推荐算法——NCF知识总结代码实现
NCF知识总结代码实现
- 1. NeuralCF 模型的结构
- 1.1 回顾CF和MF
- 1.2 NCF 模型结构
- 1.3 NeuralCF 模型的扩展---双塔模型
- 2. NCF代码实现
- 2.1 tensorflow
- 2.2 pytorch
NeuralCF:如何用深度学习改造协同过滤?
随着技术的发展,协同过滤相比深度学习模型的弊端就日益显现,因为它是通过直接利用非常稀疏的共现矩阵进行预测的,所以模型的泛化能力非常弱,遇到历史行为非常少的用户,就没法产生准确的推荐结果。
虽然,可以通过矩阵分解算法增强它的泛化能力,但因为矩阵分解是利用非常简单的内积方式来处理用户向量和物品向量的交叉问题的,所以,它的拟合能力也比较弱。
2017 年,新加坡国立的研究者就使用深度学习网络来改进了传统的协同过滤算法,取名 NeuralCF(神经网络协同过滤)。NeuralCF 大大提高了协同过滤算法的泛化能力和拟合能力,让这个经典的推荐算法又重新在深度学习时代焕发生机。
1. NeuralCF 模型的结构
1.1 回顾CF和MF
先来简单回顾一下协同过滤和矩阵分解的原理。协同过滤是利用用户和物品之间的交互行为历史,构建出一个像图左一样的共现矩阵。在共现矩阵的基础上,利用每一行的用户向量相似性,找到相似用户,再利用相似用户喜欢的物品进行推荐。
矩阵分解则进一步加强了协同过滤的泛化能力,它把协同过滤中的共现矩阵分解成了用户矩阵和物品矩阵,从用户矩阵中提取出用户隐向量,从物品矩阵中提取出物品隐向量,再利用它们之间的内积相似性进行推荐排序。
如果用神经网络的思路来理解矩阵分解,它的结构图就是图 2 这样的。

图 2 中的输入层是由用户 ID 和物品 ID 生成的 One-hot 向量,Embedding 层是把 One-hot 向量转化成稠密的 Embedding 向量表达,这部分就是矩阵分解中的用户隐向量和物品隐向量。输出层使用了用户隐向量和物品隐向量的内积作为最终预测得分,之后通过跟目标得分对比,进行反向梯度传播,更新整个网络。
把矩阵分解神经网络化之后,把它跟 Embedding+MLP 以及 Wide&Deep 模型做对比,我们可以一眼看出网络中的薄弱环节:矩阵分解在 Embedding 层之上的操作好像过于简单了,就是直接利用内积得出最终结果。这会导致特征之间还没有充分交叉就直接输出结果,模型会有欠拟合的风险。
1.2 NCF 模型结构
针对矩阵分解的弱点,NeuralCF 对矩阵分解进行了改进,它的结构图是图 3 这样的。

NeuralCF 用一个多层的神经网络替代掉了原来简单的点积操作。这样就可以让用户和物品隐向量之间进行充分的交叉,提高模型整体的拟合能力。
1.3 NeuralCF 模型的扩展—双塔模型
NeuralCF 的模型结构之中,蕴含了一个非常有价值的思想,就是我们可以把模型分成用户侧模型和物品侧模型两部分,然后用互操作层把这两部分联合起来,产生最后的预测得分。
这里的用户侧模型结构和物品侧模型结构,可以是简单的 Embedding 层,也可以是复杂的神经网络结构,最后的互操作层可以是简单的点积操作,也可以是比较复杂的 MLP 结构。但只要是这种物品侧模型 + 用户侧模型 + 互操作层的模型结构,我们把它统称为“双塔模型”结构。

对于 NerualCF 来说,它只利用了用户 ID 作为“用户塔”的输入特征,用物品 ID 作为“物品塔”的输入特征。事实上,我们完全可以把其他用户和物品相关的特征也分别放入用户塔和物品塔,让模型能够学到的信息更全面。比如说,YouTube 在构建用于召回层的双塔模型时,就分别在用户侧和物品侧输入了多种不同的特征。
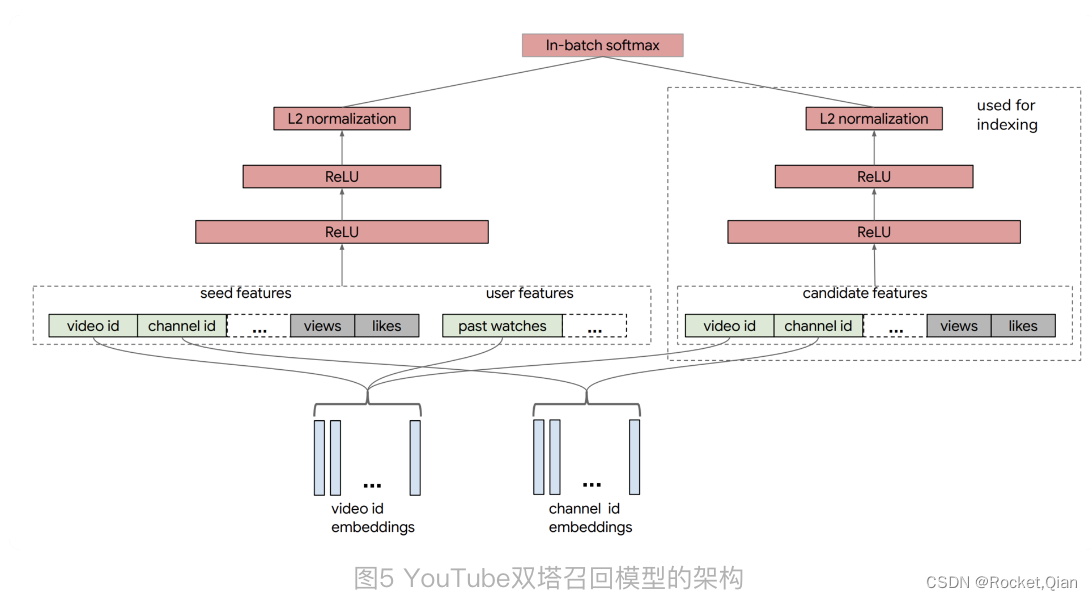
YouTube 召回双塔模型的用户侧特征包括了用户正在观看的视频 ID、频道 ID(图中的 seed features)、该视频的观看数、被喜欢的次数,以及用户历史观看过的视频 ID 等等。物品侧的特征包括了候选视频的 ID、频道 ID、被观看次数、被喜欢次数等等。在经过了多层 ReLU 神经网络的学习之后,双塔模型最终通过 softmax 输出层连接两部分,输出最终预测分数。
这个双塔模型相比Embedding MLP 和 Wide&Deep 有优势:在实际工作中,双塔模型最重要的优势就在于它易上线、易服务。
注意看物品塔和用户塔最顶端的那层神经元,那层神经元的输出其实就是一个全新的物品 Embedding 和用户 Embedding。拿图 4 来说,物品塔的输入特征向量是 x,经过物品塔的一系列变换,生成了向量 u(x),那么这个 u(x) 就是这个物品的 Embedding 向量。同理,v(y) 是用户 y 的 Embedding 向量,这时,我们就可以把 u(x) 和 v(y) 存入特征数据库,这样一来,线上服务的时候,我们只要把 u(x) 和 v(y) 取出来,再对它们做简单的互操作层运算就可以得出最后的模型预估结果了。
所以使用双塔模型,不用把整个模型都部署上线,只需要预存物品塔和用户塔的输出,以及在线上实现互操作层就可以了。如果这个互操作层是点积操作,那么这个实现可以说没有任何难度,这是实际应用中非常容易落地的,这也正是双塔模型在业界巨大的优势所在。
2. NCF代码实现
2.1 tensorflow
NeuralCF模型部分的实现
# neural cf model arch two. only embedding in each tower, then MLP as the interaction layers
def neural_cf_model_1(feature_inputs, item_feature_columns, user_feature_columns, hidden_units):# 物品侧特征层item_tower = tf.keras.layers.DenseFeatures(item_feature_columns)(feature_inputs)# 用户侧特征层user_tower = tf.keras.layers.DenseFeatures(user_feature_columns)(feature_inputs)# 连接层及后续多层神经网络interact_layer = tf.keras.layers.concatenate([item_tower, user_tower])for num_nodes in hidden_units:interact_layer = tf.keras.layers.Dense(num_nodes, activation='relu')(interact_layer)# sigmoid单神经元输出层output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(interact_layer)# 定义keras模型neural_cf_model = tf.keras.Model(feature_inputs, output_layer)return neural_cf_model
代码中定义的生成 NeuralCF 模型的函数,接收了四个输入变量。其中 feature_inputs 代表着所有的模型输入, item_feature_columns 和 user_feature_columns 分别包含了物品侧和用户侧的特征。在训练时,如果只在 item_feature_columns 中放入 movie_id ,在 user_feature_columns 放入 user_id, 就是NeuralCF的经典实现了。
通过 DenseFeatures 层创建好用户侧和物品侧输入层之后,再利用 concatenate 层将二者连接起来,然后输入多层神经网络进行训练。如果想要定义多层神经网络的层数和神经元数量,可以通过设置 hidden_units 数组来实现。
2.2 pytorch
#GMF层
class GMF(nn.Module):def __init__(self,embedding_dim):super(GMF, self).__init__()self.embedding_dim = embedding_dimself.fc = nn.Linear(self.embedding_dim,self.embedding_dim)def forward(self, user_emb, item_emb):out = self.fc(user_emb*item_emb).sigmoid()return out#MLP
class MLP_Layer(nn.Module):def __init__(self,input_dim,output_dim=None,hidden_units=[],hidden_activations="ReLU",final_activation=None,dropout_rates=0,batch_norm=False,use_bias=True):super(MLP_Layer, self).__init__()dense_layers = []if not isinstance(dropout_rates, list):dropout_rates = [dropout_rates] * len(hidden_units)if not isinstance(hidden_activations, list):hidden_activations = [hidden_activations] * len(hidden_units)hidden_activations = [set_activation(x) for x in hidden_activations]hidden_units = [input_dim] + hidden_unitsfor idx in range(len(hidden_units) - 1):dense_layers.append(nn.Linear(hidden_units[idx], hidden_units[idx + 1], bias=use_bias))if batch_norm:dense_layers.append(nn.BatchNorm1d(hidden_units[idx + 1]))if hidden_activations[idx]:dense_layers.append(hidden_activations[idx])if dropout_rates[idx] > 0:dense_layers.append(nn.Dropout(p=dropout_rates[idx]))if output_dim is not None:dense_layers.append(nn.Linear(hidden_units[-1], output_dim, bias=use_bias))if final_activation is not None:dense_layers.append(set_activation(final_activation))self.dnn = nn.Sequential(*dense_layers) # * used to unpack listdef forward(self, inputs):return self.dnn(inputs)def set_device(gpu=-1):if gpu >= 0 and torch.cuda.is_available():os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)device = torch.device(f"cuda:{gpu}")else:device = torch.device("cpu")return devicedef set_activation(activation):if isinstance(activation, str):if activation.lower() == "relu":return nn.ReLU()elif activation.lower() == "sigmoid":return nn.Sigmoid()elif activation.lower() == "tanh":return nn.Tanh()else:return getattr(nn, activation)()else:return activationdef get_dnn_input_dim(enc_dict,embedding_dim):num_sparse = 0num_dense = 0for col in enc_dict.keys():if 'min' in enc_dict[col].keys():num_dense+=1elif 'vocab_size' in enc_dict[col].keys():num_sparse+=1return num_sparse*embedding_dim+num_densedef get_linear_input(enc_dict,data):res_data = []for col in enc_dict.keys():if 'min' in enc_dict[col].keys():res_data.append(data[col])res_data = torch.stack(res_data,axis=1)return res_data
# NCF 模型
class NCF(nn.Module):def __init__(self,embedding_dim1=16, # GMF 对应的Embedding层embedding_dim2=32, # MLP 对应的Embedding层hidden_units=[64, 32, 16],loss_fun = 'torch.nn.BCELoss()',enc_dict=None):super(NCF, self).__init__()self.embedding_dim1 = embedding_dim1 # GMF Embself.embedding_dim2 = embedding_dim2 # MLP Embself.hidden_units = hidden_unitsself.loss_fun = eval(loss_fun)self.enc_dict = enc_dict# GMFself.user_emb_layer1 = nn.Embedding(self.enc_dict['user_id']['vocab_size'],self.embedding_dim1)self.item_emb_layer1 = nn.Embedding(self.enc_dict['item_id']['vocab_size'],self.embedding_dim1)# MLPself.user_emb_layer2 = nn.Embedding(self.enc_dict['user_id']['vocab_size'],self.embedding_dim2)self.item_emb_layer2 = nn.Embedding(self.enc_dict['item_id']['vocab_size'],self.embedding_dim2)self.gmf = GMF(self.embedding_dim1)self.mlp = MLP_Layer(input_dim=self.embedding_dim2*2, hidden_units=self.hidden_units,hidden_activations='relu', dropout_rates=0)# GMF:[batch,Emb1] MLP:[batch,hidden_units[-1]]-> FC的输入维度:self.embedding_dim1 + self.hidden_units[-1]self.fc = nn.Linear(self.embedding_dim1 + self.hidden_units[-1],1)def forward(self, data):# GMFuser_emb1 = self.user_emb_layer1(data['user_id'])item_emb1 = self.item_emb_layer1(data['item_id'])# MLPuser_emb2 = self.user_emb_layer2(data['user_id'])item_emb2 = self.item_emb_layer2(data['item_id'])# GMFgmf_out = self.gmf(user_emb1, item_emb1)# MLPmlp_input = torch.cat([user_emb2,item_emb2],axis=-1)mlp_out = self.mlp(mlp_input)#输出final_input = torch.cat([gmf_out,mlp_out],axis=-1)y_pred = self.fc(final_input).sigmoid()loss = self.loss_fun(y_pred.squeeze(-1),data['label'])output_dict = {'pred':y_pred,'loss':loss}return output_dict
相关文章:
推荐算法——NCF知识总结代码实现
NCF知识总结代码实现1. NeuralCF 模型的结构1.1 回顾CF和MF1.2 NCF 模型结构1.3 NeuralCF 模型的扩展---双塔模型2. NCF代码实现2.1 tensorflow2.2 pytorchNeuralCF:如何用深度学习改造协同过滤? 随着技术的发展,协同过滤相比深度学习模型的…...

redis(4)String字符串
前言 Redis中有5大数据类型,分别是字符串String、列表List、集合Set、哈希Hash、有序集合Zset,本篇介绍Redis的字符串String Redis字符串 String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value…...

session一致性问题
在http访问请求中,web服务器会自动为同一个浏览器的访问用户自动创建唯一的session,提供数据存储功能。最常见的,会把用户的登录信息、用户信息存储在session中,以保持登录状态。只要用户不重启浏览器,每次http短连接请…...

上岸16K,薪资翻倍,在华为外包做测试是一种什么样的体验····
现在回过头看当初的决定,还是正确的,自己转行成功,现在进入了华为外包测试岗,脱离了工厂生活,薪资也翻了一倍不止。 我17年毕业于一个普通二本学校,电子信息工程学院,是一个很不出名的小本科。…...
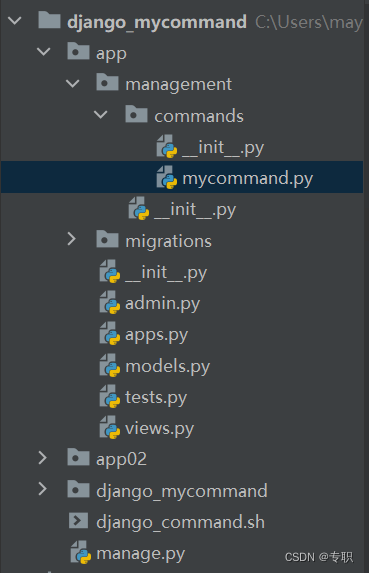
django项目中如何添加自定义的django command
项目目录 1.我们自己建立的application叫做app,首先在这个app目录下,我们需要新建management目录,这个目录里应该包括:__ init__.py(内容为空,用于打包)和commands目录,然后在comma…...

【算法基础】哈希表⭐⭐⭐
一、哈希表 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 给定表M,存在函数f(key),对任意…...

基于SpringMVC、Spring、MyBatis开发的校园点餐系统
文章目录 项目介绍主要功能截图:后台登录用户管理商品管理评论管理订单管理角色管理咨询管理前台前台首页我的订单商品详情支付方式选择支付成功页面部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题…...
LeetCode 热题 C++ 148. 排序链表 152. 乘积最大子数组 160. 相交链表
力扣148 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 1: 输入:head [4,2,1,3] 输出:[1,2,3,4]示例 2: 输入:head [-1,5,3,4,0] 输出:[-1,0,3,4,5]示例 3&#x…...

JavaScript 基础【快速掌握知识点】
目录 为什么要学JavaScript? 什么是JavaScript 特点: 组成: JavaScript的基本结构 基本结构 内部引用 外部引用 console对象进行输出 JavaScript核心语法 1、变量声明 2、数据类型 3、运算符 4、条件语句 5、循环语句 6、数组 7…...
基于Frenet优化轨迹的⾃动驾驶动作规划⽅法
动作规划(Motion Control)在⾃动驾驶汽⻋规划模块的最底层,它负责根据当前配置和⽬标配置⽣成⼀序列的动作,本⽂介绍⼀种基于Frenet坐标系的优化轨迹动作规划⽅法,该⽅法在⾼速情况下的ACC辅助驾驶和⽆⼈驾驶都具有较强…...
Spring(入门)
1. 什么是spring,它能够做什么?2. 什么是控制反转(或依赖注入)3. AOP的关键概念4. 示例 4.1 创建工程4.2 pom文件4.3 spring配置文件4.4 示例代码 4.4.1 示例14.4.2 示例2 (abstract,parent示例)4.4.3 使用有参数构造方法创建jav…...

2023-02-25力扣每日一题
链接: https://leetcode.cn/problems/minimum-swaps-to-make-strings-equal/ 题意: 给定字符串s1,s2,仅由x,y组成 每次可以在两边各挑一个字符交换 求让s1等于s2的最小步骤 解: 1000啊1000,双指针贪一下就过了 …...
如何外网登录管理云通信短信网关平台?——快解析映射方案
云通信(Cloud Communications )是基于云计算商业模式应用的通信平台服务,简单易用,满足企业一键群发场景,支持多种语言SDK和API 接入。各个通信平台软件都集中在云端,且互通兼容,用户只要登录云通信平台,不…...

学习 Python 之 Pygame 开发魂斗罗(三)
学习 Python 之 Pygame 开发魂斗罗(三)继续编写魂斗罗1. 角色站立2. 角色移动3. 角色跳跃4. 角色下落继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(二)中,我们完成了角色的创建和更新,现…...

【华为OD机试模拟题】用 C++ 实现 - 最多获得的短信条数(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 分积木(2023.Q1) 【华为OD机试模拟题】用 C++ 实现 - 吃火锅(2023.Q1) 【华为OD机试模拟题】用 C++ 实现 - RSA 加密算法(2023.Q1) 【华为OD机试模拟题】用 C++ 实现 - 构成的正方形数量(2023.Q1) 【华为OD机试模拟…...

linux系统加exfat驱动
u盘假如是fat格式不支持大于4G文件,所以一般u盘用exfat格式,兼容性更好 有的老linux没支持exfat格式,那就自己装个驱动吧 sudo apt-get install exfat-fuse exfat-utils 有一台fedora27需要yum安装,国外源比较慢,改…...
3,预初始化(一)(大象无形9.2)
正如书中所说,预初始化流程由FEngineLoop::PreInit()所实现 主要处理流程 1,设置路径:当前程序路径,当前工作目录路径,游戏的工程路径 2,设置标准输出:设置GLog系统输出的设备,是输出到命令行…...
)
【PAT甲级题解记录】1013 Battle Over Cities (25 分)
【PAT甲级题解记录】1013 Battle Over Cities (25 分) 前言 Problem:1013 Battle Over Cities (25 分) Tags:DFS 连通图 Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1013 Battle Over Cities (25 分) 问题描述 给…...

CSS-关键帧动画
animation和transition的区别 相同点:都是随时间改变元素的属性值 不同点:transition需要触发一个时间(hover或者click事件)才会随时间改变其css属性;而animation在不需要触发任何事件的情况下也是可以显示的随时间变化来改变元素的css属性值,从而达到一种动画的效果,cs…...
Allegro如何画Photoplot_Outline操作指导
Allegro如何画Photoplot_Outline操作指导 在用Allegro进行PCB设计的时候,最后进行光绘输出前,Photoplot_Outline是必备一个图形,所有在Photoplot_Outline中的图形将被输出,Photoplot_Outline以外的图形都将不被输出。 如何绘制Photoplot_Outline,具体操作如下 点击Shape点…...

vue3+python基于Django的校园二手物品交易系统设计与实现49895951
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键实现细节扩展性设计参考开源项目项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目…...

IDM激活脚本完全指南:3种方法实现永久免费使用
IDM激活脚本完全指南:3种方法实现永久免费使用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为Internet Download Manager(IDM&…...

YOLOv11公共场所人群年龄目标检测数据集-280张-pedestrian-1_5
YOLOv11公共场所人群年龄目标检测数据集 📊 数据集基本信息 目标类别: [‘adult’, ‘child’, ‘elder’]中文类别:[‘成人’, ‘儿童’, ‘老人’]训练集:196 张验证集:56 张测试集:28 张总计:…...
)
解锁Midjourney大画幅秘密:3步实现电影级宽幅输出(含17组实测--ar 16:9至32:9全适配prompt模板)
更多请点击: https://codechina.net 第一章:Midjourney大画幅输出的核心原理与视觉范式 Midjourney的大画幅输出并非简单缩放像素,而是基于其扩散模型对高维潜在空间的结构化采样与语义一致性重合成。其核心依赖于隐式超分辨率(I…...

38 - Go 命令行参数处理:从 os.Args 到 flag 的底层设计
文章目录38 - Go 命令行参数处理:从 os.Args 到 flag 的底层设计为什么需要命令行参数?命令行参数的本质最基础的参数处理:os.Args基础使用示例获取单个参数flag 标准库:Go 官方参数解析器最简单的 flag 示例为什么 flag.String 返…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...

前端架构演进:从单体到微前端
前端架构演进:从单体到微前端 前端架构的发展历程 第一阶段:单体应用(Mono Repo) ├── src/ │ ├── components/ │ ├── pages/ │ ├── services/ │ ├── utils/ │ └── styles/ └── index.html…...

ncmdumpGUI:免费解锁网易云音乐加密文件,3分钟实现跨设备播放自由
ncmdumpGUI:免费解锁网易云音乐加密文件,3分钟实现跨设备播放自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到过这样…...

蒙古语TTS准确率仅73%?ElevenLabs 2024Q2基准测试报告曝光:词级准确率91.4%,但需绕过这2个API默认参数坑
更多请点击: https://codechina.net 第一章:蒙古语TTS准确率争议的真相还原 近年来,多款商用及开源蒙古语文本转语音(TTS)系统在公开评测中报告了92%–97%的词级准确率,但一线教育机构与本地化团队反馈的实…...

Potree加载点云实战:从CloudCompare检查到浏览器3D展示的全链路避坑
Potree点云加载全流程实战:从数据验收到3D可视化的深度指南 点云数据正逐渐成为三维地理信息系统、建筑信息模型和数字孪生领域的核心载体。作为开源点云可视化库的佼佼者,Potree以其高效的Web端渲染能力赢得了众多开发者的青睐。然而在实际项目集成过程…...