一些经典的神经网络(第17天)
1. 经典神经网络LeNet
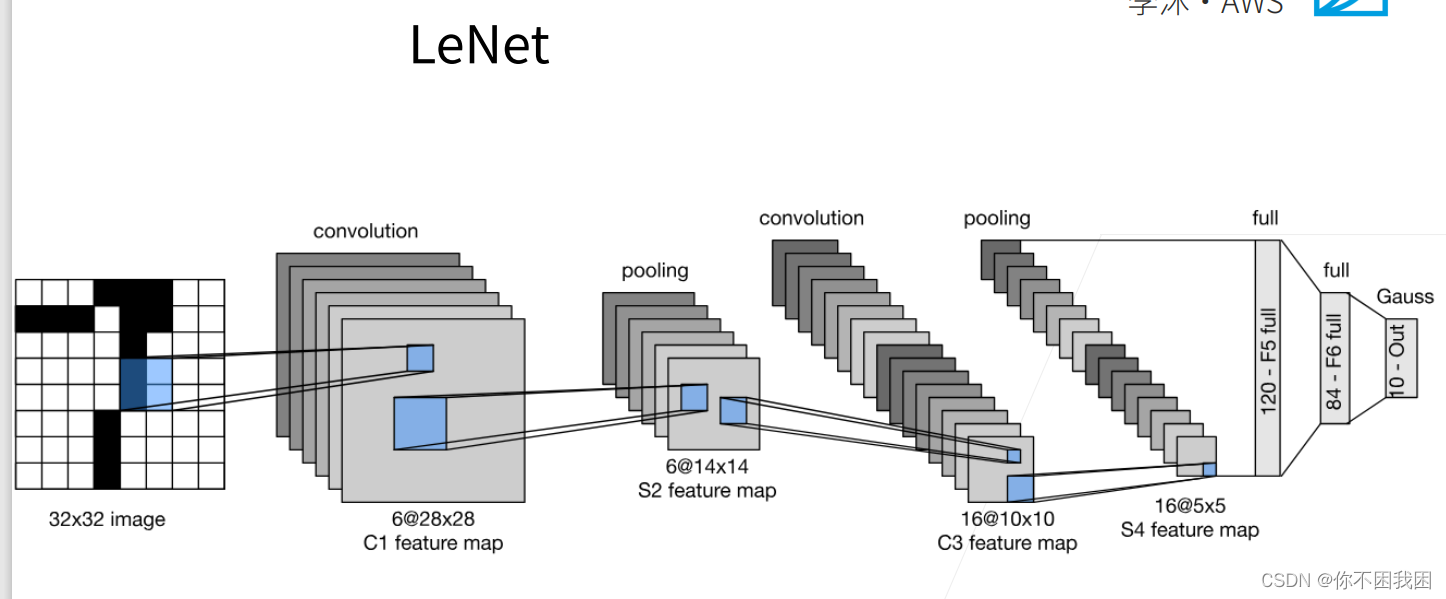
LeNet是早期成功的神经网络;
先使用卷积层来学习图片空间信息
然后使用全连接层来转到到类别空间
【通过在卷积层后加入激活函数,可以引入非线性、增加模型的表达能力、增强稀疏性和解决梯度消失等问题,从而提高卷积神经网络的性能和效果】
LeNet由两部分组成:卷积编码器和全连接层密集块
import torch
from torch import nn
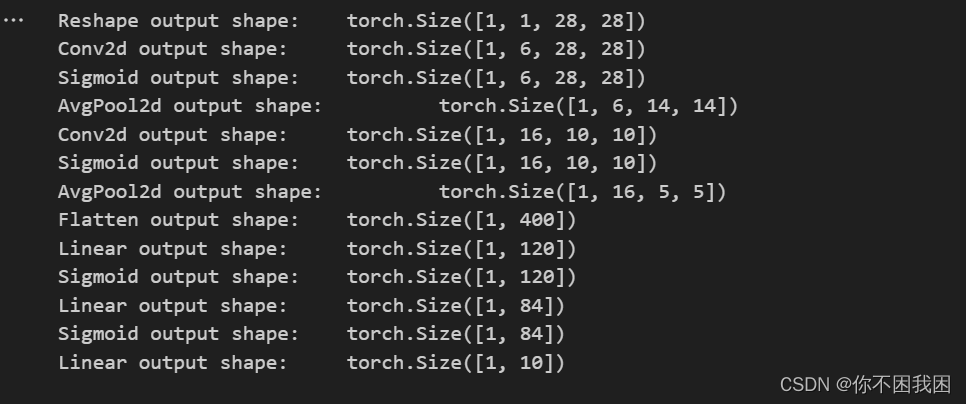
from d2l import torch as d2lclass Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28) # 批量数不变,通道数=1,h=28, w=28net = torch.nn.Sequential(Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), # 在卷积后加激活函数,填充是因为原始处理数据是32*32nn.AvgPool2d(kernel_size=2, stride=2), # 池化层nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), # 将4D结果拉成向量# 相当于两个隐藏层的MLPnn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 10))
检查模型
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X) """对神经网络 net 中的每一层进行迭代,并打印每一层的输出形状layer.__class__.__name__ 是获取当前层的类名,即层的类型"""print(layer.__class__.__name__, 'output shape: \t', X.shape)
LeNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 对evaluate_accuarcy函数进行轻微的修改
def evaluate_accuracy_gpu(net, data_iter, device=None): """使用GPU计算模型在数据集上的精度。"""if isinstance(net, torch.nn.Module):net.eval()if not device:device = next(iter(net.parameters())).devicemetric = d2l.Accumulator(2)for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1] # 分类正确的个数 / 总个数
【
net.to(device) 是将神经网络 net 中的所有参数和缓冲区移动到指定的设备上进行计算的操作。
net 是一个神经网络模型。device 是指定的设备,可以是 torch.device 对象,如 torch.device(‘cuda’) 表示将模型移动到 GPU 上进行计算,或者是字符串,如 ‘cuda:0’ 表示将模型移动到指定编号的 GPU 上进行计算,也可以是 ‘cpu’ 表示将模型移动到 CPU 上进行计算。
通过调用 net.to(device),模型中的所有参数和缓冲区将被复制到指定的设备上,并且之后的计算将在该设备上进行。这样可以利用 GPU 的并行计算能力来加速模型训练和推断过程。
注意,仅仅调用 net.to(device) 并不会对输入数据进行迁移,需要手动将输入数据也移动到相同的设备上才能与模型进行计算。例如,可以使用 input = input.to(device) 将输入数据 input 移动到指定设备上。】
# 为了使用 GPU,我们还需要一点小改动
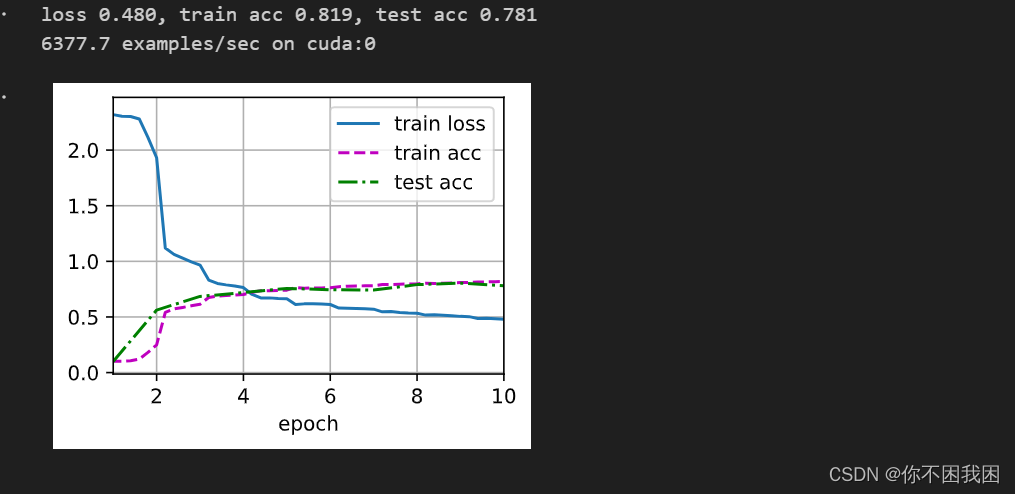
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)。"""def init_weights(m): # 初始化权重if type(m) == nn.Linear or type(m) == nn.Conv2d: nn.init.xavier_uniform_(m.weight)net.apply(init_weights) # 对整个网络应用初始化print('training on', device)net.to(device) # 将神经网络 net 中的所有参数和缓冲区移动到指定的设备上进行计算的操作optimizer = torch.optim.SGD(net.parameters(), lr=lr) # 定义优化器loss = nn.CrossEntropyLoss() # 定义损失函数# 动画效果animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3) # metric被初始化为存储3个指标值的累加器net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()# 将输入输出数据也移动到相同的设备X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]# 动画效果if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
2. 深度卷积神经网络(AlexNet)
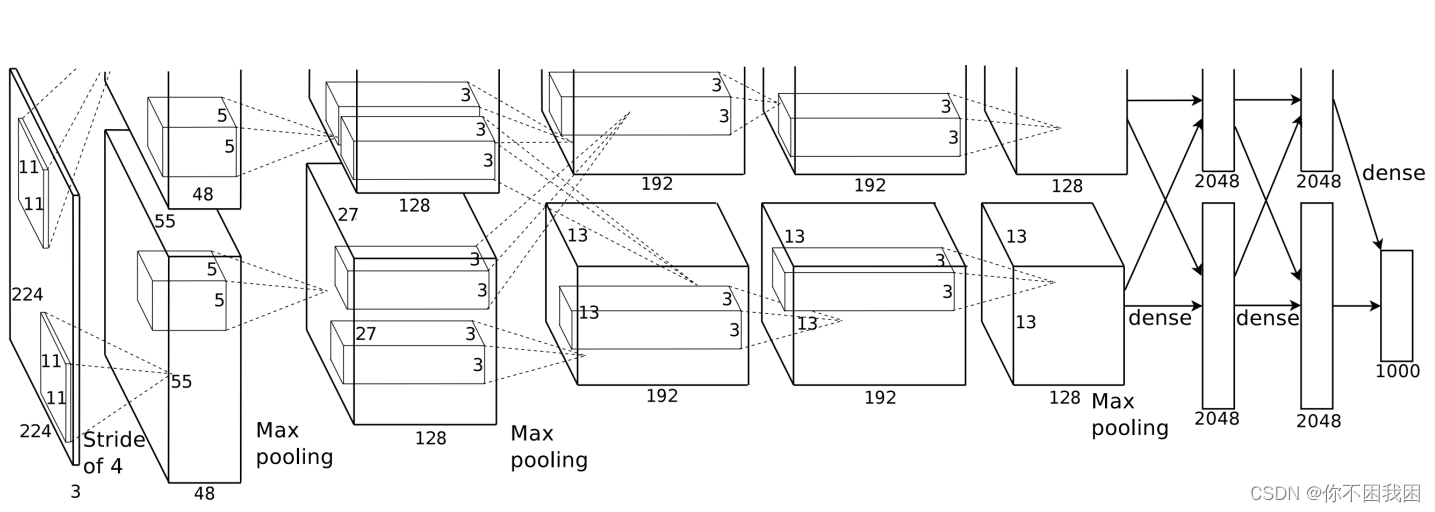
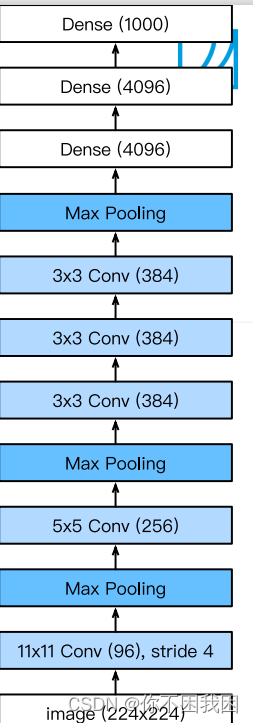
AlexNet架构 VS LeNet:
更大的核窗口和步长,因为图片更大了
更大的池化窗口,使用maxpooling
更多的输出通道
添加了3层卷积层
更多的输出
更多细节:
- 激活函数从sigmod变成了Rel(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层dropout
- 数据增强
总结:
- AlexNet是更大更深的LeNet,处理的参数个数和计算复杂度大幅度提升
- 新加入了丢弃法,ReLU激活函数,最大池化层和数据增强
代码实现:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(), # 在MNIST输入通道是1,在ImageNet测试集上输入为3nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(), # 相比于LeNet将激活函数改为ReLUnn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(), # 将4D->2Dnn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5), # 添加丢弃nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),nn.Linear(4096, 10)) # 在Fashion-MNIST上做测试所以输出为10
# 构造一个单通道数据,来观察每一层输出的形状
X = torch.randn(1, 1, 224, 224)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'Output shape:\t', X.shape)
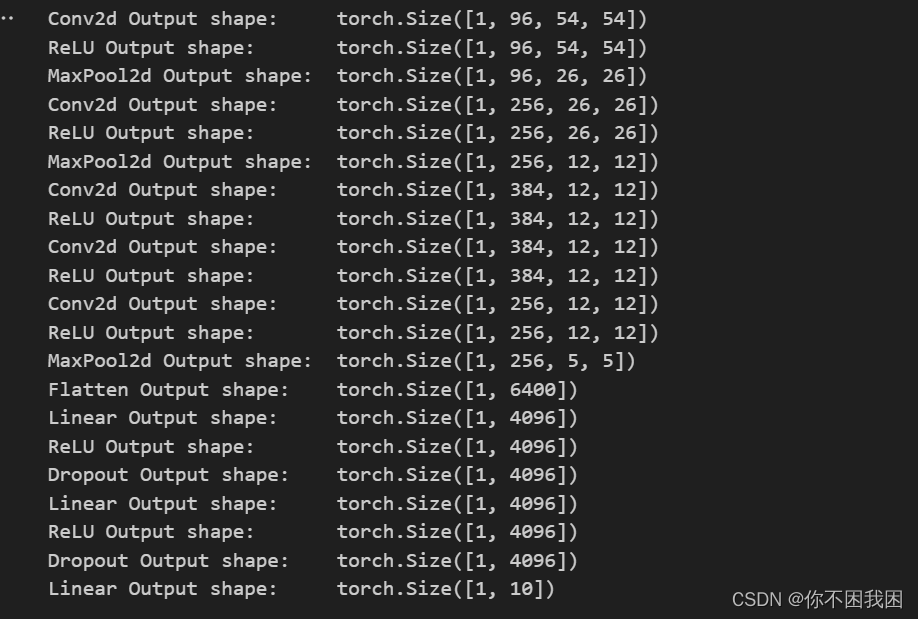
# Fashion-MNIST图像的分辨率低于ImageNet图像,所以将其增加到224x224
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 训练AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
相关文章:
一些经典的神经网络(第17天)
1. 经典神经网络LeNet LeNet是早期成功的神经网络; 先使用卷积层来学习图片空间信息 然后使用全连接层来转到到类别空间 【通过在卷积层后加入激活函数,可以引入非线性、增加模型的表达能力、增强稀疏性和解决梯度消失等问题,从而提高卷积…...

Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件 版本号步骤hadoopcore-site.xmlhdfs-site.xmlmapred-site.xmlslavesworkersyarn-site.xml hivehive-site.xmlspark-defaults.conf sparkhdfs-site.xmlhive-site.xmlslavesyarn-site.xmlspark-env.sh 版本号 apache-hive-3.1.3-…...

Hutool工具类参考文章
Hutool工具类参考文章 日期: 身份证:...

【 Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全】
Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全 本文主要介绍了Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值&#x…...

eclipse 配置selenium环境
eclipse环境 安装selenium的步骤 配置谷歌浏览器驱动 Selenium安装-如何在Java中安装Selenium chrome驱动下载 eclipse 启动配置java_home: 在eclipse.ini文件中加上一行 1 配置java环境,网上有很多教程 2 下载eclipse,网上有很多教程 ps&…...
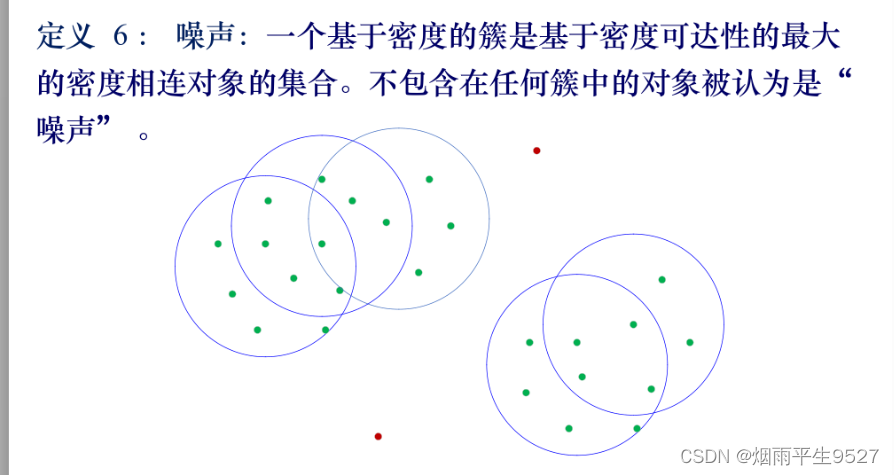
数据挖掘(6)聚类分析
一、什么是聚类分析 1.1概述 无指导的,数据集中类别未知类的特征: 类不是事先给定的,而是根据数据的相似性、距离划分的聚类的数目和结构都没有事先假定。挖掘有价值的客户: 找到客户的黄金客户ATM的安装位置 1.2区别 二、距离和相似系数 …...
在启智平台上安装anconda
安装Anaconda3-5.0.1-Linux-x86_64.sh python版本是3.6 在下面的网站上找到要下载的anaconda版本,把对应的.sh文件下载下来 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 把sh文件压缩成.zip文件,拖到启智平台的调试页面 上传到平台上 un…...

棒球省队建设实施办法·棒球1号位
棒球省队建设实施办法 1. 建设目标与原则 提升棒球省队整体竞技水平 为了提升棒球省队整体竞技水平,我们需要采取一系列有效的措施。 首先,我们应该加强对棒球运动的投入和关注。各级政府和相关部门应加大对棒球运动的经费投入,提高球队的…...

架构案例2017(五十二)
第5题 阅读以下关于Web系统架构设计的叙述,在答题纸上回答问题1至问题3.【说明】某电子商务企业因发展良好,客户量逐步增大,企业业务不断扩充,导致其原有的B2C商品交易平台己不能满足现有业务需求。因此,该企业委托某…...

给四个点坐标计算两条直线的交点
文章目录 1 chatgpt42、文心一言3、星火4、Bard总结 我使用Chatgpt4和文心一言、科大讯飞星火、google Bard 对该问题进行搜索,分别给出答案。先说结论,是chatgpt4和文心一言给对了答案, 另外两个部分正确。 问题是:python 给定四…...

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…...
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程系统化教程,不需英语基础。学习链接 https://edu.csdn.net/course/detail/39036...

YOLOv7改进:动态蛇形卷积(Dynamic Snake Convolution),增强细微特征对小目标友好,实现涨点 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征,对小目标检测很适用 Dynamic Snake Convolution | 亲测在多个数据集能够实现大幅涨点 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.…...

从文心大模型4.0与FuncGPT:用AI为开发者打开新视界
今天,在百度2023世界大会上,文心大模型4.0正式发布,而在大洋的彼岸,因为大模型代表ChatGPT之类的AI编码工具来势汹汹,作为全世界每个开发者最爱的代码辅助网站,Stack Overflow的CEO Prashanth Chandrasekar…...
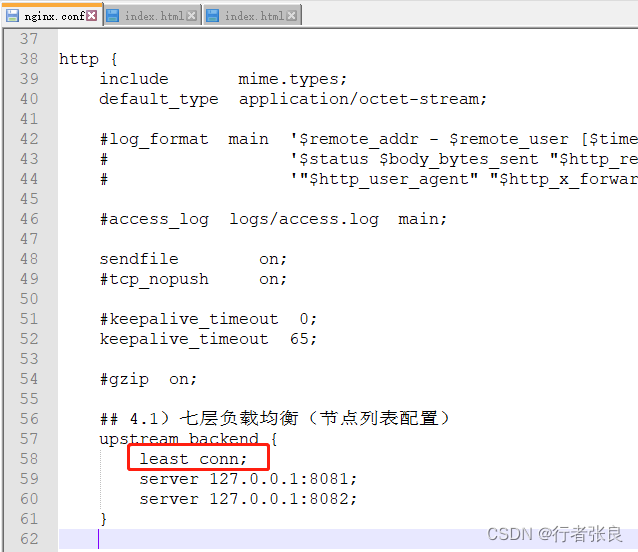
Nginx集群负载均衡配置完整流程
今天,良哥带你来做一个nginx集群的负载均衡配置的完整流程。 一、准备工作 本次搭建的操作系统环境是win11,linux可配置类同。 1)首先,下载nginx。 下载地址为:http://nginx.org/en/download.html 良哥下载的是&am…...

如何生成SSH服务器的ed25519公钥SHA256指纹
最近搭建ubuntu服务器,远程登录让确认指纹,研究一番搞懂了,记录一下。 1、putty 第一次登录服务器,出现提示: 让确认服务器指纹是否正确。 其中:箭头指向的 ed25519 :是一种非对称加密的签名方法…...
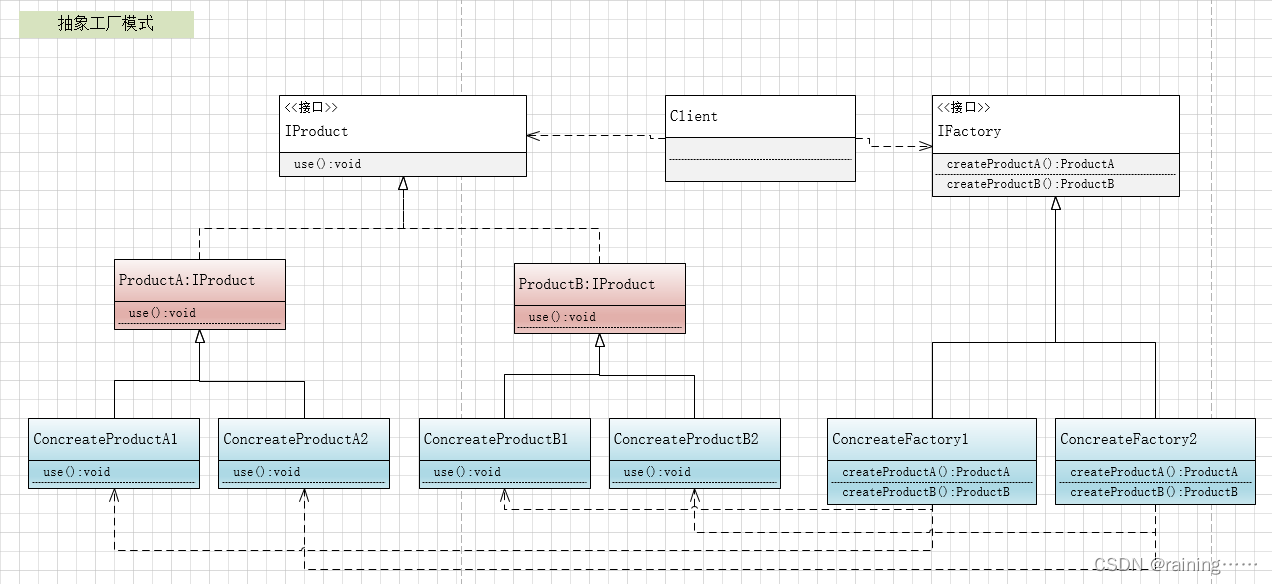
设计模式:抽象工厂模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
大家好!本节主要介绍设计模式中的抽象工厂模式。 简介: 抽象工厂模式,它是所有形态的工厂模式中最为抽象和最具一般性的一种形态。它用于处理当有多个抽象角色时的情况。抽象工厂模式可以向客户端提供一个接口,使客户端在不必指…...
ocpp-远程启动(RemoteStartTransaction)、远程停止(RemoteStopTransaction)
目录 1、介绍 2、远程启动-RemoteStartTransaction 3、远程停止-RemoteStopTransaction 4、代码 4.1 OcppRechongFeign 4.2 CmdController 4.3 CmdService 4.4 RemoteStartTransactionReq 4.5 接收报文-DataAnalysisController 4.6 接收报文实现类-DataAnalysisServi…...
【网络安全】安全的系统配置
系统配置是网络安全的重要组成部分。一个不安全的系统配置可能会使网络暴露在攻击者面前,而一个安全的系统配置可以有效地防止攻击者的入侵。在本文中,我们将详细介绍如何配置一个安全的系统,包括操作系统配置,网络服务配置&#…...

conda使用一般步骤
Terminal:conda create --name myenv python3.7 如果环境不行的话 1.source /opt/anaconda3/bin/activate 2.可能是没有源 vim ~/.condarc将需要的源装上 conda clean -i将原先的源删除 3.然后再conda create即可 4.需要激活环境 conda activate numpy 5.pycharm配置…...

LabVIEW编程整洁之道:提升代码可读性与可维护性的实战技巧
1. 项目概述:从“能用”到“好用”的进阶之路在LabVIEW这个图形化编程环境里摸爬滚打十几年,我见过太多工程师能把功能做出来,但做出来的程序却像一团乱麻——前面板控件堆叠、程序框图连线交错、结构嵌套深不见底。这样的程序,别…...
)
TVA智能体范式的工业视觉革命(4)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战)
告别UUID!用Apache Commons Lang3的RandomStringUtils生成更灵活的随机字符串(Java实战) 在Java开发中,生成随机字符串的需求无处不在——从用户邀请码、临时密码到订单编号,我们经常需要快速生成一串既随机又可读的字…...

从游戏显卡到专业GIS:如何为你的SuperMap三维场景挑选并调校一张合适的显卡
从游戏显卡到专业GIS:如何为你的SuperMap三维场景挑选并调校一张合适的显卡 在数字孪生和智慧城市建设的浪潮中,三维GIS平台正成为空间数据分析的核心工具。SuperMap作为国产GIS软件的领军者,其三维模块对硬件性能的需求常常让技术决策者陷入…...

从家庭网络到公网:一次完整的HTTP请求,在Wireshark中看清NAT的“魔术”
从家庭网络到公网:一次完整的HTTP请求,在Wireshark中看清NAT的“魔术” 清晨的阳光透过窗帘洒在书桌上,你像往常一样打开笔记本电脑,在浏览器地址栏输入"www.baidu.com"并按下回车。这个看似简单的动作背后,…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

如何用MPC-HC打造专业级影音播放体验:从安装到优化的完整指南
如何用MPC-HC打造专业级影音播放体验:从安装到优化的完整指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc MPC-HC(Media Playe…...

跨平台图形API实战选型:从Vulkan、DirectX到Metal与WebGPU的架构抉择
1. 图形API的演变与现状 十年前我刚入行时,OpenGL还是图形开发的主流选择。记得第一次在Ubuntu上配置GLFW环境就花了整整两天,而现在Vulkan只需要几行命令就能跑起来。这种变化背后是GPU架构的革命性演进——从固定功能管线到可编程着色器,再…...

推荐靠谱多模型聚合平台生产厂家,技术扎实服务贴心有保障
随着AI大模型应用场景不断拓展,企业对多模型聚合平台的需求持续攀升。行业报告显示,近一年国内企业采购多模型聚合服务的订单量同比增长超60%,如何选择技术扎实、服务贴心的平台生产厂家,成为企业数字化转型的关键决策。一、技术实…...

AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环Agent 早就跑通了,但有一条横切线一直没单独写过:深度阅读那种动辄一千多字的输出,怎么知道 LLM 是不是在自圆其说。这周回过头来补这一篇,顺便把本周做的几个小改动一并…...