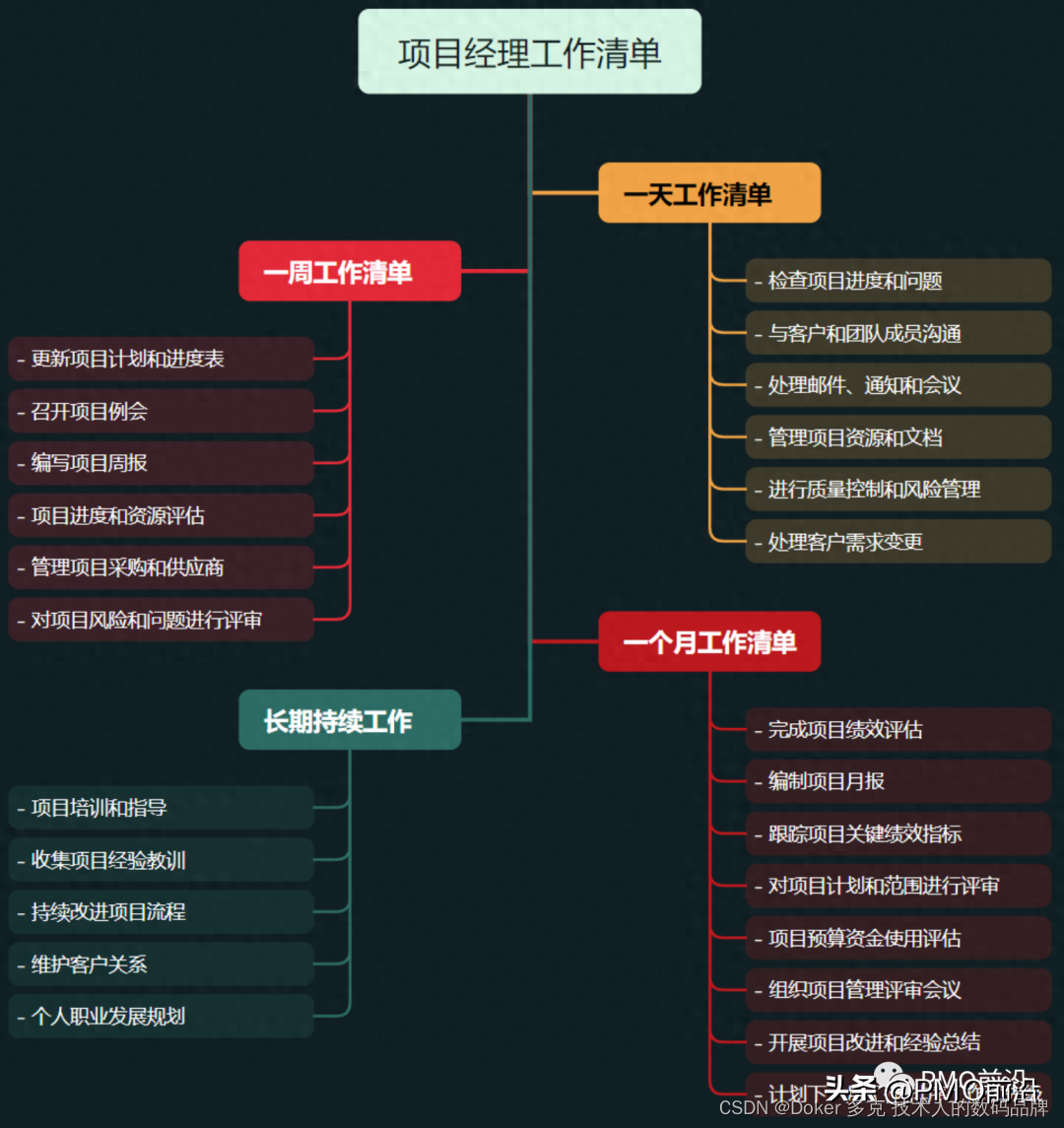
项目经理每天,每周,每月的工作清单
很多不懂项目管理的伙伴问,项目经理每天每周每个月的工作是什么呢? 仿佛他们什么都管,但是又没有具体的产出,但是每天看他们比谁都忙,其实很简单,项目中的每个环节负责具体的事情,但是每个环节…...
Java —— 运算符
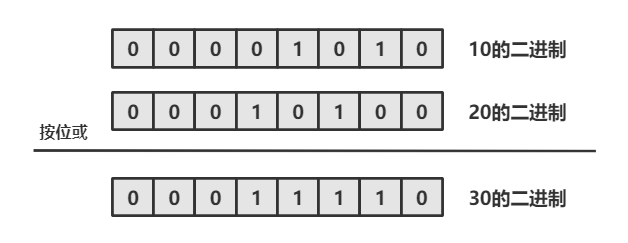
目录 1. 什么是运算符 2. 算术运算符 2.1 基本四则运算符: 加减乘除模( - * / %) 2.2 增量运算符 - * %与 自增/自减运算符 -- 3. 关系运算符 4. 逻辑运算符 4.1 逻辑与 && 4.2 逻辑或|| 4.3 逻辑非 ! 4.4 短路求值 5. 位运算符 5.1 按位与 & 5.2 按位或 5.3 按位…...

【C++ 中的友元函数:解密其神秘面纱】
友元函数,作为C中一个重要但常常被误解的概念,经常让初学者感到困惑。本文将带您逐步了解友元函数的含义、用途以及如何正确使用它们。 什么是友元函数? 在C中,友元函数是一种特殊的函数,它允许某个类或类的成员函数…...
YOLOv8涨点技巧:手把手教程,注意力机制如何在不同数据集上实现涨点的工作,内涵多种网络改进方法
💡💡💡本文独家改进:手把手教程,解决注意力机制引入到YOLOv8在自己数据集不涨点的问题点,本文提供五种改进方法来解决此问题; ContextAggregation | 亲测在血细胞检测项目中涨点,…...

牛客:FZ12 牛牛的顺时针遍历
FZ12 牛牛的顺时针遍历 文章目录 FZ12 牛牛的顺时针遍历题目描述题解思路题解代码 题目描述 题解思路 通过一个变量来记录当前方向,遍历矩阵,每次遍历一条边,将该边的信息加入到结果中 题解代码 func spiralOrder(matrix [][]int) []int {…...
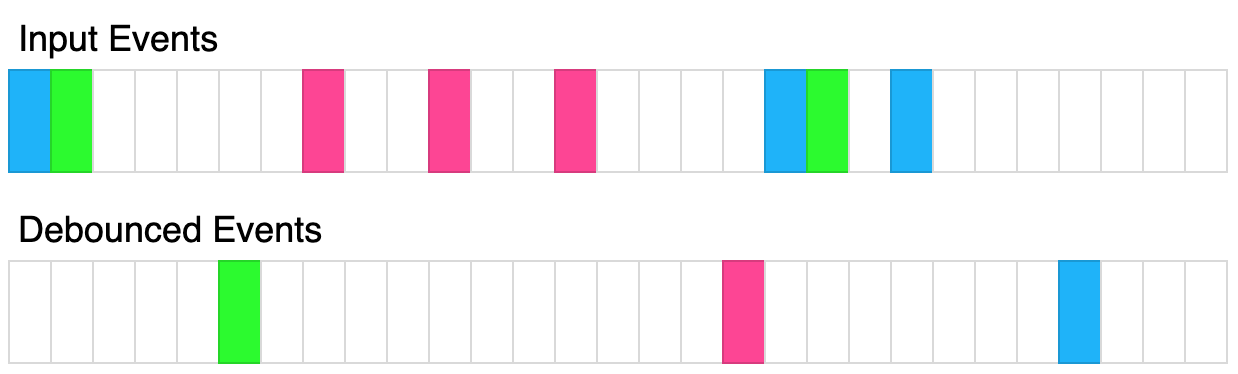
函数防抖(javaScript)
防抖说明 (1)防抖的目的: 当多次执行某一个动作的时候,限制函数调用的次数,节约资源。 (2)防抖的概念: 函数防抖(debounce):就是指触发事件后&…...
日常学习记录随笔-redis实战
redis的持久化(rdb,aof,混合持久化) redis的主从架构以及redis的哨兵架构 redis的clusterredis 是要做持久化的,一般用redis会把数据放到缓存中为了提升系统的性能 如果redis没有持久化,重启的化数据就会丢失,所有的请…...
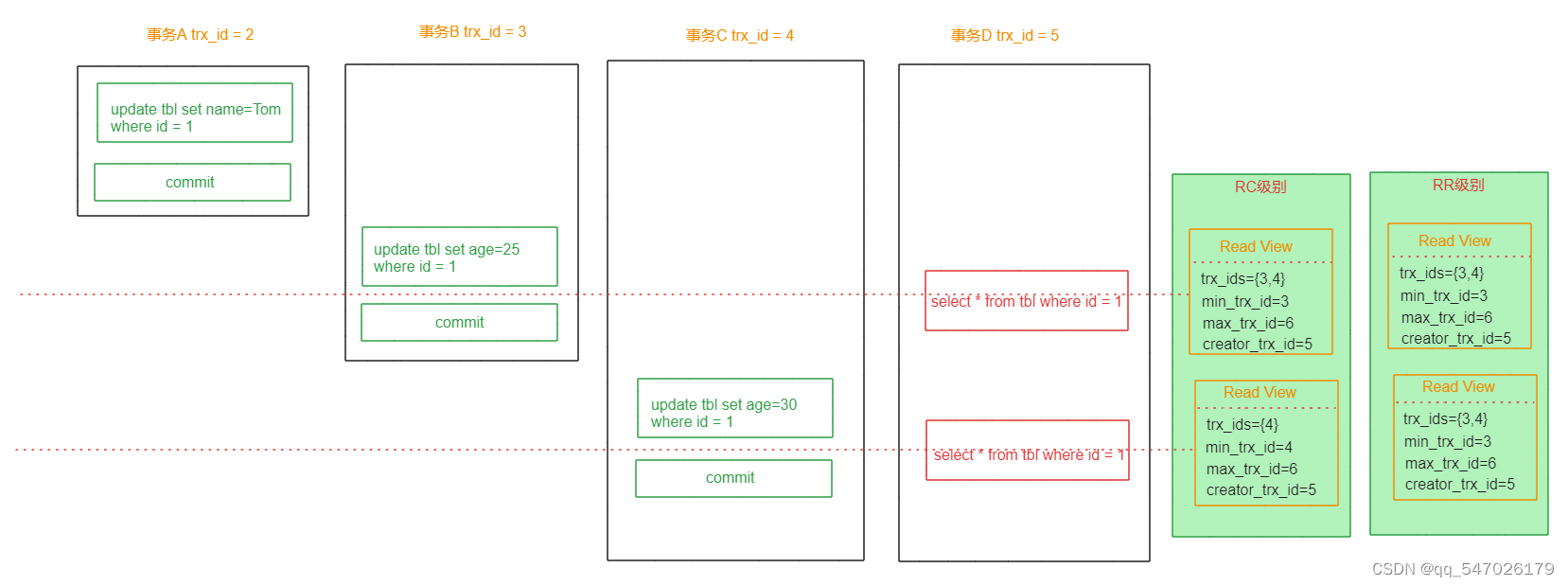
MySQL事务MVCC详解
一、概述 MVCC (MultiVersion Concurrency Control) 叫做多版本并发控制机制。主要是通过数据多版本来实现读-写分离,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读,从而提高数据库并发性能。 MVCC只在已提交读(…...

SQL RDBMS 概念
SQL RDBMS 概念 RDBMS是关系数据库管理系统(Relational Database Management System)的缩写。 RDBMS是SQL的基础,也是所有现代数据库系统(如MS SQL Server、IBMDB2、Oracle、MySQL和MicrosoftAccess)的基础。 关系数据库管理系统(Relational Database Management Sy…...
onlyoffice的介绍搭建、集成过程。Windows、Linux
文章目录 什么是onlyoffice功能系统要求安装必备组件 windows搭建资源下载安装数据库onlyoffice安装测试 Linux搭建dockerdocker-compose 项目中用到的技术,做个笔记哈~ 什么是onlyoffice 在本地服务器上安装ONLYOFFICE Docs Community Edition Community Edition…...

37. 解数独
编写一个程序,通过填充空格来解决数独问题。 数独的解法需 遵循如下规则: 数字 1-9 在每一行只能出现一次。数字 1-9 在每一列只能出现一次。数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图) 数独部分空…...
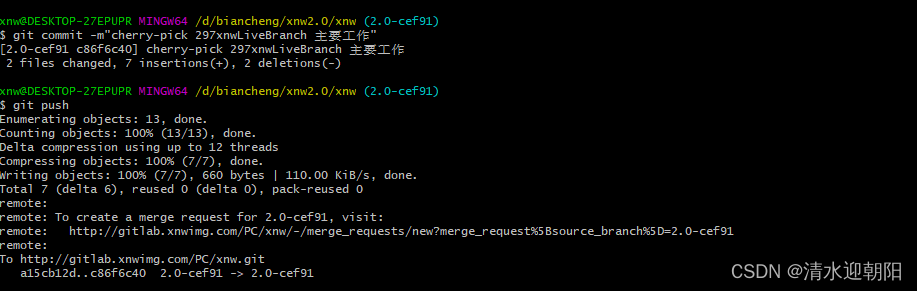
git cherry-pick 合并某次提交
一、无冲突的情况 1、合并其它分支某次提交 切换到主分支,想把其他分支的某次commit修改 合并到主分支上, 可以用 git cherry-pick 命令 比如,其它分支,某次提交的commit Hash 是30e48158badc39801f1ce3cb375a07b872d6f220 &a…...

【面试HOT100】子串普通数组矩阵
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于LeetCodeHot100进行的,每个知识点的修正和深入主要参考…...

告别本科论文 “从零焦虑”:okbiye AI 写作如何用 “全流程定制” 终结熬夜改稿循环
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 本科论文写到崩溃,是每个毕业生都懂的痛。 我见过凌晨三点的宿舍走廊,有人对着 Word 文档掉眼泪;也见过…...

别再只删node_modules了!npm run serve报错‘There is likely additional logging output above’的完整排查与修复手册
从日志溯源到根治:npm run serve报错的系统性排查指南 当你满怀期待地敲下npm run serve,却迎面撞上那句"There is likely additional logging output above"时,是否感到一阵无力?删除node_modules重装就像重启电脑——…...

5个简单步骤:用YimMenu在GTA V中打造安全游戏体验
5个简单步骤:用YimMenu在GTA V中打造安全游戏体验 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

3步解锁QQ音乐格式限制:qmcflac2mp3让你的音乐随处可听
3步解锁QQ音乐格式限制:qmcflac2mp3让你的音乐随处可听 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经遇到过这样的烦恼:从…...

5分钟极速上手:通达信缠论插件ChanlunX让技术分析智能化
5分钟极速上手:通达信缠论插件ChanlunX让技术分析智能化 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为复杂的缠论分析而头疼吗?面对K线图中的顶底分型、笔段划分、中枢识别…...

如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南
如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp Vant Weapp是一款轻量、可靠的小程序UI组件库,专为微信小程序开…...

Multiverse 引擎3.0:大屏、移动、AR三端覆盖,AR交互功能详解
在Multiverse 3.0版本中,我们首次实现了移动端、大屏端与AR端的全覆盖。基于“一模双擎”架构,用户在Web端可视化编辑器(支持“拖、拉、拽”搭建场景)中创建的数字孪生场景,可在像素流中直接加载,自动适配到…...

【Midjourney双色调风格终极指南】:20年视觉算法专家亲授3步精准复刻电影级Duotone效果
更多请点击: https://kaifayun.com 第一章:双色调美学的视觉起源与Midjourney适配性解析 双色调(Duotone)并非现代数字设计的发明,其视觉基因可追溯至19世纪的凹版印刷工艺——通过两块独立印版叠加单色油墨…...

从零实现一个电商图片下载器:技术方案与核心代码
引言如果你想自己开发一款电商图片下载工具,本文提供完整的技术方案和核心代码参考。一、技术选型组件推荐方案备选方案浏览器内核CEFElectron下载库libcurlrequests界面框架QtElectron跨平台CEF QtElectron二、核心代码实现2.1 浏览器初始化cppCefRefPtr<CefBr…...

3分钟搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG完整指南
3分钟搞定M3U8视频下载:N_m3u8DL-CLI-SimpleG完整指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 还在为无法下载在线视频而烦恼吗?想保存喜欢的教学视…...