Hive用户中文使用手册系列(二)
命令和 CLI
语言手册命令
命令是 non-SQL statements,例如设置 property 或添加资源。它们可以在 HiveQL 脚本中使用,也可以直接在CLI或Beeline中使用。
| 命令 | 描述 |
|---|---|
| 退出 | 使用 quit 或 exit 退出交互式 shell。 |
| 重启 | 将 configuration 重置为默认值(从 Hive 0.10 开始:请参阅HIVE-3202)。使用 hive 命令行中的 set 命令或-hiveconf 参数设置的任何 configuration 参数都将重置为默认值 value。请注意,这不适用于使用 key name 的“hiveconf:”前缀在 set 命令中设置的 configuration 参数(出于历史原因)。 |
| 设置<‘key‘> = <‘value‘> | 设置特定 configuration 变量(key)的 value。 |
| 组 | 打印由用户或 Hive 覆盖的 configuration 变量列表。 |
| 设置-v | 打印所有 Hadoop 和 Hive configuration 变量。 |
Sample 用法:
hive> set mapred.reduce.tasks=32;hive> set;hive> select a.* from tab1;hive> !ls;hive> dfs -ls;
Hive CLI
$HIVE_HOME/bin/hive 是一个 shell 实用程序,可用于以交互方式或批处理方式 run Hive 查询。
有利于 Beeline CLI 的弃用
HiveServer2(在 Hive 0.11 中引入)有自己的名为Beeline的 CLI,它是一个基于 SQLLine 的 JDBC client。由于新开发的重点是 HiveServer2,Hive CLI 很快就会被弃用支持 Beeline(HIVE-10511)。
请参阅 HiveServer2 文档中的使用 Beeline 替换 Hive CLI 的 Implementation和Beeline - 新命令 Line Shell。
Hive 命令 Line 选项
要获得帮助,请 run“hive -H”或“hive --help”。
用法(在 Hive 0.9.0 中):
usage: hive-d,--define <key=value> Variable substitution to apply to Hivecommands. e.g. -d A=B or --define A=B-e <quoted-query-string> SQL from command line-f <filename> SQL from files-H,--help Print help information-h <hostname> Connecting to Hive Server on remote host--hiveconf <property=value> Use value for given property--hivevar <key=value> Variable substitution to apply to hivecommands. e.g. --hivevar A=B-i <filename> Initialization SQL file-p <port> Connecting to Hive Server on port number-S,--silent Silent mode in interactive shell-v,--verbose Verbose mode (echo executed SQL to theconsole)
版本信息
从 Hive 0.10.0 开始,还有一个额外的命令 line 选项:
--database <dbname> Specify the database to use
注意:支持变体“-hiveconf”以及“–hiveconf”。
例子
有关使用hiveconf选项的示例,请参阅可变替代。
- 从命令 line 运行查询的示例
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a'
- 设置 Hive configuration 变量的示例
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a' --hiveconf hive.exec.scratchdir=/home/my/hive_scratch --hiveconf mapred.reduce.tasks=32
- 使用静默模式将数据从查询转储到文件中的示例
$HIVE_HOME/bin/hive -S -e 'select a.col from tab1 a' > a.txt
- 从本地磁盘运行脚本 non-interactively 的示例
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
- 从 Hadoop 支持的文件系统中运行脚本 non-interactively 的示例(从Hive 0.14开始)
$HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql
$HIVE_HOME/bin/hive -f s3://mys3bucket/s3-script.sql
- 在进入交互模式之前 running 初始化脚本的示例
$HIVE_HOME/bin/hive -i /home/my/hive-init.sql
hiverc 文件
在没有-i选项的情况下调用 CLI 将尝试加载 H I V E H O M E / b i n / . h i v e r c 和 HIVE_HOME/bin/.hiverc 和 HIVEHOME/bin/.hiverc和HOME/.hiverc 作为初始化 files。
Logging
Hive 使用 log4j 进行 logging。默认情况下,这些日志不会发送到标准输出,而是捕获到 Hive 的 log4j properties 文件指定的 log 文件中。默认情况下,Hive 将在 Hive 安装的conf/目录中使用hive-log4j.default,该目录将日志写入/tmp//hive.log并使用WARN level。
通常需要将日志发送到标准输出 and/or 更改 logging level 以进行调试。这些可以通过命令 line 完成,如下所示:
$HIVE_HOME/bin/hive --hiveconf hive.root.logger=INFO,console
hive.root.logger指定 logging level 以及 log 目标。将console指定为目标会将日志发送到标准错误(而不是 log 文件)。
清除悬空划痕目录的工具
有关临时目录的信息,请参阅设置 HiveServer2 中的Scratch Directory Management,以及可以在 Hive CLI 和 HiveServer2 中使用的 command-line 用于删除悬空临时目录的工具。
Hive 批处理模式命令
当$HIVE_HOME/bin/hive与-e或-f选项一起运行时,它以批处理模式执行 SQL 命令。
- hive -e ''执行查询 string。
- hive -f 从文件执行一个或多个 SQL 查询。
Version 0.14
从 Hive 0.14 开始,可以来自 Hadoop 支持的文件系统之一(HDFS,S3,etc.))。
$HIVE_HOME/bin/hive -f hdfs://<namenode>:<port>/hive-script.sql $HIVE_HOME/bin/hive -f s3://mys3bucket/s3-script.sql
Hive Interactive Shell 命令
当$HIVE_HOME/bin/hive在没有-e或-f选项的情况下运行时,它将进入交互式 shell 模式。
使用 ”;” (分号)终止命令。可以使用“ - ”前缀指定脚本中的注释。
Sample 用法:
hive> set mapred.reduce.tasks=32;hive> set;hive> select a.* from tab1;hive> !ls;hive> dfs -ls;
Hive 资源
Hive 可以管理向 session 添加资源,其中这些资源需要在查询执行 time 时提供。资源可以是 files,jars 或 archives。可以将任何本地可访问的文件添加到 session。
将资源添加到 session 后,Hive 查询可以通过其 name(在 map/reduce/transform 子句中)引用它,并且资源在整个 Hadoop cluster 上的执行 time 时在本地可用。 Hive 使用 Hadoop 的分布式缓存在查询执行 time 时将添加的资源分发到 cluster 中的所有计算机。
用法:
ADD { FILE[S] | JAR[S] | ARCHIVE[S] } <filepath1> [<filepath2>]*LIST { FILE[S] | JAR[S] | ARCHIVE[S] } [<filepath1> <filepath2> ..]DELETE { FILE[S] | JAR[S] | ARCHIVE[S] } [<filepath1> <filepath2> ..]
- FILE 资源只是添加到分布式缓存中。通常,这可能类似于要执行的转换脚本。
- JAR 资源也被添加到 Java classpath 中。这在 reference objects 中是必需的,它们包含诸如 UDF 之类的对象。有关自定义 UDF 的更多信息,请参见Hive 插件。
- ARCHIVE 资源会自动取消归档,作为分发它们的一部分。
例:
hive> add FILE /tmp/tt.py;hive> list FILES;/tmp/tt.pyhive> select from networks a MAP a.networkid USING 'python tt.py' as nn where a.ds = '2009-01-04' limit 10;
Version 1.2.0
从Hive 1.2.0开始,可以使用 ivy://group:module:version 形式的常春藤 URL 添加和删除资源? querystring。
- group - 模块来自哪个模块 group。直接转换为 Maven groupId 或 Ivy Organization。
- module - 要加载的模块的 name。直接转换为 Maven artifactId 或 Ivy artifact。
- version - 要使用的模块的 version。可以使用任何 version 或*(最新)或 Ivy 范围。
可以在 querystring 中传递各种参数,以配置如何以及将哪些 jars 添加到工件中。参数采用 key value 对的形式,由’&'分隔。
用法:
ADD { FILE[S] | JAR[S] | ARCHIVE[S] } <ivy://org:module:version?key=value&key=value&...> <ivy://org:module:version?key=value&key1=value1&...>*
DELETE { FILE[S] | JAR[S] | ARCHIVE[S] } <ivy://org:module:version> <ivy://org:module:version>*
此外,我们可以在相同的 ADD 和 DELETE 命令中混合使用和。
ADD { FILE[S] | JAR[S] | ARCHIVE[S] } { <ivyurl> | <filepath> } <ivyurl>* <filepath>*
DELETE { FILE[S] | JAR[S] | ARCHIVE[S] } { <ivyurl> | <filepath> } <ivyurl>* <filepath>*
可以传递的不同参数是:
- exclude:以 org:module 形式使用逗号分隔的 value。
- transitive:取值 true 或 false。默认为 true。当 transitive = true 时,将下载所有传递依赖项并将其添加到 classpath。
- ext:要添加的文件的扩展名。 'jar’默认情况下。
- 分类器:要解析的 maven 分类器。
例子:
hive>ADD JAR ivy://org.apache.pig:pig:0.10.0?exclude=org.apache.hadoop:avro;
hive>ADD JAR ivy://org.apache.pig:pig:0.10.0?exclude=org.apache.hadoop:avro&transitive=false;
除非某些依赖项由其他资源共享,否则 DELETE 命令将删除资源及其所有传递依赖项。如果两个资源共享一组传递依赖项,并且使用 DELETE 语法删除其中一个资源,则除了共享的资源外,将删除资源的所有传递依赖项。
例子:
hive>ADD JAR ivy://org.apache.pig:pig:0.10.0
hive>ADD JAR ivy://org.apache.pig:pig:0.11.1.15
hive>DELETE JAR ivy://org.apache.pig:pig:0.10.0
如果 A 是包含 pig-0.10.0 的传递依赖性的集合,并且 B 是包含 pig-0.11.1.15 的传递依赖性的集合,则在执行上述命令之后,将删除 A-(A 交集 B)。
有关详细信息,请参阅HIVE-9664。
如果转换脚本中使用的 files 已经在 Hadoop cluster 中使用相同路径 name 的所有计算机上可用,则不必将 files 添加到 session。例如:
- … MAP a.networkid USING ‘wc -l’ …
这里wc是所有机器上都可用的可执行文件。 - … MAP a.networkid USING ‘/home/nfsserv1/hadoopscripts/tt.py’ …
这里tt.py可以通过在所有 cluster 节点上配置相同的 NFS 挂载点访问。
请注意,Hive configuration 参数还可以指定 jars,files 和 archives。有关更多信息,请参见Configuration 变量。
HCatalog CLI
HCatalog 随 Hive 一起安装,从 Hive release 0.11.0 开始。
许多(但不是全部)hcat命令可以作为hive命令发出,反之亦然。有关详细信息,请参阅HCatalog 手册中的 HCatalog 命令 Line 接口文档。
Beeline - 命令 Line Shell
此页面描述了HiveServer2支持的不同 clients。 HiveServer2 的其他文档包括:
- HiveServer2 概述
- 设置 HiveServer2
- Hive Configuration Properties:HiveServer2
版
在 Hive version 0.11 中引入。见HIVE-2935。
Beeline - 命令 Line Shell
HiveServer2 支持与 HiveServer2 一起使用的命令 shell Beeline。它是一个基于 SQLLine CLI(http://sqlline.sourceforge.net/)的 JDBC client。 SQLLine 的详细文件也适用于 Beeline。
使用 Beeline 替换 Hive CLI 的 Implementation
Beeline shell 既可以在嵌入模式下工作,也可以在 remote 模式下工作。在嵌入模式下,它运行嵌入式 Hive(类似于Hive CLI),而 remote 模式用于连接到 Thrift 上的单独 HiveServer2 process。从Hive 0.14开始,当 Beeline 与 HiveServer2 一起使用时,它还会从 HiveServer2 打印 log 消息,以查询它对 STDERR 执行的查询。 Remote HiveServer2 模式建议用于 production 使用,因为它更安全,不需要为用户授予直接的 HDFS/metastore 访问权限。
在 remote 模式下,HiveServer2 只接受有效的 Thrift calls - 即使在 HTTP 模式下,消息体也包含 Thrift 有效负载。
Beeline示例
% bin/beeline
Hive version 0.11.0-SNAPSHOT by Apache
beeline> !connect jdbc:hive2://localhost:10000 scott tiger
!connect jdbc:hive2://localhost:10000 scott tiger
Connecting to jdbc:hive2://localhost:10000
Connected to: Hive (version 0.10.0)
Driver: Hive (version 0.10.0-SNAPSHOT)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show tables;
show tables;
+-------------------+
| tab_name |
+-------------------+
| primitives |
| src |
| src1 |
| src_json |
| src_sequencefile |
| src_thrift |
| srcbucket |
| srcbucket2 |
| srcpart |
+-------------------+
9 rows selected (1.079 seconds)您还可以在命令 line 上指定连接参数。这意味着您可以从 UNIX shell 历史记录中找到带有连接 string 的命令。
% beeline -u jdbc:hive2://localhost:10000/default -n scott -w password_file
Hive version 0.11.0-SNAPSHOT by ApacheConnecting to jdbc:hive2://localhost:10000/defaultBeeline与 NoSASL 连接
如果您想通过 NOSASL 模式进行连接,则必须明确指定身份验证模式:
% bin/beeline beeline> !connectjdbc:hive2://<host>:<port>/<db>;auth=noSasl hiveuser pass
HiveServer2 Logging
从 Hive 0.14.0 开始,HiveServer2 操作日志可用于 Beeline clients。这些参数配置 logging:
- hive.server2.logging.operation.enabled
- hive.server2.logging.operation.log.location
- hive.server2.logging.operation.verbose(Hive 0.14 to 1.1)
- hive.server2.logging.operation.level(Hive 1.2 向前)
HIVE-11488(Hive 2.0.0)将 logging queryId 和 sessionId 的支持添加到 HiveServer2 log 文件中。要启用它,edit/add%X {。 435}和%X {。 436}到 logging configuration 文件的 pattern 格式 string。
取消查询
当用户在 Beeline shell 上输入CTRL+C时,如果有一个查询在同一 time 运行运行,则 Beeline 会在关闭与 HiveServer2 的 socket 连接时尝试取消查询。仅当hive.server2.close.session.on.disconnect设置为true时才会启用此行为。从 Hive 2.2.0(HIVE-15626)开始当用户输入CTRL+C时,当取消 running 查询时,Beeline 不会退出命令 line shell。如果用户希望退出 shell,则在取消查询时,可以在第二个 time 输入CTRL+C。但是,如果当前没有查询 running,则第一个CTRL+C将退出 Beeline shell。此行为类似于 Hive CLI 处理CTRL+C的方式。
!quit是退出 Beeline shell 的推荐命令。
终端脚本中的后台查询
可以使用 nohup 和 disown 等命令将 Beeline 与终端 run 断开连接以进行批处理和自动化脚本。
某些版本的 Beeline client 可能需要一种解决方法,允许 nohup 命令在不停止的情况下将 Beeline process 正确放入后台。见HIVE-11717,H IVE-6758。
可以更新以下环境变量:
export HADOOP_CLIENT_OPTS="$HADOOP_CLIENT_OPTS -Djline.terminal=jline.UnsupportedTerminal"
Running with nohangup(nohup)和&符号(&)将 process 放在后台并允许终端断开连接,同时保持 Beeline process running。
nohup beeline --silent=true --showHeader=true --outputformat=dsv -f query.hql </dev/null > /tmp/output.log 2> /tmp/error.log &
相关文章:
)
Hive用户中文使用手册系列(二)
命令和 CLI 语言手册命令 命令是 non-SQL statements,例如设置 property 或添加资源。它们可以在 HiveQL 脚本中使用,也可以直接在CLI或Beeline中使用。 命令描述退出使用 quit 或 exit 退出交互式 shell。重启将 configuration 重置为默认值(从 Hive…...
2023年中国清净剂行业需求现状及前景分析[图]
清净剂用于中和由于燃烧和润滑油氧化产生的酸性物质,并清除颗粒和污物。这类杂质在油中的溶解度有限,因此,清净剂可以最大程度减少沉积物的生成,降低污染,提高环保排放标准。成熟产品有磺酸盐、硫化烷基酚盐、烷基水杨…...

文心一言 VS 讯飞星火 VS chatgpt (115)-- 算法导论10.2 8题
八、用go语言,说明如何在每个元素仅使用一个指针 x.np(而不是通常的两个指针 next和prev)的下实现双向链表。假设所有指针的值都可视为 k 位的整型数,且定义x.npx.next XOR x.prev,即x.nert和x.prev 的 k 位异或。(NIL 的值用0表示。)注意要说…...

Redis的BitMap实现分布式布隆过滤器
布隆过滤器(Bloom Filter)是一种高效的概率型数据结构,用于判断一个元素是否属于一个集合。它通过使用哈希函数和位数组来存储和查询数据,具有较快的插入和查询速度,并且占用空间相对较少。 引入依赖 <!--切面--&…...

【linux API分析】module_init
linux版本:4.19 module_init()与module_exit()用于驱动的加载,分别是驱动的入口与退出函数 module_init():内核启动时或动态插入模块时调用module_exit():驱动移除时调用 本篇文章介绍module_init() module_init() module_init…...
NSDT孪生编辑器助力智慧城市
技术有能力改变城市的运作方式,提高效率,为游客和居民提供更好的体验,实现更可持续的运营和更好的决策。 当今城市面临的主要挑战是什么,成为智慧城市如何帮助克服这些挑战? 我们生活在一个日益城市化的世界…...

如何优雅的实现接口统一调用
耦合问题 有些时候我们在进行接口调用的时候,比如说一个push推送接口,有可能会涉及到不同渠道的推送,以我目前业务场景为例,我做结算后端服务的,会与金蝶财务系统进行交互,那么我结算后端会涉及到多个结算…...
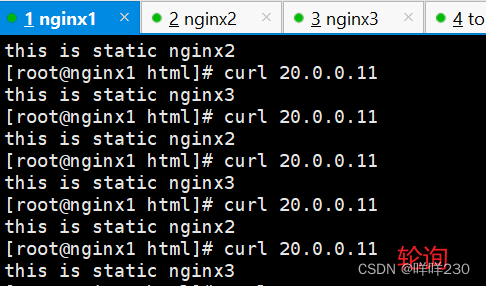
tomcat、nginx实现四层转发+七层代理+动静分离实验
实验环境: nginx1——20.0.0.11——客户端 静态页面: nginx2——20.0.0.21——代理服务器1 nginx3——20.0.0.31——代理服务器2 动态页面: tomcat1——20.0.0.12——后端服务器1 tomcat2——20.0.0.22——后端服务器2 实验步骤&…...
交通目标检测-行人车辆检测流量计数 - 计算机竞赛
文章目录 0 前言1\. 目标检测概况1.1 什么是目标检测?1.2 发展阶段 2\. 行人检测2.1 行人检测简介2.2 行人检测技术难点2.3 行人检测实现效果2.4 关键代码-训练过程 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 毕业设计…...

Java Excel转PDF,支持xlsx和xls两种格式, itextpdf【即取即用】
Java Excel转PDF itextpdf,即取即用 工具方法一、使用方式1、本地转换2、网络下载 二、pom依赖引入三、工具方法三、引文 本篇主要为工具方法整理,参考学习其他博主文章做了整理,方便使用。 工具方法 一、使用方式 1、本地转换 导入依赖创…...

重生奇迹mu宠物带来不一样的体验
重生奇迹mu宠物有什么作用? 全新版本中更是推出了各种宠物,在玩游戏时还可以带着宠物,一起疯狂的刷怪等等,可以为玩家带来非常不错的游戏体验,那么下面就来给大家说说各种宠物适合做什么事情。 1、强化恶魔适合刷怪 …...
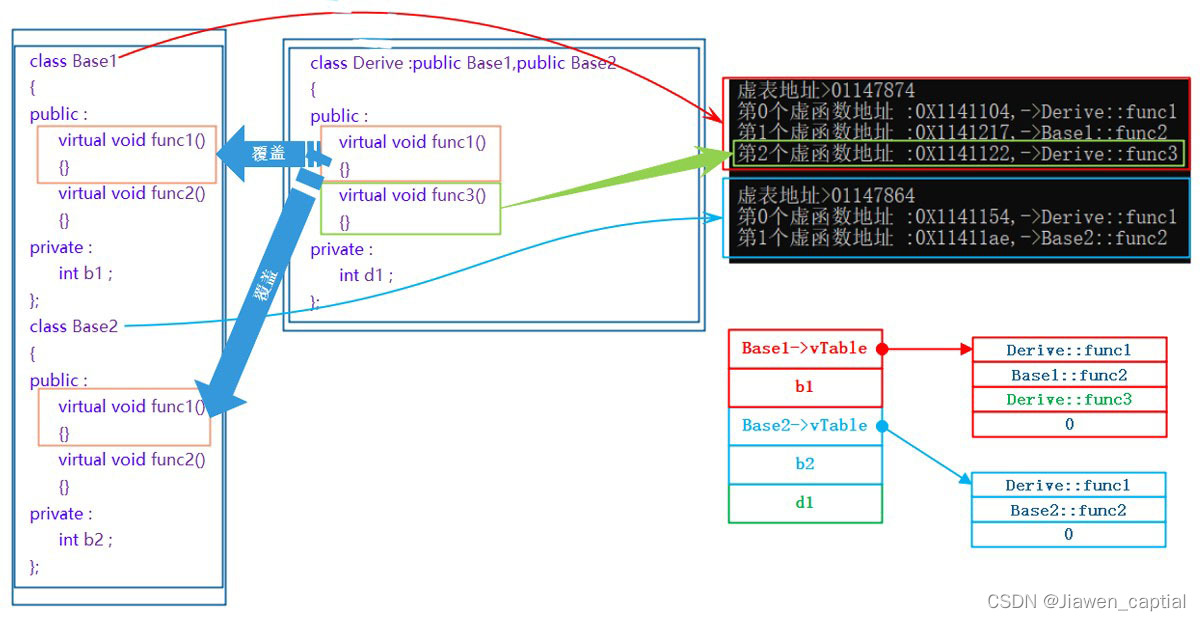
【C++笔记】多态的原理、单继承和多继承关系的虚函数表、 override 和 final、抽象类、重载、覆盖(重写)、隐藏(重定义)的对比
1.final关键字 引出:设计一个不能被继承的类。有如下方法: class A { private:A(int a0):_a(a){} public:static A CreateOBj(int a0){return A(a);} protected:int _a; } //简介限制,子类构成函数无法调用父类构造函数初始化 //子类的构造…...
安装thinkphp6并使用多应用模式,解决提示路由不存在解决办法
1. 安装稳定版tp框架 composer create-project topthink/think tptp是安装完成的目录名称 ,可以根据自己需要修改。 如果你之前已经安装过,那么切换到你的应用根目录下面,然后执行下面的命令进行更新: composer update topthin…...

FPGA笔试
1、FPGA结构一般分为三部分:可编程逻辑块(CLB)、可编程I/O模块和可编程内部连线。 2 CPLD的内部连线为连续式布线互连结构,任意一对输入、输出端之间的延时是固定 ;FPGA的内部连线为分段式布线互连结构,各…...

Pytorch:cat、stack、squeeze、unsqueeze的用法
Pytorch:cat、stack、squeeze、unsqueeze的用法 torch.cat 在指定原有维度上链接传入的张量,所有传入的张量都必须是相同形状 torch.cat(tensors, dim0, *, outNone) → Tensor tensor:相同形状的tensor dim:链接张量的维度,不能超过传入张…...

聊聊HttpClient的RedirectStrategy
序 本文主要研究一下HttpClient的RedirectStrategy RedirectStrategy org/apache/http/client/RedirectStrategy.java public interface RedirectStrategy {/*** Determines if a request should be redirected to a new location* given the response from the target ser…...

【1day】复现宏景OA KhFieldTree接口 SQL注入漏洞
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、资产测绘 三、漏洞复现 四、漏洞修复 一、漏洞描述 宏景OA是一款基于...

同为科技TOWE智能PDU引领数据中心机房远控用电安全高效
随着数据中心的环境变得更加动态和复杂,许多数据中心都在对数据中心管理人员施加压力,要求提高可用性,同时降低成本,提升效率。新一代高密度服务器和网络设备的投入使用,增加了对更高密度机架的需求,并对整…...

支付成功后给指定人员发送微信公众号消息
支付成功后给指定人员(导购)发送微信公众号消息 微信openid已录入数据库表 调用后台接口发送消息接口调用代码如下: //----add by grj 20231017 start //订单支付成功发送微信公众号消息$.ajax({url:http://www.menggu100.com:7077/strutsJsp…...
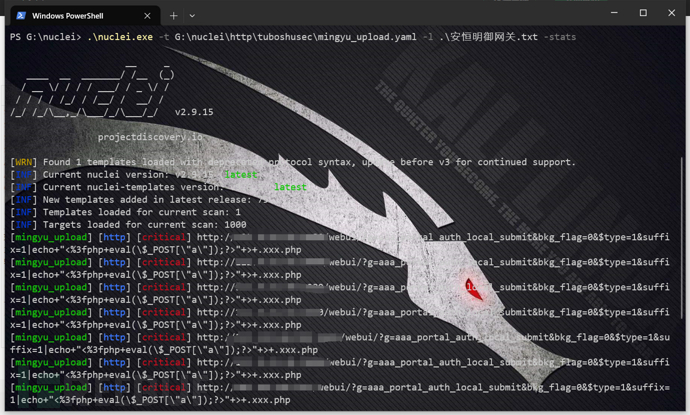
漏洞复现--安恒明御安全网关文件上传
免责声明: 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直…...

小米耳机音效进阶指南:解锁灰色定制音效与多模式协同优化
1. 小米耳机音效问题排查:为什么定制音效选项是灰色的? 最近不少小米耳机用户反馈,在连接Redmi K50 Ultra等机型时,发现定制音效选项显示为灰色无法开启。这个问题其实很常见,我自己用Xiaomi Buds 4 Pro时也遇到过。经…...
深度解析:如何让你的飞控代码轻松跑在不同芯片上?)
ArduPilot硬件抽象层(HAL)深度解析:如何让你的飞控代码轻松跑在不同芯片上?
ArduPilot硬件抽象层(HAL)深度解析:跨平台飞控开发实战指南 当开发者尝试将ArduPilot移植到一块全新的飞控板时,最常遇到的挑战莫过于如何让同一套控制算法在不同硬件架构上无缝运行。这正是硬件抽象层(HAL)设计的精妙之处——它如同一位技艺高超的翻译官…...

实战应用场景:Codex CLI在开发工作流中的最佳实践
实战应用场景:Codex CLI在开发工作流中的最佳实践 本文详细介绍了Codex CLI在现代化开发工作流中的四个关键应用场景:代码重构与组件现代化迁移、自动化测试生成与执行、安全漏洞扫描与代码审查、以及批量文件操作与Git集成。通过实际案例展示了如何利用…...

ARMv8.3指针认证技术原理与安全实践
1. AArch64指针认证技术深度解析指针认证(Pointer Authentication)是ARMv8.3-A引入的关键安全特性,通过在指针的高位比特中嵌入加密签名(Pointer Authentication Code, PAC)来验证指针的完整性。这项技术能有效防御ROP…...

告别复制粘贴!用Python+GoBot Pro 1.0,5分钟搞定Excel数据自动录入网页表单
告别复制粘贴!用PythonGoBot Pro 1.0,5分钟搞定Excel数据自动录入网页表单 在数据驱动的时代,重复性劳动正成为效率的最大杀手。每天面对成百上千条Excel数据需要手动录入网页表单的场景,从市场调研、活动报名到用户注册ÿ…...

2026届学术党必备的十大AI学术方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI工具运用越来越广泛,然而随之出现的信息过多无法承受以及决策变得复杂的状况&…...

NLP-Models-Tensorflow在情感分析中的应用:79种分类器的全面评估
NLP-Models-Tensorflow在情感分析中的应用:79种分类器的全面评估 【免费下载链接】NLP-Models-Tensorflow Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 < Tensorflow < 2.0 项目地址: https://gitcode.com/gh_mi…...

建模也有Skills了:MWORKS.Sysplorer Skills已开源至MoHub!
智能体能调用建模工具,并不等于它能稳定完成工程建模任务。在真实工程场景中,一个可交付的模型往往要经过需求理解、模型库选择、组件映射、参数补全、检查翻译、仿真验证、结果判读和交付归档。过去,这些环节高度依赖工程师经验;…...

UE材质背后的物理课:从菲涅尔到BRDF,理解PBR渲染的数学与视觉魔法
UE材质背后的物理课:从菲涅尔到BRDF,理解PBR渲染的数学与视觉魔法 当你在虚幻引擎中拖动粗糙度滑块时,是否思考过这个0到1的数值如何精确控制光线在虚拟表面的舞蹈?PBR渲染不是魔法,而是将自然界的光影规律翻译成计算机…...

Perplexity搜索响应延迟突增2100ms?内部API调用链路拆解,开发者必看避坑清单
更多请点击: https://codechina.net 第一章:Perplexity搜索响应延迟突增2100ms?现象复现与影响定性 近期监控系统捕获到Perplexity搜索API端点( /v1/search)在UTC时间2024-06-12T08:14:22Z起出现持续约17分钟的P99延迟…...