从头开始机器学习:线性回归

一、说明
- 代码/注释存储库链接
拉曼欣德
GitHub - ramanthind02/Machine_learning_from_scratch_Linear_Regression
二、线性回归简介
二维线性回归只是在数据图上绘制一条最佳拟合线,你可能已经在高中数学和物理中做过了。我想非常清楚地说明,机器学习只是一个几何问题,你已经熟悉了。当您在较低维度上工作并且实际绘制数据时,这个想法变得很明显。对于不知情的人来说,这似乎是魔术,但实际上它只是“美化的曲线”。
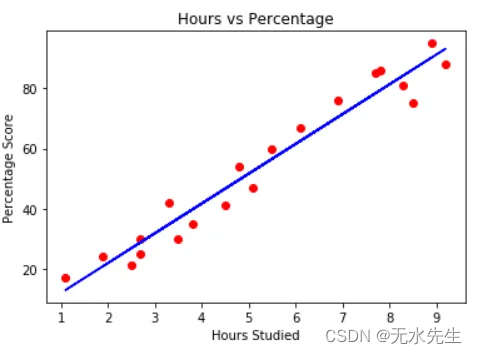
线性回归中的术语“回归”是指预测实数或向量。上面是线性回归的简单示例,模型只是一条线的函数。我们的数据以以下形式出现
![]()
其中 N = 样本数。如果你计算上面的点,你会发现 N=20。在这里,我们的输入 X = 学习所花费的小时数→ Y = 百分比分数。实际上,这两个变量可能是任何东西,我们测量什么并不重要。X 可以是身高,Y 可以是体重。X可能是温度,Y可能是冰淇淋销售。无论情况如何,该方法都保持不变,将线性回归用于解剖学与将其用于业务之间没有区别。“所有数据都是一样的”是机器学习中经常使用的一句话。
三、一维线性回归
您可能想知道为什么这个标题是“一维线性回归”,即使我们处于二维空间中。在机器学习中,“维度”一词通常是指输入的数量或更常见的特征,在这种情况下,我们有 1 个特征 x.认为解决方案在 2D 线性回归情况下非常明显,有人可以说我可以画一条最适合自己的线,为什么要费心使用机器学习。好吧,我们想要一种更系统的方法来绘制这条线并测量它的“拟合数据”程度,而不仅仅是任意地这样做。此外,当我们转向更高的维度时,这将不再可能。我们的最佳拟合线的公式定义为
![]()
这是我们的模型。从技术上讲,我们可以为 a 和 b 输入任何值,并拥有一个有效的线性回归模型,但它不会有任何好处,因为它根本没有学习数据。变量 a 和 b 是我们模型的参数,因为这些是我们可以转动的旋钮和刻度盘,以使我们的模型表现更好。在机器学习中,a通常被称为权重项,b是偏差项。我们希望我们的最佳拟合线尽可能接近 y 在所有 i 上的实际值。我们想定义另一个称为误差函数的函数,这个函数将我们的模型和训练数据作为输入并输出一个错误,我们的模型表现得多么糟糕。一个明显的想法是只取我们的预测和 y 的实际值之间的差异。

假设我们有一个误差为 +3 的项,另一个项的误差为 -3,即使模型表现不佳,我们的总误差为零。我们可以取绝对值,但我们将取差值的平方,这在数学上更容易使用,并且它具有更大的误差=更大的成本的额外好处。通过取 y 的所有值的误差之和,我们得到误差函数。

用我们的表达式代替我们得到的一条线

现在我们有一个函数来表示模型的误差。我们希望最小化模型参数 a 和 b 的成本 E。请注意,我们已经有了 x 和 y,因为它是我们的训练数据。直觉上,您可能已经知道我们将如何使用我们的好朋友微积分来做到这一点。我们的误差函数是一个单调递增的二次函数,这很方便,如果我们取导数并将导数设置为 0,我们可以找到全局最小值。
四、练习:推导解决方案
现在,您应该对如何找到正确的参数a和b有一个一般的直觉,以最小化此成本函数。把我们带到第一个练习。取 a 和 b 的偏导数并找到它们的全局最小值的公式,使用生成的 2 个方程求解 2 个未知数 a 和 b。这将是很多代数,所以要做好准备......
一些提示...
- 请记住,有限求和的导数只是其求和项的导数之和。
- 回想一下样本均值的定义
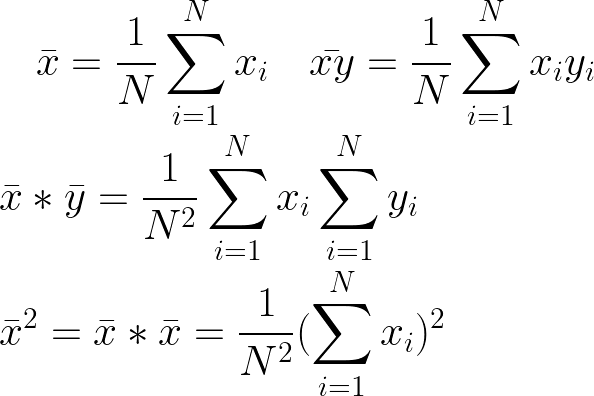
这些将派上用场,使您的最终答案干净简洁
- 如果您遇到困难,请查看解决方案,这可能有助于您弄清楚该怎么做,如果这不起作用,则可以在名为“1D_Linear_Regression_derivation”的存储库中以“”命名进行完整的分步推导
- 如果您不能立即自己解决,请不要担心,只要继续练习直到可以!
五、解决
在取 E 关于 a 和 b 的导数并将它们设置为 0 之后,我们得到这两个方程
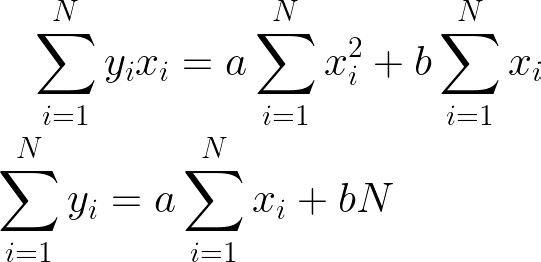
我们有 2 个方程和 2 个未知数,a 和 b。我们可以使用消除来求解 a 和 b。我们可以用字母代替第一个和第二个表达式项,以使代数更容易。
![]()
使用消除求解这些方程后,我们得到

代入我们原来的求和项,并使用上面的示例均值公式进行简化,我们得到

如果你自己走到了这一步,恭喜你!大部分工作已经完成,我们实际上可以使用 NumPy 在几行代码中编写此解决方案。在此之前,让我们找到一种方法来评估我们的模型表现如何。
六、确定模型的性能
有多种不同的方法来判断我们的模型,我们将使用 r-sqaured 公式来做到这一点。我们不会从头开始推导出这个公式,但我会解释使用它背后的直觉。
公式如下:

请注意,分子只是我们的误差公式。分母是所有 y 的总和减去 y 的平均值.SS 只是表示“平方和”。分母可以被认为是基线模型,即每次都只预测 y 平均值的模型。我们可以将模型的误差与每次都猜测 y 均值的模型的误差进行比较。我们来看看几个案例
- ss 残差<ss 总数
在这种情况下,如果我们的残差非常小(接近 0),则残差和总计之间的除法结果也将接近于零。导致 r 平方接近 1。这意味着我们的模型表现非常好,因为我们的误差总和非常小。
- SS 残差 = SS 总计
在这种情况下,如果我们的残差等于总数,这意味着我们的模型几乎只是预测每个值的y平均值。除法的结果是 1,这导致 r 平方接近 0,不好......
- SS残差>SS总数
在这种情况下,我们的模型实际上预测比猜测平均值更糟糕。除法得到一个数> 1,这导致 r 平方为负数。
七、练习:编码一维线性回归
正如您很快就会看到的那样,从头开始编写线性回归模型比推导解决方案要容易得多。回想一下,NumPy 有一个用于点积的特殊函数,并且函数可以在不使用 for 循环的情况下非常快速地获取数组的平均值和和。我们想改变前面的 a 和 b 方程,以利用这 3 个函数,即点积、总和和平均值。可以在不重新排列方程式的情况下编写解决方案,只是需要做更多的工作。在这里使用您自己的直觉。
如果要查看简化公式的分步工作,请参阅存储库中名为“1D_Linear_Regression_numpy_derivation”的文件

遵循 NumPy 中的语法
重新排列 a 和 b 以便于编码后,转到并在Linear_regression文件夹中下载 1D_Linear_regression_practice.ipynb 以及 salary.csv。如果您想自己尝试此操作,只需下载数据集即可。练习文件已经有一些为可视化编写的代码。在您喜欢的编辑器中打开它。如果遇到困难,解决方案也在同一文件夹中提供。
八、多元线性回归
现在我们进入线性回归,但有多个输入变量。仅仅“手工绘制最合适的线”的琐碎解决方案在这里不再适用。在现实世界中,我们可能有多个变量会影响我们的结果。例如,房价可能受到位置、房屋大小、建造年份等的影响......
![]()
回想一下我们之前的数据,在多项式回归中,没有任何变化,只是 x 现在与标量相比是一个向量。我们可以将所有输入放入此向量中。这个向量的大小是x的大小,它被称为由字母D表示的维度。我们还需要所有这些输入的所有权重。我们可以将它们存储在大小为 D 的名为 w 的向量中。我们的新模型定义为:

i 范围从 1-N
![]()
T 用于转置,而不是用于电源!
额外的偏置项b很烦人,让我们通过将其吸收到第一个项中来摆脱它。这将在将来推导解决方案时对我们有所帮助。我们可以将模型重写为:

上面的模型用于 1 样本预测。我们实际上可以利用矩阵乘法的力量来一次生成所有预测的输出。我们可以在名为 X 的大小为 NxD 的矩阵中表示所有样本。

如果我们取 1 行 X,则表示 1 个形状为 1xD(特征向量)的样本。然而,在线性代数中,惯例是将向量视为列向量。因此,对于 1 个样本预测,我们有
![]()
尺寸:1x1 = 1xD * Dx1
如果我们想得到所有 N 个样本的预测,我们将 X 乘以 w。我将标注矩阵和向量的大小,因此不会混淆维度。![]()
在这里,y 是一个向量,包含所有样本 N 的所有预测值。我们可以将一列 1 附加到 X 并在 w 中添加一个 w0 项以解释偏差项。当我们推导出解决方案时,您会意识到这样做是为了减少计算的乏味。
让我们做一个快速的具体例子,将所有这些理论思想固化为石头。假设我们有 3 个特征(输入),所以 D=3,我们有 5 个样本,所以 N=5。如果您到目前为止感到困惑,请尝试在纸上进行此计算。
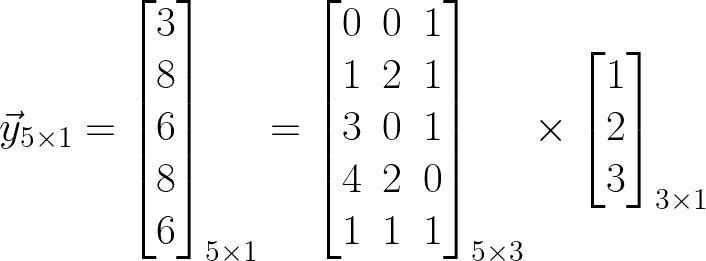
假设我们想对第三个样本进行 1 个样本预测。

请注意 X 的第 3 行如何在此处表示为列向量
九、求解多元线性回归
我们的误差方程不会改变,因此我们可以简单地遵循用于求解一维线性回归的相同方法。现在唯一的问题是它会更抽象一点。该解决方案包含一些矩阵微积分,我们可以一次获取整个矩阵的导数,而不是取单个样本的导数。为了使扩展不那么混乱,我们可以将 y 重命名为一个名为 t 的变量作为目标,并将 y-hat 重命名为 y。这可能会令人困惑,如果您看到 t(目标),则假设 y 是预测,反之亦然,如果您看到 y-hat。为了进行推导,您将扩展我在下面已经为您开始的成本函数,并将带有 reepect 的导数取为 w 而不是上面所说的 wj。您可以使用一些矩阵导数公式。
矩阵导数公式来自这本方便的书,其中包含一堆公式,您可以在此处找到
https://www.math.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf

提示。。。
- 请记住,矩阵乘法不是可交换的,而是结合的
- 对已转置的矩阵进行转置,结果为原始矩阵
- 两个矩阵 AB 的乘积的转置等于 B 转置时间 A 转置
- 请记住,在取导数时,任何不包含我们采用导数 wrt 的变量的变量。被视为常量
- 如果您自己无法弄清楚,请看一下解决方案和您坚持的部分。包含所有步骤的完整派生可以在文件“Mult_Linear_Regression_derivation”的存储库中找到
十、方程解法
在扩展这两个术语并替换为 X 和 w 之后。我们得到
![]()
现在让我们重新排列一些矩阵,以便我们可以使用矩阵导数公式
![]()
现在我们可以使用我们的矩阵导数公式来取导数
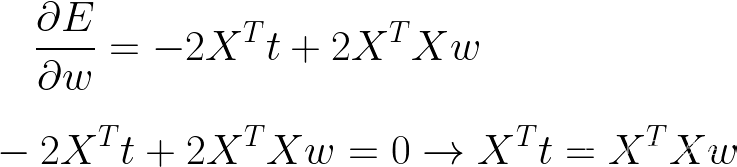
通过一些轻微的重新排列,我们可以隔离w
![]()
十一、练习:编码多元线性回归
现在我们可以从头开始编码多项式回归模型,它与一维线性回归模型没有什么不同。幸运的是,NumPy对我们刚刚求解的公式有一个函数,因为像这样求解方程很常见。

您可以在存储库中找到名为“mult_linear_regression_data”的数据集 在求解 w 之前,不要忘记将 1 的列附加到 X 以确保存在偏差项。顺序并不重要,但将其作为第一列是惯例。如果您自己编码时遇到困难,可以在存储库中找到名为“Mult_Linear_regression_solution”的解决方案
十二、机器学习实践
现在我们已经了解了模型的工作原理以及如何从头开始构建它们,我们可以继续讨论您在实际进行机器学习时会遇到的更多实际问题。我们已经学会了如何“构建”模型,但现在我们必须测试它们的性能,调整和优化它们的性能,修改它们以在不同情况下工作,并处理意外问题。如果我们没有首先从头开始构建模型,所有这些都是不可能的,现在我们知道模型是如何从内到外工作的,实际问题更容易处理。
十三、训练、测试和过拟合
很容易被引诱到最大化准确性是我们的目标的想法,如果我们能在训练期间让我们的模型达到 99.99% 的准确率,这意味着我们有一个好的模型,但请记住我们最初设定的目标。我们希望能够预测未来,而不仅仅是完美地预测我们目前拥有的数据。我们希望我们的模型能够准确地预测以前从未见过的数据。随着我们的模型在训练数据方面变得越来越好,在某一时刻它会“记住”它,如果我们给模型任何新数据,它会挣扎,因为它会不断预测它最初训练的数据。
下面是近似曲线时过度拟合的几何示例。

拟合不足是模型尚未学习数据
为了防止这种情况发生,我们可以拆分数据,其中大部分用于训练,并保留一小部分在完成训练后测试我们的模型。我们希望尽量减少训练数据和测试数据的误差。总有一天,进一步的训练将导致过度拟合和测试数据误差增加。一般其常规是将80%的数据拆分用于训练目的,并使用20%的数据进行测试。除了像我上面提到的拆分数据之外,还有许多技术和方法,但这超出了本博客的范围。

现在过度拟合并不总是模型的错误,如果你没有足够的数据,就没有足够的数据供模型学习,它会开始过度拟合你给它的少量数据。
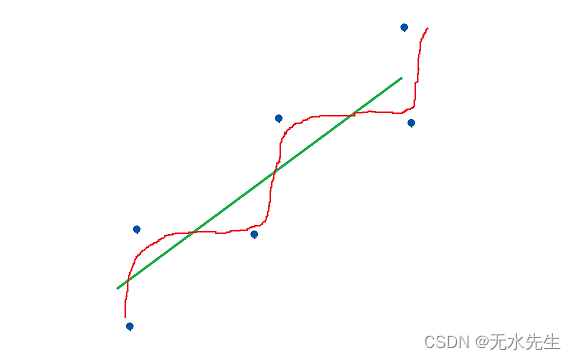
绿线是数据的真实分布
十四、特征工程
让我们学习一些特征工程。我们一直对模型一心一意,但我认为是时候让数据有时间发光了。特征工程是将原始数据转换为特征的过程,这些特征可以更好地表示预测模型的基础模式。特征工程可以使平庸的模型从性能不佳转变为具有令人难以置信的性能。“垃圾进,垃圾出”是数据科学中的一句俗语。我们不能指望我们的模型在没有提供正确数据的情况下表现良好。我们将探索特征工程的一些应用,这些应用使我们能够扩展简单线性回归模型的功能。
十五、多项式回归
是否可以使用线性回归对曲线进行建模。如果我们只能对线性关系进行建模,那将是相当令人失望的。有时,输入可能与输出具有非线性相关性。请记住,我们的模型基本上只是一维场景中一条线的方程。考虑输入“在健身房花费的时间”和输出“获得的肌肉。在绘制数据图表后,我们意识到这种关系可能是对数的,即在健身房多花几个小时!=增加更多的肌肉。我们可以使用二次函数更好地近似这种关系。因此,我们可以向模型添加一个二次项。现在我们的模型是
![]()
我们可以添加任意数量的多项式项以更好地拟合数据,我们可以添加一个 x 立方项等等,但是要小心,因为这会导致过度拟合,想想无限泰勒级数如何近似任何函数。您可能想知道“我如何知道何时在多元线性回归中执行此操作?绘制每个要素与输出之间的关系并分析关系并选择适当的多项式项。

您可能需要查看这些函数的外观
如果关系很复杂,这可能需要一些实验,您希望在不过度拟合的情况下捕获输入和输出之间的关系。多项式回归本质上是在数据中添加一个额外的特征列。这不会改变我们之前派生的模型解决方案。它只是以多项式项的形式增加了一个额外的输入,因此我们称之为特征工程。有一个数据集血压数据集,你可以在下面找到这个想法。
Data for multiple linear regression
我不会为此共享代码,因为它与我们之前所做的没有太大区别。只需根据输出绘制每个要素,观察关系,然后将适当的多项式项追加到数据中即可。
十六、处理分类变量
现在,如果我们有不能表示为数字的变量怎么办。一个例子是预测汽车价格,制造汽车的公司可能是宝马、丰田、福特等......模型无法输入单词。为了解决这个问题,我们将使用独热编码。我们可以将所有类别编码为二进制字符串,其中每个二进制值表示 True 或 False。对于 3 个可能的类别,您的二进制字符串长度为 3。
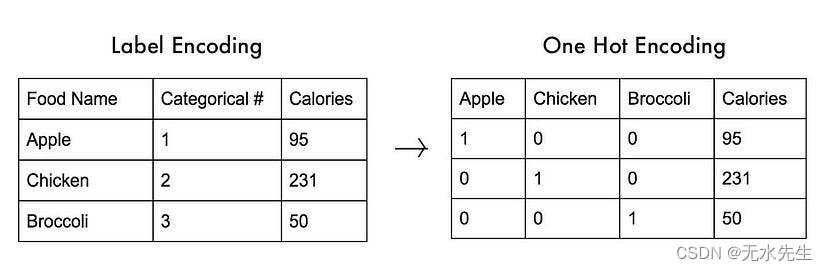
上面完成的标签编码(其中为每个类别分配一个唯一编号)在线性回归中不是一个好主意,因为模型使用输入的大小来确定其输出。实际上,SkLearn中有一个类可以为您完成所有这些工作。
import numpy as np
from sklearn.preprocessing import OneHotEncoder# Sample data
data = [['cat'], ['dog'], ['bird'], ['fish'], ['cat']]# Initialize OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)# Fit and transform data
onehot_encoded = encoder.fit_transform(data)print(onehot_encoded)十七、后续步骤
我在这个博客中没有介绍很多内容,比如正则化、梯度下降、交叉验证和标准化。也许我将来会更新这个博客,添加一些新的东西。从这里开始的下一个合乎逻辑的步骤是学习更多的监督机器学习模型,如果你想尽快进入Nueral网络和深度学习,最好是逻辑回归。希望我没有犯任何错误,如果您发现任何错误,请告诉我。
相关文章:
从头开始机器学习:线性回归
一、说明 本篇实现线性回归的先决知识是:基本线性代数,微积分(偏导数)、梯度和、Python (NumPy);从线性方程入手。 代码/注释存储库链接 拉曼欣德 GitHub - ramanthind02/Machine_learning_from…...
1-k8s1.23.6-底座搭建-基于docker
这里写自定义目录标题 一、服务器准备二、安装docker三、安装k8s四、安装部署dashboard 一、服务器准备 服务器准备 服务器名称服务器IP角色CPU(最低要求)内存(最低要求)master192.168.248.10master2核2Gworker1192.168.248.11node2核2Gworker2192.168.248.12node2核2G 修改ip&…...
】76 - Thermal 功耗 之 /dev/thermalmgr 相关调试命令汇总)
【SA8295P 源码分析 (一)】76 - Thermal 功耗 之 /dev/thermalmgr 相关调试命令汇总
【SA8295P 源码分析】76 - Thermal 功耗 之 /dev/thermalmgr 相关调试命令汇总 1、配置文件:/mnt/etc/system/config/thermal-engine.conf2、获取当前SOC所有温度传感器的温度:cat /dev/thermalmgr3、查看所有 Thermal 默认配置和自定义配置:echo query config > /dev/th…...
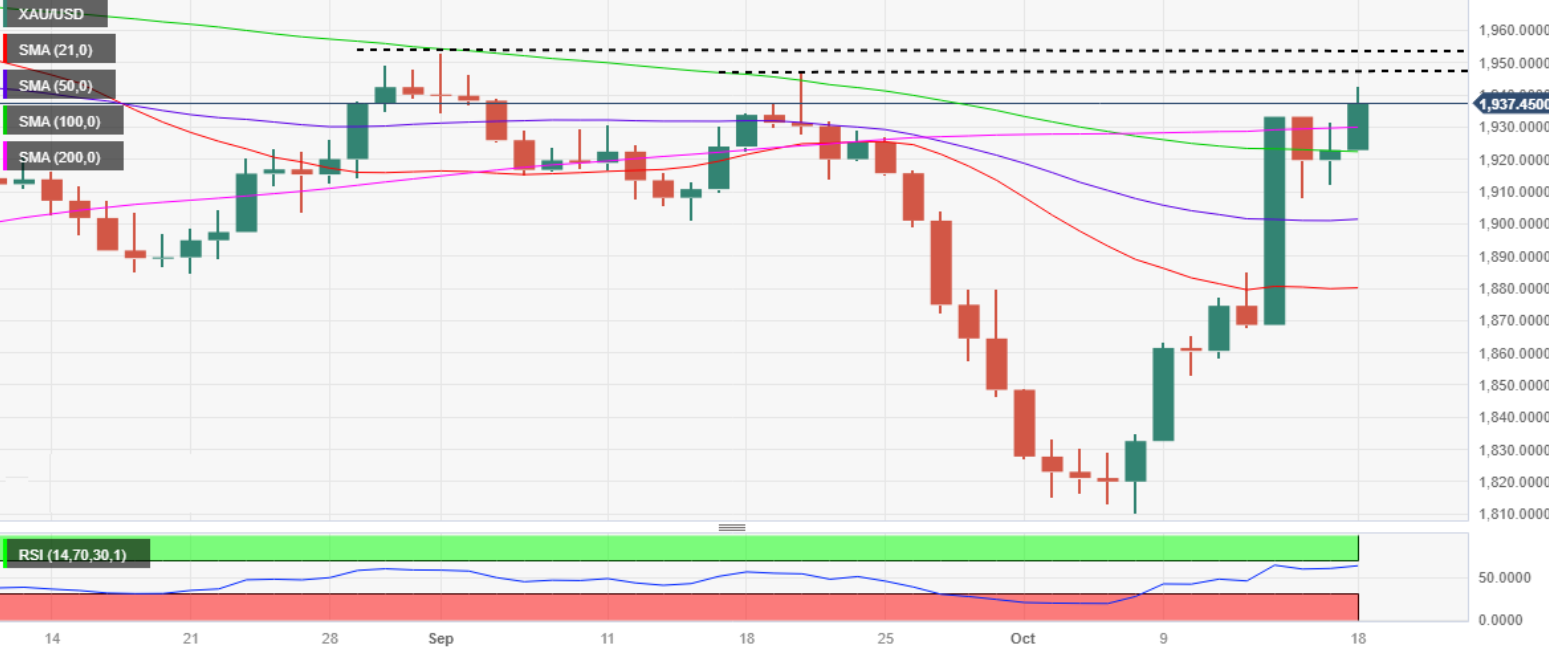
每日汇评:随着上升趋势的恢复,黄金在1950美元上方等待破位
周三早间,黄金价格逼近1950美元,买家纷纷出手; 尽管市场情绪谨慎,但美元与美债交投疲弱,中国的乐观情绪逐渐消退; 金价重拾200日移动均线,但料持续升穿1950美元; 金价正从每盎司1943…...

postgresql字符串处理的函数
1. SPLIT_PART SPLIT_PART() 函数通过指定分隔符分割字符串,并返回第N个子串。语法: SPLIT_PART(string, delimiter, position) string : 待分割的字符串 delimiter:指定分割字符串 position:返回第几个字串,从1开始&…...

(1)攻防世界web-Training-WWW-Robots
1.开启环境,查看网页 翻译一下 2.前往robots.txt 命令:http://61.147.171.105:57663/robots.txt 3.前往fl0g.php 命令:http://61.147.171.105:57663/fl0g.php 4.得到flag cyberpeace{92ec1ef9b6d900100399093b9ae9e386}...
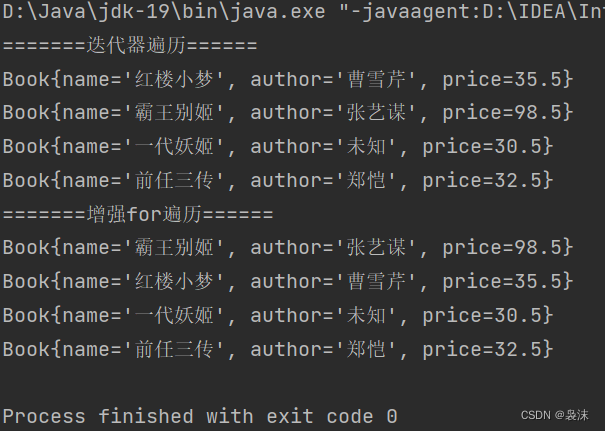
list.set交换数据需要(or不需要)添加其他中间变量,两个例子告诉你
说明:set()方法是来修改指定位置的元素。 两个参数,第一个参数是要修改的元素的索引,第二个参数是要设置的新值。 案例一:当链表中传入的是字符串时: public static void main(String[] args) {List list new Linke…...
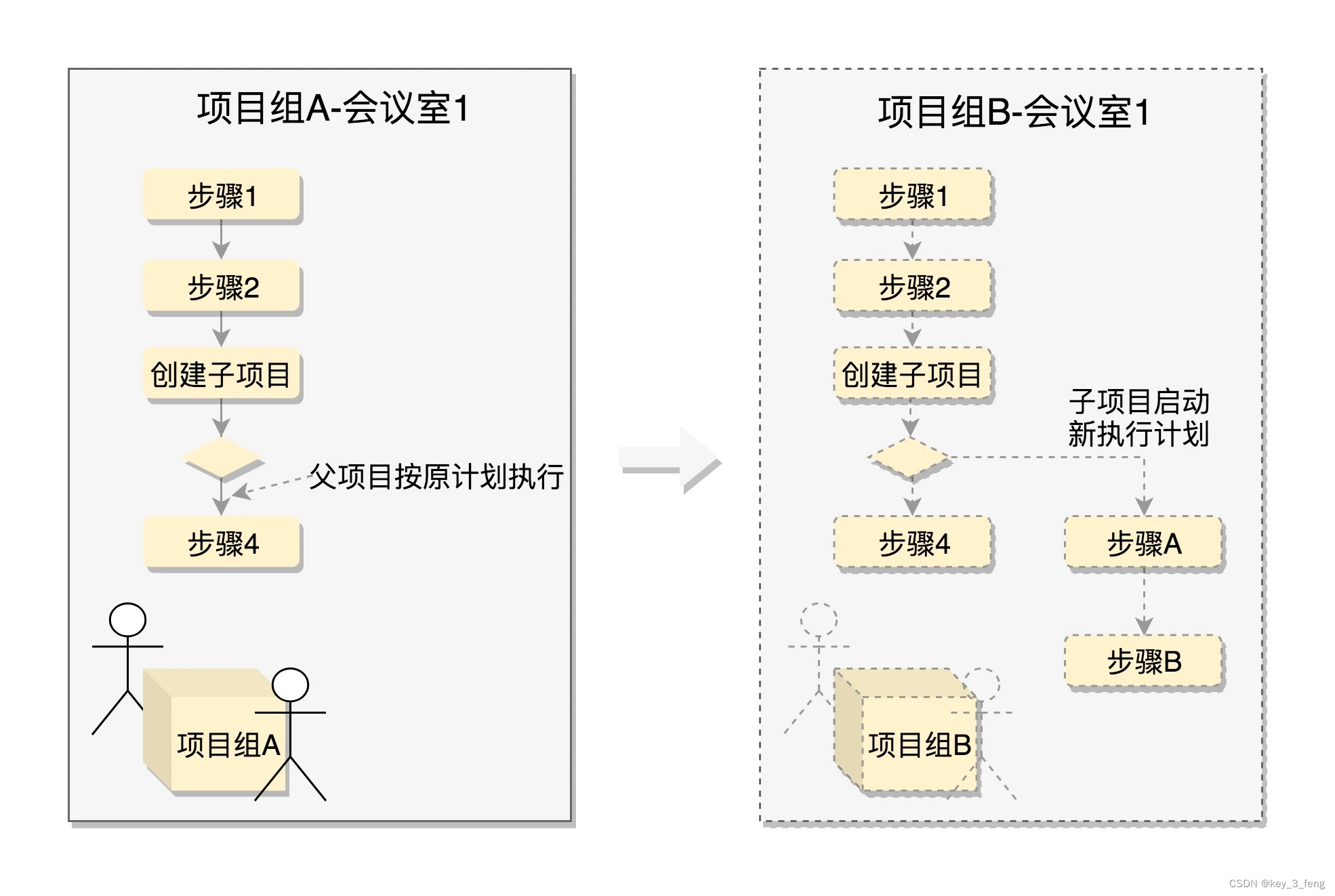
Linux中的主要系统调用
Linux 操作系统中就是创建进程。创建进程的系统调用叫fork。在 Linux 里,要创建一个新的进程,需要一个老的进程调用 fork 来实现,其中老的进程叫作父进程(Parent Process),新的进程叫作子进程(C…...
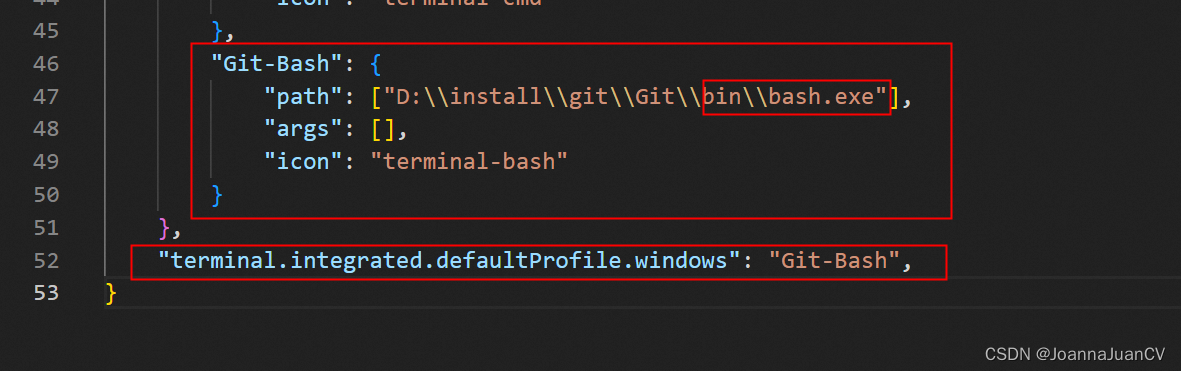
在vscode中配置git bash终端、git 源码管理
打开vscode文件->首选项->设置,打开设置搜索shell windows将以下配置添加到vscode中的settings.json中 注意: terminal.integrated.profiles.windows这个配置项是就是添加终端的terminal.integrated.defaultProfile.windows这个是配置默认选项的…...
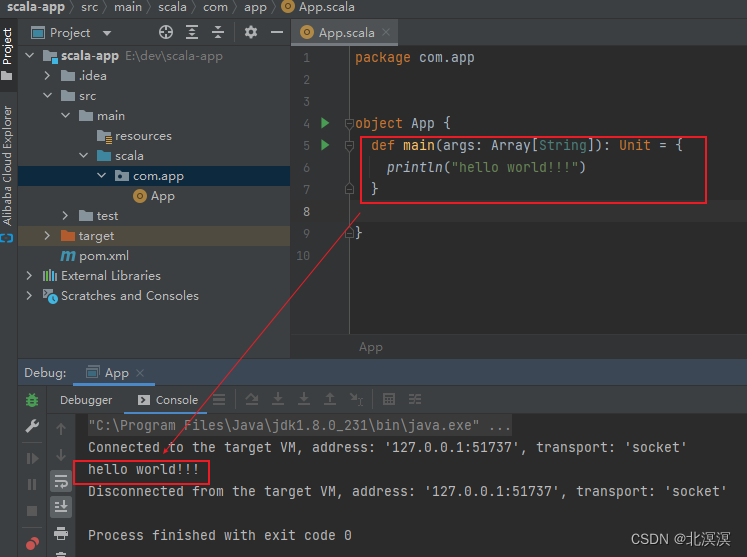
(三十四)大数据实战——scala运行环境安装配置及IDEA开发工具集成
前言 本节内容我们主要介绍一下scala运行环境的安装配置以及在idea开发工具中集成scala插件,便于scala项目的开发。 在开始scala安装配置之前,我们要先安装好jvm运行环境,scala运行于Java虚拟机(JVM)上,并…...

Double 4 VR智能互动教学系统的教学应用
1. 激发学习兴趣 Double 4 VR智能互动教学系统通过虚拟现实技术为学生创造了一个身临其境的学习环境。学生可以通过戴上VR头盔,进入虚拟世界中与教学内容互动。这种沉浸式的学习方式能够激发学生的学习兴趣,使他们更加主动地参与到课堂中来。 2. 提供直…...
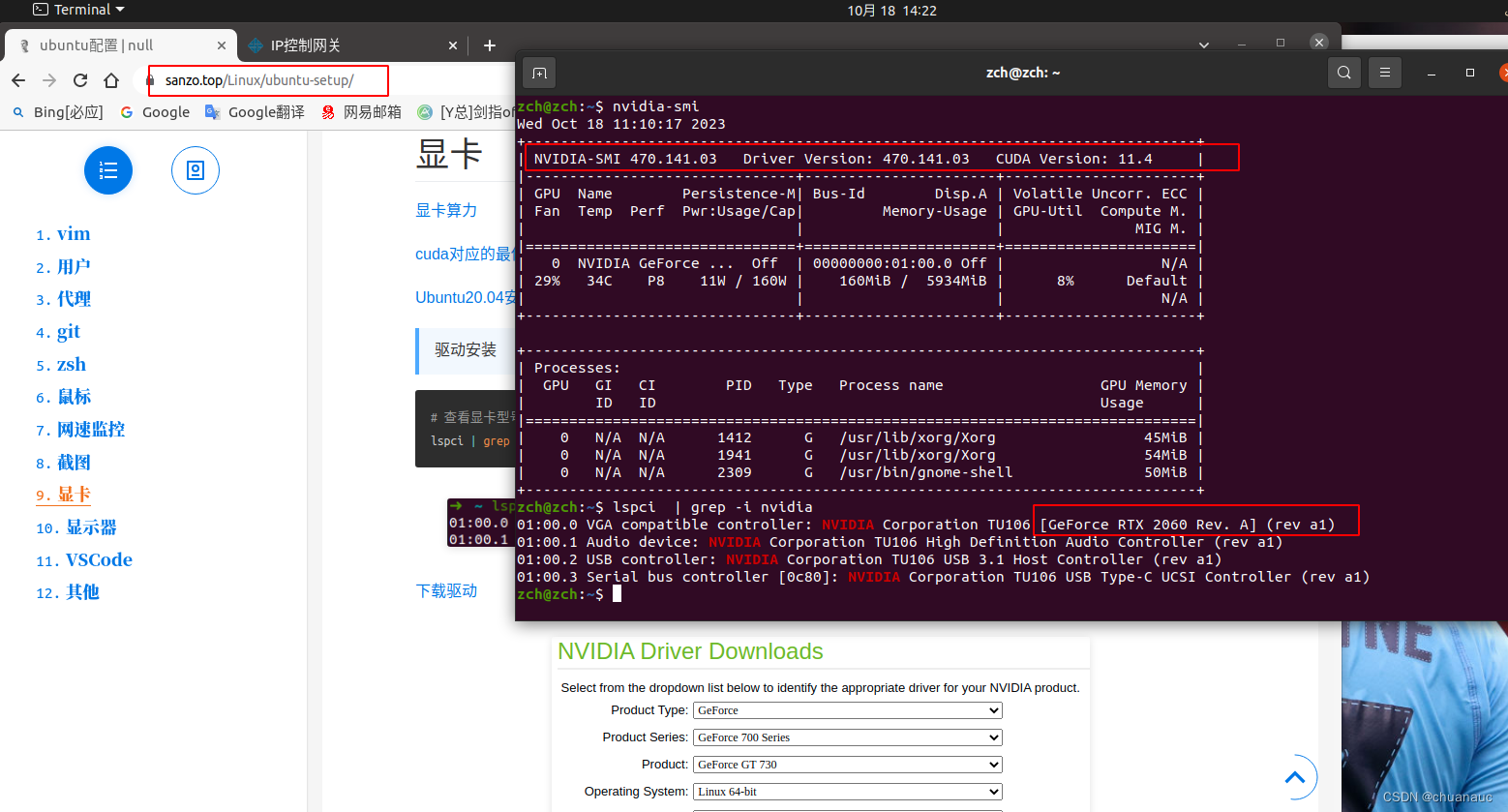
GPU 驱动下载记录
1. 我的GPU 是这个:GeForce RTX 2060 下载链接是:Official Drivers | NVIDIA...

KILM: Knowledge Injection into Encoder-Decoder Language Models
本文是LLM系列文章,针对《KILM: Knowledge Injection into Encoder-Decoder Language Models》的翻译。 KILM:知识注入到编码器-解码器语言模型 摘要1 引言2 相关工作3 方法4 实验5 讨论6 结论局限性 摘要 大型预训练语言模型(PLMs)已被证明在其参数内保…...
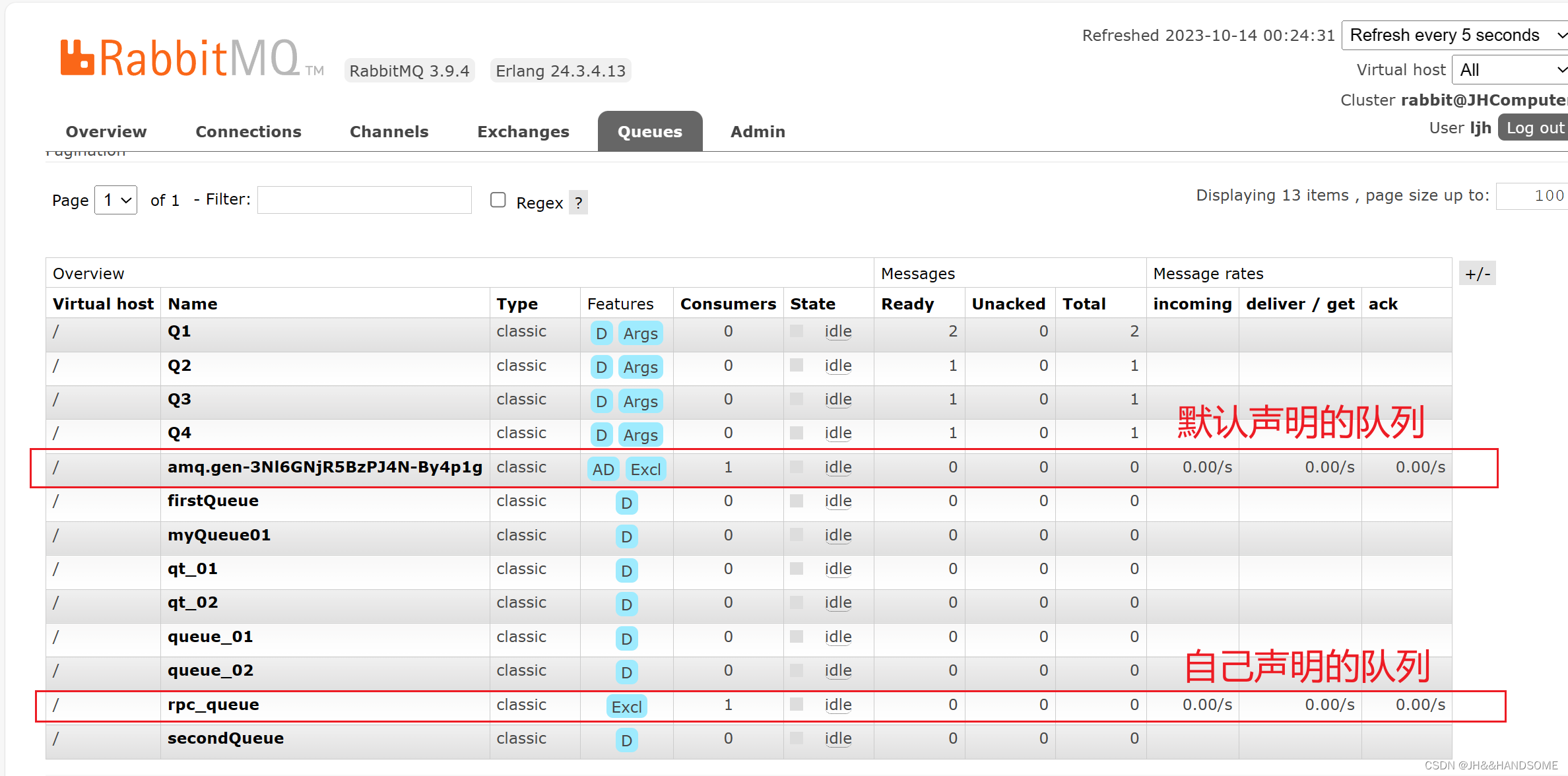
205、使用消息队列实现 RPC(远程过程调用)模型的 服务器端 和 客户端
目录 ★ RPC模型(远程过程调用通信模型)▲ 完整过程:代码演示总体流程解释:ConstantUtil 常量工具类ConnectionUtil RabbitMQ连接工具类Server 服务端Client 客户端测试结果服务端客户端 完整代码ConstantUtil 常量工具类Connecti…...

C++中的函数
在C中,函数是程序的一部分,它执行特定的任务。函数的基本语法如下: type function-name( parameter list ) { body of the function } type 是函数的返回类型,function-name 是函数的名称, parameter list 是传递…...

java操作时间的方式
java操作时间的方式 获取年月日时分秒 public class Test { public static void main(String[] args) { System.out.println("----------使用Calendar--------------------"); Calendar cal Calendar.getInstance(); System.out.println(&q…...

上网冲浪发现多处XSS
突然的发现 今天上网冲浪,突然想起来有一种神器,叫废话生成器,之前是在哪里下了个软件玩了一下,然后就给删除了,因为我觉得这个软件不过就是调用了一个web接口实现的,一个网页能解决的事还要我下一个软件。…...

机器学习的打分方程汇总
机器学习的打分方程集合 受到机器学习(Machine Learning)和深度学习(Deep Learning)等算法模型的创新性冲击,其应用范围涵盖了自然语言处理(Natural Language Processing)、自动驾驶(…...

一文了解数据管理框架以及数据战略制定方法
这一节主要介绍数据管理这一章的另一重要部分,也就是我们在数据管理经常使用到的数据管理框架以及数据战略制定方法。 要制定数据管理框架,或者是组织需要制定数据治理规划或数据管理规划,需要首先制定与业务战略对齐的数据战略。 01、数据…...

智能管家“贾维斯”走进现实?AI Agent或成2023科技领域新风向标
漫威粉们想必都知道《钢铁侠》系列电影中,有一个不可或缺的角色——贾维斯。但就算是没有看过任何一部大电影的路人,只要通过一个词就可以了解“贾维斯”是一个什么样的角色——智能管家。 作为托尼斯塔克的助手,贾维斯的存在让主人的生活更…...

鼎讯 SZT-1000A:交通网络多合一智能测试仪
铁路、高速公路通信网络业务密集、链路复杂,集传输、监控、收费于一体,对测试设备的集成度、便携性、精准度要求极高。鼎讯 SZT-1000A 以太网测试仪,以 “一机多能、超轻便携” 的优势,成为交通领域网络安装、调试、运维的核心利器…...

初次接触Taotoken的新手从注册到成功发起第一次API调用的全过程记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken的新手从注册到成功发起第一次API调用的全过程记录 作为一名刚开始接触大模型开发的工程师,我最近在寻…...

Crontab实战指南:从基础配置到高级调试技巧
1. Crontab入门:从零开始掌握定时任务 第一次接触Crontab时,我被这个看似简单却功能强大的工具深深吸引。作为Linux系统中最经典的定时任务工具,它就像一位不知疲倦的助手,能够精确地在指定时间执行你交代的任何任务。记得刚开始使…...

5分钟极速上手:用Open-Lyrics让AI为你的音频自动生成专业字幕
5分钟极速上手:用Open-Lyrics让AI为你的音频自动生成专业字幕 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。…...

【亲测免费】 探索INA282:电流检测与测量的利器
探索INA282:电流检测与测量的利器 【下载地址】INA282电路图与使用说明 INA282电路图与使用说明本仓库提供了一个关于INA282的详细资源文件,包括电路图和使用说明 项目地址: https://gitcode.com/open-source-toolkit/9e96c 项目介绍 INA282是一…...

magic-api异常处理与错误排查:常见问题解决方案大全
magic-api异常处理与错误排查:常见问题解决方案大全 【免费下载链接】magic-api magic-api 是一个接口快速开发框架,通过Web页面编写脚本以及配置,自动映射为HTTP接口,无需定义Controller、Service、Dao、Mapper、XML、VO等Java对…...

Taotoken稳定直连与路由策略保障了我的线上服务SLA
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken稳定直连与路由策略保障了我的线上服务SLA 将线上服务的AI功能迁移到一个新的平台,首要的考量往往是稳定性。当…...

书匠策AI论文生存指南:降重降AIGC,2025届毕业生的“反内卷外挂“
🎬 开场:一场关于"论文能不能活着毕业"的生存实验 朋友们,今天咱不开学术讲座,咱开一场生存发布会。 2025年写毕业论文是什么体验?你辛辛苦苦码了两万字,满怀信心点了查重——好家伙࿰…...

LLMs 的新前沿:挑战、解决方案与工具
原文:towardsdatascience.com/the-new-frontiers-of-llms-challenges-solutions-and-tools-b1d48c34cf8e?sourcecollection_archive---------2-----------------------#2024-01-25 https://towardsdatascience.medium.com/?sourcepost_page---byline--b1d48c34cf8…...

3分钟快速上手:FanControl风扇控制软件的终极静音散热方案
3分钟快速上手:FanControl风扇控制软件的终极静音散热方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...