avro格式详解
【Avro介绍】
Apache Avro是hadoop中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。
Avro提供了:
丰富的数据结构
可压缩、快速的二进制数据格式
一个用来存储持久化数据的容器文件
远程过程调用
与动态语言的简单集成,代码生成不需要读取或写入数据文件,也不需要使用或实现RPC协议。代码生成是一种可选的优化,只值得在静态类型语言中实现。
基于以上这些优点,avro在hadoop体系中被广泛使用。除此之外,在hudi、iceberg中也都有用到avro作为元数据信息的存储格式。
【schema】
Avro依赖"schema"(模式)来实现数据结构的定义,schema通过json对象来进行描述表示,具体表现为:
一个json字符串命名一个定义的类型
一个json对象,其格式为`{"type":"typeName" ...attributes...}`,其中`typeName`为原始类型名称或复杂类型名称。
一个json数组,表示嵌入类型的联合
schema中的类型由原始类型(也就是基本类型)(null、boolean、int、long、float、double、bytes和string)和复杂类型(record、enum、array、map、union和fixed)组成。
1、原始类型
原始类型包括如下几种:
null:没有值
boolean:布尔类型的值
int:32位整形
long:64位整形
float:32位浮点
double:64位浮点
bytes:8位无符号类型
string:unicode字符集序列
原始类型没有指定的属性值,原始类型的名称也就是定义的类型的名称,因此,schema中的"string"等价于{"type":"string"}。
2、复杂类型
Avro支持6种复杂类型:records、enums、arrays、maps、unions和fixed。
1)Records
reocrds使用类型名称"record",并支持以下属性
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
doc:一个json字符串,为用户提供该模式的说明(可选)
aliases:字符串的json数组,为该记录提供备用名称
fields:一个json数组,罗列所有字段(必选),每个字段又都是一个json对象,并包含如下属性:
name:字段的名称(必选)
doc:字段的描述(可选)
type:一个schema,定义如上
default:字段的默认值
order:指定字段如何影响记录的排序顺序,有效值为`"ascending"`(默认值)、"descending"和"ignore"。
aliases:别名
一个简单示例:
{"type": "record","name": "LongList","aliases": ["LinkedLongs"],"fields", [{"name": "value", "type": "long"},{"name": "next", "type": ["null", "LongList"]}]
}2)Enums
Enum使用类型名称"enum",并支持以下属性
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
aliases:字符串的json数组,为该记录提供备用名称
doc:一个json字符串,为用户提供该模式的说明(可选)
symbols:一个json数组,以json字符串的形式列出符号。在枚举中每个符号必须唯一,不能重复,每个符号都必须匹配正则表达式"[A-Za-z_][A-Za-z0-9_]*"。
default:该枚举的默认值。
示例:
{"type": "enum","name": "Suit","symbols": ["SPADES", "HEARTS", "DIAMONDS", "CLUBS"]
}3) Arrays
item:数组中元素的schema
一个例子:声明一个value为string的array
{"type": "array","items": "string","default": []
}4)Maps
values:map的值(value)的schema,其key被假定为字符串
一个例子:声明一个value为long类型,(key类型为string)的map
{"type": "map","values": "long","default": {}
}5)Unions
联合使用json数组表示,例如[null, "test"]声明一个模式,它可以是空值或字符串。
需要注意的是:当为union类型的字段指定默认值时,默认值的类型必须与union第一个元素匹配,因此,对于包含"null"的union,通常先列出"null",因为此类型的union的默认值通常为空。
另外, union不能包含多个相同类型的schema,类型为record、fixed和eum除外。
6)Fixed
Fixed使用类型名称"fixed"并支持以下属性:
name:提供记录名称的json字符串(必选)
namespace:限定名称的json字符串
aliases:字符串的json数组,为该记录提供备用名称
doc:一个json字符串,为用户提供该模式的说明(可选)
size:一个整数,指定每个值的字节数(必须)
例如,16字节的数可以声明为:
{"type": "fixed","name": "md5","size": 16
}【Avro的文件存储格式】
1、数据编码
1)原始类型
对于null类型:不写入内容,即0字节长度的内容表示;
对于boolean类型:以1字节的0或1来表示false或true;
对于int、long:以zigzag的方式编码写入
对于float:固定4字节长度,先通过floatToIntBits转换为32位整数,然后按小端编码写入。
对于double:固定8字节长度,先通过doubleToLongBits转换为64位整型,然后按小端编码写入。
对于bytes:先写入长度(采用zigzag编码写入),然后是对应长度的二进制数据内容
对于string:同样先写入长度(采用zigzag编码写入),然后再写入字符串对应utf8的二进制数据。
2)复杂类型
对于enums:只需要将enum的值所在的Index作为结果进行编码即可,例如,枚举值为["A","B","C","D"],那么0就表示”A“,3表示"D"。
对于maps:被编码为一系列的块。每个块由一个长整数的计数表示键值对的个数(采用zigzag编码写入),其后是多个键值对,计数为0的块表示map的结束。每个元素按照各自的schema类型进行编码。
对于arrays:与map类似,同样被编码为一系列的块,每个块包含一个长整数的计数,计数后跟具体的数组项内容,最后以0计数的块表示结束。数组项中的每个元素按照各自的schema类型进行编码。
对于unions:先写入long类型的计数表示每个value值的位置序号(从零开始),然后再对值按对应schema进行编码。
对于records:直接按照schema中的字段顺序来进行编码。
对于fixed:使用schema中定义的字节数对实例进行编码。
2、存储格式
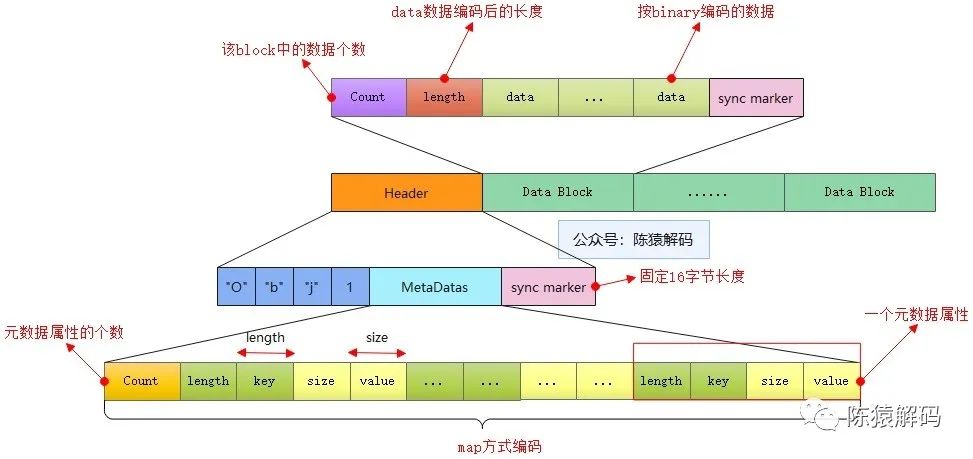
在一个标准的avro文件中,同时存储了schema的信息,以及对应的数据内容。具体格式由三部分组成:
魔数
固定4字节长度,内容为字符'O','b','j',以及版本号标识,通常为1。
元数据信息
文件的元数据属性,包括schema、数据压缩编码方式等。整个元数据属性以一个map的形式编码存储,每个属性都以一个KV的形式存储,属性名对应key,属性值对应value,并以字节数组的形式存储。最后以一个固定16字节长度的随机字符串标识元数据的结束。
数据内容
而数据内容则由一个或多个数据块构成。每个数据块的最前面是一个long型(按照zigzag编码存储)的计数表示该数据块中实际有多少条数据,后面再跟一个long型的计数表示编码后的(N条)数据的长度,随后就是按照编码进行存储的一条条数据,在每个数据块的最后都有一个16字节长度的随机字符串标识块的结束。
整体存储内容如下图所示:
3、存储格式
我们通过一个实际例子来对照分析下。
首先定义schema的内容,具体为4个字段的表,名称(字符串)、年龄(整型)、技能(数组)、其他(map类型),详细如下所示:
{"type":"record","name":"person","fields": [{"name": "name","type": "string"},{"name": "age","type": "int"},{"name": "skill","type": {"type":"array","items": "string"}},{"name": "other","type": {"type": "map","values": "string"}}]
}再按照上面的schema定义两条数据(person.json):
{"name":"hncscwc","age":20,"skill":["hadoop","flink","spark","kafka"],"other":{"interests":"basketball"}}
{"name":"tom","age":18, "skill":["java","scala"],"other":{}}通过avro-tools可以生成一个avro文件:
java -jar avro-tools-1.7.4.jar fromjson --schema-file person.avsc person.json > person.avro通过二进制的方式查看生成的avro文件内容:
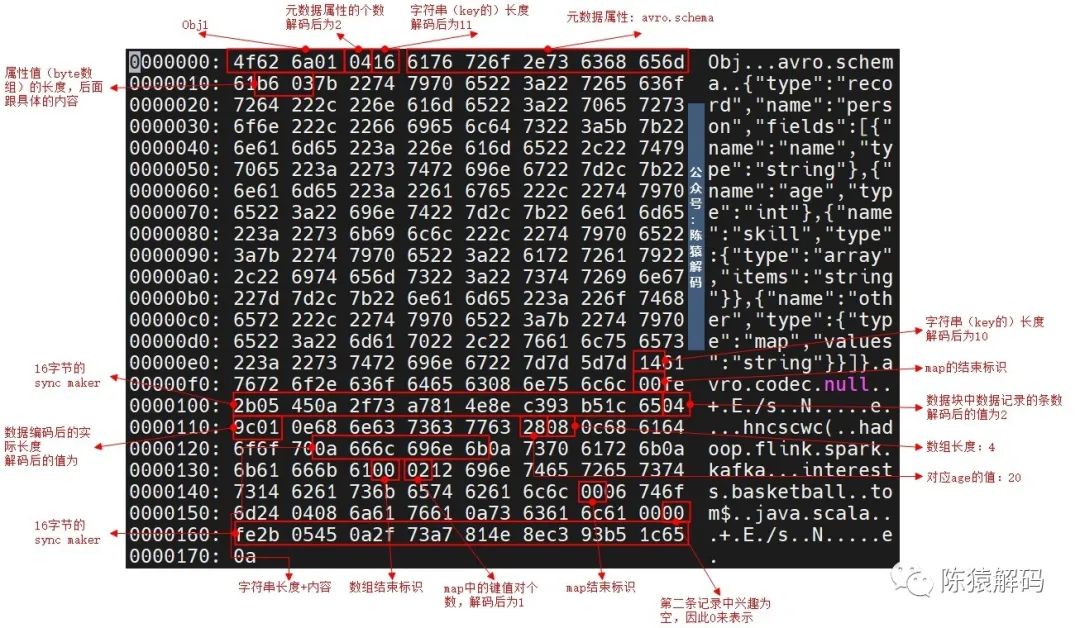
另外,对于一个已存在的文件,也可以通过avro-tools工具查看schema内容、数据内容。
[root@localhost avro]$ java -jar avro-tools-1.7.4.jar getschema ./person.avro
{"type" : "record","name" : "person","fields" : [ {"name" : "name","type" : "string"}, {"name" : "age","type" : "int"}, {"name" : "skill","type" : {"type" : "array","items" : "string"}}, {"name" : "other","type" : {"type" : "map","values" : "string"}} ]
}
[root@localhost avro]$ java -jar avro-tools-1.7.4.jar tojson ./person.avro
{"name":"hncscwc","age":20,"skill":["hadoop","flink","spark","kafka"],"other":{"interests":"basketball"}}
{"name":"tom","age":18,"skill":["java","scala"],"other":{}}【小结】
本文对avro的格式定义、编码方式、以及实际存储的文件格式进行了详细说明,最后也以一个实际例子进行了对照说明。另外, 在官网中还涉及rpc的使用、mapreduce的使用,这里就没有展开说明,有兴趣的可移步官网进行查阅。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,也可以拍砖指点,最后,欢迎加我微信交流~
相关文章:
avro格式详解
【Avro介绍】Apache Avro是hadoop中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。Avro提供了:丰富的数据结构可压缩、快速的二进制数据格式一个用来存储持久化数据的容器文件远程过程…...

【涨薪技术】0到1学会性能测试 —— LR录制回放事务检查点
前言 上一次推文我们分享了性能测试分类和应用领域,今天带大家学习性能测试工作原理、事务、检查点!后续文章都会系统分享干货,带大家从0到1学会性能测试,另外还有教程等同步资料,文末免费获取~ 01、LR工作原理 通常…...

卡尔曼滤波原理及代码实战
目录简介1.原理介绍场景假设(1).下一时刻的状态(2).增加系统的内部控制(3).考虑运动系统外部的影响(4).后验估计:预测结果与观测结果的融合卡尔曼增益K2.卡尔曼滤波计算过程(1).预测阶段(先验估计阶段)(2).更新阶段(后验估计阶段&…...
Jmeter使用教程
目录一,简介二,Jmeter安装1,下载2,安装三,创建测试1,创建线程组2,创建HTTP请求默认值3,创建HTTP请求4,添加HTTP请求头5,添加断言6,添加查看结果树…...

论文笔记|固定效应的解释和使用
DeHaan E. Using and interpreting fixed effects models[J]. Available at SSRN 3699777, 2021. 虽然固定效应在金融经济学研究中无处不在,但许多研究人员对作用的了解有限。这篇论文解释了固定效应如何消除遗漏变量偏差并影响标准误差,并讨论了使用固…...
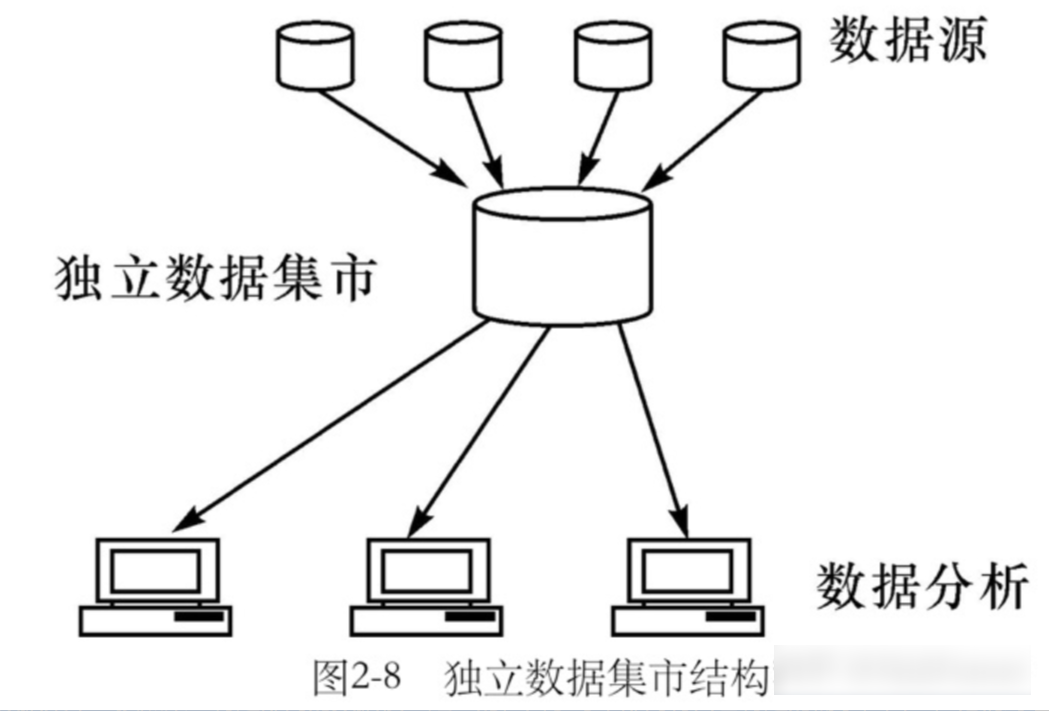
数据集市与数据仓库的区别
数据仓库是企业级的,能为整个企业各个部门的运作提供决策支持;而数据集市则是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。 1、两种数据集市结构 数据集市按数据的来源分为以下两种 &#x…...

Golang学习Day3
😋 大家好,我是YAy_17,是一枚爱好网安的小白。 本人水平有限,欢迎各位师傅指点,欢迎关注 😁,一起学习 💗 ,一起进步 ⭐ 。 ⭐ 此后如竟没有炬火,我便是唯一的…...
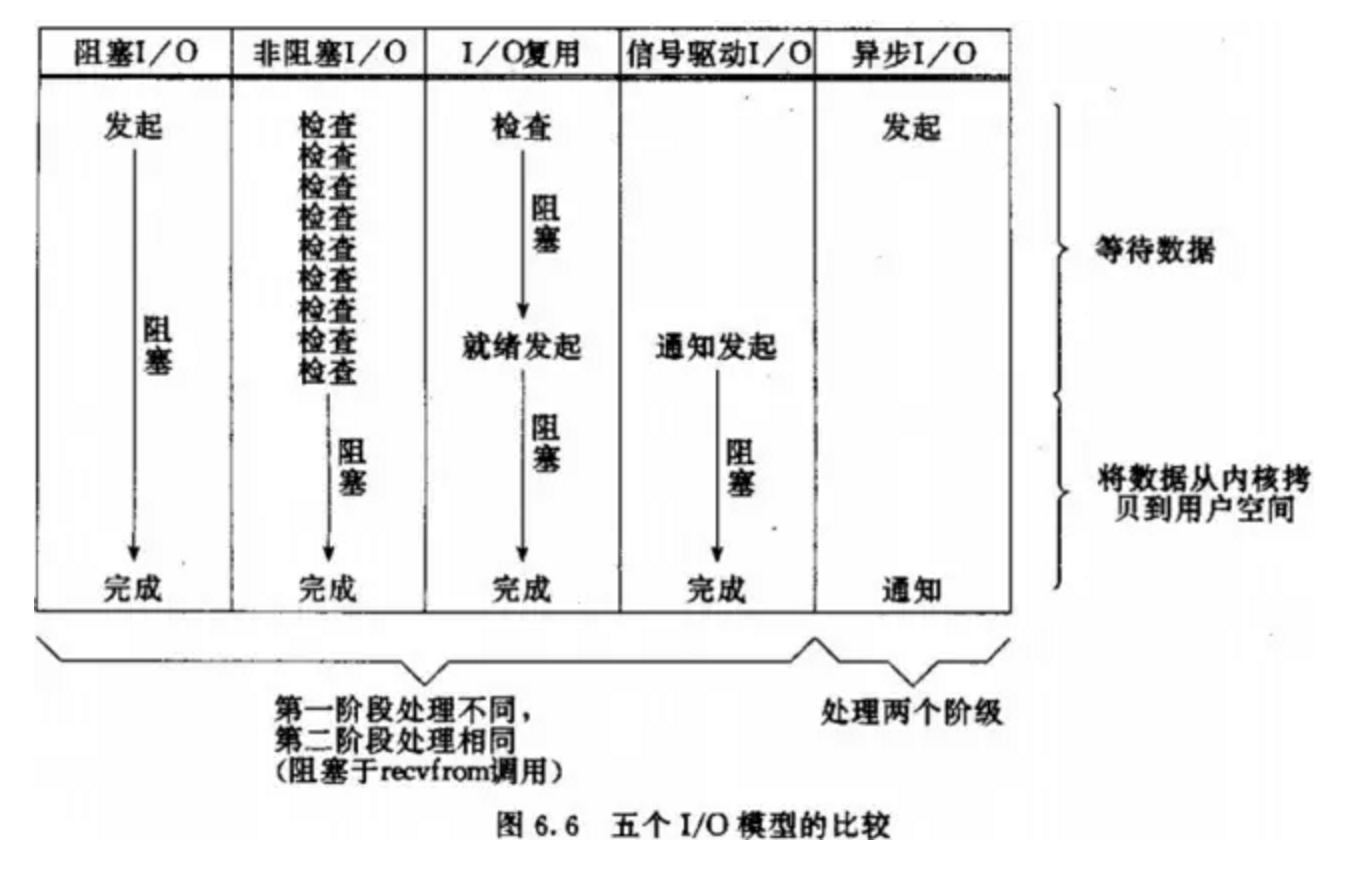
Python并发编程-事件驱动模型
一、事件驱动模型介绍 1、传统的编程模式 例如:线性模式大致流程 开始--->代码块A--->代码块B--->代码块C--->代码块D--->......---&…...
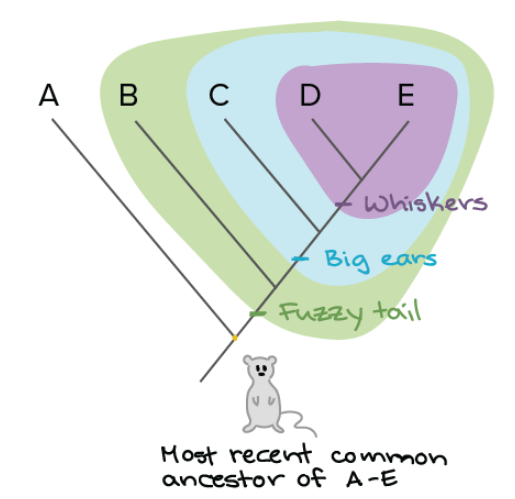
构建系统发育树简述
1. 要点 系统发育树代表了关于一组生物之间的进化关系的假设。可以使用物种或其他群体的形态学(体型)、生化、行为或分子特征来构建系统发育树。在构建树时,我们根据共享的派生特征(不同于该组祖先的特征)将物种组织成…...
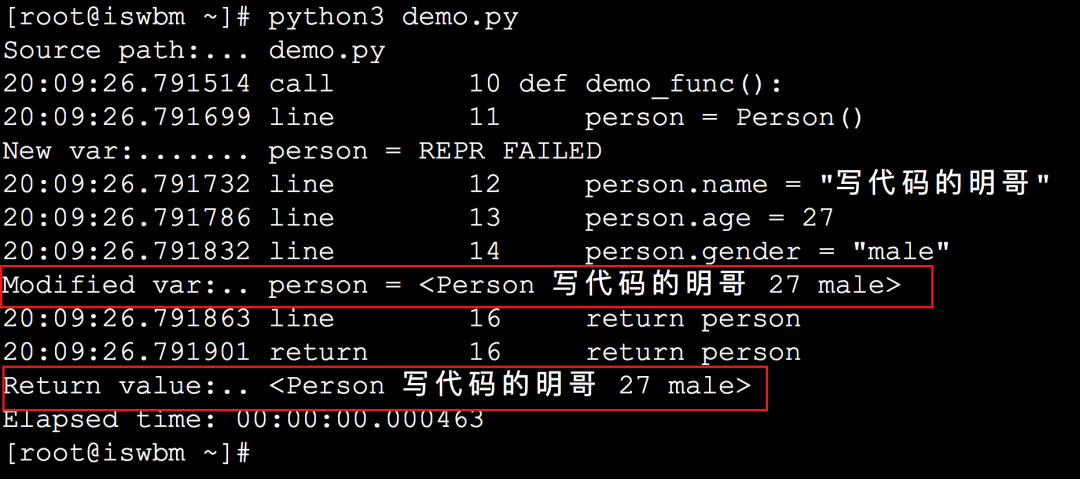
这款 Python 调试神器推荐收藏
大家好,对于每个程序开发者来说,调试几乎是必备技能。 代码写到一半卡住了,不知道这个函数执行完的返回结果是怎样的?调试一下看看 代码运行到一半报错了,什么情况?怎么跟预期的不一样?调试一…...
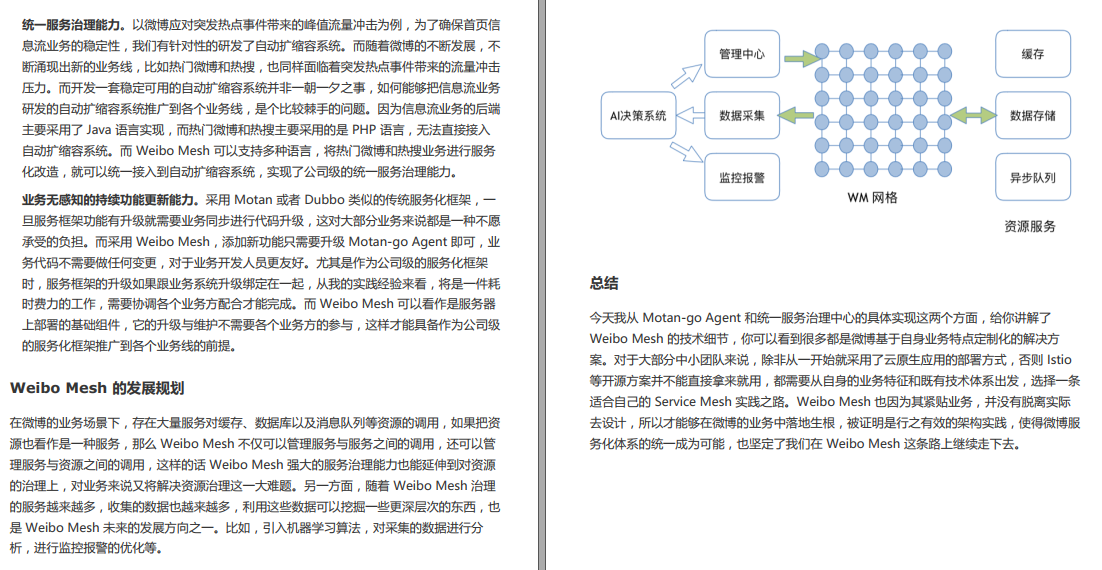
金三银四吃透这份微服务笔记,面试保准涨10K+
很多人对于微服务技术也都有着一些疑虑,比如: 微服务这技术虽然面试的时候总有人提,但作为一个开发,是不是和我关系不大?那不都是架构师的事吗?微服务不都是大厂在玩吗?我们这个业务体量用得着…...
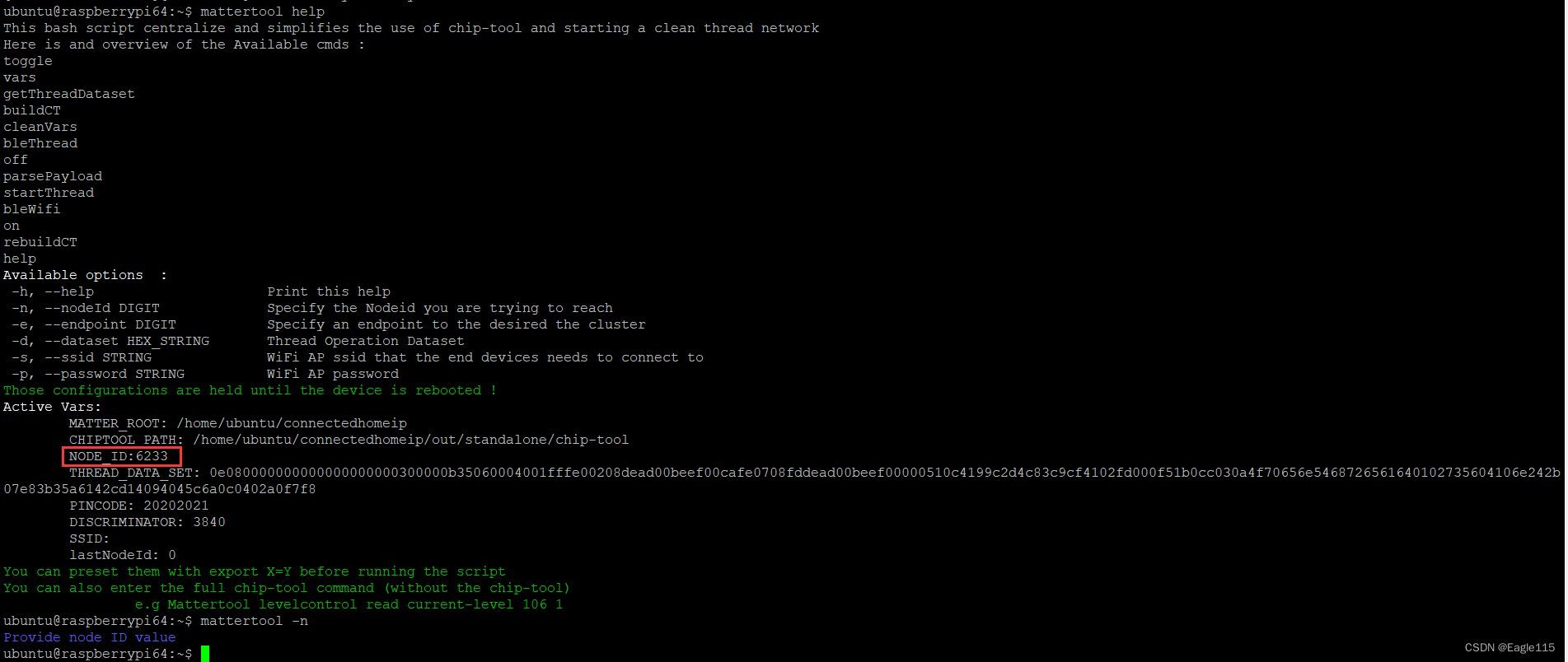
构建matter over Thread的演示系统-efr32
文章目录1. 简介2. 构建测试系统2.1设置 Matter Hub(Raspberry Pi)2.2 烧录Open Thread RCP固件2.3 烧录待测试的matter设备3. 配网和测试:3.1 使用mattertool建立Thread网络3.2 使用mattertool配置设备入网3.3 使用mattertool控制matter设备3.4 查看节点的Node ID等…...

【一天一门编程语言】Matlab 语言程序设计极简教程
Matlab 语言程序设计极简教程 用 markdown 格式输出答案。 不少于3000字。细分到2级目录。 目录 Matlab 语言程序设计极简教程 简介Matlab 工作空间Matlab 基本数据类型Matlab 语句和表达式Matlab 函数和程序Matlab 图形界面程序设计Matlab 应用实例 简介 Matlab是一种编…...
看似平平无奇的00后,居然一跃上岸字节,表示真的卷不过......
又到了一年一度的求职旺季金!三!银!四!在找工作的时候都必须要经历面试这个环节。在这里我想分享一下自己上岸字节的面试经验,过程还挺曲折的,但是还好成功上岸了。大家可以参考一下! 0821测评 …...

BZOJ2142 礼物
题目描述 一年一度的圣诞节快要来到了。每年的圣诞节小E都会收到许多礼物,当然他也会送出许多礼物。不同的人物在小E 心目中的重要性不同,在小E心中分量越重的人,收到的礼物会越多。小E从商店中购买了n件礼物,打算送给m个人 &…...
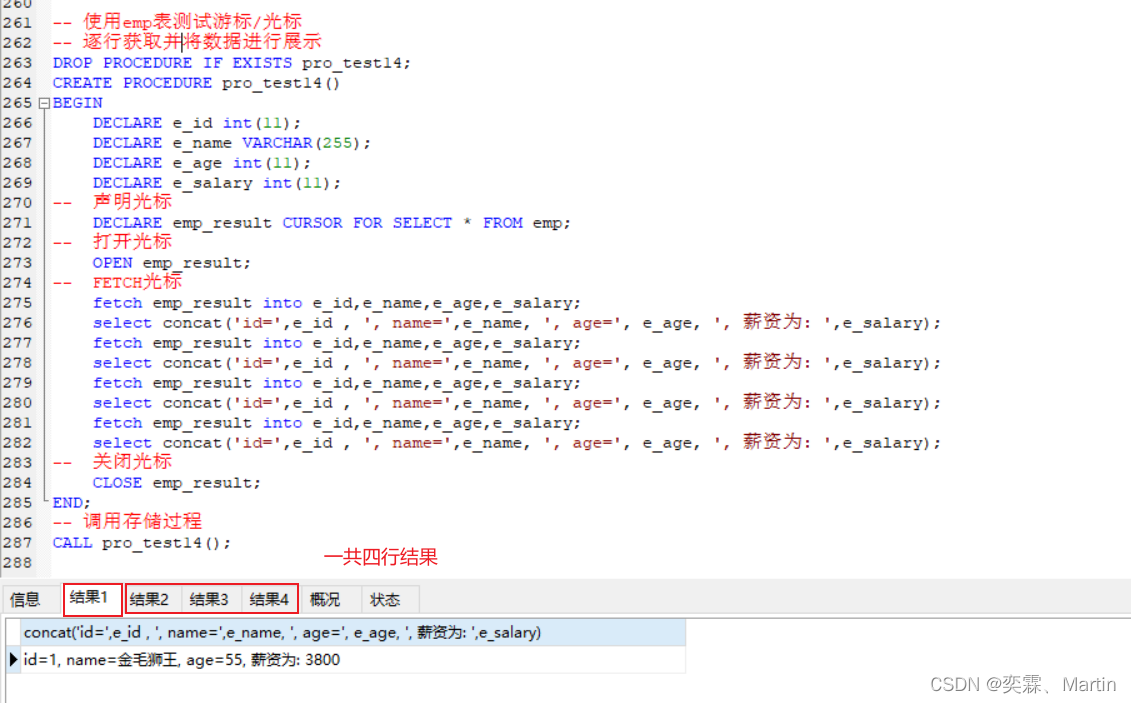
MySQL高级第一讲
目录 一、MySQL高级01 1.1 索引 1.1.1 索引概述 1.1.2 索引特点 1.1.3 索引结构 1.1.4 BTREE结构(B树) 1.1.5 BTREE结构(B树) 1.1.6 索引分类 1.1.7 索引语法 1.1.8 索引设计原则 1.2 视图 1.2.1 视图概述 1.2.2 创建或修改视图 1.3 存储过程和函数 1.3.1 存储过…...

前端面试常用内容——基础积累
1.清除浮动的方式有哪些? 高度塌陷:当所有的子元素浮动的时候,且父元素没有设置高度,这时候父元素就会产生高度塌陷。 清除浮动的方式: 1.1 给父元素单独定义高度 优点: 快速简单,代码少 缺…...
跟着《代码随想录》刷题(三)——哈希表
3.1 哈希表理论基础 哈希表理论基础 3.2 有效的字母异位词 242.有效的字母异位词 C bool isAnagram(char * s, char * t){int array[26] {0};int i 0;while (s[i]) {// 并不需要记住字符的ASCII码,只需要求出一个相对数值就可以了array[s[i] - a];i;}i 0;whi…...
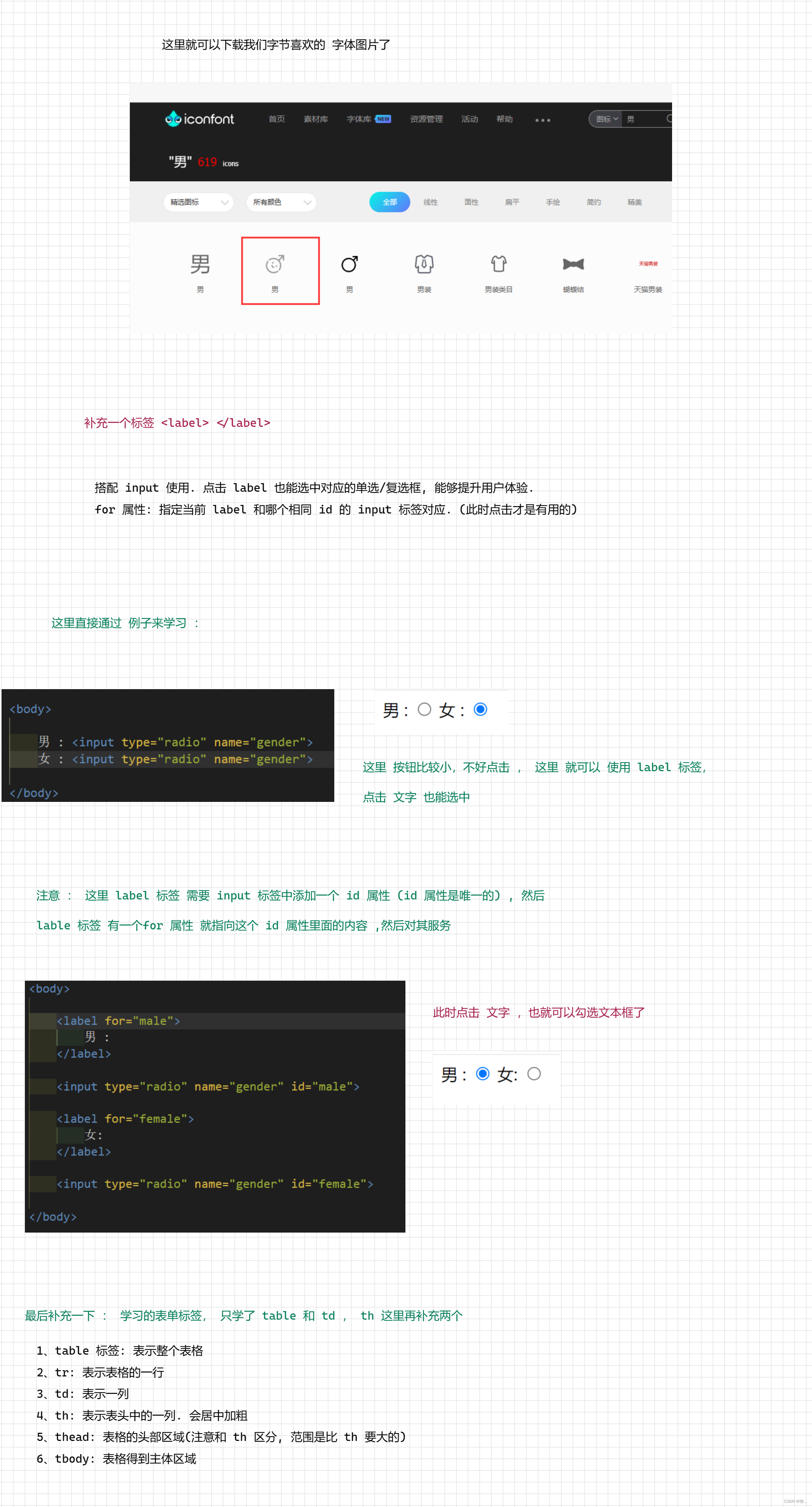
HTML - 扫盲
文章目录1. 前言2. HTML2.1 下载 vscode3 HTML 常见标签3.1 注释标签3.2 标题标签3.3 段落标签3.4 换行标签3.5 格式化标签1. 加粗2. 倾斜3. 下划线3.6 图片标签3.7 超链接标签3.8 表格标签3.9 列表标签4. 表单标签4.1 from 标签4.2 input 标签4.3 select 标签4.4 textarea标签…...
【系统分析师之路】2022上案例分析历年真题
【系统分析师之路】2022上案例分析历年真题 【系统分析师之路】2022上案例分析历年真题【系统分析师之路】2022上案例分析历年真题2022上案例分析历年真题第一题(25分)2022上案例分析历年真题第二题(25分)2022上案例分析历年真题第…...

西门子PLC对接须知:从通信到编程的实战指南
在工业自动化领域,西门子S7系列PLC凭借强大的功能和广泛的兼容性,成为众多企业的首选。无论是设备集成、数据采集还是系统升级,掌握PLC对接的核心要点,是保障项目高效落地的关键。本文将从通信连接、编程架构、数据处理三个维度&a…...

手写NumPy版RBM:从能量函数到吉布斯采样的可调试实现
1. 项目概述:这不是又一个“RBM扫盲帖”,而是一次亲手拆解神经网络祖师爷级模型的实操复盘Restricted Boltzmann Machine(受限玻尔兹曼机),简称RBM,不是教科书里那个被反复引用却没人真去跑通的抽象符号&am…...

Malware-Traffic-Analysis.net:真实恶意流量分析实战指南
1. 这不是另一个“抓包教程网站”,而是一套真实攻防现场的流量解剖实验室Malware-Traffic-Analysis.net——这个名字乍看平平无奇,像极了某篇技术博客末尾随手贴出的参考资料链接。但如果你真点进去,翻过首页那几行朴素的英文介绍,…...

应对每日大赛突发需求,用Taotoken多模型聚合能力灵活选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对每日大赛突发需求,用Taotoken多模型聚合能力灵活选型 在每日大赛这类节奏快、任务多变的场景里,开发者…...

Godot RTS开发实战:从导航到建造的原子化实现
1. 为什么“从零开始玩转Godot RTS引擎”不是一句空话,而是真能落地的开发路径很多人看到“RTS”两个字母就下意识缩手——星际争霸、帝国时代、红色警戒这些名字背后是庞大的系统、复杂的寻路、海量单位同步、资源采集逻辑、建造队列、科技树、视野遮蔽……一连串术…...

软考高项案例分析8:项目风险管理
软考高项案例分析8:项目风险管理 一、项目风险管理过程 1、规划风险管理; 2、识别风险; 3、实施定性风险分析; 4、实施定量风险分析; 5、规划风险应对; 6、实施风险应对; 7、监督风险; 二、案例分析知识点 1. 风险应对措施 威胁应对策略:上报、规避、转移、…...

YOLOv11公共场所吸烟行为目标检测数据集-6496张-smoking-detection-1
YOLOv11公共场所吸烟行为目标检测数据集 📊 数据集基本信息 目标类别: [‘not_smoking’, ‘smoking’]中文类别:[‘不吸烟’, ‘吸烟’]训练集:5644 张验证集:569 张测试集:283 张总计:6496 张…...
)
【独家首发】ElevenLabs未公开的缅甸文字母映射表+音节切分规则(含Unicode 15.1适配清单)
更多请点击: https://codechina.net 第一章:ElevenLabs缅甸文语音支持的底层架构概览 ElevenLabs 对缅甸文(Burmese, my-MM)的语音合成支持并非简单添加语言标签,而是依托其端到端神经语音建模栈完成深度适配。其核心…...

知识竞赛裁判怎么当?评分标准与争议处理
知识竞赛裁判怎么当?评分标准与争议处理公平 专业 高效 守护竞赛的生命线🎯 一、裁判的角色与职责知识竞赛裁判是竞赛公平的守护者,不仅要掌握规则,还要具备快速判断和沟通能力。核心职责:📋 赛前熟悉题…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...